多圖詳解:不停機分庫分表五個步驟
1 理論知識
1.1 分庫分表是否必要
分庫分表確實可以解決單表資料量大這個問題,但是並非首選。因為分庫分表至少引入了三個必須解決的突出問題。
第一是分庫分表方案本身具有的複雜性。第二是本地事務失效問題,原本在同一個資料庫中可以保證強一致性業務邏輯,分庫之後事務失效。第三是難以聚合查詢問題,因為分庫分表後查詢條件中必須帶有shardingKey,所以限制了很多查詢場景。
我們在之前文章《面試官問單表資料量大是否必須分庫分表》介紹過解決單表資料量過大問題,可以按照刪、換、分、拆、異、熱這六個字順序進行處理,而不是一上來就分庫分表。
刪是指刪除歷史資料並進行歸檔。換是指不要只使用資料庫資源,有些資料可以儲存至其它替代資源。分是指讀寫分離,增加多個讀範例應對讀多寫少的網際網路場景。拆是指分庫分表,將資料分散至不同的庫表中減輕壓力。異指資料異構,將一份資料根據不同業務需求儲存多份。熱是指熱點資料,這是一個非常值得注意的問題。
1.2 分庫分表兩大維度
假設有一個電商資料庫存放訂單、商品、支付三張業務表。隨著業務量越來越大,這三張業務資料表也越來越大,查詢效能顯著降低,資料拆分勢在必行,那麼資料拆分可以從縱向和橫向兩個維度進行。
1.2.1 縱向拆分
縱向拆分就是按照業務拆分,我們將電商資料庫拆分成三個庫,訂單庫、商品庫。支付庫,訂單表在訂單庫,商品表在商品庫,支付表在支付庫。這樣每個庫只需要儲存本業務資料,物理隔離不會互相影響。
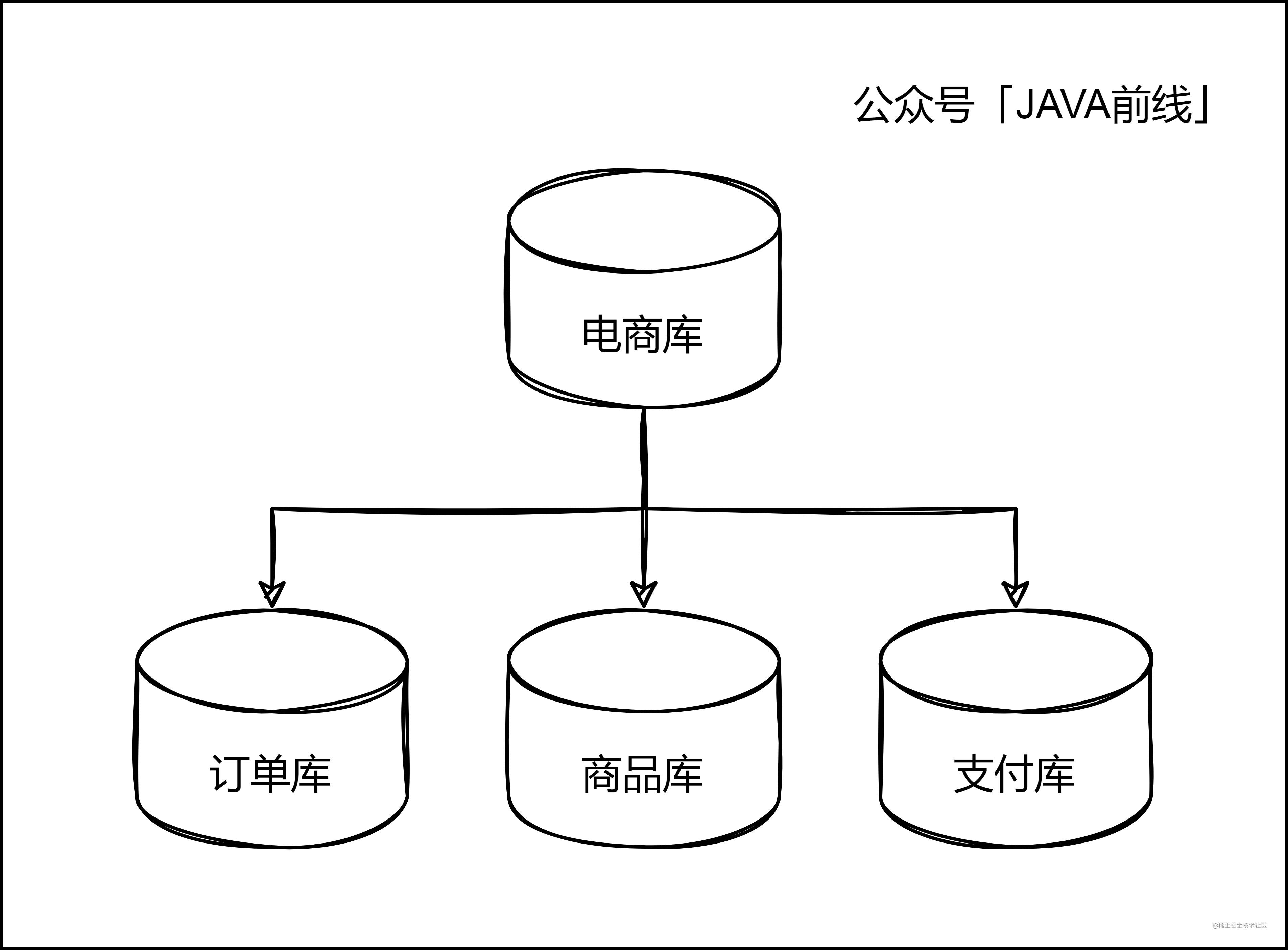
1.2.2 橫向拆分
按照縱向拆分方案,現在我們已經有三個庫了,平穩執行了一段時間。但是隨著業務增長,每個單庫單表的資料量也越來越大,逐漸到達瓶頸。
這時我們就要對資料表進行橫向拆分,所謂橫向拆分就是根據某種規則將單庫單表資料分散到多庫多表,從而減小單庫單表的壓力。
橫向拆分策略有很多方案,最重要的一點是選好ShardingKey,也就是按照哪一列進行拆分,怎麼分取決於我們存取資料的方式。
(1) 範圍分片
如果我們選擇的ShardingKey是訂單建立時間,那麼分片策略是拆分四個資料庫,分別儲存每季度資料,每個庫包含三張表,分別儲存每個月資料:

這個方案的優點是對範圍查詢比較友好,例如我們需要統計第一季度的相關資料,查詢條件直接輸入時間範圍即可。這個方案的問題是容易產生熱點資料。例如雙11當天下單量特別大,就會導致11月這張表資料量特別大從而造成存取壓力。
(2) 查表分片
查表法是根據一張路由表決定ShardingKey路由到哪一張表,每次路由時首先到路由表裡查到分片資訊,再到這個分片去取資料。我們分析一個查表法思想應用實際案例。
Redis官方在3.0版本之後提供了叢集方案RedisCluster,其中引入了雜湊槽(slot)這個概念。一個叢集固定有16384個槽,在叢集初始化時這些槽會平均分配到Redis叢集節點上。每個key請求最終落到哪個槽計算公式是固定的:
SLOT = CRC16(key) mod 16384
