多執行緒基礎知識點梳理
基礎概念
- 程序(process):程序是計算機中的一個任務,比如開啟瀏覽器、IntelliJ IDEA。
- 執行緒(thread):程序內部有多個子任務,叫執行緒。比如IDEA在敲程式碼的同時還能自動儲存、自動導包,都是子執行緒做的。
程序和執行緒的關係就是一個程序包含一個或多個執行緒。
執行緒是作業系統排程的最小任務單位。執行緒自己不能決定什麼時候執行,由作業系統決定什麼時候排程。因此多執行緒程式設計中,程式碼的先後順序不代表程式碼的執行順序。
多執行緒有什麼好處?
- 提高應用程式的效能。非同步程式設計讓程式更快的響應。
- 提高CPU利用率。一個執行緒阻塞,另一個執行緒繼續執行,充分利用CPU。
同時多執行緒也會帶來安全問題,比如多個執行緒讀寫一個共用變數,會出現資料不一致的問題。
什麼時候考慮用多執行緒?
- 高並行。系統在同一時間要處理多個任務時,需要用多執行緒。
- 很耗時的操作。如檔案讀寫,非同步執行不讓程序阻塞。
- 不影響方法主流程邏輯,但又影響介面效能的操作,如資料同步,使用非同步方式能提高介面效能。
建立執行緒的方式
多執行緒的建立方法基本有四種:
- 繼承
Thread類 - 實現
Runnalble介面 - 實現
Callable介面 - 執行緒池
1.繼承Thread類
public class ThreadTest extends Thread {
@Override
public void run() {
System.out.println("新執行緒開始...");
}
public static void main(String[] args) {
ThreadTest t = new ThreadTest();
t.start();
System.out.println("main執行緒結束...");
}
}
main執行緒結束...
新執行緒開始...
啟動一個新執行緒總是呼叫它的start()方法,而不是run()方法;ThreadTest子執行緒啟動後,它跟main就開始同時執行了,誰先執行誰後執行由作業系統排程。所以多執行緒程式碼的執行順序跟程式碼順序無關。
2.實現Runnable介面
實現Runnable介面,重寫run()方法,作為構造器引數傳給Thread,呼叫start()方法啟動執行緒。
public class Test {
public static void main(String[] args) {
RunnableThread r = new RunnableThread();
new Thread(r).start();
new Thread(r).start();
}
}
class RunnableThread implements Runnable {
@Override
public void run() {
System.out.println("新執行緒開始...");
}
}
一般推薦使用實現Runnable的方式來建立新執行緒,它的優點有:
- Java中只有單繼承,介面則可以多實現。如果一個類已經有父類別,它就不能再繼承
Thread類了,繼承了Thread類就不能再繼承其他類,有侷限性。實現Runnable介面則沒有侷限性。 - 實現
Runnable介面的類具有共用資料的特性,它可以同時作為多個執行緒的執行單位(target),此時多個執行緒操作的是同一個物件的run方法,這個物件所有變數在這幾個執行緒間是共用的。而繼承Thread的方式做不到,比如A extends Thread,每次啟動執行緒都是new A().start(),每次的A物件都不同。
3. 實現Callable介面
Callable區別於Runnable介面的點在於,Callable的方法有返回值,還能丟擲異常。
public interface Callable<V> {
V call() throws Exception;
}
Callable的用法:
- 配合
FutureTask一起使用,FutureTask是RunnableFuture介面的典型實現,RunnableFuture介面從名字來看,它同時具有Runnable和Future介面的的能力。FutureTask提供2個構造器,同時支援Callable方式和Runnable方式的任務。FutureTask可作為任務傳給Thread的構造器。 - 使用執行緒池時,呼叫
ExecutorService#submit方法,返回一個Future物件。 Future物件的get()方法能返回非同步執行的結果。呼叫get()方法時,如果非同步任務已經完成,就直接返回結果。如果非同步任務還沒完成,那麼get()方法會阻塞,一直等待任務完成才返回結果,這一點也是FutureTask的缺點。
Callable和FutureTask一起使用的例子:
public class CallableTest {
public static void main(String[] args) {
// 建立Callable介面實現類的物件
CallableThread sumThread = new CallableThread();
// 建立FutureTask物件
FutureTask<Integer> futureTask = new FutureTask<>(sumThread);
// 將FutureTask的物件作為引數傳遞到Thread類的構造器中,建立Thread物件,並呼叫start()
new Thread(futureTask).start();
try {
// 獲取Callable中call方法的返回值
Integer sum = futureTask.get();
System.out.println("總和為" + sum);
} catch (InterruptedException | ExecutionException e) {
e.printStackTrace();
}
System.out.println("main執行緒結束");
}
}
class CallableThread implements Callable<Integer> {
@Override
public Integer call() throws Exception {
int sum = 0;
for (int i = 1; i <= 100; i++) {
sum += i;
}
Thread.sleep(2000); // 等待2s驗證futureTask.get()是否等待
return sum;
}
}
總和為5050
main執行緒結束
在JDK原始碼中可看到get()方法執行時,會判斷執行緒狀態如果是未完成,會進入一個無限迴圈,直到任務完成才返回執行結果。
public V get() throws InterruptedException, ExecutionException {
int s = state;
if (s <= COMPLETING) // 如果未完成,則等待完成
s = awaitDone(false, 0L);
return report(s);
}
private int awaitDone(boolean timed, long nanos) throws InterruptedException {
// ...
