飛槳Paddle動轉靜@to_static技術設計
一、整體概要
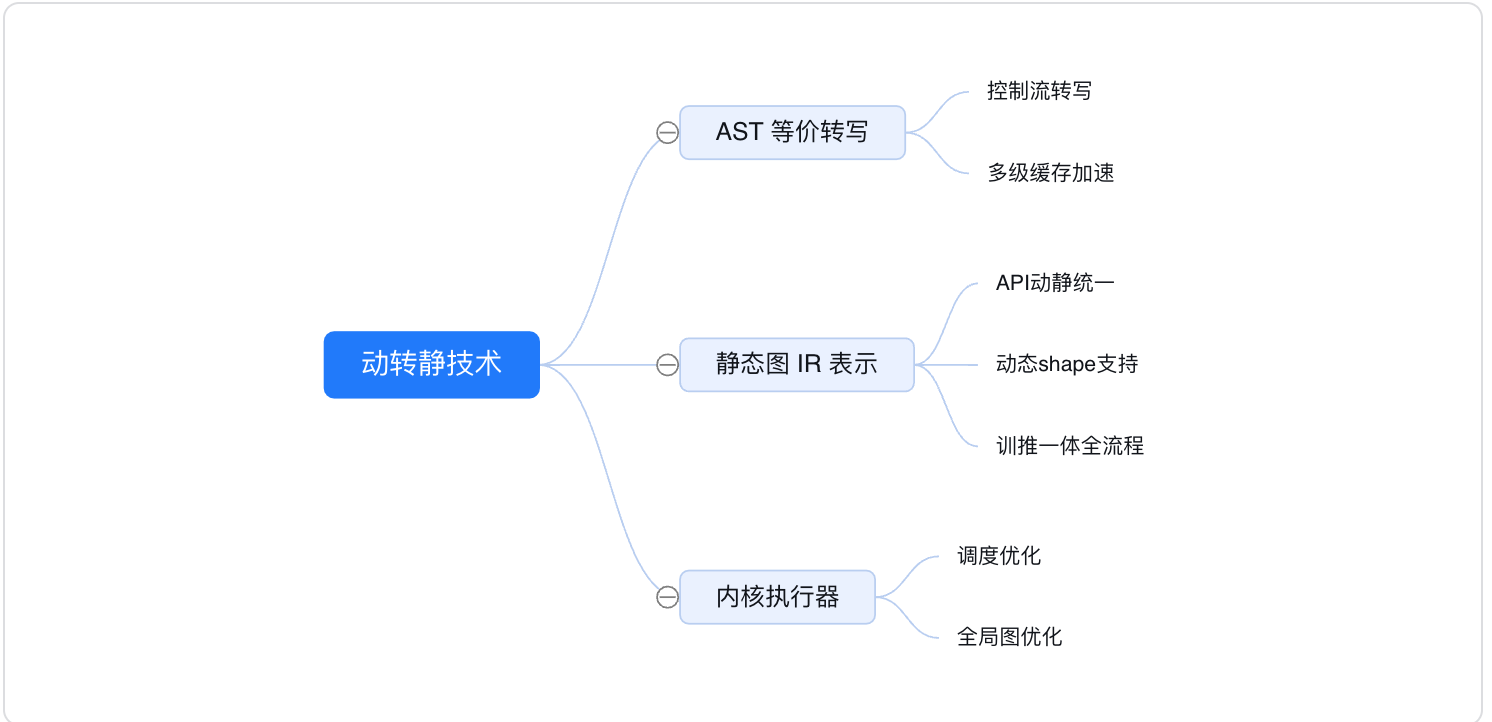
在深度學習模型構建上,飛槳框架支援動態圖程式設計和靜態圖程式設計兩種方式,其程式碼編寫和執行方式均存在差異:
- 動態圖程式設計: 採用 Python 的程式設計風格,解析式地執行每一行網路程式碼,並同時返回計算結果。
- 靜態圖程式設計: 採用先編譯後執行的方式。需先在程式碼中預定義完整的神經網路結構,飛槳框架會將神經網路描述為 Program 的資料結構,並對 Program 進行編譯優化,再呼叫執行器獲得計算結果。
動態圖程式設計體驗更佳、更易偵錯,但是因為採用 Python 實時執行的方式,開銷較大,在效能方面與 C++ 有一定差距;靜態圖偵錯難度大,但是將前端 Python 編寫的神經網路預定義為 Program 描述,轉到 C++ 端重新解析執行,脫離了 Python 依賴,往往執行效能更佳,並且預先擁有完整網路結構也更利於全域性優化。
從2.0 版本開始,Paddle預設開啟了動態圖執行模式,Paddle提供了動轉靜(@to_static)模組功能支援使用者實現動態圖程式設計,一鍵切換靜態圖訓練和部署的程式設計體驗。
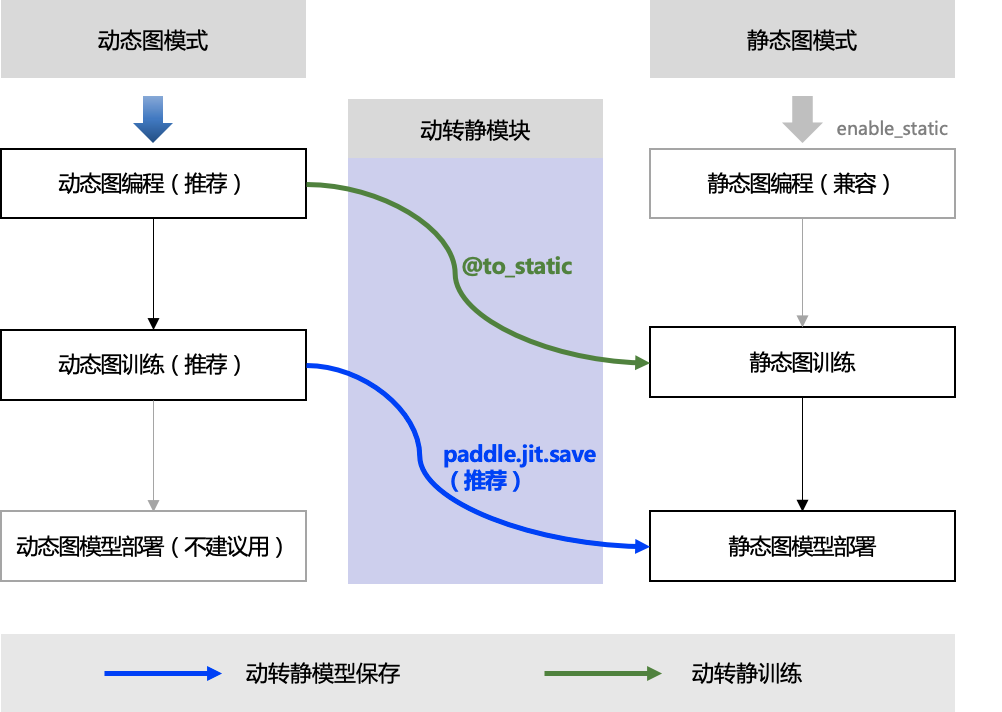
二、轉換原理
在飛槳框架內部,動轉靜模組在轉換上主要包括對輸入資料 InputSpec 的處理,對函數呼叫的遞迴轉寫,對 IfElse、For、While 控制語句的轉寫,以及 Layer 的 Parameters 和 Buffers 變數的轉換。如下是動轉靜模組的轉換技術大致流程:
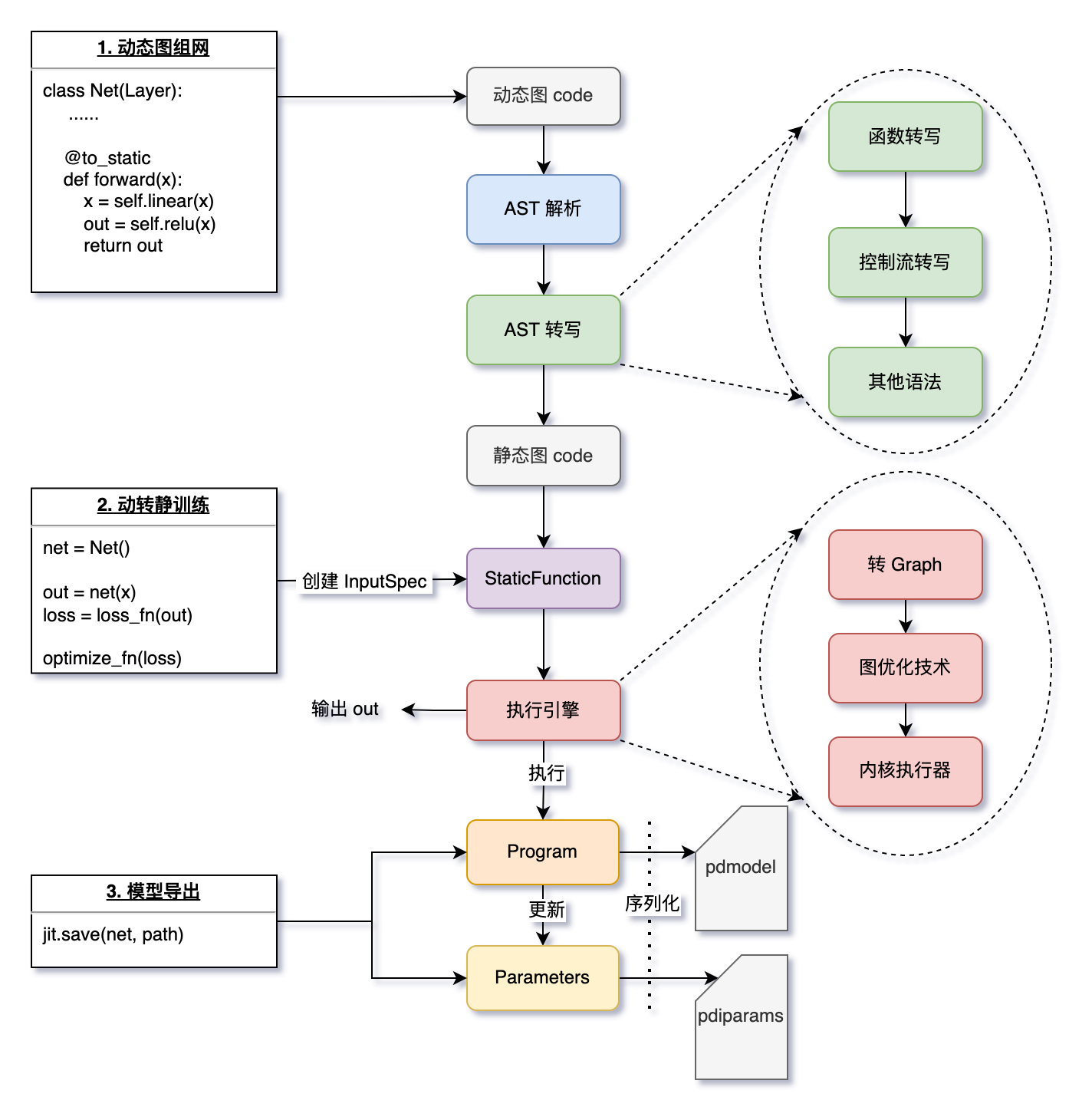
2.1 AST 解析動態圖程式碼
