深入理解 slab cache 記憶體分配全鏈路實現
本文原始碼部分基於核心 5.4 版本討論
在經過上篇文章 《從核心原始碼看 slab 記憶體池的建立初始化流程》 的介紹之後,我們最終得到下面這幅 slab cache 的完整架構圖:
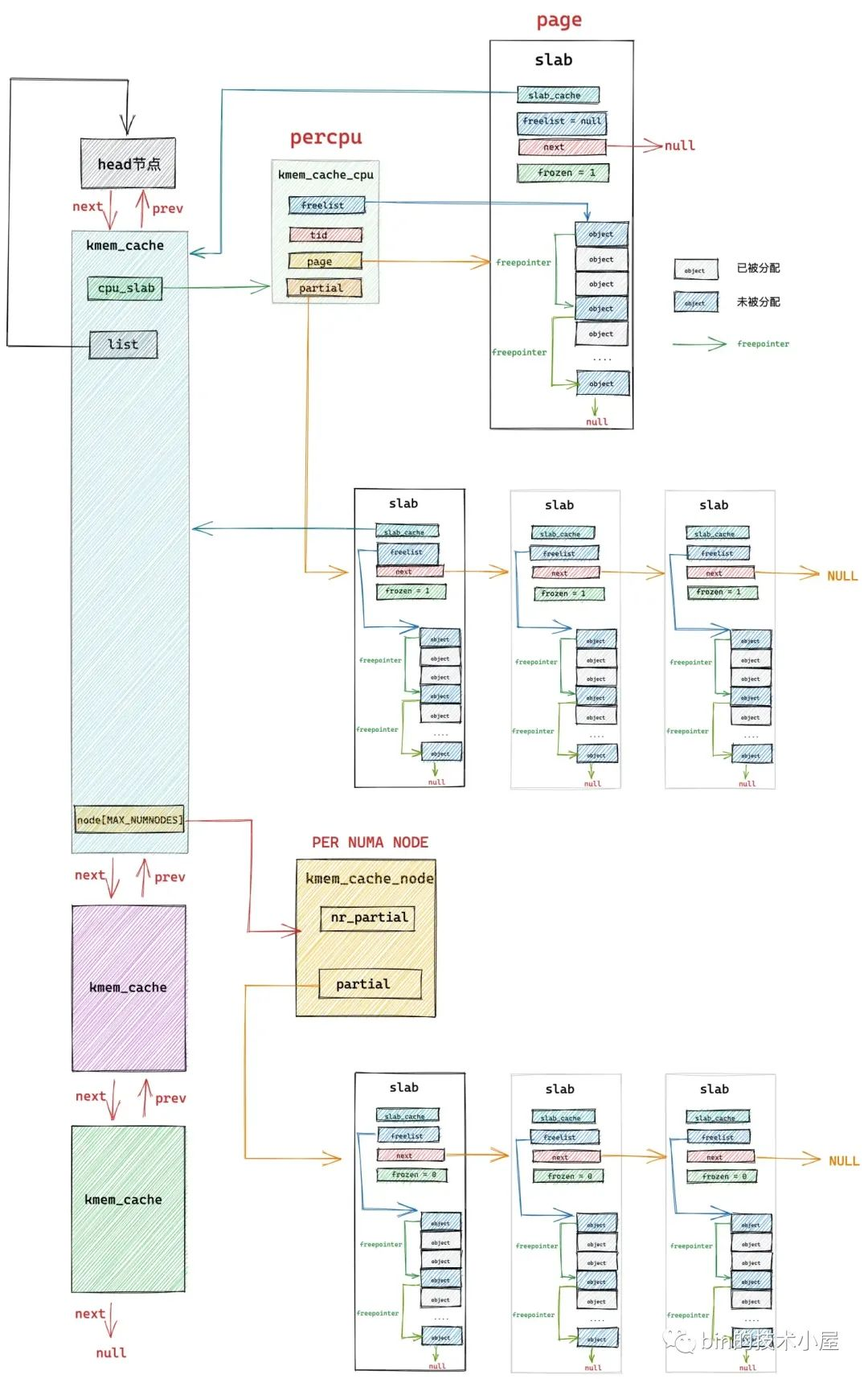
本文筆者將帶大家繼續從核心原始碼的角度繼續拆解 slab cache 的實現細節,接下來筆者會基於上面這幅 slab cache 完整架構圖,詳細介紹一下 slab cache 是如何進行記憶體分配的。

1. slab cache 如何分配記憶體
當我們使用 fork() 系統呼叫建立程序的時候,核心需要為程序建立 task_struct 結構,struct task_struct 是核心中的核心資料結構,當然也會有專屬的 slab cache 來進行管理,task_struct 專屬的 slab cache 為 task_struct_cachep。
下面筆者就以核心從 task_struct_cachep 中申請 task_struct 物件為例,為大家剖析 slab cache 分配記憶體的整個原始碼實現。
核心通過定義在檔案 /kernel/fork.c 中的 dup_task_struct 函數來為程序申請
task_struct 結構並初始化。
static struct task_struct *dup_task_struct(struct task_struct *orig, int node)
{
...........
struct task_struct *tsk;
// 從 task_struct 物件專屬的 slab cache 中申請 task_struct 物件
tsk = alloc_task_struct_node(node);
...........
}
// task_struct 物件專屬的 slab cache
static struct kmem_cache *task_struct_cachep;
static inline struct task_struct *alloc_task_struct_node(int node)
{
// 利用 task_struct_cachep 動態分配 task_struct 物件
return kmem_cache_alloc_node(task_struct_cachep, GFP_KERNEL, node);
}
核心中通過 kmem_cache_alloc_node 函數要求 slab cache 從指定的 NUMA 節點中分配物件。
// 定義在檔案:/mm/slub.c
void *kmem_cache_alloc_node(struct kmem_cache *s, gfp_t gfpflags, int node)
{
void *ret = slab_alloc_node(s, gfpflags, node, _RET_IP_);
return ret;
}

static __always_inline void *slab_alloc_node(struct kmem_cache *s,
gfp_t gfpflags, int node, unsigned long addr)
{
// 用於指向分配成功的物件
void *object;
// slab cache 在當前 cpu 下的本地 cpu 快取
struct kmem_cache_cpu *c;
// object 所在的記憶體頁
struct page *page;
// 當前 cpu 編號
unsigned long tid;
redo:
// slab cache 首先嚐試從當前 cpu 本地快取 kmem_cache_cpu 中獲取空閒物件
// 這裡的 do..while 迴圈是要保證獲取到的 cpu 本地快取 c 是屬於執行程序的當前 cpu
// 因為程序可能由於搶佔或者中斷的原因被排程到其他 cpu 上執行,所需需要確保兩者的 tid 是否一致
do {
// 獲取執行當前程序的 cpu 中的 tid 欄位
tid = this_cpu_read(s->cpu_slab->tid);
// 獲取 cpu 本地快取 cpu_slab
c = raw_cpu_ptr(s->cpu_slab);
// 如果開啟了 CONFIG_PREEMPT 表示允許優先順序更高的程序搶佔當前 cpu
// 如果發生搶佔,當前程序可能被重新排程到其他 cpu 上執行,所以需要檢查此時執行當前程序的 cpu tid 是否與剛才獲取的 cpu 本地快取一致
// 如果兩者的 tid 欄位不一致,說明程序已經被排程到其他 cpu 上了, 需要再次獲取正確的 cpu 本地快取
} while (IS_ENABLED(CONFIG_PREEMPT) &&
unlikely(tid != READ_ONCE(c->tid)));
// 從 slab cache 的 cpu 本地快取 kmem_cache_cpu 中獲取快取的 slub 空閒物件列表
// 這裡的 freelist 指向本地 cpu 快取的 slub 中第一個空閒物件
object = c->freelist;
// 獲取本地 cpu 快取的 slub,這裡用 page 表示,如果是複合頁,這裡指向複合頁的首頁 head page
page = c->page;
if (unlikely(!object || !node_match(page, node))) {
// 如果 slab cache 的 cpu 本地快取中已經沒有空閒物件了
// 或者 cpu 本地快取中的 slub 並不屬於我們指定的 NUMA 節點
// 那麼我們就需要進入慢速路徑中分配物件:
// 1. 檢查 kmem_cache_cpu 的 partial 列表中是否有空閒的 slub
// 2. 檢查 kmem_cache_node 的 partial 列表中是否有空閒的 slub
// 3. 如果都沒有,則只能重新到夥伴系統中去申請記憶體頁
object = __slab_alloc(s, gfpflags, node, addr, c);
// 統計 slab cache 的狀態資訊,記錄本次分配走的是慢速路徑 slow path
stat(s, ALLOC_SLOWPATH);
} else {
// 走到該分支表示,slab cache 的 cpu 本地快取中還有空閒物件,直接分配
// 快速路徑 fast path 下分配成功,從當前空閒物件中獲取下一個空閒物件指標 next_object
void *next_object = get_freepointer_safe(s, object);
// 更新 kmem_cache_cpu 結構中的 freelist 指向 next_object
if (unlikely(!this_cpu_cmpxchg_double(
s->cpu_slab->freelist, s->cpu_slab->tid,
object, tid,
next_object, next_tid(tid)))) {
note_cmpxchg_failure("slab_alloc", s, tid);
goto redo;
}
// cpu 預取 next_object 的 freepointer 到 cpu 快取記憶體,加快下一次分配物件的速度
prefetch_freepointer(s, next_object);
stat(s, ALLOC_FASTPATH);
}
// 如果 gfpflags 掩碼中設定了 __GFP_ZERO,則需要將物件所佔的記憶體初始化為零值
if (unlikely(slab_want_init_on_alloc(gfpflags, s)) && object)
memset(object, 0, s->object_size);
// 返回分配好的物件
return object;
}
2. slab cache 的快速分配路徑
