全網最詳細解讀《GIN-HOW POWERFUL ARE GRAPH NEURAL NETWORKS》!!!
Abstract + Introduction
GNNs 大都遵循一個遞迴鄰居聚合的方法,經過 k 次迭代聚合,一個節點所表徵的特徵向量能夠捕捉到距離其 k-hop 鄰域的鄰居節點的特徵,然後還可以通過 pooling 獲取到整個圖的表徵(比如將所有節點的表徵向量相加後用於表示一個圖表徵向量)。
關於鄰居聚合策略以及池化策略都有很多相關的研究,並且這些 GNNs 已經達到了目前最先進的效能,然而對於 GNNs 的各種性質以及效能上限我們並沒有一個理論性的認識,也沒有對 GNN 表徵能力的形式化分析。言下之意:這些 GNNs 模型的研究雖然效果很好,但並沒有系統理論的支撐,並不知道是基於什麼導致了更好的效能,而是基於經驗主義的。
本文提出了一個理論框架以分析 GNNs 表徵的能力,正式描述了不同 GNNs 變體在學習表徵以及區分不同圖結構時的效能。該理論框架由 GNN 與 WL-test 之間的密切聯絡所啟發。與 GNN 類似,WL-test 也會遞迴地聚合節點的鄰居特徵。也是因為 WL-test 聚合更新的性質使其效能強大。既然二者在操作上都非常相似,那麼從理論上看 GNN 也能夠具備跟 WL-test 一樣強大的判別能力。
為了在數學上形式化上述見解,理論框架首先會將給定節點的鄰居節點特徵向量表示為一個 multiset,即一個可能包含重複元素的集合。GNNs 的鄰居聚合就能夠被看作是對 multiset 進行處理的聚合函數。
作者研究了 multiset 聚合函數的多種變體,並從理論上分析了聚合函數對於區分不同 multiset 的判別能力。為了具備強大的表徵能力,GNN 必須將不同的 multiset 聚合成不同的表示。只要聚合函數能夠達到跟 hash 雜湊一樣的單射性,那麼理論上是能夠達到跟 WL-test 一樣的判別能力的。因此,聚合函數的單射性越強,GNN 的表徵能力就越強。
該篇論文的研究成果總結如下:
- 展示了 GNNs 在區分圖結構時,理論上能夠達到與 WL-test 相似的效能。
- 在上述條件下,建立了鄰居聚合以及 Graph readout 的 condition。
- 識別了當下流行的 GNN 變體(GCN,GraphSAGE)無法區分的圖結構,並精確表徵了其能夠成功捕捉的圖結構型別。
- 開發了一個簡單的神經網路架構 GIN,並且證明了它在表徵能力上與 WL-test 效能相當。
作者通過圖資料集的分類任務驗證了理論,其中 GNN 的表徵能力對於捕獲圖結構的資訊至關重要。研究比較了基於不同聚合函數 GNNs,結果證明效能最強大的 GIN 模型從經驗的角度來看也具備高表徵能力,幾乎能夠完美擬合訓練資料,而一些較弱的 GNN 變體則通常欠擬合訓練資料。此外,表徵能力更強的 GNNs 在測試集精度上比其他模型效能更優,主要表現在圖分類任務上達到了目前最優的效能。
PRELIMINARIES
我們用 \(G=(V, E)\) 表示一個圖,節點特徵向量表示為 \(X_v\)。我們主要考慮兩個任務:
- 節點分類任務:每個節點 \(v ∈ V\) 都有一個關聯的標籤 \(y_v\) 並且我們的目標是去學習每個節點 \(v\) 的表徵向量 \(h_v\),每個節點 \(v\) 的標籤預測過程能夠被表示為 \(y_v = f(h_v)\)
- 圖分類任務:給定圖集合 \(\{G_1, G_2, ..., G_n\} ∈ G\) 並且其標籤集合為 \(\{y_1, y_2, ..., y_n\} ∈ Y\),目標是學習每個圖的表徵向量 \(h_G\) 以預測圖的標籤,整個過程可以被表示為 \(y_G = g(h_G)\)
Graph Neural Networks. GNNs 利用圖的結構和節點特徵 \(X_v\) 去學習一個節點表徵向量 \(h_v\)(或是整個圖的表徵向量 \(h_G\))。當前 GNNs 都採用了鄰居聚合策略,通過聚合策略迭代更新每個節點的表徵向量。經過 k 次聚合迭代後,一個節點的表徵能夠捕捉 k-hop 鄰居節點的特徵資訊。形式上,第 k 層 GNN 可表示為:

其中 \(h_v(k)\) 表示節點 \(v\) 在第 k 次迭代的特徵向量。我們初始化 \(h(0)=X_v\),並且 \(N(v)\) 是節點 V 的鄰居節點集合。
公式表達的意思即:先聚合節點 \(v\) 的鄰居節點表徵,得到 \(a_v(k)\),然後結合 \(a_v(k)\) 與節點自身的表徵 \(h_v(k-1)\) 生成節點 \(v\) 新的表徵 \(h_v(k)\)。
