8張圖帶你全面瞭解kafka的核心機制
前言
kafka是目前企業中很常用的訊息佇列產品,可以用於削峰、解耦、非同步通訊。特別是在巨量資料領域中應用尤為廣泛,主要得益於它的高吞吐量、低延遲,在我們公司的解決方案中也有用到。既然kafka在企業中如此重要,那麼本文就通過幾張圖帶大家全面認識一下kafka,現在我們不妨帶入kafka設計者的角度去思考該如何設計,它的架構是怎麼樣的、都有哪些元件組成、如何進行擴充套件等等。
kafka基礎架構
現在假如有100T大小的訊息要傳送到kafka中,資料量非常大,一臺機器儲存不下,面對這種情況,你該如何設計呢?
很簡單,分而治之,一臺不夠,那就多臺,這就形成了一個kafka叢集。如下圖所示,一個broker就是一個kafka節點,100T資料就有3個節點分擔,每個節點約33T,這樣就能解決問題了,還能提高吞吐量。
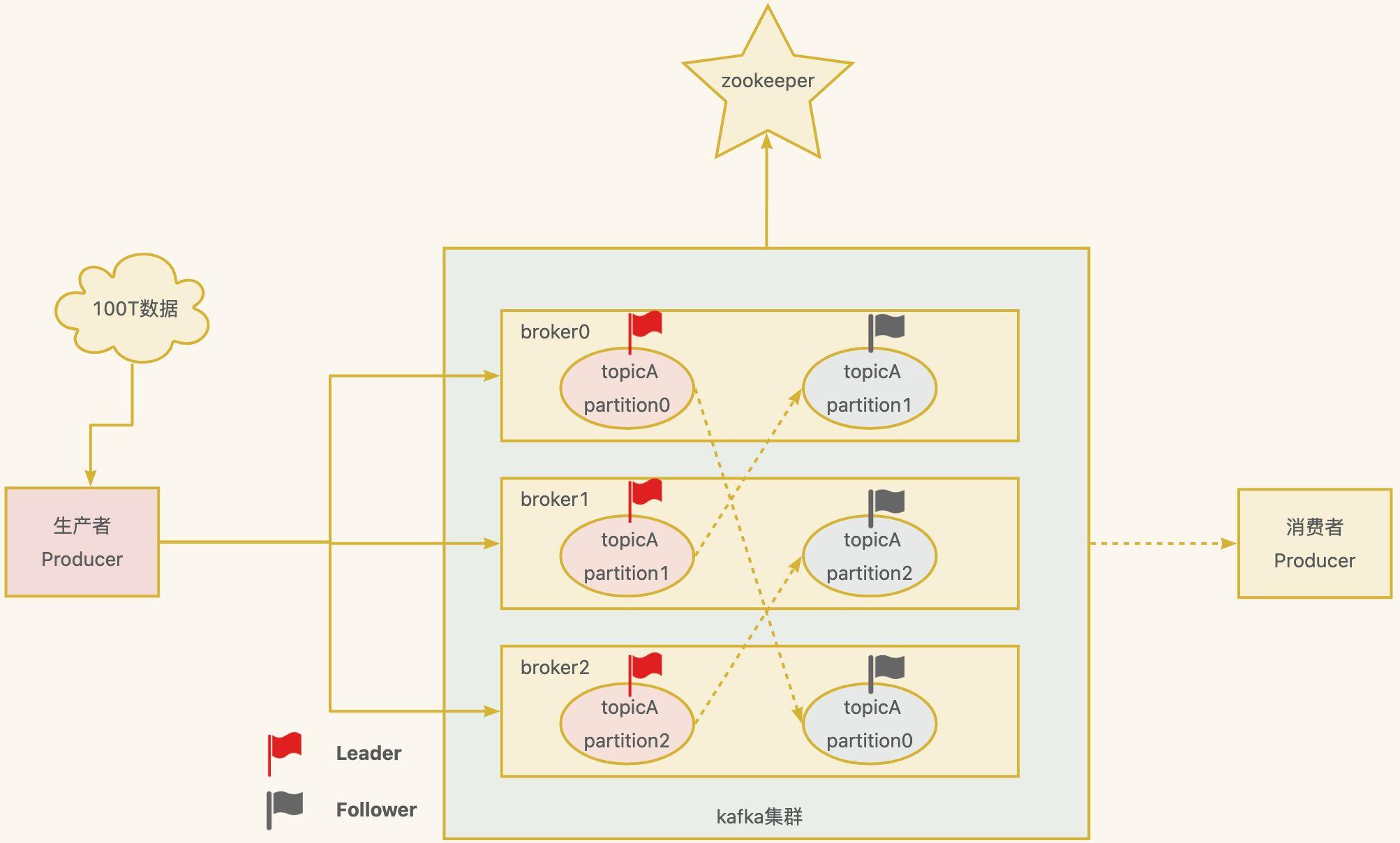
- Topic: 可以理解為一個佇列,一個kafka叢集中可以定義很多的topic,比如上圖中的
topicA。 - Partition: 為了實現擴充套件性,提高吞吐量,一個非常大的
topic可以分佈到多個broker(即伺服器)上,一個topic可以分為多個partition,每個partition是一個有序的佇列。比如上圖中的topicA被分成了3個partition。 - Replica: 副本,如果資料只放在一個
broker中,萬一這個broker宕機了怎麼辦?為了實現高可用,一個topic的每個分割區都有若干個副本,一個Leader和若干個Follower。比如上圖中的虛線連線的就是它的副本。 - Leader: 每個分割區多個副本的「主」,生產者傳送資料的物件,以及消費者消費資料的物件都是
Leader。 - Follower: 每個分割區多個副本中的「從」,實時從
Leader中同步資料,保持和Leader資料的同步。Leader發生故障時,某個Follower會成為新的Leader。 - Producer: 訊息生產者,就是向
Kafka broker發訊息的使用者端,後面詳細講解。 - Consumer: 訊息消費者,向
