扯什麼kafka順序消費,然後呢?古爾丹,代價是什麼
著名面試八股文之kafka為什麼讀寫效率高,寫的答案之一是partition順序寫,因而能保證分割區內的不連續的有序性。
這裡的重點是有序追加到磁碟,而不是嚴格意義上的完全有序性。
幾年前參加了一巨量資料崗位面試,95%的時間在扯java基礎(這個可以有)和java web相關。剩下大約5%的時間換了人聊了一個kafka問題,算是巨量資料直接相關的東西吧。
於是有以下對話。
M:kafka能保證順序消費嗎?
我:呃,我覺得不能。
幾秒停頓,措詞中。。。。。
M:kafka分割區內能保證順序消費啊!
M君帶著一絲得意,看看我的簡歷。
又擡起頭,彷彿在說,你改悔罷!

我:是的,但有前提,不能完全保證,得看場景。。。
M:其實我們公司沒有巨量資料開發,巨量資料相關用的XXX(不記得了,大約是某公司的一個什麼巨量資料一攬子解決方案)
我:???
該公司是做車聯相關的產品的(沒有自己獨立的巨量資料平臺,應該車輛使用者不多,資料不大,業務不復雜),
湊巧,我也剛好做過某網紅新能源車相關的巨量資料平臺。
這裡結合新能源車背景來聊一聊kafka在該背景業務場景下,單分割區順序消費到底靠不靠譜。
我們從資料生產消費兩端分別講一講。
生產端
1.終端問題
終端故障,網路或未知原因
比如車輛感測器故障等問題導致本身就亂序傳送了,徒之奈何?
比如我們在T+1做定時任務計算車輛前一天的充電行程等任務時,就少部份地發現,還有前兩天三天的資料,延遲尺度達到了天。
常規性地發現,網路情況達到小時級別的延遲。
之所以是凌晨定時任務跑前一天的資料,就是因為資料延遲時有發生。
如果實時計算,需要資料延遲儘可能的小,在watermark機制(這部份最後會提到)下,超出部份資料將不會被納入計算。這樣行程充電等業務就會被漏算,或者一個完整的過程會被切割等異常情形。
關於資料延遲這一塊,某些情形上游甲方廠商可能可以解決,有些情形它也束手無策啊,它控制不了終端操作使用者的行為。
這時候作為一線開發者,如果一開始答應了產品/運維為了時效性而使用實時計算,到時候出了問題,你能用各種理由解釋不是我們的問題?
當初規劃選型的時候考慮到了嗎?有備案嗎?現在還認可嗎?
等一系列甩鍋扯皮問題。
2.資料傾斜
當時我們的業務主要是基於某車怎麼樣進行計算。想要對車輛產生的資料進行順序消費,至少應該將單輛車的資料統一傳送到固定的某個partition分割區。
對吧?
也就是我們今天討論的前提是基於一個常識,當我們討論kafka能否順序消費,一定是分割區內才有討論的可能,跨分割區整個topic是不能夠的。
當然,你也可以說我需要基於上百萬輛車全部進行順序消費。那每輛車有一千多個感測訊號,只要在操作過程中,每兩秒鐘相關的訊號都會上報一條記錄,每天幾十上百億的資料全部統一順序處理?
