「StackLLaMA」: 用 RLHF 訓練 LLaMA 的手把手教學
2023-05-05 12:01:28
如 ChatGPT,GPT-4,Claude語言模型 之強大,因為它們採用了 基於人類反饋的強化學習 (Reinforcement Learning from Human Feedback, RLHF) 來使之更符合我們的使用場景。
本部落格旨在展示用 RLHF 訓練一個 LLaMA 模型,以回答 Stack Exchange 上的問題。具體而言,包含以下幾個方面:
- 有監督的微調 (Supervised Fine-tuning,SFT)。
- 獎勵 / 偏好建模 (Reward / preference modeling,RM)。
- 基於人類反饋的強化學習 (RLHF)。
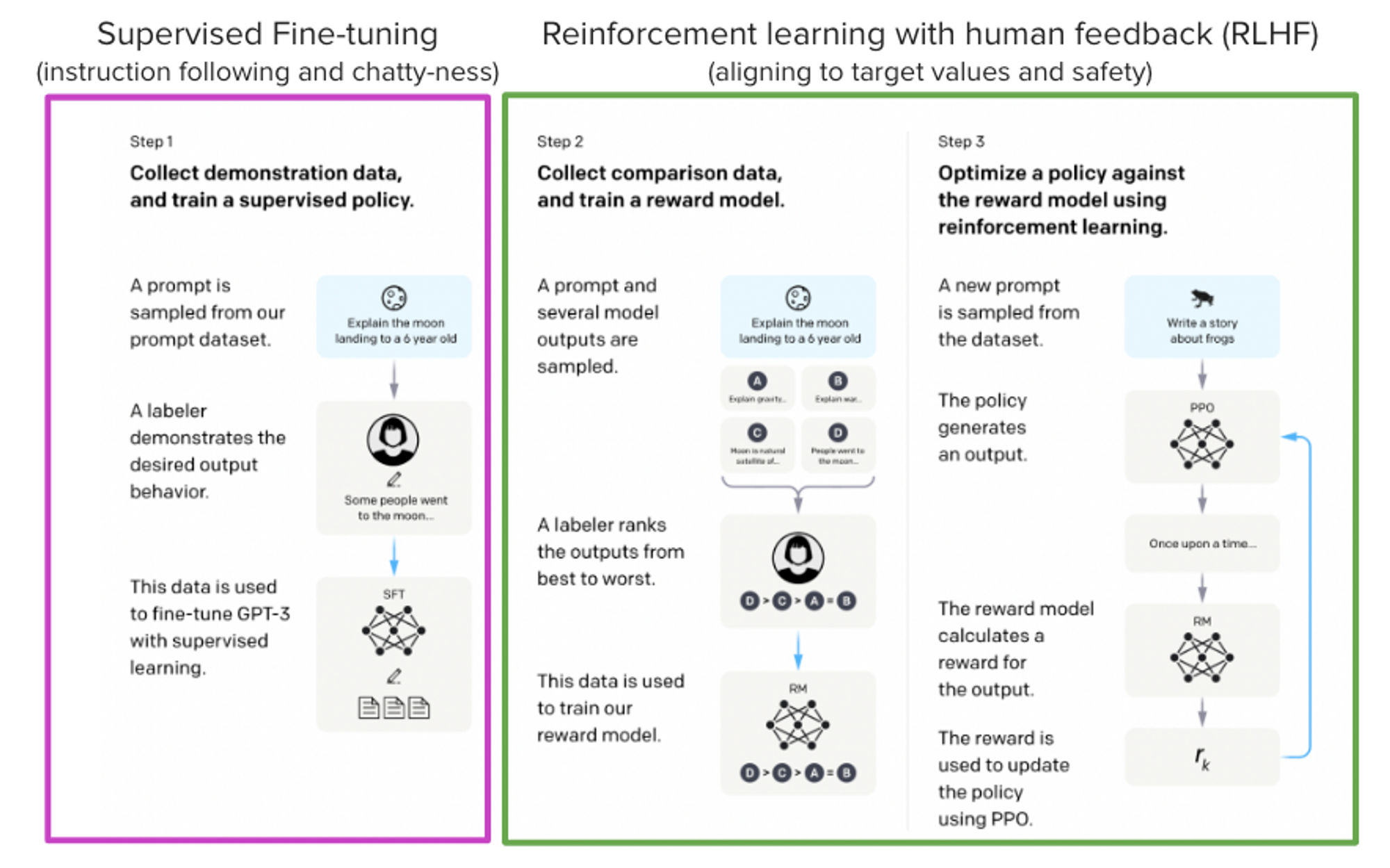
摘自 InstructGPT 論文,Ouyang, Long, et al. 「Training language models to follow instructions with human feedback.」 arXiv preprint arXiv:2203.02155 (2022).