圖資料庫 NebulaGraph 的記憶體管理實踐之 Memory Tracker
![]()
資料庫的記憶體管理是資料庫核心設計中的重要模組,記憶體的可度量、可管控是資料庫穩定性的重要保障。同樣的,記憶體管理對圖資料庫 NebulaGraph 也至關重要。
圖資料庫的多度關聯查詢特性,往往使圖資料庫執行層對記憶體的需求量巨大。本文主要介紹 NebulaGraph v3.4 版本中引入的新特性 Memory Tracker,希望通過 Memory Tracker 模組的引入,實現細粒度的記憶體使用量管控,降低 graphd 和 storaged 發生被系統 OOM kill 的風險,提升 NebulaGraph 圖資料庫的核心穩定性。
注:為了同程式碼保持對應,本文部分用詞直接使用了英文,e.g. reserve 記憶體 quota。
可用記憶體
在進行 Memory Tracker 的介紹之前,這裡先介紹下相關的背景知識:可用記憶體。
程序可用記憶體
在這裡,我們簡單介紹下各個模式下,系統是如何判斷可用記憶體的。
物理機模式
資料庫核心會讀取系統目錄 /proc/meminfo,來確定當前環境的實際記憶體和剩餘記憶體,Memory Tracker 將「實際實體記憶體」作為「程序可以使用的最大記憶體」;
容器/cgroup 模式
在 nebula-graphd.conf 檔案中有一個設定項 FLAG_containerized 用來判斷是否資料庫跑在容器上。將 FLAG_containerized(預設為 false)設定為 true 之後,核心會讀取相關 cgroup path 下的檔案,確定當前程序可以使用多少記憶體;cgroup 有 v1、v2 兩個版本,這裡以 v2 為例;
| FLAG | 預設值 | 解釋 |
|---|---|---|
| FLAG_cgroup_v2_memory_max_path | /sys/fs/cgroup/memory.max | 通過讀取路徑確定最大記憶體使用量 |
| FLAG_cgroup_v2_memory_current_path | /sys/fs/cgroup/memory.current | 通過讀取路徑確定當前記憶體使用量 |
舉個例子,在單臺機器上分別控制 graphd 和 storaged 的記憶體額度。你可以通過以下步驟:
step1:設定 FLAG_containerized=true;
step2:建立 /sys/fs/cgroup/graphd/,/sys/fs/cgroup/storaged/,並設定各自目錄下的 memory.max;
step3:在 etc/nebula-graphd.conf,etc/nebula-storaged.conf 新增相關設定
--containerized=true
--cgroup_v2_controllers=/sys/fs/cgroup/graphd/cgroup.controllers
--cgroup_v2_memory_stat_path=/sys/fs/cgroup/graphd/memory.stat
--cgroup_v2_memory_max_path=/sys/fs/cgroup/graphd/memory.max
--cgroup_v2_memory_current_path=/sys/fs/cgroup/graphd/memory.current
Memory Tracker 可用記憶體
在獲取「程序可用記憶體」以後,系統需要將其換算成 Memory Tracker 可 track 的記憶體,「程序可用記憶體」與「Memory Tracker 可用記憶體」有一個換算公式;
memtracker_limit = ( total - FLAGS_memory_tracker_untracked_reserved_memory_mb ) * FLAGS_memory_tracker_limit_ratio
