HTAP for MySQL 在騰訊雲資料庫的演進
摘要:MySQL在充分利用多核計算資源方面比較欠缺,無法同時滿足線上業務和分析型業務的客戶需求,而單獨部署一套專用的分析型資料庫意味著額外的成本和複雜的資料鏈路。本次主題將介紹騰訊雲資料庫為滿足此類場景而在HTAP for MySQL產品方面進行的嘗試。
2023首屆雲資料庫技術沙龍 MySQL x ClickHouse 專場,在杭州市海智中心成功舉辦。本次沙龍由NineData、菜根發展、良倉太炎共創聯合主辦。本次,騰訊TEG資料庫產品部高階技術專家陸洪勇,為大家分享一下《HTAP for MySQL 在騰訊雲資料庫的演進》的一些技術內容。
本文內容根據演講錄音以及PPT整理而成。

陸洪勇,騰訊TEG資料庫產品部高階技術專家,曾在 SAP 做過多年HANA資料庫核心的設計與研發,阿里雲 Polardb 資料庫核心的設計與研發。目前在騰訊雲資料庫做 HTAP for MySQL 相關產品的設計與開發。

今天我來講一下,HTAP for MySQL 在騰訊雲資料庫的演進。主要介紹的內容如下:首先介紹一下產品背景,然後會介紹產品的兩個重要功能,第一個是並行查詢,第二個是列存索引,這也是MySQL能力提升的最重要的兩個方面。

這個產品實際上是我們所提到的公有云,公有云的概念大家都比較熟悉。其中一個產品是 Tencent DB for MySQL,這是一個基於 MySQL 開源的託管產品。類似的產品還有阿里雲的 RDS。這是一個典型的、傳統的 MySQL 主從複製架構,通過 binlog 進行資料複製。每個節點都有自己的紀錄檔和資料。
