詳解叢集級備份恢復:物理細粒度備份恢復
摘要:在實際使用過程中,資料庫叢集級的故障並非高概率事件,如何安全高效地幫助客戶備份恢復一部分資料庫元素,才是更加實際的需求,這也是細粒度備份恢復的意義所在。
本文分享自華為雲社群《GaussDB(DWS)之物理細粒度備份恢復》,作者:我的橘子呢 。
1. 認識物理細粒度備份恢復
相對於叢集級備份恢復海量的檔案備份恢復操作,物理細粒度備份能夠從更小的粒度、以更少的資料檔案操作,對單庫、單表進行備份與恢復。在實際使用過程中,資料庫叢集級的故障並非高概率事件,如何安全高效地幫助客戶備份恢復一部分資料庫元素,如schema或部分表,才是更加實際的需求,這也是細粒度備份恢復的意義所在。
物理細粒度備份以小粒度如database級、schema級、表級等為單位,對資料庫檔案進行物理備份,由於相對於叢集級粒度更小,因此也更加高效實用。目前Roach工具支援的物理細粒度備份恢復功能主要包括:schema級全量備份、schema級增量備份、從細粒度備份集恢復單表/多表、從叢集級備份集(帶細粒度引數)恢復單表或多表。這些功能基本上滿足了實際使用過程中對細粒度備份恢復的要求。物理細粒度備份恢復功能圖如圖1所示。

圖1 細粒度備份恢復功能示意圖
2. 瞭解物理細粒度備份
物理細粒度的備份能力是從Roach的基線版本繼承而來的,大部分沿用了叢集級備份的設計思路,即基本的備份流程是備份行存檔案,建立一致性點,備份xlog、clog等檔案,最後備份列存檔案。物理細粒度備份在此基礎上需要進一步考慮以下幾個問題。
2.1 備份的資料內容
給定對應粒度備份任務如一張表,如何在備份最少資料的情況下保證恢復該表時資料的完整性?考慮該問題需要同時從備份資料小和資料完整性兩個方面考慮。備份資料量最小最理想的情況是隻備份資料庫中該表以及相關表對應的物理檔案,同時不考慮資料的拷貝檔案,也就是隻備份節點中主DN對應的資料檔案。然而從資料的完整性角度來說,只備份表對應的物理檔案是不夠的,為了保證恢復階段能恢復到一致性點,需要依賴xlog、clog等紀錄檔檔案,而這些檔案不能以更小的粒度劃分,因此需要全部備份。圖2列出了細粒度備份在保證資料完整性的情況下所必須備份的檔案示意圖。
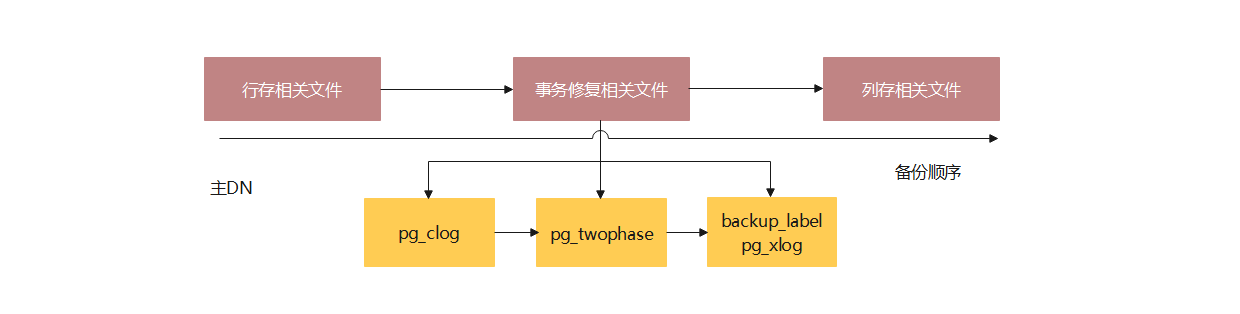
圖2 物理細粒度備份資料內容示意圖
2.2 備份集的儲存結構
現階段叢集級備份時會將資料檔案和組態檔等壓縮排同一個備份的rch檔案中,在恢復單表時需要一起獲取回來並過濾,邏輯較為混亂。因此,為了恢復時能夠更精確地獲取檔案,細粒度備份對資料備份結構進行了進一步改造,將不同型別的檔案儲存在不同的rch檔案中,以更小的粒度對儲存結構進行了劃分。如圖3所示,行列存相關的檔案儲存在data目錄下,以database為單位進行了劃分,每個database目錄下存在row目錄和col目錄,分別對應儲存行存檔案和列存檔案。archive資料夾儲存xlog相關檔案,xact檔案儲存clog相關檔案,gloabal資料夾儲存資料目錄下其他檔案。