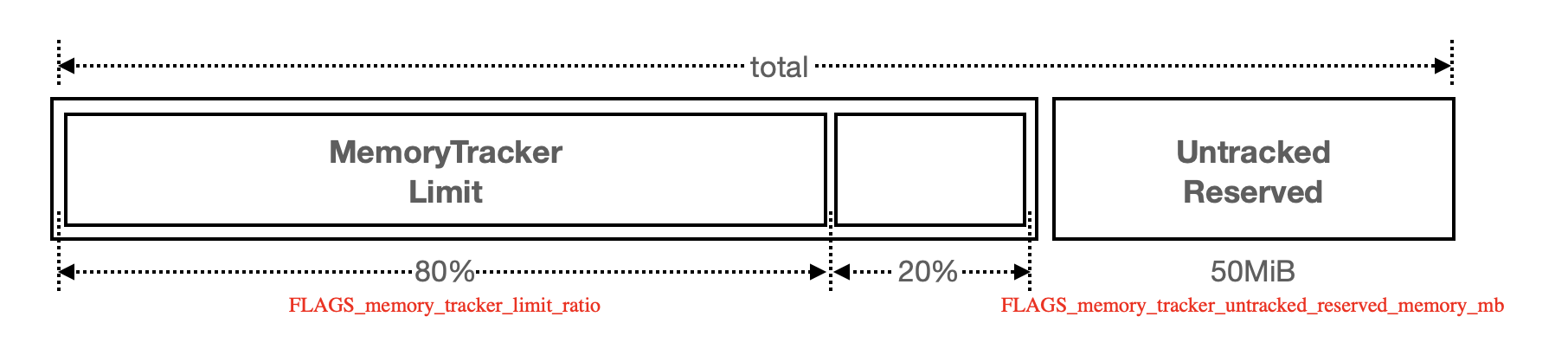
| FLAG | 預設值 | 解釋 | 支援動態改 |
|---|---|---|---|
| memory_tracker_untracked_reserved_memory_mb | 50 M | Memory Tracker 會管理通過 new/delete 申請的記憶體,但程序除了通過此種方式申請記憶體外,還可能存在其他方式佔用的記憶體;比如通過呼叫底層的 malloc/free 申請,這些記憶體通過此 flag 控制,在計算時會扣除此部分未被 track 的記憶體。 | Yes |
| memory_tracker_limit_ratio | 0.8 | 指定 Memory Tracker 可以使用的記憶體比例,在一些場景,我們可能需要調小來防止 OOM。 | Yes |
這裡來詳細展開說下 memory_tracker_limit_ratio 的使用:
- 在混合部署環境中,存在多個 graphd 或 storaged 混合部署是需要調小。比如 graphd 只佔用 50% 記憶體,則需在 nebula-graphd.conf 中將其手動改成 0.5;
- 取值範圍:
memory_tracker_limit_ratio除了(0,1]取值範圍外,還額外定義了兩個特殊值:2:通過資料庫核心感知當前系統執行環境的可用記憶體,動態調整可用記憶體。由於此種方式非實時,有一定的概率會感知不精準;3:limit 將被設成一個極大值,起到關閉 Memory Tracker 的效果;
Memory Tracker 的設計與實現方案
下面,講下 Memory Tracker 的設計與實現。整體的 Memory Tracker 設計,包含 Global new/delete operator、MemoryStats、system malloc、Limiter 等幾個子模組。這個部分著重介紹下 Global new/delete operator 和 MemoryStats 模組。
![]()
Global new/delete operator
Memory Tracker 通過 overload 全域性 new/delete operator,接管記憶體的申請和釋放,從而做到在進行真正的記憶體分配之前,進行記憶體額度分配的管理。這個過程分解為兩個步驟:
- 第一步:通過 MemoryStats 進行記憶體申請的彙報;
- 第二步:呼叫 jemalloc 發生真正的記憶體分配行為;
jemalloc:Memory Tracker 不改變底層的 malloc 機制,仍然使用 jemalloc 進行記憶體的申請和釋放;
MemoryStats
全域性的記憶體使用情況統計,通過 GlobalMemoryStats 和 ThreadMemoryStats 分別對全域性記憶體和執行緒內部記憶體進行管理;
ThreadMemoryStats
thread_local 變數,執行引擎執行緒在各自的 ThreadMemoryStats 中維護執行緒的 MemoryStats,包括「記憶體 Reservation 資訊」和「是否允許拋異常的 throwOnMemoryExceeded」;
- Reservation
每個執行緒 reserve 了 1 MB 的記憶體 quota,從而避免頻繁地向 GlobalMemoryStats 索要額度。不管是申請還是返還時,ThreadMemoryStats 都會以一個較大的記憶體塊作為與全域性交換的單位。
alloc:在本地 reserved 1 MB 記憶體用完了,才問全域性要下一個 1 MB。通過此種方式來儘可能降低向全域性 quota 申請記憶體的頻率;
dealloc:返還的記憶體先加到執行緒的 reserved 中,當 reserve quota 超過 1 MB 時,還掉 1 MB,剩下的自己留著;
// Memory stats for each thread.