for (; ; ) { // 無線迴圈,直到任務完成
// ...
int s = state;
if (s > COMPLETING) {
if (q != null)
q.thread = null;
return s;
}
// ...
}
}
Future和FutureTask
使用Callable介面前,需要了解Future和FutureTask。
在Java並行程式設計中,Future介面代表著非同步計算結果。它定義的方法有:
get():獲取結果,任務未完成前會一直等待,直到完成;get(long timeout, TimeUnit unit):獲取結果,但只等待指定的時間;新增超時時間可以讓呼叫執行緒及時釋放,不會死等;cancel(boolean mayInterruptIfRunning):取消當前任務;mayInterruptIfRunning的作用是,如果任務在執行中,這時取消任務,如果mayInterruptIfRunning為true就中斷,否則不中斷。isCancelled():任務在執行完成前被取消,返回true,否則返回false;isDone():判斷任務是否已完成。任務完成包括:正常完成、丟擲異常而完成、任務被取消。
FutureTask作為Future的實現類,也有侷限性。比如get()方法會阻塞呼叫執行緒;不能將多個非同步計算結果合併到一起等等,針對這些侷限,Java8提供了CompletableFuture。
4.執行緒池
下面我將圍繞這幾個問題,來討論一下執行緒池。
- 執行緒池是什麼?
- 為什麼使用執行緒池,或者說使用執行緒池的好處是什麼?
- 執行緒池怎麼使用?
- 執行緒池的原理是什麼,它怎麼做到重複利用執行緒的?
執行緒池是什麼
執行緒池(Thread Pool)是一種基於池化思想的管理執行緒的工具,它內部維護了多個執行緒,目的是能重複利用執行緒,控制並行量,降低執行緒建立及銷燬的資源消耗,提升程式穩定性。
為什麼使用執行緒池
使用執行緒池的好處:
- 降低資源消耗:重複利用已建立的執行緒,降低執行緒建立和銷燬造成的損耗。
- 提高響應速度:任務到達時,無需等待執行緒建立即可立即執行。
- 提高執行緒的可管理性:執行緒是稀缺資源,如果無限制建立,不僅會消耗系統資源,還會因為執行緒的不合理分佈導致資源排程失衡,降低系統的穩定性。使用執行緒池可以進行統一的分配、調優和監控。
執行緒池解決的核心問題就是資源管理問題,在並行場景下,系統不能夠確定在任意時刻,有多少任務需要執行,有多少資源需要投入。這種不確定性將帶來以下若干問題:
- 頻繁申請/銷燬資源和排程資源,將帶來額外的消耗,可能非常巨大。
- 對資源無限申請缺少抑制手段,易引發系統資源耗盡的風險。
- 系統無法合理管理內部的資源分佈,會降低系統的穩定性。
執行緒池這種基於池化思想的技術就是為了解決這類問題。
執行緒池怎麼使用
執行緒池的的核心實現類是ThreadPoolExecutor,呼叫execute或者submit方法即可開啟一個子任務。
public class ThreadPoolTest {
private static ThreadPoolExecutor poolExecutor =
new ThreadPoolExecutor(1, 1, 5, TimeUnit.SECONDS, new LinkedBlockingQueue<>(1));
public static void main(String[] args) throws ExecutionException, InterruptedException {
Runnable runnableTask = () -> System.out.println("runnable task end");
poolExecutor.execute(runnableTask);
Callable<String> callableTask = () -> "callable task end";
Future<String> future = poolExecutor.submit(callableTask);
System.out.println(future.get());
}
}
ThreadPoolExecutor的核心構造器有7個引數,我們來分析一下每個引數的含義:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
// 省略...
