架構師日記-從程式碼到設計的效能優化指南 | 京東雲技術團隊
一 前言
服務效能是指服務在特定條件下的響應速度、吞吐量和資源利用率等方面的表現。據統計,效能優化方面的精力投入,通常佔軟體開發週期的10%到25%左右,當然這和應用的性質和規模有關。效能對提高使用者體驗,保證系統可靠性,降低資源使用率,甚至增強市場競爭力等方面,都有著很大的影響。
效能優化是個系統性工程,宏觀上可分為網路,服務,儲存幾個方向,每個方向又可以細分為架構,設計,程式碼,可用性,度量等多個子項。 本文將重點從程式碼和設計兩個子項展開,談談那些提升效能的知識點。當然,很多效能提升策略都是有代價的,適用於某些特定場景,大家在學習和使用的時候,最好帶著批判的思維,決策前,做好利弊權衡。
先簡單羅列一下效能優化方向:
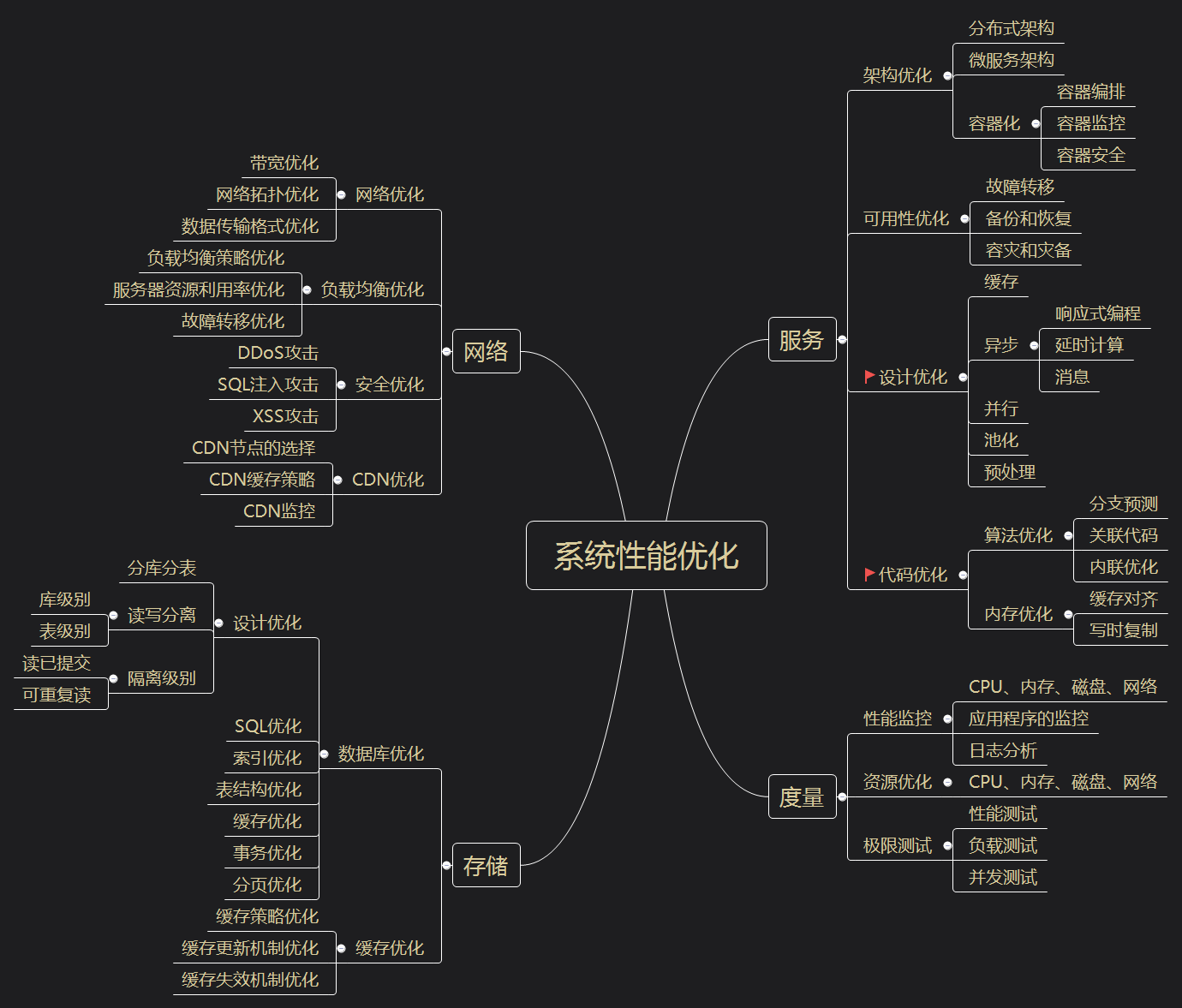
二 程式碼優化
2.1 關聯程式碼
關聯程式碼優化是通過預載入相關程式碼,避免在執行時載入目的碼,造成執行時負擔。我們知道Java有兩個類載入器:Bootstrap class loader和Application class loader。Bootstrap class loader負責載入Java API中包含的核心類,而Application class loader則負責載入自定義類。關聯程式碼優化可以通過以下幾種方式來實現。
預載入關聯
預載入關聯類是指在程式啟動時預先載入目標與關聯類,以避免在執行時載入。可以通過靜態程式碼塊來實現預載入,如下所示:
public class MainClass {
static {
// 預載入MyClass,其實現了相關功能
Class.forName("com.example.MyClass");
}
// 執行相關功能的程式碼
// ...
