分庫分表的 21 條法則,hold 住!
大家好,我是小富~
本文是《分庫分表ShardingSphere5.x原理與實戰》系列的第二篇文章,距離上一篇文章已經過去好久了,慚愧慚愧~
還是不著急實戰,咱們先介紹下在分庫分表架構實施過程中,會接觸到的一些通用概念,瞭解這些概念能夠幫助理解市面上其他的分庫分表工具,儘管它們的實現方法可能存在差異,但整體思路基本一致。因此,在開始實際操作之前,我們有必要先掌握這些通用概念,以便更好地理解和應用分庫分表技術。
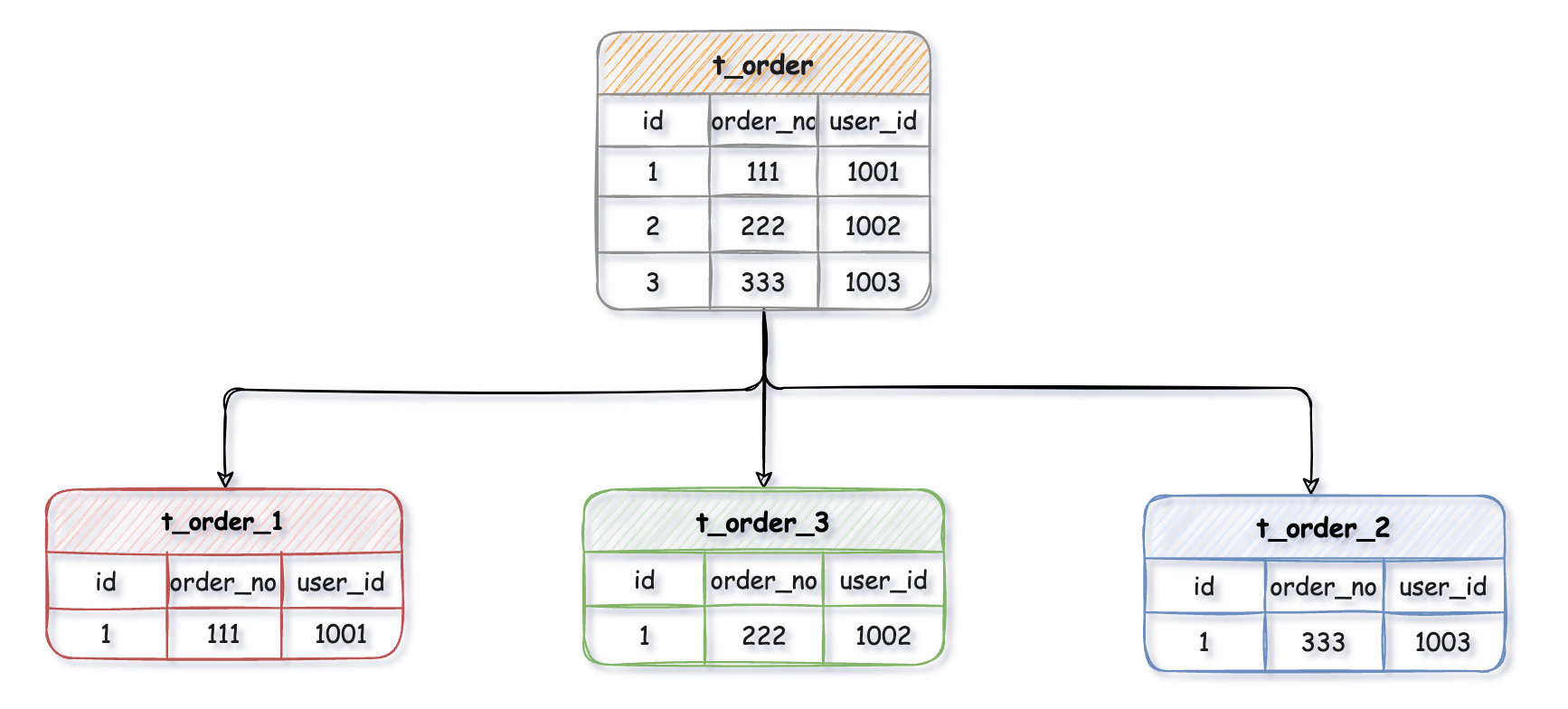
我們結合具體業務場景,以t_order表為例進行架構優化。由於資料量已經達到億級別,查詢效能嚴重下降,因此我們採用了分庫分表技術來處理這個問題。具體而言,我們將原本的單庫分成了兩個庫,分別為DB_1和DB_2,並在每個庫中再次進行分表處理,生成t_order_1和t_order_2兩張表,實現對訂單表的分庫分表處理。
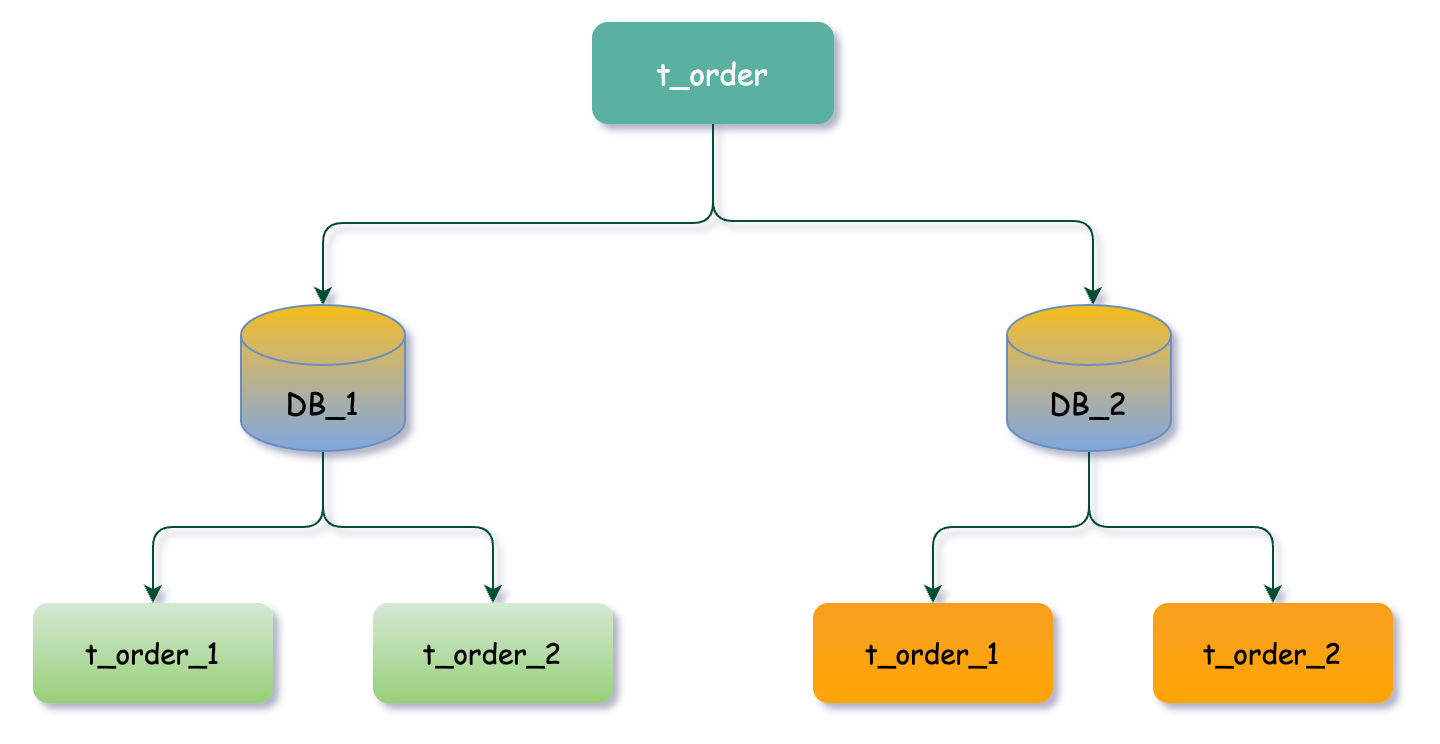
資料分片
通常我們在提到分庫分表的時候,大多是以水平切分模式(水平分庫、分表)為基礎來說的,資料分片它將原本一張資料量較大的表 t_order 拆分生成數個表結構完全一致的小資料量表(拆分表) t_order_0、t_order_1、···、t_order_n,每張表只儲存原大表中的一部分資料。
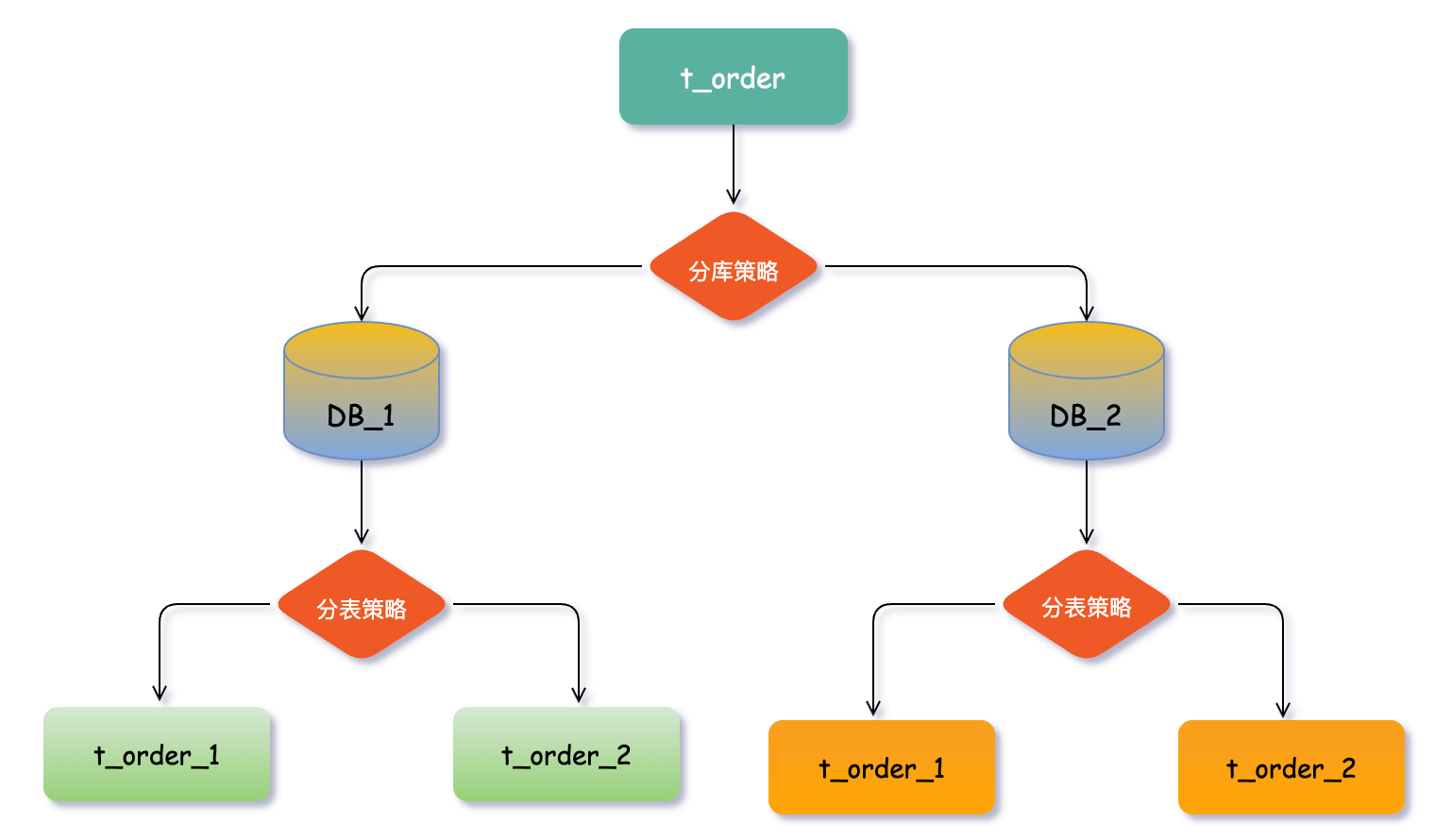
資料節點
資料節點是資料分片中一個不可再分的最小單元(表),它由資料來源名稱和資料表組成,例如上圖中 DB_1.t_order_1、DB_2.t_order_2 就表示一個資料節點。
