通過空間佔用和執行計劃瞭解SQL Server的行儲存索引
1 索引介紹
索引是一種幫助查詢語句能夠快速定位到資料的一種技術。索引的儲存方式有行儲存索引、列儲存索引和記憶體優化三種儲存方式:
- 行儲存索引,使用B+樹結構,行儲存指的是資料儲存格式為堆、聚集索引和記憶體優化表的表,用於OLTP場景。行儲存索引按順序排列的值列表,每個值都有指向其所在的資料頁面的指標。
- 聚集索引
- 非聚集索引
- 唯一索引
- 篩選索引
- 列儲存索引,使用列結構儲存,列儲存指的是在邏輯上整理為包含行和列的表,實際上以列式資料格式儲存的資料,用於OLAP場景。使用基於列的資料儲存和查詢處理。
- 聚集列儲存
- 非聚集列儲存
- 記憶體優化索引,使用Bw樹儲存,Bw樹使用一種「旋轉」技術,更適合處理處理範圍查詢和隨機插入/刪除操作,適用於各種場景下的資料儲存和查詢。
本文中我們討論的索引就是行儲存索引中的聚集索引和非聚集索引,不涉及其它索引。
Bw樹使用一組新的旋轉技術,支援更加高效的範圍查詢操作。而B+樹則使用葉節點連結串列來處理範圍查詢。在B+樹中,如果您需要範圍查詢,您需要遍歷整個連結串列,這會增加查詢的時間成本。相比之下,Bw樹通過一些特殊的旋轉操作,能夠使得範圍查詢操作更加高效,從而顯著提高查詢效能。
假設需要查詢數位在100到200之間的資料,那麼B+樹需要遍歷相應的葉節點連結串列,而Bw樹則可以使用一些特殊的旋轉操作,跳過某些節點,快速定位到相應的資料範圍,從而減少了查詢的時間成本。
總體來說,Bw樹在範圍查詢和隨機操作等特殊情況下比B+樹更加高效。但是對於其他型別的查詢操作,它們的效能並沒有很大的區別,具體的效果需要根據應用場景來進行具體分析。
2 行儲存索引的資料組織結構
聚集索引和非聚集索引都是使用B+樹結構組織的,最頂層稱為根節點,中間層稱為中間節點,最底層稱為葉節點。在聚集索引中,葉節點包含了基礎表的資料頁,根節點和中間節點包含了索引行的索引頁,每個索引行包含一個鍵值和一個指標,通過指標來找到某個葉節點的資料行。而在非聚集索引中,葉節點只包含了索引行的索引頁,沒有資料頁,它的索引行中只有指標,通過指標來找到對應的堆表的RID或者聚集索引的資料頁。
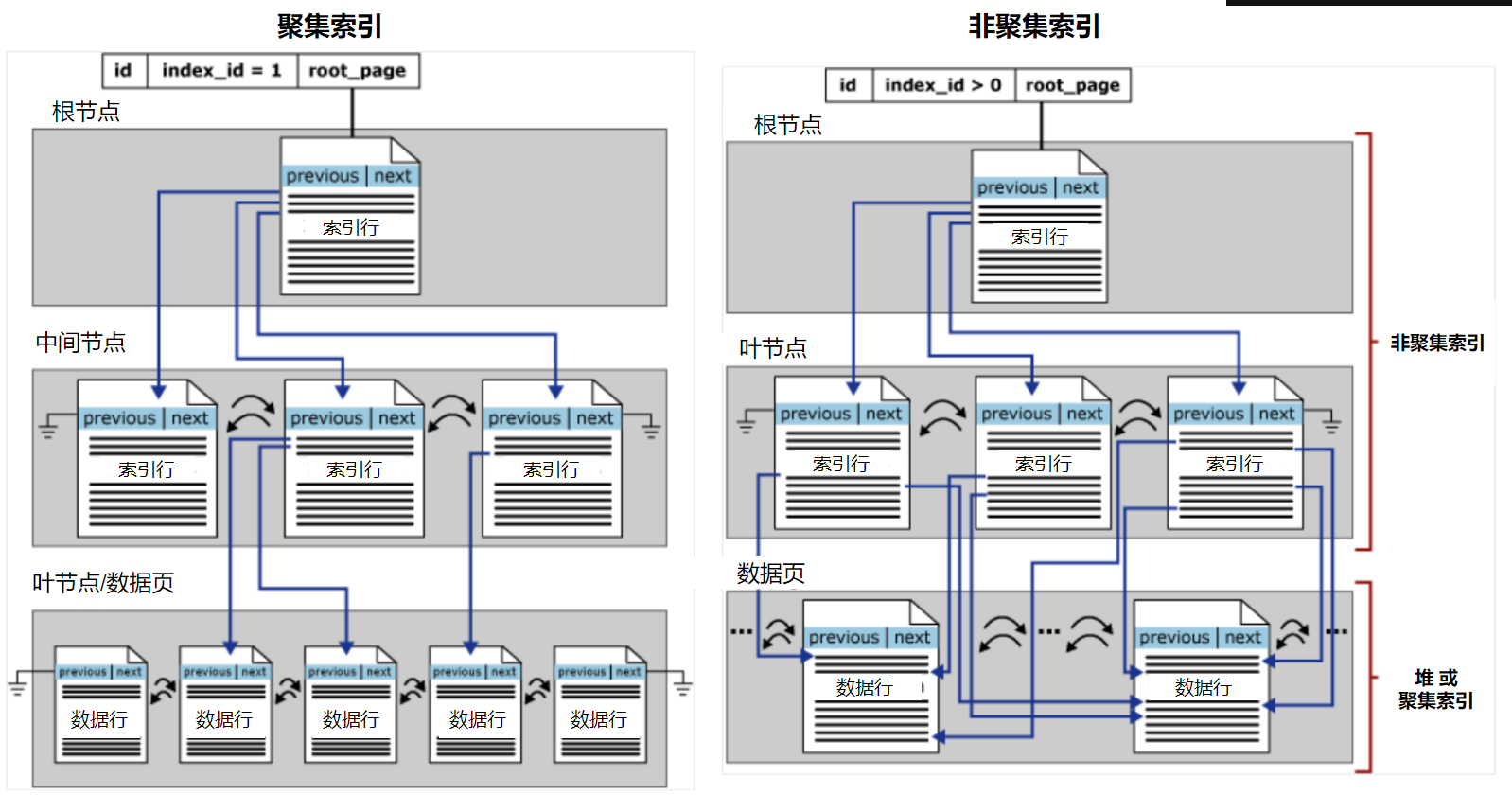
聚集索引決定了表中資料行的儲存順序(升序/降序),所以每張表只能有1個聚集索引,可以使用CREATE CLUSTERED INDEX來手動建立聚集索引,也可以是在建表時指定主鍵的方式來自動建立。