當某個函數被 @to_static 裝飾、或用 paddle.jit.to_static() 包裹時,飛槳會隱式地解析動態圖的 Python 程式碼(即解析:抽象語法樹,簡稱 AST)。
2.2 AST 轉寫,得到靜態圖程式碼
- 函數轉寫:遞迴地對所有函數進行轉寫,實現使用者僅需在最外層函數新增 @to_static 的體驗效果。
- 控制流轉寫:使用者的程式碼中可能包含依賴 Tensor 的控制流程式碼,飛槳框架會自動且有選擇性地將 if、for、while 轉換為靜態圖對應的控制流。
- 其他語法處理:包括 break、continue、assert、提前 return 等語法的處理。
2.3 生成靜態圖的 Program 和 Parameters
- 得到靜態圖程式碼後,根據使用者指定的 InputSpec 資訊(或訓練時根據實際輸入 Tensor 隱式建立的 InputSpec)作為輸入,執行靜態圖程式碼生成 Program。每個被裝飾的函數,都會被替換為一個 StaticFunction 物件,其持有此函數對應的計算圖 Program,在執行 paddle.jit.save 時會被用到。
- 對於 trainable=True 的 Buffers 變數,動轉靜會自動識別並將其和 Parameters 一起儲存到 .pdiparams 檔案中。
2.4 執行動轉靜訓練
- 使用執行引擎執行函數對應的 Program,返回輸出 out。
- 執行時會根據使用者指定的 build_strategy 策略應用圖優化技術,提升執行效率。
2.5使用 paddle.jit.save 儲存靜態圖模型
- 使用 paddle.jit.save 時會遍歷模型 net 中所有的函數,將每個的 StaticFunction 中的計算圖 Program 和涉及到的 Parameters 序列化為磁碟檔案。
三、轉靜組網流程
3.1 樣例解讀
import numpy as np
import paddle
import paddle.nn as nn
class LinearNet(paddle.nn.Layer):
def __init__(self):
super(LinearNet, self).__init__()
self._linear = nn.Linear(10, 3)
@paddle.jit.to_static
def forward(self, x):
y = self._linear(x)
return y
# create network
layer = LinearNet()
adam = opt.Adam(learning_rate=0.001, parameters=layer.parameters())
for batch_id, x in enumerate(data_loader()):
out = layer(image)
loss = paddle.mean(out)
loss.backward()
opt.step()
opt.clear_grad()
檔案開始的樣例中 forward 函數包含一行組網程式碼: Linear 。以 Linear 為例,在 Paddle 的框架底層,每個 Paddle 的組網 API 的實現包括兩個分支:
class Linear(...):
def __init__(self, ...):
# ...(略)
def forward(self, input):
if in_dygraph_mode(): # 動態圖分支
core.ops.matmul(input, self.weight, pre_bias, ...)