這樣kafka topic就只能有一個分割區,這樣的kafka叢集吞吐量不敢想象。
要保證某輛車產生的資料固定發到某個分割區,一般情況下,是對車輛的VIN碼(車輛唯一標識,相當於人的身份證)對分割區數求模,得到的就是該車輛應該傳送的分割區ID。
kafka的傳送分割區策略:
-
如果未自定義分割區策略,且key為空,輪詢分割區傳送,保證各分割區資料平衡。
kafkaTemplate.send(topic, info); -
如果未自定義分割區策略,指定了key,則使用預設分割區策略。key對分割區數求模得到傳送的分割區。
kafkaTemplate.send(topic,key, info);
預設分割區策略為org.apache.kafka.clients.producer.internals.DefaultPartitioner
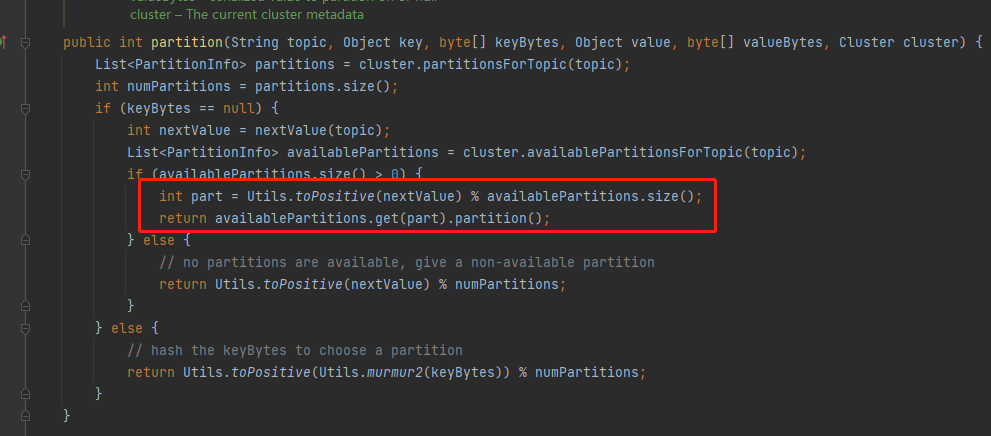
- 如果指定了自定義分割區策略,不管指沒指定key,以自定義策略為準。
@Component
public class DefinePartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
// 這裡也可以設定分割區數或者定時獲取分割區數
return key.hashCode() % (cluster.partitionsForTopic(topic).size() - 1);
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}
然後指定分割區策略
spring.kafka.producer.properties.partitioner.class = com.nyp.test.service.DefinePartitioner
將vin作為key,或者自定義分割區,可以將同一輛車傳送的資料指定到同一分割區。
但是在實踐的過程當中,我們會發現,有的車作為長途或短途的運輸車輛,或者作為網約車,那麼每天上報的資料會相對較大,
而有的車當天沒有出行或其它充電等任何操作,則沒有上報資料。
這樣就會造成資料傾斜,導致各節點(broker)各分割區之間資料嚴重不平衡。
可能會導致以下情況(2,3主要針對巨量資料框架)
- GC 頻繁
過多的資料集中在某些分割區,使得JVM 的記憶體資源短缺,導致頻繁 GC。 - 吞吐下降、延遲增大
資料單點和頻繁 GC 導致吞吐下降、延遲增大。 - 系統崩潰
嚴重情況下,過長的 GC 導致 TaskManager 失聯,系統崩潰。
3.擴容分割區的代價
kafka的弱點,也是Pulsar的優點。
簡單點說,kafka的資料與broker是存放在一起的,如果要加broker,就需要將資料平衡到新的broker。
而Pulsar的架構則是節點與資料分離,訊息服務層與儲存層完全解耦,從而使各層可以獨立擴充套件,所以擴容的時候會非常方便。當然這不是本文的重點。
總之,
當kafka需要擴容或者對topic增加分割區時,由第2點我們得知,資料將發往哪個分割區將由key%分割區數決定,當分割區數量變化後,所有的現有資料在進行擴容或重分割區的時候都必須進行key%分割區數進行重路由。
這一步的代價必須考慮進去。
4.單分割區,A,B訊息順序傳送,A失敗B成功,A再重試傳送,變成BA順序?
