資料治理之關鍵環節後設資料管理開源專案datahub探索
@
概述
定義
datahub 官網地址 https://datahubproject.io/ 最新版本v0.10.2
datahub 官網檔案地址 https://datahubproject.io/docs/
datahub 原始碼地址 https://github.com/datahub-project/datahub
DataHub是一個面向現代資料棧的開源後設資料平臺,依賴於後設資料管理的現代方法。其前身是LinkedIn為了提高資料團隊的工作效率,開發並開源的WhereHows;DataHub的可延伸後設資料平臺支援資料發現、資料可觀察性和聯合治理,有助於控制資料生態系統的複雜性。
DataHub是一個現代資料目錄,旨在實現端到端資料發現、資料可觀察性和資料治理。這個可延伸的後設資料平臺是為開發人員構建的,以控制其快速發展的資料生態系統的複雜性,併為資料從業者利用其組織內資料的總價值。
後設資料是開啟資料治理的探索之路的關鍵環節。
在DAMA-DMBOK2中描述後設資料最常見的定義是「關於資料的資料」。這個定義非常簡單,但也容易引起誤解。可以歸類為後設資料的資訊範圍很廣,不僅包括技術和業務流程、資料規則和約束,還包括邏輯資料結構與物理資料結構等。它描述了資料本身(如資料庫、資料元素、資料模型),資料表示的概念(如業務流程、應用系統、軟體程式碼、技術基礎設施),資料與概念之間的聯絡(關係)。後設資料可以幫助組織理解其自身的資料、系統和流程,同時幫助使用者評估資料質量,對資料庫與其他應用程式的管理來說是不可或缺的。它有助於處理、維護、整合、保護和治理其他資料。
- 如果沒有可靠的後設資料,組織就不知道它擁有什麼資料、資料表示什麼、資料來自何處、它如何在系統中流轉,誰有權存取它,或者對於資料保持高質量的意義。
- 如果沒有後設資料,組織就不能將其資料作為資產進行管理。
- 實際上,如果沒有後設資料,組織可能根本無法管理其資料
簡而言之,後設資料是「 提供有關其他資料的資訊的資料,後設資料也是資料,後設資料管理是為了對資料資產進行有效的組織。它使用後設資料來幫助管理他們的資料。它還可以幫助資料專業人員收集、組織、存取和豐富後設資料,以支援資料治理。
DataHub有巨大的生態系統,預構建整合包括Kafka, Airflow, MySQL, SQL Server, Postgres, LDAP, Snowflake, Hive, BigQuery等等;且社群正在不斷新增更多的整合。
核心功能
- 搜尋和發現
- 搜尋資料堆疊的所有角落:DataHub的統一搜尋體驗顯示了跨資料庫、資料湖、BI平臺、ML功能商店、編排工具等的搜尋結果。
- 跟蹤端到端沿襲:通過跟蹤跨平臺、資料集、ETL/ELT管道、圖表、儀表板等的沿襲,快速瞭解資料的端到端旅程。
- 理解中斷變更對下游依賴關係的影響:使用影響分析主動識別哪些實體可能受到破壞性更改的影響。
- 「後設資料360」概覽:結合技術和邏輯後設資料,提供資料實體的360º檢視。生成資料集統計以瞭解資料的形狀和分佈。
- 從Great Expectations等工具獲取歷史資料驗證結果。
- 利用DataHub的Schema Version History跟蹤資料物理結構隨時間的變化。
- 現代資料治理
- 實時治理:action框架支援以下實時用例
- 通知:在DataHub上進行更改時生成特定於組織的通知。例如,當向任何資料資產新增「PII」標記時,向治理團隊傳送電子郵件。
- 工作流整合:將DataHub整合到組織的內部工作流中。例如,當在資料集上提出特定的標籤或術語時,建立Jira票據。
- 同步:將DataHub中的更改同步到第三方系統。例如,將DataHub中的標記新增反映到Snowflake中。