正如筆者在前邊文章 《細節拉滿,80 張圖帶你一步一步推演 slab 記憶體池的設計與實現》 中的 「 7. slab 記憶體分配原理 」 小節裡介紹的原理,slab cache 在最開始會進入 fastpath 分配物件,也就是說首先會從 cpu 本地快取 kmem_cache_cpu->freelist 中獲取物件。
在獲取 kmem_cache_cpu 結構的時候需要保證這個 cpu 本地快取是屬於當前執行程序的 cpu。
在開啟了 CONFIG_PREEMPT 的情況下,核心是允許優先順序更高的程序搶佔當前 cpu 的,當發生 cpu 搶佔之後,程序會被核心重新排程到其他 cpu 上執行,這樣一來,程序在被搶佔之前獲取到的 kmem_cache_cpu 就與當前執行程序 cpu 的 kmem_cache_cpu 不一致了。
核心在 slab_alloc_node 函數開始的地方通過在 do..while 迴圈中不斷判斷兩者的 tid 是否一致來保證這一點。
隨後核心會通過 kmem_cache_cpu->freelist 來獲取 cpu 快取 slab 中的第一個空閒物件。
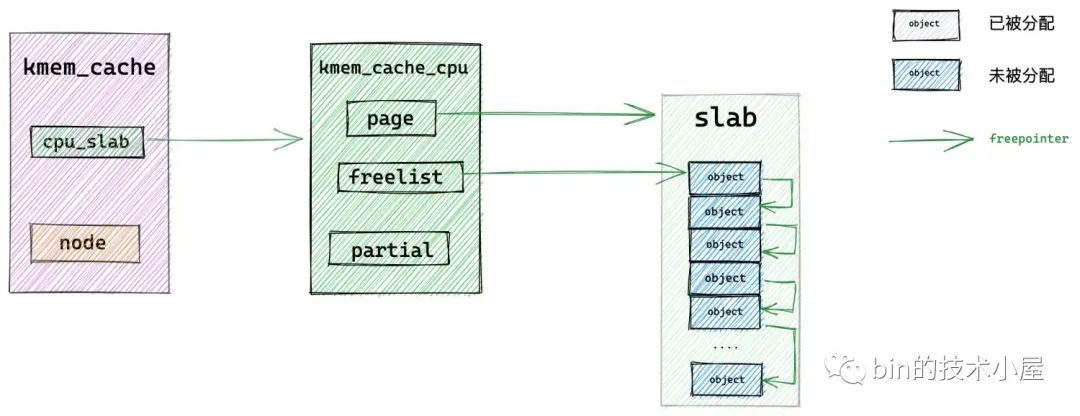
如果當前 cpu 快取 slab 是空的(沒有空閒物件可供分配)或者該 slab 所在的 NUMA 節點並不是我們指定的。那麼就會通過 __slab_alloc 進入到慢速分配路徑 slowpath 中。
如果當前 cpu 快取 slab 有空閒的物件並且 slab 所在的 NUMA 節點正是我們指定的,那麼將當前 kmem_cache_cpu->freelist 指向的第一個空閒物件從 slab 中拿出,並分配出去。

隨後通過 get_freepointer_safe 獲取當前分配物件的 freepointer 指標(指向其下一個空閒物件),然後將 kmem_cache_cpu->freelist 更新為 freepointer (指向的下一個空閒物件)。
// slub 中的空閒物件中均儲存了下一個空閒物件的指標 free_pointer
// free_pointor 在 object 中的位置由 kmem_cache 結構的 offset 指定
static inline void *get_freepointer_safe(struct kmem_cache *s, void *object)
{
// freepointer 在 object 記憶體區域的起始地址
unsigned long freepointer_addr;
// 指向下一個空閒物件的 free_pontier
void *p;
// free_pointer 位於 object 起始地址的 offset 偏移處
freepointer_addr = (unsigned long)object + s->offset;
// 獲取 free_pointer 指向的地址(下一個空閒物件)
probe_kernel_read(&p, (void **)freepointer_addr, sizeof(p));
// 返回下一個空閒物件地址
return freelist_ptr(s, p, freepointer_addr);
}
3. slab cache 的慢速分配路徑
static void *__slab_alloc(struct kmem_cache *s, gfp_t gfpflags, int node,
unsigned long addr, struct kmem_cache_cpu *c)
{
void *p;
unsigned long flags;
// 關閉 cpu 中斷,防止並行存取
local_irq_save(flags);
#ifdef CONFIG_PREEMPT
// 當開啟了 CONFIG_PREEMPT,表示允許其他程序搶佔當前 cpu
// 執行程序的當前 cpu 可能會被其他優先順序更高的程序搶佔,當前程序可能會被排程到其他 cpu 上
// 所以這裡需要重新獲取 slab cache 的 cpu 本地快取
c = this_cpu_ptr(s->cpu_slab);
#endif
// 進入 slab cache 的慢速分配路徑
p = ___slab_alloc(s, gfpflags, node, addr, c);
// 恢復 cpu 中斷
local_irq_restore(flags);
return p;
}
核心為了防止 slab cache 在慢速路徑下的並行安全問題,在進入 slowpath 之前會把中斷關閉掉,並重新獲取 cpu 本地快取。這樣做的目的是為了防止再關閉中斷之前,程序被搶佔,排程到其他 cpu 上。
static void *___slab_alloc(struct kmem_cache *s, gfp_t gfpflags, int node,
unsigned long addr, struct kmem_cache_cpu *c)
{
// 指向 slub 中可供分配的第一個空閒物件
void *freelist;
// 空閒物件所在的 slub (用 page 表示)
struct page *page;
// 從 slab cache 的本地 cpu 快取中獲取快取的 slub
page = c->page;
if (!page)
// 如果快取的 slub 中的物件已經被全部分配出去,沒有空閒物件了
// 那麼就會跳轉到 new_slab 分支進行降級處理走慢速分配路徑
goto new_slab;
redo:
// 這裡需要再次檢查 slab cache 本地 cpu 快取中的 freelist 是否有空閒物件
// 因為當前程序可能被中斷,當重新排程之後,其他程序可能已經釋放了一些物件到快取 slab 中
// freelist 可能此時就不為空了,所以需要再次嘗試一下
freelist = c->freelist;
if (freelist)
// 從 cpu 本地快取中的 slub 中直接分配物件
goto load_freelist;
// 本地 cpu 快取的 slub 用 page 結構來表示,這裡是檢查 page 結構的 freelist 是否還有空閒物件
// c->freelist 表示的是本地 cpu 快取的空閒物件列表,剛我們已經檢查過了
// 現在我們檢查的 page->freelist ,它表示由其他 cpu 所釋放的空閒物件列表
// 因為此時有可能其他 cpu 又釋放了一些物件到 slub 中這時 slub 對應的 page->freelist 不為空,可以直接分配
freelist = get_freelist(s, page);
// 注意這裡的 freelist 已經變為 page->freelist ,並不是 c->freelist;
if (!freelist) {
// 此時 cpu 本地快取的 slub 裡的空閒物件已經全部耗盡
// slub 從 cpu 本地快取中脫離,進入 new_slab 分支走慢速分配路徑
c->page = NULL;
stat(s, DEACTIVATE_BYPASS);
goto new_slab;
}
stat(s, ALLOC_REFILL);
load_freelist:
// 被 slab cache 的 cpu 本地快取的 slub 所屬的 page 必須是 frozen 凍結狀態,只允許本地 cpu 從中分配物件
VM_BUG_ON(!c->page->frozen);
// kmem_cache_cpu 中的 freelist 指向被 cpu 快取 slub 中第一個空閒物件
// 由於第一個空閒物件馬上要被分配出去,所以這裡需要獲取下一個空閒物件更新 freelist
c->freelist = get_freepointer(s, freelist);
// 更新 slab cache 的 cpu 本地快取分配物件時的全域性 transaction id
// 每當分配完一次物件,kmem_cache_cpu 中的 tid 都需要改變
c->tid = next_tid(c->tid);
// 返回第一個空閒物件
return freelist;
new_slab:
......... 進入 slowpath 分配物件 ..........
