如何從800萬資料中快速撈出自己想要的資料?
一、需求調研
正如題目所說,我們使用的是Oracle資料庫,資料量在800萬左右。我們要完成的事情就是在著800萬資料中,通過某些欄位進行模糊查詢,得到我們所需要的結果集。
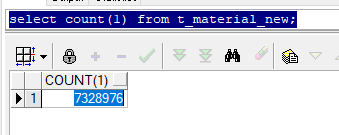
這是表裡的資料,一共7328976 條資料,接近800萬
select count(1) from t_material_new;
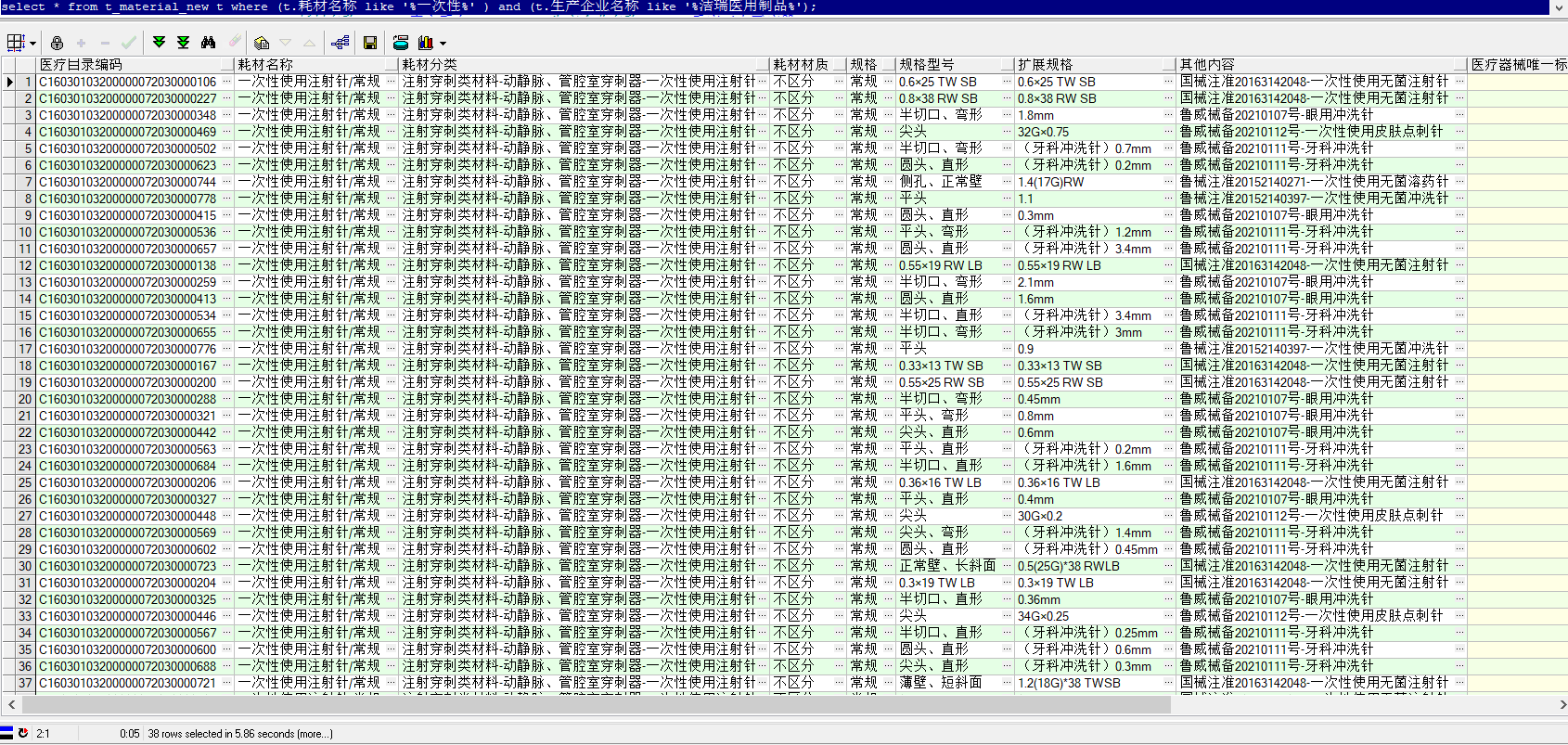
這是我們想要的結果,根據耗材名稱、生產企業名稱 或其他欄位模糊查詢出我們想要的結果集
select * from t_material_new t where (t.耗材名稱 like '%一次性%' ) and (t.生產企業名稱 like '%潔瑞醫用製品%');
二、常規思路
一聽到要模糊查詢,我們想到得關鍵字當然是like了。
like我們常用的有以下三種匹配方式
- 欄位 like '%關鍵字%' 查詢出欄位包含」關鍵字」的記錄
- 欄位 like '關鍵字%' 查詢出欄位以」關鍵字」開始的記錄
- 欄位 like '%關鍵字' 查詢出欄位以」關鍵字」結束的記錄
我們都知道like關鍵字的查詢效率比較低,我們來看下具體查詢效率
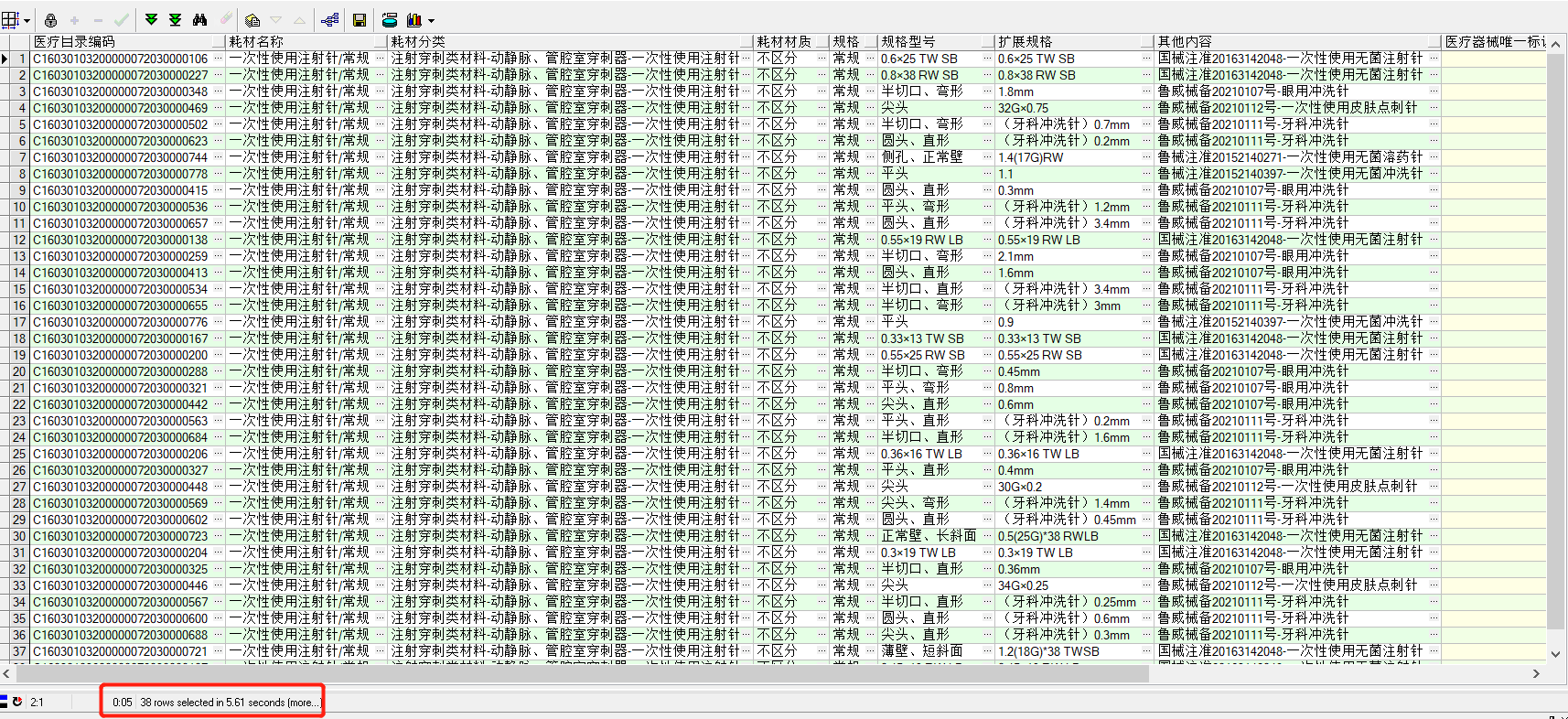
1、欄位 like '%關鍵字%' 方式
-- 1、查詢包含關鍵字記錄 需要花費5.61s
select * from t_material_new t where (t.耗材名稱 like '%一次性%' ) and (t.生產企業名稱 like '%潔瑞醫用製品%');