對於 Aggregate 以及 combine 的選擇對於 GNN 的效能有著至關重要的影響,並且也有很多相關的研究,比如 GraphSAGE 的 Aggregate 則表示為如下:
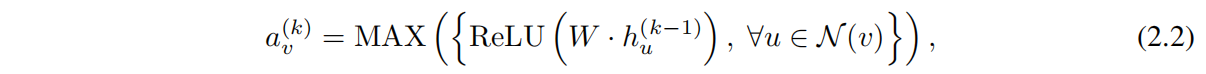
其中 \(W\) 是可學習的引數矩陣,\(Max\) 表示為 element-wise max-pooling。Combine 則表示為一個線性對映 \(W·[h_v(k-1), a_v(k)]\)。
即:GraphSAGE 會將所有的鄰居節點進行一個線性投影,然後通過 ReLU 啟用,再取出其中的最大值作為鄰居聚合後的表徵向量。這個鄰居節點 multiset 的表徵向量會跟節點自身的表徵向量拼在一起作線性投影。
而在 GCN 中 則是採用了 element-wise mean-poolinig,並且 Aggregate 和 Combine 過程結合到了一起:
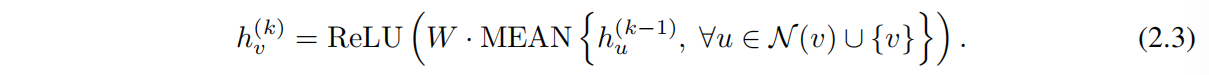
即:GCN 會先對鄰居節點以及節點自身取平均,然後對結果線性投影,然後通過 ReLU 啟用,結果作為最終的節點表徵向量。
而許多其他的 GNNs 聚合/Combine 過程都能夠被公式 2.1 表示。
對於節點分類任務,最後一次迭代的節點的表徵 \(h_v(K)\) 則會被用於預測。對於圖分類任務,\(READOUT\) 函數則會聚合最後一次迭代的節點特徵得到一個圖表徵向量 \(h_G\):

READOUT 可以是簡單的排列不變函數,比如對所有圖節點特徵求和,也可以是更加複雜的圖級別池化函數。
Weisfeiler-Lehman test. 圖同構問題是指 判別兩個圖是否具備拓撲相同性。而 WL-test 則是針對圖同構問題的一個高效的演演算法,它的判別操作過程類似於 GNN 中的鄰居聚合,wL-test 迭代地聚合節點與鄰居節點的標籤,將聚合的標籤進行一次 hash 雜湊為一個新的唯一標籤。如果在某次迭代中,兩個圖之間的節點標籤不同,則可以判定兩個圖是非同構的。
下圖是圖同構問題的一個簡單判別流程,從上至下的 3 個圖中,2 和 3 為同構圖,1 則是與二者為異構圖。相同的顏色表示相同的節點特徵,鄰居聚合雜湊後會生成一個新的特徵。若經過若干次迭代後,若對應節點的顏色不同,則能夠斷言二者互為異構圖。
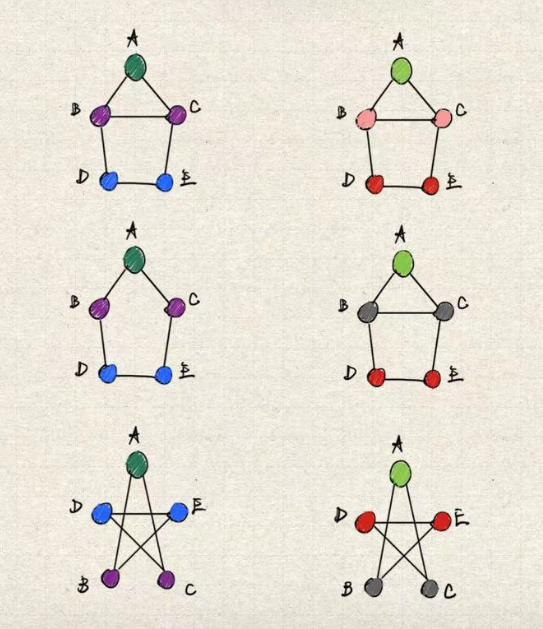
WL-test 只能夠判別兩個圖不是同構圖,但並不能判定兩個圖一定是同構圖。
而 Shervashidze et al. 又基於 WL-test 提出了 WL subtree kernel 演演算法,該演演算法能夠評估兩個圖的相似性。
作者並沒有詳細解釋 WL subtree kernel 的具體計算過程,這裡我們也不必過於糾結具體的演演算法,只需要知道 WL WL subtree kernel 能夠高效地判定兩個圖結構的相似性。
如果我們能夠在圖分類任務中,精確而高效地判定出兩個圖的相似性,那麼在預測任務中,就更容易確定兩個圖是否屬於一個類別。而 GNN 的聚合操作與 WL-test 高度相似,因此我們可以合理懷疑:GNN 能夠在圖相似性評估的過程(圖表徵學習)中達到 WL-test 的效能水平。只要聚合函數能起到跟 hash 函數一樣的單射性,那麼理論上二者是能夠達到同級別的效能水平的。
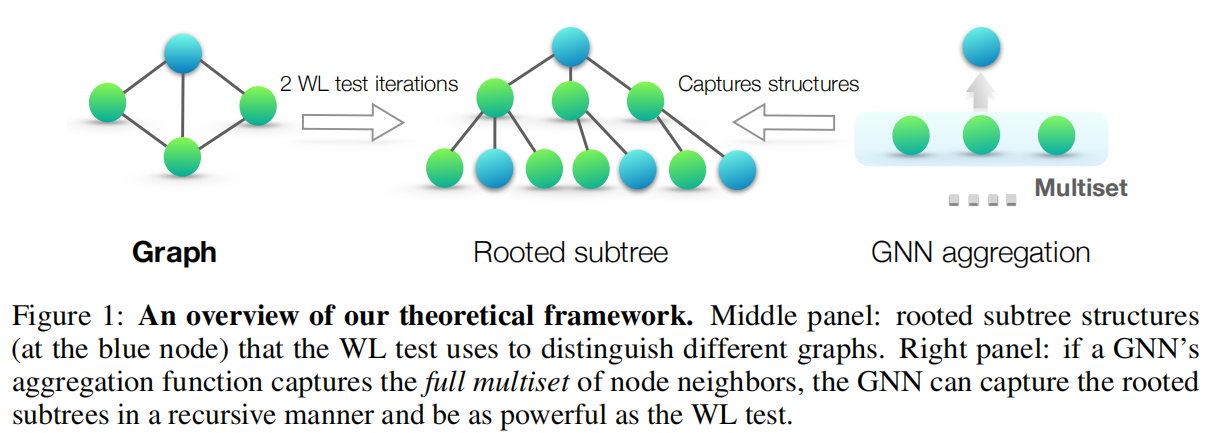
Figure 1. 簡單表述了經過 2 次 WL-test 迭代後,每個節點聚合的鄰居資訊。這個過程是跟 GNN agreegation 高度相似的。
3 THEORETICAL FRAMEWORK: OVERVIEW
整個論文中,作者假設節點的特徵向量是離散的(畢竟特徵向量值連續的情況下,99.9999% 都不會聚合出一個相同的嵌入,作者也就沒牛逼可吹了)。作者將這樣的圖稱為有限圖。對於有限圖,更深折積層的特徵向量也同樣是離散的。

作者這裡給出了 Multiset 的定義,但我們不用太關注這個概念,直接將其理解為節點的鄰居即可。
為了研究 GNN 的表徵能力,作者分析了 GNN 什麼情況下會將兩個節點對映到嵌入空間中的相同位置。直觀地說,一個最強大的 GNN 只有在兩個節點具備相同的鄰居子樹結構時才會將它們對映到同一個嵌入空間的位置。我們也可以將問題簡化為:GNN是否對映兩個相同的鄰域特徵(multiset)對映到相同的嵌入表示。畢竟最強大的 GNN 永遠不會將兩個不同的鄰域特徵對映到同一個嵌入,即聚合函數必須是單射 injective 的。因此,我們將 GNN 的聚合函數抽象為一種可以由 neural network 表示的 multiset function,並分析該函數是否能夠表示為 injective multiset function。