struct ThreadMemoryStats {
ThreadMemoryStats();
~ThreadMemoryStats();
// reserved bytes size in current thread
int64_t reserved;
bool throwOnMemoryExceeded{false};
};
- throwOnMemoryExceeded
執行緒在遇到超過記憶體額度時,是否 throw 異常。只有在設定 throwOnMemoryExceeded 為 true 時,才會 throw std::bad_alloc。需要關閉 throw std::bad_alloc 場景見 Catch std::bac_alloc 章節。
GlobalMemoryStats
全域性記憶體額度,維護了 limit 和 used 變數。
-
limit:通過執行環境和設定資訊,換算得到 Memory Tracker 可管理的最大記憶體。limit 同 Limiter 模組的作用,詳細記憶體換算見上文「Memory Tracker 可用記憶體」章節;
-
used:原子變數,彙總所有執行緒彙報上來的已使用記憶體(包括執行緒 reserved 的部分)。如果 used + try_to_alloc > limit,且在
throwOnMemoryExceeded為 true 時,則會拋異常std::bac_alloc。
Catch std::bac_alloc
由於 Memory Tracker overload new/delete 會影響所有執行緒,包括三方執行緒。此時,throw bad_alloc 在一些第三方執行緒可能出現非預期行為。為了杜絕此類問題發生,我們採用在程式碼路徑上主動開啟記憶體檢測,選擇在運算元、RPC 等模組主動開啟記憶體檢測;
運算元的記憶體檢測
在 graph/storage 的各個運算元中,新增 try...catch (在當前執行緒進行計算/分配記憶體) 和 thenError (通過 folly::Executor 非同步提交的計算任務),感知 Memory Tracker 丟擲 std::bac_alloc。資料庫再通過 Status 返回錯誤碼,使查詢失敗;
在進行一些記憶體偵錯時,可通過開啟 nebula-graphd.conf 檔案中的 FLAGS_memory_tracker_detail_log 設定項,並調小 memory_tracker_detail_log_interval_ms 觀察查詢前後的記憶體使用情況;
folly::future 非同步執行
thenValue([this](StorageRpcResponse<GetNeighborsResponse>&& resp) {
memory::MemoryCheckGuard guard;
// memory tracker turned on code scope
return handleResponse(resp);
})
.thenError(folly::tag_t<std::bad_alloc>{},
[](const std::bad_alloc&) {
// handle memory exceed
})
同步執行
memory::MemoryCheckGuard guard; \
try {
// ...
} catch (std::bad_alloc & e) { \
// handle memory exceed
}
RPC 的記憶體檢測
RPC 主要解決 Request/Response 物件的序列化/反序列化的記憶體額度控制問題,由於 storaged reponse 返回的資料均封裝在 DataSet 資料結構中,所以問題轉化為:DataSet 的序列化、反序列化過程中的記憶體檢測。
序列化:DataSet 的物件構造在 NebulaGraph 運算元返回結果邏輯中,預設情況下,已經開啟記憶體檢測;
反序列化:通過 MemoryCheckGuard 顯式開啟,在 StorageClientBase::getResponse's onError 可捕獲異常;
錯誤碼
為了便於分辨哪個模組發生問題,NebulaGraph 中還新增了相關錯誤碼,分別表示 graphd 和 storaged 發生 memory exceeded 異常:
E_GRAPH_MEMORY_EXCEEDED = -2600, // Graph memory exceeded
E_STORAGE_MEMORY_EXCEEDED = -3600, // Storage memory exceeded
延伸閱讀
- 什麼是 malloc 以及動態記憶體分配:https://en.wikipedia.org/wiki/C_dynamic_memory_allocation
- jemalloc
謝謝你讀完本文 (///▽///)