線上FullGC問題排查實踐——手把手教你排查線上問題
作者:京東科技 韓國凱
一、問題發現與排查
1.1 找到問題原因
問題起因是我們收到了jdos的容器CPU告警,CPU使用率已經達到104%

觀察該機器紀錄檔發現,此時有很多執行緒在執行跑批任務。正常來說,跑批任務是低CPU高記憶體型,所以此時考慮是FullGC引起的大量CPU佔用(之前有類似情況,告知使用者後重啟應用後解決問題)。
通過泰山檢視該機器記憶體使用情況:

可以看到CPU確實使用率偏高,但是記憶體使用率並不高,只有62%,屬於正常範圍內。
到這裡其實就有點迷惑了,按道理來說此時記憶體應該已經打滿才對。
後面根據其他指標,例如流量的突然進入也懷疑過是jsf介面被突然大量呼叫導致的cpu佔滿,所以記憶體使用率不高,不過後面都慢慢排除了。其實在這裡就有點一籌莫展了,現象與猜測不符,只有CPU增長而沒有記憶體增長,那麼什麼原因會導致單方面CPU增長?然後又朝這個方向排查了半天也都被否定了。
後面突然意識到,會不會是監控有「問題」?
換句話說應該是我們看到的監控有問題,這裡的監控是機器的監控,而不是JVM的監控!
JVM的使用的CPU是在機器上能體現出來的,而JVM的堆記憶體高額使用之後在機器上體現的並不是很明顯。