只要 multiset function 能表示為單射函數,這就意味著在 GNN 的聚合鄰居操作中,對於不同鄰域的特徵,聚合後能夠獲取到一個唯一的輸出表徵,這樣就能夠捕捉到更多的圖結構資訊以及鄰居節點的特徵資訊。GNN 就能夠獲得非常強大的表徵能力。
injective function,即單射函數,表示輸入跟輸出是一對一的關係,即對於不同的輸入x,f(x) 永遠不可能存在相同的輸出。
接下來,我們將利用這個推論(injective multiset function)來開發一個最強大的 GNN。在 Section.5 我們研究了當下流行的 GNN variants 並且發現它們的聚合方式都本質上不滿足 injective 的特性,因此其模型的表徵能力都不太強,但這些模型也可以捕獲到 Graph 的其他的有趣的屬性。
4 BUILDING POWERFUL GRAPH NEURAL NETWORKS
首先我們給出了 GNN 模型的最大表徵能力,即具備單射性的聚合策略。理想情況下,最強大的 GNN 可以通過將不同的圖結構對映到不同的嵌入空間來區分它們。然而,這種將任意兩個不同的 Graph 對映到不同的嵌入空間的能力意味著要解決一個困難的圖同構問題。即:我們希望同構圖對映到相同的嵌入空間,非同構圖對映到不同的嵌入空間。但在我們的分析中,我們利用一個稍微弱一些的標準來定義 GNN 的表徵能力 —— WL-test,它通常能夠很好地區分非同構圖,並且效能也較高,除了少數例外情況(比如正則圖)。

引理2:只要圖神經網路能夠將任意兩個異構圖劃分到兩個不同的嵌入,那麼 WL-test 也一定可以將這兩個圖判定為異構圖。簡單來說,圖神經網路能做的,WL-test 一定能做;但圖神經網路不能做的,WL-test 也能做。
因此,任何基於聚合的 GNN 在區分不同的圖方面最多也就跟 WL-test 一樣強大。那麼是否存在與 WL-test 一樣強大的 GNN 呢?
Theorem 3. 給出了肯定的答案:若鄰居聚合函數與 Readout function 都是 injective function,那麼這樣的 GNN 與 WL-test 一樣強大。

定理3:若對於任意兩個非同構圖 \(G_1\) and \(G_2\)(由 WL-test 判定),那麼只要 GNN 具備足夠多層且滿足下面兩個條件,就能夠將兩圖對映到不同的嵌入:
-
GNN 通過式子 \(h_v(k)=φ(h_v(k-1), f(\{h_u(k-1):u∈N(v)\}))\) 聚合並且遞迴更新節點特徵
其中,函數 \(f(x)\) 的入參為 multisets,\(φ(x)\) 表示一個 combination 操作,且滿足 injective。
-
GNN 的 graph-level readout 入參也是 multisets(即節點特徵 \(\{h_v(k)\}\)),並且 readout 滿足 injective。
作者已經在附錄中給出了定理3的證明。對於有限圖,單射效能夠很好地描述一個函數是否能夠維持輸入資訊的獨特性。但對於無限圖,由於其中的節點特徵是連續的,則需要進一步考慮。
此外,描述學習到的特徵在函數影象中的親密度也是一件非常有趣的事情。我們將把這些問題留到未來的工作,並且將重心放到輸入節點特徵來自可數集合的情況。

引理4:主要是告訴我們,只要特徵空間是離散的,那麼在聚合後依然能夠得到一個離散的特徵空間。本篇論文也是在特徵離散的前提下討論的。
除了區分不同的圖以外,GNN 還有一個重要的優點,即能夠捕獲圖結構的相似性。而 WL-test 是無法捕獲圖之間的相似性的,這也是為什麼我們不直接採用 WL-test 到圖資料任務處理中。
原因在於:WL-test 中節點的特徵向量本質上是 one-hot encodings,即描述節點屬於哪個類別的 one-hot 編碼,且經過鄰居聚合 hash 後得到的也只是 「代表新的節點類別的 one-hot」,無法得到一個具備節點特徵與圖結構資訊的空間嵌入,因此不能捕獲子樹之間的相似性。
相比之下,滿足 Theorem 3 的 GNN 通過學習將鄰居節點特徵聚合對映到一個向量空間,相隔較遠距離的嵌入大概率不屬於一個類別,而相隔較近的嵌入則同屬一個類別。這使得 GNN 不僅可以區分不同的圖結構,還可以將近似的圖結構對映到相似的嵌入,並捕獲圖結構之間的依賴關係。捕獲節點的結構相似性被證明是有助於泛化的,特別是當鄰居的特徵向量的是稀疏的,或者存在噪聲邊緣特徵時。