}
使用執行緒池
執行緒池可以讓多個任務使用同一個執行緒池中的執行緒,從而減少執行緒的建立和銷燬成本。使用執行緒池時,可以在程式啟動時建立執行緒池,並在主執行緒中預載入相關程式碼。然後以非同步方式使用執行緒池中的執行緒來執行相關程式碼,可以提高程式的效能。
使用靜態變數
可以使用靜態變數來快取與關聯程式碼有關的物件和資料。在程式啟動時,可以預先載入關聯程式碼,並將物件或資料儲存在靜態變數中。然後在程式執行時使用靜態變數中快取的物件或資料,以避免重複載入和生成。這種方式可以有效地提高程式的效能,但需要注意靜態變數的使用,確保它們在多執行緒環境中的安全性。
2.2 快取對齊
在介紹快取對齊之前,需要先普及一些CPU指令執行的相關知識。
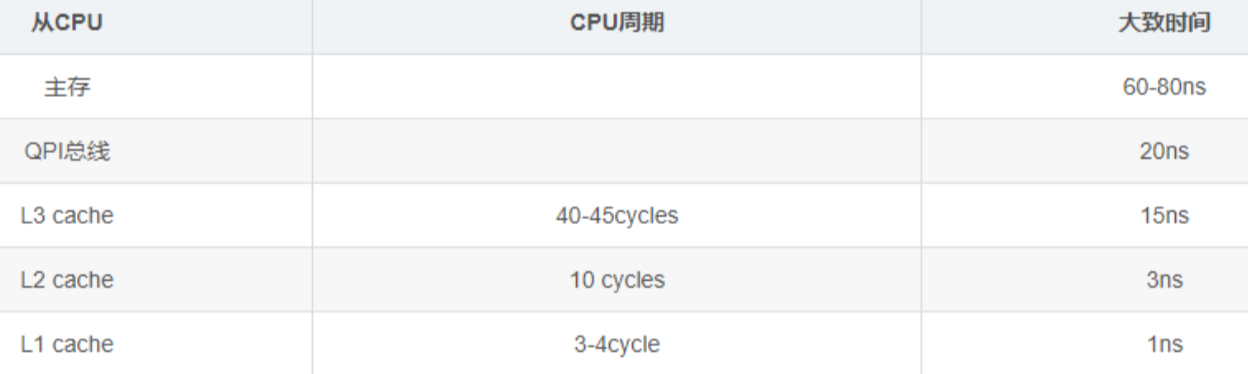
- 快取行(Cache line) : CPU讀取記憶體資料時並非一次唯讀一個位元組,一般是會讀一段64位元組(硬體決定)長度的連續的記憶體塊(chunks of memory),這些塊我們稱之為快取行。
- 偽共用(False Sharing):當執行在兩個不同CPU上的兩個執行緒寫入兩個不同的變數時,如果這兩個變數恰好儲存在同一個 CPU 快取行中,就會發生偽共用(False Sharing)。即當第一個執行緒修改快取行中其中一個變數時,其他參照此快取行變數的執行緒的快取行將會無效。如果CPU需要讀取失效的快取行,它必須等待快取行重新整理,這會導致效能下降。
- CPU停止運轉(stall):當一個核心需要等待另一個核心重新載入快取行時(出現偽共用時),它無法繼續執行下一條指令,只能停止運轉等待,這被稱之為stall。減少偽共用也就意味著減少了stall的發生。
- IPC(instructions per cycle):它表示平均每個 CPU 週期執行的指令數量,很顯然該數值越大效能越好。可以基於IPC指標(比如:閾值1.0)來簡單判斷程式是屬於存取密集型還是計算密集型。Linux系統中可以通過tiptop命令來檢視每個程序的CPU硬體資料:

如何簡單來區分訪存密集型和計算密集型程式?