每張表可以有多個非聚集索引,可以針對不同的查詢語句和業務場景來建立非聚集索引,只能是使用CREATE NONCLUSTERED INDEX來手動建立非聚集索引。
3 兩種索引的空間佔用對比
由於聚集索引的葉節點儲存了是資料頁,由中間節點存放了指標,而非聚集索引的葉節點存放了指標(行定位器),那通過B+樹的構造,可以大概判斷是非聚集索引要消耗的空間更多,因為非聚集索引要存放更多的指標資訊(葉節點的數量肯定會比中間節點的數量多)。
3.1 使用sp_spaceused檢視索引大小
- 檢視基礎表order_line,目前行數1232537行,資料大小約80MB,未建立索引。
使用exec sp_spaceused order_line命令檢視。

- 在order_line表的
ol_w_id、ol_d_id、ol_o_id和ol_number列上建立聚簇索引order_line_i1_clusteredCREATE UNIQUE CLUSTERED INDEX [order_line_i1_clustered] ON [dbo].[order_line] ( [ol_w_id] ASC, [ol_d_id] ASC, [ol_o_id] ASC, [ol_number] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = OFF, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] GO - 檢視表的索引大小,約232KB,說明聚簇索引
order_line_i1_clustered的大小為232KB-24KB=208KB。
使用exec sp_spaceused order_line命令檢視。

- 在order_line表的ol_w_id、ol_d_id、ol_o_id和ol_number列上建立非聚簇索引
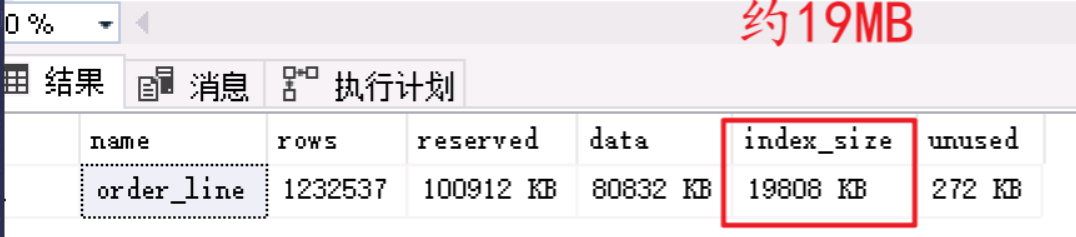
order_line_i1_nonclusteredCREATE UNIQUE CLUSTERED INDEX [order_line_i1_clustered] ON [dbo].[order_line] ( [ol_w_id] ASC, [ol_d_id] ASC, [ol_o_id] ASC, [ol_number] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = OFF, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] GO - 檢視表的索引大小,約19MB,說明非聚簇索引