另一個產品是我們的雲原生資料庫產品 TDSQL-C,它有兩個基本特點:資源池化和極致彈性。在這個產品中,我們使用了分散式共用儲存來儲存資料,而 CPU 和記憶體等資源也將實現相應的池化,後續我們還會陸續推出相應的產品。極致彈效能力在於使用了共用儲存,所以我們每一個唯讀節點,可以很容易的掛載上來。同時,共用儲存也很容易進行擴容和縮容,這是我們產品的基本背景介紹。

首先,我們通過對大量重點客戶在大盤上的分析,發現客戶存在兩大痛點。其中,第一個痛點極其重要,即穩定性問題。第二個痛點是慢查詢,這是一個非常令人頭疼的事情。慢查詢的原因有很多,比如使用者沒有為某些查詢建立索引或者索引未命中。另一個更為普遍的原因是MySQL單核處理能力在資料量較大時的瓶頸。
針對這些問題,業界提出了幾種解決方案。第一種是提高多核處理能力,包括多節點並行查詢和MPP。第二種是提高指令執行效率,其中一種方法是向量化執行,包括SIMD指令,另一種方法是JIT編譯,目前在一些商業資料庫用的還比較多一點。第三種是提高資訊密度,由於行存資料庫中資料之間的相似性較低,因此需要進行一些壓縮或批次處理是比較難的,另一個解決方案是使用列式儲存。
在業界中,部署模式也存在類似的三種。其中一種是中間鍵模式,即在MySQL叢集中構建一箇中介軟體,通過中介軟體進行分散式查詢分析和並行執行,最終的執行片段會下壓到每一個的MySQL節點上去,這樣MySQL能夠把分析型能力能夠解決,其中阿里雲Polardb-X產品就是比較典型的例子。另一種是專有的AP系統,該系統建立在MySQL之外單獨建立一個分析型系統,包括ClickHouse是比較好的一個方案,通過 binlog 或者其他的形式進行紀錄檔同步,相當於提供專用的紀錄檔分析,將正常資料或TP資料通過MySQL,分析的話就通過AP進行處理。我們的產品其實是想在MySQL本身構建並行查詢和AP能力,使使用者能夠無需感知我們的底層操作,不會對業務造成侵入,同時獲得非常大的效能提升。

