【筆記】跟吳恩達和IsaFulford學提示詞工程(初級開發者入門課程)
- 標籤: #Prompt #LLM
- 建立時間:2023-04-28 17:05:45
- 連結:課程(含JupyterNotebook) ,中文版
- 講師:Andrew Ng,Isa Fulford

閱讀提示
這是一篇入門的教學,入門的意思是指大部分內容,可能你都已經知道了,但是知道不等於掌握,Prompt是一門實踐經驗主義科學,LLM是個黑盒,你只要不斷去「實踐」才能爛熟於心,所以這篇筆電身建議僅作為一個「提示」,幫你回顧知識點。你需要點開課程(含JupyterNotebook),然後在裡面一行一行地閱讀程式碼、執行程式碼、修改程式碼,才能更好地掌握。
筆記
01 Introduction 介紹
- LLM分成兩個基本大類:base-LLM和Instruction-Tuned-LLM,前者稱為基礎語言模型,始終基於預訓練資料預測下一個單詞,後者又稱為指令式語言模型,它針對指令進行了微調,使它更可能完成人類的指令。像「翻譯」就是一種常見指令。OpenAI的模型中,InstructGPT models列出了它們針對指令優化的模型,表格中也列出了不同的指令微調訓練方法,如SFT、FeedME、PPO。
02 Guidelines 準則
- 寫指令要求清晰和具體,但不等於短。
- 用定界符如"""、```、---、<>、
。它可以防止prompt注入,給LLM產生混亂的理解。 - 用結構化輸出:如直接要求它以HTML或者JSON格式輸出。
- 要求檢查:要求LLM先檢查是否滿足某個條件後,再進行輸出,如果條件不滿足可以直接告知。
- 利用少樣本學習,展示一個你期望的例子給LLM。
- 用定界符如"""、```、---、<>、
- 給模型一些思考的時間,你給它太簡單的描述它回答的可能不是你要的,你給它太難的問題它可能也算不出來。
- 讓模型按步驟來解答,第一步你應該怎麼答,第二步你應該……最後……。可以設定一些分隔符,並且你在展示你想要的格式的時候,使用這些分隔符,比如你告訴LLM,文字在Text:<>裡面……
- 讓模型自己推匯出過程,而不僅僅是結果,展示一個帶有解題過程的例子給LLM,演示中,讓LLM負責判斷學生做題是否正確,這時候就需要告訴模型學生的解題思路。
避免模型產生幻覺:要告訴模型先查詢相關資料,再根據相關資料來回答問題。(但模型產生幻覺很難避免,也是目前模型研究領域努力的方向)
03 Iterative 提示工程需要持續迭代(編寫Prompt就是一個不斷修正表達的過程)
編寫Prompt的過程是不斷迭代的。
基本步驟:編寫Prompt、測試、分析為什麼、再編寫(澄清你的想法)、再測試……,直到滿意為止。
範例中,測試了總結行銷文案、用50個單詞、3個句子、280個字元、增加目標使用者、增加產品引數、增加輸出格式要求、來表達等,LLM表現得都不錯,不過值得注意的是,它們並不會嚴格按照這個字數限制來,可能會略長一點。
04 Summarizing 總結類的應用(總結、提取資訊)
如果你有個電商網站,裡面有大量的使用者評論,你可以利用「總結」的能力來簡化你的工作量。
LLM不僅支援「總結(summarize)」還可以「提取資訊(extract)」。
範例中,測試了限制字數、限定主題、關注價格、用提取替換總結,並用一個for迴圈,以相同的prompt模板來套用不同的內容,以達到批次處理的目的。
05 Inferring 推理類應用(情緒判斷、主題推斷等)
同樣是在使用者評論中,你如果想看看有多少積極反饋有多少消極反饋,則需要用到「LLM推理」的能力。
範例中,LLM可以推理使用者的情緒(sentiment)、識別情緒型別(如:happy, satisfied, grateful, impressed, content)、提取品牌和商品資訊並按JSON格式輸出、一次執行多個任務(提取使用者評論的商品並推理使用者的情緒) 、推斷主題、基於推斷的主題設計一個提醒程式等。
06 Transforming 轉換類應用(翻譯、格式轉換、糾錯等)
將一種語言轉換為另一種語言這類應用可以叫做轉換類應用。
範例中,翻譯一段文字到另一種語言、識別一段文字是哪種語言、同時翻譯成兩種以上的語言、指定正式還是非正式的語氣、指定語言使用的場合比如商務場合的郵件、除了自然語言翻譯還可以是json到html這樣程式語言的翻譯、要求LLM幫你糾正語法錯誤。