}
corePoolSize:執行緒池的核心執行緒數。執行緒池中的執行緒數小於corePoolSize時,直接建立新的執行緒來執行任務。workQueue:阻塞佇列。當執行緒池中的執行緒數超過corePoolSize,新任務會被放到佇列中,等待執行。maximumPoolSize:執行緒池的最大執行緒數量。keepAliveTime:非核心執行緒空閒時的存活時間。非核心執行緒即workQueue滿了之後,再提交任務時建立的執行緒。非核心執行緒如果空閒了,超過keepAliveTime後會被回收。unit:keepAliveTime的時間單位。threadFactory:建立執行緒的工廠。預設的執行緒工廠會把提交的任務包裝成一個新的任務。handler:拒絕策略。當執行緒池的workQueue已滿且執行緒數達到最大執行緒數時,新提交的任務執行對應的拒絕策略。
JDK也提供了一個快速建立執行緒池的工具類Executors,它提供了多種建立執行緒池的方法,但通常不建議使用Executors來建立執行緒池,因為它提供的很多工具方法,要麼使用的阻塞佇列沒有設定邊界,要麼是沒有設定最大執行緒的上限。任務一多容易發生OOM。實際開發應該根據業務自定義執行緒池。
執行緒池的原理
execute
執行緒池的核心執行機制在於execute方法,所有的任務排程都是通過execute方法完成的。
public void execute(Runnable command) {
// ...
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) { // (1)
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) { // (2)
int recheck = ctl.get();
// 重新檢查狀態,如果是非執行狀態,接著執行佇列刪除操作,然後執行拒絕策略
if (! isRunning(recheck) && remove(command))
reject(command);
// 如果是因為remove(command)刪除佇列元素失敗,再判斷池中執行緒數量
// 如果池中執行緒數為0則新增一個任務為null的非核心執行緒
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false)) // (3)
reject(command);
}
透過execute方法的3個if判斷,可以把它的邏輯梳理為3個部分:
- 第一個
if:如果執行緒數量小於核心執行緒數,則建立一個執行緒來執行新提交的任務。 - 第二個
if:如果執行緒數量大於等於核心執行緒數,則將任務新增到該阻塞佇列中。 else if:執行緒池狀態不對,或者新增到佇列失敗即佇列滿了,則建立一個非核心執行緒執行新提交的任務。如果非核心執行緒建立失敗就執行拒絕策略。
addWorker
execute中的核心邏輯要看addWoker方法,它承擔了核心執行緒和非核心執行緒的建立。addWorker方法前半部分程式碼用一個雙重for迴圈確保執行緒池狀態正確,後半部分的邏輯是建立一個執行緒物件Worker,開啟新執行緒執行任務的過程。
Worker是對提交進來的執行緒的封裝,建立的worker會被新增到一個HashSet,執行緒池中的執行緒都維護在這個名為workers的HashSet中並被執行緒池所管理。
前面說到,Worker本身也是一個執行緒物件,它實現了Runnable介面,在addWorker中會啟動一個新的任務,所以我們要看它的run方法,而run方法的核心邏輯是runWorker方法。
final void runWorker(Worker w) {
// ...
try {
while (task != null || (task = getTask()) != null) {
// ...
try {
try {
task.run(); // 執行普通的run方法
} finally {
task = null; // task置空
}
}
}
} finally {
processWorkerExit(w, completedAbruptly); // 回收空閒執行緒
}
}
可以看到runWorker方法中有一個while迴圈,迴圈執行task的run方法,這裡的task就是提交到執行緒池的任務,它對當成了普通的物件,執行完task.run(),最後會把task設定為null。
再看回圈的條件,已知task是有可能為空的,所以我們再看看(task = getTask()) != null這個條件,如果getTask() == null則跳出迴圈執行processWorkerExit方法,processWorkerExit方法的作用是回收空閒執行緒。
getTask
很多答案都在getTask()方法中。
private Runnable getTask() {
boolean timedOut = false; // Did the last poll() time out?
for (; ; ) { // (1)
// 校驗執行緒池狀態的程式碼,先省略...
int wc = workerCountOf(c);
// Are workers subject to culling?
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize; // (2)
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c)) // 執行緒數減1
return null; // 這裡時中斷外層while迴圈的時機
continue;
}
try {
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take(); // (3)
if (r != null)
return r; // 取到值了就在外層的while迴圈中執行任務
timedOut = true; // 否則就標記為獲取佇列任務超時
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
結合(1)、(3)這兩個地方可以看出,getTask()方法是一個無限迴圈,不斷從阻塞佇列中取任務,取到了任務就返回,到外層runWorker方法中,執行這個任務的run方法,即執行緒池通過啟動一個Worker子執行緒來執行提交進來的任務,並且一個Worker執行緒會執行多個任務!
