從原理到應用,人人都懂的ChatGPT指南
作者:京東科技 何雨航
引言
如何充分發揮ChatGPT潛能,已是眾多企業關注的焦點。但是,這種變化對員工來說未必是好事情。IBM計劃用AI替代7800個工作崗位,遊戲公司使用MidJourney削減原畫師人數......此類新聞屢見不鮮。理解並應用這項新技術,對於職場人來說重要性與日俱增。
一、GPT模型原理
理解原理是有效應用的第一步。ChatGPT是基於GPT模型的AI聊天產品,後文均簡稱為GPT。
從技術上看,GPT是一種基於Transformer架構的大語言模型(LLM)。GPT這個名字,實際上是"Generative Pre-trained Transformer"的縮寫,中文意為「生成式預訓練變換器」。
1.大模型和傳統AI的區別是什麼?
傳統AI模型針對特定目標訓練,因此只能處理特定問題。例如,很會下棋的AlphaGO。
而自然語言處理(NLP)試圖更進一步,解決使用者更為通用的問題。可以分為兩個關鍵步驟:自然語言理解(NLU)和自然語言生成(NLG)。

以SIRI為代表的人工智慧助手統一了NLU層,用一個模型理解使用者的需求,然後將需求分配給特定的AI模型進行處理,實現NLG並向用戶反饋。然而,這種模式存在顯著缺點。如微軟官方圖例所示,和傳統AI一樣,使用者每遇到一個新的場景,都需要訓練一個相應的模型,費用高昂且發展緩慢,NLG層亟需改變。
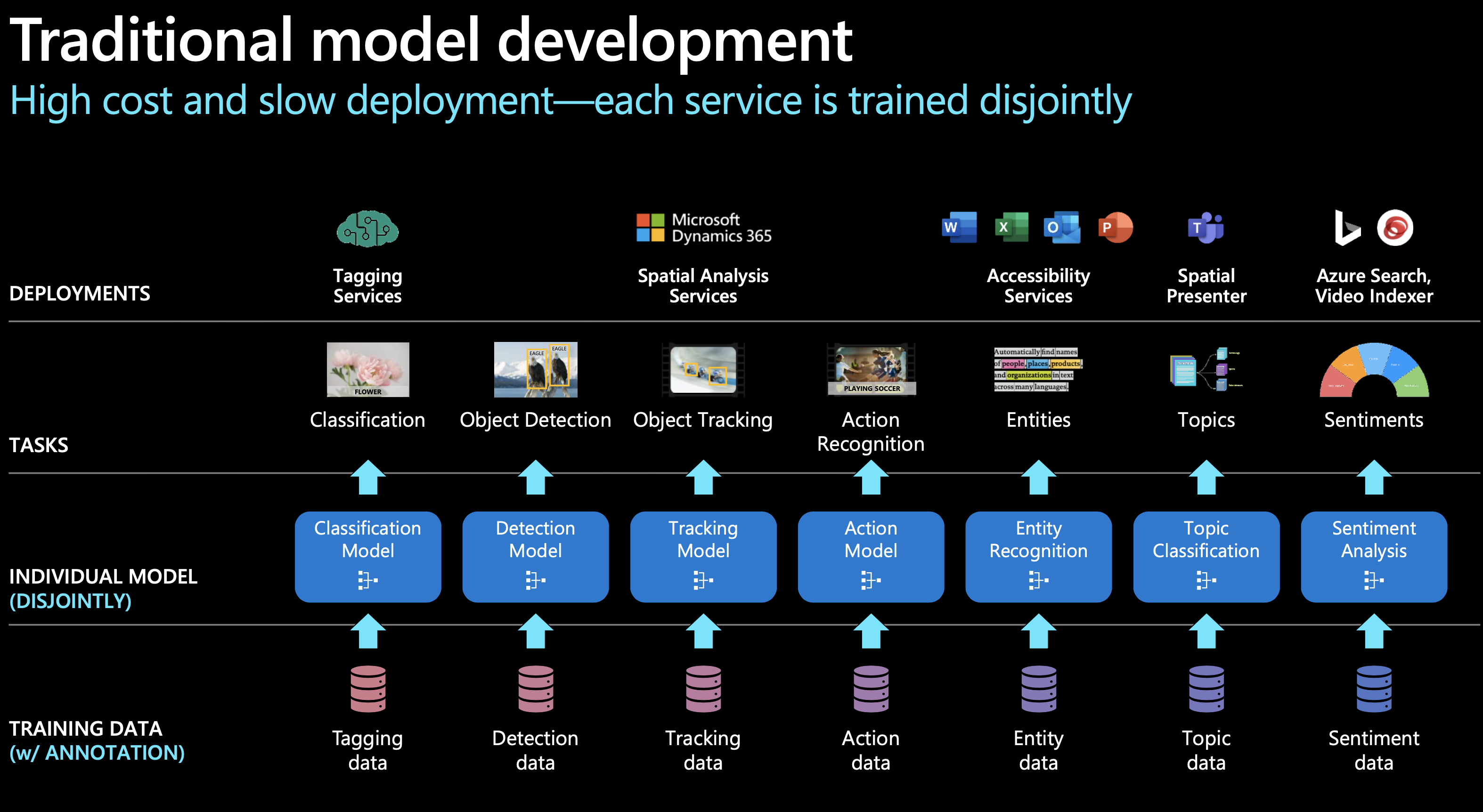
大型語言模型(如GPT)採用了一種截然不同的策略,實現了NLG層的統一。秉持著「大力出奇跡」的理念,將海量知識融入到一個統一的模型中,而不針對每個特定任務分別訓練模型,使AI解決多型別問題的能力大大加強。
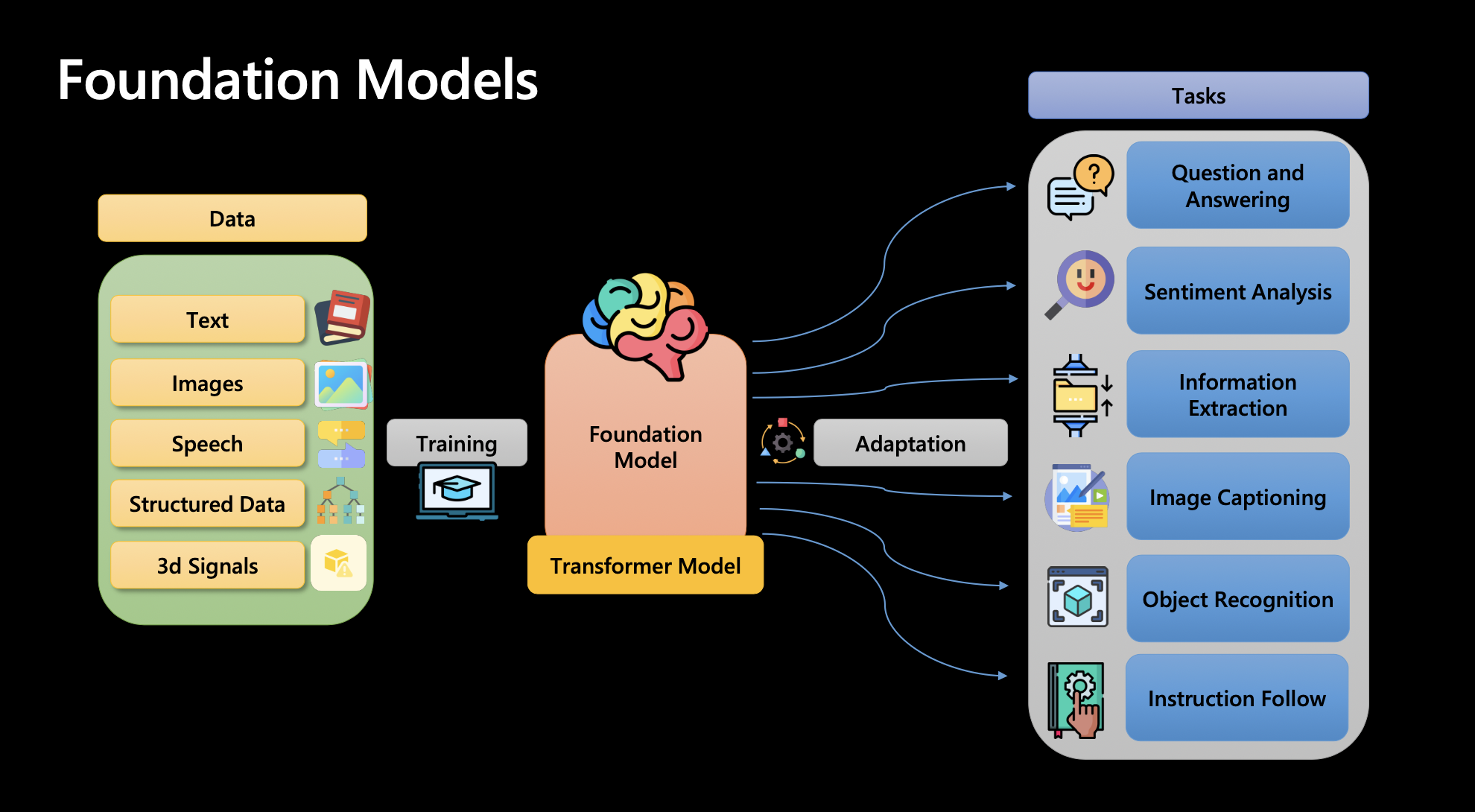
2.ChatGPT如何實現NLG?
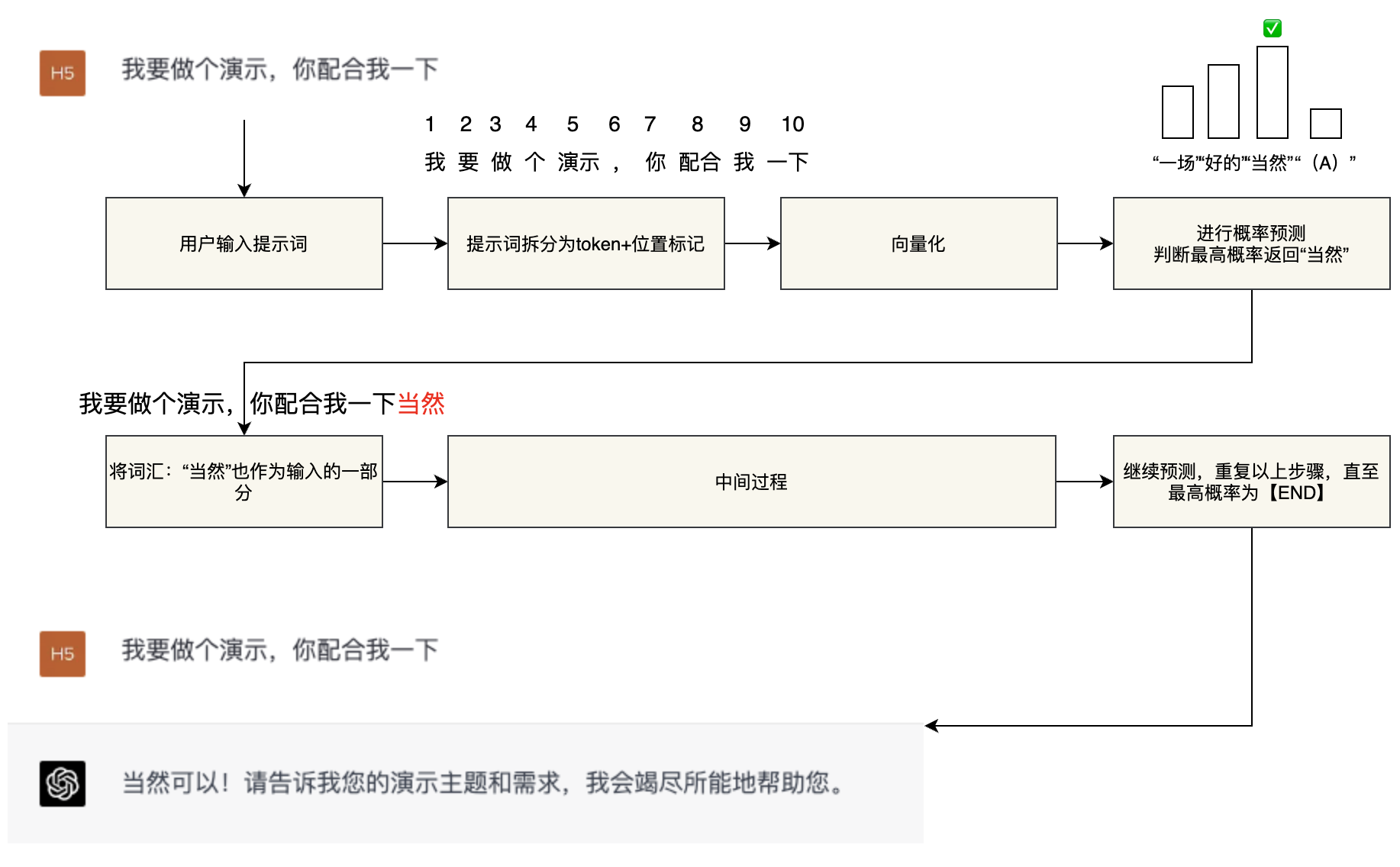
AI本質上就是個逆概率問題。GPT的自然語言生成實際上是一個基於概率的「文字接龍」遊戲。我們可以將GPT模型簡化為一個擁有千億引數的「函數」。當用戶輸入「提示詞(prompt)」時,模型按照以下步驟執行:
①將使用者的「提示詞」轉換為token(準確地說是「符號」,近似為「詞彙」,下同)+token的位置。
②將以上資訊「向量化」,作為大模型「函數」的輸入引數。
③大模型根據處理好的引數進行概率猜測,預測最適合回覆使用者的詞彙,並進行回覆。
④將回復的詞彙(token)加入到輸入引數中,重複上述步驟,直到最高概率的詞彙是【END】,從而實現一次完整的回答。這種方法使得GPT模型能夠根據使用者的提示,生成連貫、合理的回覆,從而實現自然語言處理任務。
3.上下文理解的關鍵技術
GPT不僅能理解使用者當前的問題,還能基於前文理解問題背景。這得益於Transformer架構中的「自注意力機制(Self-attention)」。該機制使得GPT能夠捕捉長文字中的依賴關係。通俗地說,GPT在進行文字接龍判斷時,不僅基於使用者剛輸入的「提示」,還會將之前多輪對話中的「提示」和「回覆」作為輸入引數。然而,這個距離長度是有限的。對於GPT-3.5來說,其距離限制為4096個詞彙(tokens);而對於GPT-4,這個距離已經大幅擴充套件至3.2萬個tokens。
4.大模型為何驚豔?
我們已經介紹了GPT的原理,那麼他是如何達成這種神奇效果的呢?主要分三步:
①自監督學習:利用海量的文字進行自學,讓GPT具備預測上下文概率的基本能力。
②監督學習:人類參與,幫助GPT理解人類喜好和期望的答案,本質為微調(fine-tune)。
③強化學習:根據使用者使用時的反饋,持續優化和改進回答質量。
其中,自監督學習最關鍵。因為,大模型的魅力在於其「大」——大在兩個方面:
①訓練資料量大:
即訓練大模型的資料規模,以GPT-3為例,其訓練資料來源為網際網路的各種精選資訊以及經典書籍,規模達到了45TB,相當於閱讀了一億本書。
②模型引數量大:
引數是神經網路中的一個術語,用於捕捉資料中的規律和特徵。通常,宣稱擁有百億、千億級別引數的大型模型,指的都是其引數量。
追求大型模型的引數量是為了利用其神奇的「湧現能力」,實現所謂的「量變引起質變」。舉例來說,如果要求大模型根據emoji猜電影名稱,如