Kafka broker取訊息的使用者端,多個Consumer會組成一個消費者組,後面詳細講解。 - Zookeeper:用來記錄kafka中的一些後設資料,比如kafka叢集中的broker,leader是誰等等,但
Kafka2.8.0版本以後也支援非zk的方式,大大減少了和zk的互動。
kafka生產者流程
前面通過一張圖片講解了kafka整體的架構,那現在我們來看看kafka生產者傳送的整個過程,這裡面也是大有文章。
在訊息傳送的過程中,涉及到了兩個執行緒——main 執行緒和 Sender 執行緒。在 main 執行緒中建立了一個雙端佇列 RecordAccumulator。main 執行緒將訊息傳送給 RecordAccumulator,Sender 執行緒不斷從 RecordAccumulator 中拉取訊息傳送到 Kafka Broker。
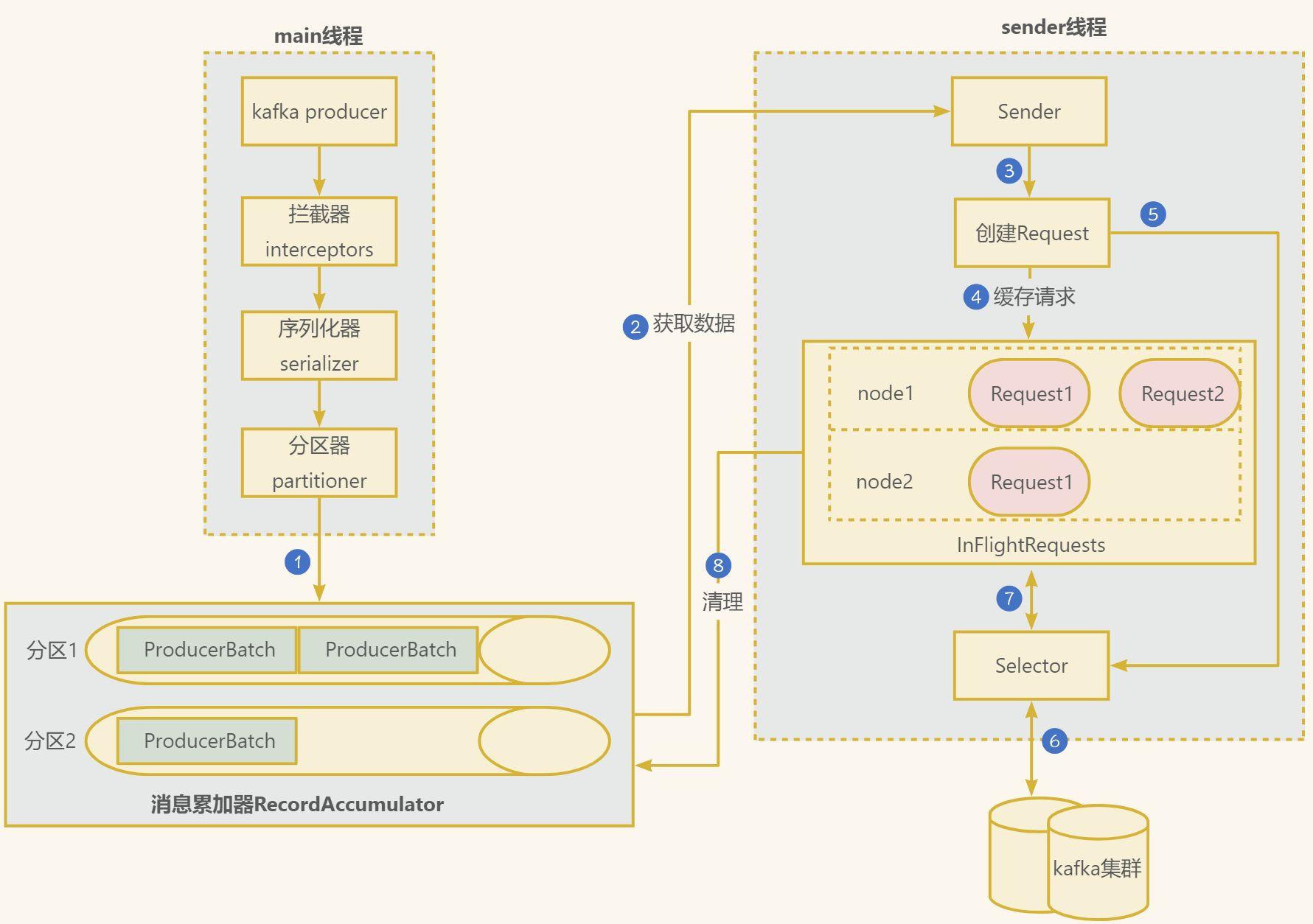
- 在主執行緒中由
kafkaProducer建立訊息,然後通過可能的攔截器、序列化器和分割區器的作用之後快取到訊息累加器(RecordAccumulator, 也稱為訊息收集器)中。
- 攔截器: 可以用來在訊息傳送前做一些準備工作,比如按照某個規則過濾不符合要求的訊息、修改訊息的內容等,也可以用來在傳送回撥邏輯前做一些客製化化的需求,比如統計類工作。
- 序列化器: 用於在網路傳輸中將資料序列化為位元組流進行傳輸,保證資料不會丟失。
- 分割區器: 用於按照一定的規則將資料分發到不同的kafka broker節點中
Sender執行緒負責從RecordAccumulator獲取訊息並將其傳送到Kafka中。
RecordAccumulator主要用來快取訊息以便Sender執行緒可以批次傳送,進而減少網路傳輸的資源消耗以提升效能。
RecordAccumulator快取的大小可以通過生產者使用者端引數buffer.memory設定,預設值為33554432B,即32M。
- 主執行緒中傳送過來的訊息都會被迫加到