return out
else: # 靜態圖分支
self._helper.append_op(type="matmul", inputs=inputs, ...) # <----- 生成一個 Op
if self.bias is not None:
self._helper.append_op(type='elementwise_add', ...) # <----- 生成一個 Op
return out
動態圖 layer 生成 Program ,其實是開啟 paddle.enable_static() 時,在靜態圖下逐行執行使用者定義的組網程式碼,依次新增(對應append_op 介面) 到預設的主 Program(即 main_program ) 中。當呼叫 loss.backward() 函數時,飛槳框架會根據loss的計算路徑,進行反向自動鏈式求導生成對應的反向靜態圖子圖。

上面提到,所有的組網程式碼都會在靜態圖模式下執行,以生成完整的 Program 。但靜態圖 append_op 有一個前置條件必須滿足:
- 前置條件:append_op() 時,所有的 inputs,outputs 必須都是靜態圖的 Variable 型別,不能是動態圖的 Tensor 型別。
- 原因:靜態圖下,操作的都是描述類單元:計算相關的 OpDesc ,資料相關的 VarDesc 。可以分別簡單地理解為 Program 中的 Op 和 Variable 。
因此,在動轉靜時,我們在需要在某個統一的入口處,將動態圖 Layers 中 Tensor 型別(包含具體資料)的 Weight 、Bias 等變數轉換為同名的靜態圖 Variable。
- ParamBase → Parameters
- VarBase → Variable
技術實現上,我們選取了框架層面給飛槳靜態圖 Program 新增運算元的 append_op 函數作為型別轉換的統一入口:即 Block.append_op 函數中,生成 Op 之前
def append_op(self, *args, **kwargs):