一個key請求過來怎麼知道去哪臺Redis節點獲取資料?這就要用到查表法思想:
(1) 使用者端連線任意一臺Redis節點,假設隨機存取到節點A
(2) 節點A根據key計算出slot值
(3) 每個節點都維護著slot和節點對映關係表
(4) 如果節點A查表發現該slot在本節點,直接返回資料給使用者端
(5) 如果節點A查表發現該slot不在本節點,返回給使用者端一個重定向命令,告訴使用者端應該去哪個節點請求這個key的資料
(6) 使用者端向正確節點發起連線請求
查表法方案優點是可以靈活制定路由策略,如果我們發現有的分片已經成為熱點則修改路由策略。缺點是多一次查詢路由表操作增加耗時,而且路由表如果是單點也可能會有單點問題。
(3) 雜湊分片
現在比較流行的分片方法是雜湊分片,相較於範圍分片,雜湊分片可以較為均勻將資料分散在資料庫中。我們現在將訂單庫拆分為4個庫編號為[0,3],每個庫包含3張表編號為[0,2],如下圖如所示:
我們選擇使用orderId作為ShardingKey,那麼orderId=100這個訂單會儲存在哪張表?因為是分庫分表,第一步確定路由到哪一個庫,取模計算結果表示庫表序號:
db_index = 100 % 4 = 0
第二步確定路由到哪一張表:
table_index = 100 % 3 = 1
第三步資料路由到0號庫1號表:
在實際開發中路由邏輯並不需要我們手動實現,因為有許多開源框架通過設定就可以實現路由功能,例如ShardingSphere、TDDL框架等等。
2 分庫分表準備工作
2.1 計算庫表數量
分幾個庫和幾張表是在分庫分表工作開始前必須要回答的問題,我們首先看看阿里巴巴開發手冊的建議:單錶行數超過500萬行或者單表容量超過2GB才推薦進行分庫分表,如果預計3年後資料量根本達不到這個級別,請不要在建立表時就分庫分表。
我們提取出這個建議的兩個關鍵詞500萬、3年作為預估庫表數的基線,假設業務資料日增量60萬,那麼應該如何預估需要分多少個庫,多少張表呢?
日增量60萬計算3年後資料總量:
三年資料總量 = 60 * 365 * 3 = 65700
隨著後續業務發展日增量會超過60萬,所以我們要對資料總量進行冗餘,冗餘指數是多少根據業務情況而定,本文按照3倍冗餘:
三年資料總量三倍冗餘 = 65700 * 3 = 197100
按照單表500萬並向上取整至2的冪次計算表數量
表數量 = 197100 / 500 = 394.2 向上取整 = 512
所有表放在一個庫並不合適,因為隨著資料量增大,存取並行量也會呈正相關增大,一個資料庫範例是難以支撐的。本文按照一個資料庫範例包含32張表計算庫數量:
庫數量 = 512 / 32 = 16
2.2 shardingKey
確定shardingKey非常關鍵,因為作為分片指標,當資料拆分至多個庫表之後,代理層只能根據shardingKey進行表路由。假設我們設定了userId作為shardingKey,那麼後續DML操作都必須包含userId欄位。但是現在有一種場景只有orderId作為查詢條件,那麼我們應該如何處理這種場景呢?