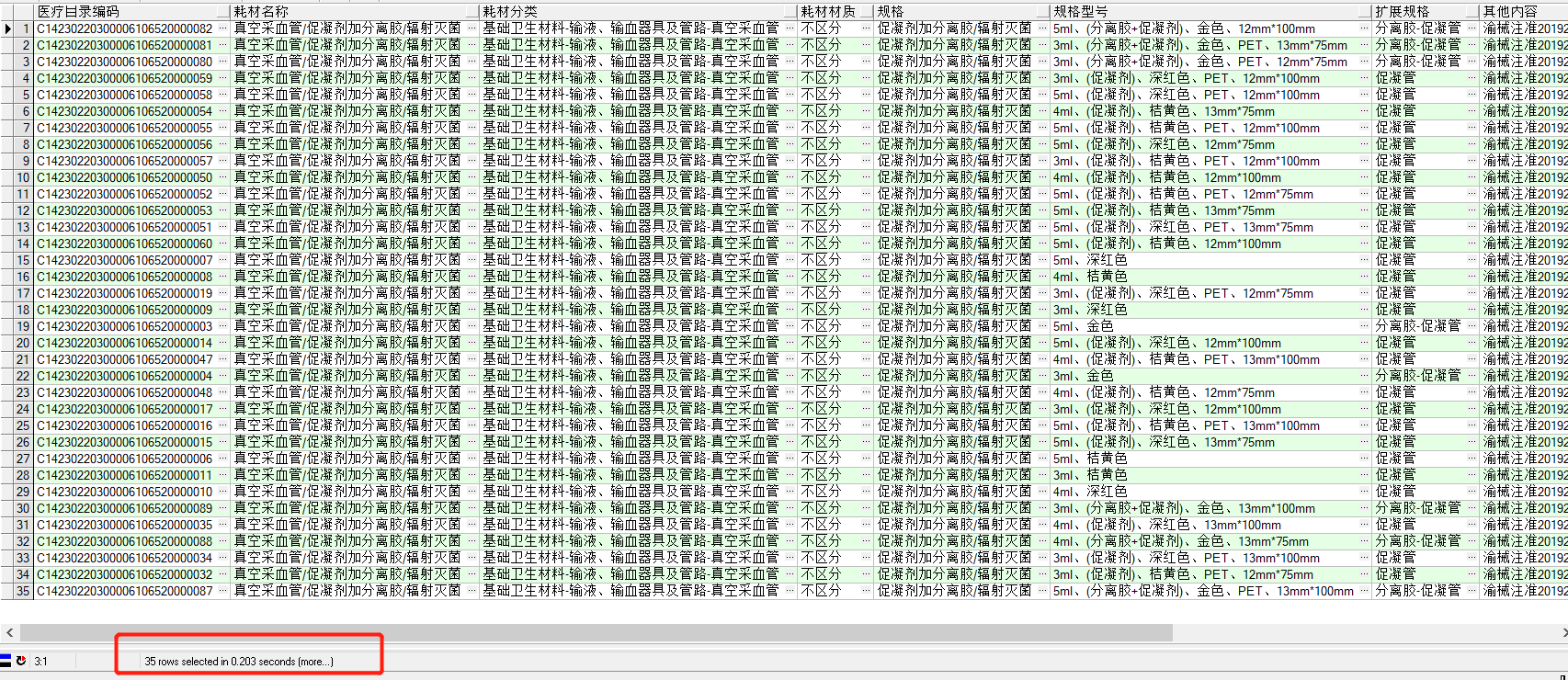
2、欄位 like '關鍵字%' 方式
-- 2、查詢以」關鍵字」開始的記錄 花費0.203s
select * from t_material_new t where (t.耗材名稱 like '真空採血%') and (t.生產企業名稱 like '重慶三豐醫療器%');
3、 欄位 like '%關鍵字' 方式
3、查詢以」關鍵字」結束的記錄 花費0.484s
select * from t_material_new t where (t.耗材名稱 like '%腸內') and (t.生產企業名稱 like '%療器械有限公司');
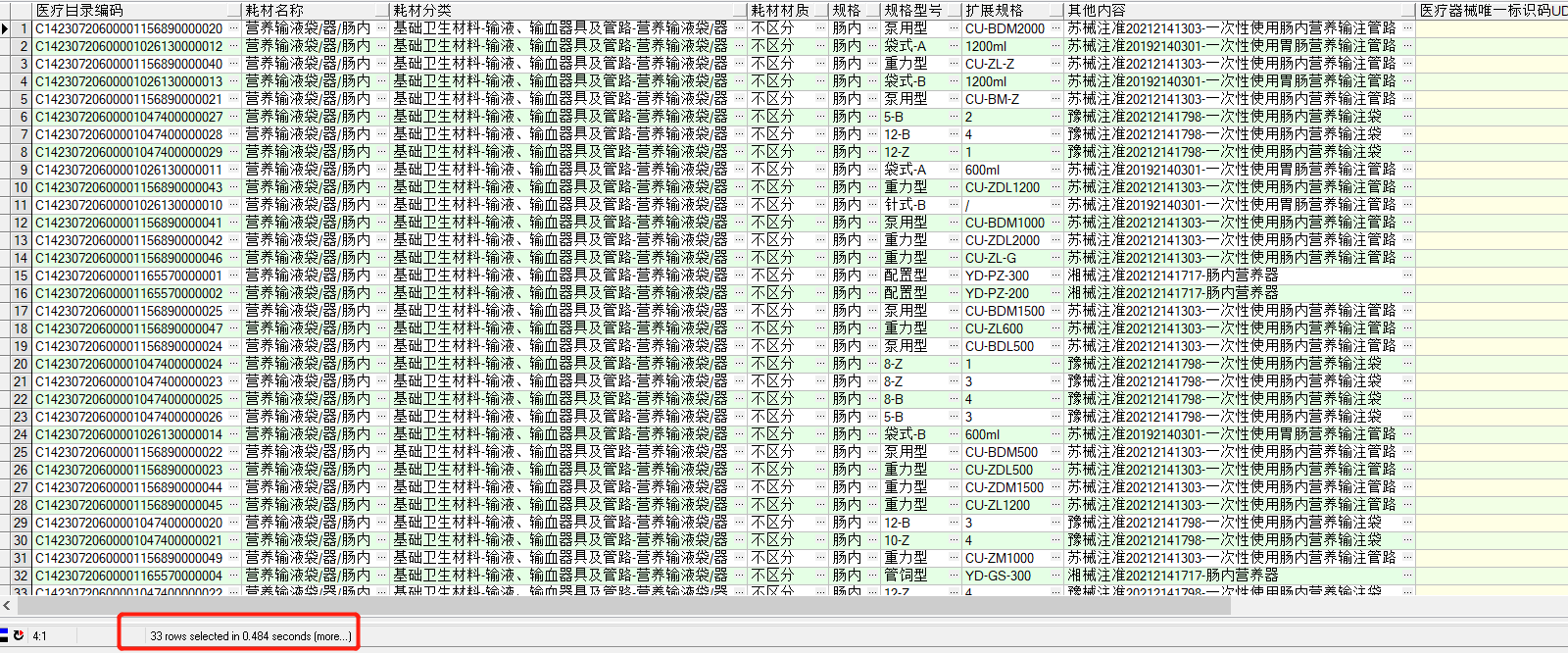
通過以上測試,我們可以得出以下結論
- 欄位 like '%關鍵字%' 沒法走索引,效率極低
- 欄位 like '關鍵字%' 和 欄位 like '%關鍵字' 可以走到索引,查詢效率可以接受
我們讓使用者通過第二種、或第三種方式檢索也不太現實。
那就只能想想辦法看能不能優化了。
四、尋找解決方案
遇到問題總是要解決的,然後就去請教大佬了。
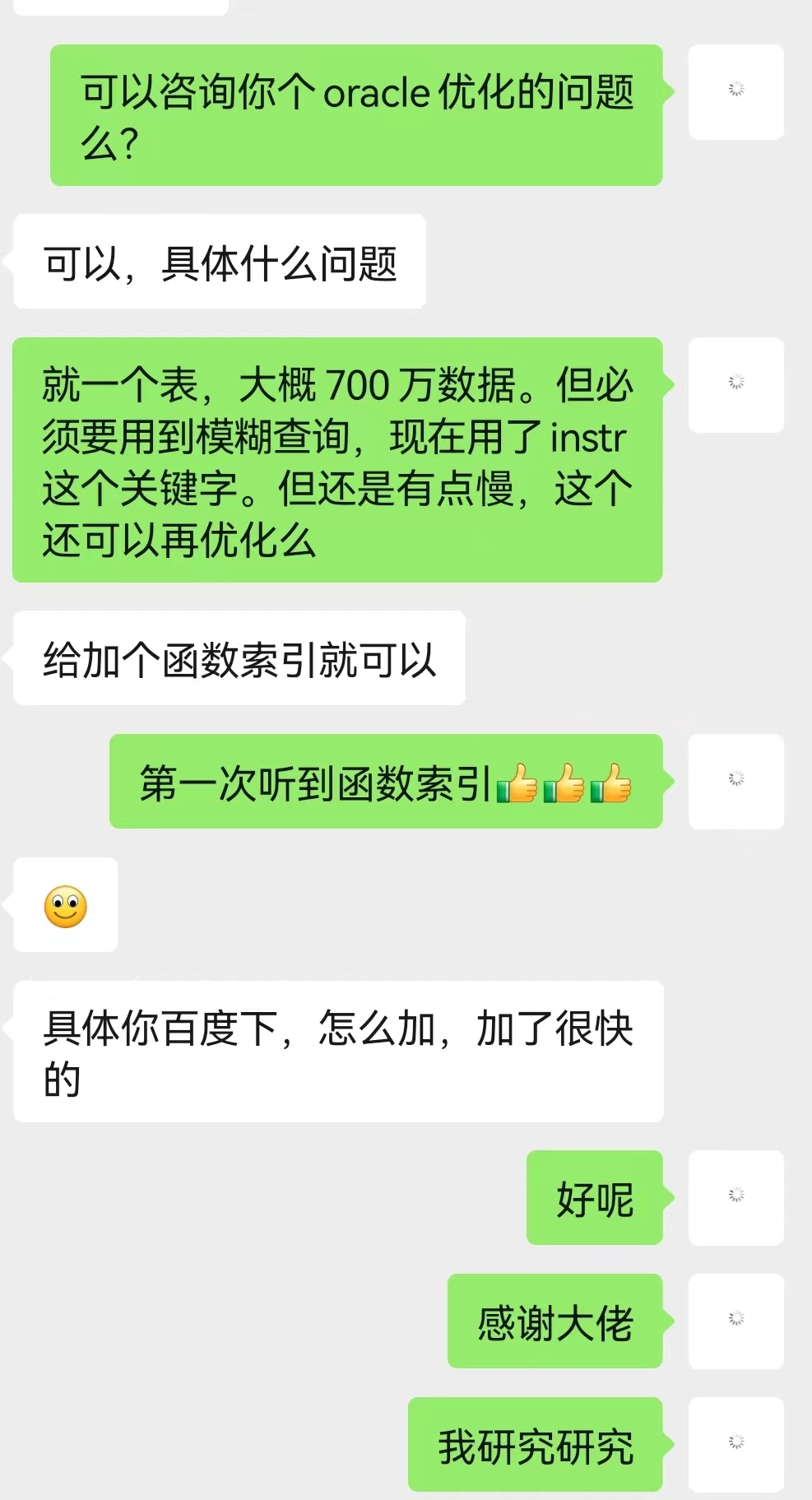
諮詢後小結:
(1)建立函數索引
原來函數也是可以建立索引的,get到新技能了。但是這裡的由於函數入參內容的不確定性,沒法建立函數索引。這種方案便被否決了
(2)提升硬體質量
作為一名資深打工人,提升硬體質量當然不是由我能決定的了。
以上兩種方案都不行,那就只能另闢蹊徑了。
問了度娘之後,從網上有找到了兩種相對靠譜的方案。