遂去sgm檢視對應節點的jvm相關情況:
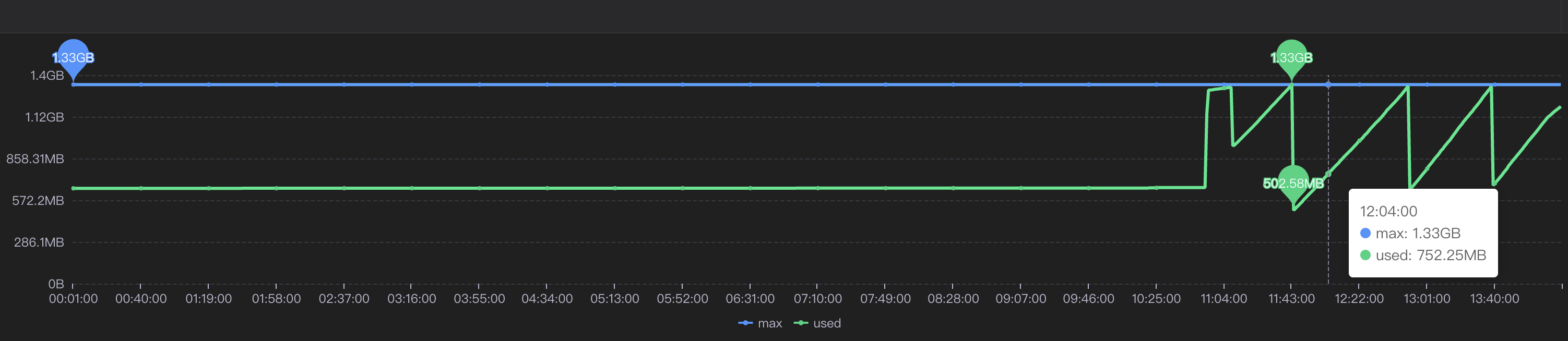
可以看到我們的堆記憶體老年代確實有過被打滿然後又清理後的情況,檢視此時的CPU使用情況也可以與GC時間對應上。
那麼此時可以確定,是Full GC引起的問題。
1.2 找到FULL GC的原因
我們首先dump出了gc前後的堆記憶體快照,
然後使用JPofiler進行記憶體分析。(JProfiler是一款堆記憶體分析工具,可以直接連線線上jvm實時檢視相關資訊,也可以分析dump出來的堆記憶體快照,對某一時刻的堆記憶體情況進行分析)
首先將我們dump出來的檔案解壓,修改字尾名.bin,然後開啟即可。(我們使用行雲上自帶的dump小工具,也可以自己去機器上通過命令手工dump檔案)
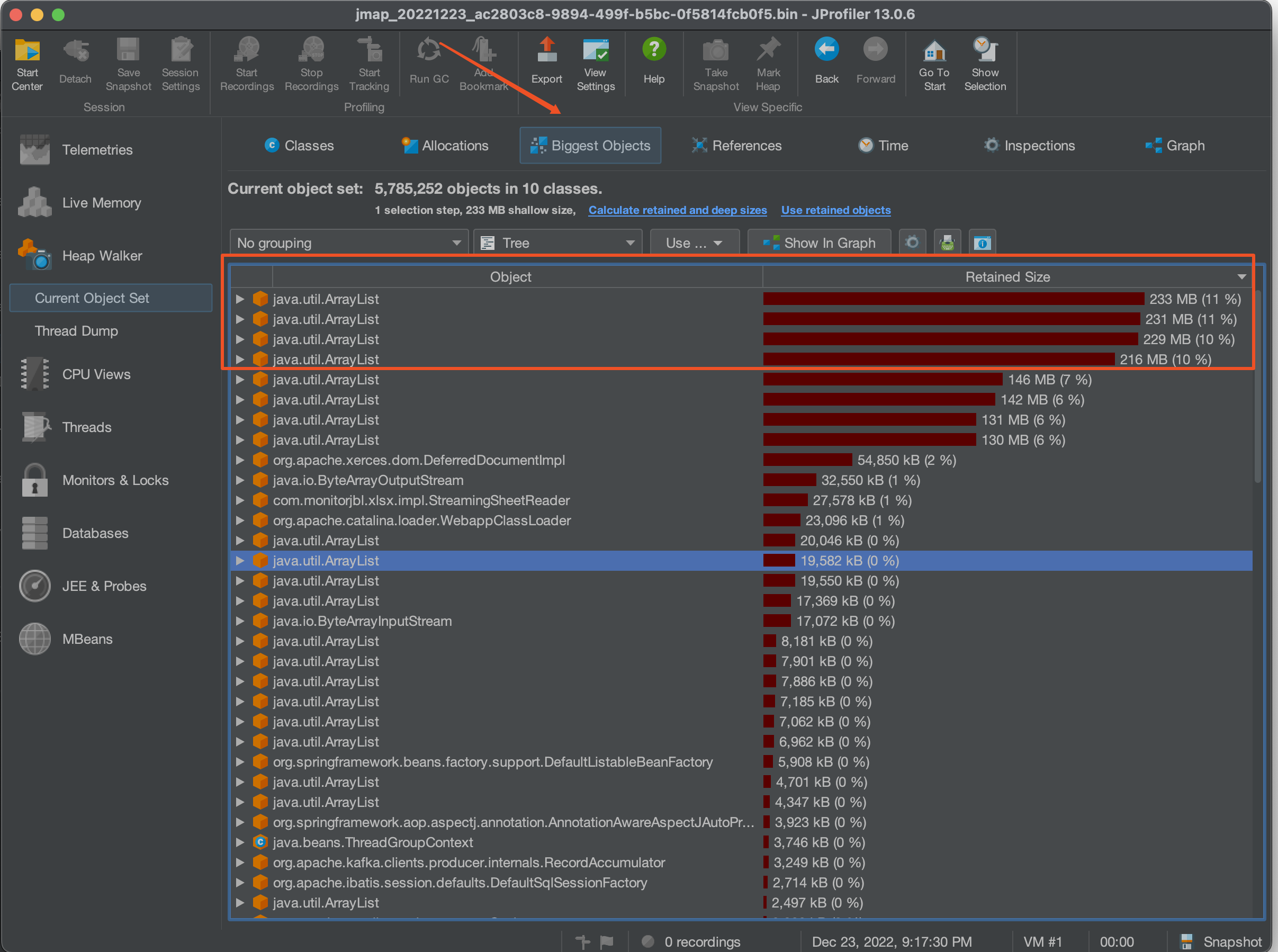
首先選擇Biggest Objects,檢視當時堆記憶體中最大的幾個物件。
從圖中可以看出,四個List物件就佔據了近900MB的記憶體,而我們剛剛看到堆記憶體最大也只有1.3GB,因此再加上其他的物件,很容易就會把老年代佔滿引發full gc的問題。