第一種方案是設計orderId包含userId相關特徵,這樣即使只有訂單號作為查詢條件,也可以擷取userId特徵進行分片:
訂單號 = 毫秒數 + 版本號 + userId後六位 + 全域性序列號
第二種方案是資料異構,核心思想是以空間換時間,一份資料根據不同維度儲存到多個資料媒介,資料異構一般分為如下型別。
資料異構至MySQL:我們可以選擇orderId作為shardingKey儲存至另一個資料庫範例,那麼orderId就可以作為條件進行查詢。
資料異構至ES:如果每一個維度都新建一個資料庫範例也是不現實的,所以我們可以將資料同步至ES滿足多維度查詢需求。
資料異構至Hive:MySQL和ES可以滿足實時查詢需求,Hive可以滿足離線分析需求,報表等資料分析工作無需通過主庫,而是可以通過Hive進行。
現在又引出一個新問題,業務不可能每次都將資料寫入多個資料來源,這樣會帶來效能問題和資料一致性問題,所以需要一個管道進行各資料來源之間同步,阿里開源的canal元件可以解決這個問題。
3 分庫分表範例
在完成準備工作之後,我們可以開始分庫分表工作了。分庫分表方法有很多種,但是說到底都是在處理兩類資料:存量和增量。存量表示舊資料庫已經存在的資料,增量表示不存在於舊資料庫待新增或者變更的資料。根據存量和增量這兩種型別,我們可以將分庫分表方法分為停服拆分和不停服拆分。