1、將like 關鍵字替換為instr 函數
2、建立全文索引
四、說幹就幹,實現它
1 將like 改為instr函數
① 函數簡介
instr 俗稱字元查詢函數。用於查詢目標字串在源字串中出現的位置
② 語法格式
-- sourceString 代表源字串
-- destString 代表目標字串
-- start 代表從源字串查詢開始位置,預設為1,可以省略 負數表示倒數第幾位開始查詢
-- appearPosition 代表想從源字元中查詢出第幾次出現目標字串destString 預設為1,可以省略
instr(sourceString,destString,start,appearPosition)
instr('源字串', '目標字串' ,'開始位置','第幾次出現')
③ 舉個栗子
-- 省略後兩個預設引數
select instr('helloworld','l') from dual; --返回結果:3 即第一次出現"l"的位置是第3位
select instr('helloworld','wo') from dual; --返回結果:6 即第一次出現"wo"的位置是第6位
select instr('helloworld','wr') from dual; --返回結果:0 即未查詢到字串"wr"
--帶上後兩位引數
select instr('helloworld','l',2,2) from dual; --返回結果:4 即在"helloworld"的第2位(e)開始,查詢第二次出現的"l"的位置是4
select instr('helloworld','l',-2,3) from dual; --返回結果:3 即在"helloworld"的倒數第2(l)號位置開始,往回查詢第三次出現的「l」的位置是3