4.1 GRAPH ISOMORPHISM NETWORK (GIN)
在確立了最強大的 GNN 的開發條件後(滿足單射的聚合函數),我們接下來開發一個簡單的架構,圖同構網路 GIN,它能夠被證明滿足 Theorem 3. 中的條件。這個模型推廣了 WL-test 從而實現了 GNNs 系模型的最強判別能力。
為了建模一個單射鄰居聚合函數,作者提出了一種 「deep multisets」 理論,即:用神經網路引數化 「通用的單射鄰居聚合函數」。下一個 Lemma 說明了 sum-aggregators 能夠在鄰居聚合函數上具備單射的性質。
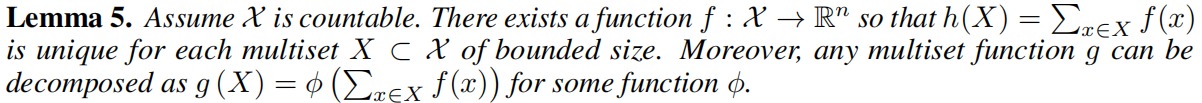
引理5:假設向量空間 \(\mathcal{X}\) 是離散的,那麼一定存在函數 \(f\) 將節點特徵進行投影到一個 n 維嵌入的函數,使得 \(h(X) = \sum_{x ∈ X} f(x)\) 的值對於每一個位於向量空間 \(\mathcal{X}\) 的 multiset \(X\) 都能取到一個唯一的值。此外,任何一個 multiset function \(g\) 都能被拆解為 \(g(X) = φ(\sum_{x ∈ X} f(x))\),其中 \(φ\) 是某個函數。
引理5,主要就是證明了 sum-aggregation 的單射性,我們明白這一點即可。
作者在論文附錄中證明了 Lemma 5. 這裡我們先不去管證明了。
Deep MultiSets 和 sets 最重要的一個區別是:是否滿足單射的性質。比如 mean-aggregator 就不滿足單射性質。(後面會解釋 mean-aggregation 為什麼不滿足單射性)
「Deep MultiSets 和 sets 最重要的一個區別是:是否滿足單射的性質。」 這句話我並不是看的很懂,個人的理解是:聚合函數的引數的豐富程度能夠決定能否滿足單射的性質,比如平均聚合的多集特徵中,真正處理的只是整個特徵集合中的一部分特徵。
以 Lemma 5. 中的 「通用的單射鄰居聚合函數」 建模機制作為構建模組,我們可以構想出一個聚合方案,該方案能夠表示一個 「入參為節點以及其鄰居 multiset」 的泛函數,因此滿足 Theorem 3. 中的 injective condition。下一個推論給出了一個簡單而具體的公式。
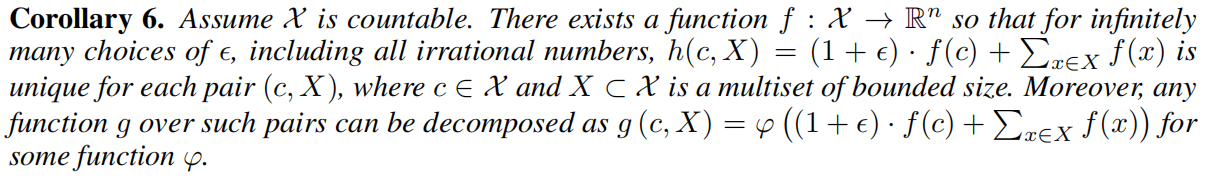
推論6:對於引數 \(\epsilon\),由無限種可能使得 \(h(c, X) = (1 + \epsilon) * f(c) + \sum_{x ∈ X} f(x)\) 對於每一個元組 (c, X) 都能夠拿得唯一的值。
其實跟引理5 差不太多,只需要把 c 理解為節點自身,X 理解為節點鄰居多集即可。
鑑於普遍近似理論 universal approximation theorem (Hornik et al., 1989; Hornik, 1991),我們可以利用 MLPs 建模並學習 Corollary 6. 中的 \(f\) and \(ϕ\) 函數。實際操作上,我們用單層感知機對 \(f^{(k+1)}◦ϕ^{(k)}\) 進行建模,因為 MLPs 能夠表示函數的組合。
在第一次迭代聚合時,若輸入的特徵是 one-hot encodings,那麼我們在進行 sum 聚合之前並不需要 MLPs,因為這些特徵的求和操作已經滿足單射性質。我們可以讓 \(\epsilon\) 作為一個可學習引數或是固定引數。那麼此時 GIN 的聚合操作可以由如下公式表示:

一般來說,可能存在許多其他強大的 GNNs。但 GIN 是最強大的 GNNs 之一,同時也很簡單。
4.2 GRAPH-LEVEL READOUT OF GIN
通過 GIN 學習的節點嵌入可以直接用於節點分類問題以及鏈路預測問題,但對於圖分類問題,我們提出了以下方法:通過節點的嵌入構造整個圖的嵌入。一般我們會把這個過程稱為 Graph Readout。
Graph Readout 的一個重要因素是:隨著迭代(聚合)次數增加,對應於子樹結構的節點表徵會變得更加精細以及覆蓋範圍更廣。因此足夠的迭代次數是獲得良好判別能力的關鍵。然而,有時較少迭代的特徵也可能會帶來更好的泛化能力,所以並不是一味的增加聚合次數就能夠讓效能變得更好。