RecordAccumulator的某個雙端佇列(Deque)中,RecordAccumulator內部為每個分割區都維護了一個雙端佇列,即Deque<ProducerBatch>, 訊息寫入快取時,追加到雙端佇列的尾部。 Sender讀取訊息時,從雙端佇列的頭部讀取。ProducerBatch是指一個訊息批次;與此同時,會將較小的ProducerBatch湊成一個較大ProducerBatch,也可以減少網路請求的次數以提升整體的吞吐量。ProducerBatch大小可以通過batch.size控制,預設16kb。Sender執行緒會在有資料積累到batch.size,預設16kb,或者如果資料遲遲未達到batch.size,Sender執行緒等待linger.ms設定的時間到了之後就會獲取資料。linger.ms單位ms,預設值是0ms,表示沒有延遲。
Sender從RecordAccumulator獲取快取的訊息之後,會將資料封裝成網路請求<Node,Request>的形式,這樣就可以將Request請求發往各個Node了。- 請求在從
sender執行緒發往Kafka之前還會儲存到InFlightRequests中,它的主要作用是快取了已經發出去但還沒有收到伺服器端響應的請求。InFlightRequests預設每個分割區下最多快取5個請求,可以通過設定引數為max.in.flight.request.per. connection修改。 - 請求
Request通過通道Selector傳送到kafka節點。 - 傳送後,需要等待kafka的應答機制,取決於設定項
acks.
- 0:生產者傳送過來的資料,不需要等待資料落盤就應答。
- 1:生產者傳送過來的資料,
Leader收到資料後應答。 - -1(all):生產者傳送過來的資料,Leader和副本節點收齊資料後應答。預設值是-1,-1 和all 是等價的。
Request請求接受到kafka的響應結果,如果成功的話,從InFlightRequests清除請求,否則的話需要進行重發操作,可以通過設定項retries決定,當訊息傳送出現錯誤的時候,系統會重發訊息。retries表示重試次數。預設是 int 最大值,2147483647。- 清理訊息累加器
RecordAccumulator中的資料。
kafka消費者流程
原來kafka生產者傳送經過了這麼多流程,我們現在來看看kafka消費者又是如何進行的呢?
