NodeJs 實踐之他說
NodeJs 實踐之他說
作為前端,我們知道 node 在構建方面是成功的,我們也聽說過全棧,那麼 node 是否能應用在企業級的後端?一起來看一下騰訊視訊的 NodeJs 改造。
Tip: 故事大概是 2018 年,主角楊浩,來源於:

背景
騰訊視訊是一個內容型的網頁。
在 2014 年以前使用的是 C++ 動態生成頁面。有兩個問題:
- 前端不太會維護 C++ 的那套東西
- C++ 定時生成網頁。有多少個視訊,它就會生成多少個網頁,然後推播到對應的伺服器中。如果更改了某個視訊的資訊,得等到下次生成網頁才會更新
於是打算使用 NodeJs 來對其進行改造。
第一隻怪 - 打通 NodeJs
由於騰訊視訊是內容型的網頁,當時有 30% 的流量來自搜尋引擎,所以需要更好的 SEO,於是選用 SSR(伺服器渲染)。
Tip: Vue_SSR中也提到伺服器端渲染的優勢:更快的首屏載入、更好的 SEO
NodeJs 扮演的角色如下:
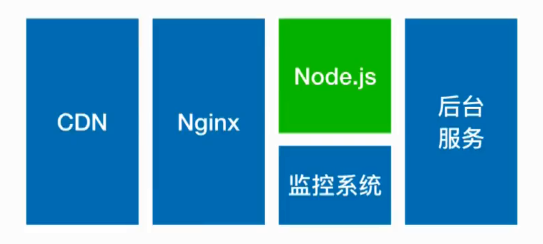
請求經過 cdn,經過 nginx 通過負載均衡存取 NodeJs 服務,NodeJs 從各個後臺服務拉取資料,渲染好了在返回給前端。
Tip:相當於以前用 c++ 生成頁面,現在由 NodeJs 生成頁面。
打通 RPC 呼叫
rpc(作用類似 http 協定) 就是遠端資源呼叫,因為 node 需要從各個後臺服務拉取資料。這裡涉及4個方面的事情:
負載均衡。node 和後臺服務之間有一層負載均衡,用的是一種類DNS負載均衡,所以得和負載均衡服務互動,拿到每次需要存取伺服器的ipMongo/mysql/redis(redis - 基於鍵值對的記憶體資料庫) 儲存的打通。比較簡單,就是對應 npm 包的使用後臺私有協定。例如二進位制的協定某場景下比http協定好一些- 監控系統/紀錄檔系統
Tip: DNS除了能解析域名之外還具有負載均衡的功能
高並行下程序管理
node 是單執行緒,使用 cluster 模組建立多個 Nodejs 程序,實現高並行和高可用性。但 cluster 還有點缺陷,做了以下幾點優化:
心跳- master 定時給 cluster 發資訊,如果有回覆說明它還活著,否則就是僵死,就 kill 它記憶體檢測- 監控 cluster 記憶體,如果記憶體過高,可能就是記憶體漏失,也殺死它重啟- cluster kill 後,有的應用可能不能用,就需要將其重啟
Tip:在 Node.js 中,cluster 模組提供了一種簡單的方式來建立多個 Node.js 程序,以實現高並行和高可用性。通過叢集模組,開發者可以使用現有的單執行緒程式程式碼,並將其自動拆分到多個子程序中執行,從而充分利用 CPU 和記憶體資源,提高應用的效率和穩定性。
第二隻怪 - 維護 NodeJs
終於把 Node 打通了,現在可以用 node 寫點東西了。
要用 node 寫一個穩定的服務,也不是那麼簡單。node 很容易掛掉,比如一點語法問題。
Node 人員不足
懂前端的人很多,但懂 node 的就相對要少。寫後端需要懂後端那套東西,要會伺服器調優,還要懂運維。
為了解決 Node 人員不足,決定使用框架來平滑 node 曲線。
之前要用 node 寫專案難度大,是因為需要經歷這4步:業務邏輯 -> 會寫 NodeJs -> 熟悉 rpc 呼叫 -> 熟悉運維(效能調優)
現在用框架,只需要寫業務邏輯就能開幹。
這裡框架主要使用設定化,遮蔽底層複雜的實現,對外暴露友好的設定。就像 webpack,讓前端構建生態非常繁榮。
要做設定化,就得分析 ssr 本質:從各個後臺領取資料,簡單處理後進行渲染。
ssr抽象表示:請求引數 -> 後端資料 + 模板 -> 頁面文字
ssr 公式:內容=f(資料來源,模板)
只要將資料來源和模板設定化,就可以通過一個函數解決 ssr 的問題。
模板引擎的選型
研究瞭如下幾種模板:
- art-template 國內有名的開源模板引擎
- es6 template string + vm.runInNewContext(編譯和執行程式碼,作用類似 new Function('console.log("1")'))
- vue ssr、react ssr
art-template 中的 forEach 可以使用預編譯語法來實現,由於互動較少,所以無需使用 vue和react。而且 es6 模板速度測試比 vue-server-render 快很多。
所以最終選取第二種方案:es6 template。
資料來源
資料來源的設定用如下一個 json 表示:
module.exports = {
video: {
url: "http://...."