因此,作者利用到了每一次迭代聚合的節點表徵資訊,通過類似 Jumping Knowledge Networks (Xu et al., 2018) 的架構來實現,並用下列 Readout concat 方案替換 Eq 2.4:
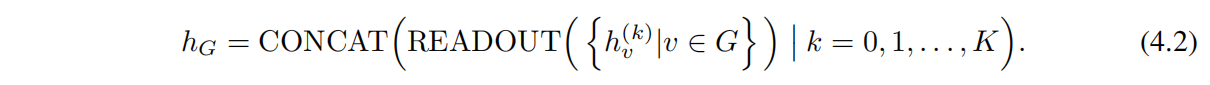
即,把每一次迭代聚合得到的表徵進行一個 concat。
基於 Theorem 3. 和 Corollary 6. GNN 能夠很好地推廣 WL-test 和 WL subtree kernel(在求和之前,我們不需要額外的 MLP,原因跟 Eq 4.1 的相同,此時的 sum 已經滿足了單射性質)
5 LESS POWERFUL BUT STILL INTERESTING GNNS
接下來,我們研究一下不滿足 Theorem 3 (單射)條件的 GNNs,包括 GCN,GraphSAGE。再從兩個方面開展關於聚合函數 Eq4.1 的消融實驗
- 用 1-layer 的感知機而不採用 MLPs(單純鄰域節點線性求和作為聚合策略是否可行)
- 均值池化或最大池化,而不採用 sum(不採用求和而是採用 mean or max 的聚合策略是否可行)
我們將會驚訝地發現,這些 GNN 變體會無法識別一些簡單的圖,並且效能也不如 wL-test 強大。但儘管如此,採用 mean aggregators 的模型(如 GCN)在節點分類任務中還是會得到不錯的結果。為了更便於理解,我們將精確地描述不同 GNN 變體能或不能捕捉到的圖,並且討論有關 「圖學習」 的含義。
5.1 1-LAYER PERCEPTRONS ARE NOT SUFFICIENT
Lemma 5 中的函數 \(f\) 能夠將截然不同的 multisets 對映到一個唯一的 Embeddings 上。基於普遍近似理論,函數 \(f\) 能夠被 MLP 引數化。儘管如此,許多現有的 GNNs 都採用的是單層的感知機,然後通過 Relu 進行非線性啟用。這樣的單層對映屬於廣義線性模型的例子。因此我們感興趣的是:單層感知機是否能夠用於圖學習。但 Lemma 7 表明,確實存在單層感知機永遠無法區分的 multisets。
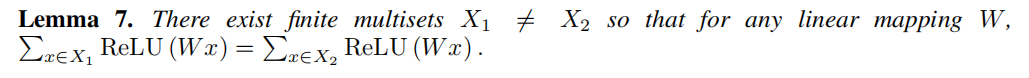
引理7:確實存在不同的多集 \(X_1 ≠ X_2\),但對於任何對映 \(W\) 二者對映後的嵌入都是相等的。單層感知機可以是某種線性對映,此時 GNN 層會退化為簡單的鄰域特徵求和。但引理7是建立線上性對映中缺乏偏置項 bias 的基礎上的。
雖然有了偏置項和足夠大的輸出維度,單層感知機大概率能夠區分不同的 multisets,但儘管如此,與採用多層感知機的模型不同,單層感知機即便是帶有偏置項,也不屬於 multisets function 的通用逼近函數。因此,即便 1-layer GNN 能夠將不同的圖嵌入到不同的表徵,但這種嵌入可能無法充分捕獲兩個圖的相似性,並且對於簡單分類器(比如線性分類器)來說很難擬合。在 Section 7 中我們將會看到,1-layer GNN 在應用圖分類任務時,會導致嚴重的欠擬合,並且在 test Accuracy 方面也通常比 MLPs GNN 表現差。
5.2 STRUCTURES THAT CONFUSE MEAN AND MAX-POOLING
如果我們在聚合操作中,將 \(h(X) = \sum_{x∈X}f(x)\) 替換為 GCN 中的 mean pooling 或者 GraphSAGE 中的 max pooling 可能會發生什麼?
平均池化聚合以及最大池化聚合都仍然屬於 well-defined 的多集函數,因為它們都是排列不變的。但它們都不滿足單射性。圖2根據聚合器的表徵能力對三種聚合器進行了排名,並且圖3闡述了 max-pooling 和 mean-pooling 無法區分的結構。節點顏色表明了不同的節點特徵,並且我們假設 GNNs 會在 combine 操作之前先執行 Aggregation。
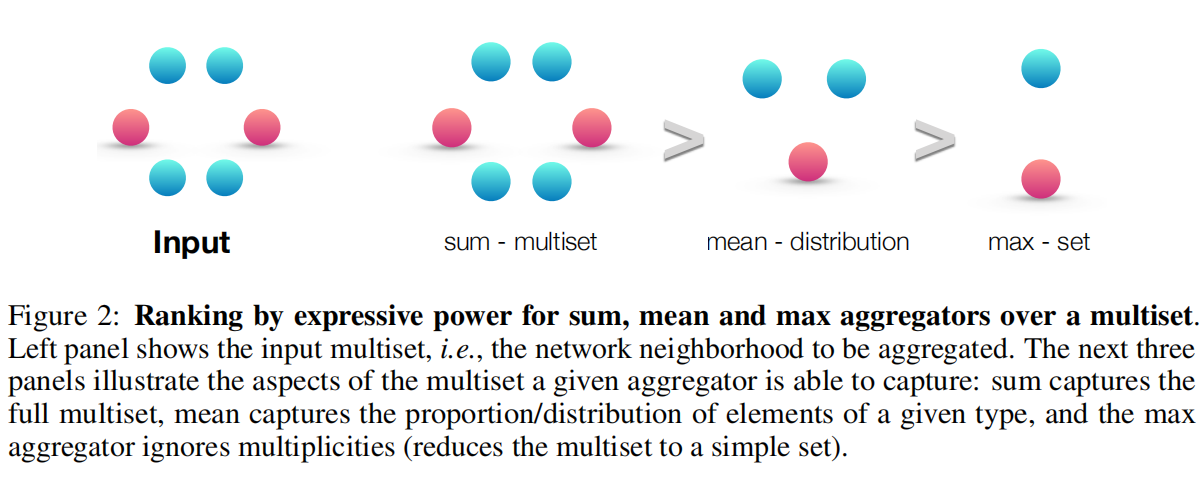
對於 sum 聚合來說,能夠捕捉 multiset 中所有特徵的資訊,而 mean 聚合能捕捉部分比例特徵的資訊,而 max 聚合則忽略了特徵資訊的多樣性。
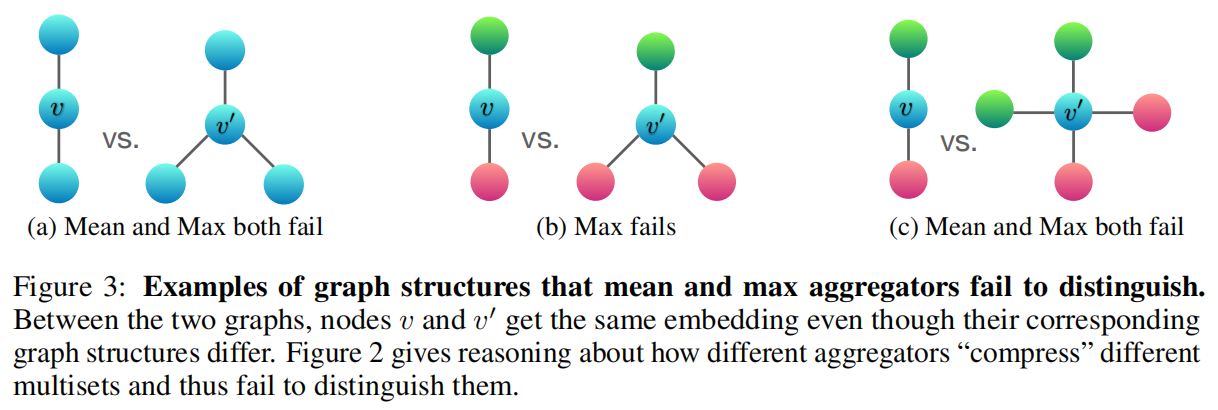