選擇其中一個最大的物件作為我們要檢視的物件
這個時候我們已經可以定位到對應的大記憶體物件對應的位置:

其實至此我們已經能夠大概定位出問題所在,如果還是不確定的話,可以檢視具體的物件資訊,方法如下:
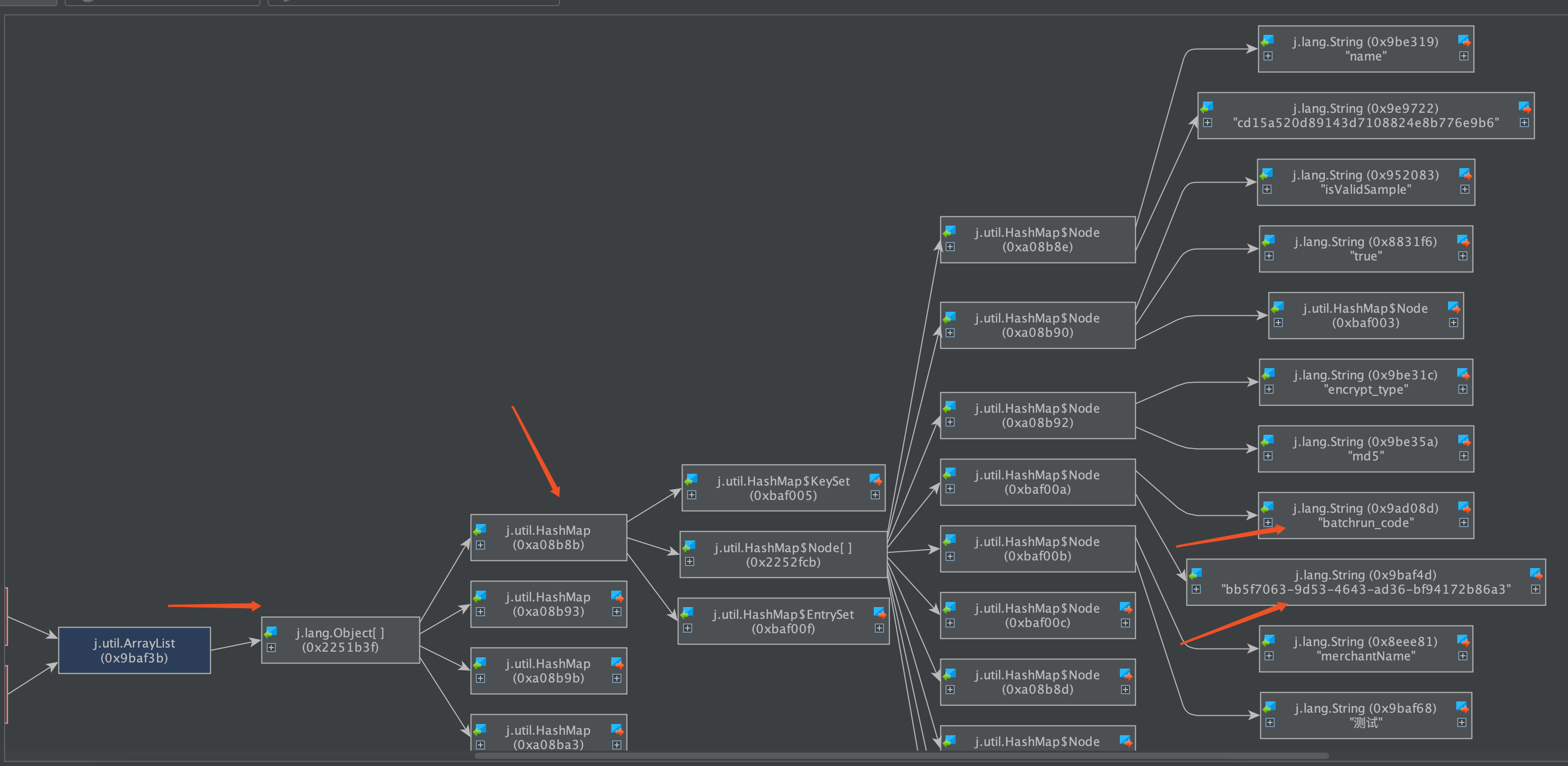
可以看到我們的大List物件,其實內部是很多個Map物件,而每個Map物件中又有很多鍵值對。
在這裡也可以看到Map中的相關屬性資訊。
也可以在以下介面直接看到相關資訊:

然後一路點下去就可以看到對應的屬性。
至此,我們理論上已經找到了大物件在程式碼中的位置。
二、問題解決
2.1 找到大物件在程式碼中的位置與問題的根本原因
首先我們根據上述過程找到對應位置與邏輯
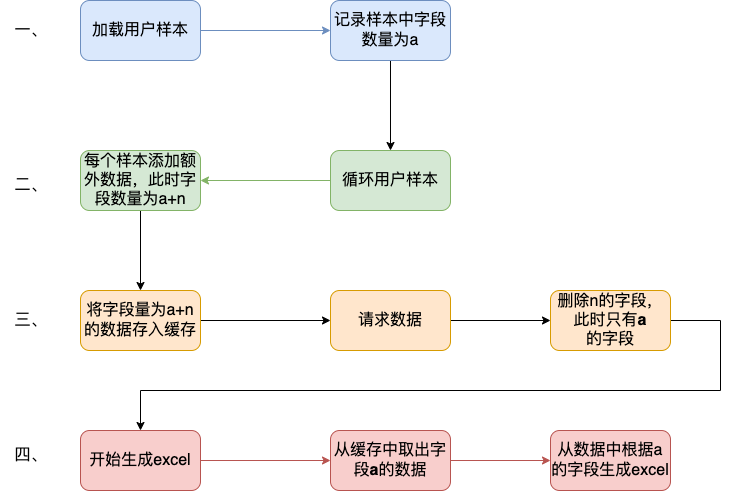
我們的專案中大概邏輯是這樣的:
- 首先會解析使用者上傳的Excel樣本,並將其載入到記憶體中作為一個List變數,即我們上述看到的變數。一個20w的樣本,此時欄位數量有a個,大概佔用空間100mb左右。
- 然後遍歷迴圈使用者樣本,根據使用者樣本中的資料,再增加一些額外的請求資料,根據此資料請求相關結果。此時欄位數量有a+n個,佔用空間已經在200mb左右。
- 迴圈完成後將此200mb的資料存入快取。
- 開始生成excel,將200mb資料從快取中取出,並根據之前記錄的a個欄位,取出初始的樣本欄位填充至excel。
用流程圖表示為:

結合一些具體排查問題的圖片:

其中一個現象是每次gc後的最小記憶體正在逐步變大,對應上述步驟中第二步,記憶體正在逐步膨脹。
結論:
將使用者上傳的excel樣本載入到記憶體中,並將其作為一個List<Map<String, String>>的結構儲存起來,首先一個20mb的excel檔案以此方式儲存會膨脹佔用120mb左右堆記憶體,此步驟會大量佔用堆記憶體,並且因為任務邏輯原因,該大物件記憶體會在jvm中存在長達4-12小時之久,導致一但任務過多,jvm堆記憶體很容易被打滿。
這裡列舉了為什麼使用HashMap會導致記憶體膨脹,其主要原因是儲存空間效率比較低:
一個Long物件佔記憶體計算:在HashMap<Long,Long>結構中,只有Key和Value所存放的兩個長整型資料是有效資料,共16位元組(2×8位元組)。這兩個長整型封包裝成java.lang.Long物件之後,就分別具有8位元組的MarkWord、8位元組的Klass指標,再加8位元組儲存資料的long值(一個包裝物件佔24位元組)。
然後這2個Long物件組成Map.Entry之後,又多了16位元組的物件頭(8位元組MarkWord+8位元組Klass指標=16位元組),然後一個8位元組的next欄位和4位元組的int型的hash欄位(8位元組next指標+4位元組hash欄位+4位元組填充=16位元組),為了對齊,還必須新增4位元組的空白填充,最後還有HashMap中對這個Entry的8位元組的參照,這樣增加兩個長整型數位,實際耗費的記憶體為(Long(24byte)×2)+Entry(32byte)+HashMapRef(8byte)=88byte,空間效率為有效資料除以全部記憶體空間,即16位元組/88位元組=18%。
——《深入理解Java虛擬機器器》5.2.6
以下是剛上傳的excel中dump出的堆記憶體物件,其佔用的記憶體達到了128mb,而上傳的excel實際只有17.11mb。


