知乎問題:如何說服技術老大用 Redis ?

這個問題很微妙,可能這位同學內心深處,覺得 Redis 是所有應用快取的標配。
快取的世界很廣闊,對於應用系統來講,我們經常將快取劃分為本地快取和分散式快取。
本地快取 :應用中的快取元件,快取元件和應用在同一程序中,快取的讀寫非常快,沒有網路開銷。但各應用或叢集的各節點都需要維護自己的單獨快取,無法共用快取。
分散式快取:和應用分離的快取元件或服務,與本地應用隔離,多個應用可直接共用快取。
1 快取的本質
我們常常會講:「加了快取,我們的系統就會更快」 。
所謂的「更快」,本質上做到了如下兩點:
-
減小 CPU 消耗
將原來需要實時計算的內容提前算好、把一些公用的資料進行復用,這可以減少 CPU 消耗,從而提升響應效能。
-
減小 I/O 消耗
將原來對網路、磁碟等較慢媒介的讀寫存取變為對記憶體等較快媒介的存取,從而提升響應效能。
假如可以通過增強 CPU、I/O 本身的效能來滿足需求的話,升級硬體往往是更好的解決方案,即使需要一些額外的投入成本,也通常要優於引入快取後可能帶來的風險。
從開發角度來說,引入快取會提高系統複雜度,因為你要考慮快取的失效、更新、一致性等問題。
從運維角度來說,快取會掩蓋掉一些缺陷,讓問題在更久的時間以後,出現在距離發生現場更遠的位置上。
從安全形度來說,快取可能洩漏某些保密資料,也是容易受到攻擊的薄弱點。
因此,快取是把雙刃劍。
2 本地快取 JDK Map
JDK Map 經常用於快取實現:
-
HashMap
HashMap 是一種基於雜湊表的集合類,它提供了快速的插入、查詢和刪除操作。可以將鍵值對作為快取項的儲存方式,將鍵作為快取項的唯一識別符號,值作為快取項的內容。
-
ConcurrentHashMap
ConcurrentHashMap 是執行緒安全的 HashMap,它在多執行緒環境下可以保證高效的並行讀寫操作。
-
LinkedHashMap
LinkedHashMap 是一種有序的 HashMap ,它保留了元素插入的順序,可以按照插入順序或者存取順序進行遍歷。
-
TreeMap
TreeMap 是一種基於紅黑樹的有序 Map,它可以按照鍵的順序進行遍歷。
筆者曾經負責藝龍紅包系統,紅包活動就是儲存在 ConcurrentHashMap 中 ,通過定時任務重新整理快取 。
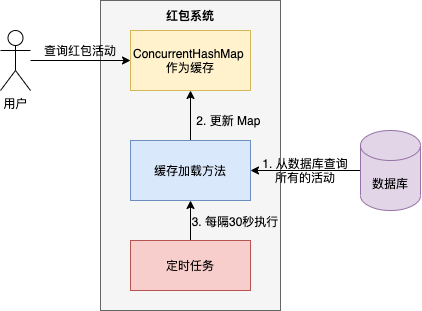
核心流程:
1、紅包系統啟動後,初始化一個 ConcurrentHashMap 作為紅包活動快取 ;
2、資料庫查詢所有的紅包活動 , 並將活動資訊儲存在 Map 中 ;
3、定時任務每隔 30 秒 ,執行快取載入方法,重新整理快取。
為什麼紅包系統會將紅包活動資訊儲存在本地記憶體 ConcurrentHashMap 呢 ?