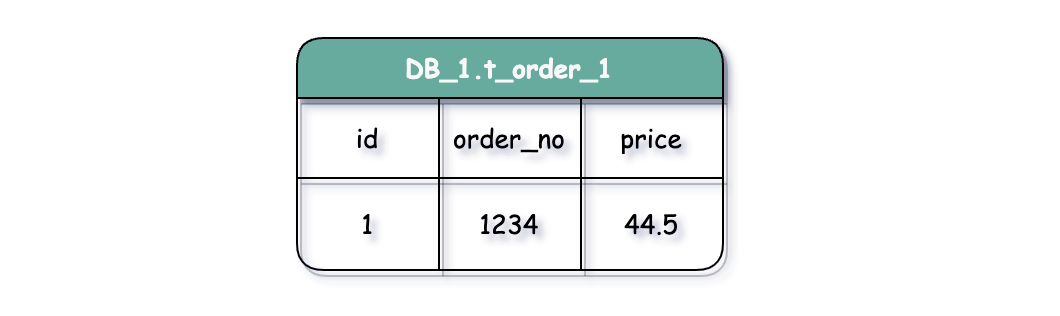
邏輯表
邏輯表是指具有相同結構的水平拆分表的邏輯名稱。
比如我們將訂單表t_order 分表拆分成 t_order_0 ··· t_order_9等10張表,這時我們的資料庫中已經不存在 t_order這張表,取而代之的是若干的t_order_n表。
分庫分表通常對業務程式碼都是無侵入式的,開發者只專注於業務邏輯SQL編碼,我們在程式碼中SQL依然按 t_order來寫,而在執行邏輯SQL前將其解析成對應的資料庫真實執行的SQL。此時 t_order 就是這些拆分表的邏輯表。
業務邏輯SQL
select * from t_order where order_no='A11111'
真實執行SQL
select * from DB_1.t_order_n where order_no='A11111'
真實表
真實表就是在資料庫中真實存在的物理表DB_1.t_order_n。
廣播表
廣播表是一類特殊的表,其表結構和資料在所有分片資料來源中均完全一致。與拆分表相比,廣播表的資料量較小、更新頻率較低,通常用於字典表或設定表等場景。由於其在所有節點上都有副本,因此可以大大降低JOIN關聯查詢的網路開銷,提高查詢效率。
需要注意的是,對於廣播表的修改操作需要保證同步性,以確保所有節點上的資料保持一致。
廣播表的特點:
-
在所有分片資料來源中,廣播表的資料完全一致。因此,對廣播表的操作(如插入、更新和刪除)會實時在每個分片資料來源中執行一遍,以保證資料的一致性。
-