④ 用instr函數改寫上面的sql
select * from t_material_new t where (t.耗材名稱 like '%一次性%' ) and (t.生產企業名稱 like '%潔瑞醫用製品%'); -- 得到結果集需要 6.11秒
-- 相當於
select * from t_material_new t where instr(t.耗材名稱,'一次性')>0 and instr(t.生產企業名稱, '潔瑞醫用製品')>0; -- 得到結果集只需要3.812秒
小結:用instr函數改寫like 關鍵字後,查詢效率明顯提高了。
但是,還有沒有其他方式可以再優化一下呢?
經過小編堅持不懈的問度娘之後,還真找到了另一個方法,那就建立全文索引。
建立全文索引有點複雜,具體操作參照【2使用Oracle全文索引】
2 使用Oracle全文索引
溫馨提示:建立索引是需要佔用一部分磁碟空間的,這其實也是我們常說的以空間換取時間
① Oracle版本的要求
Oracle 10g或以上版本才支援,其他低版本的就不能使用了
② 建立索引前準備工作
oracle全文檢索需要ctxsys使用者的支援,我們需要使用ctxsys使用者下的ctx_ddl這個包。
在建立全文索引過程中,基本上都在使用這個包。
我們在安裝Oracle的時候,ctxsys使用者可能沒啟用。
我們這裡要做的有兩步
Ⅰ 解鎖ctxsys使用者,以獲得ctx_ddl包的使用許可權。
-- 需要以Oracle管理員system使用者進行解鎖
alter user ctxsys account unlock;