- 審計:隨著時間的推移,審計誰對DataHub進行了哪些更改。
- 管理實體所有權:快速方便地為使用者和使用者組分配實體所有權。
- 使用標籤、術語表和域進行管理:授權資料所有者通過以下方式管理其資料實體
- 標籤:非正式的,鬆散控制的標籤,作為搜尋和發現的工具。沒有正式的中央管理。
- 術語表術語:具有可選層次結構的受控詞彙表,通常用於描述核心業務概念和度量。
- 域:精心策劃的頂級資料夾或類別,廣泛用於資料網格中,按部門(如財務、行銷)或資料產品組織實體。
- DataHub管理
- 建立使用者、組和存取策略:DataHub管理員可以建立policy來定義誰可以對哪些資源執行哪些操作。當您建立一個新的策略時,您將能夠定義以下內容
- 策略型別—平臺(頂級DataHub平臺特權,即管理使用者、組和策略)或後設資料(操縱所有權、標記、檔案等的能力)
- 資源型別——指定資源的型別,如資料集、儀表板、管道等
- 特權-選擇一組許可權,如編輯所有者、編輯檔案、編輯連結
- 使用者及/或群組-分配相關的使用者及群組;您還可以將策略分配給資源所有者,而不管他們屬於哪個組
- 從UI中攝取後設資料:使用DataHub使用者介面建立、設定、排程和執行批次處理後設資料攝取。通過最小化操作客製化整合管道所需的開銷,這使得將後設資料放入DataHub變得更加容易。
- 建立使用者、組和存取策略:DataHub管理員可以建立policy來定義誰可以對哪些資源執行哪些操作。當您建立一個新的策略時,您將能夠定義以下內容
- 後設資料管理的現代方法
- 自動後設資料攝取:基於推播的攝取可以使用預構建的發射器,也可以使用我們的框架發出自定義事件。基於拉的攝取抓取後設資料源。我們已經與Kafka, MySQL, MS SQL, Postgres, LDAP, Snowflake, Hive, BigQuery等進行了預構建整合。攝取可以自動使用我們的氣流整合或其他排程選擇。
- 發現可信資料:瀏覽和搜尋不斷更新的資料集、儀表板、圖表、ML模型等目錄。
- 理解資料背景:DataHub是檔案、模式、所有權、沿襲、管道、資料質量、使用資訊等方面的一站式商店。
- 實時治理:action框架支援以下實時用例
概念
- 通用概念
- 統一資源名稱URN (Uniform Resource Name):是用來唯一定義DataHub中任何資源的URI方案。格式 urn:
: : - 策略:DataHub中的存取策略定義誰可以對哪些資源做什麼。
- 角色:DataHub提供了使用角色來管理許可權的功能。
- 存取令牌(個人存取令牌):個人存取令牌(Personal Access Tokens,簡稱pat)允許使用者在程式碼中表示自己,並在關注安全性的部署中以程式設計方式使用DataHub的api。PATs與啟用身份驗證的後設資料服務一起使用,為DataHub增加了一層保護,只有授權使用者才能以自動化的方式執行操作。
- 檢視:允許您儲存和共用過濾器集,以便在瀏覽DataHub時重用。檢視可以是公共的,也可以是個人的。
- 棄用:是指示實體棄用狀態的方面,通常它表示為布林值。
- 攝入來源:指的是我們從中提取後設資料的資料系統。例如有BigQuery、Looker、Tableau和其他許多資料來源。
- 容器:相關資料資產的容器。
- 資料平臺:是包含資料集、儀表板、圖表和後設資料圖中建模的所有其他型別資料資產的系統或工具。
- 資料集:代表了通常在資料庫中以表或檢視表示的資料集合(例如BigQuery, Snowflake, Redshift等),流處理環境中的流(Kafka, Pulsar等),資料湖系統(S3, ADLS等)中以檔案或資料夾形式存在的資料束。
- 圖表:從資料集派生的單個資料視覺化。單個圖表可以是多個儀表板的一部分。圖表可以附帶標籤、所有者、連結、術語表和描述。例子包括超集或觀察者圖。