-
紅包系統是高並行應用,快速將請求結果響應給前端,大大提升使用者體驗;
-
紅包活動數量並不多,就算全部放入到 Map 裡也不會產生記憶體溢位的問題;
-
定時任務重新整理快取並不會影響紅包系統的業務。
筆者見過很多單體應用都使用這種方案,該方案的特點是簡潔易用,工程實現也容易 。
3 本地快取框架
雖然使用 JDK Map 能快捷構建快取,但快取的功能還是比較孱弱的。
因為現實場景裡,我們可能需要給快取新增快取統計、過期失效、淘汰策略等功能。
於是,本地快取框架應運而生。
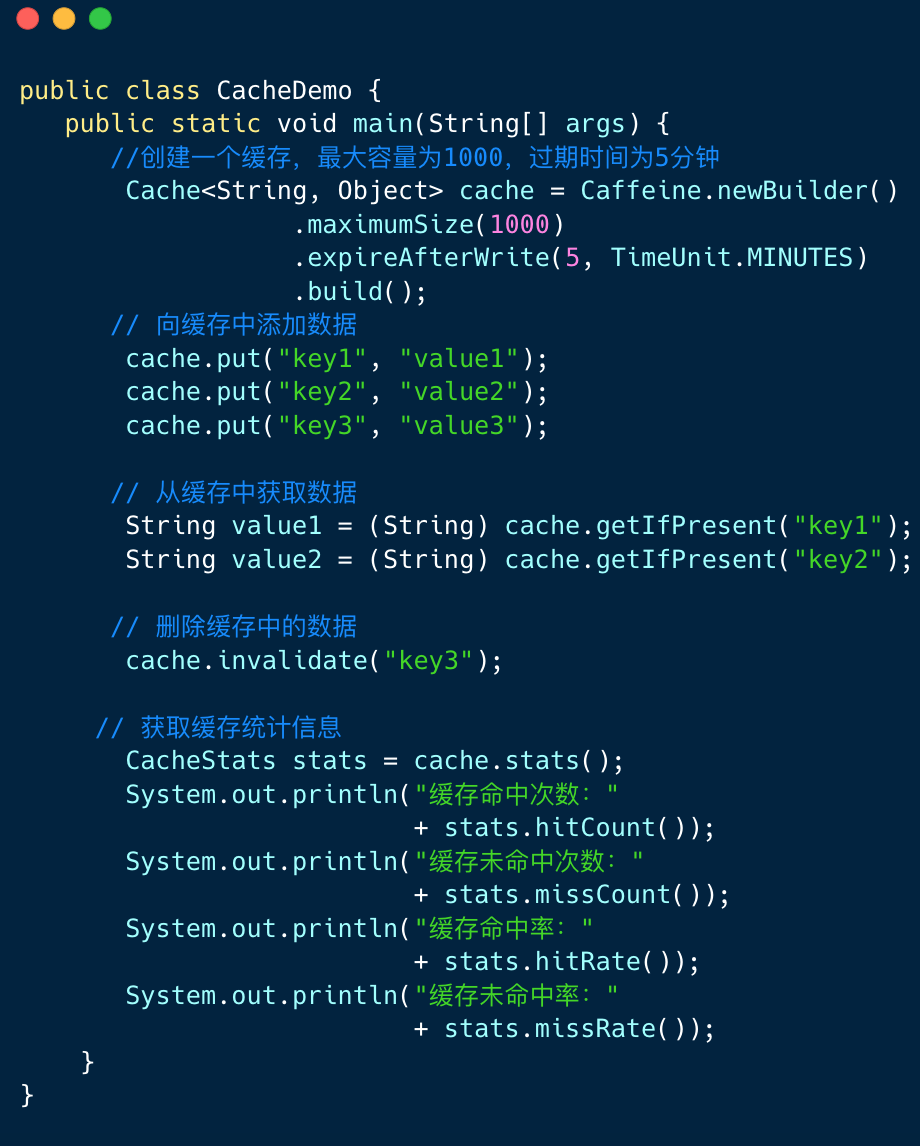
流行的 Java 快取框架包括: Ehcache , Google Guava , Caffine Cache 。

下圖展示了 Caffine 框架的使用範例。
雖然本地快取框架的功能很強大,但是本地快取的缺陷依然明顯。
1、高並行的場景,應用重啟之後,本地快取就失效了,系統的負載就比較大,需要花較長的時間才能恢復;
2、每個應用節點都會維護自己的單獨快取,快取同步比較頭疼。
4 分散式快取
分散式快取是指將快取資料分佈在多臺機器上,以提高快取容量和並行讀寫能力的快取系統。分散式快取通常由多臺機器組成一個叢集,每臺機器上都執行著相同的快取服務程序,快取資料被均勻地分佈在叢集中的各個節點上。
Redis 是分散式快取的首選,甚至我們一提到快取,很多後端工程師首先想到的就它。
下圖是神州專車訂單的 Redis 叢集架構 。將 Redis 叢集拆分成四個分片,每個分片包含一主一從,主從可以切換。 應用 A 根據不同的快取 key 存取不同的分片。

與本地快取相比,分散式快取具有以下優點:
1、容量和效能可延伸
通過增加叢集中的機器數量,可以擴充套件快取的容量和並行讀寫能力。同時,快取資料對於應用來講都是共用的。
2、高可用性
由於資料被分佈在多臺機器上,即使其中一臺機器故障,快取服務也能繼續提供服務。
但是分散式快取的缺點同樣不容忽視。
1、網路延遲
分散式快取通常需要通過網路通訊來進行資料讀寫,可能會出現網路延遲等問題,相對於本地快取而言,響應時間更長。
2、複雜性
分散式快取需要考慮序列化、資料分片、快取大小等問題,相對於本地快取而言更加複雜。
筆者曾經也認為無腦上快取 ,系統就一定更快,但直到一次事故,對於分散式快取的觀念才徹底改變。
2014年,同事開發了比分直播的系統,所有的請求都是從分散式快取 Memcached 中獲取後直接響應。常規情況下,從快取中查詢資料非常快,但線上使用者稍微多一點,整個系統就會特別卡。