我們再看看getTask()何時返回null,因為返回null才可以看下一步的processWorkerExit方法。
getTask()返回null主要看timed && timedOut這個條件。變數值timed為true的條件是:允許核心執行緒超時或者執行緒數大於核心執行緒數。timedOut變數為true的條件是從workQueue為空了,取不到任務了,但是這個前提是timed == true,執行workQueue.poll的時候,因為workQueue.poll方法獲取任務最多等待keepAliveTime的時間,超過這個時間獲取不到就返回null,而workQueue.take()方法獲取不到任務會一直等待!
因此,在核心執行緒不會超時的情況下,如果池中的執行緒數小於核心執行緒數,這個getTask()會一直迴圈下去,這就是在這種情況下執行緒池不會自動關閉的原因!反之,在核心執行緒不會超時的情況下,如果池中的執行緒數超過核心執行緒數,才會對多餘的執行緒回收。如果allowCoreThreadTimeOut == true,即核心執行緒也能超時,當阻塞佇列為空,所有Worker執行緒都會被回收。
ThreadPoolExecutor的註釋說,當池中沒有剩餘執行緒,執行緒池會自動關閉。
A pool that is no longer referenced in a program AND has no remaining threads will be shutdown automatically
但我也沒找到證據,沒看到哪裡顯式呼叫shutdown(),但確實會自動關閉。
processWorkerExit
getTask()獲取不到任務後,會執行processWorkerExit方法回收執行緒。在這裡,Worker執行緒集合隨機刪除一個執行緒物件,然後再隨機中斷一個workers中的執行緒。可見執行緒銷燬執行緒的方式時刪除執行緒參照,讓JVM自動回收。
private void processWorkerExit(Worker w, boolean completedAbruptly) {
// ...
try {
workers.remove(w);
}
// 呼叫interrupt()方法中斷執行緒,一次中斷一個
tryTerminate();
// ...
}
執行緒池原理總結
最後我們回到最初的問題,執行緒池的原理是什麼,執行緒池怎麼做到重複利用執行緒的?
執行緒池通過維護一組叫Worker的執行緒物件來處理任務。線上程數不超過核心執行緒數的情況下,一個任務對應一個Worker執行緒,超過核心執行緒數,新的任務會提交到阻塞佇列。一個Worker執行緒在啟動後,除了執行第一次任務之外,還會不斷向阻塞佇列中消費任務。如果佇列裡沒任務了,Worker執行緒會一直輪詢,不會退出;只有在池中執行緒數超過核心執行緒數時才退出輪詢,然後回收多餘的空閒執行緒。即一個Worker執行緒會處理多個任務,且Worker執行緒受執行緒池管理,不會隨意回收。
執行緒池的拒絕策略
拒絕策略的目的是保護執行緒池,避免無節制新增任務。JDK使用RejectedExecutionHandler介面代表拒絕策略,並提供了4個實現類。執行緒池的預設拒絕策略是AbortPolicy,丟棄任務並丟擲異常。實際開發中使用者可以通過實現這個介面去客製化拒絕策略。

執行緒的狀態
New:新建立的執行緒,尚未執行;Runnable:執行中的執行緒,正在執行run()方法的Java程式碼;Blocked:執行中的執行緒,因為某些操作被阻塞而掛起;Waiting:執行中的執行緒,因為某些操作在等待中;Timed Waiting:執行中的執行緒,因為執行sleep()方法正在計時等待;Terminated:執行緒已終止,因為run()方法執行完畢。
當執行緒啟動後,它可以在Runnable、Blocked、Waiting和Timed Waiting這幾個狀態之間切換,直到最後變成Terminated狀態,執行緒終止。
執行緒終止的原因有:
- 執行緒正常終止:
run()方法執行到return語句返回; - 執行緒意外終止:
run()方法因為未捕獲的異常導致執行緒終止; - 對某個執行緒的
Thread範例呼叫stop()方法強制終止(過時方法,不推薦使用)。
Thread類的常用方法