對於廣播表的查詢操作,僅需要在任意一個分片資料來源中執行一次即可。
-
與任何其他表進行JOIN操作都是可行的,因為由於廣播表的資料在所有節點上均一致,所以可以存取到任何一個節點上的相同資料。
什麼樣的表可以作為廣播表呢?
訂單管理系統中,往往需要查詢統計某個城市地區的訂單資料,這就會涉及到省份地區表t_city與訂單流水錶DB_n.t_order_n進行JOIN查詢,因此可以考慮將省份地區表設計為廣播表,核心理念就是避免跨庫JOIN操作。
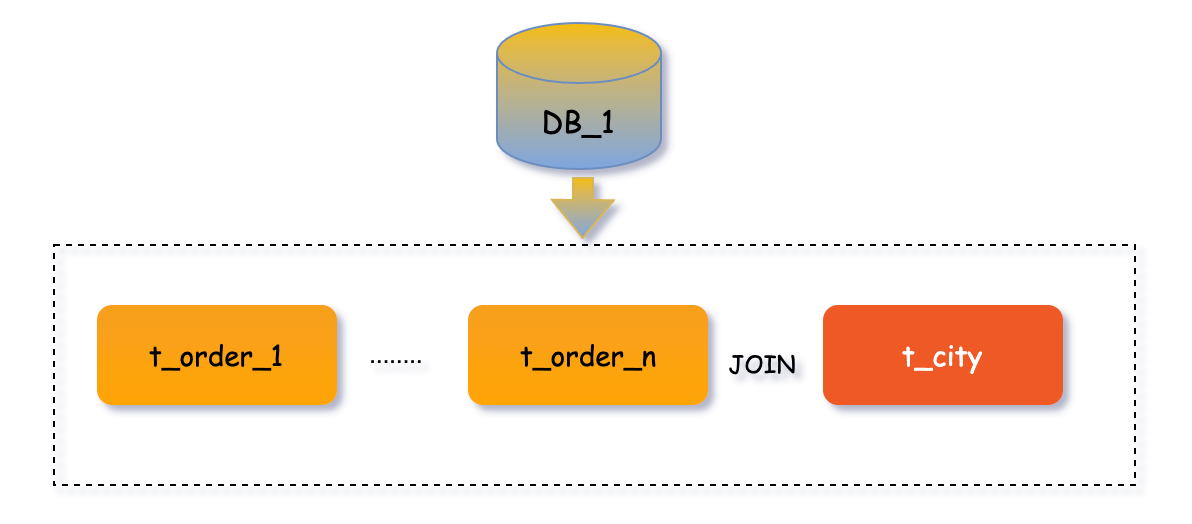
注意:上邊我們提到廣播表在資料插入、更新與刪除會實時在每個分片資料來源均執行,也就是說如果你有1000個分片資料來源,那麼修改一次廣播表就要執行1000次SQL,所以儘量不在並行環境下和業務高峰時進行,以免影響系統的效能。
單表
單表指所有的分片資料來源中僅唯一存在的表(沒有分片的表),適用於資料量不大且無需分片的表。
如果一張表的資料量預估在千萬級別,且沒有與其他拆分表進行關聯查詢的需求,建議將其設定為單表型別,儲存在預設分片資料來源中。
分片鍵
分片鍵決定了資料落地的位置,也就是資料將會被分配到哪個資料節點上儲存。因此,分片鍵的選擇非常重要。
比如我們將 t_order 表進行分片後,當插入一條訂單資料執行SQL時,需要通過解析SQL語句中指定的分片鍵來計算資料應該落在哪個分片中。以表中order_no欄位為例,我們可以通過對其取模運算(比如 order_no % 2)來得到分片編號,然後根據分片編號分配資料到對應的資料庫範例(比如 DB_1 和 DB_2)。拆分表也是同理計算。