}
在 slab cache 進入慢速路徑之前,核心還需要再次檢查本地 cpu 快取的 slab 的儲存容量,確保其真的沒有空閒物件了。
如果本地 cpu 快取的 slab 為空( kmem_cache_cpu->page == null ),直接跳轉到 new_slab 分支進入 slow path。
如果本地 cpu 快取的 slab 不為空,那麼需要再次檢查 slab 中是否有空閒物件,這麼做的目的是因為當前程序可能被中斷,當重新排程之後,其他程序可能已經釋放了一些物件到快取 slab 中了,所以在進入 slowpath 之前還是有必要再次檢查一下 kmem_cache_cpu->freelist。
如果碰巧,其他程序在當前程序被中斷之後,已經釋放了一些物件回快取 slab 中了,那麼就直接跳轉至 load_freelist 分支,走 fastpath 路徑,直接從快取 slab (kmem_cache_cpu->freelist) 中分配物件,避免進入 slowpath。
load_freelist:
// 更新 freelist,指向下一個空閒物件
c->freelist = get_freepointer(s, freelist);
// 更新 tid
c->tid = next_tid(c->tid);
// 返回第一個空閒物件
return freelist;
如果 kmem_cache_cpu->freelist 還是為空,則需要再次檢查 slab 本身的 freelist 是否空,注意這裡指的是 struct page 結構中的 freelist。
struct page {
// 指向記憶體頁中第一個空閒物件
void *freelist; /* first free object */
// 該 slab 是否在對應 slab cache 的本地 CPU 快取中
// frozen = 1 表示快取再本地 cpu 快取中
unsigned frozen:1;
}
大家讀到這裡一定會感覺非常懵,kmem_cache_cpu 結構中有一個 freelist,page 結構也有一個 freelist,懵逼的是這兩個 freelist 均是指向 slab 中第一個空閒物件,它倆之間有什麼差別嗎?
事實上,這一塊的確比較複雜,邏輯比較繞,所以筆者有必要詳細的為大家說明一下,以解決大家心中的困惑。
首先,在 slab cache 的整個架構體系中的確存在兩個 freelist:
-
一個是 page->freelist,因為 slab 在核心中是使用 struct page 結構來表示的,所以 page->freelist 只是單純的站在 slab 的視角來表示 slab 中的空閒物件列表,這裡不考慮 slab 在 slab cache 架構中的位置。
-
另一個是 kmem_cache_cpu->freelist,特指 slab 被 slab cache 的本地 cpu 快取之後,slab 中的空閒物件連結串列。這裡可以理解為 slab 中被 cpu 快取的空閒物件。當 slab 被提升為 cpu 快取之後,page->freeelist 直接賦值給 kmem_cache_cpu->freelist,然後 page->freeelist 置空。slab->frozen 設定為 1,表示 slab 被凍結在當前 cpu 的本地快取中。
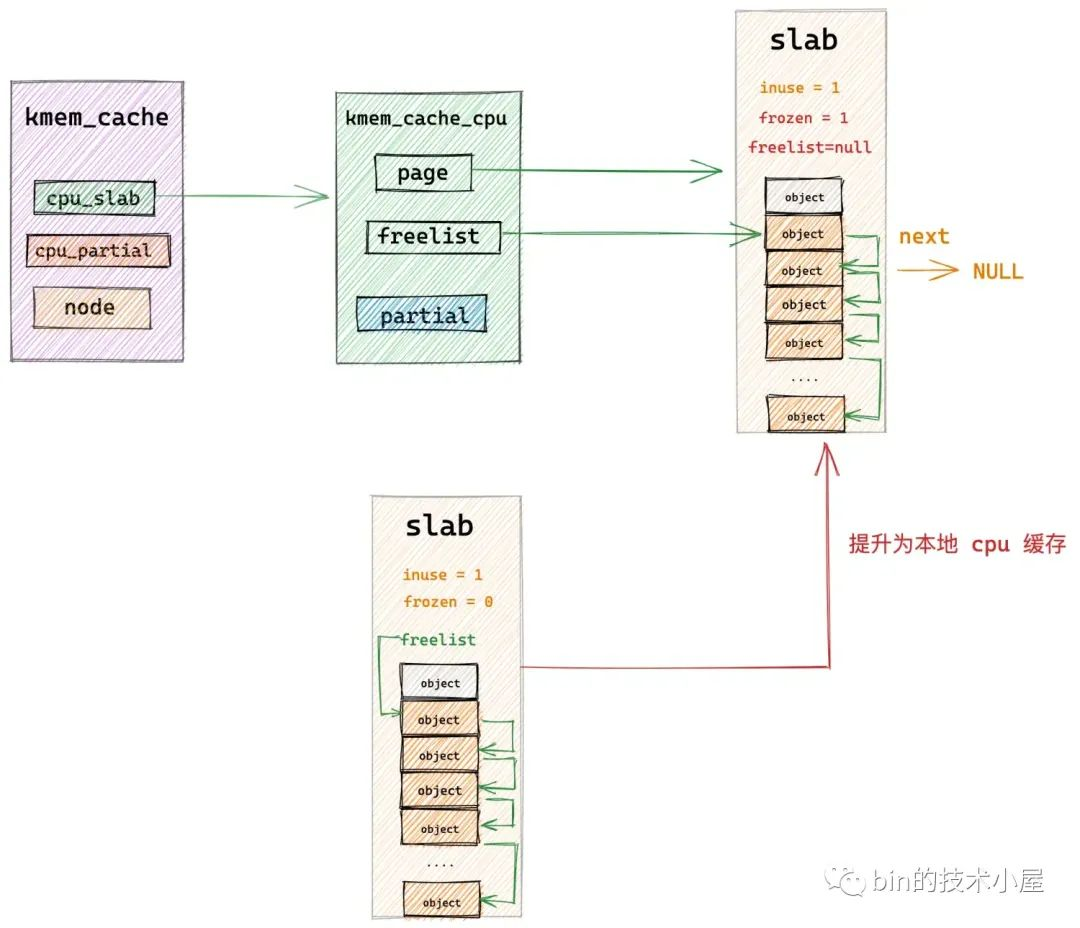
而 slab 一旦被當前 cpu 快取,它的狀態就變為了凍結狀態(slab->frozen = 1),處於凍結狀態下的 slab,當前 cpu 可以從該 slab 中分配或者釋放物件,但是其他 cpu 只能釋放物件到該 slab 中,不能從該 slab 中分配物件。
-
如果一個 slab 被一個 cpu 快取之後,那麼這個 cpu 在該 slab 看來就是本地 cpu,當本地 cpu 釋放物件回這個 slab 的時候會釋放回 kmem_cache_cpu->freelist 連結串列中
-
如果其他 cpu 想要釋放物件回該 slab 時,其他 cpu 只能將物件釋放回該 slab 的 page->freelist 中。
什麼意思呢?筆者來舉一個具體的例子為大家詳細說明。
如下圖所示,cpu1 在本地快取了 slab1,cpu2 在本地快取了 slab2,程序先從 slab1 中獲取了一個物件,正常情況下如果程序一直在 cpu1 上執行的話,當程序釋放該物件回 slab1 中時,會直接釋放回 kmem_cache_cpu1->freelist 連結串列中。
但如果程序在 slab1 中獲取完物件之後,被排程到了 cpu2 上執行,這時程序想要釋放物件回 slab1 中時,就不能走快速路徑了,因為 cpu2 本地快取的是 slab2,所以 cpu2 只能將物件釋放至 slab1->freelist 中。
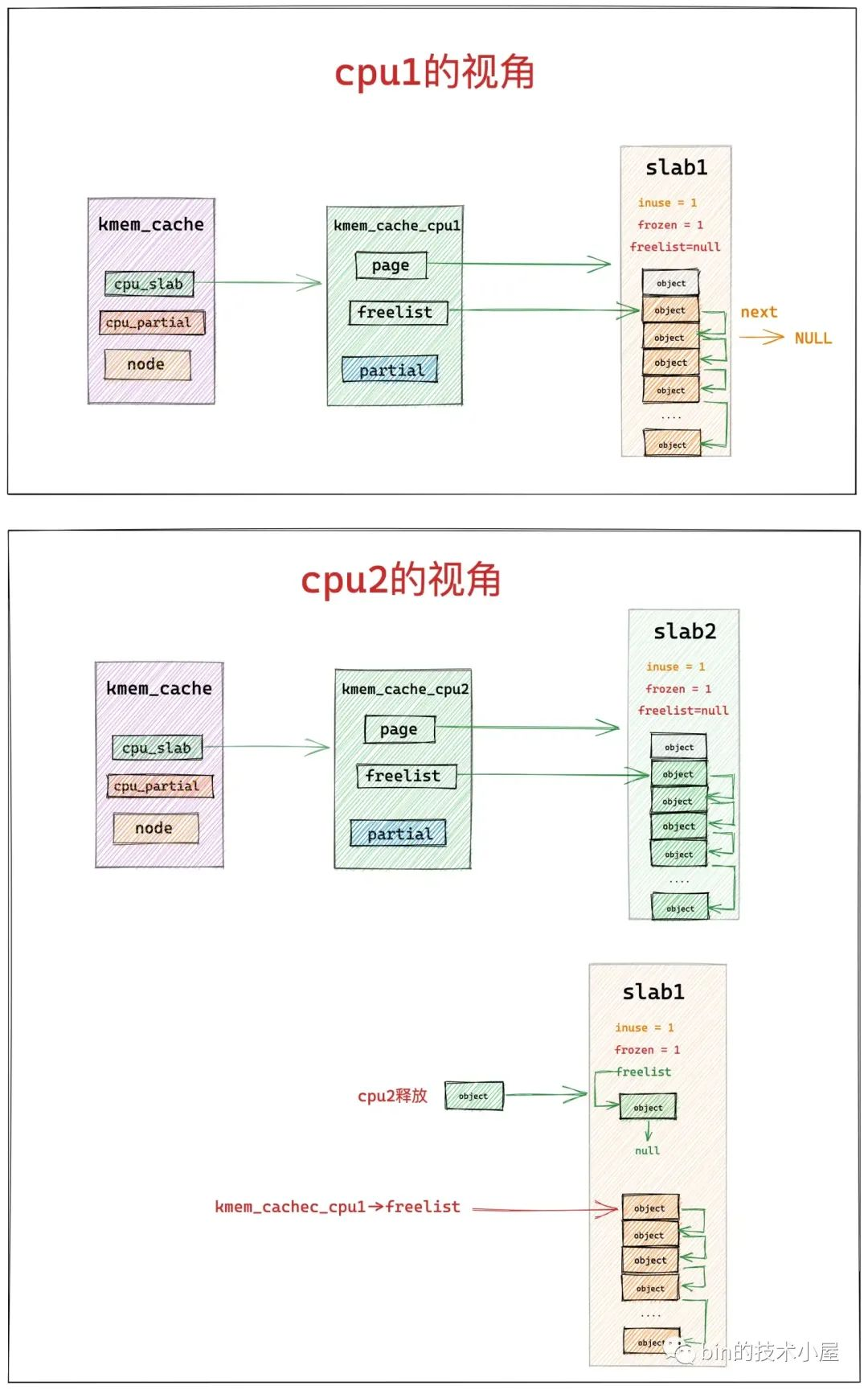
這種情況下,在 slab1 的內部視角里,就有了兩個 freelist 連結串列,它們的共同之處都是用於組織 slab1 中的空閒物件,但是 kmem_cache_cpu1->freelist 連結串列中組織的是快取再 cpu1 原生的空閒物件,slab1->freelist 連結串列組織的是由其他 cpu 釋放的空閒物件。
明白了這些,讓我們再次回到 ___slab_alloc 函數的開始處,首先核心會在 slab cache 的本地 cpu 快取 kmem_cache_cpu->freelist 中查詢是否有空閒物件,如果這裡沒有,核心會繼續到 page->freelist 中檢視是否有其他 cpu 釋放的空閒物件
如果兩個 freelist 連結串列都沒有空閒物件了,那就證明 slab cache 在當前 cpu 本地快取中的 slab 已經為空了,將該 slab 從當前 cpu 本地快取中脫離解凍,程式跳轉到 new_slab 分支進入慢速分配路徑。
// 檢視 page->freelist 中是否有其他 cpu 釋放的空閒物件
static inline void *get_freelist(struct kmem_cache *s, struct page *page)
{
// 用於存放要更新的 page 屬性值
struct page new;
unsigned long counters;
void *freelist;
do {
// 獲取 page 結構的 freelist,當其他 cpu 向 page 釋放物件時 freelist 指向被釋放的空閒物件
// 當 page 被 slab cache 的 cpu 本地快取時,freelist 置為 null
freelist = page->freelist;
counters = page->counters;
new.counters = counters;
VM_BUG_ON(!new.frozen);
// 更新 inuse 欄位,表示 page 中的物件 objects 全部被分配出去了
new.inuse = page->objects;
// 如果 freelist != null,表示其他 cpu 又釋放了一些物件到 page 中 (slub)。
// 則 page->frozen = 1 , slub 依然凍結在 cpu 本地快取中