-
如果 IPC < 1.0, 很可能是 Memory stall 佔主導,多半意味著訪存密集型。
-
如果IPC > 1.0, 很可能是計算密集型的程式。
- CPU利用率:是指系統中CPU處於忙碌狀態的時間與總時間的比例。忙碌狀態時間又可以進一步拆分為指令(instruction)執行消耗週期cycle(%INS) 和 stalled 的週期cycle(%STL)。perf 採集了10秒內全部 CPU 的執行狀態:
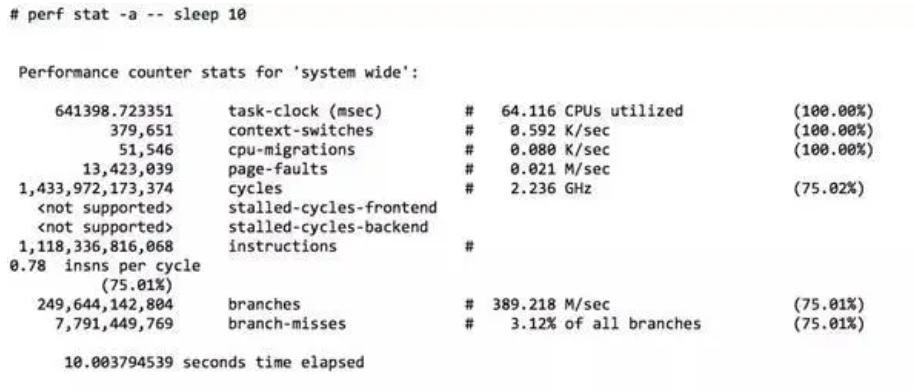
IPC計算
IPC = instructions/cycles
上圖中,可以計算出結果為:0.79
現代處理器一般有多條流水線(比如:4核心),執行 perf 的那臺機器,IPC的理論值可達到4.0。
如果我們從 IPC的角度來看,這臺機器只執行到其處理器最高速度的 19.7%(0.79 / 4.0)。
總之,通過Top命令,看到CPU使用率之後,可以進一步分析指令執行消耗週期和 stalled 週期,有這些更詳細的指標之後,就能夠知道該如何更好地對應用和系統進行調優。
- 快取對齊: 是通過調整資料在記憶體中的分佈,讓資料在被快取時,更有利於CPU從快取中讀取,從而避免了頻繁的記憶體讀取,提高了資料存取的速度。
快取填充(Padding)
減少偽共用也就意味著減少了stall的發生,其中一個手段就是通過填充(Padding)資料的形式,即在適當的距離處插入一些對齊的空間來填充快取行,從而使每個執行緒的修改不會髒汙同一個快取行。
/**
* 快取行填充測試
*
* @author liuhuiqing
* @date 2023年04月28日
*/
public class FalseSharingTest {
private static final int LOOP_NUM = 1000000000;
public static void main(String[] args) throws InterruptedException {
Struct struct = new Struct();
long start = System.currentTimeMillis();
Thread t1 = new Thread(() -> {
for (int i = 0; i < LOOP_NUM; i++) {
struct.x++;
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < LOOP_NUM; i++) {
struct.y++;
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("cost time [" + (System.currentTimeMillis() - start) + "] ms");
}
static class Struct {
// 共用變數
volatile long x;
// 一個long佔用8個位元組,此處定義7個填充資料,來保證業務資料x和y分佈在不同的快取行中
long p1, p2, p3, p4, p5, p6, p7;
// long[] paddings = new long[7];// 使用陣列代替不會生效,思考一下,為什麼?
// 共用變數
volatile long y;
}
}
經過本地測試,這種以空間換時間的方式,即實現了快取行資料對齊的方式,在執行效率方面,比沒有對齊之前,提高了5倍!
@Contended註解
在Java 8中,引入了@Contended註解,該註解可以用來告訴JVM對欄位進行快取對齊(將欄位放入不同的快取行),從而提高程式的效能。使用@Contended註解時,需要在JVM啟動時新增引數-XX:-RestrictContended,實現如下所示:
import sun.misc.Contended;
public class ContendedTest {
@Contended
volatile long a;
@Contended
volatile long b;
public static void main(String[] args) throws InterruptedException {
ContendedTest c = new ContendedTest();
Thread thread1 = new Thread(() -> {
for (int i = 0; i < 10000_0000L; i++) {
c.a = i;
}
});
Thread thread2 = new Thread(() -> {
for (int i = 0; i < 10000_0000L; i++) {
c.b = i;
}
});
final long start = System.nanoTime();
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println((System.nanoTime() - start) / 100_0000);
}
}
對齊記憶體與本地變數
快取填充是解決CPU偽共用問題的解決方案之一,在實際應用中,是否還有其它方案來解決這一問題呢?答案是有的:即對齊記憶體和本地變數。
- 對齊記憶體:記憶體行的大小一般為64個位元組,這個大小是硬體決定的,但大多數編譯器預設情況下都以4位元組的邊界對齊,通過將變數按照記憶體行的大小對齊,可以避免偽共用問題;
- 本地變數:在不同執行緒之間使用不同的變數儲存資料,避免不同的執行緒之間共用同一塊記憶體,Java中的ThreadLocal就是一種典型的實現方式;
2.3 分支預測
分支預測是CPU動態執行技術中的主要內容,是通過猜測程式中的分支語句(如if-else語句或者回圈語句)的執行路徑來提高CPU執行效率的技術。其原理是根據之前的歷史記錄和統計資料,預測程式下一步要執行的指令是分支跳轉指令還是順序執行指令,從而提前載入相關資料,減少CPU等待指令執行的空閒時間。預測準確率越高,CPU的效能提升就越高。那麼如何提高預測的準確率呢?