Ⅱ 將ctx_ddl包的操作許可權賦給需要操作的使用者
grant execute on ctx_ddl to testuser;
③建立分析器
oracle text的分析器 ,類似於lucene中的分詞器,將需要檢索的記錄,按照一定的方式進行片語拆分,然後存放在索引表中。檢索的時候根據索引表中存放的拆分片語,對傳入的關鍵字進行匹配,並返回匹配結果集。
oracle text中的分析器有3種:
- basic_lexer:只能根據空格和標點來進行拆分。比如「雲南楚雄」,只能拆分為「雲南楚雄」一個片語
- chinese_vgram_lexer:專門的漢語分析器,按字單元進行拆分,比如「雲南楚雄」,可以拆分為「雲」、「雲南「、」南楚」、「楚雄」、「雄」五個片語。這種方式的好處是能夠將所有有可能的片語全部儲存進索引表,使得資料不會遺漏。
- chinese_lexer:一種新的漢語分析器,能夠認識大部分常用的漢語詞彙,並按常用詞彙進行拆分儲存。比如「雲南楚雄」,只會被拆分為「雲南」、「楚雄」兩個片語。
為了是的需要檢索的資料不會出現遺漏,這裡我們選擇chinese_vgram_lexer 這個分詞器
登入我們需要查詢資料的使用者,以chinese_vgram_lexer 這種分詞器方式建立分析器
-- 建立一個「chinese_vgram_lexer」分析器,名稱為my_lexer
begin
ctx_ddl.create_preference ('my_lexer', 'chinese_vgram_lexer');
end;
④ 建立過濾片語
我們在檢索資料的時候,通常不需要某些片語進行檢索,就如同上面查詢條件中的生產企業。