在 Figure 3a 中,所有的節點都具備相同的特徵,因此對於 mean 和 max 聚合都會得到相同的結果,不具備單射性。即便兩個圖從結構上來看並不相同,但 mean and max 聚合卻能夠取到相同的值,也就意味著在這種情況下,mean and max 聚合無法捕獲到任何圖結構的資訊。但對於 sum pooling aggregators 能夠給出不同的值,也就意味著 sum aggregator 能夠區分這兩種圖結構(但單純的線性求和可能無法獲取到圖結構資訊)。同樣的引數也可以應用於任何無標記的圖。如果使用節點度而不是常數值作為節點輸入特徵,原則上,mean 聚合可以起到類似 sum 聚合的作用,但最大池化不能。
Fig.3a 表明,平均和最大池化對於區分具備重複特徵的節點是困難的。我們定義 \(h_{color}\) 為節點特徵的對映結果(相同特徵會對映到相同的顏色)。Fig.3b 表明,對於兩個不同結構的圖,最大池化聚合 \(max(h_{g}, h_{r})\) and \(max (h_{g}, h_{r}, h_{r})\) 能夠取到相同的表徵。因此最大池化聚合並不能區分這兩張圖。但 sum aggregator 仍然能夠區分。同樣地,對於 Fig.3c,mean and max pooling 同樣會無法區分,因為 \(\frac{1}{2}(hg + hr) = \frac{1}{4}(hg + hg + hr + hr)\)
5.3 MEAN LEARNS DISTRIBUTIONS
為了描述 mean aggregator 能夠區分的 multisets 類別,我們考慮一個例子:\(X_1=(S, m)\) and \(X_2=(S, k·m)\),其中 \(X_1\) and \(X_2\) 擁有相同元素但個數不同(但成比例)的集合,任何平均聚合器都將 \(X_1\) 和 \(X_2\) 對映到相同的嵌入,因為它只是對 \(X_i\) 的特徵取平均值。
若在 graph 任務中,若 提取統計資訊以及資訊分佈 比 提取特定結構資訊 更加重要,那麼 mean aggregator 的效果還不錯。此外,若節點特徵多樣且重複性較少時,mean aggregator 跟 sum aggregator 的效果一樣好。或許這能夠被解釋為什麼平均存在一定的侷限性,但平均聚合 GNNs 對節點分類的任務依然很有效,比如文章主題分類,社群檢測這類任務,它們都屬於節點特徵豐富,且鄰域特徵分佈為分類任務提供了更明顯的資訊。
5.4 MAX-POOLING LEARNS SETS WITH DISTINCT ELEMENTS
Fig.3 的例子表明:最大池化會將多個具備相同特徵的節點視為單個節點(即,將 multiset 看作為單個 set)。最大池化捕捉特徵的並非確切的圖結構資訊,也不是圖節點的分佈資訊。最大池化適用於識別 「代表性骨架」,Qi et al. 的工作從經驗上表明,最大池化聚合學習適合識別 3D 點雲的 「骨架」,並且對噪聲和異常值具有更強的魯棒性。為了完整性起見,下一個推論表明,最大池化聚合器捕獲了 multiset 的底層集合。
可以將 3D 點雲理解為三維影象,一般會應用於建築安全隱患識別,城市管理等。
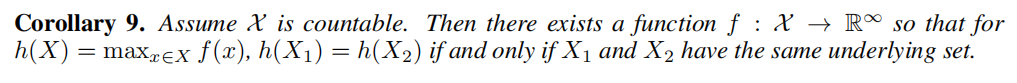
推論9:可以簡單理解為,max 聚合能夠捕捉到結構相似的底層結構資訊。其實跟最大池化的特性比較相似,具備更好的魯棒性以及抗噪性,但缺點是會丟失一些資訊。但即便如此,依然能夠捕獲到底層結構相同的類別。
5.5 REMARKS ON OTHER AGGREGATORS
還有一些其他的非標準鄰居聚合方式,但本篇論文並未提及,比如:weighted average via attention (Velickovic et al., 2018),LSTM pooling (Hamilton et al., 2017a; Murphy et al., 2018). 本文強調的是:該理論框架足夠普適去描述基於聚合方式的 GNNs 的表徵效能。未來會考慮應用框架去分析和理解其他的聚合方式。
6 OTHER RELATED WORK
儘管 GNNs 取得了成功(從經驗主義的角度來看),但用數學方法研究其性質的工作相對較少。一個例外是Scarselli et.al(2009a)的工作,他認為:最早的 GNN 模型(Scarselli et.al,2009b)可以在概率上近似於 measurable functions。Lei et.al(2017)表明,他們提出的架構位於圖核的 RKHS(abbr. reproducing kernel Hilbert space 再生式原子核希爾伯特空間) 中,但沒有明確研究它可以區分哪些圖。這些作品都側重於一個特定的體系結構,並不容易推廣到多個體繫結構。