圖3 物理細粒度備份儲存結構示意圖
2.3 備份資料相關檔案的組織形式
考慮這樣一個問題,當備份一張表時,除了備份這張表本身對應的資料檔案,我們還應該備份與這張表關聯的一些輔助表,比如列存表的cudesc表、存在變長欄位對應的toast表等,只有這樣才能保證恢復後這張表的可用性,那麼備份的時候怎麼知道該表存在哪些關聯表呢?細粒度備份採用Map檔案對錶關係進行組織,對錶所有的關聯表及檔案進行統一收集記錄。該資訊對於細粒度備份恢復至關重要,主要有以下兩個方面的作用:
(1)備份時:得到一張表的Map資訊,在備份行列存檔案時,按照Map中記錄的資訊,將表需要備份的相關檔案加入到需要備份的file_list中,後續備份時就可以按照該file_list進行檔案的備份,省去了檔案的掃描動作。
(2)恢復時:恢復時根據Map資訊,得到目標表相關的檔案記錄,就可以對應獲取所需的資料檔案,並根據表的元資訊建立恢復時的路徑對映關係。
Map檔案的生成是在備份行存檔案之前,各節點以主DN個數為單位,並行獲取Map資訊,分別生成自己的Map檔案。Map資訊的獲取,需要從多個level進行:
Agent –> Instance –> Database –> Schema –>Table –> RelatedRelations
在得到各表對應的Map資訊後,會按照一定的格式框架組織多層的json格式,並將對應的json資訊以schema為單位寫入到schemaname.map中,最終持久化儲存到媒介下後設資料目錄對應的節點級根路徑中:
/roach/backup_key/map/dn_6001_6002/databasename/schemaname.map
Map檔案對應的json儲存內容如圖4所示。

圖4 Map檔案Json格式
2.4 備份壓縮檔案與資料檔案的對映關係
考慮細粒度恢復一張表時,如何在備份集大量的rch壓縮檔案中挑選出我們想要的表在哪些rch檔案裡。細粒度備份恢復在備份過程中會生成額外的fine_file_list資訊,每張rch檔案都有一個fine_file_list檔案與之相對應。該fine_file_list檔案記錄了對應rch檔案中儲存了哪些表,在恢復時就可以根據fine_file_list找到待恢復表涉及哪些rch檔案,精準獲取必要的rch檔案,這樣就可以大幅提升細粒度恢復的效能。
只有行列存資料的rch檔案存在對應的fine_file_list檔案。fine_file_list儲存在節點元資訊目錄下對應的資料夾中:
/roach/backup_key/fine_file_list/dn_6001_6002/row/file_0_fine_list
/roach/backup_key/fine_file_list/dn_6001_6002/col/file_0_fine_list
2.5 備份表定義匯出檔案
細粒度恢復是線上進行的,在進行單表或多表恢復時需要建立出與原表定義相同的表,再進行表物理檔案的替換,這就必須知道原表的DDL元資訊。因此,在備份過程中需要同時匯出各個表的DDL元資訊。物理細粒度備份恢復利用的GaussDB(DWS)自帶的gs_dump工具對錶定義進行匯出。由於該資訊只用於恢復過程,因此在細粒度備份剛開始時會啟動gs_dump去匯出所有的表的DDL資訊,並讓備份過程與DDL匯出並行,不需要阻塞等待,減少整體物理細粒度的備份時間。DDL匯出流程如圖5所示。
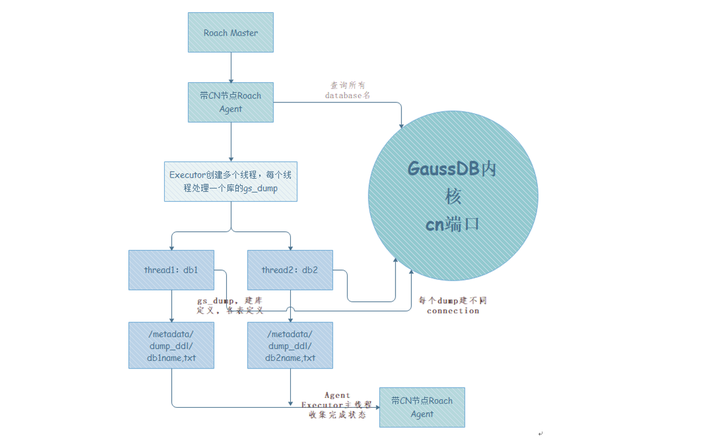
圖5 匯出DDL流程圖
匯出的DDL資訊以schema為單位儲存在節點元資訊目錄下對應的資料夾中:
/roach/backup_key/dumped_ddl/databasename.schemaname
2.6 物理細粒度備份整體流程
經過以上介紹,細粒度備份的關鍵步驟都已經清楚了,下面給出細粒度備份的整體流程圖,如圖6所示。