通過 jstat 命令發現 GC 頻率極高,幾次請求就將新生代佔滿了,而且 CPU 的消耗都在 GC 執行緒上。初步判斷是快取值過大導致的,果不其然,快取大小在 300k 到 500k 左右。
解決過程還比較波折,分為兩個步驟:
- 修改新生代大小,從原來的 2G 修改成 4G,並精簡快取資料大小 (從平均 300k 左右降為 80k 左右);
- 把快取拆成兩個部分,第一部分是全量資料,第二部分是增量資料(資料量很小)。頁面第一次請求拉取全量資料,當比分有變化的時候,通過 websocket 推播增量資料。
經過這次優化,筆者理解到:快取雖然可以提升整體速度,但是在高並行場景下,快取物件大小依然是需要關注的點,稍不留神就會產生事故。另外我們也需要合理地控制讀取策略,最大程度減少 GC 的頻率 , 從而提升整體效能。
5 多級快取
開源中國網站最開始完全是用本地快取框架 Ehcache 。
後來隨著存取量的激增,出現了一個可怕的問題:「因為 Java 程式更新很頻繁,每次更新的時候都要重啟。一旦重啟後,整個 Ehcache 快取裡的資料都被清掉。重啟後若大量存取進來的話,開源中國的資料庫基本上很快就會崩掉」。
於是,開源中國開發了多級快取框架 J2Cache,使用了多級快取 Ehcache + Redis 。
多級快取有如下優勢:
- 離使用者越近,速度越快;
- 減少分散式快取查詢頻率,降低序列化和反序列化的 CPU 消耗;
- 大幅度減少網路 IO 以及頻寬消耗。
本地快取做為一級快取,分散式快取做為二級快取,首先從一級快取中查詢,若能查詢到資料則直接返回,否則從二級快取中查詢,若二級快取中可以查詢到資料,則回填到一級快取中,並返回資料。若二級快取也查詢不到,則從資料來源中查詢,將結果分別回填到一級快取,二級快取中。

2018年,筆者服務的一家電商公司需要進行 app 首頁介面的效能優化。筆者花了大概兩天的時間完成了整個方案,採取的是兩級快取模式,同時利用了 Guava 的惰性載入機制,整體架構如下圖所示:
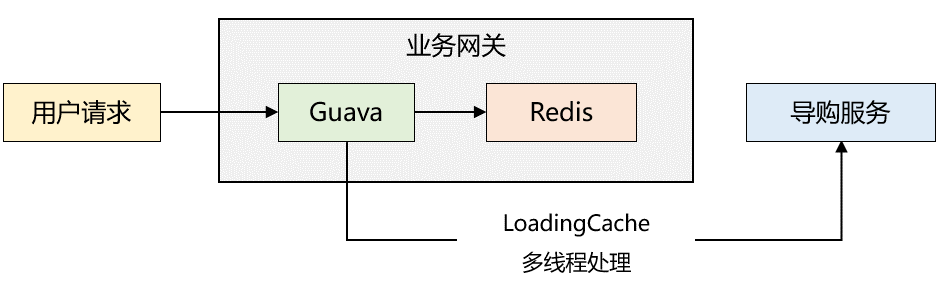
快取讀取流程如下:
1、業務閘道器剛啟動時,本地快取沒有資料,讀取 Redis 快取,如果 Redis 快取也沒資料,則通過 RPC 呼叫導購服務讀取資料,然後再將資料寫入本地快取和 Redis 中;若 Redis 快取不為空,則將快取資料寫入本地快取中。
2、由於步驟1已經對本地快取預熱,後續請求直接讀取本地快取,返回給使用者端。
