文生視訊: 任務、挑戰及現狀

範例視訊由 ModelScope 生成。
最近生成模型方向的進展如排山倒海,令人目不暇接,而文生視訊將是這一連串進展的下一波。儘管大家很容易從字面上理解文生視訊的意思,但它其實是一項相當新的計算機視覺任務,其要求是根據文字描述生成一系列時間和空間上都一致的影象。雖然看上去這項任務與文生圖極其相似,但眾所周知,它的難度要大得多。這些模型是如何工作的,它們與文生圖模型有何不同,我們對其效能又有何期待?
在本文中,我們將討論文生視訊模型的過去、現在和未來。我們將從回顧文生視訊和文生圖任務之間的差異開始,並討論無條件視訊生成和文生視訊兩個任務各自的挑戰。此外,我們將介紹文生視訊模型的最新發展,探索這些方法的工作原理及其效能。最後,我們將討論我們在 Hugging Face 所做的工作,這些工作的目標就是促進這些模型的整合和使用,我們還會分享一些在 Hugging Face Hub 上以及其他一些地方的很酷的演示應用及資源。

根據各種文字描述輸入生成的視訊範例,圖片來自論文 Make-a-Video。
文生視訊與文生圖
最近文生圖領域的進展多如牛毛,大家可能很難跟上最新的進展。因此,我們先快速回顧一下。
就在兩年前,第一個支援開放詞彙 (open-vocabulary) 的高質量文生圖模型出現了。第一波文生圖模型,包括 VQGAN-CLIP、XMC-GAN 和 GauGAN2,都採用了 GAN 架構。緊隨其後的是 OpenAI 在 2021 年初發布的廣受歡迎的基於 transformer 的 DALL-E、2022 年 4 月的 DALL-E 2,以及由 Stable Diffusion 和 Imagen 開創的新一波擴散模型。Stable Diffusion 的巨大成功催生了許多產品化的擴散模型,例如 DreamStudio 和 RunwayML GEN-1; 同時也催生了一批整合了擴散模型的產品,例如 Midjourney。
儘管擴散模型在文生圖方面的能力令人印象深刻,但相同的故事並沒有擴充套件到文生視訊,不管是擴散文生視訊模型還是非擴散文生視訊模型的生成能力仍然非常受限。文生視訊模型通常在非常短的視訊片段上進行訓練,這意味著它們需要使用計算量大且速度慢的滑動視窗方法來生成長視訊。因此,眾所周知,訓得的模型難以部署和擴充套件,並且在保證上下文一致性和視訊長度方面很受限。
文生視訊的任務面臨著多方面的獨特挑戰。主要有:
- 計算挑戰: 確保幀間空間和時間一致性會產生長期依賴性,從而帶來高計算成本,使得大多數研究人員無法負擔訓練此類模型的費用。
- 缺乏高質量的資料集: 用於文生視訊的多模態資料集很少,而且通常資料集的標註很少,這使得學習複雜的運動語意很困難。
- 視訊字幕的模糊性: 「如何描述視訊從而讓模型的學習更容易」這一問題至今懸而未決。為了完整描述視訊,僅一個簡短的文字提示肯定是不夠的。一系列的提示或一個隨時間推移的故事才能用於生成視訊。
在下一節中,我們將分別討論文生視訊領域的發展時間線以及為應對這些挑戰而提出的各種方法。概括來講,文生視訊的工作主要可以分為以下 3 類:
- 提出新的、更高質量的資料集,使得訓練更容易。
- 在沒有
文字 - 視訊對的情況下訓練模型的方法。 - 計算效率更高的生成更長和更高解析度視訊的方法。
如何實現文生視訊?