- 指示板:用於視覺化的圖表集合。儀表板可以附加標籤、所有者、連結、術語表和描述。例子包括Superset或Mode Dashboard。
- 資料工作:處理資料資產的可執行作業,其中「處理」意味著使用資料、生成資料或兩者兼而有之。在編排系統中,這有時被稱為「DAG」中的單個「任務」。例如Airflow任務。
- 資料流:具有依賴關係的資料作業的可執行集合,或DAG。有時被稱為「管道」。例如AirflowDAG。
- 術語表術語:資料生態系統中的共用詞彙表。
- 術語組:類似於一個資料夾,包含術語甚至其他術語組,以允許巢狀結構。
- 標籤:是非正式的,鬆散控制的標籤,有助於搜尋和發現。可以將它們新增到資料集、資料集模式或容器中,以一種簡單的方式對實體進行標記或分類,而不必將它們與更廣泛的業務術語表或詞彙表關聯。
- 域:是精心策劃的頂級資料夾或類別,相關資產可以在其中顯式分組。
- 所有者:是指對實體具有所有權的使用者或組。例如,所有者可以存取資料集或列。
- 使用者(主體):CorpUser表示企業中個人(或帳戶)的身份。
- 組(CorpGroup):表示企業中一組使用者的身份。
- 統一資源名稱URN (Uniform Resource Name):是用來唯一定義DataHub中任何資源的URI方案。格式 urn:
- 後設資料模型
- 實體:是後設資料圖中的主節點。例如資料集或CorpUser的範例是一個實體。
- 方面:是描述實體的特定切面的屬性集合。方面可以在實體之間共用,例如,「所有權」是一個可以在所有擁有所有者的實體之間重用的方面。
- 關係:表示兩個實體之間的命名邊。它們是通過切面中的外來鍵屬性以及自定義註釋(@Relationship)宣告的。
後設資料應用
後設資料管理一般具備如下功能:
- 搜尋和發現:資料表、欄位、標籤、使用資訊
- 存取控制:存取控制組、使用者、策略
- 資料血緣:管道執行、查詢
- 合規性:資料隱私/合規性註釋型別的分類
- 資料管理:資料來源設定、攝取設定、保留設定、資料清除策略
- AI 可解釋性、再現性:特徵定義、模型定義、訓練執行執行、問題陳述
- 資料操作:管道執行、處理的資料分割區、資料統計
- 資料質量:資料質量規則定義、規則執行結果、資料統計
其他開源
Apache Atlas 官網地址 https://atlas.apache.org/ 最新版本2.3.0
Apache Atlas 原始碼地址 https://github.com/apache/atlas
Apache Atlas是一套可延伸的核心基礎治理服務,使企業能夠有效地滿足Hadoop中的合規要求,並允許與整個企業資料生態系統整合;Apache Atlas為組織提供開放的後設資料管理和治理功能,以構建資料資產的目錄,對這些資產進行分類和治理,併為資料科學家、分析師和資料治理團隊提供圍繞這些資料資產的共同作業功能。有官方檔案,部署比較重
Amundsen 官網地址 https://www.amundsen.io/amundsen/ 最新版本4.1.1
Amundsen 原始碼地址 https://github.com/amundsen-io/amundsen
Amundsen是一個開源資料發現和後設資料引擎,用於提高資料分析師、資料科學家和工程師在與資料互動時的生產力。今天,它通過索引資料資源(表、儀表板、流等)和基於使用模式的頁面級搜尋來實現這一點(例如,查詢次數多的表比查詢次數少的表顯示得早)。可以把它想象成谷歌資料搜尋;有官方檔案
Marquez 官網地址 https://marquezproject.ai/ 最新版本0.33.0
Marquez 原始碼地址 https://github.com/MarquezProject/marquez