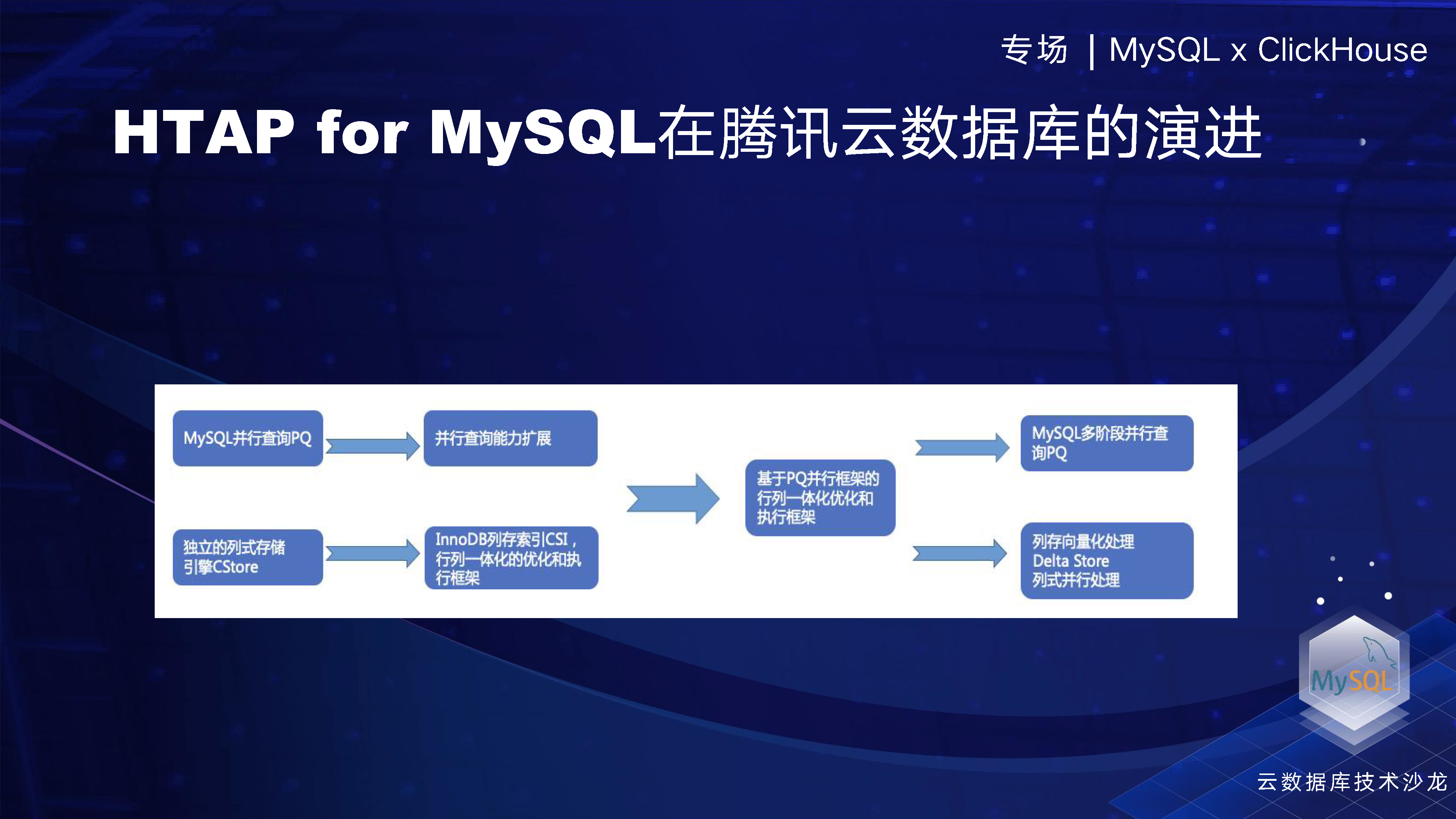
首先,在上面的這個過程中,我們進行了並行查詢的演進,而下面一排是關於列式儲存和引擎的演化。這兩個功能是獨立開發的。然後,在去年的六七月份,我們將這兩個技術融合,使得我們的公有云產品上,MySQL和雲原生產品具有了並行查詢和列存框架。這樣一來,使用者可以享受到極大的執行效率提升。
這個框架的融合之後,我們的兩個團隊可以持續擴充套件各自的能力,所以後面的擴充套件很容易被整合進這個框架裡面。例如,我們在列存做的向量化處理和delta store等,都可以很容易地被吸收到這個執行框架中。只要將這些功能合入到框架中,使用者就可以充分體驗到這些帶來的效能優勢。
在2021年底,我們做了一個列存索引的功能,相當於建立了一個 InnoDB的索引,資料可以通過非同步傳輸同步到列存中,以實現資料及時同步。後面我們會有一個具體框架,可以看下我們是怎麼做的。
首先,我們來介紹一下並行查詢, 我們舉了一個範例,從TPCH中選取了一個簡單的查詢語句進行測試。在MySQL普通執行下,該查詢需要約64秒的時間。而在使用並行查詢後,四個DOP、四個worker只需要16秒的時間。可以看到並行查詢的效率提升是線性的,達到了四倍。這是MySQL原有的執行計劃,我們可以看到每個worker執行緒都有一個sender節點,用於資料傳送。最終資料會在gather層進行彙總。這是一個典型的並行執行計劃。下面是並行查詢的狀態,可以通過 show process 進行檢視。

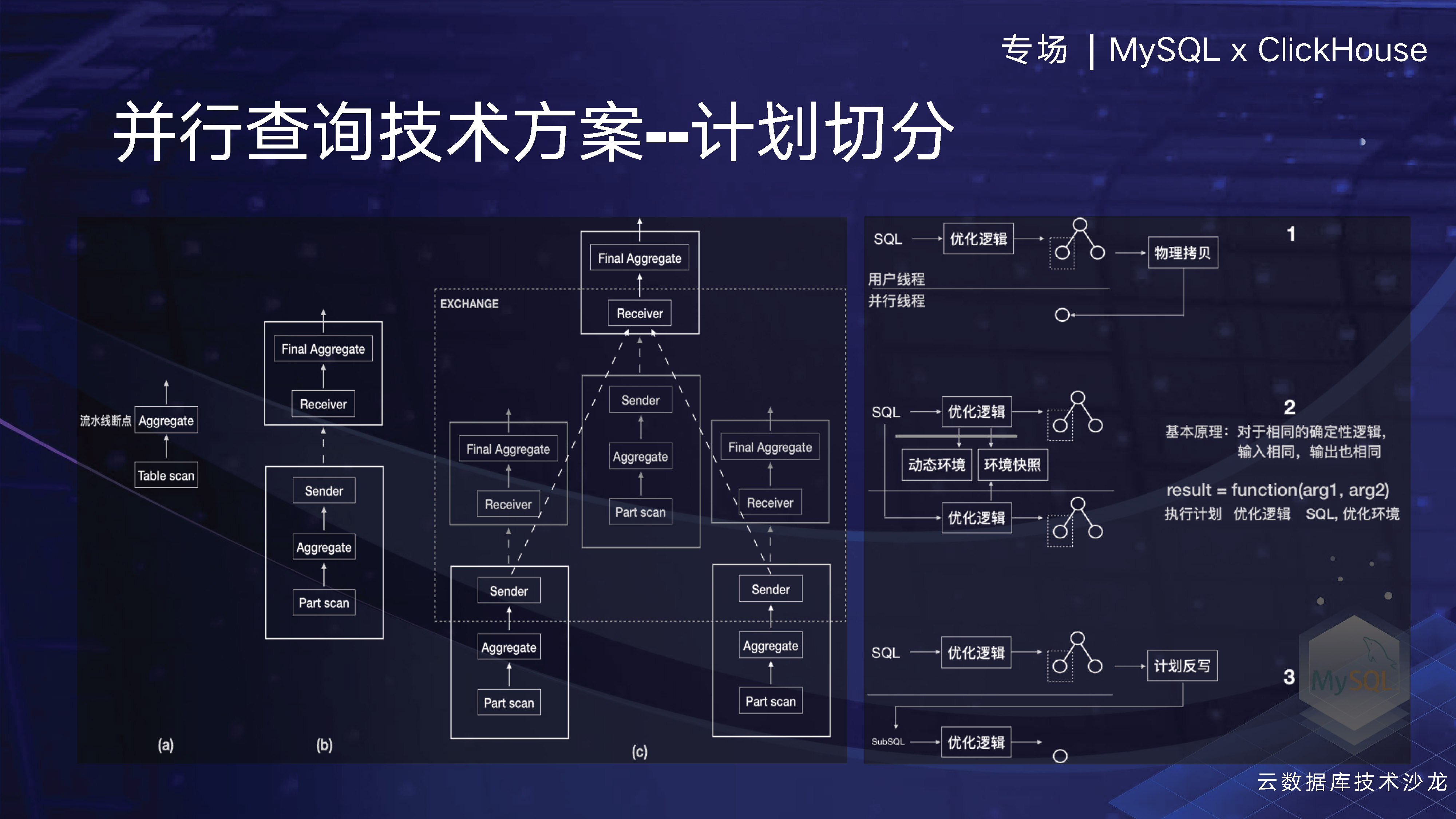