我們不希望輸入「公司」 、「有限公司」、「有限責任公司」等這樣的關鍵詞,也會檢索出結果。
我們就可以通過建立過濾片語,以實現建立索引的時候將這些片語過濾掉
-- 建立一個片語過濾器
begin
ctx_ddl.create_stoplist('my_stoplist');
end;
-- 往片語過濾器中新增過濾關鍵字
begin
ctx_ddl.add_stopword('my_stoplist','公司');
ctx_ddl.add_stopword('my_stoplist','股份有限公司');
ctx_ddl.add_stopword('my_stoplist','有限責任公司');
end;
⑤ 到了最重要的一步,建立索引
以上所有都是為這一步準備的。
根據需求,我們需要對錶t_material_new 中的耗材名稱和生產企業名稱進行檢索。
所以我們需要以耗材名稱和生產企業名稱欄位建立索引。建立指令碼如下
注:以下指令碼在執行的時候需要花費一點時間,耐心等待即可
-- 在t_material_new表中的【耗材名稱】和【生產企業名稱】欄位上建立索引,索引類系那個為context型別,該索參照到的分析器為前面定義的my_lexer,該索參照到的過濾片語為前面定義得my_stoplist
create index INDEX_MATERIAL_NAME on t_material_new(耗材名稱) indextype is CTXSYS.CONTEXT parameters('lexer my_lexer stoplist my_stoplist');