相比之下,上述結論為分析和描述一個廣泛類別的 GNN 的表達能力提供了一個更一般的理論框架。最近,許多基於 GNN 的架構被提出,包括和聚合和 MLP(巴塔格利亞等人,2016;斯卡塞利等人,2009b;Duvenaud等人,2015),而大多數沒有理論推導。與許多先前的 GNN 架構相比,我們的圖同構網路(GIN)在理論上更加充分,並且簡單而強大。
measurable functions: 不太理解這個概念具體是什麼函數,我個人暫且理解為可以通過公式表達的函數(或者能夠通過最大近似理論去利用 MLPs 逼近的函數)
7 EXPERIMENTS
在實驗部分比較了 GIN 於其他較弱的 GNN 變體在測試集,訓練集上的表現。訓練集能夠去評估模型的表徵能力,且測試集能評估模型的泛化能力。
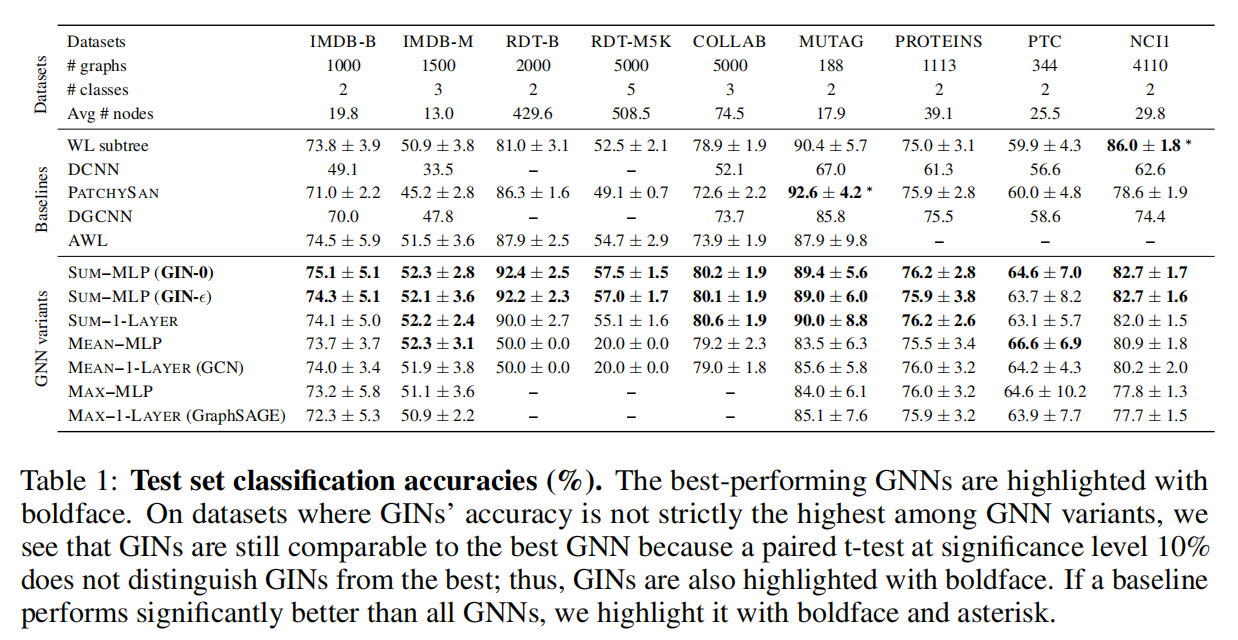
Datasets. 我們採用 9 個圖分類 benchmarks:4個生物資訊學資料集(MUTAG,PTC,NCI1,PROTEINS)以及5個社群網路資料集(COLLAB,IMDB-BINARY,IMDB-MULTI,REDDIT-BINARY,REDDIT-MULTI5K)。重要的是,我們實驗目的並不是讓模型依賴於輸入節點的特徵,而是主要讓模型從網路結構中學習。因此,在生物資訊學 Graph 中,節點具有分類輸入特徵;但在社群網路中,節點沒有特徵。
對於社群網路資料集,我們建立節點特徵如下:對於 REDDIT 資料集,我們將所有的節點特徵向量設定為統一(因此,這裡的特徵是不具備資訊的);對於其他的社群網路 Graphs,我們基於節點 degrees 去生成 one-hot encodings 以表示節點特徵。資料集統計彙總於 table.1 更多的資料細節可以在 Appendix.I 中找到。
Models and configurations. 我們評估了 GINs(Eqs.4.1 and 4.2)以及其他 less powerful GNN 變體。而針對 GIN 框架,我們考慮它的兩個變體:
- 基於 Eq.4.1 進行梯度下降學習引數 \(\epsilon\) 的 GIN-\(\epsilon\)
- 一個更簡單的 GIN-0,其中 Eq.4.1 的引數 \(\epsilon\) 固定為0。
實驗表明 GIN-0 有更強大的效能:GIN-0 不僅與 GIN-\(\epsilon\) 同樣擬合訓練資料,而且具備良好的泛化效能,而在測試精度方面略微但始終優於GIN-\(\epsilon\)。對於其他較弱的 GNN 變體 我們考慮替換 GIN-0 的 sum 聚合,採用 mean or max-pooling,或者替換多層感知機為單層感知機。
在 Fig.4 以及 Table.1 中,模型會根據 其採用的聚合方式/感知機的層數 來命名,例如 mean-1-layer 和 max-1-layer 分別對應了 GCN 和 GraphSAGE,並且會在此基礎上進行較小的修改。我們對 GINs 以及 GNN 變體都採用相同的 Graph Readout(Eq.4.2),為了更好的測試效能,生物學資訊資料集上採用 sum readout,社群網路資料集採用 mean readout。
實驗採用十折交叉驗證,並且報告了交叉驗證中,10次驗證精度的平均值和標準差。對於所有的模型設定,採用5個 GNN 層(包括輸入層),並且 MLPs 採用2層。Batch Normalization 應用於每一個 hidden layer。採用 Adam optimizer 並且初始化學習率為 0.01 並且以每 50 次 epochs 進行一次衰減率為 0.5 的權重衰減。我們對於每個資料集都需要調整的超參為:
- hidden units number:對於生物資訊學 Graph 採用 {16, 32},社群網路 Graph 採用 64
- batch size:
- dropout ratio:{0, 0.5} after dense layer
- epochs number:調整為 10 次平均交叉驗證精度最好的 single epoch
注意,由於資料集size較小,使用驗證集進行超參調整時非常不穩定的,比如 MUTAG 驗證集只包含 18 條資料。

我們還報告了對於不同 GNNs 的訓練精度,所有的模型超參都是固定的:
- 5 GNN layers(include input layer)
- hidden units of size 64