這裡我們介紹一個具體的實現方案。在MySQL中,有一個比較困難的方案需要計劃切分,這是因為在傳統的資料庫中,如我之前從事的HANA資料庫,生成的計劃與資料是分離的,因此plan在傳輸到其他worker執行緒時很容易實現。但是MySQL是比較難的,主要在於傳統開發模式導致了計劃和資料的耦合,使得直接進行plan拷貝非常困難。後面我們簡單介紹下包括業界常用的三種方案。然後我們看一下這樣簡單的一個plan,舉個例子,比如我們table scan上有一個聚合資料的表,經過計劃切分後,我們會在worker執行緒上新增一個並行執行的節點,然後再上層新增一個receiver節點來匯聚結果。如果有更多的worker,切分的數量也會相應增加。
第一個方案是將來自SQL的邏輯計劃和物理計劃依次生成,然後將物理計劃拷貝到並行worker現場上。這需要對每一個MySQL執行計劃裡面涉及的資料結構全部做克隆操作,且工作量巨大,據我們瞭解,當前公有云上TOP廠商中,至少有兩家採用了這種方案。不過這種方案存在一些問題,其中廠商投入了大量人力和物力,而另外對MySQL的程式碼進行了大量的入侵。在後期,你很難跟上社群的,因為社群在不斷做程式碼重構。
第二種方案實際上是一種更常見的商業資料庫方案。當SQL語句到達時,它將生成一個邏輯計劃,並通過拷貝一些環境資料到worker執行緒,從而生成一個執行計劃。這是一個很自然而然的操作。我們目前採用了這種方案,並通過它實現了比其他友商更好的效果,而且只用了他們1/4的人力和時間。這並不是吹牛,如果有機會大家可以試一試。我們之所以能夠採用這種方案,而其他友商採用了其他的方案,一方面是因為我們從社群中獲得了一些經驗和技術紅利,另一方面是因為我們參與了社群的構建。社群在不斷重構SQL構層,將邏輯計劃和物理計劃分離,通過 iterator機制拆分得更清晰,這為我們提供了基礎,使我們能夠完成這項工作。