讓我們來看看文生視訊的工作原理以及該領域的最新進展。我們將沿著與文生圖類似的研究路徑,探索文生視訊模型的流變,並探討迄今為止我們是如何解決文生視訊領域的具體挑戰的。
與文生圖任務一樣,文生視訊也是個年輕的方向,最早只能追溯到幾年前。早期研究主要使用基於 GAN 和 VAE 的方法在給定文字描述的情況下自迴歸地生成視訊幀 (參見 Text2Filter 及 TGANs-C)。雖然這些工作為文生視訊這一新計算機視覺任務奠定了基礎,但它們的應用範圍有限,僅限於低解析度、短距以及視訊中目標的運動比較單一、孤立的情況。

最初的文生視訊模型在解析度、上下文和長度方面極為有限,影象取自 TGANs-C。
受文字 (GPT-3) 和影象 (DALL-E) 中大規模預訓練 Transformer 模型的成功啟發,文生視訊研究的第二波浪潮採用了 Transformer 架構。Phenaki、Make-A-Vide、NUWA、VideoGPT 和 CogVideo 都提出了基於 transformer 的框架,而 TATS 提出了一種混合方法,從而將用於生成影象的 VQGAN 和用於順序地生成幀的時間敏感 transformer 模組結合起來。在第二波浪潮的諸多框架中,Phenaki 尤其有意思,因為它能夠根據一系列提示 (即一個故事情節) 生成任意長視訊。同樣,NUWA-Infinity 提出了一種雙重自迴歸 (autoregressive over autoregressive) 生成機制,可以基於文字輸入合成無限長度的影象和視訊,從而使得生成高清的長視訊成為可能。但是,Phenaki 或 NUWA 模型均無法從公開渠道獲取。
Phenaki 的模型架構基於 transformer,圖片來自 此處。
第三波也就是當前這一波文生視訊模型浪潮主要以基於擴散的架構為特徵。擴散模型在生成多樣化、超現實和上下文豐富的影象方面取得了顯著成功,這引起了人們對將擴散模型推廣到其他領域 (如音訊、3D ,最近又拓展到了視訊) 的興趣。這一波模型是由 Video Diffusion Models (VDM) 開創的,它首次將擴散模型推廣至視訊領域。然後是 MagicVideo 提出了一個在低維隱空間中生成視訊剪輯的框架,據其報告,新框架與 VDM 相比在效率上有巨大的提升。另一個值得一提的是 Tune-a-Video,它使用 單文字 - 視訊對微調預訓練的文生圖模型,並允許在保留運動的同時改變視訊內容。隨後湧現出了越來越多的文生視訊擴散模型,包括 Video LDM、Text2Video-Zero、Runway Gen1、Runway Gen2 以及 NUWA-XL。
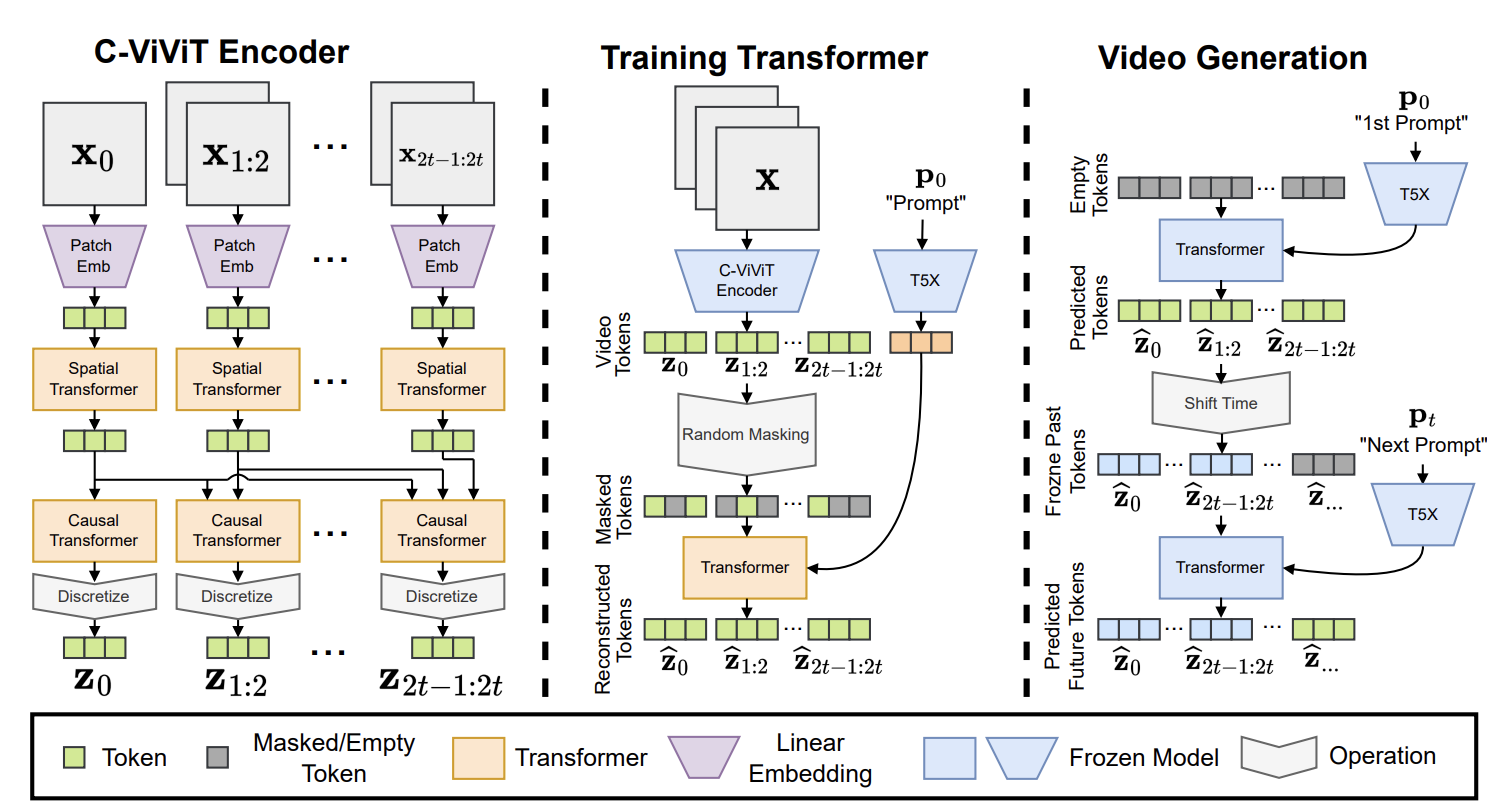