收穫一個可以標記文字差異的Python程式碼:
from IPython.display import display, Markdown, Latex, HTML, JSON
from redlines import Redlines
diff = Redlines(text,response)
display(Markdown(diff.output_markdown))
07 Expanding 擴充套件類應用(拓寫)
LLM擅長於將一個簡短的文字寫得更長,並補充一些修飾,融入一些特定的語言風格。
範例中,LLM表現為一個郵件回覆助理的角色。讓LLM寫一段回覆客戶的郵件、要求它使用客戶來信中的詳細資訊(讓客戶感覺比較真實)、可以調整溫度值來讓回覆不那麼死板。
請不要將其用於垃圾郵件編寫等不負責任的任務。
08 Chatbot 聊天機器人
給OpenAI API傳送的訊息,role包含system、user和 assistant三種角色。system設定的是全域性的風格、限制等資訊,user表示人類,assistant表示LLM。
def get_completion(prompt, model="gpt-3.5-turbo"):
messages = [{"role": "user", "content": prompt}]
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=0, # this is the degree of randomness of the model's output
)
return response.choices[0].message["content"]
def get_completion_from_messages(messages, model="gpt-3.5-turbo", temperature=0):
response = openai.ChatCompletion.create(
model=model,
messages=messages,
temperature=temperature, # this is the degree of randomness of the model's output
)
# print(str(response.choices[0].message))
return response.choices[0].message["content"]
messages = [
{'role':'system', 'content':'You are an assistant that speaks like Shakespeare.'},
{'role':'user', 'content':'tell me a joke'},
{'role':'assistant', 'content':'Why did the chicken cross the road'},
{'role':'user', 'content':'I don\'t know'} ]
response = get_completion_from_messages(messages, temperature=1)
print(response)
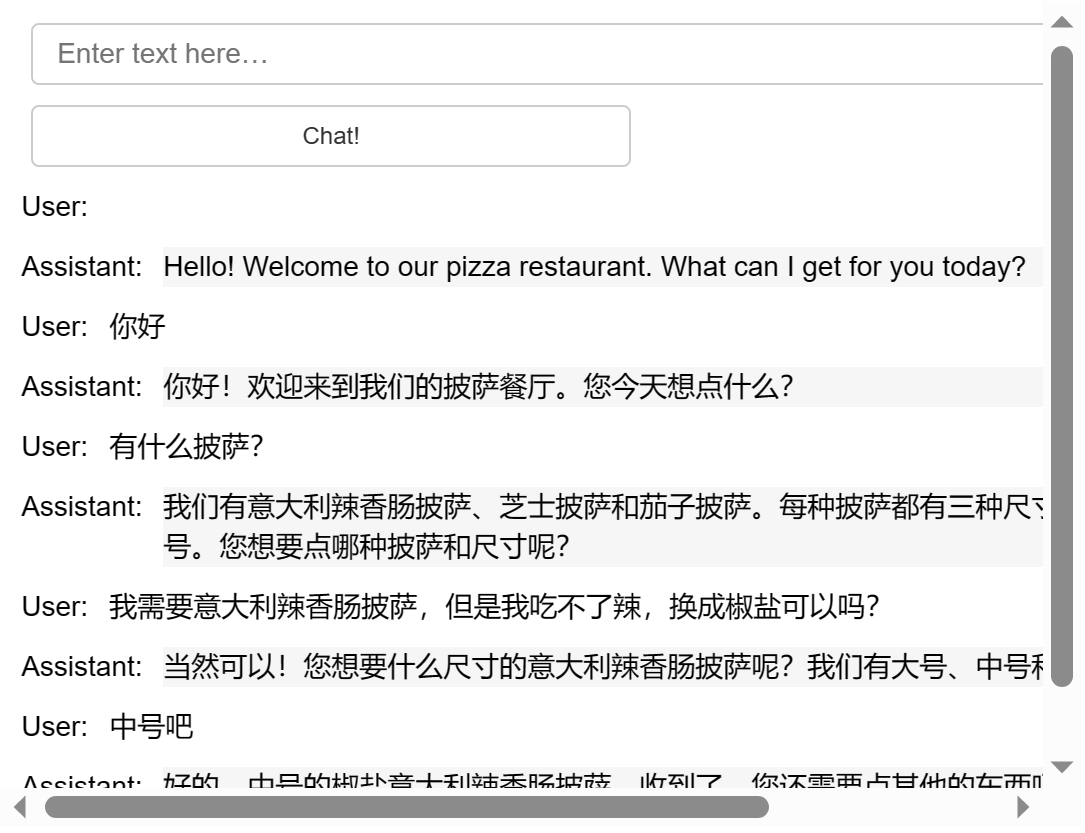
範例展示了一個可互動的GUI:
def collect_messages(_):
prompt = inp.value_input
inp.value = ''
context.append({'role':'user', 'content':f"{prompt}"})
response = get_completion_from_messages(context)
context.append({'role':'assistant', 'content':f"{response}"})
panels.append(
pn.Row('User:', pn.pane.Markdown(prompt, width=600)))
panels.append(