4.1 訊息的傳送
kafka需要在單分割區保證訊息按產生時間正序排列,至少應該保證按訊息產生的時間正序傳送。
假設訊息源嚴格按照時間產生的前提,
-
可以同步傳送,一次只傳送一條。
同步傳送,阻塞直至傳送成功,返回SendResult物件,裡面包含ProducerRecord和RecordMetadata物件。
SendResult result = kafkaTemplate.send(topic, key, info).get(); -
也可以非同步傳送,當資料達到一定大小批次提交到叢集,或者3秒鐘提交一次到叢集。
非同步傳送,返回一個ListenableFuture物件,大家應該對Future不陌生。此物件可以新增回撥方法。在成功或失敗時執行相應的任務。
ListenableFuture<SendResult<Object, Object>> listenableFuture = kafkaTemplate.send(topic, key, info);
listenableFuture.addCallback(new ListenableFutureCallback<SendResult<Object, Object>>() {
@Override
public void onFailure(Throwable ex) {
}
@Override
public void onSuccess(SendResult<Object, Object> result) {
}
});
同時,非同步傳送需要新增相應的設定,比如一次提交多少條資料,比如如果資料遲遲沒有達到傳送資料量,需要設定一個最大時間,超過這個時間閥值需提交一次,等等。
注意後兩個引數的設定。
不同版本之間,引數名稱會有差異。
batch.size
每當多個記錄被傳送到同一個分割區時,生產者將嘗試將記錄批次處理到更少的請求中。這有助於提高客戶機和伺服器上的效能。此設定控制以位元組為單位的預設批次處理大小。
較小的批大小將使批次處理不那麼常見,並可能降低吞吐量(批大小為零將完全禁用批次處理)。非常大的批次處理大小可能會更浪費記憶體,因為我們總是會分配指定批次處理大小的緩衝區,以預期會有額外的記錄。
注意幾點:
- 此引數控制的傳送批次的大小是以位元組數,而不是資料條數。
- 此引數控制粒度為分割區,而不是topic。當發往某個分割區的資料大於等於此大小時將發起一次提交。
- 合理控制此引數。
linger.ms
這個設定給出了批次處理延遲的上限:一旦我們獲得了一個分割區的batch_size值的記錄,無論這個設定如何,它都會立即傳送,但是如果我們為這個分割區積累的位元組少於這個數,我們將在指定的時間內「逗留」,等待更多的記錄出現。該設定預設為0(即沒有延遲)。例如,設定LINGER_MS_CONFIG =5可以減少傳送的請求數量,但在沒有負載的情況下,傳送的記錄將增加5ms的延遲。max.block.ms
前兩個引數能阻塞(等待)多長時間。buffer.memory
生產者可以用來緩衝等待傳送到伺服器的記錄的記憶體的總位元組數。如果傳送記錄的速度比傳送到伺服器的速度快,生產者將阻塞max.block.ms,之後它將丟擲異常。
這個設定應該大致對應於生產者將使用的總記憶體,但不是硬性限制,因為不是生產者使用的所有記憶體都用於緩衝。一些額外的記憶體將用於壓縮(如果啟用了壓縮)以及維護正在執行的請求。
4.2 訊息的確認(ack)
前面訊息已經傳送出去了,但要保證不丟訊息,不重發訊息,即Exactly Once 精次一次性消費,至少需要保證生產端的訊息確認機制。
acks引數控制的是訊息發出後,kafka叢集是否需要響應,以及響應的級別。
-
acks=0
如果設定為0,那麼生產者將不會等待伺服器的任何確認。該記錄將立即新增到通訊端緩衝區並被認為已傳送。在這種情況下,不能保證伺服器已經接收到記錄,重試設定將不會生效(因為使用者端通常不會知道任何失敗)。為每條記錄返回的偏移量將始終設定為-1。
為方便記憶,這裡的0指是的需要0個節點確認。 -
ack= 1
這將意味著leader將記錄寫入其本地紀錄檔,但將在不等待所有follower完全確認的情況下進行響應。在這種情況下,如果leader在確認記錄後立即失敗,但在follower複製它之前,那麼記錄將丟失。
為方便記憶,這裡的1指的是隻需一個節點確認,這裡一個節點肯定指的是主節點leader. -
ack=all或-1
這是最高階別的確認機制,同時也意味著吞吐量受到限制。它將等待leader和所有follower副本都響應,才認為傳送完畢。
為方便記憶,這裡的all指的是需要所有節點確認。
4.3 冪等性
回到第4小節的主題,當由於網路抖動或者其它任何已知未知原因,訊息AB傳送順序由於A失敗重試最終變成了BA的倒序,那麼kafka分割區還能保持最初期望中的AB有序性嗎?
答案是可以,只要開啟冪等性,在Producer ID(即PID)和Sequence Number的基礎上,訊息最終將保持AB的順序。
冪等性對於WEB程式設計師應該不會陌生,前端呼叫後端介面,寫入訂單或者發起支付,由於使用者重複操作網路重試等各種異常原因導致多次請求,後端應保證只響應一次請求或/且最終效果一致。
後端各微服務之間呼叫也有重試,也是同樣的道理。
具體到kafka訊息傳送,跟4.2小節中的Exactly Once實際上有相同的地方,通過設定enable.idempotence=true 開啟冪等性,它的基礎或前提條件是,會自動設定ack=all。
如何設定kafka生產端的冪等性?