在這個過程中,order_no 就是 t_order 表的分片鍵。也就是說,每一條訂單資料的 order_no 值決定了它應該存放的資料庫範例和表。選擇一個適合作為分片鍵的欄位可以更好地利用水平分片帶來的效能提升。

這樣同一個訂單的相關資料就會落在同一個資料庫、表中,查詢訂單時同理計算,就可直接定位資料位置,大幅提升資料檢索的效能,避免了全庫表掃描。
不僅如此 ShardingSphere 還支援根據多個欄位作為分片健進行分片,這個在後續對應章節中會詳細講。
分片策略
分片策略來指定使用哪種分片演演算法、選擇哪個欄位作為分片鍵以及如何將資料分配到不同的節點上。
分片策略是由分片演演算法和分片健組合而成,分片策略中可以使用多種分片演演算法和對多個分片鍵進行運算。
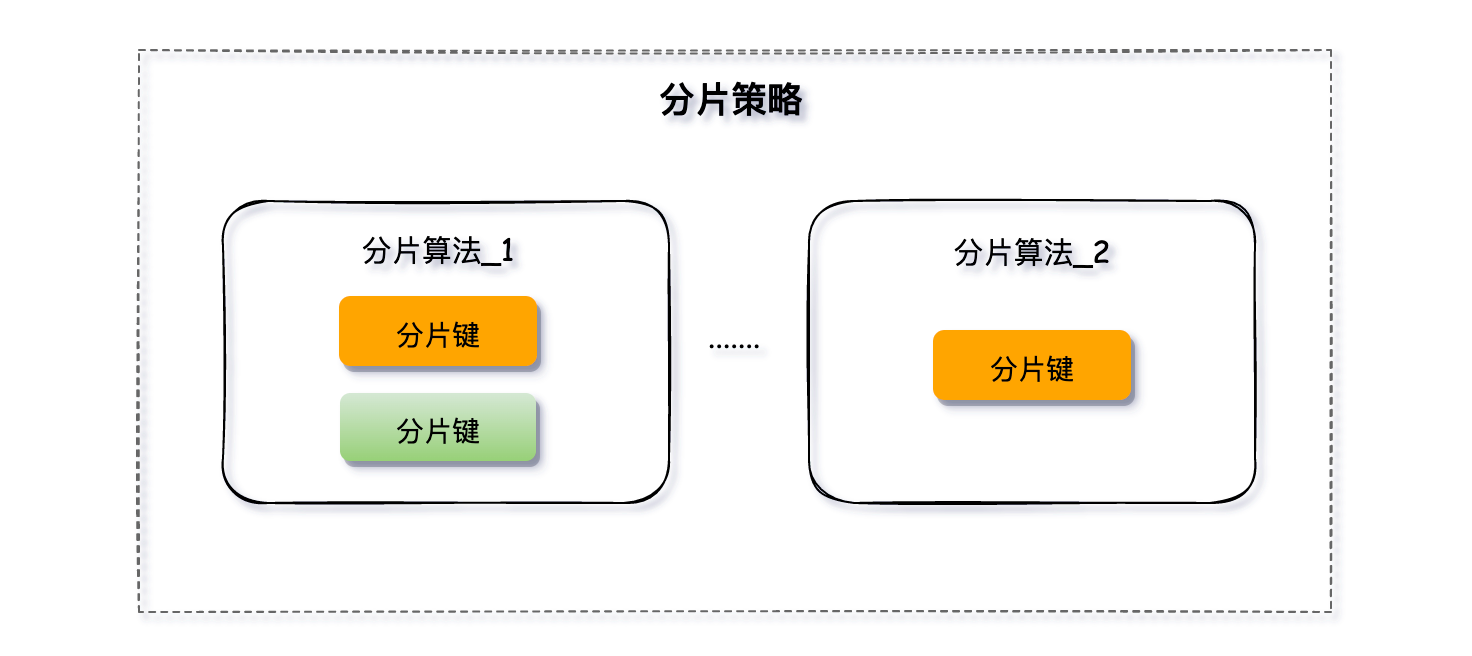
分庫、分表的分片策略設定是相對獨立的,可以各自使用不同的策略與演演算法,每種策略中可以是多個分片演演算法的組合,每個分片演演算法可以對多個分片健做邏輯判斷。
分片演演算法
分片演演算法則是用於對分片鍵進行運算,將資料劃分到具體的資料節點中。
常用的分片演演算法有很多:
- 雜湊分片:根據分片鍵的雜湊值來決定資料應該落到哪個節點上。例如,根據使用者 ID 進行雜湊分片,將屬於同一個使用者的資料分配到同一個節點上,便於後續的查詢操作。
- 範圍分片:分片鍵值按區間範圍分配到不同的節點上。例如,根據訂單建立時間或者地理位置來進行分片。
- 取模分片:將分片鍵值對分片數取模,將結果作為資料應該分配到的節點編號。例如, order_no % 2 將訂單資料分到兩個節點之一。
- .....