第三種方案使用較少。當SQL生成邏輯計劃並生成執行計劃時,對於需要執行不同的物理計劃片段,該方案通過反向編寫成SQL語句的方式來實現。然後,將SQL語句傳送到不同的worker執行緒上,這些執行緒可能是ClickHouse。由於ClickHouse無法直接執行MySQL執行計劃,因此將SQL語句傳送過去,就能夠執行了。我們之前也曾經嘗試過使用反寫SQL的方式,但是與第一個方案相比,工作量並不見得小,因為基本上必須要把整個執行計劃反向一遍。因此,我們採用第二種方案實現了非常好的效果。
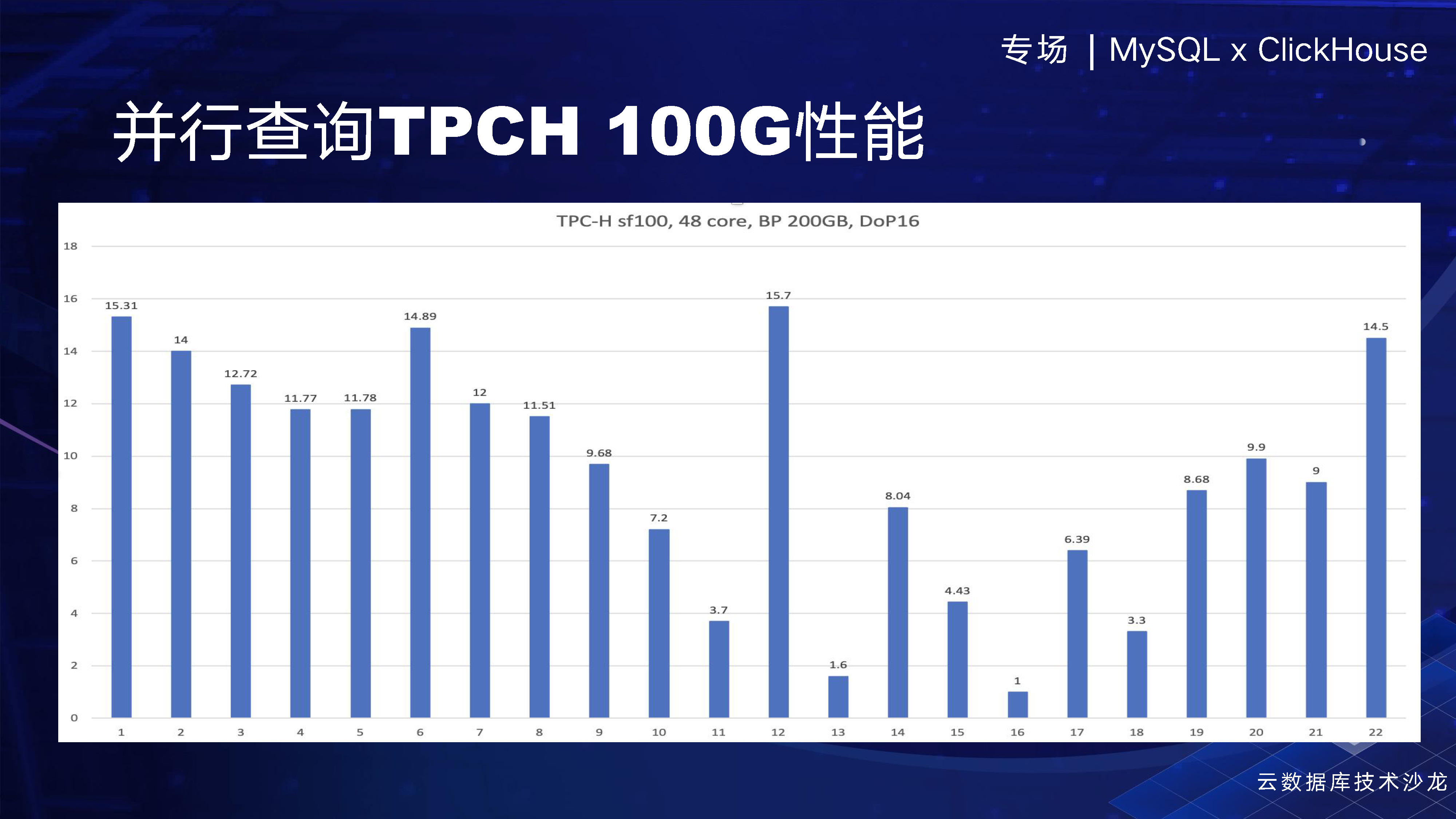
我們可以看一下,在TPCH 100G上的效能表現。在DoP為16的情況下,我們基本上有十倍以上的效能提升。我們還有一些能力暫時不支援,因此沒有進一步提升。但是,基本上能夠達到線性提升,因為現在是16DoP,我們有大約十倍的效能提升,這樣的效果非常明顯。
經過我們的並行查詢的介紹後,我們想簡要提一下我們投入最大的產品——列存索引,我們期望這個產品未來能夠為使用者帶來更好的效果和使用體驗。在列存索引的友商市場上,我們進行了分析比較了Oracle、SQL Server、 TiFlash、MySQL HeatWave等多款產品,綜合各家之長,並結合我們自身技術,我們成功設計了列層索引架構。

列層索引架構,相當於這是一個RW節點,這是一個唯讀節點,在唯讀節點上為每張表建立了一個列存的索引,但是我們知道 InnoDB 一個索引最多隻支援16個列。相比之下,我們的索引擴充套件性非常強,支援最多256列。我們也意識到,在分析型資料處理過程中,大寬表是常態,因此在未來可能需要支援更多的列。
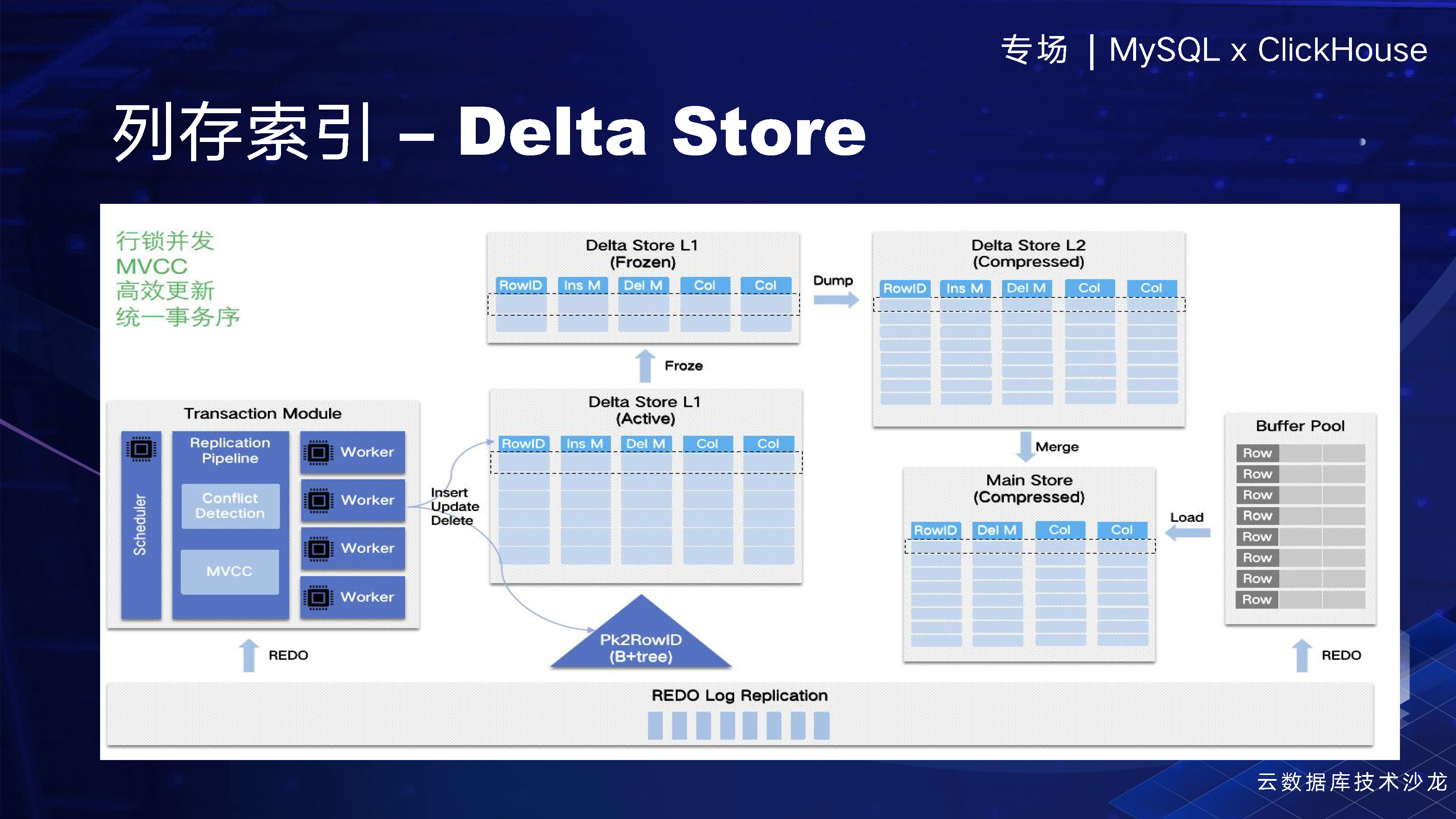