if in_dygraph_mode():
# ... (動態圖分支)
else:
inputs=kwargs.get("inputs", None)
outputs=kwargs.get("outputs", None)
# param_guard 會確保將 Tensor 型別的 inputs 和 outputs 轉為靜態圖 Variable
with param_guard(inputs), param_guard(outputs):
op = Operator(
block=self,
desc=op_desc,
type=kwargs.get("type", None),
inputs=inputs,
outputs=outputs,
attrs=kwargs.get("attrs", None))
3.2 一鍵遞迴轉寫
Python語言的靈活性對動轉靜模組要求極高。相對於靜態圖程式設計,動態圖下完全繼承了Python語言的靈活性,因此對動轉靜的語法功能實現要求很高,既要兼顧對原生Python語法的支援,也要保證靜態圖介面的正確轉換,在API使用上要儘量減少使用者使用的成本。飛槳擴充套件優化了動轉靜核心API@to_static介面功能,除了支援裝飾器模式之外,並實現使用者實現僅需一行程式碼即可一鍵遞迴轉成靜態圖,極大的減少了使用者動轉靜時的程式碼改寫量,提升了功能的易用性和使用者的使用體驗。
一鍵遞迴轉寫,得益於飛槳動轉靜的自動遞迴轉寫技術元件。通過藉助對Python抽象語法樹(下簡稱:AST)的解析,感知使用者的函數呼叫棧資訊,逐層對內部巢狀函數進行動態解析和轉寫,模擬實現「自動遞迴」的效果。為了減少同一函數的重複轉寫,飛槳新引入了兩級快取機制:即函數轉寫快取和Program轉寫快取。
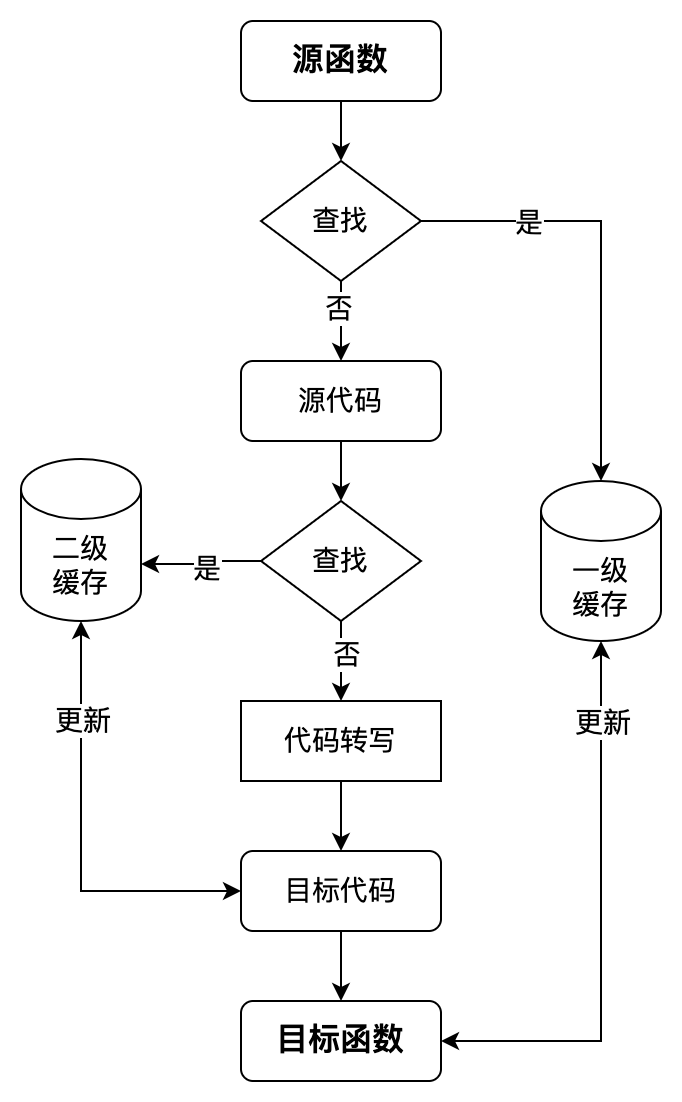
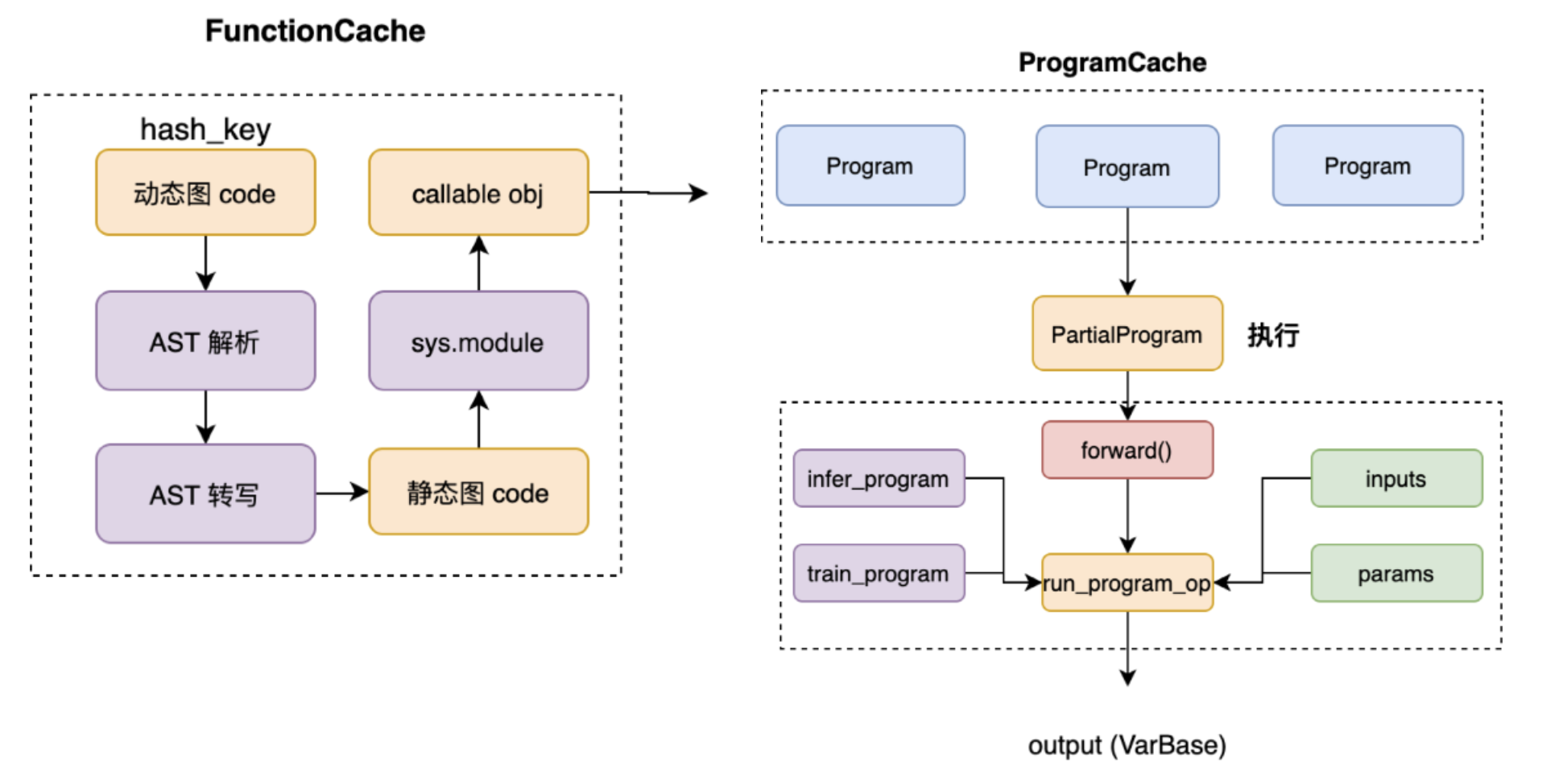