Marquez是一個開源後設資料服務,用於收集、聚合和視覺化資料生態系統的後設資料。它維護資料集如何被消費和產生的來源,提供作業執行時和資料集存取頻率的全域性可見性,資料集生命週期管理的集中化等;Marquez是由WeWork釋出並開源的。有官方檔案
Metacat 原始碼地址 https://github.com/Netflix/metacat 最新版本1.2.2
Metacat是一個統一的後設資料探索API服務。可以探索Hive, RDS, Teradata, Redshift, S3和Cassandra。Metacat提供有哪些資料、資料位於何處以及如何處理這些資料的資訊。沒有官方檔案,且2019年後沒有釋出新的release版本
架構
概覽
DataHub是第三代後設資料平臺,支援為現代資料棧構建的資料發現、共同作業、治理和端到端可觀察性。DataHub採用模型優先的理念,專注於解鎖不同工具和系統之間的互操作性。
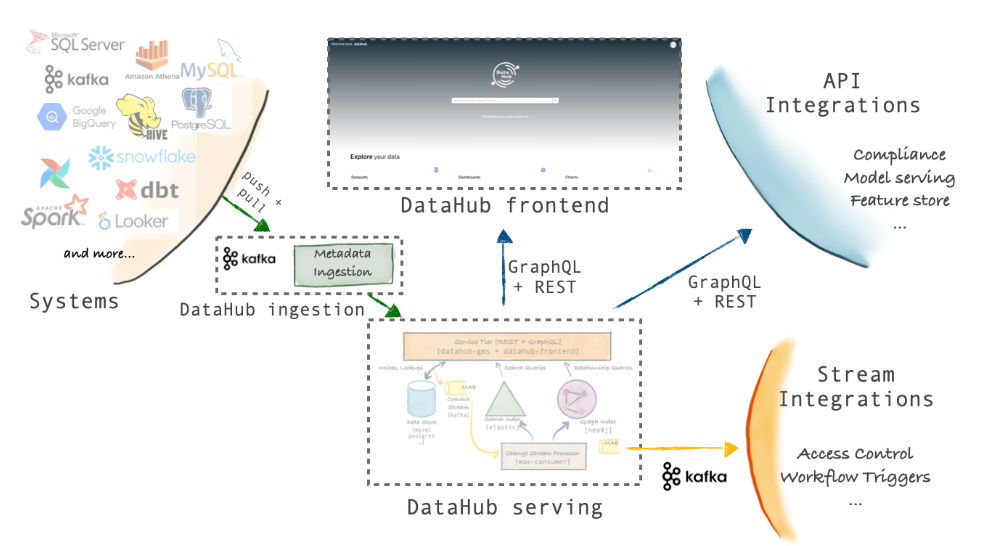
DataHub的架構有三個主要亮點
- 模式優先的後設資料建模方法:DataHub的後設資料模型使用與序列化無關的語言進行描述。它支援REST和GraphQL api。此外,DataHub支援基於avro的API,通過Kafka來通訊和訂閱後設資料更改。
- 基於流的實時後設資料平臺:DataHub的後設資料基礎設施是面向流的,這使得後設資料的變化可以在幾秒鐘內在平臺內進行通訊和反映。可以訂閱DataHub後設資料中發生的變化,從而構建實時的後設資料驅動系統。例如可以構建一個存取控制系統,該系統可以通過新增包含PII的新模式欄位來觀察以前的世界可讀資料集,並鎖定該資料集以進行存取控制檢查。
- 聯邦後設資料服務:DataHub附帶了一個後設資料服務(gms),作為開源儲存庫的一部分。然而,它也支援聯合後設資料服務,這些服務可以由不同的團隊擁有和運營——事實上,這就是LinkedIn內部執行DataHub的方式。聯邦服務使用Kafka與中央搜尋索引和圖形通訊,以支援全域性搜尋和發現,同時仍然支援後設資料的去耦所有權。這種架構非常適合實現資料網格的公司。
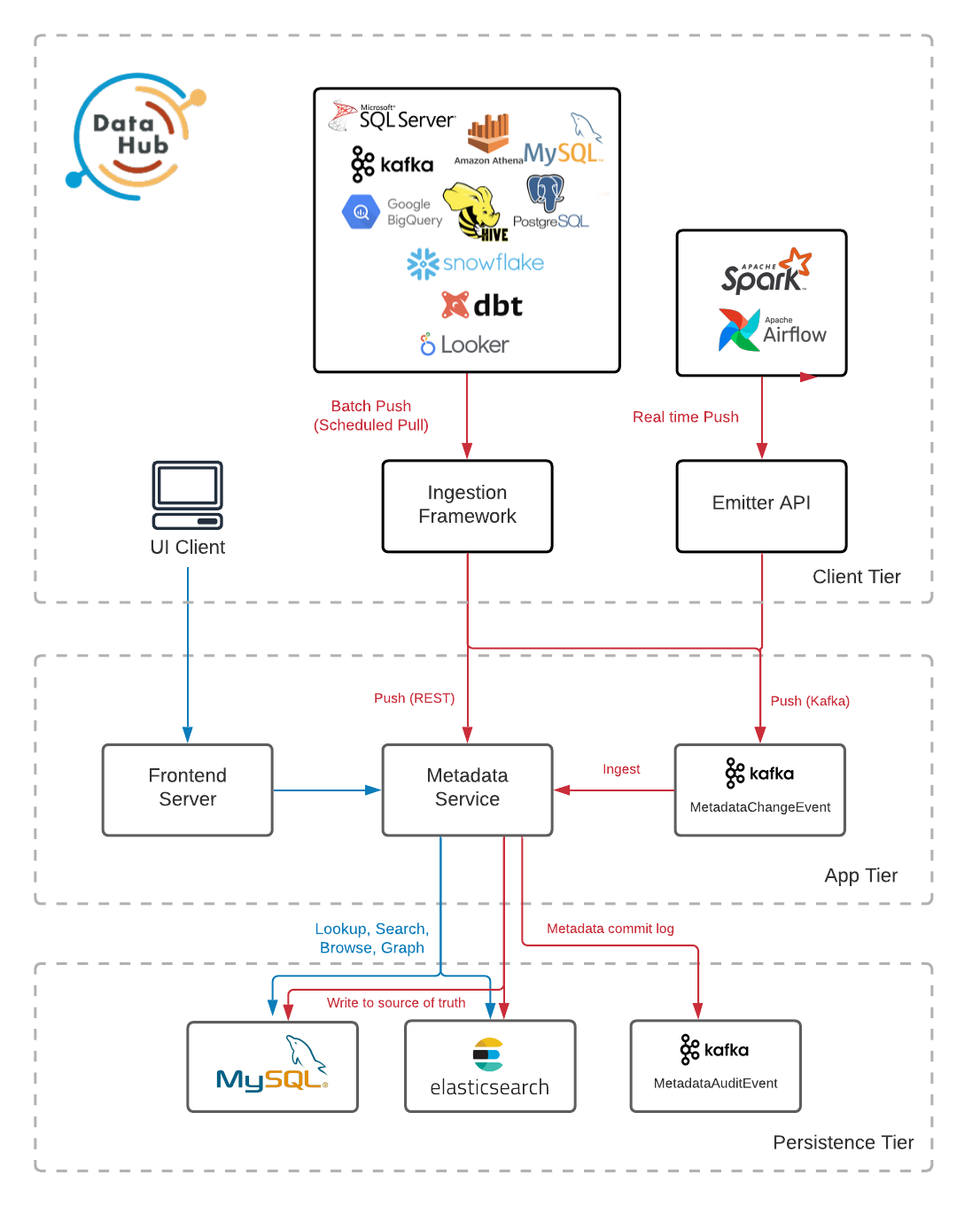
元件
DataHub平臺由如下圖所示的元件組成
- 後設資料儲存:負責儲存組成後設資料圖的實體和方面。這包括公開用於攝取後設資料、按主鍵獲取後設資料、搜尋實體和獲取實體之間關係的API。它由一個Spring Java Service託管一組Rest組成。li API端點,以及MySQL, Elasticsearch和Kafka用於主記憶體儲和索引。
- 後設資料模型:是定義組成後設資料圖的實體和方面的形狀以及它們之間的關係的模式。它們是使用PDL定義的,PDL是一種建模語言,在形式上與Protobuf非常相似,同時序列化為JSON。實體表示後設資料資產的特定類,如資料集、儀表板、資料管道等。實體的每個範例由一個稱為urn的唯一識別符號標識。方面表示附加到實體範例的相關資料束,例如其描述、標記等。
- 攝入框架:是一個模組化的,可延伸的Python庫,用於從外部源系統(如Snowflake, Looker, MySQL, Kafka)提取後設資料,將其轉換為DataHub的後設資料模型,並通過Kafka或直接使用後設資料儲存Rest api將其寫入DataHub。DataHub支援廣泛的源聯結器列表可供選擇,以及一系列功能,包括模式提取、表和列分析、使用資訊提取等。
- GraphQL API:提供了一個強型別的、面向實體的API,使得與組成後設資料圖的實體的互動變得簡單,包括用於新增和刪除標籤、所有者、連結和更多後設資料實體的API ,使用者介面也是使用該API來實現搜尋和發現、治理、可觀察性等功能。
