分享一個提高運維效率的 Python 指令碼
哈嘍大家好我是鹹魚,今天給大家分享一個能夠提升運維效率的 python 指令碼
鹹魚平常在工作當中通常會接觸到下面類似的場景:
- 容災切換的時候批次對機器上的組態檔內容進行修改替換
- 對機器批次替換某個檔案中的欄位
對於 Linux 機器,鹹魚可以寫個 shell 指令碼或者直接批次使用 sed 命令就能很好的解決
但對於 Windows 機器,上面的方法就不管用了,我們就需要想其他的辦法
這裡鹹魚給大家分享一個由 python 編寫的指令碼,這個指令碼能夠去替換指定文字檔案中的指定內容,而且還能一次替換多個內容
我們先看效果,目標檔案:name.txt
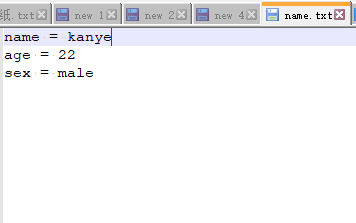
- 修改一個內容
python sed.py c:\name.txt Kanye Edison
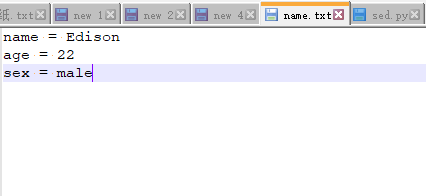
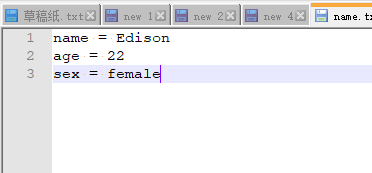
- 修改多個內容
python sed.py c:\name.txt Kanye,male Edison,female
原始碼在文末哦
首先我們匯入模組
import sys
import os
import time
from shutil import copy
然後我們來看一下指令碼中的第一個函數——data_preprocess()
def data_preprocess():
file_name, old_str, new_str = sys.argv[1:4] #接收輸入的引數:目標檔名,舊內容、新內容、字元編碼
try: # 傳入字元編碼引數
encoding = sys.argv[4]
except IndexError: # 沒有傳入字元編碼引數的話就預設使用 'utf-8' 字元編碼
encoding = 'utf-8'
old_str_list = [i.encode(encoding) for i in old_str.split(',')] # 將舊內容轉換成列表形式
new_str_list = [i.encode(encoding) for i in new_str.split(',')] # 將新內容轉換成列表形式
assert len(old_str_list) == len(new_str_list) # 判斷使用者輸入的 old_str 和 new_str 是不是一一對應
trans_tabs = list(zip(old_str_list, new_str_list)) # 將要舊內容列表(old_str_list)和新內容列表( new_str_list)中的元素一一對應
return file_name, trans_tabs # 返回目標檔名,以及一箇舊內容元素和新內容元素一一對應的列表
這個函數實現的功能是接收輸入的引數(目標檔名、要替換的內容,替換的內容、字元編碼格式),然後將要替換的內容與替換的內容分別轉換成列表形式
注意:替換多個內容時在多個內容之間用逗號隔開
例如我們敲如下命令替換一個內容:
python sed.py c:\test.txt Edison Kanye
這個函數就會返回下面內容(由於命令裡沒有傳入字元編碼引數,採取預設的 UTF-8)
file_name = c:\test.txt
trans_tabs = [(Edsion, Kanye)]
如果我們需要替換多個內容(例如將首字母改成大寫)
python sed.py c:\test.txt edsion,kanye,fish Edsion,Kanye,Fish utf-8
這個函數就會返回下面內容(命令傳入了字元編碼引數)
file_name = c:\test.txt
trans_tabs = [(edsion, Edsion), (kanye,Kanye), (fish,Fish)]
接下來我們來看第二個函數—— backup()
def backup(file_name):
time_mark = time.strftime('%Y%m%d_%H%M%S') #時間戳
bak_dir = r'C:\Users\Administrator\Desktop' #備份路徑
basename = os.path.basename(file_name)
os.makedirs(bak_dir) if not os.path.isdir(bak_dir) else True
copy(file_name, os.path.join(bak_dir, basename + '_' + time_mark))
print("備份 %s 成功" %file_name)
這個函數的功能就是在修改檔案之前先把檔案備份,防止後期我們需要回滾復原
最後我們來看最後一個函數—— sed()
這個函數便是整個指令碼的核心,它負責去執行修改替換檔案內容的操作
def sed(file_name, trans_tabs):
with open(file_name + '.swap', 'wb') as swap_fs, open(file_name, 'rb') as file_names: #開啟一個臨時檔案和目標檔案
for line in file_names: # 逐行讀取
for tab in trans_tabs:
line = line.replace(tab[0], tab[1]) if tab[0] in line else line # 修改替換操作
swap_fs.write(line) # 將修改後的內容寫入到臨時檔案當中
os.remove(file_name) # 刪除舊目標檔案
os.rename(file_name + '.swap', file_name) # 將臨時檔案重新命名,就變成了新的目標檔案
首先先開啟一個臨時檔案(file_name.swap)和目標檔案(file_name)
然後對目標檔案(file_name)進行逐行讀取到記憶體上,再去對內容進行修改,最後將修改後的內容寫入到這個臨時檔案(file_name.swap)中
修改完畢之後,把臨時檔案重新命名一下、把舊目標檔案刪掉,這個臨時檔案就變成了修改內容後的目標檔案了
import sys
import os
import time
from shutil import copy
def data_preprocess():
file_name, old_str, new_str = sys.argv[1:4]
try:
encoding = sys.argv[4]
except IndexError:
encoding = 'utf-8'
old_str_list = [i.encode(encoding) for i in old_str.split(',')]
new_str_list = [i.encode(encoding) for i in new_str.split(',')]
assert len(old_str_list) == len(new_str_list)
trans_tabs = list(zip(old_str_list, new_str_list))
return file_name, trans_tabs
def backup(file_name):
time_mark = time.strftime('%Y%m%d_%H%M%S')
bak_dir = r'C:\Users\Administrator\Desktop'
basename = os.path.basename(file_name)
os.makedirs(bak_dir) if not os.path.isdir(bak_dir) else True
copy(file_name, os.path.join(bak_dir, basename + '_' + time_mark))
print("備份 %s" %file_name)
def sed(file_name, trans_tabs):
with open(file_name + '.swap', 'wb') as swap_fs, open(file_name, 'rb') as file_names:
for line in file_names:
for tab in trans_tabs:
line = line.replace(tab[0], tab[1]) if tab[0] in line else line
swap_fs.write(line)
os.remove(file_name)
os.rename(file_name + '.swap', file_name)
file_name, trans_tabs = data_preprocess()
backup(file_name)
sed(file_name, trans_tabs)