函數轉寫快取指對於同一個函數,在第一次轉寫時會快取轉寫結果,在出現函數重複呼叫時直接命中快取,減少相同code的AST抽象語法樹解析和轉寫開銷,達到複用的效果;Program轉寫快取指對於同一個模型在每輪迭代執行時,會自動根據輸入張量的shape、dtype資訊,快取已轉寫的Program,避免訓練時每個step重複轉寫Program。
四、 動轉靜訓練
在飛槳框架中,通常情況下使用動態圖訓練,即可滿足大部分場景需求。 飛槳經過多個版本的持續優化,動態圖模型訓練的效能已經可以和靜態圖媲美。如果在某些場景下確實需要使用靜態圖模式訓練,則可以使用動轉靜訓練功能,即仍然採用更易用的動態圖程式設計,新增少量程式碼,便可在底層轉為靜態圖訓練。
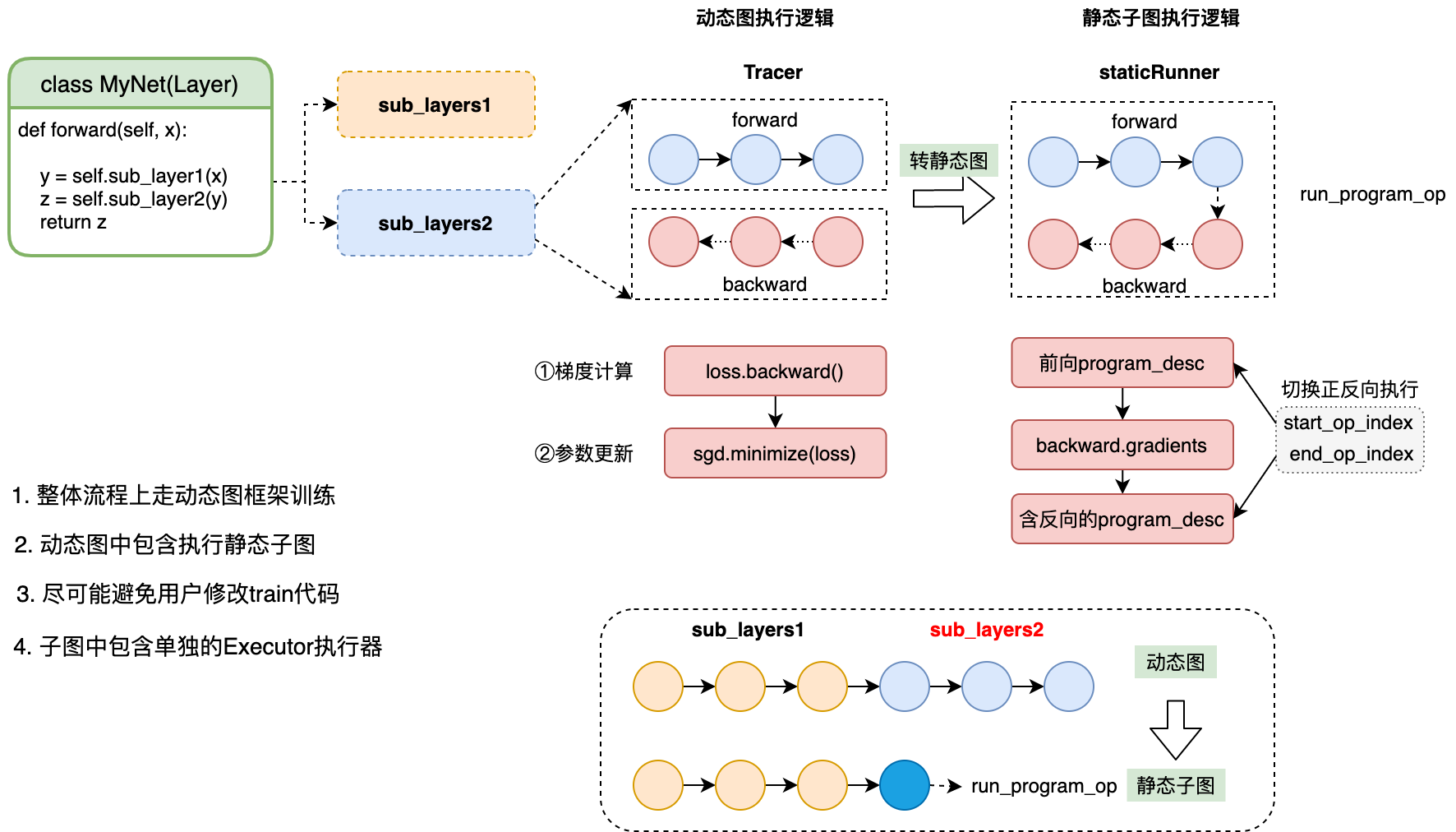
當用戶在組網入口的forward函數處新增裝飾器@to_static,會將此函數內的所 有subLayers 轉化為一個靜態子圖,並分別執行。
在如下場景時可以考慮使用動轉靜進行模型訓練,帶來的效能提升效果較明顯:
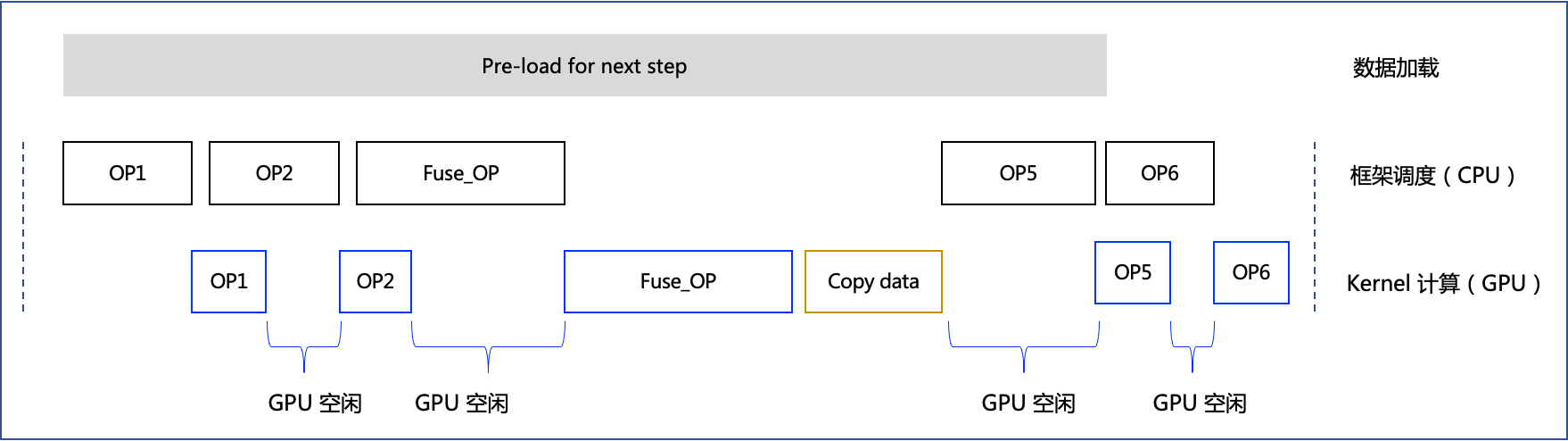
- 如果發現模型訓練 CPU 向 GPU 排程不充分的情況下。如下是模型訓練時執行單個 step 的 timeline 示意圖,框架通過 CPU 排程底層 Kernel 計算,在某些情況下,如果 CPU 排程時間過長,會導致 GPU 利用率不高(可終端執行
watch -n 1 nvidia-smi觀察)。

動態圖和靜態圖在 CPU 排程層面存在差異:
- 動態圖訓練時,CPU 排程時間涉及 Python 到 C++ 的互動(Python 前端程式碼調起底層 C++ OP)和 C++ 程式碼排程;
- 靜態圖訓練時,是統一編譯 C++ 後執行,CPU 排程時間沒有 Python 到 C++ 的互動時間,只有 C++ 程式碼排程,因此比動態圖排程時間短。
因此如果發現是 CPU 排程時間過長,導致的 GPU 利用率低的情況,便可以採用動轉靜訓練提升效能。從應用層面看,如果模型任務本身的 Kernel 計算時間很長,相對來說排程到 Kernel 拉起造成的影響不大,這種情況一般用動態圖訓練即可,比如 Bert 等模型,反之如 HRNet 等模型則可以觀察 GPU 利用率來決定是否使用動轉靜訓練。