- 使用者介面:DataHub帶有一個React UI,其中包括一組不斷髮展的功能,使發現,管理和偵錯資料資產變得輕鬆愉快。
後設資料攝取架構
DataHub支援極其靈活的攝取架構,可以支援推、拉、非同步和同步模型。
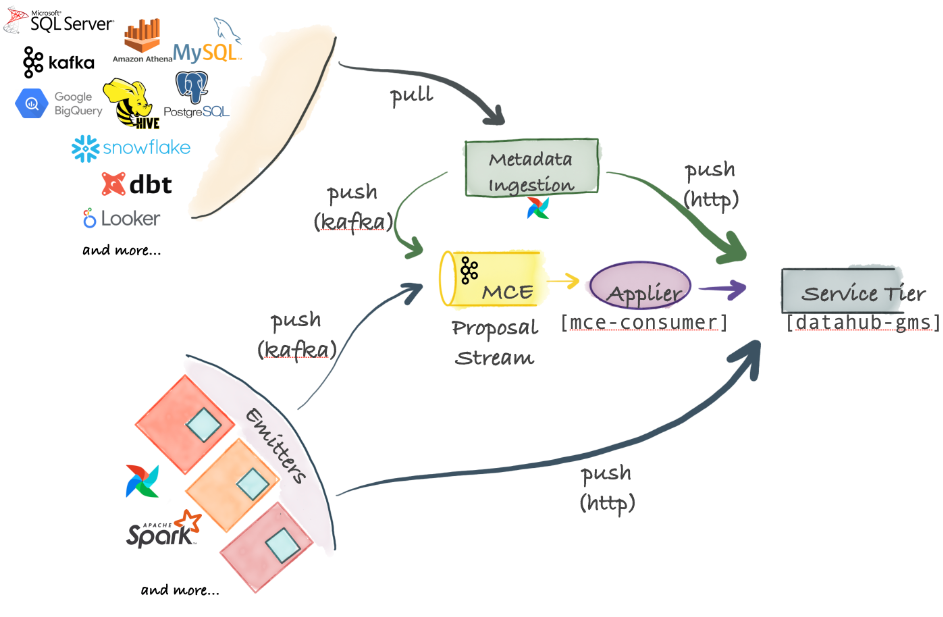
- 後設資料更改建議-中心部分:攝取的中心部分是後設資料更改建議,它表示對組織的後設資料圖進行後設資料更改的請求。後設資料變更建議可以通過Kafka傳送,用於從源系統進行高度可延伸的非同步釋出。它們還可以直接傳送到DataHub服務層公開的HTTP端點,以獲得同步的成功/失敗響應。
- 基於拉整合:DataHub附帶了一個基於Python的後設資料攝取系統,該系統可以連線到不同的源以從中提取後設資料。這些後設資料然後通過Kafka或HTTP推播到DataHub儲存層。後設資料攝取管道可以與AirFlow整合,以設定預定的攝取或捕獲沿襲。如果找不到已經支援的原始碼,那麼編寫自己的原始碼也是非常容易的。
- 基於推整合:只要可以向Kafka發出一個後設資料更改建議(Metadata Change Proposal, MCP)事件,或者通過HTTP進行一個REST呼叫,就可以將任何系統與DataHub整合。為方便起見,DataHub還提供了簡單的Python發射器,可以將其整合到系統中,從而在源點發出後設資料更改(MCP-s)。
- 內部元件:將後設資料更改建議應用於DataHub後設資料服務(mce-consumer-job);DataHub附帶了一個Spring作業mce-consumer-job,該作業使用後設資料更改建議並使用/ingest端點將其寫入DataHub後設資料服務(DataHub -gms)。
服務體系結構
DataHub服務層的高階系統關係圖如下:
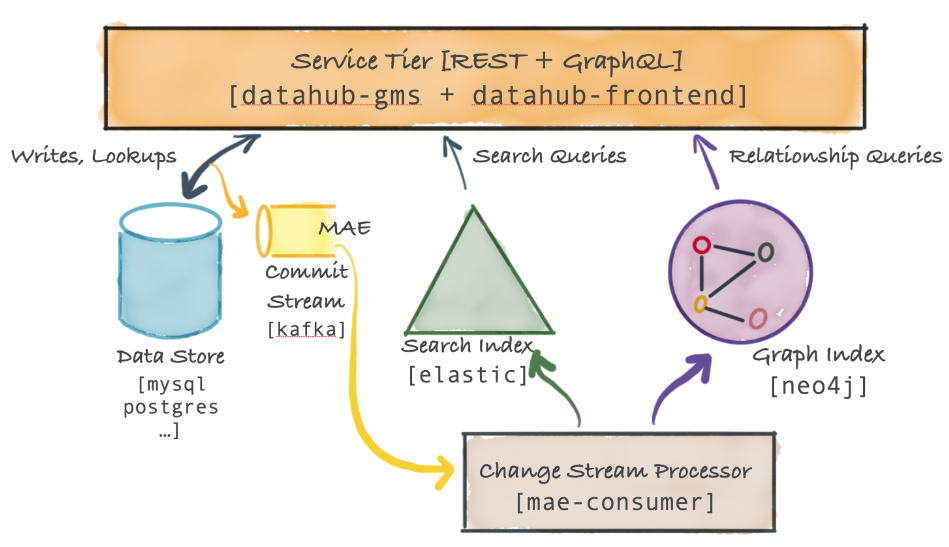
主元件稱為後設資料服務,它公開了一個REST API和一個GraphQL API,用於對後設資料執行CRUD操作。該服務還公開了搜尋和圖形查詢api,以支援二級索引樣式的查詢、全文搜尋查詢以及血緣等關係查詢。此外資料中心前端服務在後設資料圖之上公開GraphQL API。DataHub服務層元件:
- 後設資料儲存:DataHub後設資料服務將後設資料儲存在檔案儲存中(如MySQL、Postgres或Cassandra等RDBMS)。
- 後設資料變更紀錄檔流(MCL):當後設資料更改成功提交到持久儲存時,DataHub服務層還會發出提交事件後設資料更改紀錄檔。該事件通過Kafka傳送。MCL流是一個公共API,可以由外部系統(例如Actions Framework)訂閱,提供了一種非常強大的方式來實時響應後設資料中發生的變化。例如可以構建一個存取控制強制器,對後設資料的變化做出反應(例如,以前的世界可讀資料集現在有一個pii欄位),以立即鎖定有問題的資料集。注意並非所有mcp都會導致MCL,因為DataHub服務層將忽略對後設資料的任何重複更改。
- 後設資料索引應用程式(mae-consumer-job):後設資料更改紀錄檔由另一個Spring作業mae-consumer-job使用,該作業將相應的更改應用於圖和搜尋索引。該作業與實體無關,並將執行相應的圖形和搜尋索引構建器,當特定的後設資料方面發生更改時,作業將呼叫該構建器。構建器應該指導作業如何根據後設資料更改更新圖和搜尋索引。為了確保按正確的時間順序處理後設資料更改,mcl由實體URN進行鍵控——這意味著一個特定實體的所有mae將由單個執行緒依次處理。
- 後設資料查詢服務:基於主鍵的後設資料讀取(例如基於dataset-urn獲取資料集的模式後設資料)被路由到檔案儲存。基於二級索引對後設資料的讀取被路由到搜尋索引(或者也可以使用這裡描述的強一致性二級索引支援)。全文和高階搜尋查詢被路由到搜尋索引。複雜的圖查詢(如沿襲)被路由到圖索引。
