Jan 2023-Prioritizing Samples in Reinforcement Learning with Reducible Loss
1 Introduction
本文建議根據樣本的可學習性進行抽樣,而不是從經驗回放中隨機抽樣。如果有可能減少代理對該樣本的損失,則認為該樣本是可學習的。我們將可以減少樣本損失的數量稱為其可減少損失(ReLo)。這與Schaul等人[2016]的vanilla優先順序不同,後者只是對具有高損失的樣本給予高優先順序,這可能會導致資料點的重複取樣,而這些資料點由於噪聲而無法學習。
本文首先簡要描述了當前在從緩衝區中取樣時進行優先順序排序的方法,然後給出了在強化學習中減少損失的直覺。
這些實驗表明,與Hessel等人[2017]中使用的Schaul等人[2016]的損失項相比,基於可減少的損失進行優先順序排序是一種更魯棒的方法,並且可以在不增加任何額外計算複雜度的情況下進行整合。
2 Background
基本概念
2.1 Experience Replay
2.2 Target Networks
2.3 Off-Policy Algorithms
3 Related Work
3.1 Reducible Loss
優先訓練在訓練開始時保留訓練資料的子集來訓練小容量模型θho。
在訓練期間,這個保留模型用於 衡量一個資料點是否可以在不經過訓練的情況下學習
隨著持有資料集的大小增加,這種估計變得更加準確。
主模型θ和保留模型在實際訓練資料上的損失之間的差異被稱為可減少損失Lr,它用於小批次取樣中訓練資料的優先順序排序
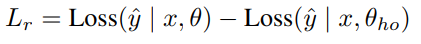
Lr被認為通過對資料點的訓練來衡量資訊的增益
3.2 Prioritization Schemes
Sinha-2020 提出了一種在當前策略平穩分佈下,基於經驗的似然度重新加權的方法,以保證重複可見狀態值函數的近似誤差較小
Lahire-2021介紹了大批次經驗回放(LaBER),通過採用 an importance sampling view(重要性取樣檢視)來估計梯度,以克服PER的優先順序過時及其超引數敏感性的問題。LaBER首先從回放緩衝區中取樣一個大批次,然後計算梯度範數,最後按優先順序向下取樣到一個較小大小的小批次。
Kumar-2020提出了分佈校正(DisCor),這是一種糾正反饋形式,可以使學習動態更加穩定。DisCor計算最優分佈並執行加權Bellman更新以重新加權重放緩衝區中的資料分佈。
受DisCor的啟發, 後悔最小化經驗重放(remn)-2021用an error network(誤差網路)估計Q值的次優性。
拓撲經驗回放(TER)-2022將智慧體的experience組織成a graph(圖),該圖跟蹤狀態q值之間的依賴性。
4 Reducible Loss for Reinforcement Learning
受監督學習中優先訓練的激勵,我們提出了一種針對強化學習問題的優先排序方案,即智慧體應該專注於具有更高的可減少TD誤差的樣本,而不是根據TD誤差進行優先順序排序,。這意味著,我們應該使用TD誤差可以減少多少的度量,而不是TD誤差
這意味著演演算法可以避免重複取樣agent無法學習的點,並且可以專注於最小化可學習點的誤差,從而提高樣本效率
為了確定樣本的學習能力,我們需要了解樣本的目標是如何表現的,以及它是如何隨時間變化的。
強化學習中的訓練資料是由變化的策略生成的。因此,holdout model需要不時地更新。
因此,在基於Q學習的強化學習方法中,hold-out模型的一個很好的代理是Eq. 8中Bellman更新中使用的目標網路:
由於目標網路僅使用線上模型引數定期更新,因此它保留了代理在使用過時策略訓練的舊資料上的效能。目標網路可以很容易地用作 沒有在新樣本上訓練的hold-out model 的近似值。
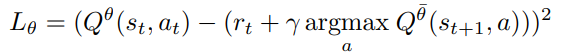
因此,我們將RL的可還原損失(ReLo)定義為資料點相對於線上網路(引數θ)和相對於目標網路(引數¯θ)的損失之差。
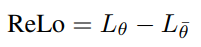
- 與PER相比相似之處,優先順序方案在低優先順序點的取樣行為上
對於PER:不重要的資料點具有較低的Lθ,在ReLo中也將保持不重要。
因為如果Lθ很低,那麼根據上述公式,ReLo也會很低。
這確保了我們保留了PER的理想行為,即不重複取樣已經學習過的點- 不同之處在於存在較大的TD誤差的取樣點:
對於PER,如果由於轉換本身的固有噪聲,一個資料點可能具有很高的TD誤差,即使在取樣多次之後仍然保持很高,但它仍然具有較高的PER優先順序。
但是它的優先順序應該降低,因為可能有其他資料點更值得取樣,因為它們有有用的資訊,可以更快地學習。
對於ReLo:這樣一個點會很低,因為Lθ和Lθ¯都很高
如果一個資料點被遺忘,那麼Lθ將高於Lθ¯,並且ReLo將確保這些點被重新存取。
4.1 Implementation
我們應該為ReLo error建立一個對映fmap,它對所有值都是單調遞增且非負的
當目標網路與主網路通過硬更新進行更新時,該值可以歸零。然而,在一次更新之後,它很快變成非零
在實踐中,我們發現將負值裁剪為零通過新增一個小引數來確保樣本有最小概率:
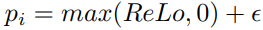
- 由於不需要任何額外的訓練,ReLo在計算上並不昂貴。它只涉及通過目標網路的狀態的一個額外的前向傳遞
對於ReLo,唯一需要計算的附加項: Qtgt(st, at)計算Lθ¯。- ReLo也沒有引入任何額外的超引數
- ReLo不一定依賴於確切的損失公式;只需要額外計算關於目標網路引數¯θ的Lalg。
如果損失只是均方誤差,那麼ReLo可以被簡化,可以用Qθ和Qθ¯的差來表示。
但對非策略Q學習方法的其他擴充套件修改了這一目標,例如分散式學習Bellemare等人[2017]最小化KL散度,但不能以相同的方式簡化兩個KL散度之間的差異。
為了使ReLo成為一種可以跨這些方法使用的通用技術,我們用Lθ和Lθ¯來定義它。
Algorithm 1