3.1 停服拆分
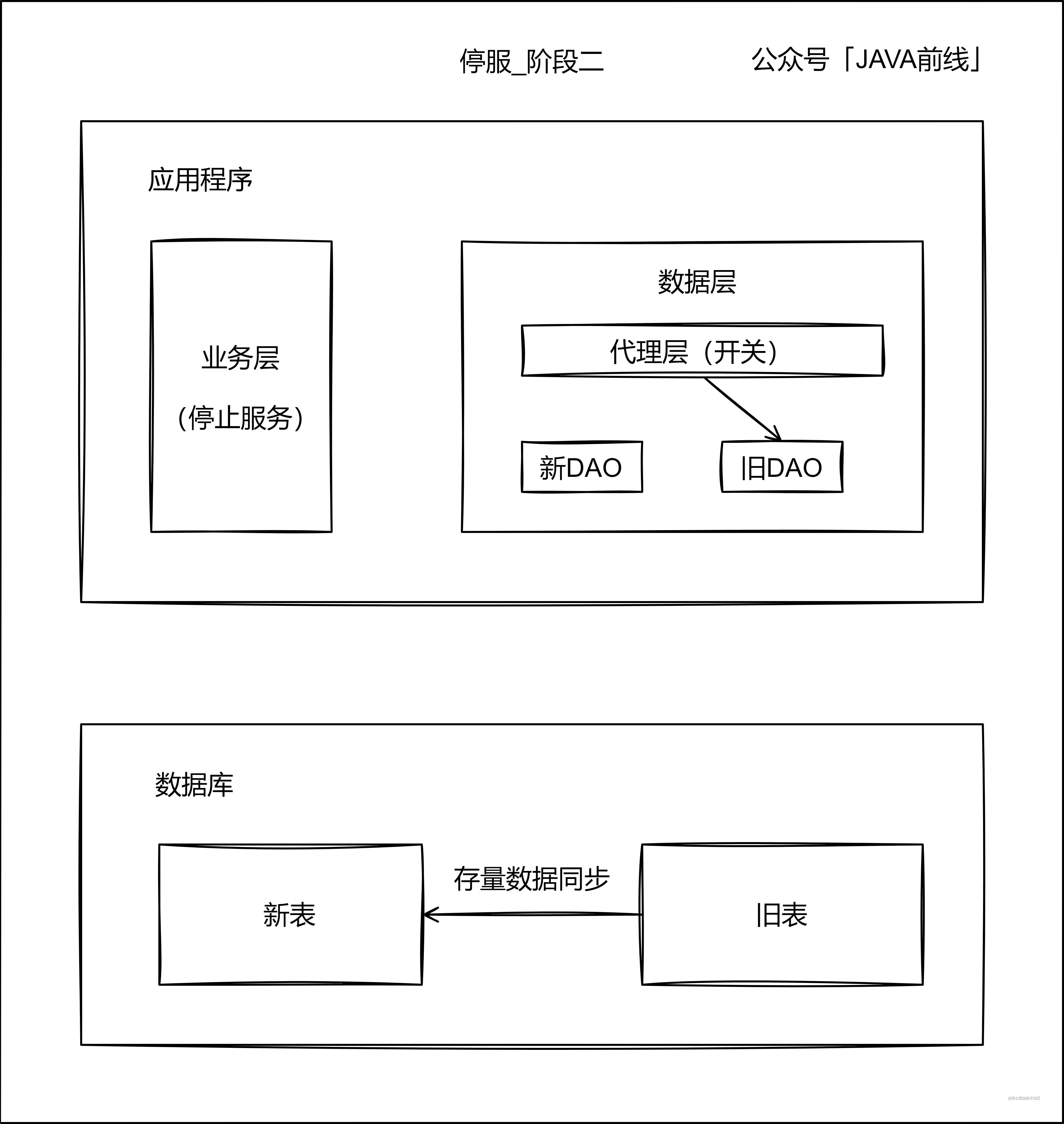
停服是指停止服務,系統不再接收新業務資料,那麼舊資料在分庫分表這個時間段內是靜止不變的,資料全部變為了存量資料。停服拆分一般分為三個階段。
第一階段首先編寫代理層和新DAO,代理層通過開關決定存取舊錶還是新表,此時流量還是全部存取舊錶:
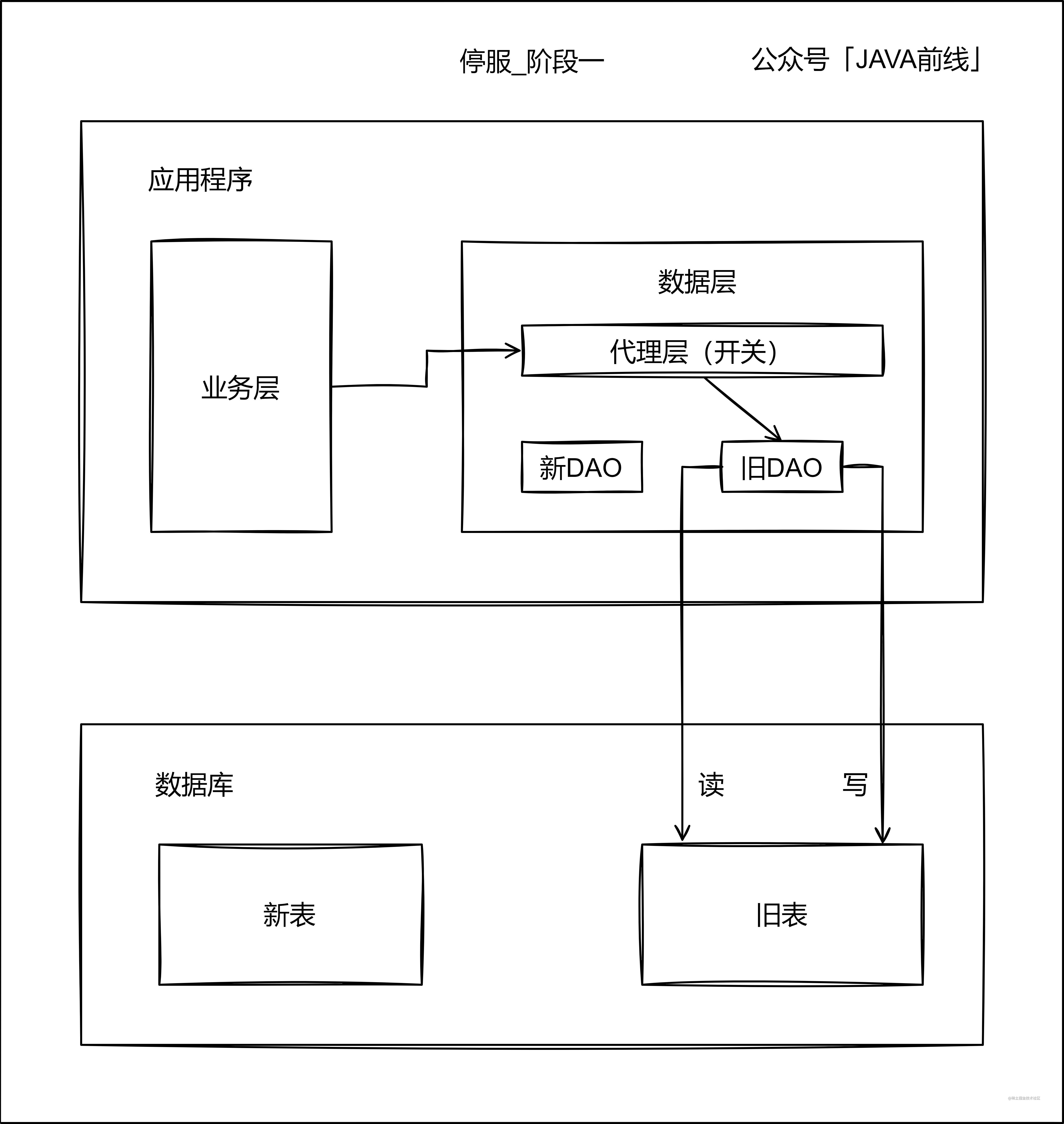
第二階段停止服務,整個應用都沒有流量,舊錶資料已經處於靜止狀態,此時通過指令碼將存量資料從舊錶遷移至新表:
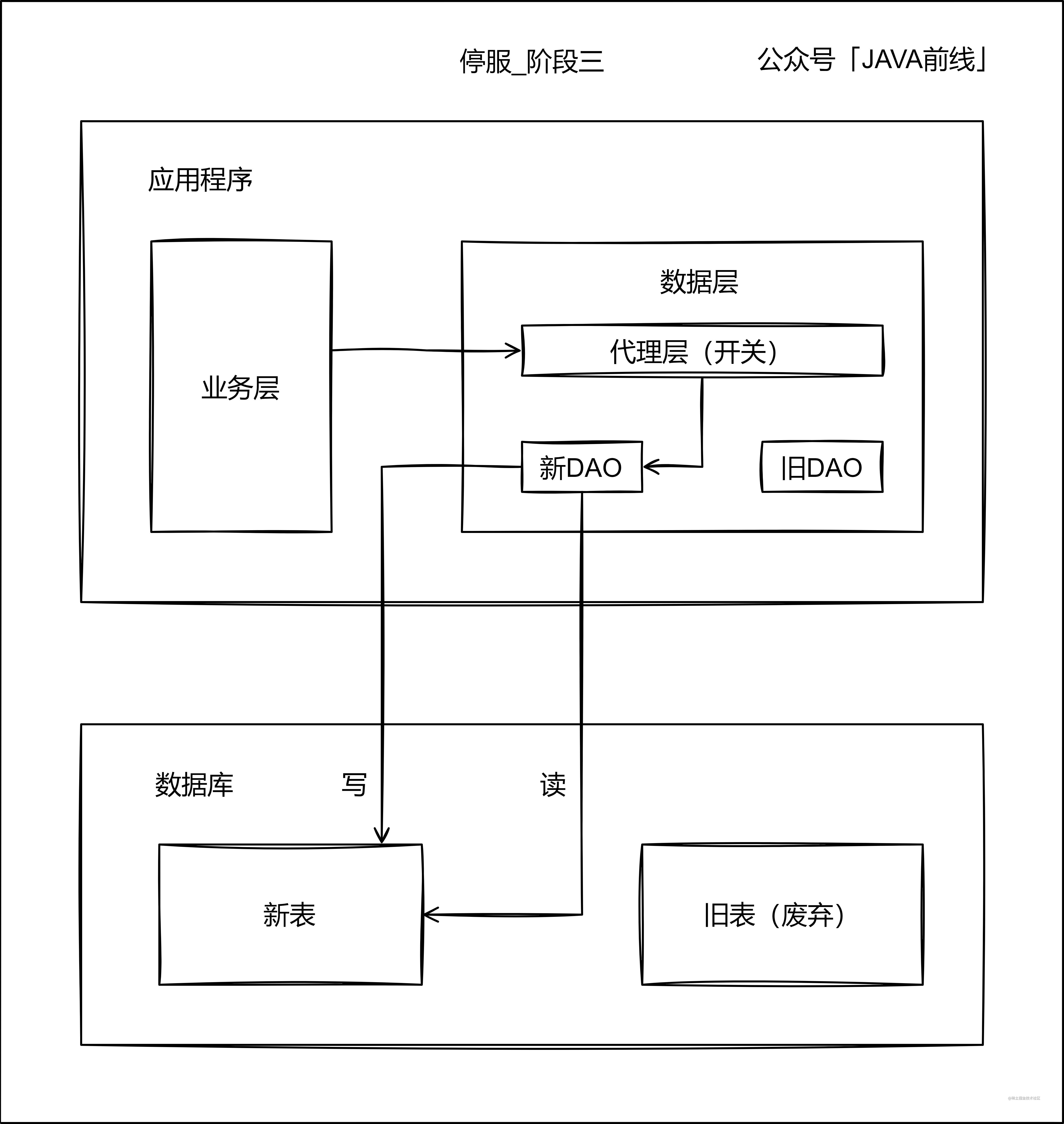
第三階段通過代理層存取新表,如果出現錯誤可以停服排查問題:
3.2 不停服拆分
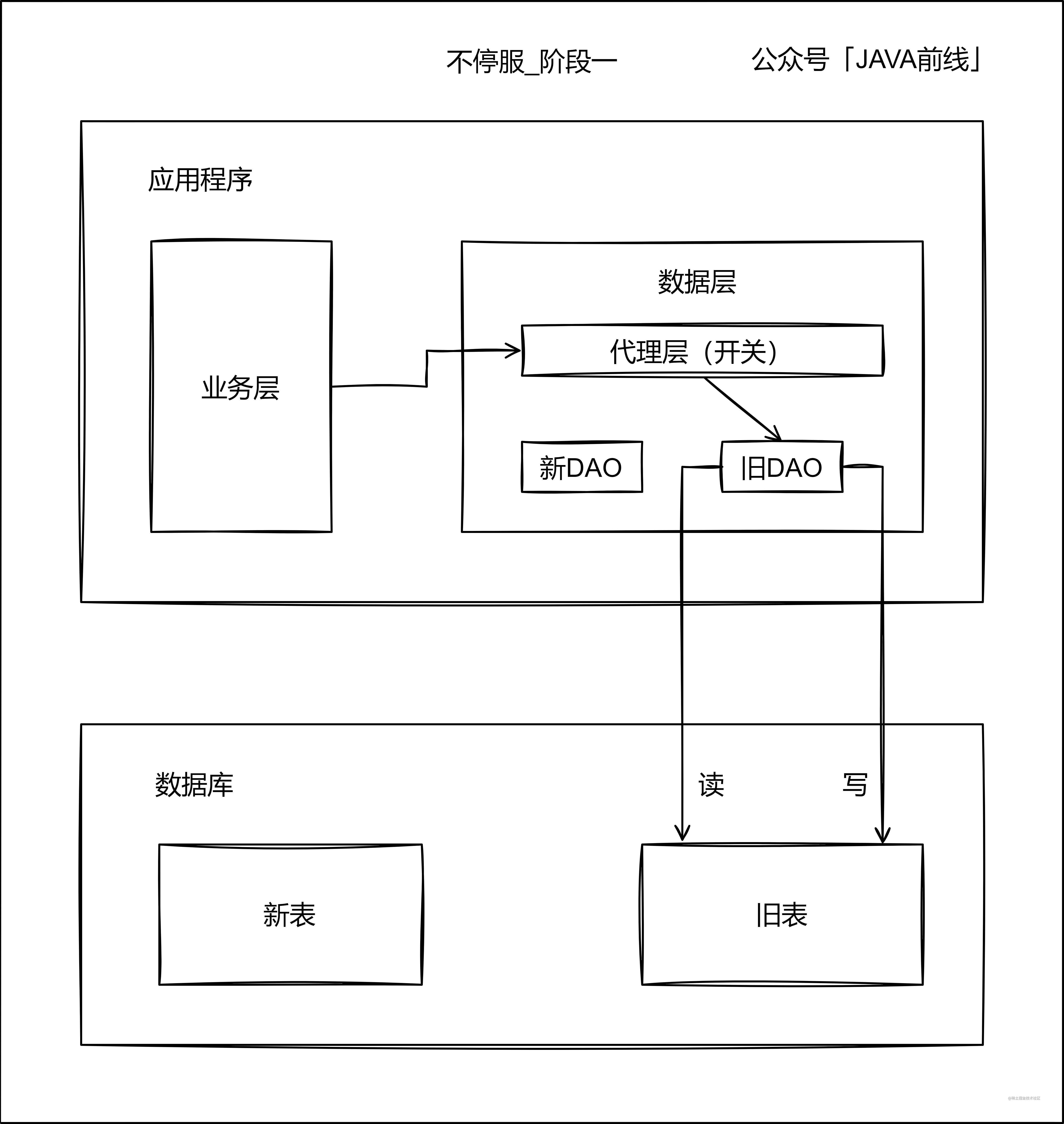
停服拆分方案比較簡單,但是在分表這段時間沒有業務流量,對業務是有損的,所以我們一般採用不停服拆分方案,一邊有流量存取,一邊進行分庫分表,此時資料不僅有存量還有增量,相對而言會複雜一些。
第一階段首先編寫代理層和新DAO,代理層通過開關決定存取舊錶還是新表,此時流量還是全部存取舊錶:
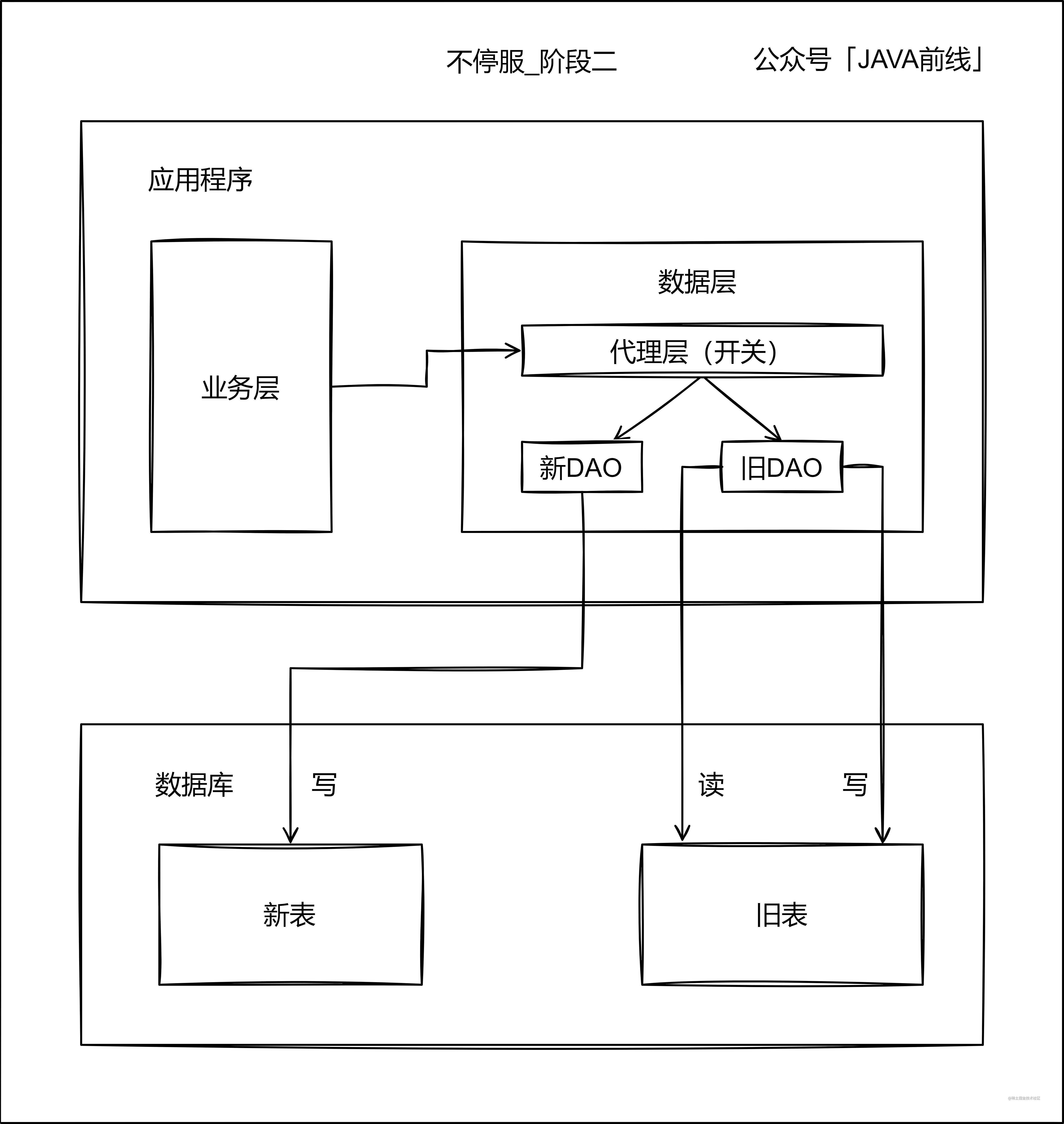