- 關注圈複雜度
過多的條件語句和巢狀的條件語句會導致分支的預測難度大幅上升,從而降低分支預測的準確率和效率。一般來說,可以通過優化程式碼邏輯結構、減少冗餘等方式來避免過多的條件語句和巢狀的條件語句。
- 優先處理常用路徑
在編寫程式碼時,應該優先處理常用路徑,以減少CPU對分支的預測,提高預測準確率和效率。例如,在if-else語句中,應該將常用的路徑放在if語句中,而將不常用的路徑放在else語句中。
2.4 寫時複製
Copy-On-Write (COW)是一種記憶體管理機制,也被稱為寫時複製。其主要思想是在需要寫入資料時,先進行資料拷貝,然後再進行操作,從而避免了對資料進行不必要的複製和操作。COW機制可以有效地降低記憶體使用率,提高程式的效能。
在建立程序或執行緒的時候,作業系統為其分配記憶體時,不是複製一個完整的實體地址空間,而是建立一個指向父程序/執行緒實體地址空間的虛擬地址空間,併為它們的所有頁面設定"唯讀"標誌。當子程序/執行緒需要修改頁面時,會觸發一個缺頁異常,並將涉及到的頁面進行資料的複製,併為複製的頁面重新分配記憶體。子程序/執行緒只能夠操作複製後的地址空間,父程序/執行緒的原始記憶體空間則被保留。
由於COW機制在寫入之前進行資料拷貝,所以可以有效地避免頻繁的記憶體拷貝和分配操作,降低了記憶體的佔用率,提高了程式的效能。並且,COW機制也避免了資料的不必要複製,從而減少了記憶體的消耗和記憶體碎片的產生,提高了系統中可用記憶體的數量。
ArrayList類可以使用Copy-On-Write機制來提高效能。
// 初始化陣列
private List<String> list = new CopyOnWriteArrayList<>();
// 向陣列中新增元素
list.add("value");
需要注意的是,Copy-On-Write機制適用於讀操作比寫操作多的情況,因為它假定寫操作的頻率較低,從而可以通過犧牲複製的開銷來減少鎖的操作和記憶體分配的消耗。
2.5 內聯優化
在Java中,每次呼叫方法都需要進行一些額外的操作,例如建立堆疊幀、儲存暫存器狀態等,這些額外的操作會消耗一定的時間和記憶體資源。內聯優化是一種編譯器優化技術,Java虛擬機器器通常使用即時編譯器(JIT)來進行方法內聯,用於提高程式的效能。內聯優化的目標是將函數的呼叫替換成函數本身的程式碼,以減少函數呼叫的開銷,從而提高程式的執行效率。
需要注意的是,方法內聯並不是在所有情況下都能夠提高程式的執行效率。如果方法內聯導致程式碼複雜度增加或者記憶體佔用增加,反而會降低程式的效能。因此,在使用方法內聯時需要根據具體情況進行權衡和優化。
final修飾符
final修飾符可以使方法成為不可重寫的方法。因為不可重寫,所以在編譯器優化時可以將它們的程式碼嵌入到呼叫它們的程式碼中,從而避免函數呼叫的開銷。使用final修飾符可以在一定程度上提高程式的效能,但同時也減弱了程式碼的可延伸性。
限制方法長度
方法的長度會影響其在編譯時能否被內聯。通常情況下,長度較小的方法更容易被內聯。因此,可以在設計中將程式碼分解和重構為更小的函數。這種方式並不是100%確保可以內聯,但至少提高了實現此優化的機會。內聯調優引數,如下表格:
| JVM引數 | 預設值 (JDK 8, Linux x86_64) | 引數說明 |
|---|---|---|
| -XX:MaxInlineSize= |
35 位元組碼 | 內聯方法大小上限 |
| -XX:FreqInlineSize= |
325 位元組碼 | 內聯熱方法的最大值 |
| -XX:InlineSmallCode= |
1000位元組的原生程式碼(非分層) 2000位元組的原生程式碼(分層編譯) | 如果最後一層的的分層編譯程式碼量已經超過這個值,就不進行內聯編譯 |
| -XX:MaxInlineLevel= |
9 | 呼叫層級比這個值深的話,就不進行內聯 |
內聯註解
在Java 5之後,引入了內聯註解@inline,使用此註解可以在編譯時通知編譯器,將該方法內聯到它的呼叫處。註解@inline在Java 9之後已經被棄用,可以使用@ForceInline註釋來替代,同時設定JVM引數:
-XX:+UnlockExperimentalVMOptions -XX:+EnableJVMCI -XX:+JVMCICompiler
@ForceInline
public static int add(int a, int b) {
return a + b;
}
2.6 編碼優化
反射機制
Java反射在一定程度上會影響效能,因為它需要在執行時進行型別檢查轉換和方法查詢,這比直接呼叫方法會更耗時。此外,反射也不會受到編譯器的優化,因此可能會導致更慢的程式碼執行速度。
要解決這個問題有以下幾種方式:
- 儘可能使用原生方法呼叫,而不是通過反射呼叫;
- 儘可能快取反射呼叫結果,避免重複呼叫。例如,可以將反射結果快取到靜態變數中,以便下次使用時直接獲取,而不必再次使用反射;
- 使用位元組碼增強技術;
下面著重介紹一下反射結果快取和位元組碼增強兩種方案。
- 反射結果快取可以大幅減少反射過程中的型別檢查,型別轉換和方法查詢等動作,是降低反射對程式執行效率影響的一種優化策略。
/**
* 反射工具類
*
* @author liuhuiqing
* @date 2023年5月7日
*/
public abstract class BeanUtils {