當資料插入時,我們會通過一個redo log以物理複製的方式將資料同步(同步和非同步均可)到列存索引中。然後,我們通過Delta Store進行並行的回放,實現高效的資料插入。
在這個框架中,我們有一個OLAP執行器,這個就是MySQL自身的執行器,但是我們使用的是統一的優化器,可以排程執行計劃,使得哪一部分在列存執行,哪一部分在行存執行。由於列存索引不斷演進,其功能可能會不斷擴充套件,因此當整個的plan過來的時候,不能完全在我們的列存執行,那我們就有一些需要在行存執行,所以當前我們需要混合的執行框架,以實現更好的效果。
在計算過程中,我們也會用到平行計算,剛剛提到的平行計算是MySQL本身,那我們在列存內部的話,我們也在構建這樣的一個能力。在未來,我期望能夠通過們的優化器對查詢語句進行整體優化,在我們這裡執行整個分析過程,以提高效率和準確性。此外,我們還將引入AVX512向量化執行,進一步提高效能。

這是簡單過一下語句例子,比如說這是一個 Nested Loop Join,假如現在只有這個第一條語句table scan和filter能到列層裡面去執行,那我們這個執行框架是怎麼做的呢?首先一條語句來了之後,它會通過這個優化器會生成混合的一個執行計劃。執行計劃就會把這個精細化,放到這個執行排程裡邊去。然後會把其中涉及到列存執行的plan,通過這個下壓介面層下壓到Cstore的執行器,執行器裡面我們會並行執行,也會進行一些原資料。例如索引資料和粗糙索引,以過濾掉一些巨量資料塊,從而提升效率。此外,我們還有SIMD 的指令的執行,最終會把結果返回到行存,從而會得到最終的結果。從這裡我們可以看出,我們是一個混合的執行框架。

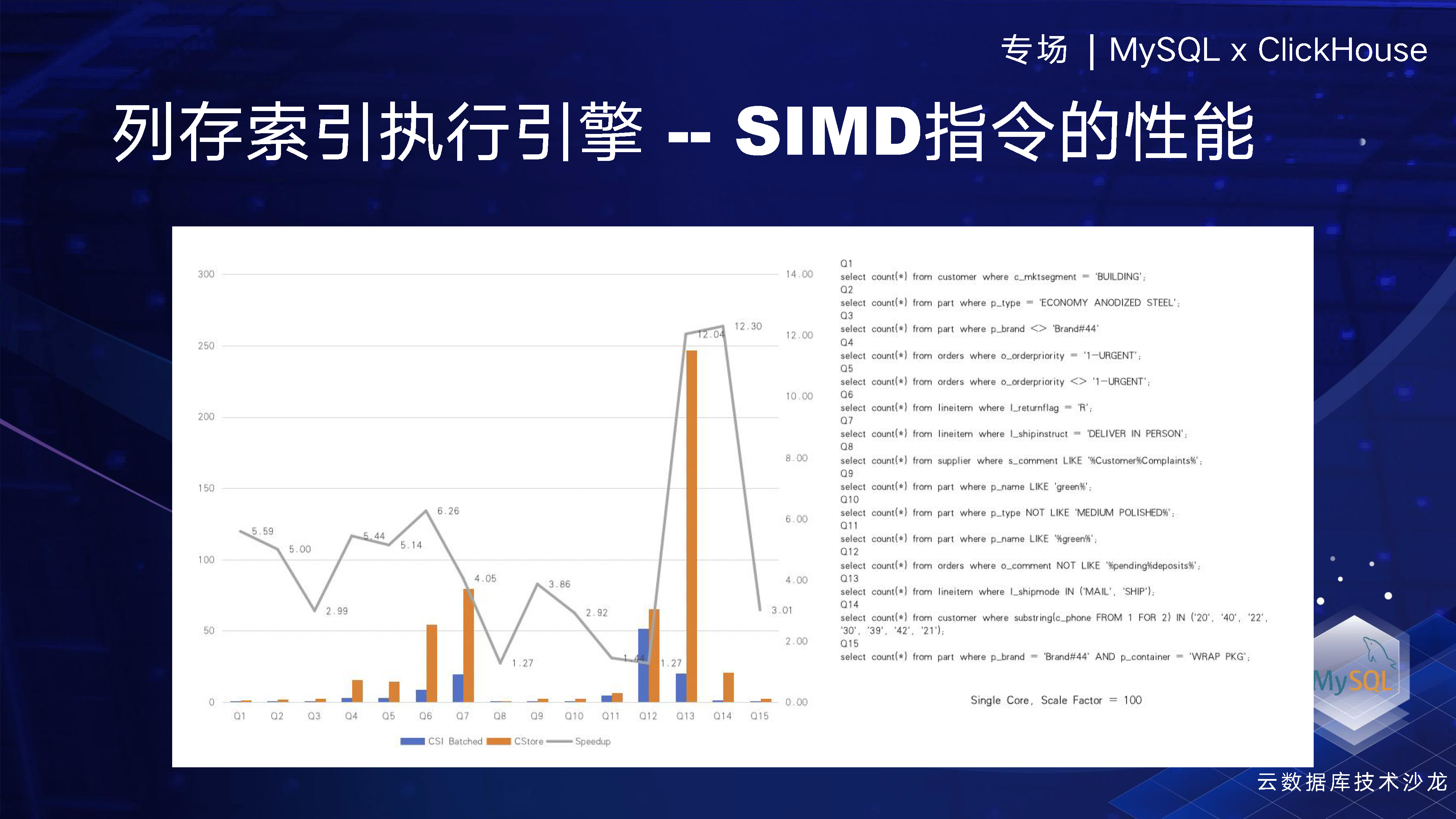