order_line_i1_clustered的大小為18MB~19MB。
使用exec sp_spaceused order_line命令檢視。
3.2 使用DBCC檢視索引大小
我們也可以通過另外一種方式來證明,通過查詢索引ID,再使用dbcc ind將索引的所有頁返回,然後再計算索引頁的結果
- 首先檢視兩個表的查詢索引ID
SELECT t.name AS TableName,i.name AS IndexName,i.index_id,i.type_desc FROM sys.dm_db_partition_stats AS s INNER JOIN sys.indexes AS i ON s.object_id = i.object_id AND s.index_id = i.index_id INNER JOIN sys.tables AS t ON t.object_id = i.object_id WHERE t.name='order_line'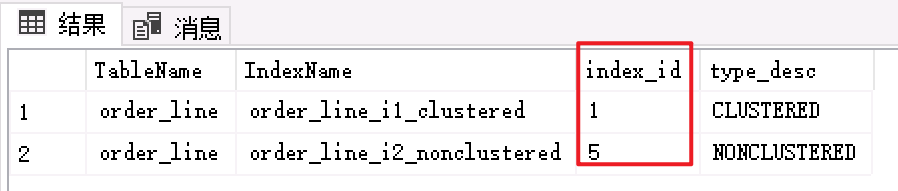
- 將兩個索引的DBCC IND結果輸出到dbcc_ind_result表中,然後計算索引的大小
CREATE TABLE dbcc_ind_result ( PageFID int, PagePID int, IAMFID int, IAMPID int, ObjectID int, IndexID int, PartitionNumber int, PartitionID bigint, iam_chain_type varchar(30), PageType int, IndexLevel int, NextPageFID int, NextPagePID int, PrevPageFID int, PrevPagePID int ); GO INSERT INTO dbcc_ind_result exec('DBCC IND(0,order_line,1)'); GO INSERT INTO dbcc_ind_result exec('DBCC IND(0,order_line,5)'); GO