create index INDEX_MATERIAL_PROD on t_material_new(生產企業名稱) indextype is CTXSYS.CONTEXT parameters('lexer my_lexer stoplist my_stoplist');
建立完索引後,我們會發現當前使用者下,關於INDEX_MATERIAL_NAME 索引多了四個表,關於
INDEX_MATERIAL_PROD 也多了四個表。

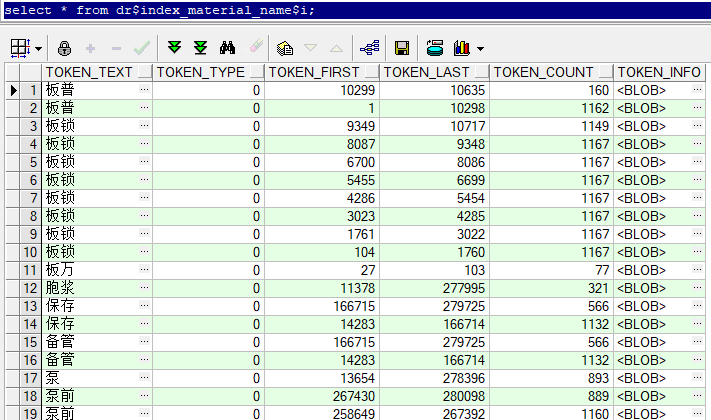
其中t_material_new表中【耗材名稱】欄位被拆分後的片語儲存在dr\(index_material_name\)i表中
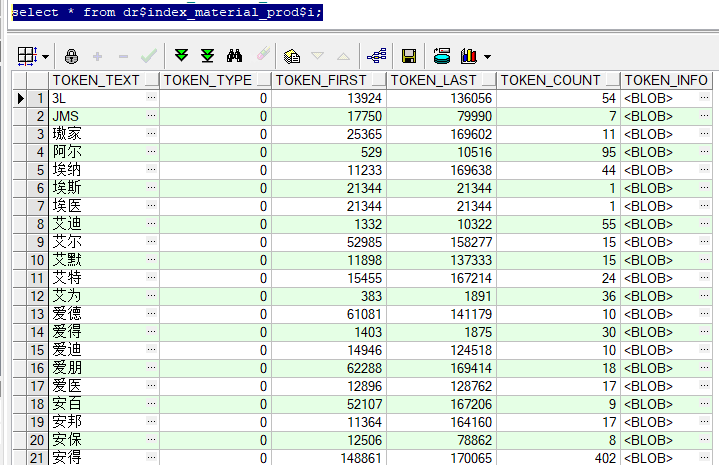
其中t_material_new表中【生產企業名稱】欄位被拆分後的片語儲存在dr\(index_material_prod\)i表中
我們來查詢下表的具體內容看看
select * from dr$index_material_name$i;
select * from dr$index_material_prod$i;
⑥ 如何使用索引?
-- 將以上查詢sql改下為用全文索引的查詢方式 (查詢出我們想要的結果集僅僅需要0.312秒)
select * from t_material_new t where contains(t.耗材名稱,'一次性')>0 and contains(t.生產企業名稱, '潔瑞醫用製品')>0;
到此,基本上已經圓滿完成了我們的需求任務。
我們做到了模糊查詢從 6.11秒--> 3.812秒--> 0.312秒
可能細心的小夥伴會發現一個問題,
如果表t_material_new 中插入了新的資料,那麼分析器中不就沒記錄到這些詞了嗎?