start():啟動當前執行緒currentThread():返回當前程式碼執行的執行緒yield(): 釋放當前CPU的執行權join():join()方法可以讓其他執行緒等待,直到自己執行完了,其他執行緒才繼續執行。setDaemon(boolean on):設定守護執行緒,也叫後臺執行緒。JVM退出時,不必關心守護執行緒是否已結束。interrupt():中斷執行緒。sleep(long millis):讓執行緒睡眠指定的毫秒數,在指定時間內,執行緒是阻塞狀態isAlive():判斷當前執行緒是否存活。
public class ThreadJoinTest {
public static void main(String[] args) throws InterruptedException {
Thread t = new Thread(() -> {
System.out.println("hello");
});
System.out.println("start");
t.start();
t.join();
System.out.println("end");
}
}
start
hello
end
volatile
執行緒間共用變數需要使用volatile關鍵字標記,確保每個執行緒都能讀取到更新後的變數值。
為什麼要對執行緒間共用的變數用關鍵字volatile宣告?這涉及到Java的記憶體模型(JMM)。
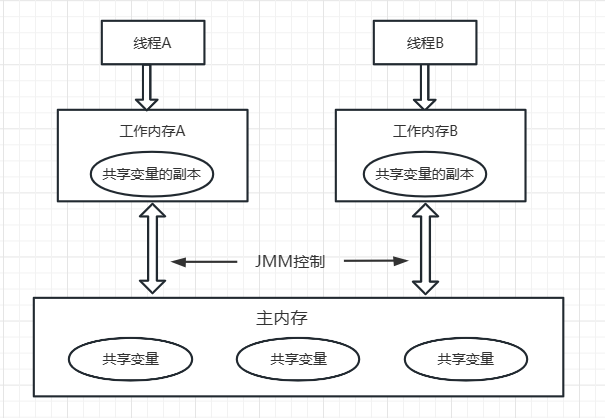
類變數、範例變數是共用變數,方法區域性變數是私有變數。共用變數的值儲存在主記憶體中,每個執行緒都有自己的工作記憶體,私有變數就儲存在工作記憶體。
在Java虛擬機器器中,共用變數的值儲存在主記憶體中,但是,當執行緒存取變數時,它會先獲取一個副本,並儲存在自己的工作記憶體中。如果執行緒修改了變數的值,虛擬機器器會在某個時刻把修改後的值回寫到主記憶體,但是,這個時間是不確定的!
這會導致如果一個執行緒更新了某個變數,另一個執行緒讀取的值可能還是更新前的。例如,主記憶體的變數a = true,執行緒1執行a = false時,它在此刻僅僅是把變數a的副本變成了false,主記憶體的變數a還是true,在JVM把修改後的a回寫到主記憶體之前,其他執行緒讀取到的a的值仍然是true,這就造成了多執行緒之間共用的變數不一致。
因此,volatile關鍵字的目的是告訴虛擬機器器:
- 每次存取變數時,總是獲取主記憶體的最新值;
- 每次修改變數後,立刻回寫到主記憶體。
volatile關鍵字解決的是可見性問題:當一個執行緒修改了某個共用變數的值,其他執行緒能夠立刻看到修改後的值。
但是volatile不能保證原子性,原子性問題需要根據實際情況做同步處理。
執行緒同步
什麼叫執行緒同步?對於多執行緒的程式來說,同步指的是在一定的時間內只允許某一個執行緒存取某個資源。
在Java中,最常見的方法是用synchronized關鍵字實現同步效果。
synchronized
synchronized可以修飾實體方法、靜態方法、程式碼塊。
synchronized的底層是使用作業系統的互斥鎖(mutex lock)實現的,它的特點是保證記憶體可見性、操作原子性。
- 記憶體可見性:可見性的原理還要回到Java記憶體模型(上面JMM的那張圖)。 synchronized上鎖時,會清空工作記憶體中變數的值,去主記憶體中獲取該變數的值;解鎖時,會把工作記憶體中變數的值同步回主記憶體中。
- 操作原子性:持有同一個鎖的兩個同步塊只能序列地執行。
使用synchronized解決了多執行緒同步存取共用變數的正確性問題。但是,它的缺點是帶來了效能下降。因為synchronized程式碼塊無法並行執行。此外,加鎖和解鎖需要消耗一定的時間,所以,synchronized會降低程式的執行效率。
不需要synchronized的操作
JVM規範定義了幾種原子操作:
- 基本型別(
long和double除外)賦值,例如:int n = 1; - 參照型別賦值,例如:
List list = anotherList。
long和double是64位元(8位元組)資料,在32位元和64位元作業系統上是不一樣的。JVM沒有明確規定64位元賦值操作是不是一個原子操作,不過在x64平臺的JVM是把long和double的賦值作為原子操作實現的。
本文來自部落格園,作者:xfcoding,轉載請註明原文連結:https://www.cnblogs.com/cloudrich/p/17407804.html