本地部署
環境要求
- Docker
- Docker Compose v2
- Python 3.7+
安裝
# 安裝DataHub命令列
python3 -m pip install --upgrade pip wheel setuptools
python3 -m pip install --upgrade acryl-datahub
datahub version

# 本地部署DataHub範例,使用docker-compose部署一個DataHub範例
datahub docker quickstart
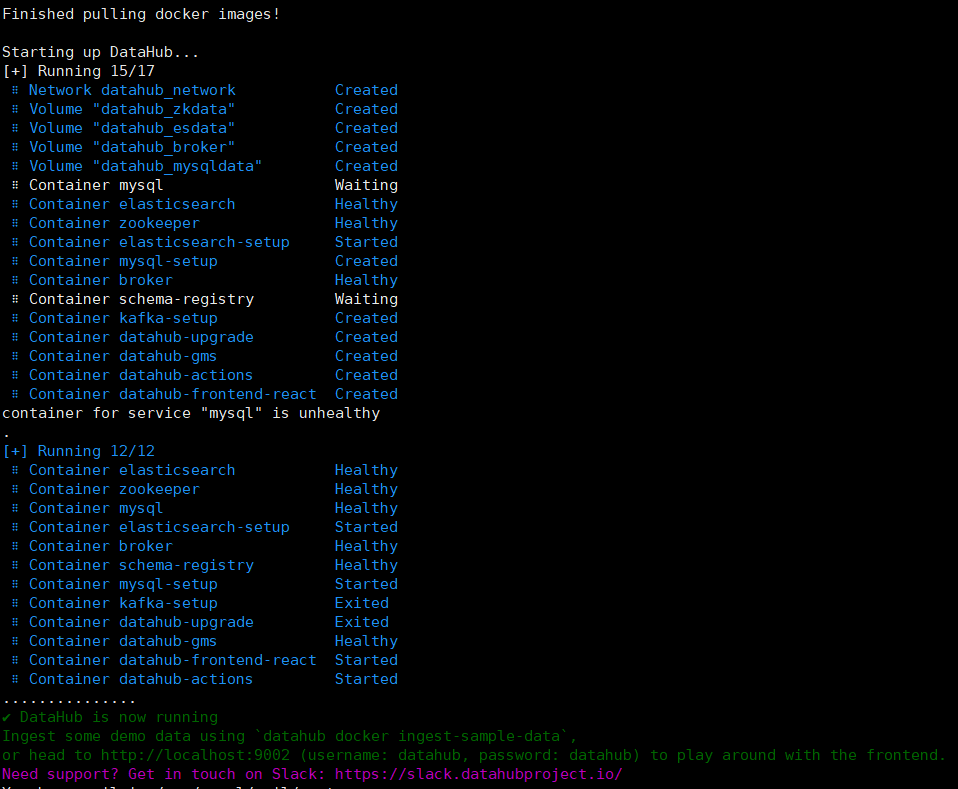
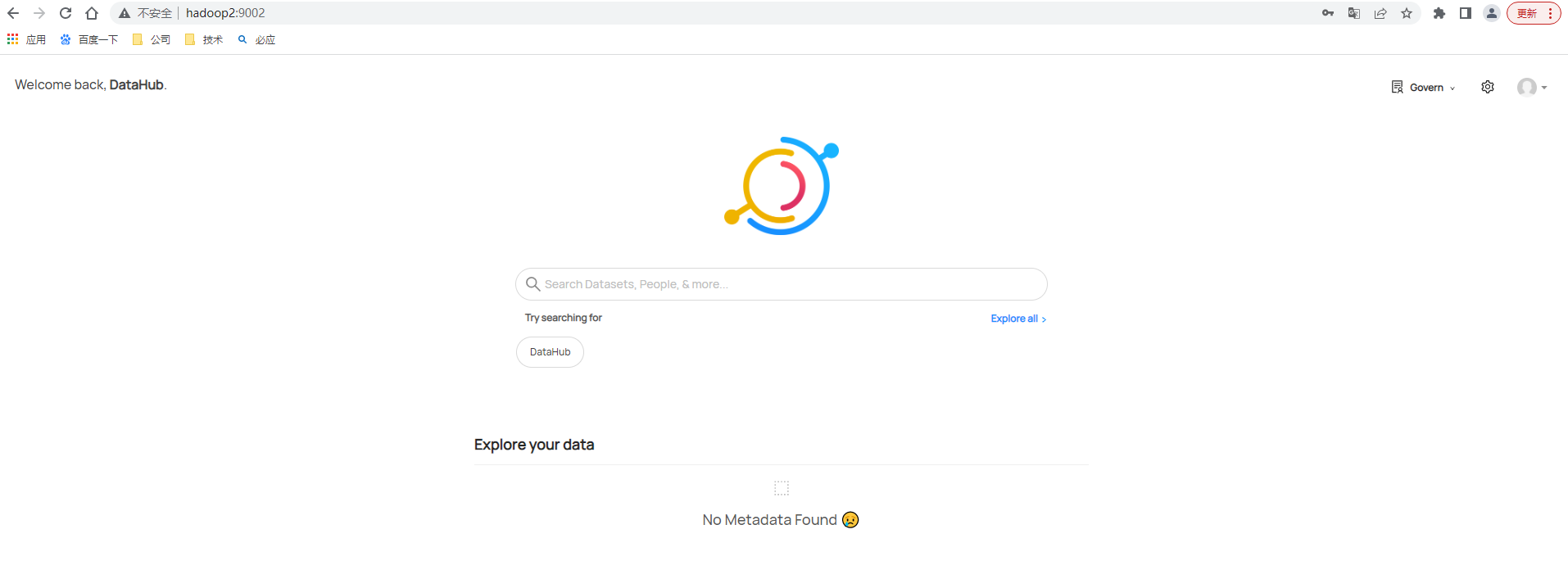
成功啟動後則可以直接存取DataHub UI (http://hadoop2:9002),登入使用者名稱和密碼為datahub/datahub,登入後主頁如下
# 也可以直接下載https://raw.githubusercontent.com/datahub-project/datahub/master/docker/quickstart/docker-compose-without-neo4j-m1.quickstart.yml這個檔案,也可以下載指定版本的https://github.com/datahub-project/datahub/archive/refs/tags/v0.10.2.tar.gz,最後找到相應docker-compose檔案然後通過docker-compose啟動
docker-compose -f docker-compose-without-neo4j-m1.quickstart.yml up -d
# 如要停止DataHub的快速啟動,可以發出以下命令。
datahub docker quickstart --stop
# 重置DataHub,要清除DataHub的所有狀態(例如,在攝取自己的狀態之前),可以使用CLI的nuke命令
datahub docker nuke
攝取樣例
# 攝取樣例後設資料可以使用下面命令,執行命令後可以檢視攝取資料
datahub docker ingest-sample-data
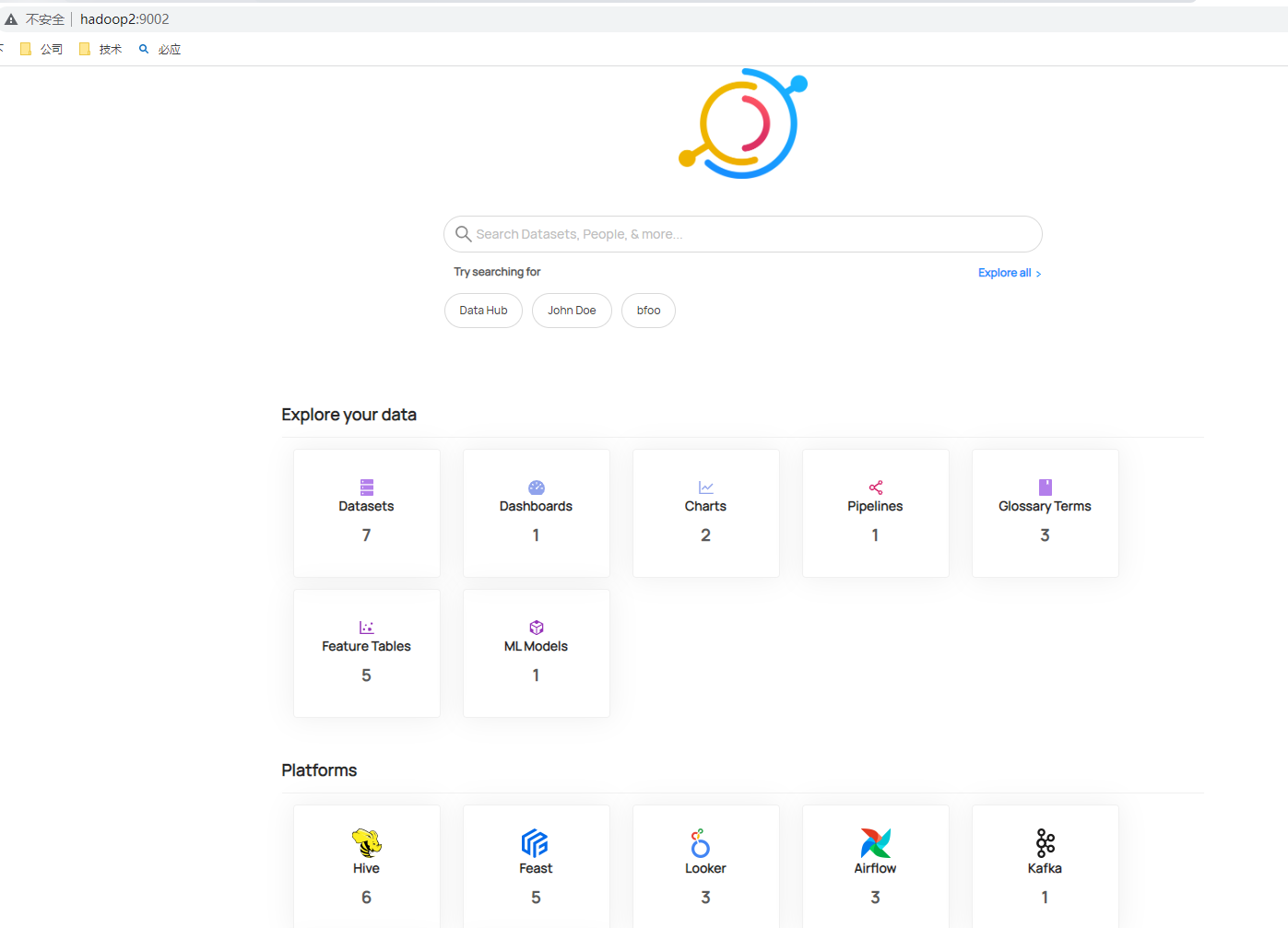
檢視具體後設資料資訊
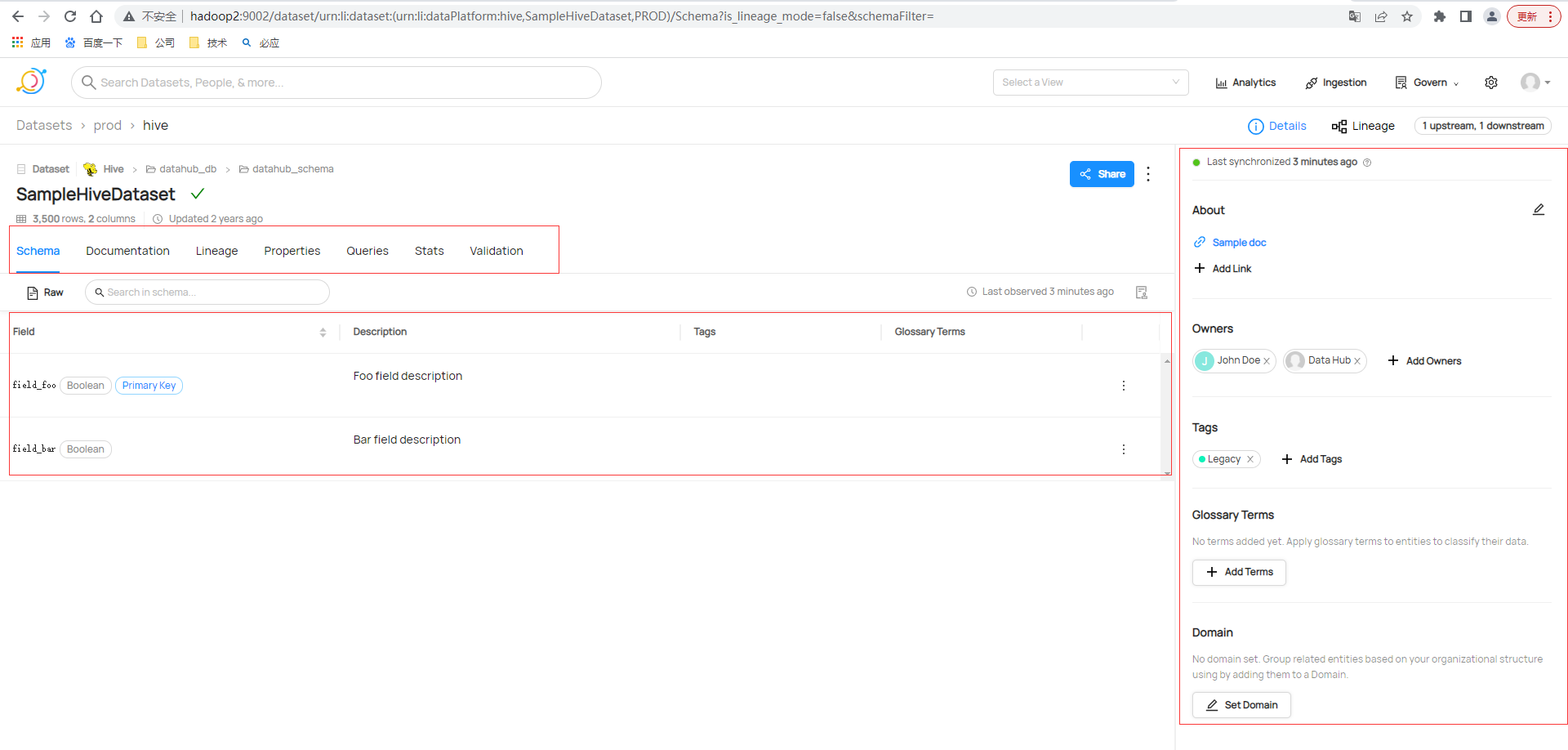
還支援檢視譜系或者沿襲,也即是常說血緣關係
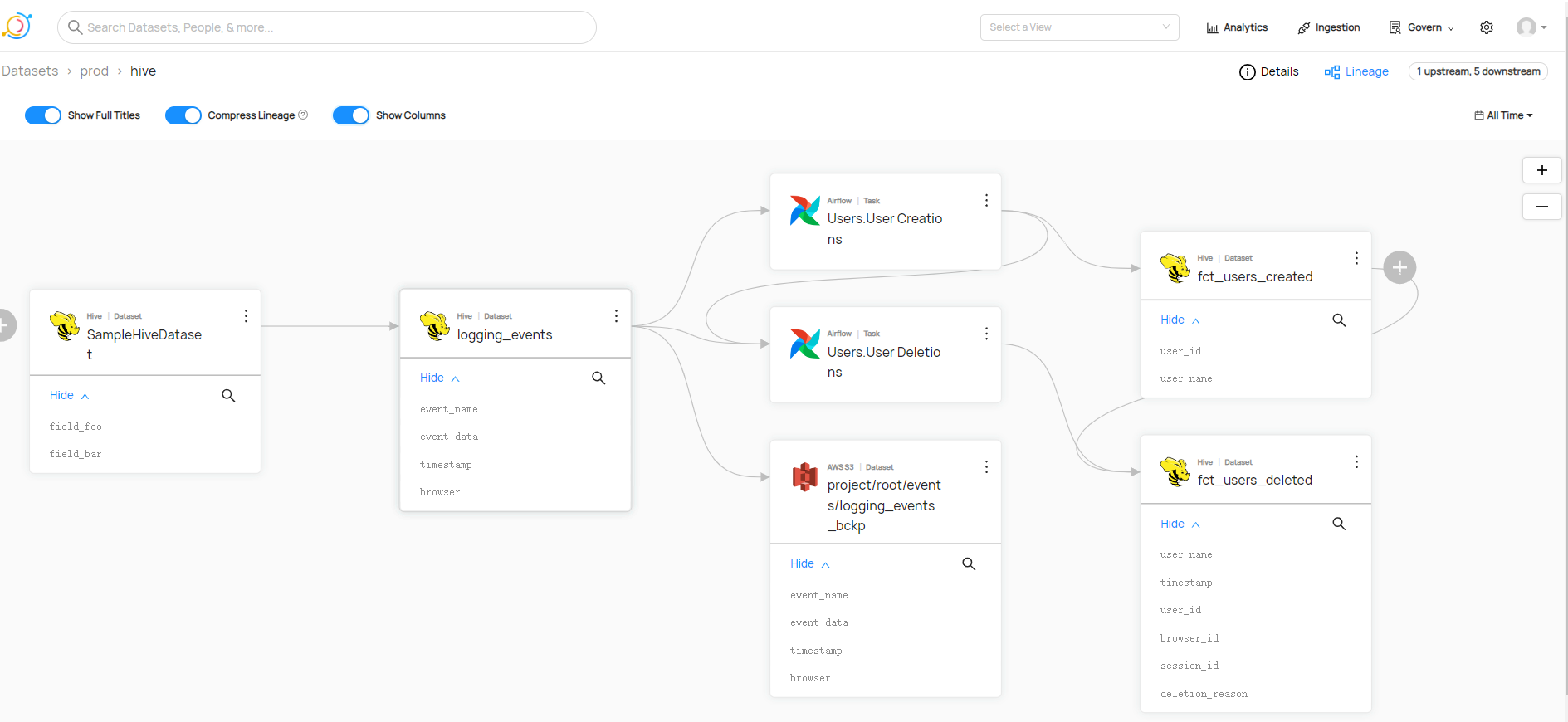
攝取入門
介紹
DataHub支援基於推和基於拉的後設資料整合。
- 基於推播的整合允許在後設資料更改時直接從資料系統發出後設資料,而基於拉的整合允許通過連線到資料系統並以批次處理或增量批次處理的方式提取後設資料,從而從資料系統「抓取」或「攝取」後設資料。支援這兩種機制意味著可以以最靈活的方式與所有系統整合。
- 內建在DataHub中的基於拉的後設資料攝取系統,該系統可以輕鬆地與資料堆疊中的各種資料來源整合。
核心概念
-
資料來源:從中提取後設資料的資料系統稱為資料來源。攝取後設資料的所有源例如BigQuery、Looker、Tableau等其他許多資料來源,目前官方上有55個。
-
接收器:是後設資料的目的地。在為DataHub設定攝取時,可能會通過REST (DataHub -sink)或Kafka (DataHub - Kafka)接收器將後設資料傳送到DataHub。在某些情況下,檔案接收器還有助於在偵錯期間儲存後設資料的持久離線副本。大多數攝取系統和指南假設的預設接收器是資料中心休息接收器,但是您也應該能夠為其他接收器調整所有接收器!