-
enable.idempotence=true
顯式開啟冪等性。kafka 3.0以上的版本,此值為false,這裡應該顯式設定。 -
replication.factor
kafka叢集的副本數 至少應大於1 -
acks=all
kafka 3.0 以後的版本,此值為1,這裡應該顯式設定。 -
max.in.flight.requests.per.connection=1
在阻塞之前,使用者端將在單個連線上傳送的未確認請求的最大數量。請注意,如果將此設定設定為大於1,並且存在失敗的傳送,則存在由於重試(即,如果啟用了重試)而導致訊息重新排序的風險。
預設值為5,如果要開啟冪等性,此值應<=5。
但如果引值>1 <=5 不會報錯,但還是有亂序的風險。 -
retries > 0
重試次數應大於0,否則沒有重試。那樣的話,A失敗後也不能再發成功,即4小節開頭的問題。
注意:當用戶設定了enable.idempotence=true,但沒有顯式設定3,4,5,則系統將選擇合適的值。如果設定了不相容的值,將丟擲ConfigException。
同時,為保證完整性,消費端應保證 enable.auto.commit=false,isolation.level=read_committed,即自動確認改為手動確認,事務隔離級別改為讀已提交。
4.3 冪等性原理
kafka為解決資料亂序和重發引入了PID和Sequence Number的概念。 每個producer都會有一個producer id即PID。這對使用者不可見。
生產端傳送的每條訊息的每個<Topic, Partition>都對應一個單調遞增的Sequence Number。
同樣,Broker端也會為每個<PID, Topic, Partition>維護一個序號,並且每Commit一條訊息時將其對應序號遞增。
-
對於接收的每條訊息,如果其序號比Broker維護的序號大1,則Broker會接受它,否則將其丟棄.
-
如果訊息序號比Broker維護的序號差值比1大,說明中間有資料尚未寫入,即亂序,此時Broker拒絕該訊息
-
如果訊息序號小於等於Broker維護的序號,說明該訊息已被儲存,即為重複訊息,Broker直接丟棄該訊息
傳送失敗後會重試,這樣可以保證每個訊息都被傳送到broker。
這裡再解釋一下為什麼能解決亂序,假設broker在接收到 A訊息之前的Sequence Number為10,
A在生產端為11,B為12,
由於某種原因,A失敗了,此時broker端的Sequence Number仍然為10
此時,B到達broker,它為12,大於10,且它們之間的差異大於1,此時拒絕訊息B.B訊息傳送失敗。
然後A重試,成功,Sequence Number變為11,
再然後B重試,此時成功。
最終,AB兩條訊息以最初的順序寫入成功。
消費端(非巨量資料模式)
5 單執行緒和多執行緒都不能保證跨分割區順序
訊息量非常大,topic具有幾十幾百分割區的情況下,消費端只用一個執行緒去消費,單是想想就知道不太現實,效能拉跨。
先搞搞一個測試demo測試多執行緒消費
向10個分割區隨機傳送100條資料,資料末尾帶上1-100遞增的序號.