Text2Video-Zero 是一個文字引導的視訊生成和處理框架,其工作方式類似於 ControlNet。它可以基於輸入的 文字資料 或 文字 + 姿勢混合資料 或 文字 + 邊緣混合資料 直接生成 (或編輯) 視訊。顧名思義,Text2Video-Zero 是一種零樣本模型,它將可訓練的運動動力學模組與預訓練的文生圖穩定擴散模型相結合,而無需使用任何 文字 - 視訊對 資料。與 Text2Video-Zero 類似,Runway Gen-1 和 Runway Gen-2 模型可以合成由文字或影象描述的內容引導的視訊。這些工作大多數都是在短視訊片段上訓練的,並且依靠帶有滑動視窗的自迴歸機制來生成更長的視訊,這不可避免地導致了上下文差異 (context gap)。 NUWA-XL 解決了這個問題,並提出了一種「雙重擴散 (diffusion over diffusion)」方法,並在 3376 幀視訊資料上訓練模型。最後,還有一些尚未在同行評審的會議或期刊上發表的開源文字到視訊模型和框架,例如阿里巴巴達摩院視覺智慧實驗室的 ModelScope 和 Tencel 的 VideoCrafter。
資料集
與其他視覺語言模型一樣,文生視訊模型通常在大型 文字 - 視訊對 資料集上進行訓練。這些資料集中的視訊通常被分成短的、固定長度的塊,並且通常僅限於少數幾個目標的孤立動作。出現這種情況的一部分原因是計算限制,另一部分原因是以有意義的方式描述視訊內容這件事本身就很難。而我們看到多模態視訊文字資料集和文生視訊模型的發展往往是交織在一起的,因此有不少工作側重於開發更易於訓練的更好、更通用的資料集。同時也有一些工作另闢蹊徑,對替代解決方案進行了探索,例如 Phenaki 將 文字 - 影象對 與 文字 - 視訊對 相結合用於文生視訊任務; Make-a-Video 則更進一步,提議僅使用 文字 - 影象對 來學習世界表象資訊,並使用單模態視訊資料以無監督的方式學習時空依賴性。
這些大型資料集面臨與文字影象資料集類似的問題。最常用的文字 - 視訊資料集 WebVid 由 1070 萬個 文字 - 視訊對 (視訊時長 5.2 萬小時) 組成,幷包含一定量的噪聲樣本,這些樣本中的視訊文字描述與視訊內容是非相干的。其他資料集試圖通過聚焦特定任務或領域來解決這個問題。例如,Howto100M 資料集包含 13600 萬個視訊剪輯,其中文字部分描述瞭如何一步一步地執行復雜的任務,例如烹飪、手工製作、園藝、和健身。而 QuerYD 資料集則聚焦於事件定位任務,視訊的字幕詳細描述了目標和動作的相對位置。CelebV-Text 是一個包含超過 7 萬個視訊的大規模人臉文字 - 視訊資料集,用於生成具有逼真的人臉、情緒和手勢的視訊。
Hugging Face 上的文生視訊
使用 Hugging Face Diffusers,你可以輕鬆下載、執行和微調各種預訓練的文生視訊模型,包括 Text2Video-Zero 和 阿里巴巴達摩院 的 ModelScope。我們目前正在努力將更多優秀的工作整合到 Diffusers 和