private static final Logger LOGGER = LoggerFactory.getLogger(BeanUtils.class);
private static final Field[] NO_FIELDS = {};
private static final Map<Class<?>, Field[]> DECLARED_FIELDS_CACHE = new ConcurrentReferenceHashMap<Class<?>, Field[]>(256);
private static final Map<Class<?>, Field[]> FIELDS_CACHE = new ConcurrentReferenceHashMap<Class<?>, Field[]>(256);
/**
* 獲取當前類及其父類別的屬性陣列
*
* @param clazz
* @return
*/
public static Field[] getFields(Class<?> clazz) {
if (clazz == null) {
throw new IllegalArgumentException("Class must not be null");
}
Field[] result = FIELDS_CACHE.get(clazz);
if (result == null) {
Field[] fields = NO_FIELDS;
Class<?> searchType = clazz;
while (Object.class != searchType && searchType != null) {
Field[] tempFields = getDeclaredFields(searchType);
fields = mergeArray(fields, tempFields);
searchType = searchType.getSuperclass();
}
result = fields;
FIELDS_CACHE.put(clazz, (result.length == 0 ? NO_FIELDS : result));
}
return result;
}
/**
* 獲取當前類屬性陣列(不包含父類別的屬性)
*
* @param clazz
* @return
*/
public static Field[] getDeclaredFields(Class<?> clazz) {
if (clazz == null) {
throw new IllegalArgumentException("Class must not be null");
}
Field[] result = DECLARED_FIELDS_CACHE.get(clazz);
if (result == null) {
result = clazz.getDeclaredFields();
DECLARED_FIELDS_CACHE.put(clazz, (result.length == 0 ? NO_FIELDS : result));
}
return result;
}
/**
* 陣列合併
*
* @param array1
* @param array2
* @param <T>
* @return
*/
public static <T> T[] mergeArray(final T[] array1, final T... array2) {
if (array1 == null || array1.length < 1) {
return array2;
}
if (array2 == null || array2.length < 1) {
return array1;
}
Class<?> compType = array1.getClass().getComponentType();
int newArrLength = array1.length + array2.length;
T[] newArr = (T[]) Array.newInstance(compType, newArrLength);
int firstArrayLen = array1.length;
System.arraycopy(array1, 0, newArr, 0, firstArrayLen);
try {
System.arraycopy(array2, 0, newArr, firstArrayLen, array2.length);
} catch (ArrayStoreException ase) {
final Class<?> type2 = array2.getClass().getComponentType();
if (!compType.isAssignableFrom(type2)) {
throw new IllegalArgumentException("Cannot store " + type2.getName() + " in an array of "
+ compType.getName(), ase);
}
throw ase;
}
return newArr;
}
}
- 位元組碼增強技術,一般使用第三方庫來實現,例如Javassist或Byte Buddy,在執行時生成位元組碼,從而避免使用反射。
為什麼動態位元組碼生成方式相比反射也可以提高執行效率呢?