public void sendDocInfo(String info) {
try {
Random random = new Random();
kafkaTemplate.send("test10", random.nextInt(9)+"", info + "_" + i).get();
} catch (Exception e) {
log.error("kafka傳送異常 " + e);
}
}
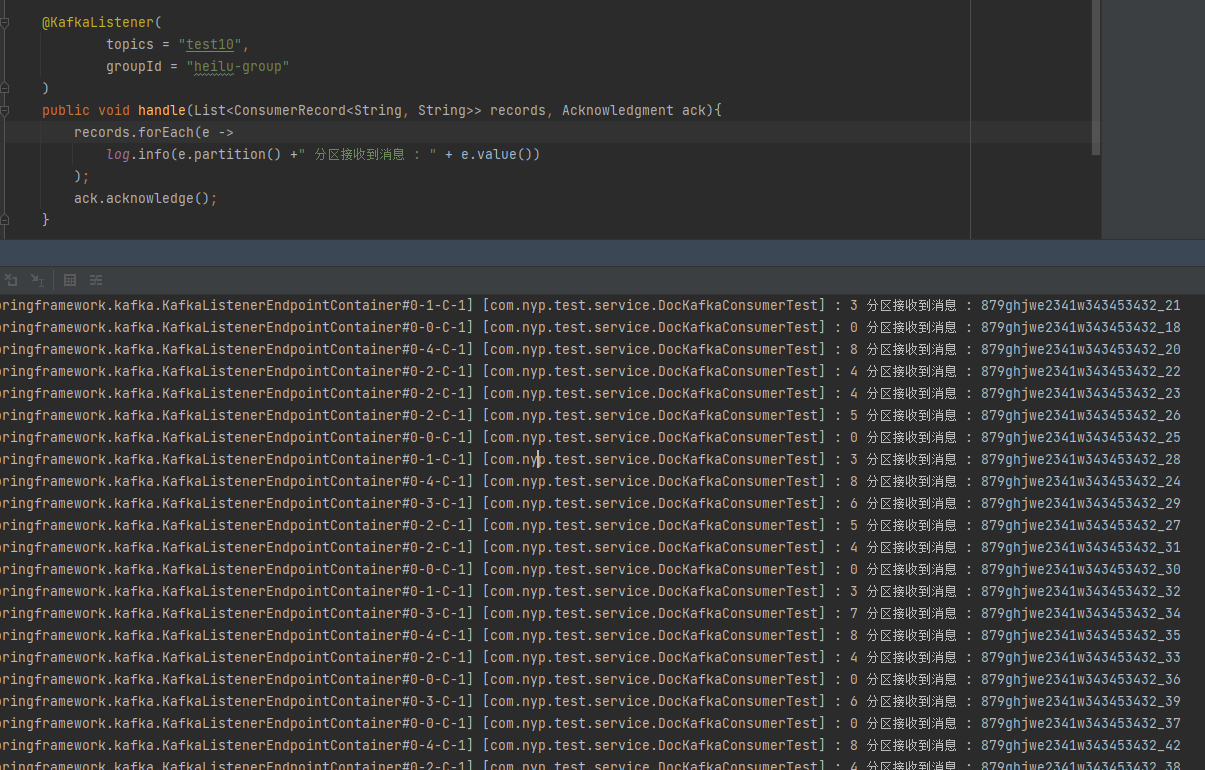
在消費端列印消費,帶上分割區ID。
@KafkaListener(
topics = "test10",
groupId = "heilu-group"
)
public void handle(List<ConsumerRecord<String, String>> records, Acknowledgment ack){
records.forEach(e -> {