Kafka 中的消費是基於拉取模式的。訊息的消費一般有兩種模式:推播模式和拉取模式。推模式是伺服器端主動將訊息推播給消費者,而拉模式是消費者主動向伺服器端發起請求來拉取訊息。
kafka是以消費者組進行消費的,一個消費者組,由多個consumer組成。形成一個消費者組的條件,是所有消費者的groupid相同。
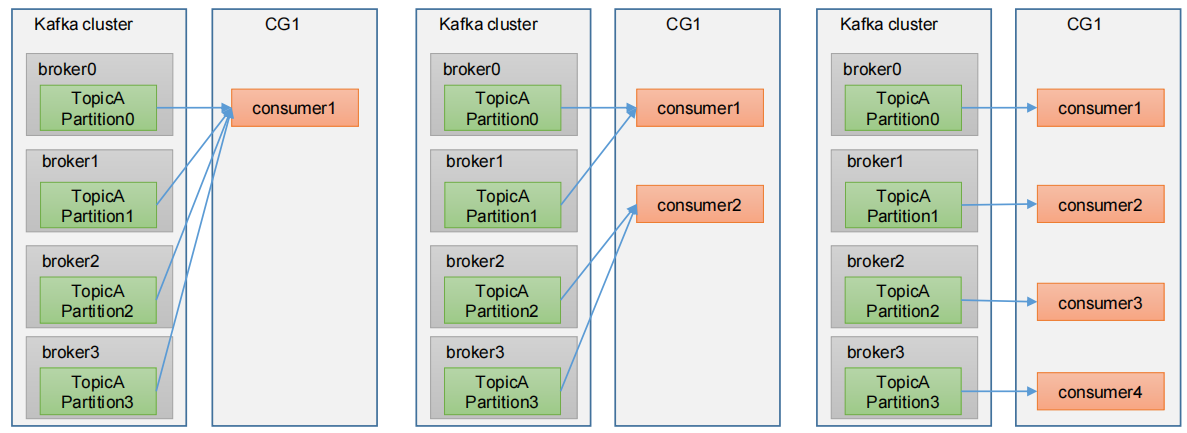
- 消費者組內每個消費者負責消費不同分割區的資料,一個分割區只能由一個組內消費者消費。如果向消費組中新增更多的消費者,超過主題分割區數量,則有一部分消費者就會閒置,不會接收任何訊息。
- 消費者組之間互不影響。所有的消費者都屬於某個消費者組,即消費者組是邏輯上的一個訂閱者。
那麼問題來了,kafka是如何指定消費者組的每個消費者消費哪個分割區?每次消費的數量是多少呢?
一、如何制定消費方案
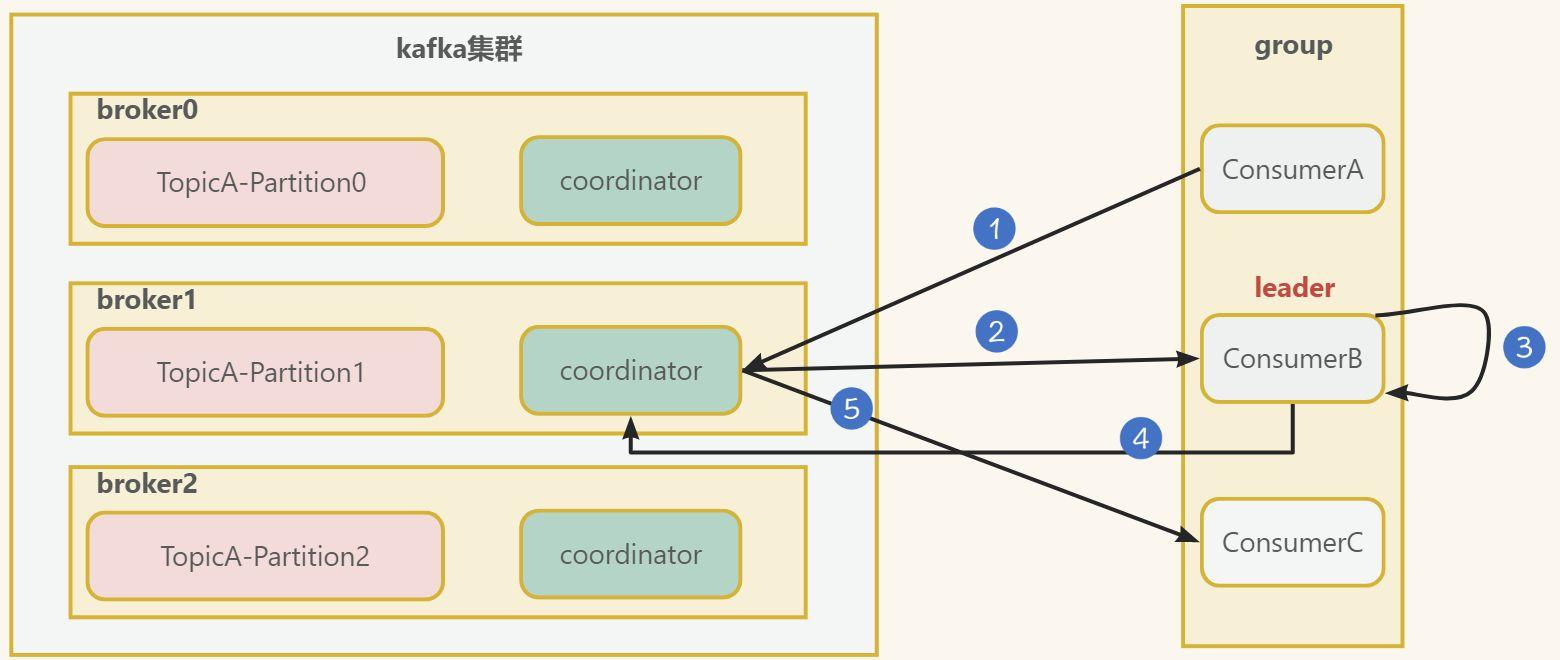
- 消費者consumerA,consumerB, consumerC向kafka叢集中的協調器