- 動態位元組碼生成的方式在編譯期就已經將型別資訊確定下來,無需進行型別檢查和轉換;
- 動態位元組碼生成的方式可以直接呼叫方法,無需查詢,提高了執行效率;
- 動態位元組碼生成的方式只需要在生成位元組碼時獲取一次Method物件,多次呼叫時可以直接使用,避免了重複獲取Method物件的開銷;
這裡就不再舉例說明了,感興趣的同學可以自行查閱資料進行深入學習。
例外處理
有效的處理異常可以保證程式的穩定性和可靠性。但異常的處理對效能還是有一定的影響的,這一點常常被人忽視。影響效能的具體表現為:
- 響應延遲:當異常被丟擲時,Java虛擬機器器需要查詢並執行相應的例外處理程式,這會導致一定的延遲。如果程式中存在大量的例外處理,這些延遲可能會累積,導致程式的整體效能下降。
- 記憶體佔用:例外處理需要在堆疊中建立異常物件,這些物件需要佔用記憶體。如果程式中存在大量的例外處理,這些異常物件可能會佔用大量的記憶體,導致程式的整體記憶體佔用量增加。
- CPU佔用:例外處理需要執行額外的程式碼,這會導致CPU佔用率增加。如果程式中存在大量的例外處理,這些額外的程式碼可能會導致CPU佔用率過高,導致程式的整體效能下降。
一些基準測試顯示,例外處理可能會導致程式的效能下降幾個百分點。在Java虛擬機器器規範中提到,在沒有異常發生的情況下,基於堆疊的方法呼叫可能比基於異常的方法呼叫快2-3倍。此外,一些實驗表明,在例外處理程式中使用大量的try-catch語句,可能會導致效能下降10倍以上。
為避免這些問題,在編寫程式碼時謹慎地使用例外處理機制,並確保對異常進行適當的記錄和報告,避免過度使用例外處理機制。
紀錄檔處理
先看以下程式碼:
LOGGER.info("result:" + JsonUtil.write2JsonStr(contextAdContains) + ", logid = " + DigitThreadLocal.getLogId());
以上範例程式碼中,類似的紀錄檔列印方式很常見,難道有什麼問題嗎?
- 效能問題:每次使用+進行字串拼接時,都會建立一個新的字串物件,這可能會導致記憶體分配和垃圾回收的開銷增加;
- 可讀性問題:使用+進行字串拼接時,程式碼可能會變得難以閱讀和理解,特別是在需要連線多個字串時;
- 如果紀錄檔級別調整到ERROR模式,我們希望紀錄檔的字串內容不需要進行加工計算,但這種寫法,即使紀錄檔處於不需要列印的模式,紀錄檔內容也進行了無效計算;
特別實在請求量和紀錄檔列印量比較高的場景下,紀錄檔內容的序列化和寫檔案操作,對服務的耗時影響可以達到10%,甚至更多。
臨時物件
臨時物件通常是指在方法內部建立的物件。大量建立臨時物件會導致Java虛擬機器器頻繁進行垃圾回收,從而影響程式的效能。也會佔用大量的記憶體空間,從而導致程式崩潰或者出現記憶體漏失等問題。
為了避免大量建立臨時物件,在編碼時,可以採取以下措施:
- 字串拼接中,使用StringBuilder或StringBuffer進行字串拼接,避免使用連線符,每次都建立新的字串物件;
- 在集合操作中,儘量使用批次操作,如addAll、removeAll等,避免頻繁的add、remove操作,觸發陣列的擴容或者縮容;
- 在正規表示式中,可以使用Pattern.compile()方法預編譯正規表示式,避免每次都建立新的Matcher物件;
- 儘量使用基本資料型別,避免使用包裝類,因為包裝類的建立和銷燬都會產生臨時物件;
- 儘量使用物件池的方式建立和管理物件,比如使用靜態工廠方法建立物件,避免使用new關鍵字建立物件,因為靜態工廠方法可以重用物件,避免建立新的臨時物件;
臨時物件的生命週期應該儘可能短,以便及時釋放記憶體資源。臨時物件的生命週期過長通常是由以下原因引起的:
- 物件未被正確地釋放:如果在方法執行完畢後,臨時物件沒有被正確地釋放,就會導致記憶體漏失風險;
- 物件過度共用:如果臨時物件被過度共用,就可能會導致多個執行緒同時存取同一個物件,從而導致執行緒安全問題和效能問題;
- 物件建立過於頻繁:如果在方法內部頻繁地建立臨時物件,就會導致記憶體開銷過大,可能會引起效能甚至記憶體溢位問題;
為避免臨時物件的生命週期過長,建議採取以下措施:
- 及時釋放物件:在方法執行完畢後,應該及時釋放臨時物件(比如主動將物件設定為null),以便回收記憶體資源;
- 避免過度共用:在多執行緒環境下,應該避免過度共用臨時物件,可以使用區域性變數或ThreadLocal等方式來避免共用問題;
- 物件池技術:使用物件池技術可以避免頻繁建立臨時物件,從而降低記憶體開銷。物件池可以預先建立一定數量的物件,並在需要時從池中獲取物件,使用完畢後再將物件放回池中;
小結
正所謂:「不積跬步,無以至千里;不積小流,無以成江海」。以上列舉的編碼細節,都會直接或間接的影響服務的執行效率,只是影響多少的問題。現實中,有時候我們不必過於苛求,但它們有一個共同的註腳:極客精神。