log.info(e.partition() +" 分割區接收到訊息 : " + e.value());
});
ack.acknowledge();
}
可以很明顯的看到跨分割區亂序。
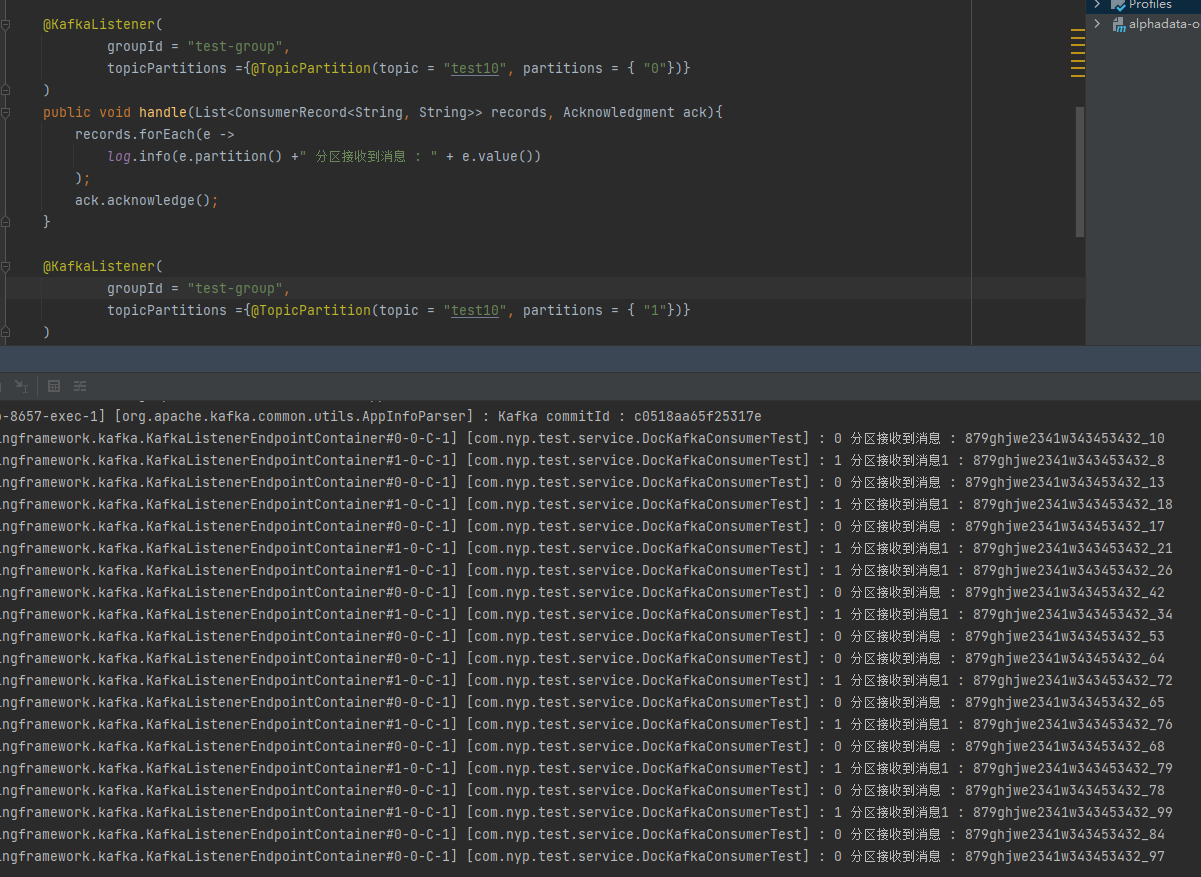
6.執行緒-分割區一一對應
這種情況能保證某個執行緒內的有序性。
但如果有上百個分割區,需要手動寫這麼多套程式碼,這好嗎?
每個執行緒只消費一個對應的分割區
@KafkaListener(
groupId = "test-group",
topicPartitions ={@TopicPartition(topic = "test10", partitions = { "0"})}
)
如圖
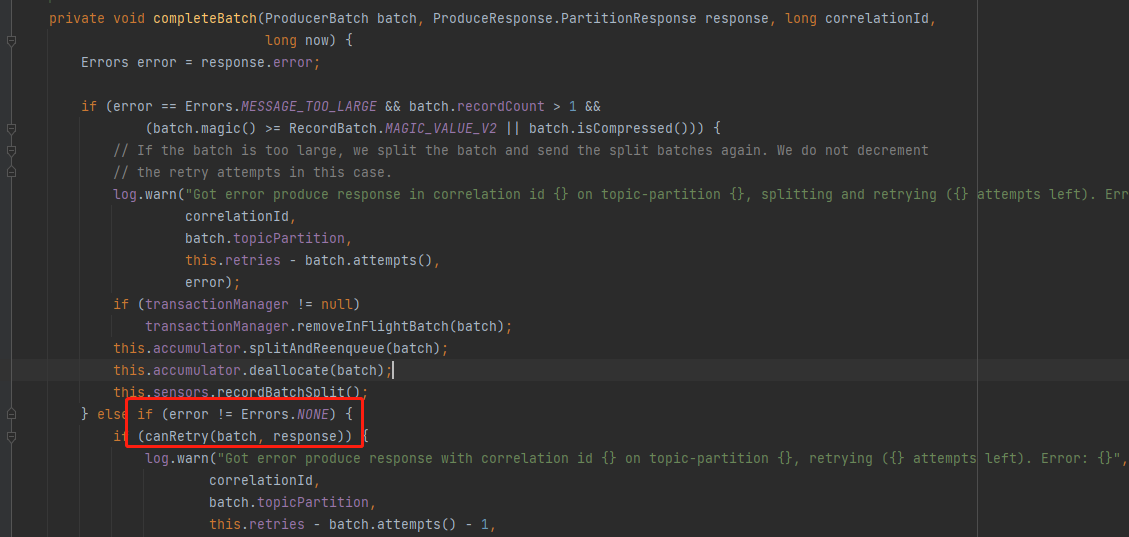
至於Retry的情況,根據原始碼,需要kafka叢集模擬一個異常才能實現,在本地通過攔截器或其它方式都是模擬不出來的。
所以沒做這塊的演示。
response.error不為NONE的情況下,才做canRetry判斷.