實際業務開發中分片的邏輯要複雜的多,不同的演演算法適用於不同的場景和需求,需要根據實際情況進行選擇和調整。
繫結表
繫結表是那些具有相同分片規則的一組分片表,由於分片規則一致所產生的的資料落地位置相同,在JOIN聯合查詢時能有效避免跨庫操作。
比如:t_order 訂單表和 t_order_item 訂單專案表,都以 order_no 欄位作為分片鍵,並且使用 order_no 進行關聯,因此兩張表互為繫結表關係。
使用繫結表進行多表關聯查詢時,必須使用分片鍵進行關聯,否則會出現笛卡爾積關聯或跨庫關聯,從而影響查詢效率。
當使用 t_order 和 t_order_item 表進行多表聯合查詢,執行如下聯合查詢的邏輯SQL。
SELECT * FROM t_order o JOIN t_order_item i ON o.order_no=i.order_no
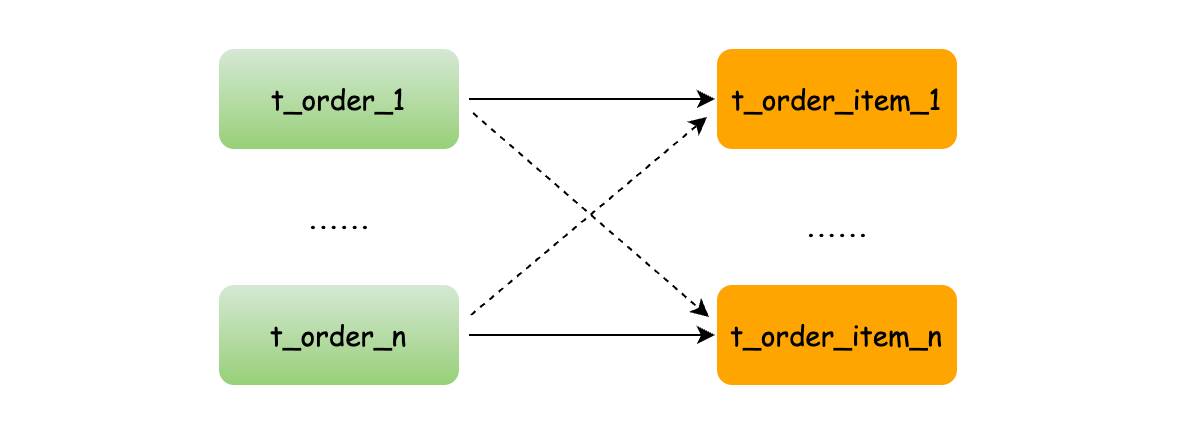
如果不設定繫結表關係,兩個表的資料位置不確定就會全庫表查詢,出現笛卡爾積關聯查詢,將產生如下四條SQL。
SELECT * FROM t_order_0 o JOIN t_order_item_0 i ON o.order_no=i.order_no
SELECT * FROM t_order_0 o JOIN t_order_item_1 i ON o.order_no=i.order_no
SELECT * FROM t_order_1 o JOIN t_order_item_0 i ON o.order_no=i.order_no
SELECT * FROM t_order_1 o JOIN t_order_item_1 i ON o.order_no=i.order_no
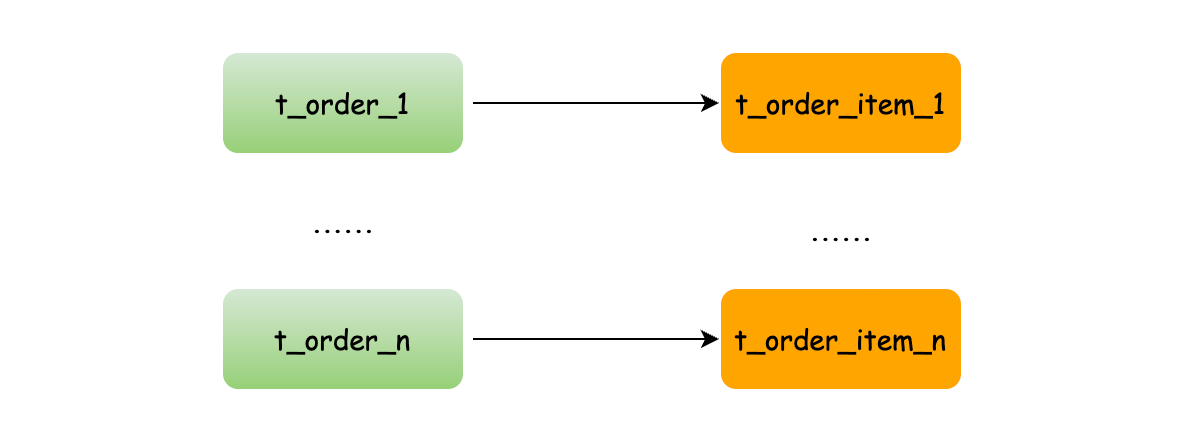
而設定繫結表關係後再進行關聯查詢時,分片規則一致產生的資料就會落到同一個庫表中,那麼只需在當前庫中 t_order_n 和 t_order_item_n 表關聯即可。
SELECT * FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id
SELECT * FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id
注意:在關聯查詢時
t_order它作為整個聯合查詢的主表。 所有相關的路由計算都只使用主表的策略,t_order_item表的分片相關的計算也會使用t_order的條件,所以要保證繫結表之間的分片鍵要完全相同。
SQL 解析
分庫分表後在應用層面執行一條 SQL 語句時,通常需要經過以下六個步驟:SQL 解析 -> 執⾏器優化 -> SQL 路由 -> SQL 改寫 -> SQL 執⾏ -> 結果歸併 。

SQL解析過程分為詞法解析和語法解析兩步,比如下邊查詢使用者訂單的SQL,先用詞法解析將這條SQL拆解成不可再分的原子單元。在根據不同資料庫方言所提供的字典,將這些單元歸類為關鍵字,表示式,變數或者操作符等型別。
SELECT order_no FROM t_order where order_status > 0 and user_id = 10086