第二階段開啟雙寫,增量資料不僅在舊錶新增和修改,也在新表新增和修改,紀錄檔或者臨時表記錄下寫入新表ID起始值,舊錶中小於這個值的資料就是存量資料:
第三階段存量資料遷移,通過指令碼將存量資料寫入新表:

第四階段停讀舊錶改讀新表,此時新表已經承載了所有讀寫業務,但是不要立刻停寫舊錶,需要保持雙寫一段時間。
不停寫舊錶有兩個原因:第一是因為如果讀新表出現問題,還可以將讀流量切回舊錶。第二是因為可以進行資料校對,例如新表和舊錶資料都同步至Hive,選取幾天的資料進行校對,從而驗證資料同步的準確性。
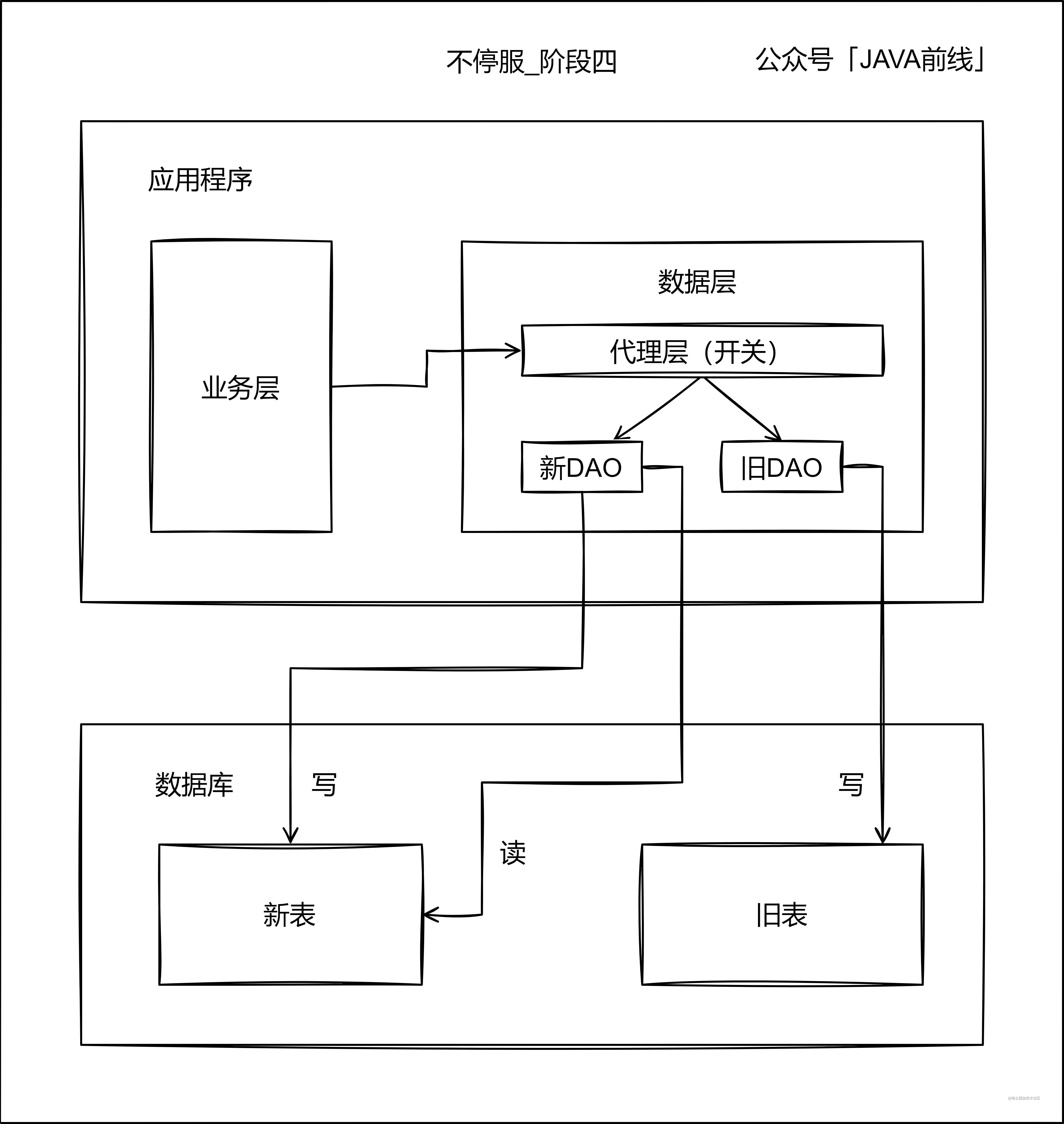
第五階段當讀寫新表一段時間之後,沒有發生業務問題,可以停寫舊錶:
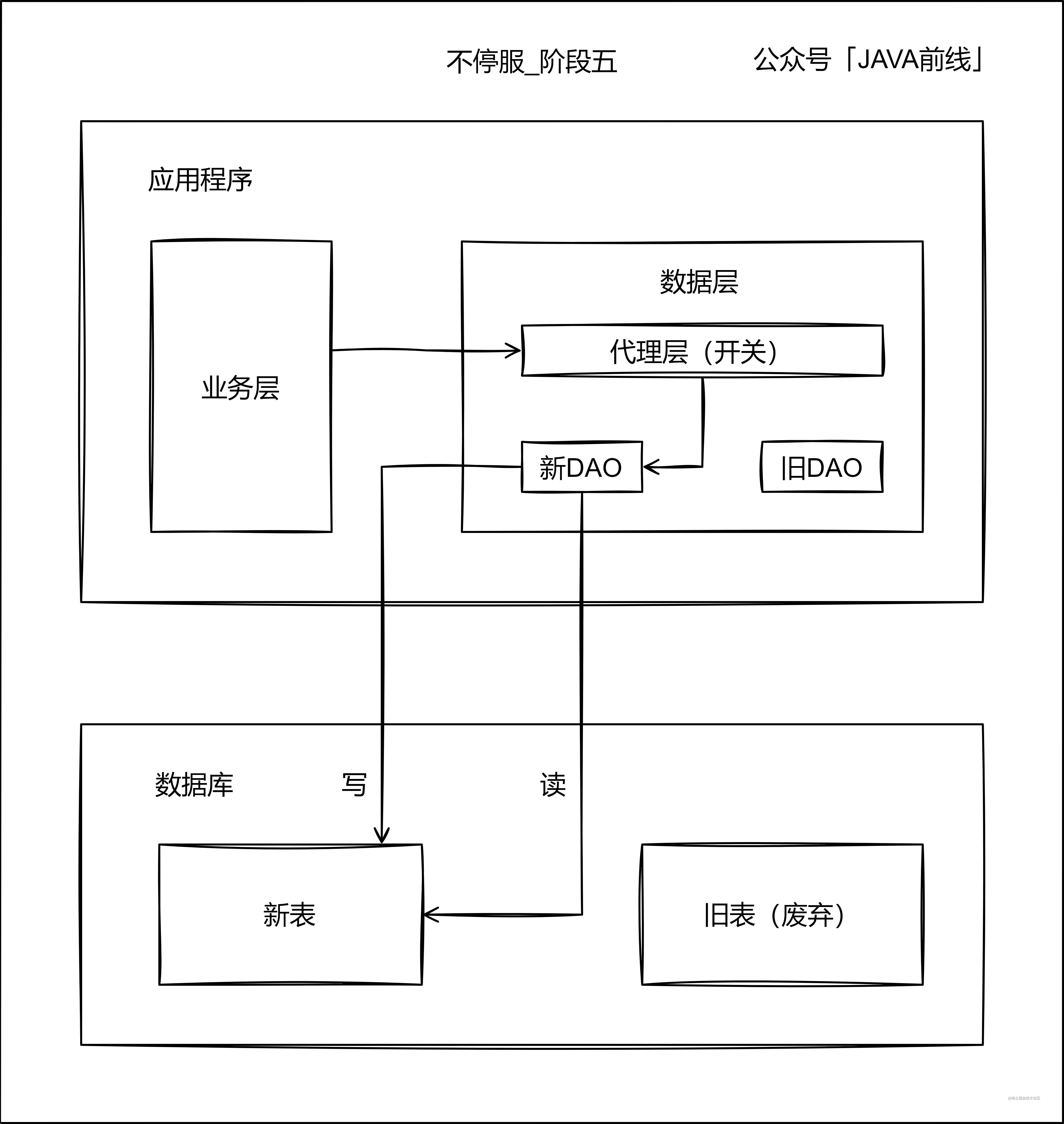
3.3 代理層實現
代理層實現了新舊資料來源切換,需要儘量減少業務層程式碼的侵入性,而介面卡模式可以有效減少對業務層的侵入性。我們首先看看舊資料存取物件和業務服務:
// 訂單資料物件
public class OrderDO {
private String orderId;
private Long price;
public String getOrderId() {
return orderId;
}
public void setOrderId(String orderId) {
this.orderId = orderId;