7.巨量資料領域的解決(緩解)方案watermark機制。
在任何生產領域,資料的延遲和亂序是一定會產生的。無非是概率大小,嚴重程度不同而已。
對於這種情況,巨量資料框架的共識是,對於資料亂序延遲,我們要等,但不能無限等待下去。
因此flink/spark引入了watermark俗稱水印機制。
請注意,此機制是為了緩解資料的延遲和亂序,而不是徹底解決該問題。
就像開篇所說的第1點,車輛跑在路上總會有各種突發狀態,感測器會老化,深山老林訊號不好,這種情況連終端生產廠商都無法徹底解決,下游資料廠商怎麼能根除呢?
watermark一般配合Window一起使用。
如果對window不瞭解的,可以參考我之前寫的這篇文章 關於我因為flink成為spark原始碼貢獻者這件小事
可以簡單理解為一個時間段(微批,短至毫秒,長可至時分秒),處理一批資料。
不是搞巨量資料的,對巨量資料不感興趣的,可以跳過這一部份。
- watermark的本質是一個時間戳,它是為了應對資料亂序和延遲的一種機制。
- watermark = max(eventTime) - 允許遲到的長度
- window中,不考慮allowLateness,當watermark等於大於end-of-window時,視窗觸發計算和銷燬。
比如:
- 有一個視窗`[12:00-12:05)`,watermark允許遲到1分鐘, 接收到兩條資料時間分別為`12:03:43`,`12:05:23`,
那麼watermark = `12:05:23 - 1 minute = 12:04:23` 小於12:05,所以視窗沒有結束,不觸發計算
注:嚴格意義來講,[watermark = `12:05:23 - 1 minute -1ms`] 因為 end-of-window判斷的時候是>= - 當接收到一條資料時間為12:06時,視窗觸發計算 如果allowLateness>0,視窗延遲銷燬,假如來了一條資料時間為12:04:49會再次觸發視窗計算 假如來了一條資料時間為12:05:01,不會進行當前視窗,會進入到下一個視窗
- 有一個視窗`[12:00-12:05)`,watermark允許遲到1分鐘, 接收到兩條資料時間分別為`12:03:43`,`12:05:23`,
那麼watermark = `12:05:23 - 1 minute = 12:04:23` 小於12:05,所以視窗沒有結束,不觸發計算
- 考慮到程式碼並行度與上游(如kafka,socket)分割區數不匹配可能會導致有些分割區消費不到資料,如測試socket只有一個分割區,而flink程式碼中有8個並行度,
那麼
- 會有7個並行度裡消費不到資料,它的watermark為Long.minvalue,
- 而flink的watermark在多並行度下,以最遲的那個為準,所以
-
整個flink任務中的watermark就為Long.minvalue,這時整個任務不會輸出任務資料,因為watermark過小,觸發不了任務window.