// 如果 freelist == null,則 page->frozen = 0, slub 從 cpu 本地快取中脫離解凍
new.frozen = freelist != NULL;
// 最後 cas 原子更新 page 結構中的相應屬性
// 這裡需要注意的是,當 page 被 slab cache 本地 cpu 快取時,page -> freelist 需要置空。
// 因為在本地 cpu 快取場景下 page -> freelist 指向其他 cpu 釋放的空閒物件列表
// kmem_cache_cpu->freelist 指向的是被本地 cpu 快取的空閒物件列表
// 這兩個列表中的空閒物件共同組成了 slub 中的空閒物件
} while (!__cmpxchg_double_slab(s, page,
freelist, counters,
NULL, new.counters,
"get_freelist"));
return freelist;
}
3.1 從本地 cpu 快取 partial 列表中分配
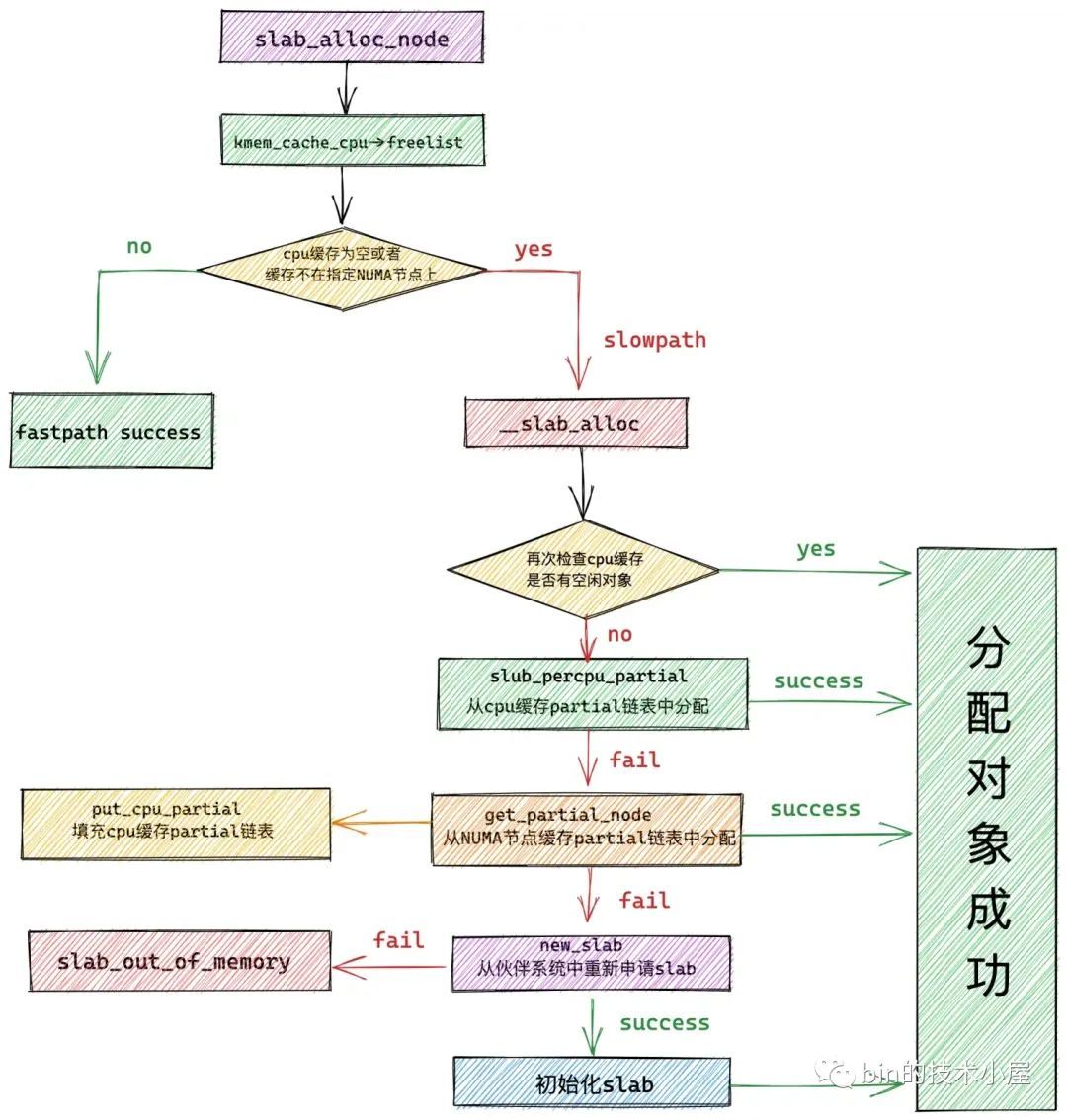
核心經過在 redo 分支的檢查,現在已經確認了 slab cache 在當前 cpu 本地快取的 slab 已經沒有任何可供分配的空閒物件了。
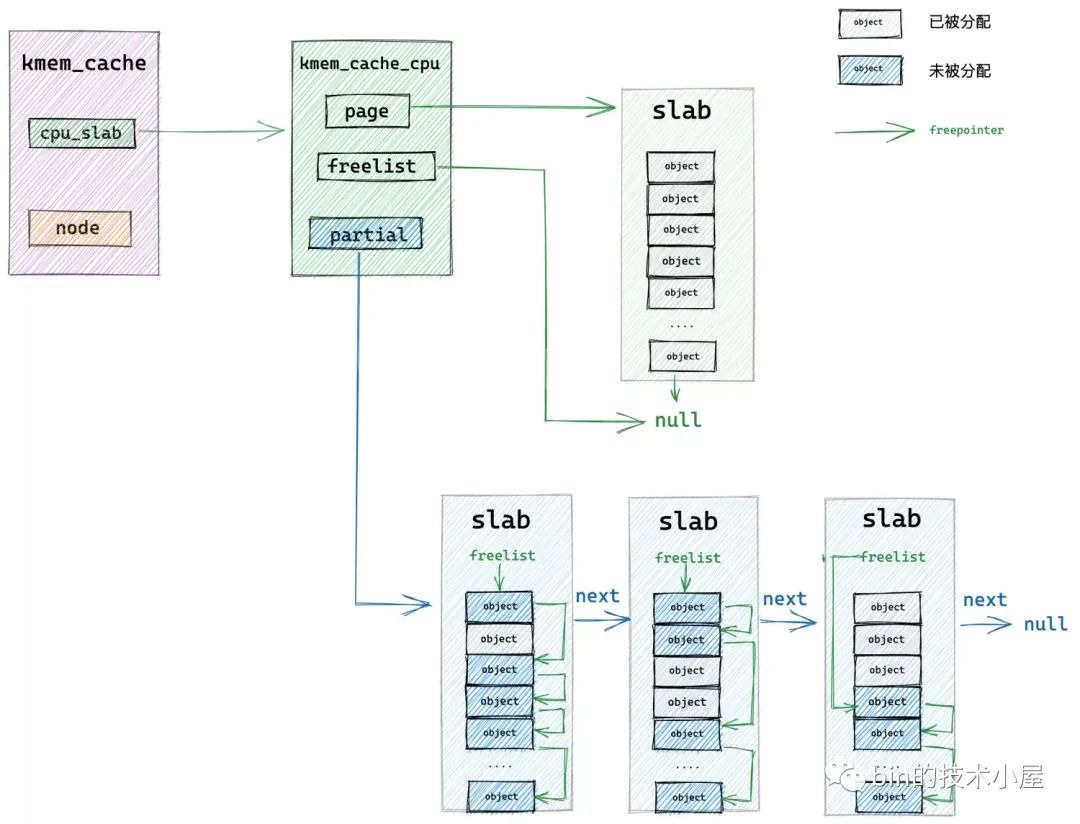
下面核心正式進入到 slowpath 開始分配物件,首先核心會到本地 cpu 快取的 partial 列表中去檢視是否有一個 slab 可以分配物件。這裡核心會從 partial 列表中的頭結點開始遍歷直到找到一個可以滿足分配的 slab 出來。
隨後核心會將該 slab 從 partial 列表中摘下,直接提升為新的本地 cpu 快取,這樣一來 slab cache 的本地 cpu 快取就被更新了,核心通過 kmem_cache_cpu->freelist 指標將快取 slab 中的第一個空閒物件分配出去,隨後更新 kmem_cache_cpu->freelist 指向 slab 中的下一個空閒物件。

static void *___slab_alloc(struct kmem_cache *s, gfp_t gfpflags, int node,
unsigned long addr, struct kmem_cache_cpu *c)
{
............ 檢查本地 cpu 快取是否為空 ...........
redo:
............ 再次確認 kmem_cache_cpu->freelist 中是否有空閒物件 ...........
............ 再次確認 page->freelist 中是否有空閒物件 ...........
load_freelist:
............ 回到 fastpath 直接從 freelist 中分配物件 ...........
new_slab:
// 檢視 kmem_cache_cpu->partial 連結串列中是否有 slab 可供分配物件
if (slub_percpu_partial(c)) {
// 獲取 cpu 本地快取 kmem_cache_cpu 的 partial 列表中的第一個 slub (用 page 表示)
// 並將這個 slub 提升為 cpu 本地快取中的 slub,賦值給 c->page
page = c->page = slub_percpu_partial(c);
// 將 partial 列表中第一個 slub (c->page)從 partial 列表中摘下
// 並將列表中的下一個 slub 更新為 partial 列表的頭結點
slub_set_percpu_partial(c, page);
// 更新狀態資訊,記錄本次分配是從 kmem_cache_cpu 的 partial 列表中分配
stat(s, CPU_PARTIAL_ALLOC);
// 重新回到 redo 分支,這下就可以從 page->freelist 中獲取物件了
// 並且在 load_freelist 分支中將 page->freelist 更新到 c->freelist 中,page->freelist 設定為 null
// 此時 slab cache 中的 cpu 本地快取 kmem_cache_cpu 的 freelist 以及 page 就變為了 partial 列表中的 slub
goto redo;
}
// 流程走到這裡表示 slab cache 中的 cpu 本地快取 partial 列表中也沒有 slub 了
// 需要近一步降級到 numa node cache —— kmem_cache_node 中的 partial 列表去查詢
// 如果還是沒有,就只能去夥伴系統中申請新的 slub,然後分配物件
// 該函數為 slab cache 在慢速路徑下分配物件的核心邏輯
freelist = new_slab_objects(s, gfpflags, node, &c);
if (unlikely(!freelist)) {
// 如果夥伴系統中無法分配 slub 所需的 page,那麼就提示記憶體不足,分配失敗,返回 null
slab_out_of_memory(s, gfpflags, node);
return NULL;
}
page = c->page;
if (likely(!kmem_cache_debug(s) && pfmemalloc_match(page, gfpflags)))
// 此時從 kmem_cache_node->partial 列表中獲取的 slub
// 或者從夥伴系統中重新申請的 slub 已經被提升為本地 cpu 快取了 kmem_cache_cpu->page
// 這裡需要跳轉到 load_freelist 分支,從本地 cpu 快取 slub 中獲取第一個物件返回
goto load_freelist;
}
核心對 kmem_cache_cpu->partial 連結串列的相關操作:
// 定義在檔案 /include/linux/slub_def.h 中
#ifdef CONFIG_SLUB_CPU_PARTIAL
// 獲取 slab cache 本地 cpu 快取的 partial 列表
#define slub_percpu_partial(c) ((c)->partial)
// 將 partial 列表中第一個 slub 摘下,提升為 cpu 本地快取,用於後續快速分配物件
#define slub_set_percpu_partial(c, p) \
({ \
slub_percpu_partial(c) = (p)->next; \
})
如果 slab cache 本地 cpu 快取 kmem_cache_cpu->partial 連結串列也是空的,接下來核心就只能到對應 NUMA 節點快取中去分配物件了。

3.2 從 NUMA 節點快取中分配
// slab cache 慢速路徑下分配物件核心邏輯
static inline void *new_slab_objects(struct kmem_cache *s, gfp_t flags,