空間效率17.1mb/128mb≈13.4%
2.2 如何解決此問題
暫且不討論上述流程是否合理,解決辦法一般可以分為兩類,一類是治本,即不把該物件放入jvm記憶體中,轉而存入快取中,不在記憶體中則大物件問題自然迎刃而解。另一類是治標,即縮小該大記憶體物件,在日常使用場景下使其一般不會觸發頻繁的full gc問題。
兩種方式各有優劣:
2.2.1 激進治療:不把他存入記憶體
解決邏輯也很簡單,例如在載入資料時,將其按照樣本載入資料一條一條存入redis快取,然後我們只需要知道樣本中有多少的數量,按照數量的先後順序從快取中取出資料,即可解決該問題。
優點:可以從根本上解決此問題,以後基本上不會存在該問題,資料量再大隻需要新增相應的redis資源即可。
缺點:首先會增加許多redis快取空間消耗,其次從顯示考慮對於我們專案來說,此處程式碼古老且晦澀難懂,改動需要較大工作量與迴歸測試。

2.2.2 保守治療:縮減其資料量
分析2.1的上述流程,首先第三步是完全沒必要的,先存入快取再取出,額外佔用快取空間。(猜測系歷史問題,此處不再深究)。
其次是在第二步中,多出來的欄位n,在請求結束後該欄位就已經無用了,因此可以考慮在請求結束後刪除無用欄位。
此時也有兩種解決方案,一種是只刪除無用欄位縮減其map大小,然後將其作為引數傳遞給生成excel使用;另一種方式是請求完成直接刪除該map,然後在生成excel時再重新讀取使用者上傳的excel樣本。
優點:改動較小,不需要太複雜的迴歸測試
缺點:在極端巨量資料量情況下,仍有可能出現full gc的情況
具體實現方式就不展開了。
其中一種實現方式
//獲取有用的欄位
String[] colEnNames = (String[]) colNameMap.get(Constant.BATCH_COL_EN_NAMES);
List<String> colList = Arrays.asList(colEnNames);
//去除無用的欄位
param.keySet().removeIf(key -> !colList.contains(key));
三、拓展思考
首先本文中監控圖是在復現當時場景時人為製造的gc常見。
在cpu使用率圖中,大家可以觀察到cpu使用率上升時間確實跟gc的時間相吻合,但是並沒有出現當時場景中的104%的CPU使用率。


其實直接原因比較簡單,就是因為系統雖然出現了full gc,但是並沒有頻繁出現。
小範圍低頻率的full gc不太會引起系統的cpu飆升,這也是我們所看到的現象。
那麼當時的場景是什麼原因呢?

我們上文提到過,我們在堆記憶體中的大物件是會隨著任務的進行逐步膨脹的,那麼當我們的任務足夠多,時間足夠長,就有可能導致每次full gc後可用空間變得越來越小,當可用空間小到一定程度之後就,每次full gc完成之後發現空間還是不夠使用,就會觸發下一次的gc,從而導致最終結果的頻繁發生gc,引起cpu頻率的飆升不下。
四、問題排查總結
- 當我們遇到線上cpu使用率過高的情況時,可以先檢視是否是full gc引起的問題,注意要看的是jvm的監控,或者使用jstat相關命令檢視。不要被機器記憶體監控所誤導。
- 如果確定是gc引起的問題,可以通過JProfiler直連線上jvm或者使用dump儲存堆快照後離線分析。
- 首先可以找到最大的物件,一般情況下是大物件引起的full gc。還有一種情況是,不像這麼明顯是四個大物件,也可能是比較均衡的十幾個50mb的物件,具體情況還需要具體分析。
- 通過上述工具找到確定有問題的物件後找到其堆疊對應的程式碼位置,通過程式碼分析找到問題的具體原因,通過其他現象推演猜測是否正確,進而找到問題的真正原因。
- 根據問題的原因解決此問題。
當然,上述只是不算很複雜的排查情況,不同的系統肯定有不同的記憶體情況,我們應當具體問題具體分析,而從此次問題中可以學到的就是如果排查解決問題的思路。