-
食譜:配方是將所有這些組合在一起的主要組態檔。它告訴我們的攝取指令碼從哪裡提取資料(源),在哪裡放置資料(接收)。
-
處理食譜中的敏感資訊:自動擴充套件設定中的環境變數(例如${MSSQL_PASSWORD}),類似於GNU bash或docker-compose檔案中的變數替換。應該使用這種環境變數替換來掩蓋配方檔案中的敏感資訊。只要您可以安全地將環境變數獲取到攝取過程中,就不需要在配方中儲存敏感資訊。
-
轉換:如果希望在資料到達攝取接收器之前對其進行修改——例如新增額外的所有者或標記——可以使用轉換器編寫自己的模組,並將其與DataHub整合。
命令列MySQL攝取範例
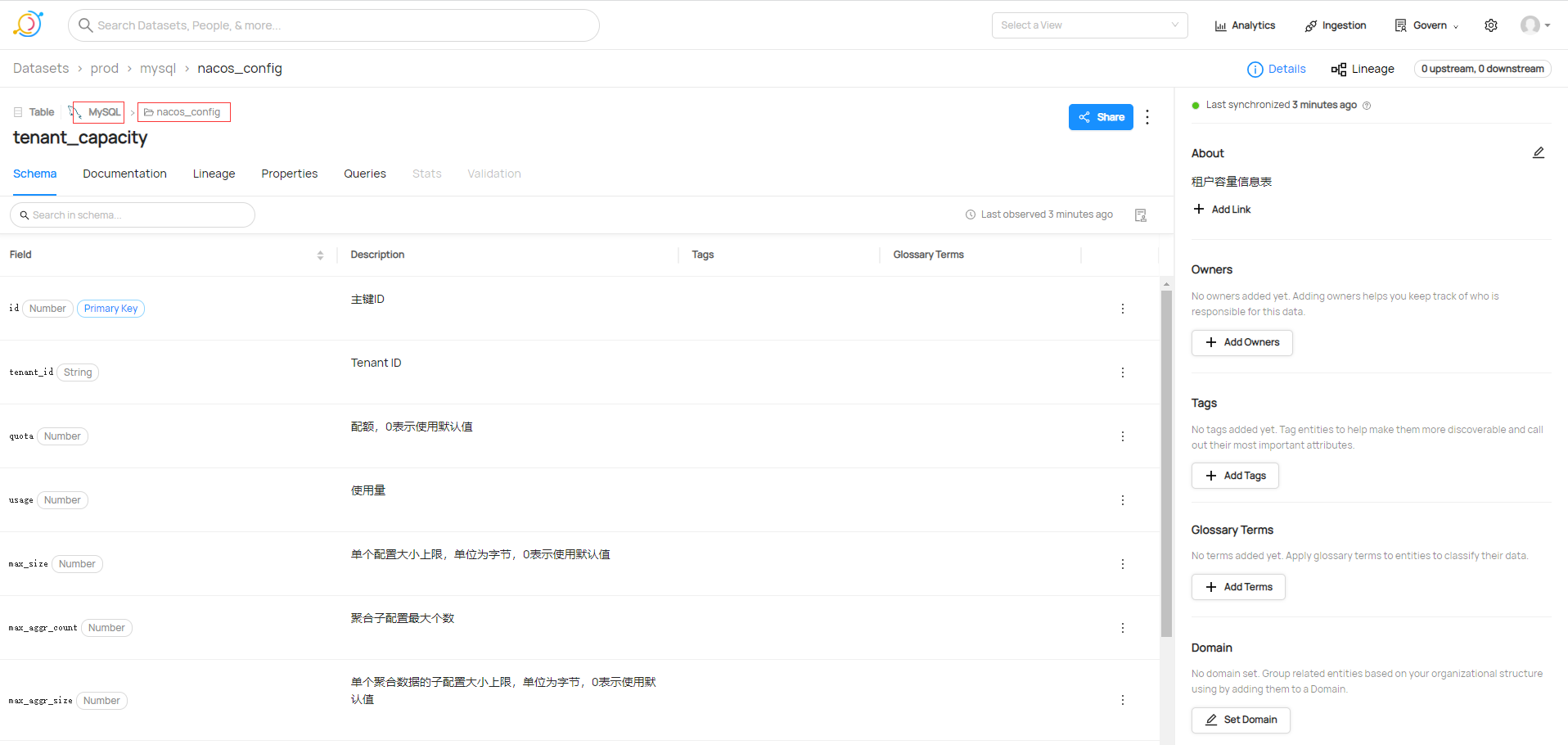
在獲取資料來源的時候,只需要編寫簡單的yml檔案就可以完成後設資料的獲取。這裡採集MySQL資料庫名為nacos_config

先檢查是否有datahub的mysql和datahub-rest外掛
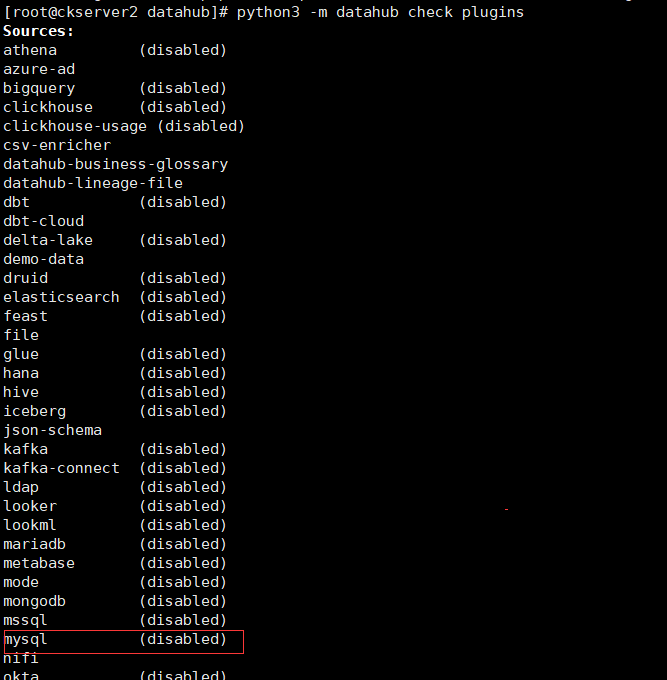
# 安裝datahub mysql外掛
pip install 'acryl-datahub[mysql]'
# 檢視datahub 外掛列表
python3 -m datahub check plugins
編寫攝取檔案,vim mysql_to_datahub_rest.yml
source:
type: mysql
config:
# Coordinates
host_port: 192.168.50.95:3306
database: nacos_config
# Credentials
username: root
password: 123456
sink:
type: "datahub-rest"
config:
server: "http://localhost:8080"
通過命令執行攝取