SELECT d.IndexID,i.name,COUNT(*) AS PageCount,COUNT(*)*8 AS SizeKB FROM dbcc_ind_result d INNER JOIN sys.indexes AS i ON d.ObjectID = i.object_id AND d.IndexID = i.index_id WHERE d.PageType=2 GROUP BY d.IndexID,i.name GO
實驗證明,在相同的列上,非聚集索引比聚集索引需要更多的空間來存放指標資訊(行定位器),消耗更多的空間。
4 兩種索引讀取資料的方式
前文提到聚集索引的葉節點存放的是資料頁,而非聚集索引葉節點存放的是指標來指向資料的位置,資料的位置可以是堆(head)的RID,也可以時聚集索引的葉節點。下面建立一張測試表來驗證。
4.1 未建立索引時
- 建立測試表,生產10000行測試資料
DROP TABLE IF EXISTS dbo.Test1; CREATE TABLE dbo.Test1 ( C1 INT, C2 INT); WITH Nums AS (SELECT TOP (10000) ROW_NUMBER() OVER (ORDER BY (SELECT 1)) AS n FROM master.sys.all_columns AS ac1 CROSS JOIN master.sys.all_columns AS ac2) INSERT INTO dbo.Test1 ( C1, C2) SELECT n, 2 FROM Nums; - 開啟統計資訊和執行計劃功能, 從10000行中查詢1行資料,例如查詢C1列為1000的資料。

執行後可以看到統計資訊項,發生了22個邏輯讀:SET STATISTICS TIME; SET STATISTICS IO; SELECT t.C1,t.C2 FROM dbo.Test1 AS t WHERE C1 = 1000;- 表 'Test1'。掃描計數 1,邏輯讀取 22 次,物理讀取 0 次,預讀 0 次,lob 邏輯讀取 0 次,lob 物理讀取 0 次,lob 預讀 0 次。
- 並且執行計劃中使用了全表掃描,需要讀取10000行資料。

4.2 建立非聚集索引後
在C1列建立1個非聚集索引後,再觀察統計資訊和執行計劃是否發生變化
- 建立非聚集索引