接著語法解析會將拆分後的SQL關鍵字轉換為抽象語法樹,通過對抽象語法樹遍歷,提煉出分片所需的上下文,上下文包含查詢欄位資訊(Field)、表資訊(Table)、查詢條件(Condition)、排序資訊(Order By)、分組資訊(Group By)以及分頁資訊(Limit)等,並標記出 SQL中有可能需要改寫的位置。

執⾏器優化
執⾏器優化是根據SQL查詢特點和執行統計資訊,選擇最優的查詢計劃並執行,比如user_id欄位有索引,那麼會調整兩個查詢條件的位置,主要是提高SQL的執行效率。
SELECT order_no FROM t_order where user_id = 10086 and order_status > 0
SQL 路由
通過上邊的SQL解析得到了分片上下文資料,在匹配使用者設定的分片策略和演演算法,就可以運算生成路由路徑,將 SQL 語句路由到相應的資料節點上。
簡單點理解就是拿到分片策略中設定的分片鍵等資訊,在從SQL解析結果中找到對應分片鍵欄位的值,計算出 SQL該在哪個庫的哪個表中執行,SQL路由又根據有無分片健分為 分片路由 和 廣播路由。
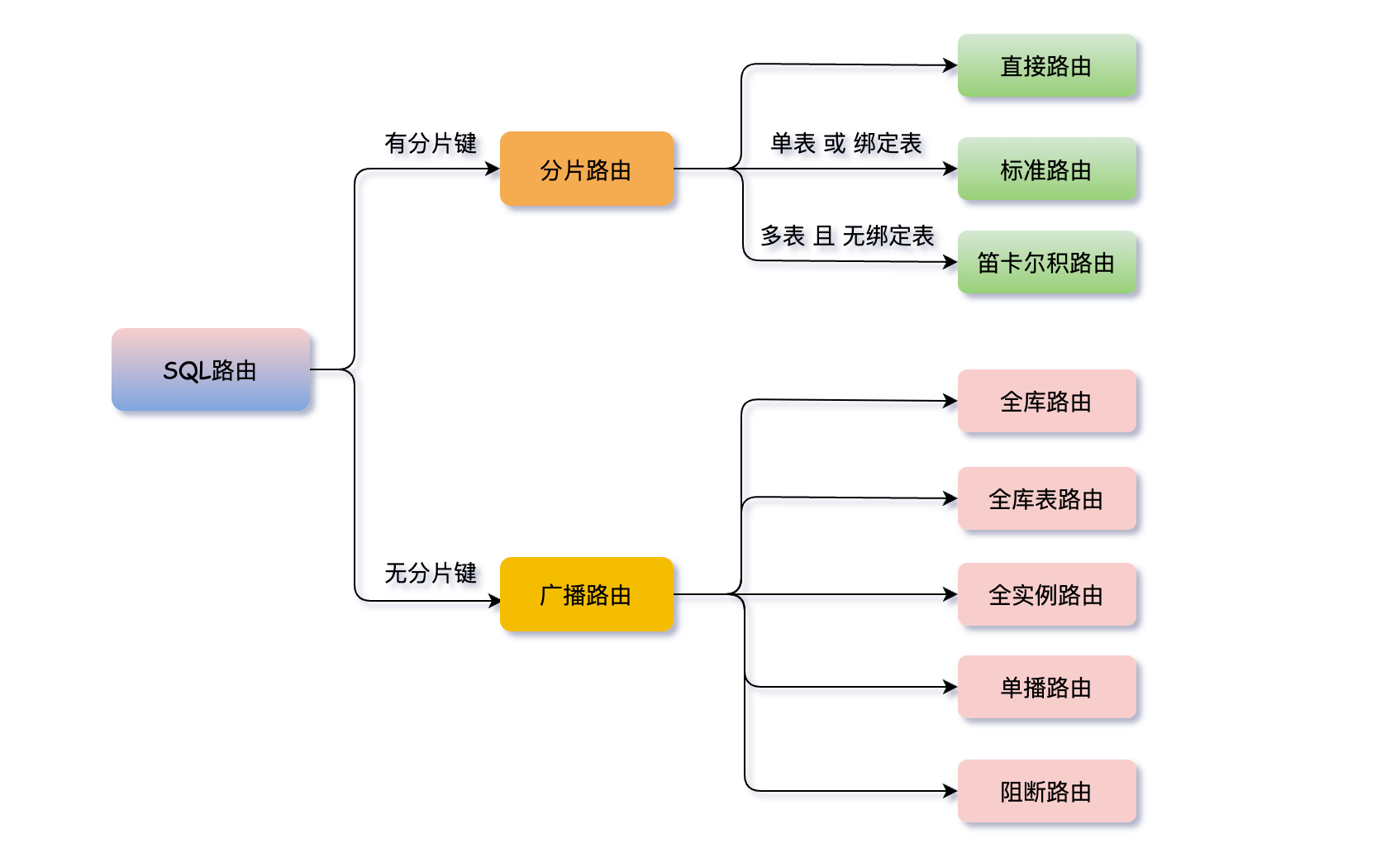
有分⽚鍵的路由叫分片路由,細分為直接路由、標準路由和笛卡爾積路由這3種型別。
標準路由
標準路由是最推薦也是最為常⽤的分⽚⽅式,它的適⽤範圍是不包含關聯查詢或僅包含繫結表之間關聯查詢的SQL。
當 SQL分片健的運運算元為 = 時,路由結果將落⼊單庫(表),當分⽚運運算元是 BETWEEN 或 IN 等範圍時,路由結果則不⼀定落⼊唯⼀的庫(表),因此⼀條邏輯SQL最終可能被拆分為多條⽤於執⾏的真實SQL。
SELECT * FROM t_order where t_order_id in (1,2)
SQL路由處理後
SELECT * FROM t_order_0 where t_order_id in (1,2)
SELECT * FROM t_order_1 where t_order_id in (1,2)
直接路由
直接路由是直接將SQL路由到指定⾄庫、表的一種分⽚方式,而且直接路由可以⽤於分⽚鍵不在SQL中的場景,還可以執⾏包括⼦查詢、⾃定義函數等複雜情況的任意SQL。
笛卡爾積路由
笛卡爾路由是由⾮繫結表之間的關聯查詢產生的,比如訂單表t_order 分片鍵是t_order_id 和使用者表t_user分片鍵是t_order_id ,兩個表的分片鍵不同,要做聯表查詢,會執行笛卡爾積路由,查詢效能較低儘量避免走此路由模式。
SELECT * FROM t_order_0 t LEFT JOIN t_user_0 u ON u.user_id = t.user_id WHERE t.user_id = 1
SELECT * FROM t_order_0 t LEFT JOIN t_user_1 u ON u.user_id = t.user_id WHERE t.user_id = 1
SELECT * FROM t_order_1 t LEFT JOIN t_user_0 u ON u.user_id = t.user_id WHERE t.user_id = 1
SELECT * FROM t_order_1 t LEFT JOIN t_user_1 u ON u.user_id = t.user_id WHERE t.user_id = 1
無分⽚鍵的路由又叫做廣播路由,可以劃分為全庫表路由、全庫路由、 全範例路由、單播路由和阻斷路由這 5種型別。