}
public Long getPrice() {
return price;
}
public void setPrice(Long price) {
this.price = price;
}
}
// 舊DAO
public interface OrderDAO {
public void insert(OrderDO orderDO);
}
// 業務服務
public class OrderServiceImpl implements OrderService {
@Resource
private OrderDAO orderDAO;
@Override
public String createOrder(Long price) {
String orderId = "orderId_123";
OrderDO orderDO = new OrderDO();
orderDO.setOrderId(orderId);
orderDO.setPrice(price);
orderDAO.insert(orderDO);
return orderId;
}
}
引入新資料來源存取物件:
// 新資料物件
public class OrderNewDO {
private String orderId;
private Long price;
}
// 新DAO
public interface OrderNewDAO {
public void insert(OrderNewDO orderNewDO);
}
介面卡模式減少業務程式碼侵入性:
// 代理層
public class OrderDAOProxy implements OrderDAO {
private OrderDAO orderDAO;
private OrderNewDAO orderNewDAO;
public OrderDAOProxy(OrderDAO orderDAO, OrderNewDAO orderNewDAO) {
this.orderDAO = orderDAO;
this.orderNewDAO = orderNewDAO;
}
@Override
public void insert(OrderDO orderDO) {
if(ApolloConfig.routeNewDB) {
OrderNewDO orderNewDO = new OrderNewDO();
orderNewDO.setPrice(orderDO.getPrice());
orderNewDO.setOrderId(orderDO.getOrderId());
orderNewDAO.insert(orderNewDO);
} else {
orderDAO.insert(orderDO);
}
}
}
// 業務服務
public class OrderServiceImpl implements OrderService {
@Resource
private OrderDAO orderDAO;
@Resource
private OrderNewDAO orderNewDAO;
@Override
public String createOrder(Long price) {
String orderId = "orderId_123";
OrderDO orderDO = new OrderDO();
orderDO.setOrderId(orderId);
orderDO.setPrice(price);
new OrderDAOProxy(orderDAO, orderNewDAO).insert(orderDO);
return orderId;
}
}
4 文章總結
分庫分表具有三個必須面對的問題:方案本身複雜性、本地事務失效問題、難以聚合查詢問題,所以分庫分表方案並非解決海量資料問題的首選。
如果必須分庫分表,首先進行容量預估並選擇合適的shardingKey,其次根據實際業務選擇停服或者不停服方案,如果選擇不停服方案,注意保持新表和舊錶雙寫一段時間,從而驗證資料準確性,希望本文對大家有所幫助。