建立非聚集索引的過程中,消耗了和前一個查詢相同的資源,統計資訊一樣:CREATE NONCLUSTERED INDEX incl ON dbo.Test1(C1);- 表 'Worktable'。掃描計數 0,邏輯讀取 0 次,物理讀取 0 次,預讀 0 次,lob 邏輯讀取 0 次,lob 物理讀取 0 次,lob 預讀 0 次。
- 表 'Test1'。掃描計數 1,邏輯讀取 22 次,物理讀取 0 次,預讀 0 次,lob 邏輯讀取 0 次,lob 物理讀取 0 次,lob 預讀 0 次。
- 執行相同的查詢語句,觀察統計資訊和執行計劃
這一次統計資訊發生了變化,比沒有索引的情況下消耗的邏輯讀更少,只發生了3個邏輯讀:- 表 'Test1'。掃描計數 1,邏輯讀取 3 次,物理讀取 0 次,預讀 0 次,lob 邏輯讀取 0 次,lob 物理讀取 0 次,lob 預讀 0 次。
- 而執行計劃則由Table SCAN變為了Index Seek和RID,先是掃描非聚集索引中特定範圍的行,該行的指標資訊為
Bmk1000,再將該指標資訊到堆中的RID,再返回資料,這個過程在表中只需要讀取1行資料。

4.3 建立聚集索引後
在非聚集索引的基礎上,我們再建立一個聚集索引,通過語句的執行計劃來了解讀取資料的方式。
- 建立聚集索引
建立聚集索引的過程中,產生的統計資訊要比非聚集要多,消耗資源也要更多:CREATE CLUSTERED INDEX icl ON dbo.Test1(C1);- 表 'Test1'。掃描計數 1,邏輯讀取 22 次,物理讀取 0 次,預讀 0 次,lob 邏輯讀取 0 次,lob 物理讀取 0 次,lob 預讀 0 次。
- 表 'Test1'。掃描計數 1,邏輯讀取 24 次,物理讀取 0 次,預讀 0 次,lob 邏輯讀取 0 次,lob 物理讀取 0 次,lob 預讀 0 次。
再來看看執行計劃,由於再4.2中建立了非聚集索引,執行計劃裡將建立聚集索引的操作拆成了兩條語句,並且還是INSERT語句: - 查詢1:首先還是對錶進行了一次全表掃描,並且按照升序的方式進行了排序後,再將資料插入到聚集索引裡面。這裡對應的就是邏輯讀取
22次這條統計資訊,完成了整個聚集索引的建立。 - 查詢2:然後對整個聚集索引掃描,並將非聚集索引的指標資訊更新為聚集索引的葉節點。這裡對應的就是邏輯讀取
24次這條統計資訊,完成了整個非聚集索引的指標資訊更新。

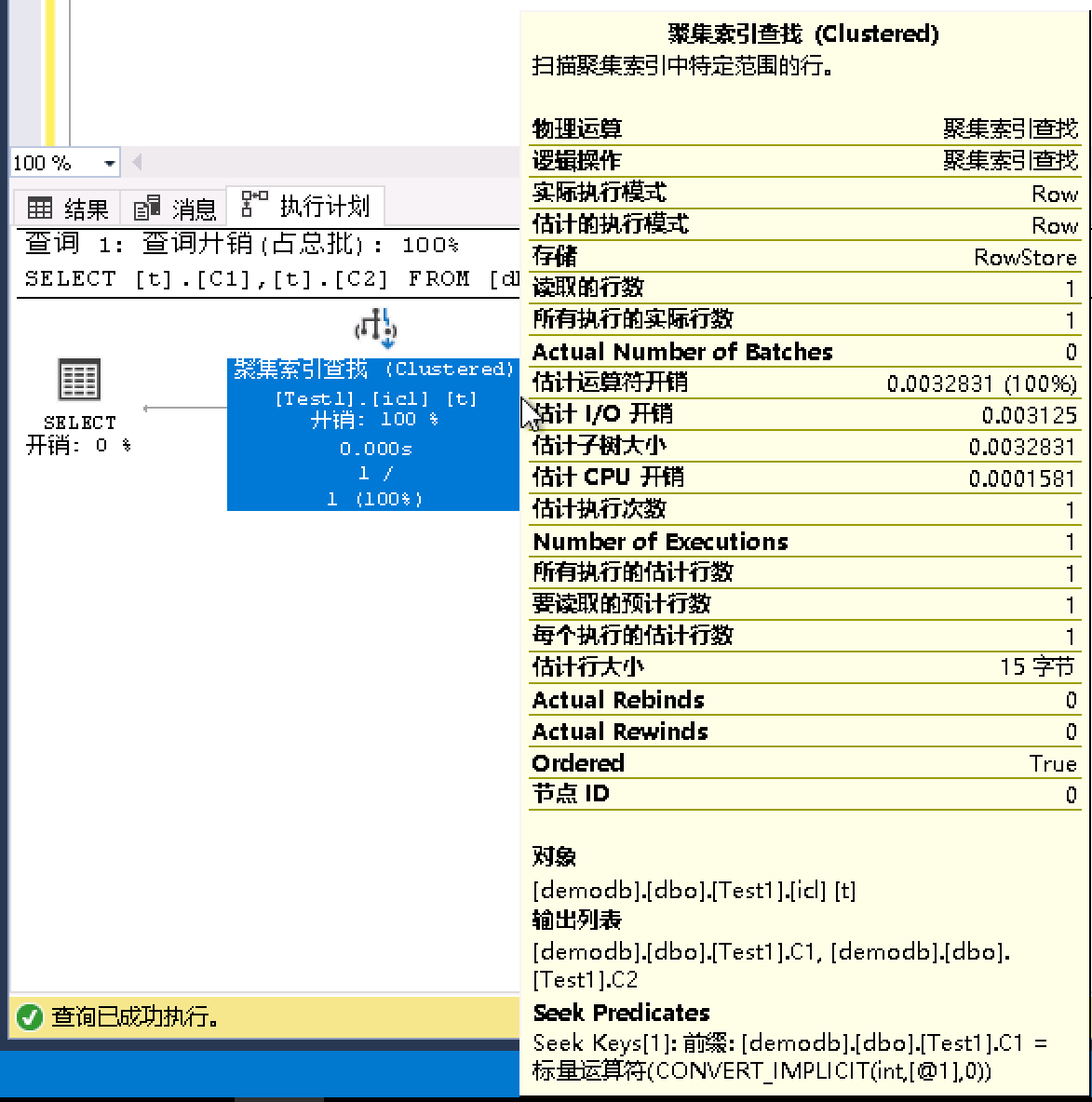