三 設計優化
3.1 快取
合理使用快取可以有效提高應用程式的效能,縮短資料存取時間,降低對資料來源的依賴性。快取可以進行多層級的設計,舉例,為了提高執行效率,CPU就設計了L1-L3三級快取。在應用設計的時候,我們也可以按照業務訴求進行層設計。常見的分層設計有本地快取(L1),遠端分散式快取(L2)兩級。
本地快取可以減少網路請求、節約計算資源、減少高負載資料來源存取等優勢,進而提高應用程式的響應速度和吞吐量。常見的本地快取中介軟體有:Caffeine、Guava Cache、Ehcache。當然你也可以在使用類似Map容器,在應用程式中構建自己的快取結構。 分散式快取相比本地快取的優勢是可以保證資料一致性、只保留一份資料,減少資料冗餘、可以實現資料分片,實現大容量資料的儲存。常見的分散式快取有:Redis、Memcached。
實現一個簡單的LRU本地快取範例如下:
/**
* Least recently used 記憶體快取過期策略:最近最少使用
* Title: 帶容量的<b>執行緒不安全的</b>最近存取排序的Hashmap
* Description: 最後存取的元素在最後面。<br>
* 如果要執行緒安全,請使用<pre>Collections.synchronizedMap(new LRUHashMap(123));</pre> <br>
*
* @author: liuhuiqing
* @date: 20123/4/27
*/
public class LRUHashMap<K, V> extends LinkedHashMap<K, V> {
/**
* The Size.
*/
private final int maxSize;
/**
* 初始化一個最大值, 按存取順序排序
*
* @param maxSize the max size
*/
public LRUHashMap(int maxSize) {
//0.75是預設值,true表示按存取順序排序
super(maxSize, 0.75f, true);
this.maxSize = maxSize;
}
/**
* 初始化一個最大值, 按指定順序排序
*
* @param maxSize 最大值
* @param accessOrder true表示按存取順序排序,false為插入順序
*/
public LRUHashMap(int maxSize, boolean accessOrder) {
//0.75是預設值,true表示按存取順序排序,false為插入順序
super(maxSize, 0.75f, accessOrder);
this.maxSize = maxSize;
}
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return super.size() > maxSize;
}
}
3.2 非同步
非同步可以提高程式的效能和響應能力,使其能更高效地處理大規模資料或並行請求。其底層原理涉及到作業系統的多執行緒、事件迴圈、任務佇列以及回撥函數等關鍵技術,除此之外,非同步的思想在應用架構設計方面也有廣泛的應用。常規的多執行緒,訊息佇列,響應式程式設計等非同步處理方案這裡就不再展開介紹了,這裡介紹兩個大家可能容易忽視但實用技能:非阻塞IO和 協程。
非阻塞IO
Java Servlet 3.0規範中引入了非同步Servlet的概念,可以幫助開發者提高應用程式的效能和並行處理能力,其原理是非阻塞IO使用單執行緒同時處理多個請求,避免了執行緒切換和阻塞的開銷,特別是在讀取大檔案或者進行復雜耗時計算場景時,可以避免阻塞其他請求的處理。Spring MVC框架中也提供了相應的非同步處理方案。
•使用Callable方式實現非同步處理
@GetMapping("/async/callable")
public WebAsyncTask<String> asyncCallable() {
Callable<String> callable = () -> {
// 執行非同步操作
return "非同步任務已完成";
};
return new WebAsyncTask<>(10000, callable);
}
•使用DeferredResult方式實現非同步處理
@GetMapping("/async/deferredresult")
public DeferredResult<String> asyncDeferredResult() {
DeferredResult<String> deferredResult = new DeferredResult<>(10000L);
// 非同步處理完成後設定結果
deferredResult.setResult("DeferredResult非同步任務已完成");