datahub ingest -c mysql_to_datahub_rest.yml
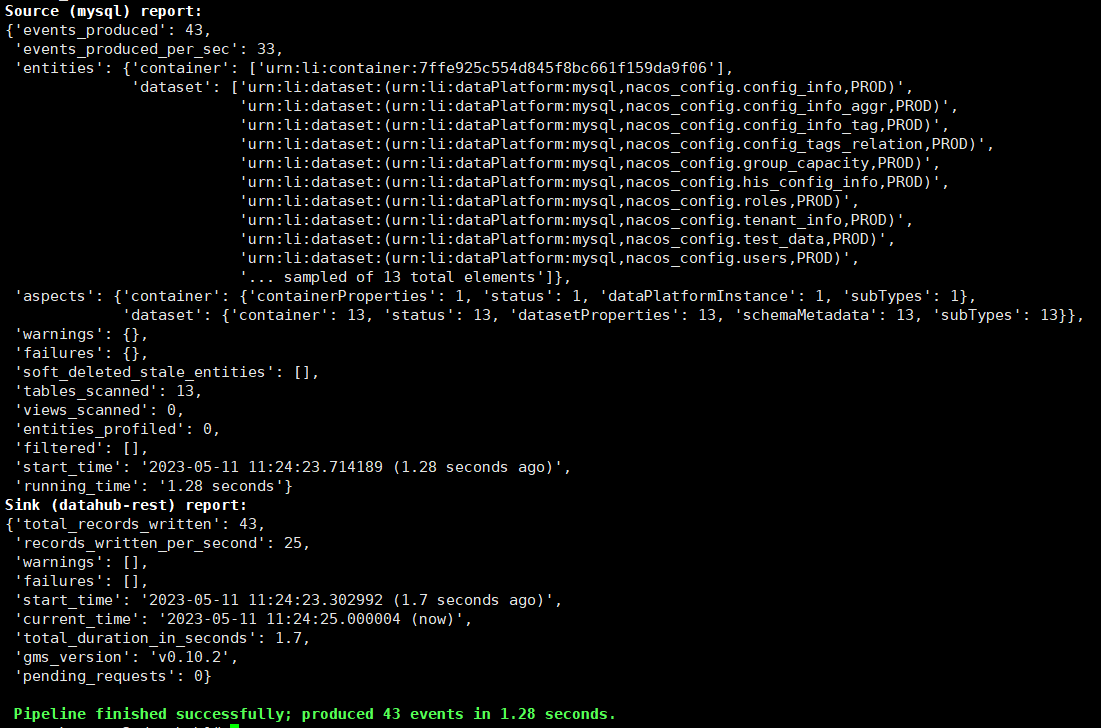
通過UI頁面也可以檢視攝取記錄
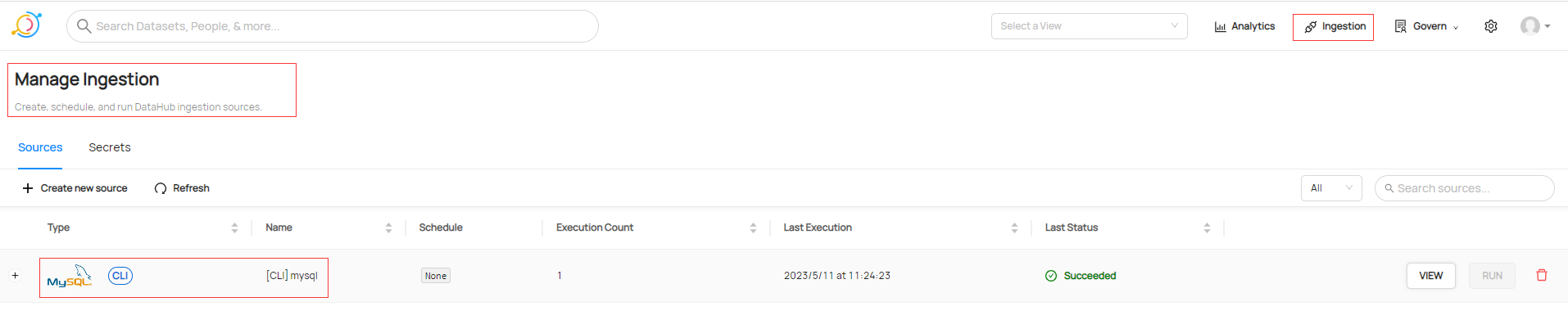
檢視剛剛新增資料庫集
設定ClickHouse攝取範例
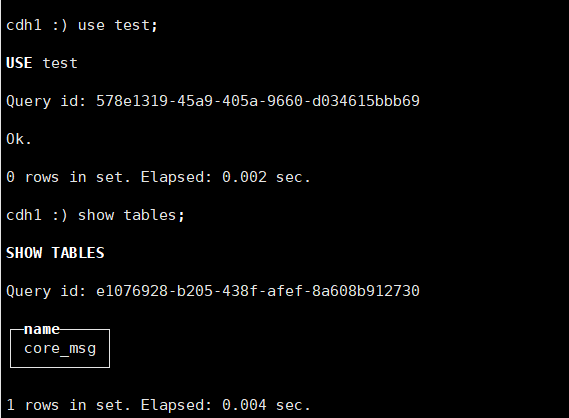
這裡建立ClickHouse的測試資料庫名為test
# 安裝clickhouse驅動
pip install 'acryl-datahub[clickhouse]'
編寫攝取檔案,vim clickhouse_to_datahub_rest.yml
source:
type: clickhouse
config:
host_port: clickhouse-server:8123
protocol: http
# Credentials
username: default
password: 123456
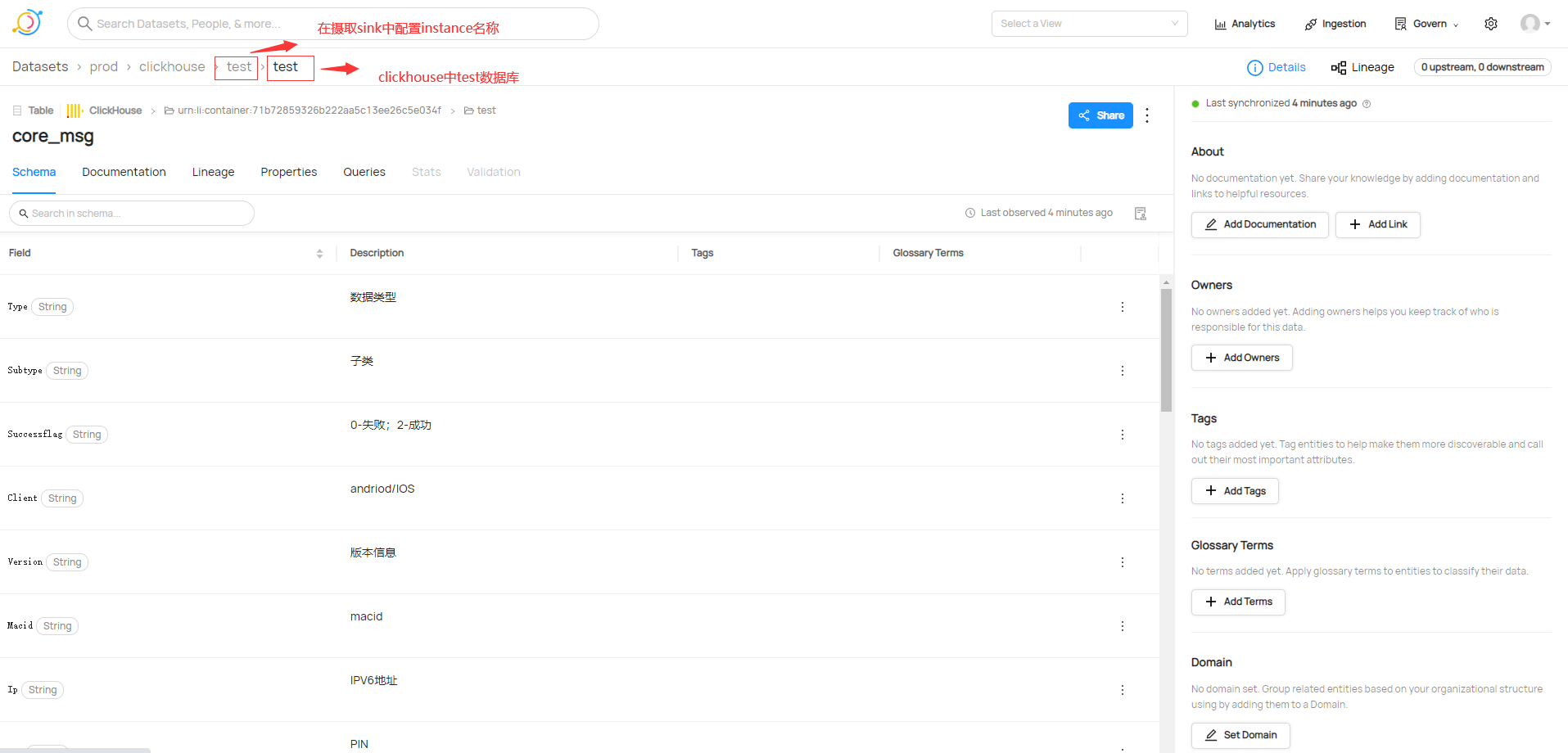
# Options,在datahub UI採集後設資料顯示的名稱
platform_instance: test
include_views: True # whether to include views, defaults to True
include_tables: True # whether to include views, defaults to True
sink:
type: "datahub-rest"
config:
server: "http://localhost:8080"
通過命令執行攝取
datahub ingest -c clickhouse_to_datahub_rest.yml
- 本人部落格網站IT小神 www.itxiaoshen.com