- minibatch of size 128
- dropout ratio 0.5
為了比較,WL subtree kernel 的訓練精度也會被報告,其中我們將迭代次數設定為4,對比 5 GNN layers。
Baselines. 我們將上述 GNNs 與最先進的圖分類基準進行比較:
- WL subtree kernel,採用 C-SVM 作為分類器,我們調整的超參為 SVM 的 C;WL iterations number \(∈ \{1,2,...,6\}\)
- 最先進的深度學習架構 —— DCNN,PATCHY-SAN,DGCNN
- Anonymous Walk Embeddings
對於深度學習方法和 AWL,我們報告了原始論文中報告的準確度。
7.1 RESULTS
Training set performance. 我們通過比較 GNNs 的訓練精度來驗證之前對 GNN 模型表徵能力的理論分析。具備較高表徵能力的模型應該具備較高的訓練準確度。Fig.4 展示了具備相同超參的 GINs 和較弱的 GNN 變體的訓練曲線。首先,理論上最強大的 GNN,即 GIN-\(\epsilon\) 和 GIN-0 都能夠完美地擬合所有的訓練集。
而在實驗中,對比 GIN-0 可以發現,GIN-\(\epsilon\) 針對引數 \(\epsilon\) 的學習並沒有在擬合訓練資料中獲得收益;採用 mean/max pooling 或單層感知機的 GNN 變體在許多資料集上都產生了嚴重的過擬合。可以發現,這些模型的訓練精度水平與之前分析的 模型表徵能力進行的排名 一致,在訓練精度方面
- MLPs 大於 1-layer perceptions
- sum aggregators 大於 mean / max aggregators
在我們的資料集上,GNN 的訓練精度從未超過 WL subtree kernel 的訓練精度,這是意料之中的,因為 GNN 通常比 WL-test 的判別能力低。例如在 IMDBBINARY 上,沒有任何一個模型能夠完美地擬合訓練集,GNN 最多也只能夠達到與 wL kernel 相同的訓練精度。這種實驗結果與論文得出的結論一致,即 WL-test 是基於聚合的 GNN 的表徵能力上限。然而 WL kernel 無法學習如何組合節點特徵(即不能具備泛化能力),這對於預測任務來說是非常關鍵的,接下來將說明這個部分。
Test set performance.
接下來,我們比較 test accuracies。雖然我們的理論結果並沒有直接談到 GNNs 的泛化能力,但我們有理由去期待具備強大表徵能力的 GNNs 能夠準確捕捉感興趣的圖結構,從而能夠很好地泛化。Table.1 比較了 GINs(Sum-MLP),其他 GNN 變體以及一些最先進的 test accuracy baselines。
首先,對於 GINs,尤其是 GIN-0,在 9 個資料集上都比較弱的 GNN 變體表現都好。GINs 在社群網路資料集上表現更好,這種型別的資料包含了大量的訓練圖資料。
而對於 Reddit 資料集,所有節點都共用相同的標量作為節點特徵。GINs 以及 sum-aggregation GNNs 都準確地捕獲了圖結構,並且顯著優於其他模型。然而,mean-aggregation GNNs 無法捕獲未標記圖的任何結構(如 Section 5.2 所預測的一樣),並且表現甚至不如隨機預測。
即使提供節點的 degree 作為輸入特徵,基於 mean-aggregation GNNs 也遠遠不如 sum-aggregation GNNs(在 REDDIT-BINARY 資料集上,mean-mlp aggregation 準確率為 71.2±4.6%,在REDDIT-MULTI5K 準確率為 41.3±2.1%)
比較 GINs(GIN-0 以及 GIN-\(\epsilon\)),我們觀察到 GIN-0 的效能略優於 GIN-\(\epsilon\)。由於兩種模型都能夠很好地擬合訓練資料,GIN-0 可能是因為比 GIN-\(\epsilon\) 更簡單因此獲得了更好的泛化能力。
8 CONCLUSION
在本文中,我們開發了一個關於 GNNs 表徵能力推到的理論基礎,並證明了當下流行的 GNN variants 的表徵能力上限。我們還基於鄰域聚合設計了一個可證明的效能最強大的 GNN。未來工作的一個有趣方向是超越鄰域聚合(或訊息傳遞),以追求更強大的圖學習架構。為了完成這個願景,理解和改進 GNN 的泛化特性以及更好地理解它們的優化前景也會很有趣。