coordinator傳送JoinGroup的請求。coordinator主要是用來輔助實現消費者組的初始化和分割區的分配。
coordinator老大節點選擇 =groupid的hashcode值 % 50(__consumer_offsets內建主題位移的分割區數量)例如:groupid的hashcode值 為1,1% 50 = 1,那麼__consumer_offsets主題的1號分割區,在哪個broker上,就選擇這個節點的coordinator作為這個消費者組的老大。消費者組下的所有的消費者提交offset的時候就往這個分割區去提交offset。
- 選出一個
consumer作為消費中的leader,比如上圖中的ConsumerB。 - 消費者
leader制定出消費方案,比如誰來消費哪個分割區等 - 把消費方案發給
coordinator - 最後
coordinator就把消費方 案下發給各個consumer, 圖中只畫了一條線,實際上是有下發各個consumer。
注意,每個消費者都會和coordinator保持心跳(預設3s),一旦超時(session.timeout.ms=45s),該消費者會被移除,並觸發再平衡;或者消費者處理訊息的時間過長(max.poll.interval.ms=5分鐘),也會觸發再平衡,也就是重新進行上面的流程。
二、消費者消費細節
現在已經初始化消費者組資訊,知道哪個消費者消費哪個分割區,接著我們來看看消費者細節。
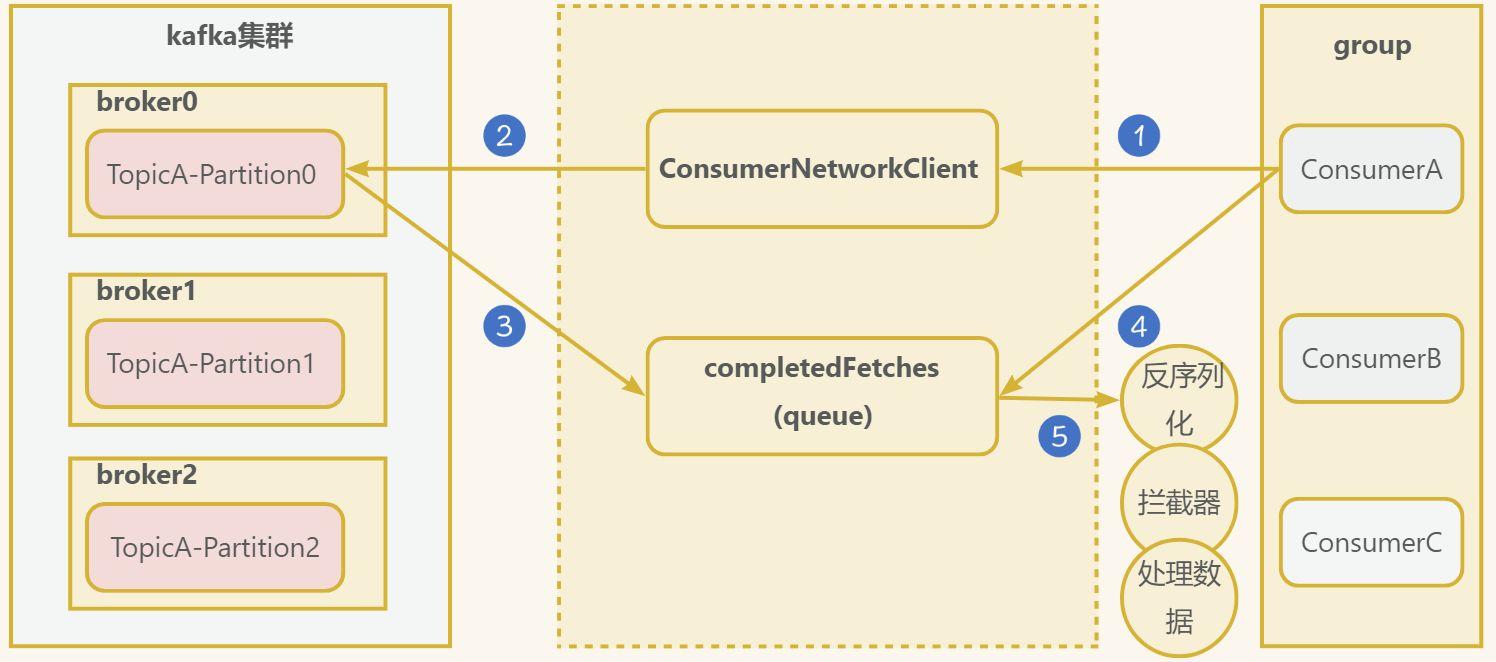
- 消費者建立一個網路連線使用者端
ConsumerNetworkClient, 傳送消費請求,可以進行如下設定:
fetch.min.bytes: 每批次最小抓取大小,預設1位元組fetch.max.bytes: 每批次最大抓取大小,預設50Mfetch.max.wait.ms:最大超時時間,預設500ms
- 傳送請求到kafka叢集
- 成功的回撥,會將資料儲存到
completedFetches佇列中 - 消費者從佇列中抓取資料,根據設定
max.poll.records一次拉取資料返回訊息的最大條數,預設500條。 - 獲取到資料後,需要經過反序列化器、攔截器等。
kafka的儲存機制