- 再次執行相同的查詢語句,消耗的邏輯讀比非聚集索引要少,只需要2次邏輯讀
- 表 'Test1'。掃描計數 1,邏輯讀取 2 次,物理讀取 0 次,預讀 0 次,lob 邏輯讀取 0 次,lob 物理讀取 0 次,lob 預讀 0 次。
- 執行計劃也不再需要使用非聚集索引和堆的RID返回資料
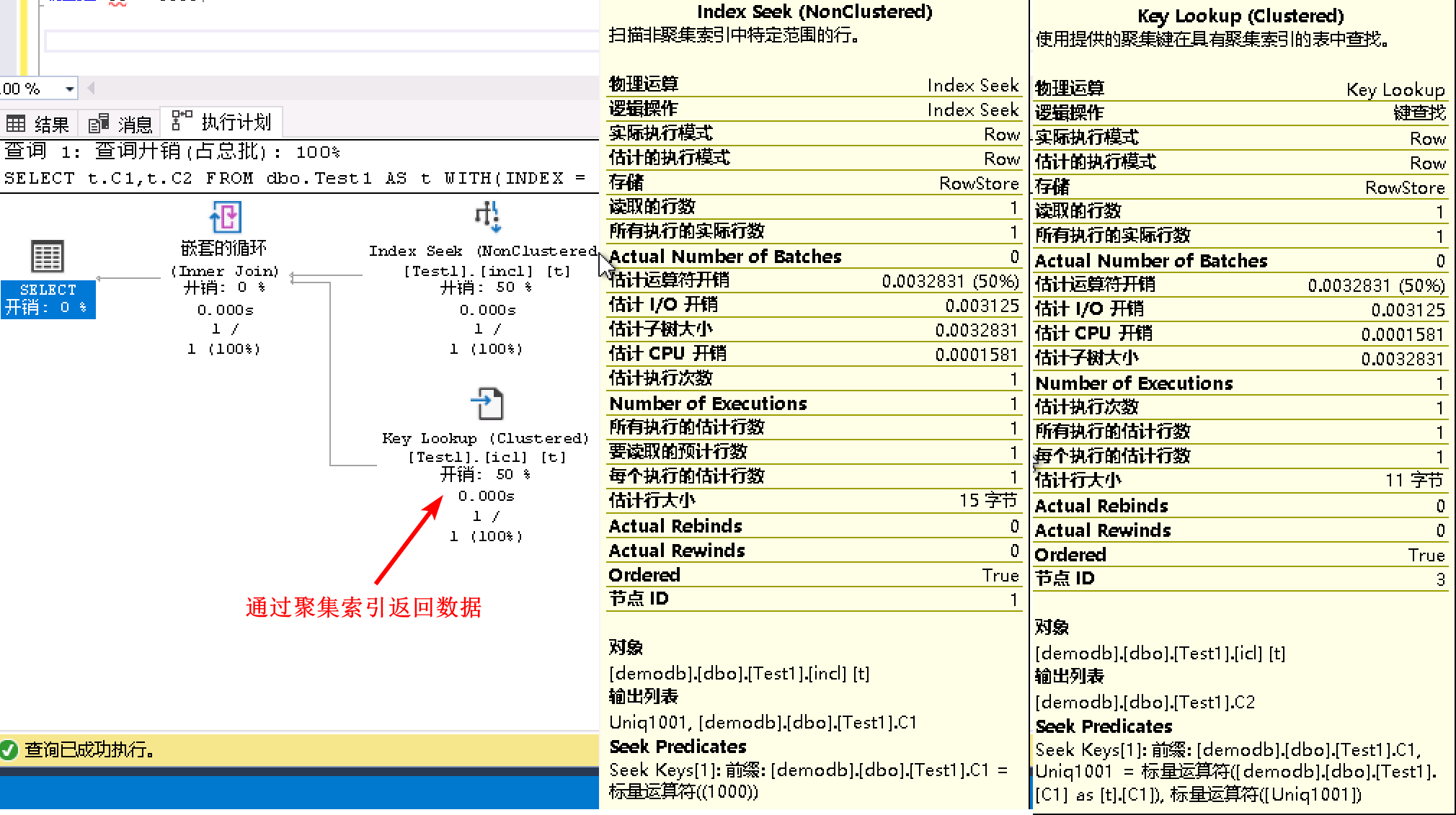
- 繼續驗證非聚集索引是否會通過聚集索引來返回資料,需要使用提示語法來固定語句使用非聚集索引。
發現這種讀取資料的方式要消耗更多的邏輯讀,比RID多了1次邏輯讀,比聚集索引多了2次邏輯讀:SELECT t.C1,t.C2 FROM dbo.Test1 AS t WITH(INDEX = incl) WHERE C1 = 1000;- 表 'Test1'。掃描計數 1,邏輯讀取 4 次,物理讀取 0 次,預讀 0 次,lob 邏輯讀取 0 次,lob 物理讀取 0 次,lob 預讀 0 次。
- 執行計劃中先到非聚集索引查詢
C1=1000所在的行,然後再將輸出的指標資訊Uniq1001到聚集索引中執行鍵值查詢,返回資料。
5 行儲存索引的基礎總結
行儲存索引的聚集索引和非聚集索引在生產環境上普遍都會使用到,在本文的基礎上,我們進行簡單總結。
- 在資料組織結構上
聚集索引的葉節點儲存的是資料頁,決定了表資料的排序方式;非聚集索引的葉節點儲存的是指標(行定位器),有可能是堆的RID,也有可能是聚集索引的指標。 - 在空間佔用上
聚集索引只需要很小的空間來儲存資料頁的資訊和順序;非聚集索引需要儲存資料的指標,佔用空間大。 - 在讀取資料的方式上
聚集索引直接通過葉節點讀取資料頁;非聚集索引需要通過指標找到RID或者聚集索引的指標,再通過聚集索引查詢鍵值。 - 在邏輯讀的次數上
直接讀聚集索引,邏輯讀最小,測試邏輯讀次數為2
通過非聚集索引+RID,邏輯讀居中,測試邏輯讀次數為3
通過聚集索引+非聚集索引,邏輯讀最大,測試邏輯讀次數為4 - 在建立方式上
聚集索引:建立主鍵時自動使用主鍵列為聚集索引,沒有主鍵時可以通過CRAETE CLUSTERED INDEX 建立,可以指定多個列;每張表只能有1個聚集索引。
非聚集索引:手動建立,通過CRAETE NONCLUSTERED INDEX 建立;每張表可以有多個非聚集索引。
本次僅對索引的基本知識進行介紹,後續再根據不同的使用場景來驗證和說明。