int node, struct kmem_cache_cpu **pc)
{
// 從 numa node cache 中獲取到的空閒物件列表
void *freelist;
// slab cache 本地 cpu 快取
struct kmem_cache_cpu *c = *pc;
// 分配物件所在的記憶體頁
struct page *page;
// 嘗試從指定的 node 節點快取 kmem_cache_node 中的 partial 列表獲取可以分配空閒物件的 slub
// 如果指定 numa 節點的記憶體不足,則會根據 cpu 存取距離的遠近,進行跨 numa 節點分配
freelist = get_partial(s, flags, node, c);
if (freelist)
// 返回 numa cache 中快取的空閒物件列表
return freelist;
// 流程走到這裡說明 numa cache 裡快取的 slub 也用盡了,無法找到可以分配物件的 slub 了
// 只能向底層夥伴系統重新申請記憶體頁(slub),然後從新的 slub 中分配物件
page = new_slab(s, flags, node);
// 將新申請的記憶體頁 page (slub),快取到 slab cache 的本地 cpu 快取中
if (page) {
// 獲取 slab cache 的本地 cpu 快取
c = raw_cpu_ptr(s->cpu_slab);
// 重新整理本地 cpu 快取,將舊的 slub 快取與 cpu 本地快取解綁
if (c->page)
flush_slab(s, c);
// 將新申請的 slub 與 cpu 本地快取繫結,page->freelist 賦值給 kmem_cache_cpu->freelist
freelist = page->freelist;
// 繫結之後 page->freelist 置空
// 現在新的 slub 中的空閒物件就已經快取再了 slab cache 的本地 cpu 快取中,後續就直接從這裡分配了
page->freelist = NULL;
stat(s, ALLOC_SLAB);
// 將新申請的 slub 對應的 page 賦值給 kmem_cache_cpu->page
c->page = page;
*pc = c;
}
// 返回空閒物件列表
return freelist;
}
核心首先會在 get_partial 函數中找到我們指定的 NUMA 節點快取結構 kmem_cache_node ,然後開始遍歷 kmem_cache_node->partial 連結串列直到找到一個可供分配物件的 slab。然後將這個 slab 提升為 slab cache 的本地 cpu 快取,並從 kmem_cache_node->partial 連結串列中依次填充 slab 到 kmem_cache_cpu->partial。
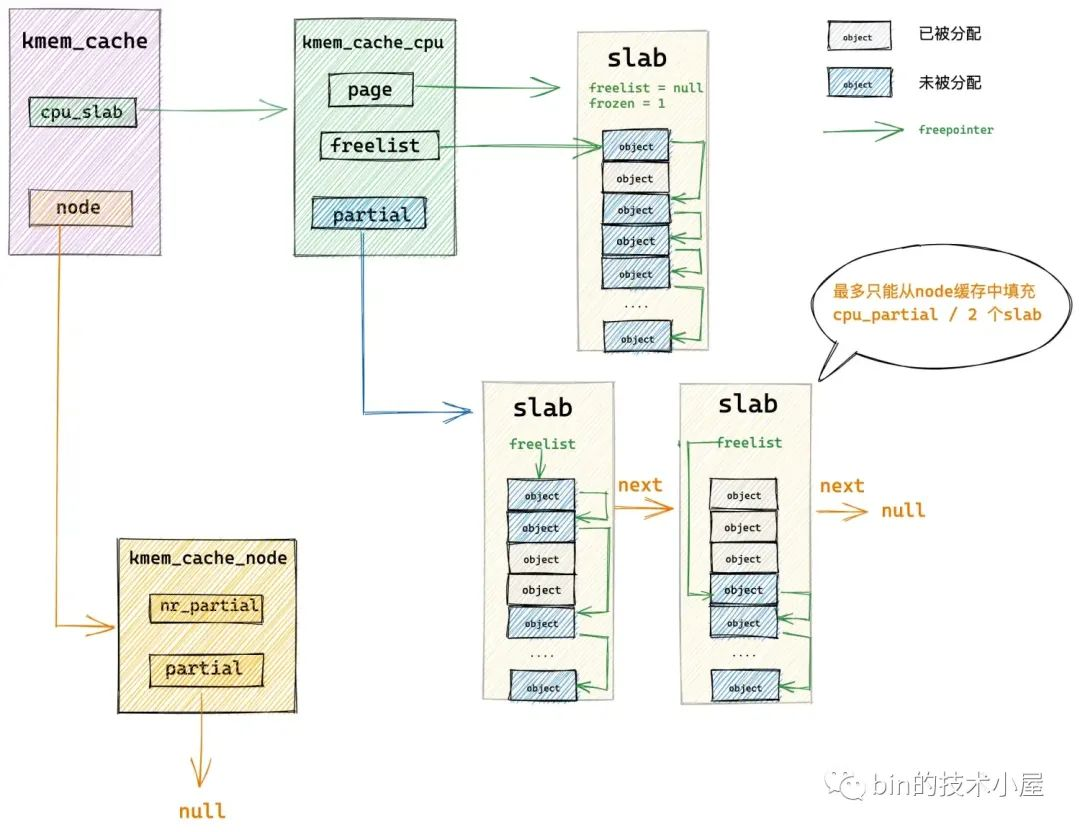
如果我們指定的 NUMA 節點 kmem_cache_node->partial 連結串列也是空的,隨後核心就會跨 NUMA 節點進行查詢,按照存取距離由近到遠,開始查詢其他 NUMA 節點 kmem_cache_node->partial 連結串列。
如果還是不行,最後就只能通過 new_slab 函數到夥伴系統中重新申請一個 slab,並將這個 slab 提升為本地 cpu 快取。
3.2.1 從 NUMA 節點快取 partial 連結串列中查詢
static void *get_partial(struct kmem_cache *s, gfp_t flags, int node,
struct kmem_cache_cpu *c)
{
// 從指定 node 的 kmem_cache_node 快取中的 partial 列表中獲取到的物件
void *object;
// 即將要所搜尋的 kmem_cache_node 快取對應 numa node
int searchnode = node;
// 如果我們指定的 numa node 已經沒有空閒記憶體了,則選取存取距離最近的 numa node 進行跨節點記憶體分配
if (node == NUMA_NO_NODE)
searchnode = numa_mem_id();
else if (!node_present_pages(node))
searchnode = node_to_mem_node(node);
// 從 searchnode 的 kmem_cache_node 快取中的 partial 列表中獲取物件
object = get_partial_node(s, get_node(s, searchnode), c, flags);
if (object || node != NUMA_NO_NODE)
return object;
// 如果 searchnode 物件的 kmem_cache_node 快取中的 partial 列表是空的,沒有任何可供分配的 slub
// 那麼繼續按照存取距離,遍歷 searchnode 之後的 numa node,進行跨節點記憶體分配
return get_any_partial(s, flags, c);
}
get_partial 函數的主要內容是選取合適的 NUMA 節點快取,優先使用我們指定的 NUMA 節點,如果指定的 NUMA 節點中沒有足夠的記憶體,核心就會跨 NUMA 節點按照存取距離的遠近,選取一個合適的 NUMA 節點。
然後通過 get_partial_node 在選取的 NUMA 節點快取 kmem_cache_node->partial 連結串列中查詢 slab。
/*
* Try to allocate a partial slab from a specific node.
*/
static void *get_partial_node(struct kmem_cache *s, struct kmem_cache_node *n,
struct kmem_cache_cpu *c, gfp_t flags)
{
// 接下來就會挨個遍歷 kmem_cache_node 的 partial 列表中的 slub
// 這兩個變數用於臨時儲存遍歷的 slub
struct page *page, *page2;
// 用於指向從 partial 列表 slub 中申請到的物件
void *object = NULL;
// 用於記錄 slab cache 本地 cpu 快取 kmem_cache_cpu 中所快取的空閒物件總數(包括 partial 列表)
// 後續會向 kmem_cache_cpu 中填充 slub
unsigned int available = 0;
// 臨時記錄遍歷到的 slub 中包含的剩餘空閒物件個數
int objects;
spin_lock(&n->list_lock);
// 開始挨個遍歷 kmem_cache_node 的 partial 列表,獲取 slub 用於分配物件以及填充 kmem_cache_cpu
list_for_each_entry_safe(page, page2, &n->partial, slab_list) {