如果想要進一步對計算圖優化,以提升模型訓練效能的情況下。相對於動態圖按一行行程式碼解釋執行,動轉靜後飛槳能夠獲取模型的整張計算圖,即擁有了全域性視野,因此可以藉助運算元融合等技術對計算圖進行區域性改寫,替換為更高效的計算單元,我們稱之為「圖優化」。如下是應用了運算元融合策略後,模型訓練時執行單個 step 的 timeline 示意圖。相對於圖 2,飛槳框架獲取了整張計算圖,按照一定規則匹配到 OP3 和 OP4 可以融合為 Fuse_OP,因此可以減少 GPU 的空閒時間,提升執行效率。
五、 動轉靜匯出部署
動轉靜模組是架在動態圖與靜態圖的一個橋樑,旨在打破動態圖模型訓練與靜態部署的鴻溝,消除部署時對模型程式碼的依賴,打通與預測端的互動邏輯。下圖展示了動態圖模型訓練——>動轉靜模型匯出——>靜態預測部署的流程。
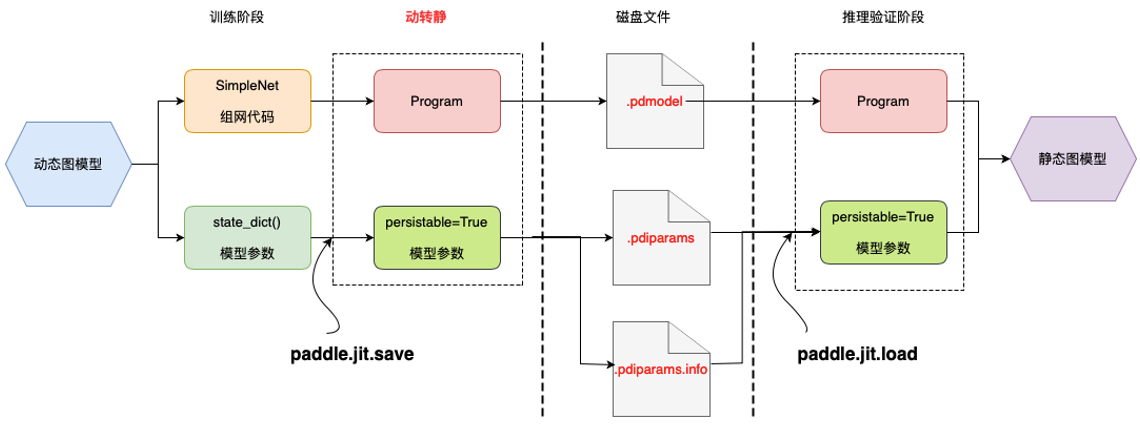
在處理邏輯上,動轉靜主要包含兩個主要模組:
- 程式碼層面:將模型中所有的 layers 介面在靜態圖模式下執行以轉為 Op ,從而生成完整的靜態 Program
- Tensor層面:將所有的 Parameters 和 Buffers 轉為可匯出的 Variable 引數( persistable=True )
通過 forward 匯出預測模型匯出一般包括三個步驟:
- 切換 eval() 模式:類似 Dropout 、LayerNorm 等介面在 train() 和 eval() 的行為存在較大的差異,在模型匯出前,請務必確認模型已切換到正確的模式,否則匯出的模型在預測階段可能出現輸出結果不符合預期的情況。
- 構造 InputSpec 資訊:InputSpec 用於表示輸入的shape、dtype、name資訊,且支援用 None 表示動態shape(如輸入的 batch_size 維度),是輔助動靜轉換的必要描述資訊。