我們都知道訊息傳送到kafka,最終是儲存到磁碟中的,我們看下kafka是如何儲存的。
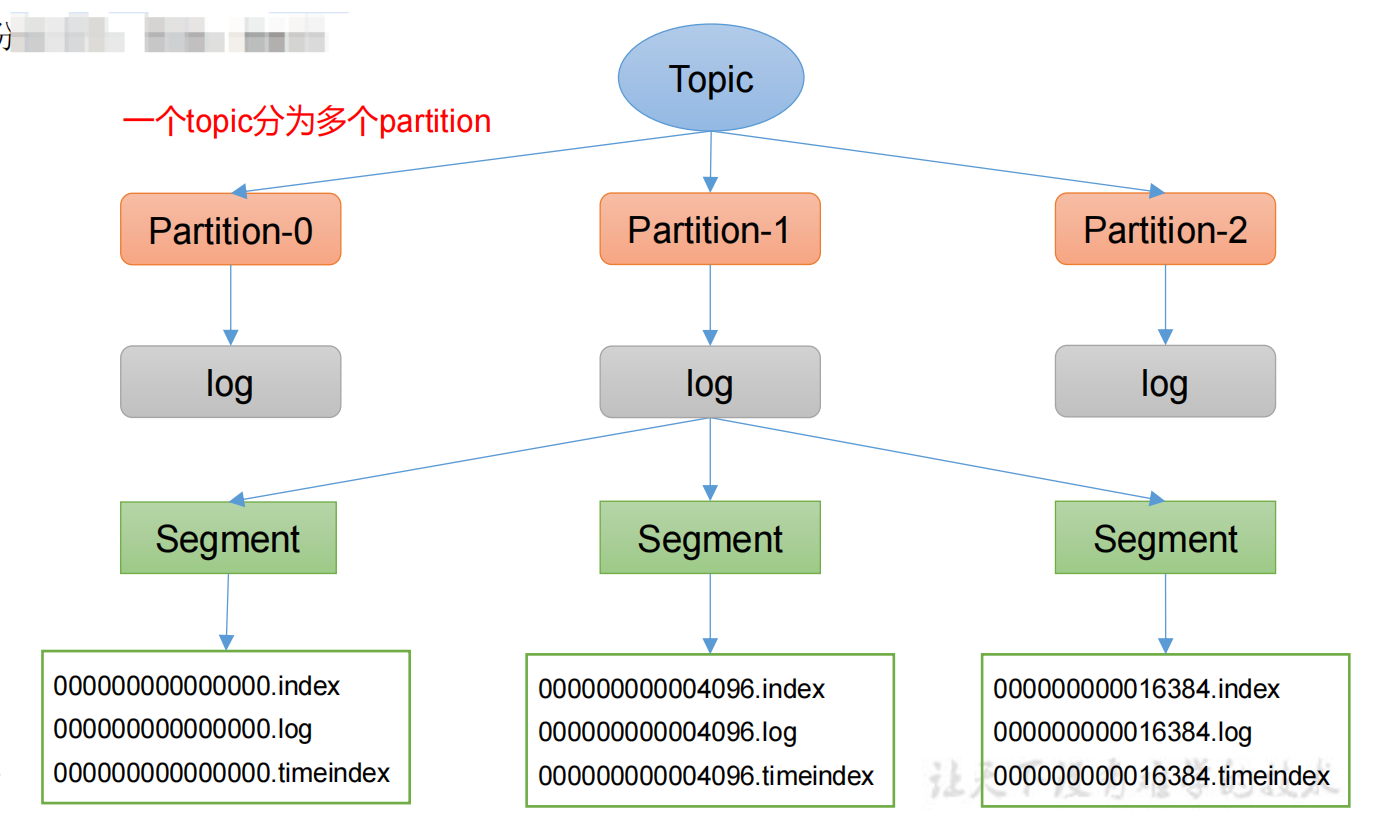
一個topic分為多個partition,每個partition對應於一個log檔案,為防止log檔案過大導致資料定位效率低下,Kafka採取了分片和索引機制,每個partition分為多個segment。每個segment包括:「.index」檔案、「.log」檔案和.timeindex等檔案,Producer生產的資料會被不斷追加到該log檔案末端。
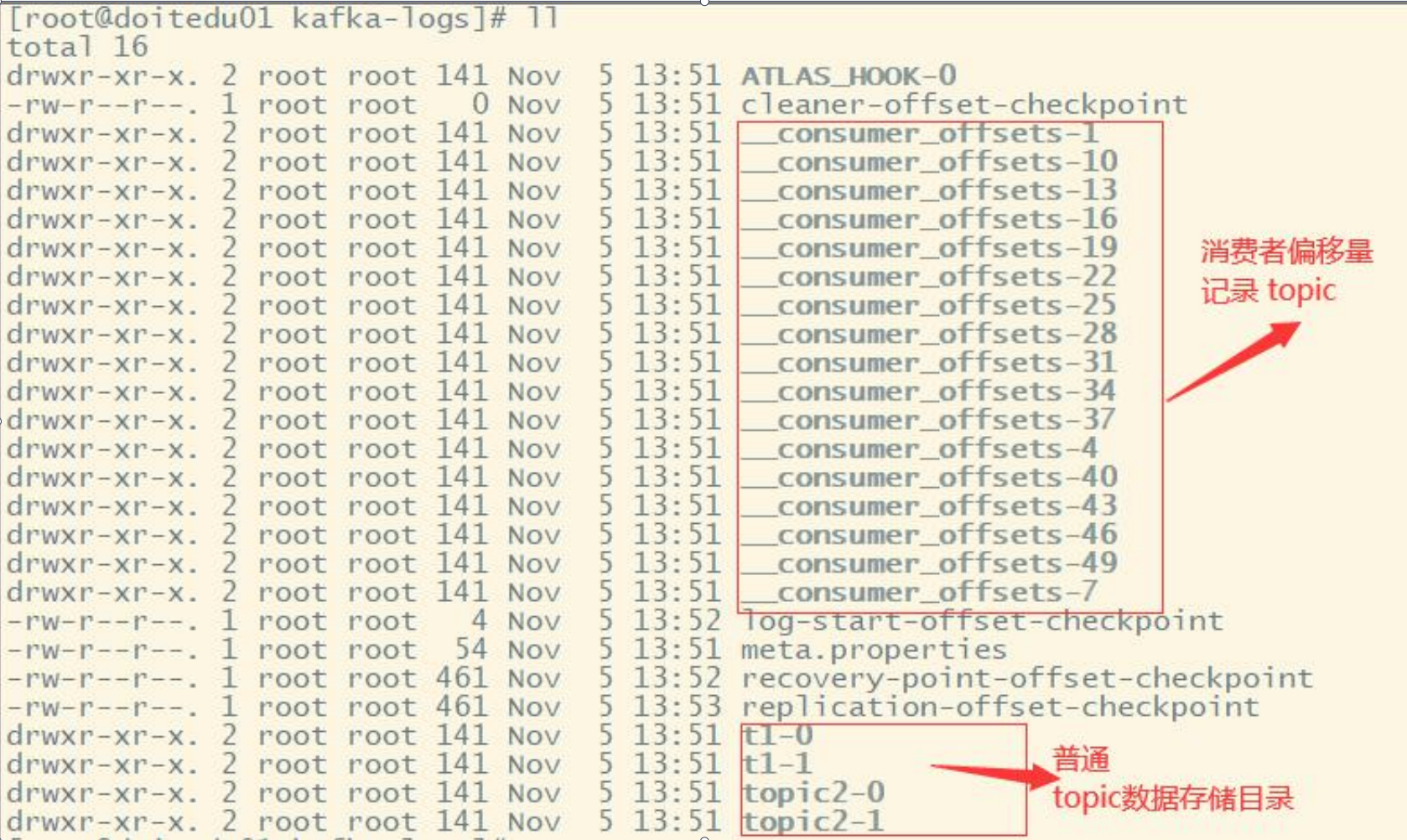
上圖中t1即為一個topic的名稱,而「t1-0/t1-1」則表明這個目錄是t1這個topic的哪個partition。
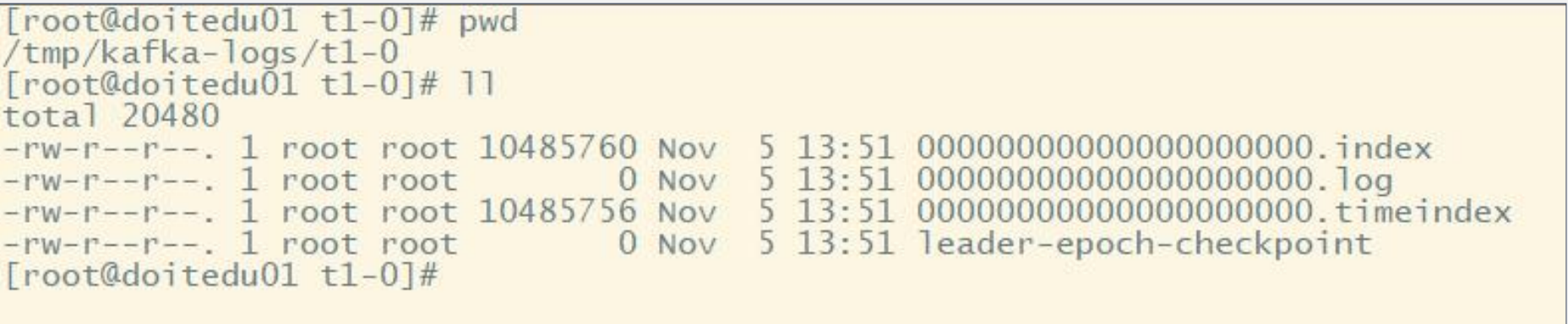
kafka中的索引檔案以稀疏索引(sparseindex)的方式構造訊息的索引,如下圖所示:

1.根據目標offset定位segment檔案
2.找到小於等於目標offset的最大offset對應的索引項
3.定位到log檔案
4.向下遍歷找到目標Record
注意:index為稀疏索引,大約每往log檔案寫入4kb資料,會往index檔案寫入一條索引。通過引數log.index.interval.bytes控制,預設4kb。
那kafka中磁碟檔案儲存多久呢?
kafka 中預設的紀錄檔儲存時間為 7 天,可以通過調整如下引數修改儲存時間。
log.retention.hours,最低優先順序小時,預設 7 天。log.retention.minutes,分鐘。log.retention.ms,最高優先順序毫秒。log.retention.check.interval.ms,負責設定檢查週期,預設 5 分鐘。
總結
其實kafka中的細節十分多,本文也只是對kafka的一些核心機制從理論層面做了一個總結,更多的細節還是需要自行去實踐,去學習。
歡迎關注個人公眾號【JAVA旭陽】交流學習
本文來自部落格園,作者:JAVA旭陽,轉載請註明原文連結:https://www.cnblogs.com/alvinscript/p/17407980.html