void *t;
// page 表示當前遍歷到的 slub,這裡會從該 slub 中獲取空閒物件賦值給 t
// 並將 slub 從 kmem_cache_node 的 partial 列表上摘下
t = acquire_slab(s, n, page, object == NULL, &objects);
// 如果 t 是空的,說明 partial 列表上已經沒有可供分配物件的 slub 了
// slub 都滿了,退出迴圈,進入夥伴系統重新申請 slub
if (!t)
break;
// objects 表示當前 slub 中包含的剩餘空閒物件個數
// available 用於統計目前遍歷的 slub 中所有空閒物件個數
// 後面會根據 available 的值來判斷是否繼續填充 kmem_cache_cpu
available += objects;
if (!object) {
// 第一次迴圈會走到這裡,第一次迴圈主要是滿足當前物件分配的需求
// 將 partila 列表中第一個 slub 快取進 kmem_cache_cpu 中
c->page = page;
stat(s, ALLOC_FROM_PARTIAL);
object = t;
} else {
// 第二次以及後面的迴圈就會走到這裡,目的是從 kmem_cache_node 的 partial 列表中
// 摘下 slub,然後填充進 kmem_cache_cpu 的 partial 列表裡
put_cpu_partial(s, page, 0);
stat(s, CPU_PARTIAL_NODE);
}
// 這裡是用於判斷是否繼續填充 kmem_cache_cpu 中的 partial 列表
// kmem_cache_has_cpu_partial 用於判斷 slab cache 是否設定了 cpu 快取的 partial 列表
// 設定了 CONFIG_SLUB_CPU_PARTIAL 選項意味著開啟 kmem_cache_cpu 中的 partial 列表,沒有設定的話, cpu 快取中就不會有 partial 列表
// kmem_cache_cpu 中快取被填充之後的空閒物件個數(包括 partial 列表)不能超過 ( kmem_cache 結構中 cpu_partial 指定的個數 / 2 )
if (!kmem_cache_has_cpu_partial(s)
|| available > slub_cpu_partial(s) / 2)
// kmem_cache_cpu 已經填充滿了,就退出迴圈,停止填充
break;
}
spin_unlock(&n->list_lock);
return object;
}
get_partial_node 函數通過遍歷 NUMA 節點快取結構 kmem_cache_node->partial 連結串列主要做兩件事情:
-
將第一個遍歷到的 slab 從 partial 連結串列中摘下,提升為本地 cpu 快取 kmem_cache_cpu->page。
-
繼續遍歷 partial 連結串列,後面遍歷到的 slab 會填充進本地 cpu 快取 kmem_cache_cpu->partial 連結串列中,直到當前 cpu 快取的所有空閒物件數目 available (既包括 kmem_cache_cpu->page 中的空閒物件也包括 kmem_cache_cpu->partial 連結串列中的空閒物件)超過了
kmem_cache->cpu_partial / 2的限制。
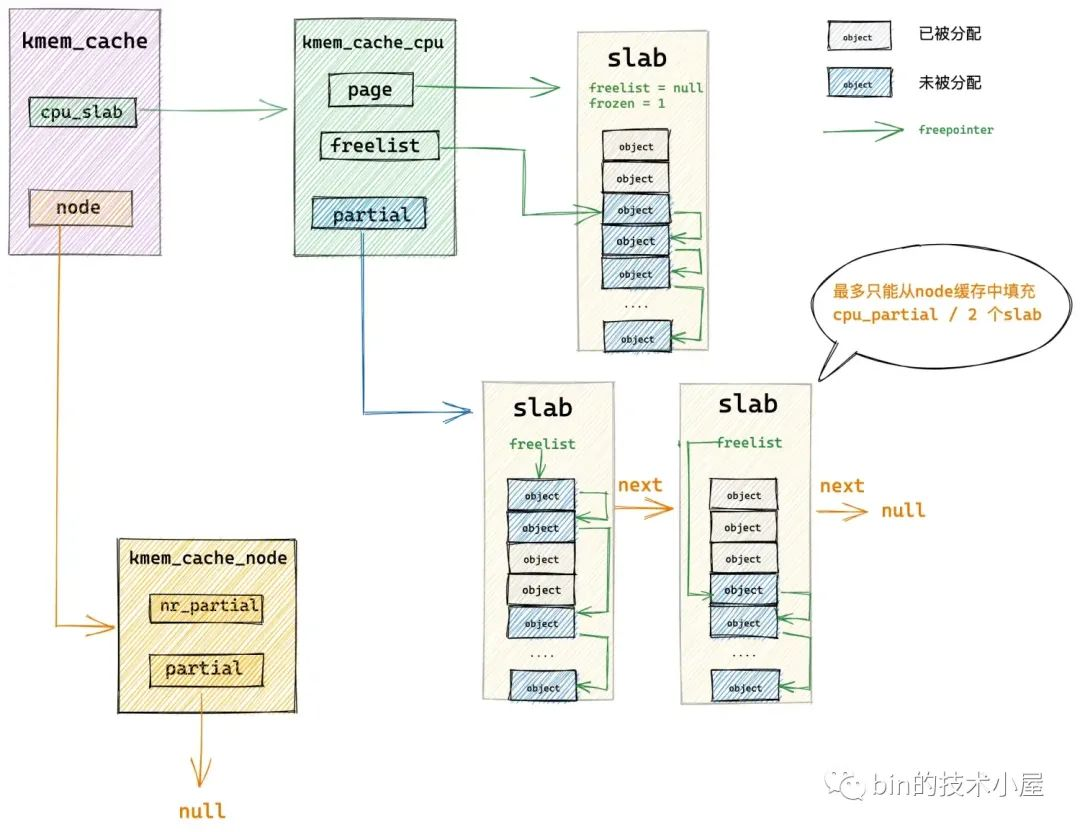
現在 slab cache 的本地 cpu 快取已經被填充好了,隨後核心會從 kmem_cache_cpu->freelist 中分配一個空閒物件出來給程序使用。
3.2.2 從 NUMA 節點快取 partial 連結串列中將 slab 摘下
// 從 kmem_cache_node 的 partial 列表中摘下一個 slub 分配物件
// 隨後將摘下的 slub 放入 cpu 本地快取 kmem_cache_cpu 中快取,後續分配物件直接就會 cpu 快取中分配
static inline void *acquire_slab(struct kmem_cache *s,
struct kmem_cache_node *n, struct page *page,
int mode, int *objects)
{
void *freelist;
unsigned long counters;
struct page new;
lockdep_assert_held(&n->list_lock);
// page 表示即將從 kmem_cache_node 的 partial 列表摘下的 slub
// 獲取 slub 中的空閒物件列表 freelist
freelist = page->freelist;
counters = page->counters;
new.counters = counters;
// objects 存放該 slub 中還剩多少空閒物件
*objects = new.objects - new.inuse;
// mode = true 表示將 slub 摘下之後填充到 kmem_cache_cpu 快取中
// mode = false 表示將 slub 摘下之後填充到 kmem_cache_cpu 快取的 partial 列表中
if (mode) {
new.inuse = page->objects;
new.freelist = NULL;
} else {
new.freelist = freelist;
}
// slub 放入 kmem_cache_cpu 之後需要凍結,其他 cpu 不能從這裡分配物件,只能釋放物件
new.frozen = 1;
// 更新 slub (page表示)中的 freelist 和 counters
if (!__cmpxchg_double_slab(s, page,
freelist, counters,
new.freelist, new.counters,
"acquire_slab"))
return NULL;
// 將 slub (page表示)從 kmem_cache_node 的 partial 列表上摘下
remove_partial(n, page);
// 返回 slub 中的空閒物件列表
return freelist;
}
3.3 從夥伴系統中重新申請 slab

假設 slab cache 當前的架構如上圖所示,本地 cpu 快取 kmem_cache_cpu->page 為空,kmem_cache_cpu->partial 為空,kmem_cache_node->partial 連結串列也為空,比如 slab cache 在剛剛被建立出來的時候就是這個架構。
在這種情況下,核心就需要通過 new_slab 函數到夥伴系統中申請一個新的 slab,填充到 slab cache 的本地 cpu 快取 kmem_cache_cpu->page 中。
static struct page *new_slab(struct kmem_cache *s, gfp_t flags, int node)