3、Guava 設定了 refresh 機制,每隔一段時間會呼叫自定義 LoadingCache 執行緒池(5個最大執行緒,5個核心執行緒)去導購服務同步資料到本地快取和 Redis 中。
優化後,效能表現很好,平均耗時在 5ms 左右。最開始我以為出現問題的機率很小,可是有一天晚上,突然發現 app 端首頁顯示的資料時而相同,時而不同。
也就是說: 雖然 LoadingCache 執行緒一直在呼叫介面更新快取資訊,但是各個 伺服器本地快取中的資料並非完成一致。 說明了兩個很重要的點:
1、惰性載入仍然可能造成多臺機器的資料不一致
2、LoadingCache 執行緒池數量設定的不太合理, 導致了執行緒堆積
最終,我們的解決方案是:
1、惰性載入結合訊息機制來更新快取資料,也就是:當導購服務的設定發生變化時,通知業務閘道器重新拉取資料,更新快取。
2、適當調大 LoadigCache 的執行緒池引數,併線上程池埋點,監控執行緒池的使用情況,當執行緒繁忙時能發出告警,然後動態修改執行緒池引數。
6 沒有銀彈
沒有銀彈是 Fred Brooks 在 1987 年所發表的一篇關於軟體工程的經典論文。
論文強調真正的銀彈並不存在,而所謂的銀彈則是指沒有任何一項技術或方法可以能讓軟體工程的生產力在十年內提高十倍。
通俗來講:在技術領域中沒有一種通用的解決方案可以解決所有問題。
技術本質上是為了解決問題而存在的,每個問題都有其獨特的環境和限制條件,沒有一種通用的技術或工具可以完美地解決所有問題。
雖然技術不斷髮展和進步,但是對於複雜的問題,仍需要結合多種技術和方法,進行系統性的思考和綜合性的解決方案設計,才能得到最優解決方案。
回到文章開頭的問題 ,如何說服技術老大用 Redis ?
假如應用就是一個單體應用,快取可以不共用,通過定時任務重新整理快取對業務沒有影響,而且本地記憶體可以 Hold 住快取的物件大小,那麼你的技術老大的方案沒有問題。
假如應用業務比較複雜,需要使用快取提升系統的效能,同時分散式快取共用的特性對於研發來講開發更加快捷,Redis 確實是個不錯的選擇,可以從研發成本、程式碼維護、人力模型等多個角度和技術老大提出自己的觀點。
總而言之,在技術領域中,沒有銀彈。我們需要不斷探索和研究新的技術,但同時也需要認識到技術的侷限性,不盲目追求所謂的「銀彈」,而是結合具體問題和需求,選擇最適合的解決方案。
如果我的文章對你有所幫助,還請幫忙點贊、在看、轉發一下,你的支援會激勵我輸出更高質量的文章,非常感謝!