全庫表路由
全庫表路由針對的是資料庫 DQL 和 DML,以及 DDL等操作,當我們執行一條邏輯表 t_order SQL時,在所有分片庫中對應的真實表 t_order_0 ··· t_order_n 內逐一執行。
全庫路由
全庫路由主要是對資料庫層面的操作,比如資料庫 SET 型別的資料庫管理命令,以及 TCL 這樣的事務控制語句。
對邏輯庫設定 autocommit 屬性後,所有對應的真實庫中都執行該命令。
SET autocommit=0;
全範例路由
全範例路由是針對資料庫範例的 DCL 操作(設定或更改資料庫使用者或角色許可權),比如:建立一個使用者 order ,這個命令將在所有的真實庫範例中執行,以此確保 order 使用者可以正常存取每一個資料庫範例。
CREATE USER [email protected] identified BY '程式設計師小富';
單播路由
單播路由用來獲取某一真實表資訊,比如獲得表的描述資訊:
DESCRIBE t_order;
t_order 的真實表是 t_order_0 ···· t_order_n,他們的描述結構相完全同,我們只需在任意的真實表執行一次就可以。
阻斷路由
⽤來遮蔽SQL對資料庫的操作,例如:
USE order_db;
這個命令不會在真實資料庫中執⾏,因為 ShardingSphere 採⽤的是邏輯 Schema(資料庫的組織和結構) ⽅式,所以無需將切換資料庫的命令傳送⾄真實資料庫中。
SQL 改寫
SQL經過解析、優化、路由後已經明確分片具體的落地執行的位置,接著就要將基於邏輯表開發的SQL改寫成可以在真實資料庫中可以正確執行的語句。比如查詢 t_order 訂單表,我們實際開發中 SQL是按邏輯表 t_order 寫的。
SELECT * FROM t_order
這時需要將分表設定中的邏輯表名稱改寫為路由之後所獲取的真實表名稱。
SELECT * FROM t_order_n
SQL執⾏
將路由和改寫後的真實 SQL 安全且高效傳送到底層資料來源執行。但這個過程並不能將 SQL 一股腦的通過 JDBC 直接傳送至資料來源執行,需平衡資料來源連線建立以及記憶體佔用所產生的消耗,它會自動化的平衡資源控制與執行效率。
結果歸併
將從各個資料節點獲取的多資料結果集,合併成一個大的結果集並正確的返回至請求使用者端,稱為結果歸併。而我們SQL中的排序、分組、分頁和聚合等語法,均是在歸併後的結果集上進行操作的。
分散式主鍵
資料分⽚後,一個邏輯表(t_order)對應諸多的真實表(t_order_n),它們之間由於⽆法互相感知,主鍵ID都從初始值累加,所以必然會產⽣重複主鍵ID,此時主鍵不再唯一那麼對於業務來說也就沒意義了。
儘管可通過設定表⾃增主鍵 初始值 和 步⻓ 的⽅式避免ID碰撞,但這樣會使維護成本加大,可延伸性差。
這個時候就需要我們手動為一條資料記錄,分配一個全域性唯一的ID,這個ID被叫做分散式ID,而生產這個ID的系統通常被叫做發號器。
大家可以參考我之前釋出的這篇文章 9種分散式ID生成方案
資料脫敏
分庫分表資料脫敏是一種有效的資料保護措施,可以確保敏感資料的機密性和安全性,減少資料洩露的風險。
比如,我們在分庫分表時可以指定表的哪些欄位為脫敏列,並設定對應的脫敏演演算法,在資料分片時解析到執行SQL中有待脫敏欄位,會直接將欄位值脫敏後的寫入庫表內。