在我們的執行引擎框架中,我們使用了SIMD指令,即單指令多資料,這是引擎中一個非常重要的部分。我們有兩張圖,第一張圖顯示了我們採用了SIMD指令和沒有采用SIMD指令但採用了批次處理 (即一次處理4096行資料)的效能比較。我們從TPCH中抽取了一部分資料,大概可以看到我們提升了 5 倍左右的效能,這說明SIMD指令的效果非常明顯。SIMD使用的是英特爾自己的指令集,例如對於一個INT8型別的計算,如果使用普通的指令,一條指令只能執行 INT8 加 INT8。但是如果使用英特爾512的AVX512指令,一條指令就可以計算64行資料,因此效率提升是非常高的。
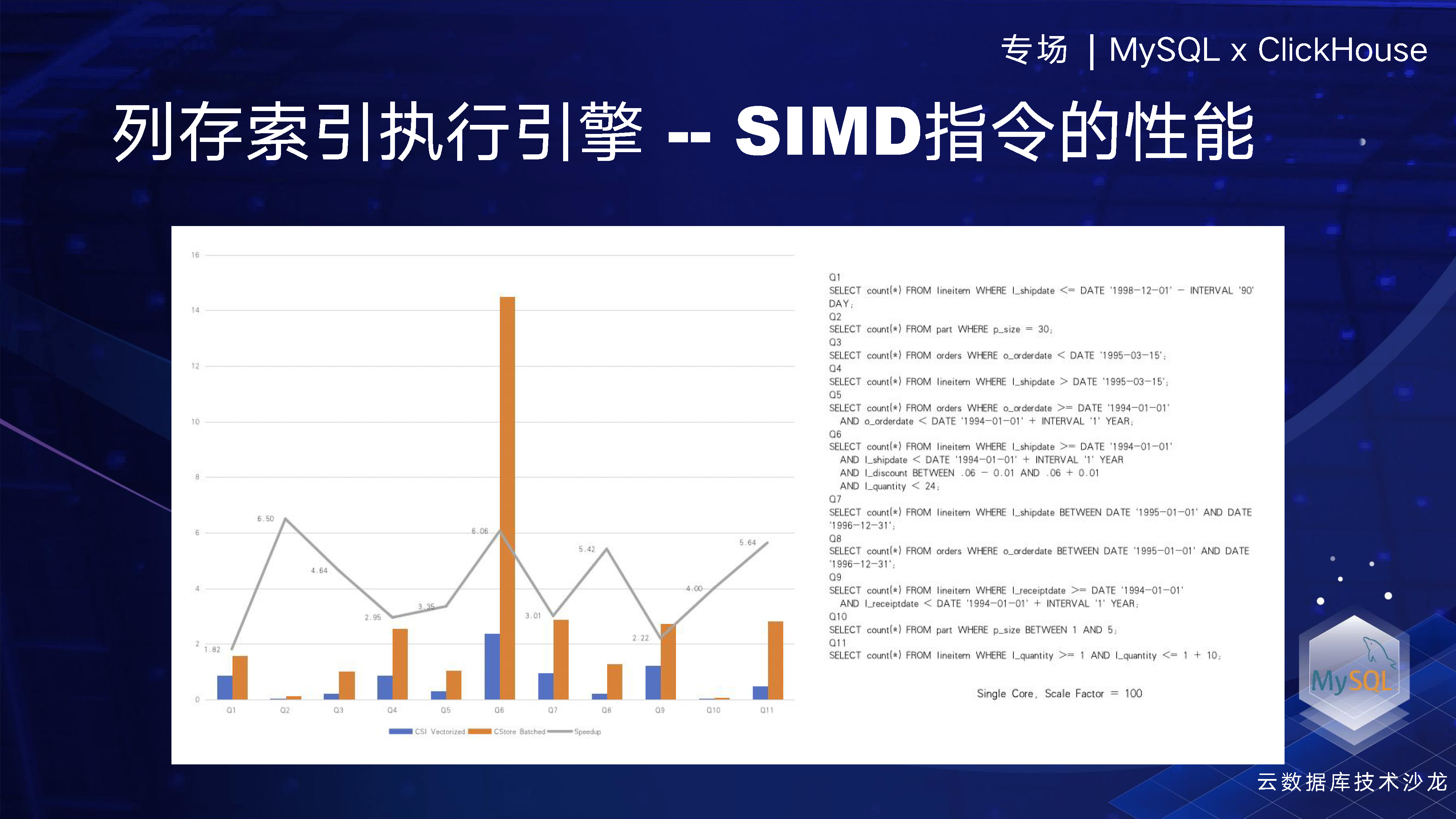
另外一點,就是我們不採用SIMD的指令,採用了批次處理方式一次處理4096行資料,另一種對比方式就是一行一行的執行,我們發現採用批次處理方式可以使效能提升約五倍左右。兩者再結合的話,效能提升將更為明顯,預計至少可以提升25倍以上。上面的測試,我們在TPCH 100G的測試場景下進行。
接下來,看下通過結合列存索引和並行查詢的plan情況,這是TPCH Q3一個語句。在這個計劃中上面是一個聚合層(協調者),底下是有多個 worker 執行緒。最底下是列存執行的一個計劃,而上面則是行存執行的計劃。這個計劃非常好地體現了我們將行列儲存的優點相結合,並加入了並行查詢的能力。這樣做的結果就是我們具備了整合多方優點的能力。

我們在列存中有一個非常重要的一點,那就是Delta Store。為什麼我們需要Delta Store呢?當你進行一個並行回放的時候,資料是通過REDO Log同步到列存中的。而Delta Store能夠提供高效的資料插入,因為它可以在記憶體中不斷地open only將資料往後插入。這樣做的好處是,它能夠提高行級並行,同時我們還有一個insert / delete mask,這使得我們在列存中具備了MVCC的能力。