{
return allocate_slab(s,
flags & (GFP_RECLAIM_MASK | GFP_CONSTRAINT_MASK), node);
}
static struct page *allocate_slab(struct kmem_cache *s, gfp_t flags, int node)
{
// 用於指向從夥伴系統中申請到的記憶體頁
struct page *page;
// kmem_cache 結構的中的 kmem_cache_order_objects oo,表示該 slub 需要多少個記憶體頁,以及能夠容納多少個物件
// kmem_cache_order_objects 的高 16 位表示需要的記憶體頁個數,低 16 位表示能夠容納的物件個數
struct kmem_cache_order_objects oo = s->oo;
// 控制向夥伴系統申請記憶體的行為規範掩碼
gfp_t alloc_gfp;
void *start, *p, *next;
int idx;
bool shuffle;
// 向夥伴系統申請 oo 中規定的記憶體頁
page = alloc_slab_page(s, alloc_gfp, node, oo);
if (unlikely(!page)) {
// 如果夥伴系統無法滿足正常情況下 oo 指定的記憶體頁個數
// 那麼這裡再次嘗試用 min 中指定的記憶體頁個數向夥伴系統申請記憶體頁
// min 表示當記憶體不足或者記憶體碎片的原因無法滿足記憶體分配時,至少要保證容納一個物件所使用記憶體頁個數
oo = s->min;
alloc_gfp = flags;
// 再次向夥伴系統申請容納一個物件所需要的記憶體頁(降級)
page = alloc_slab_page(s, alloc_gfp, node, oo);
if (unlikely(!page))
// 如果記憶體還是不足,則走到 out 分支直接返回 null
goto out;
stat(s, ORDER_FALLBACK);
}
// 初始化 slub 對應的 struct page 結構中的屬性
// 獲取 slub 可以容納的物件個數
page->objects = oo_objects(oo);
// 將 slub cache 與 page 結構關聯
page->slab_cache = s;
// 將 PG_slab 標識設定到 struct page 的 flag 屬性中
// 表示該記憶體頁 page 被 slub 所管理
__SetPageSlab(page);
// 用 0xFC 填充 slub 中的記憶體,用於核心對記憶體存取越界檢查
kasan_poison_slab(page);
// 獲取記憶體頁對應的虛擬記憶體地址
start = page_address(page);
// 在設定了 CONFIG_SLAB_FREELIST_RANDOM 選項的情況下
// 會在 slub 的空閒物件中以隨機的順序初始化 freelist 列表
// 返回值 shuffle = true 表示隨機初始化 freelist,shuffle = false 表示按照正常的順序初始化 freelist
shuffle = shuffle_freelist(s, page);
// shuffle = false 則按照正常的順序來初始化 freelist
if (!shuffle) {
// 獲取 slub 第一個空閒物件的真正起始地址
// slub 可能設定了 SLAB_RED_ZONE,這樣會在 slub 物件記憶體空間兩側填充 red zone,防止記憶體存取越界
// 這裡需要跳過 red zone 獲取真正存放物件的記憶體地址
start = fixup_red_left(s, start);
// 填充物件的記憶體區域以及初始化空閒物件
start = setup_object(s, page, start);
// 用 slub 中的第一個空閒物件作為 freelist 的頭結點,而不是隨機的一個空閒物件
page->freelist = start;
// 從 slub 中的第一個空閒物件開始,按照正常的順序通過物件的 freepointer 串聯起 freelist
for (idx = 0, p = start; idx < page->objects - 1; idx++) {
// 獲取下一個物件的記憶體地址
next = p + s->size;
// 填充下一個物件的記憶體區域以及初始化
next = setup_object(s, page, next);
// 通過 p 的 freepointer 指標指向 next,設定 p 的下一個空閒物件為 next
set_freepointer(s, p, next);
// 通過迴圈遍歷,就把 slub 中的空閒物件按照正常順序串聯在 freelist 中了
p = next;
}
// freelist 中的尾結點的 freepointer 設定為 null
set_freepointer(s, p, NULL);
}
// slub 的初始狀態 inuse 的值為所有空閒物件個數
page->inuse = page->objects;
// slub 被建立出來之後,需要放入 cpu 本地快取 kmem_cache_cpu 中
page->frozen = 1;
out:
if (!page)
return NULL;
// 更新 page 所在 numa 節點在 slab cache 中的快取 kmem_cache_node 結構中的相關計數
// kmem_cache_node 中包含的 slub 個數加 1,包含的總物件個數加 page->objects
inc_slabs_node(s, page_to_nid(page), page->objects);
return page;
}
核心在向夥伴系統申請 slab 之前,需要知道一個 slab 具體需要多少個實體記憶體頁,而這些資訊定義在 struct kmem_cache 結構中的 oo 屬性中:
struct kmem_cache {
// 其中低 16 位表示一個 slab 中所包含的物件總數,高 16 位表示一個 slab 所佔有的記憶體頁個數。
struct kmem_cache_order_objects oo;
}
通過 oo 的高 16 位獲取 slab 需要的實體記憶體頁數,然後呼叫 alloc_pages 或者 __alloc_pages_node 向夥伴系統申請。

static inline struct page *alloc_slab_page(struct kmem_cache *s,
gfp_t flags, int node, struct kmem_cache_order_objects oo)
{
struct page *page;
unsigned int order = oo_order(oo);
if (node == NUMA_NO_NODE)
page = alloc_pages(flags, order);
else
page = __alloc_pages_node(node, flags, order);
return page;