},
vidviewcount: {
dependencies: ['video'],
url: "protobuf://union.video.qq.com/...."
},
rank: {
url: "redis://admin:admin@135246:65535/get?key=haha"
}
}
這個 json 表示 ssr 過程中資料獲取邏輯,其中 vidviewcount 通過 dependencies 欄位指明依賴 video。
這裡用 http、protobuf、redis三種協定(方式)獲取資料。一個協定對應一個請求器,不在框架中的協定可以註冊即可。就像這樣:
factory.registerRequestor('http', requestor);
function requestor(){
...
}
為了增加設定的靈活性,這裡增加了幾個 hook:
{
...
fixBefore: function(param){
// 檢測引數合法性
return param
},
fixAfter: function(data){
// 檢測返回資料合法性
if(!data.vid){
throw Error('xxx')
}
return data
},
onError: function(e){
return err;
}
}
寫設定就是寫 SSR 邏輯
只要學會寫設定就能搞定 ssr 邏輯。
公式:內容=f(資料來源,模板)(引數)
ssr 外部用 koa(nodejs 的web框架) 封裝一下就是一個服務:
let app = koa()
let ssr = pigfarm(data, template)
app.use(async ctx => {
ctx.body = await ssr(ctx.query)
})
第三隻怪 - 搶後端飯碗的問題
後臺有後臺擅長的地方(邏輯、計算密集),前端有前端擅長的地方(前端網頁優化)。
尋找一個合作共贏的方式。這裡做了如下幾個有特色的前端服務:
熱更新
每次業務邏輯的改動需要經歷長時間的釋出和重啟
前面已經將資料來源和模板做到了設定化,現在修改邏輯,只需要更改資料庫中的資料來源和模板即可,做到熱更新。
首頁調優
v.qq.com 首頁包含27個模組
- 富含個性化內容,無法快取
- 頁面龐大,速度慢
- 全網頁超過40個rpc
- 個性化介面呼叫慢
利用 transfer-encoding:chunked 快速返回首屏資料,後面再載入2、3、4...屏的資料
Tip:BigPipe 是一個前端效能優化技術,採用分塊渲染的方式。transfer-encoding:chunked 是一種 HTTP協定中定義的傳輸編碼方式之一。執行伺服器在不知道響應體大小的情況下,將響應分成若干個固定大小的快進行傳輸。
容災
前端容災是指在前端應用中,為了保障可靠性和穩定性而採用的一系列技術和策略,以確保即使在系統出現部分異常或錯誤的情況下,仍然可以正常提供服務。比如網路問題、伺服器故障等
這裡可以做整頁備份。
js 中用高階函數非常容易實現快取。請看範例:
function memoize(func) {
// 用於快取
const cache = {};
return function(...args) {
const key = JSON.stringify(args);
// 如果快取中有值,直接返回
if (cache[key]) {
return cache[key];
}
const result = func.apply(this, args);
cache[key] = result;
return result;
};
}
出處:https://www.cnblogs.com/pengjiali/p/17409232.html
本文版權歸作者和部落格園共有,歡迎轉載,但未經作者同意必須保留此段宣告,且在文章頁面明顯位置給出原文連線。