return deferredResult;
}
協程
我們知道執行緒的建立、銷燬都十分消耗系統資源,所以有了執行緒池,但這還不夠,因為執行緒的數量是有限的(千級別),執行緒會阻塞作業系統執行緒,無法儘可能的提高吞吐量。因為使用執行緒的成本很高,所以才會有了虛擬執行緒,它是使用者態執行緒,成本是相當低廉的,排程也完全由使用者進行控制(JDK 中的排程器),它同樣可以進行阻塞,但不用阻塞作業系統執行緒,充分提高了硬體利用率,高並行也上了一個量級。
很長一段時間,協程概念並非作為JVM內建的功能,而是通過第三方庫或框架實現的。目前比較常用的協程實現庫有Quasar、Kilim等。但在Java19版本中,引入了虛擬執行緒(Virtual Threads )的支援(處於Preview階段)。
虛擬執行緒是java.lang.Thread的一個實現,可以使用java.lang.Thread.Builder介面建立
Thread thread = Thread.ofVirtual()
.name("Virtual Threads")
.unstarted(runnable);
也可以通過一個執行緒工廠類進行建立:
ThreadFactory factory = Thread.ofVirtual().factory();
虛擬執行緒執行的載體必須是執行緒,同一個執行緒中可以執行多個虛擬執行緒範例。
3.3 並行
並行處理的思想在巨量資料,多工,流水線處理,模型訓練等各個方面發揮著重要作用,包括前面介紹的非同步(多執行緒,協程,訊息等),也是建立在並行的基礎上。在應用層面,典型的場景有:
- 分散式計算框架中的MapReduce就是採用一種分而治之的思想設計出來的,將複雜或計算量大的任務,切分成一個個小的任務,小任務分別在不同的執行緒或伺服器上並行的執行,最終再彙總每個小任務的結果。
- 邊緣計算(Edge Computing)是一種分散式計算正規化,它將計算、儲存和網路服務的部分功能從雲資料中心延伸至離資料來源更近的地方,即網路的邊緣。這種計算方式能夠實現低延遲、節省頻寬、提高資料安全性以及實時處理與分析等優勢。
在程式碼實現方面,做好解耦設計,接下來就可以進行並行設計了,比如:
- 多個請求可以通過多執行緒並行處理,每個請求的不同處理階段;
- 如查詢階段,可以採用協程並行執行;
- 儲存階段,可以採用訊息訂閱釋出的方式進行處理;
- 監控統計階段,就可以採用NIO非同步的方式進行指標資料檔案的寫入;
- 請求/響應採用非阻塞IO模式;
3.4 池化
池化就是初始預設資源,降低每次獲取資源的消耗,如建立執行緒的開銷,獲取遠端連線的開銷等。典型的場景就是執行緒池,資料庫連線池,業務處理結果快取池等。
以資料庫連線池為例,其本質是一個 socket 的連線。為每個請求開啟和維護資料庫連線,尤其是動態資料庫驅動的應用程式的請求,既昂貴又浪費資源。為什麼這麼說呢?以MySQL資料庫建立連線(TCP協定)為例,建立連線總共分三步:
- 建立TCP連線,通過三次握手實現;
- 伺服器傳送給使用者端「握手資訊」 ,使用者端響應該握手訊息;
- 使用者端「傳送認證包」 ,用於使用者驗證,驗證成功後,伺服器返回OK響應,之後開始執行命令;
簡單粗略統計,完成一次資料庫連線,使用者端和伺服器之間需要至少往返7次,總計平均耗時大約在200ms左右,這對於很對C端服務來說,幾乎是不能接受的。
落實到程式碼編寫層面,也可以藉助這一思想來優化我們的程式執行效能。
- 公用的資料可以全域性只定義一份,比如使用列舉,static修飾的容器物件等;
- 根據實際情況,提前設定List,Map等容器物件的初始化容量大小,防止後面的擴容,對效能的影響;
- 亨元設計模式的應用等;
3.5 預處理
一般需要池化的內容,都是需要預處理的,比如為了保證服務的穩定性,執行緒池和資料庫連線池等需要池化的內容在JVM容器啟動時,處理真正請求之前,對這些池化內容進行預處理,等到真正的業務處理請求過來時,可以正常的快速處理。除此之外,預處理還可以體現在系統架構層面。
- 為了提高響應效能,將部分業務資料提前預載入到記憶體中;
- 為了減輕CPU壓力,將計算邏輯提前執行,直接將計算後的結果資料儲存下來,直接供呼叫方使用;
- 為了降低網路頻寬成本,將傳輸資料通過壓縮演演算法進行壓縮處理,到了目標服務,在進行解壓,獲得原始資料;
- Myibatis為了提高SQL語句的安全性和執行效率,也引入了預處理的概念;
四 總結
效能優化是程式開發過程中繞不過去一個課題,本文聚焦程式碼和設計兩個方面,從CPU硬體到JVM容器,從快取設計到資料預處理,全面的展現了效能優化的實施方向和落地細節。闡述的過程沒有追求各個方向的面面俱到,但都給到了一些場景化案例,來輔助理解和思考,起到拋磚引玉的效果。
作者:京東零售 劉慧卿
內容來源:京東雲開發者社群