小夥伴提的這個問題挺好的,當然我們也有對應的方法解決
⑦ 完善我們的索引
當我們需要修改t_material_new 表中的資料,比如新增、刪除、更新等操作時,INDEX_MATERIAL_NAME和INDEX_MATERIAL_PROD索引是不會同步更新資料的,需要我們在程式中手動的更新。
-- 更新同步索引中分詞資料
begin
ctx_ddl.sync_index('INDEX_MATERIAL_NAME')
ctx_ddl.sync_index('INDEX_MATERIAL_PROD')
end
當然了我們可以在表t_material_new 上寫一個oracle的觸發器,當新增、刪除、修改操作時,進行索引分詞更新;或者建立定時任務定時更新也可以。
定時任務的建立可以參照之前寫過的文章
Oralce定時任務實際應用
到此,Oracle模糊查詢優化就算完成了,但是還想分享一個小技巧。
怎麼將excel 表格中的資料快速匯入到Oracle資料庫中呢?
要是資料少,都好說。當資料量到幾十萬、或者幾百萬的時候就比較難了。
這裡推薦用Navicat工具匯入
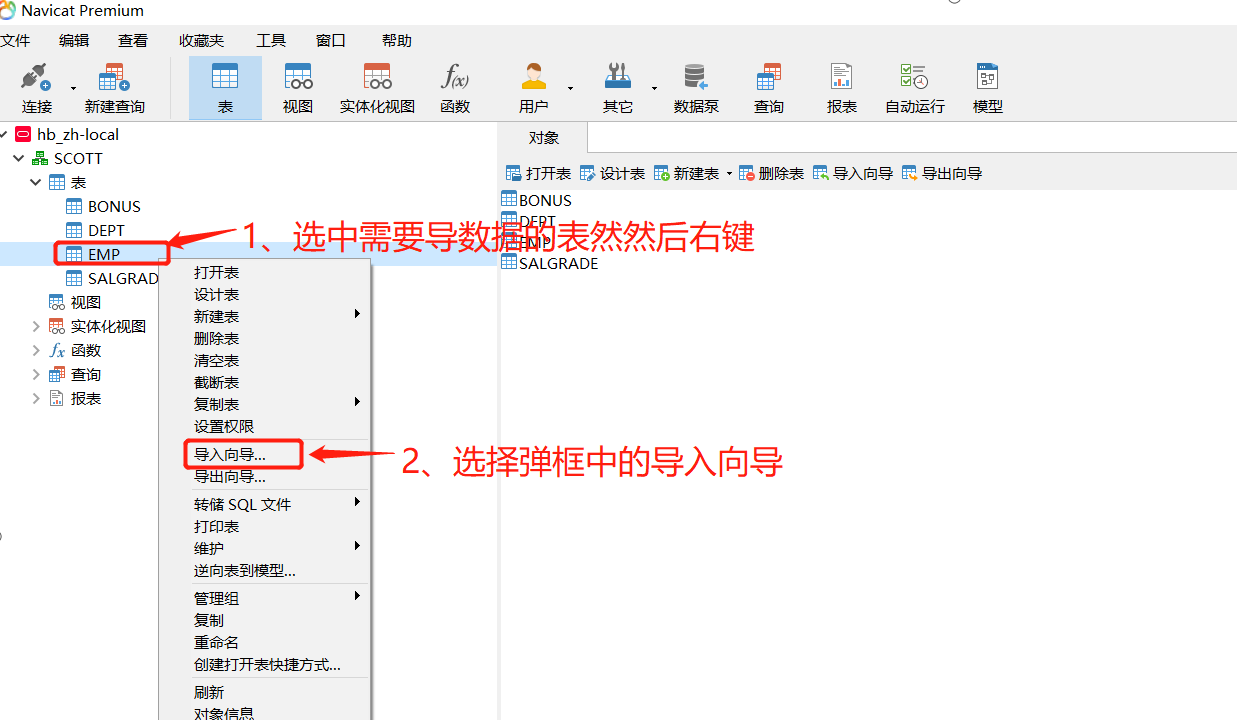
個人親自實測,匯入速度還是挺快的。
以上就是文章的全部內容了,希望對你有所幫助