- 呼叫 save 介面:呼叫 paddle.jit.save介面,若傳入的引數是類範例,則預設對 forward 函數進行 @to_static 裝飾,並匯出其對應的模型檔案和引數檔案。
如下是一個簡單的範例:
import paddle
from paddle.jit import to_static
from paddle.static import InputSpec
class SimpleNet(paddle.nn.Layer):
def __init__(self):
super(SimpleNet, self).__init__()
self.linear = paddle.nn.Linear(10, 3)
def forward(self, x, y):
out = self.linear(x)
out = out + y
return out
def another_func(self, x):
out = self.linear(x)
out = out * 2
return out
net = SimpleNet()
# train(net) 模型訓練 (略)
# step 1: 切換到 eval() 模式
net.eval()
# step 2: 定義 InputSpec 資訊
x_spec = InputSpec(shape=[None, 3], dtype='float32', name='x')
y_spec = InputSpec(shape=[3], dtype='float32', name='y')
# step 3: 呼叫 jit.save 介面
net = paddle.jit.save(net, path='simple_net', input_spec=[x_spec, y_spec]) # 動靜轉換
執行上述程式碼樣例後,在當前目錄下會生成三個檔案,即代表成功匯出預測模型:
simple_net.pdiparams // 存放模型中所有的權重資料
simple_net.pdmodel // 存放模型的網路結構
simple_net.pdiparams.info // 存放額外的其他資訊