pn.Row('Assistant:', pn.pane.Markdown(response, width=600, style={'background-color': '#F6F6F6'})))
return pn.Column(*panels)
import panel as pn # GUI
pn.extension()
panels = [] # collect display
context = [ {'role':'system', 'content':"""
You are OrderBot, an automated service to collect orders for a pizza restaurant. \
You first greet the customer, then collects the order, \
and then asks if it's a pickup or delivery. \
You wait to collect the entire order, then summarize it and check for a final \
time if the customer wants to add anything else. \
If it's a delivery, you ask for an address. \
Finally you collect the payment.\
Make sure to clarify all options, extras and sizes to uniquely \
identify the item from the menu.\
You respond in a short, very conversational friendly style. \
The menu includes \
pepperoni pizza 12.95, 10.00, 7.00 \
cheese pizza 10.95, 9.25, 6.50 \
eggplant pizza 11.95, 9.75, 6.75 \
fries 4.50, 3.50 \
greek salad 7.25 \
Toppings: \
extra cheese 2.00, \
mushrooms 1.50 \
sausage 3.00 \
canadian bacon 3.50 \
AI sauce 1.50 \
peppers 1.00 \
Drinks: \
coke 3.00, 2.00, 1.00 \
sprite 3.00, 2.00, 1.00 \
bottled water 5.00 \
"""} ] # accumulate messages
inp = pn.widgets.TextInput(value="Hi", placeholder='Enter text here…')
button_conversation = pn.widgets.Button(name="Chat!")
interactive_conversation = pn.bind(collect_messages, button_conversation)
dashboard = pn.Column(
inp,
pn.Row(button_conversation),
pn.panel(interactive_conversation, loading_indicator=True, height=300),
)
dashboard
這裡需要注意的是,因為context是全域性的,所以每一次訊息都會帶上之前的歷史訊息,並行送給伺服器端。
09 Conclusion 結論
- 原則:
- 寫指令要求清晰和具體。
- 給模型一些思考的時間。
- 提示的開發過程是持續迭代的。
- 能力:總結、推理、轉換、擴充套件。
本文最初我釋出在了 https://volnet.hashnode.dev/gpt-prompt-dev-deeplearningai 說是釋出,也就是自己寫著玩,連那個blog都是看著好奇隨手註冊的,不過今天看到很多割韭菜的公眾號默默拿走了,想想,既然有人需要,還是發到我永遠最愛的部落格園吧~
轉載請註明出處:https://www.cnblogs.com/volnet/p/gpt-prompt-dev-deeplearningai.html