對於使用者的個人資訊,如姓名、地址和電話號碼等,可以通過加密、隨機化或替換成偽亂資料的方式進行脫敏,以確保使用者的隱私得到保護。
大家可以參考我之前釋出的這篇文章 大廠也在用的 6種 資料脫敏方案
分散式事務
分散式事務的核心問題是如何實現跨多個資料來源的原子性操作。
由於不同的服務通常會使用不同的資料來源來儲存和管理資料,因此,跨資料來源的操作可能會導致資料不一致性或丟失的風險。因此,保證分散式事務的一致性是非常重要的。
以訂單系統為例,它需要呼叫支付系統、庫存系統、積分系統等多個系統,而每個系統都維護自己的資料庫範例,系統間通過API介面交換資料。
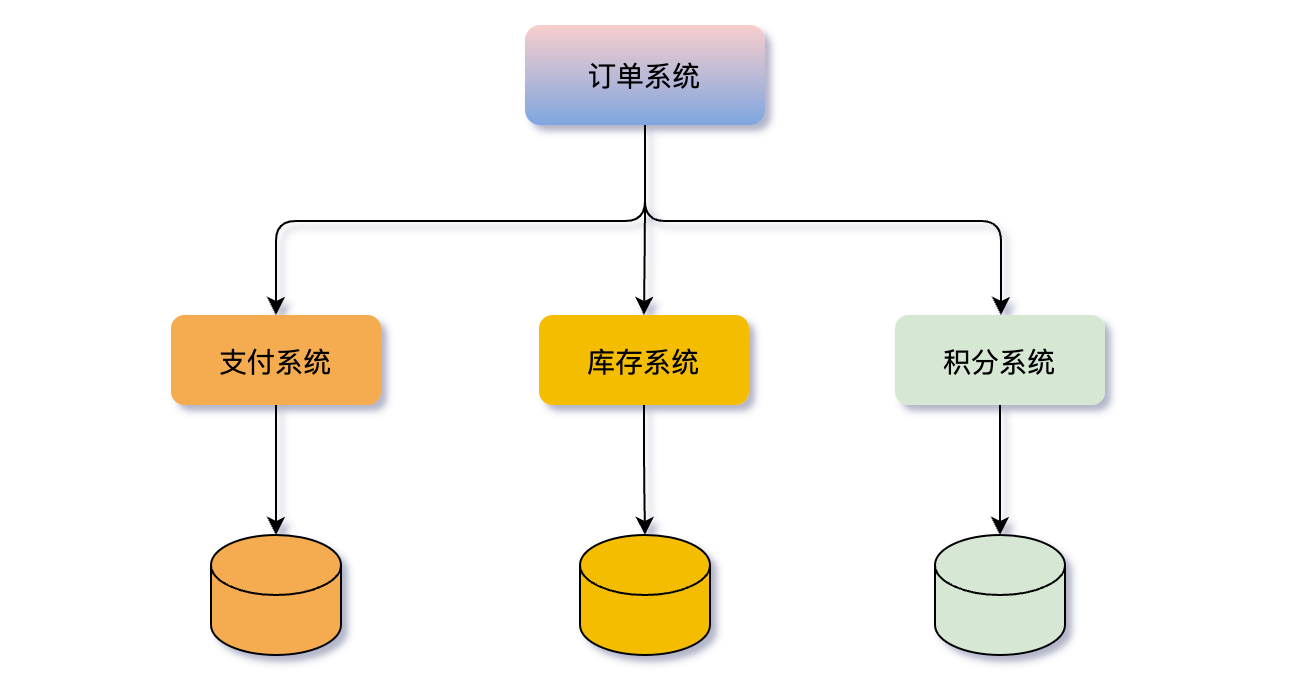
為了保證下單後多個系統同時呼叫成功,可以使用強一致性事務的XA協定,或者柔性事務的代表工具Seata,來實現分散式事務的一致性。這些工具可以幫助開發人員簡化分散式事務的實現,減少錯誤和漏洞的出現,提高系統的穩定性和可靠性。
經過分庫分表之後,問題的難度進一步提升。自身訂單服務,也需要處理跨資料來源的操作。這樣一來,系統的複雜度顯著增加。因此,不到萬不得已的情況下,最好避免採用分庫分表的解決方案。
關於分散式事務詳細的介紹,大家可以參考我之前釋出的這篇文章 對比 5 種分散式事務方案,還是寵幸了阿里的 Seata(原理 + 實戰)
資料遷移
分庫分表後還有個讓人頭疼的問題,那就是資料遷移,為了不影響現有的業務系統,通常會新建資料庫叢集遷移資料。將資料從舊叢集的資料庫、表遷移到新叢集的分庫、分表中。這是一個比較複雜的過程,在遷移過程中需要考慮資料量、資料一致性、遷移速度等諸多因素。
遷移主要針對 存量資料 和 增量資料 的處理,存量資料指舊資料來源中已經存在且有價值的歷史資料,增量資料指當下持續增長以及未來產生的業務資料。
存量資料可以採用定時、分批次的遷移,遷移過程可能會持續幾天。
增量資料可以採用新、舊資料庫叢集雙寫模式。待資料遷移完畢,業務驗證了資料一致性,應用直接切換資料來源即可。
後續我們會結合三方工具,來演示遷移的過程。
影子庫
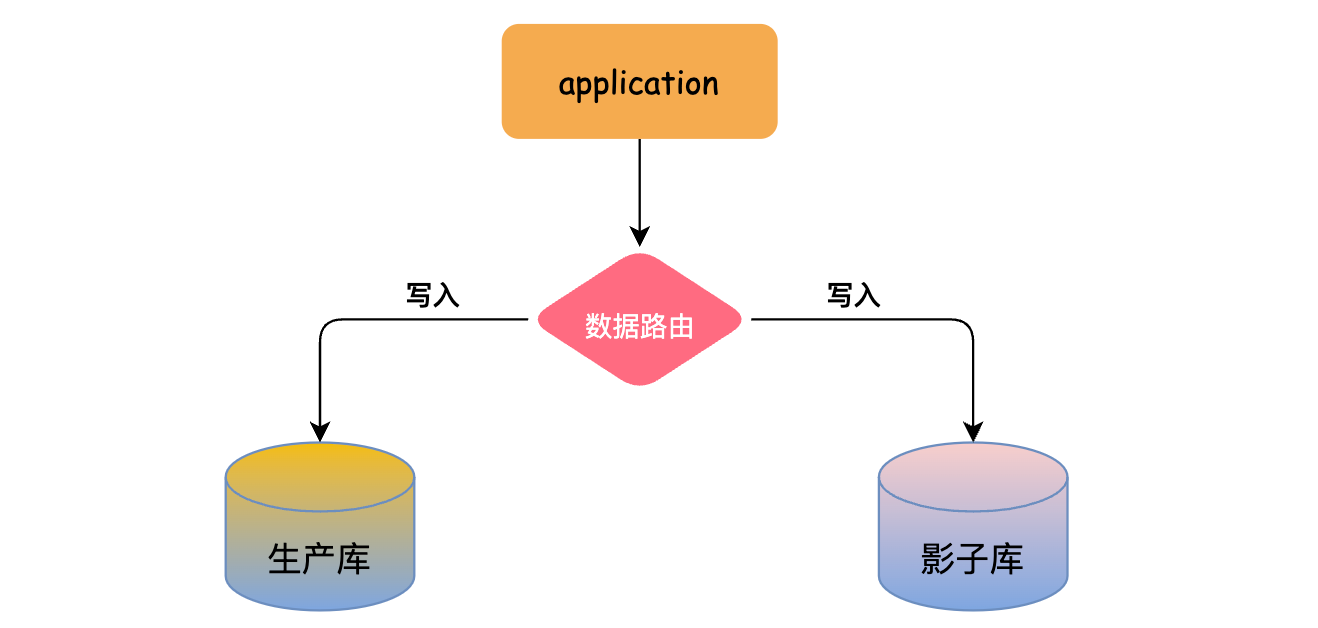
什麼是影子庫(Shadow Table)?
影子庫是一個與生產環境資料庫結構完全相同的範例,它存在的意義是為了在不影響線上系統的情況下,驗證資料庫遷移或者其他資料庫變更操作的正確性,以及全鏈路壓測。影子庫中儲存的資料是從生產環境中定期複製過來的,但是它不對線上業務產生任何影響,僅用於測試,驗證和偵錯。
在進行資料庫升級、版本變更、引數調優等操作前,通過在影子庫上模擬這些操作,可以發現潛在的問題,因為測試環境的資料是不可靠的。
在使用影子庫時,需要遵循以下幾個原則:
-
與生產環境資料庫的結構應該完全一致,包括表結構、索引、約束等;
-
資料要與生產環境保持一致,可以通過定期同步方式實現;
-
讀寫操作不會影響生產環境,一般情況下應該禁止在影子庫上執行更新、刪除等操作;
-
由於影子庫的資料特點,存取許可權應該嚴格控制,只允許授權人員進行存取和操作;
總結
本文介紹了關於分庫分表架構的21個通用概念,對有一定的瞭解之後,接下來我們將進入更深度的內容,包括讀寫分離、資料脫敏、分散式主鍵、分散式事務、設定中心、註冊中心、Proxy服務等實戰案例的講解和原始碼分析。
下期文章將是《分庫分表ShardingSphere5.x原理與實戰》系列的第三篇,《快速實現分庫分表的 2種方式》。
我是小富,下期見~