圖6 物理細粒度備份流程圖
3. 瞭解物理細粒度恢復
與叢集級恢復停止叢集進行資料覆蓋的方式不同,細粒度恢復採用線上恢復的方式,該方法的核心思想就是在當前叢集中建立與原表定義完全相同的目標表,再將兩張表相關的物理檔案進行一一替換。細粒度恢復的方法能夠線上進行,對現有叢集影響較小,但同時也對恢復過程資料的控制有了更高的要求。
物理細粒度恢復的大致流程如圖7所示。
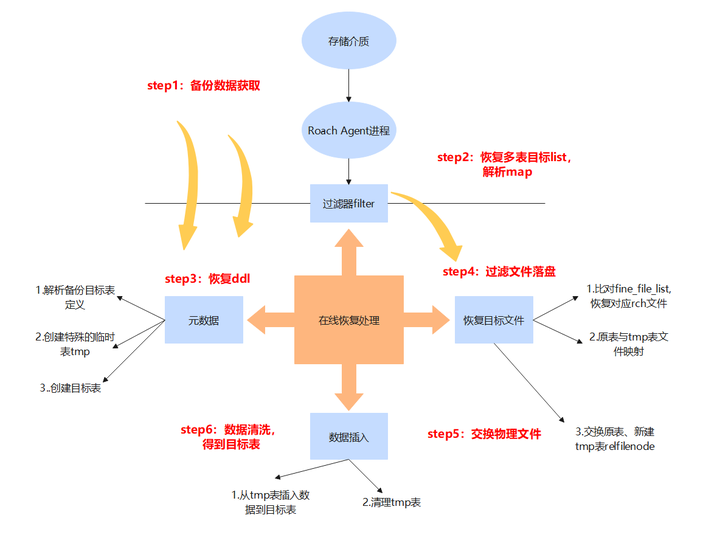
圖7 物理細粒度恢復流程圖
4. 使用物理細粒度備份恢復
GaussDB(DWS)的Roach工具現階段支援schema級的物理細粒度備份,下面介紹如何發起物理細粒度備份以及如何從細粒度備份集中恢復一張表。
4.1 獲取物理細粒度備份集
Roach工具現支援schema級的細粒度備份,如下為命令列中發起schema級物理細粒度備份的命令:

圖8 發起schema級備份
以下引數為必選引數:
- –master-port : 程序埠號
- –media-type : 儲存媒介
- –media-destination : 壓縮資料儲存路徑
- –metadata-destination : 後設資料儲存路徑
- –dbname : 資料庫名稱
- –schema-list : 多schema清單檔名,內容格式為每行一個schema名
- –physical-fine-grained : 物理細粒度引數
其中指定schema清單時如果只有一個schema,也可以直接使用–schemaname引數直接指定需要備份的schema名稱,此外,同時備份多個schema時,schema需要在同一個database下。
除了schema級別備份,為支援從叢集級備份集中細粒度恢復單表或多表,可以通過在叢集級命令中加入物理細粒度引數:–physical-fine-grained來生成細粒度恢復需要的Map檔案、fine_file_list資訊。如下為叢集級帶細粒度引數的命令:

圖9 叢集級備份帶細粒度引數
需要說明的是,帶細粒度引數的叢集級備份依然是叢集級的,只是為支援從該備份集細粒度恢復單表生成了額外的細粒度相關檔案。
4.2 從物理細粒度備份集恢復表
Roach工具現支援從細粒度備份集或(叢集級帶細粒度引數備份集)恢復單表或多表,假如當前資料庫使用者不小心刪除了一張表,又不想對停止業務對整個叢集進行恢復,如果之前做過物理細粒度相關備份,備份集中有這張表,那麼細粒度恢復就是最好的選擇。細粒度恢復可以線上進行,不影響叢集的正常使用,發起細粒度恢復的命令如下:

圖10 細粒度恢復表命令
以下引數為必選引數:
- –clean
- –master-port
- –media-type
- –media-destination
- –metadata-destination
- –backup-key : 恢復基於的備份集
- –physical-fine-grained : 物理細粒度引數
- –dbname : 資料庫名稱
- –table-list : 待恢復表列表,格式為schemaname.tablename
- –restore-target-list : 恢復後表列表,格式為schemaname.tablename
其中–table-list指定了需要恢復的哪些表,–restore-target-list指定了恢復後表的名稱,要求–restore-target-list的表順序與–table-list的表順序一一對應。如果要全部恢復到原表,則這兩個表清單可以指向相同檔案。兩個表清單引數對應的檔案內容格式是:每個表一行,且必須帶schema名。
5. 總結
細粒度備份和恢復以更小的粒度對資料檔案進行了備份恢復操作。考慮到備份資料的完整性以及備份恢復的效能,細粒度備份過程增加了ddl匯出、Map檔案生成等關鍵步驟,其中從資料目錄下的物理檔案資訊到Map資訊、再從Map資訊到備份的rch檔案對應的fine_file_list資訊,形成了對備份資料檔案連續的記錄鏈條。恢復過程中如果出現缺少資料的情況,可以通過對備份過程中以上所說資訊的互相對比快速定位到出現問題的環節,因此,掌握以上資訊十分關鍵,可以幫助我們更好地使用細粒度備份恢復功能。