結合我們在MySQL上的SCN機制,我們就能夠提供完整的事務檢視,從而實現完整性的事務查詢。當資料插滿後,我們會將其凍結並把它download到磁碟上去進行壓縮,當一些資料會永久的被被刪掉了,或者說這個資料永遠所有人都能看到了,我們會進行一些空洞的compaction。然後再 merge到 main store裡面去,其實有點像 LSMtree 的架構。
現在我再講一下,我們這個產品中並行查詢部分已經上線了,在公有云上已經可以使用。而列存索引這部分目前正在內部灰度和一些大客戶的試用中,取得了非常好的效果。儘管還沒有正式推出,但我們在PQ查詢的基礎上,我們又有至少三倍以上的效能提升,這是在還沒有完全加入向量化的情況下。而如果在向量化加持之後,我們期望會有更大的效能提升。

目前這個階段的話,我們正在做一些工作,例如並行查詢在MySQL這一部分,我們可能會做MPP。列存的話,我們有可能會開發自己的MPP,以及包括支援大型的儲存。最後,我想重點談談我們的統一核心的技術空間,因為我們知道,公有云和私有云是不同的技術架構。公有云使用共用儲存,而私有云使用分散式儲存。但是我們已經將並行查詢擴充套件到了私有云上,這意味著我們公有云和私有云都使用了同一個並行框架。接下來,我們會將列存能力擴充套件到私有云上。這意味著我們一套能力可以在兩個系統上完全複用。目前來看,我們可能是友商中第一個實現這種統一核心的機制。

今天我的分享就到這兒,謝謝。
本次大會圍繞「技術進化,讓資料更智慧」為主題,匯聚位元組跳動、阿里雲、玖章算術、華為雲、騰訊雲、百度的6位資料庫領域專家,深入 MySQL x ClickHouse 的實踐經驗和技術趨勢,結合企業級的真實場景落地案例,與廣大技術愛好者一起交流分享。