類似於木桶理論,一個木桶能裝多少水由最短的那根木桶決定;同樣的,flink任務中的watermark由最小的分割區的watermark決定。
解決方法:
- 設定兩邊分割區度保持一致
- 高版本里 .withIdleness(Duration.ofSeconds(x)) 在這個時間裡,如果有空閒分割區沒有消費資料,那麼它將不持有水印, 即全域性水印的推進將不考慮這些空閒分割區。
- 如果flink任務收到一個錯誤資料,遠超現在的系統時間,如2100-09-09 00:00:00,在除了空閒分割區外的分割區都收到這樣的資料,那麼flink任務的watermark 將超過系統時間,那麼正常資料將不會被系統正常處理。這時,在watermark生成器這裡要做特殊處理。
- Watermark怎樣生成?實時生成和週期性生成(時間或者條數),別忘了第5條。
這部份的原始碼,感興趣的可以試一下,引入flink依賴,版本1.14,沒有使用kafka,使用
nc -lk 9090可生產資料。我的觀點是,每一個後端程式設計師都應該瞭解一點巨量資料計算。
可以看下我這篇文章。public static void main(String[] args) { Configuration configuration = new Configuration(); configuration.setInteger("heartbeat.timeout", 180000); configuration.setInteger(RestOptions.PORT, 8082); StreamExecutionEnvironment streamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment(configuration); // 並行度和上游資料分割區數對watermark生效的影響 // streamExecutionEnvironment.setParallelism(1); // nc -lk 9090 DataStream<TestObject> dataStream = streamExecutionEnvironment .socketTextStream( "192.168.124.123", 9090) .map( e -> { try { Gson gson = new GsonBuilder() .setDateFormat("yyyy-MM-dd HH:mm:ss") .create(); TestObject object = gson.fromJson(e, TestObject.class); return object; } catch (Exception exception) { exception.printStackTrace(); System.out.println("異常資料 = " + e); return new TestObject(); } }); try { OutputTag<TestObject> lateOutput = new OutputTag<>("lateData", TypeInformation.of(TestObject.class)); SingleOutputStreamOperator result = dataStream .filter(e -> StringUtils.isNoneBlank(e.key)) .assignTimestampsAndWatermarks( (WatermarkStrategy<TestObject>) WatermarkStrategy .<TestObject> forBoundedOutOfOrderness(Duration.ofSeconds(10)) .withTimestampAssigner( (row, ts) -> { System.out.println("source = " + row); DateTimeFormatter dtf2 = DateTimeFormatter .ofPattern("yyyy-MM-dd HH:mm:ss", Locale.CHINA); Long time = row.getTime().getTime(); System.out.println("time = " + time); // 如果eventTime > 系統時間,這裡要做處理 // TODO 如果eventTime遠小於系統時間,可能會拖慢整體的Watermark Long now = System.currentTimeMillis(); return time > now ? now : time; } ) .withIdleness(Duration.ofSeconds(5)) ) .keyBy(e -> e.key) .window( SlidingEventTimeWindows.of( Time.seconds(60 * 2), Time.seconds(60))) // 將延遲的資料旁路輸出 .sideOutputLateData(lateOutput) .process( new ProcessWindowFunction<TestObject, Object, String, TimeWindow>() { @Override public void process(String s, Context context, Iterable<TestObject> elements, Collector<Object> out) throws Exception { System.out.println("watermark = " + context.currentWatermark()); System.out.println("watermark = " + new Timestamp(context.currentWatermark()) +" window.start = " + new Timestamp(context.window().getStart()) +" window.end = " + new Timestamp(context.window().getEnd())); elements.forEach(e -> System.out.println("e + " + e)); } }); result.print(); // 遲到不處理的資料 result.getSideOutput(lateOutput).print(); streamExecutionEnvironment.execute("WaterMark test"); } catch (Exception exception) { exception.printStackTrace(); } } @Data @NoArgsConstructor public static class TestObject { private String key; private Timestamp time; private float price; }
8. 小結
kafka為了吞吐量,在生產端設計了順序追加模式,這兩者才是因果。
得益於此,kafka單分割區內的資料可以變得有序,這只是一個副產品。它同時得考慮到資料終端帶來的先天不足,
分割區節點間的資料傾斜帶來的效能問題,
分割區節點擴容的代價,
冪等性所需要代價帶來的吞吐量限制,
以及消費端的限制。種種問題考量。
冪等性更多的是做一次精準消費,防止重複消費,有序只是副產品。
有且只有一次精準消費,可比什麼勞什子有序消費重要得多!就像摩托車是一個交通工具,能跑在廉價的道路(普通伺服器)上,將便利(曾經高大上的巨量資料)帶到千家萬戶(普通小公司)。
但它不是裝X工具。給我個人的感覺,如果真要把kafka的分割區有序性強行用到生產環境,就像下圖這樣。

告辭。
參考:
https://nightlies.apache.org/flink/flink-docs-release-1.15/zh/docs/dev/datastream/operators/windows/
https://juejin.cn/post/7200672322113077303
https://juejin.cn/post/7226612646543818807