}
關於 alloc_pages 函數分配實體記憶體頁的詳細過程,感興趣的讀者可以回看下 《深入理解 Linux 實體記憶體分配全鏈路實現》
如果當前 NUMA 節點中的空閒記憶體不足,或者由於記憶體碎片的原因導致夥伴系統無法滿足 slab 所需要的記憶體頁個數,導致分配失敗。
那麼核心會降級採用 kmem_cache->min 指定的尺寸,向夥伴系統申請只容納一個物件所需要的最小記憶體頁個數。
struct kmem_cache {
// 當按照 oo 的尺寸為 slab 申請記憶體時,如果記憶體緊張,會採用 min 的尺寸為 slab 申請記憶體,可以容納一個物件即可。
struct kmem_cache_order_objects min;
}
如果夥伴系統仍然無法滿足,那麼就只能跨 NUMA 節點分配了。如果成功地向夥伴系統申請到了 slab 所需要的記憶體頁 page。緊接著就會初始化 page 結構中與 slab 相關的屬性。
通過 kasan_poison_slab 函數將 slab 中的記憶體用 0xFC 填充,用於 kasan 對於記憶體越界相關的檢查。
// 定義在檔案:/mm/kasan/kasan.h
#define KASAN_KMALLOC_REDZONE 0xFC /* redzone inside slub object */
// 定義在檔案:/mm/kasan/common.c
void kasan_poison_slab(struct page *page)
{
unsigned long i;
// slub 可能包含多個記憶體頁 page,挨個遍歷這些 page
// 清除這些 page->flag 中的記憶體越界檢查標記
// 表示當存取到這些記憶體頁的時候臨時禁止記憶體越界檢查
for (i = 0; i < compound_nr(page); i++)
page_kasan_tag_reset(page + i);
// 用 0xFC 填充這些記憶體頁的記憶體,用於記憶體存取越界檢查
kasan_poison_shadow(page_address(page), page_size(page),
KASAN_KMALLOC_REDZONE);
}
最後會初始化 slab 中的 freelist 連結串列,將記憶體頁中的空閒記憶體塊通過 page->freelist 連結串列組織起來。
如果核心開啟了 CONFIG_SLAB_FREELIST_RANDOM 選項,那麼就會通過
shuffle_freelist 函數將記憶體頁中空閒的記憶體塊按照隨機的順序串聯在 page->freelist 中。
如果沒有開啟,則會在 if (!shuffle) 分支中,按照正常的順序初始化 page->freelist。
最後通過 inc_slabs_node 更新 NUMA 節點快取 kmem_cache_node 結構中的相關計數。
struct kmem_cache_node {
// slab 的個數
atomic_long_t nr_slabs;
// 該 node 節點中快取的所有 slab 中包含的物件總和
atomic_long_t total_objects;
};
static inline void inc_slabs_node(struct kmem_cache *s, int node, int objects)
{
// 獲取 page 所在 numa node 再 slab cache 中的快取
struct kmem_cache_node *n = get_node(s, node);
if (likely(n)) {
// kmem_cache_node 中的 slab 計數加1
atomic_long_inc(&n->nr_slabs);
// kmem_cache_node 中包含的總物件計數加 objects
atomic_long_add(objects, &n->total_objects);
}
}
4. 初始化 slab freelist 連結串列
核心在對 slab 中的 freelist 連結串列初始化的時候,會有兩種方式,一種是按照記憶體地址的順序,一個一個的通過物件 freepointer 指標順序串聯所有空閒物件。
另外一種則是通過隨機的方式,隨機獲取空閒物件,然後通過物件的 freepointer 指標將 slab 中的空閒物件按照隨機的順序串聯起來。

考慮到順序初始化 freelist 比較直觀,為了方便大家的理解,筆者先為大家介紹順序初始化的方式。
static struct page *allocate_slab(struct kmem_cache *s, gfp_t flags, int node)
{
// 獲取 slab 的起始記憶體地址
start = page_address(page);
// shuffle_freelist 隨機初始化 freelist 連結串列,返回 false 表示需要順序初始化 freelist
shuffle = shuffle_freelist(s, page);
// shuffle = false 則按照正常的順序來初始化 freelist
if (!shuffle) {
// 獲取 slub 第一個空閒物件的真正起始地址
// slub 可能設定了 SLAB_RED_ZONE,這樣會在 slub 物件記憶體空間兩側填充 red zone,防止記憶體存取越界
// 這裡需要跳過 red zone 獲取真正存放物件的記憶體地址
start = fixup_red_left(s, start);
// 填充物件的記憶體區域以及初始化空閒物件
start = setup_object(s, page, start);
// 用 slub 中的第一個空閒物件作為 freelist 的頭結點,而不是隨機的一個空閒物件
page->freelist = start;
// 從 slub 中的第一個空閒物件開始,按照正常的順序通過物件的 freepointer 串聯起 freelist
for (idx = 0, p = start; idx < page->objects - 1; idx++) {
// 獲取下一個物件的記憶體地址
next = p + s->size;
// 填充下一個物件的記憶體區域以及初始化
next = setup_object(s, page, next);
// 通過 p 的 freepointer 指標指向 next,設定 p 的下一個空閒物件為 next
set_freepointer(s, p, next);
// 通過迴圈遍歷,就把 slub 中的空閒物件按照正常順序串聯在 freelist 中了
p = next;
}
// freelist 中的尾結點的 freepointer 設定為 null
set_freepointer(s, p, NULL);
}
}
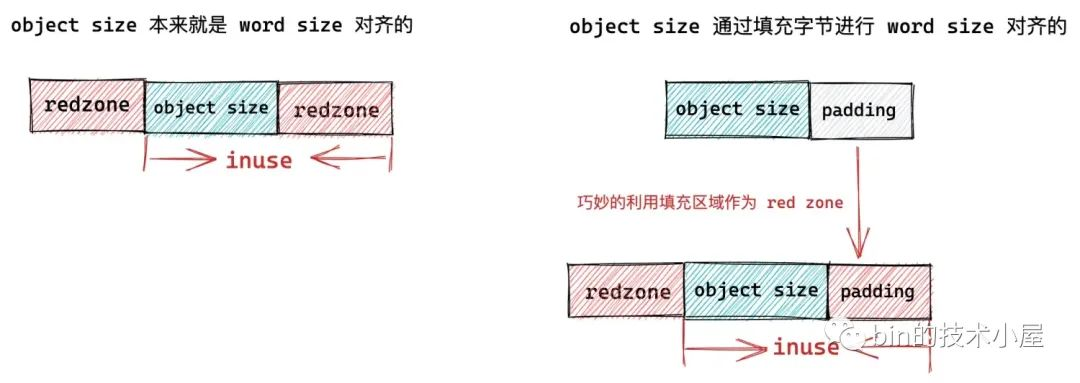
核心在順序初始化 slab 中的 freelist 之前,首先需要知道 slab 的起始記憶體地址 start,但是考慮到 slab 如果設定了 SLAB_RED_ZONE 的情況,那麼在 slab 物件左右兩側,核心均會插入兩段 red zone,為了防止記憶體存取越界。

所以在這種情況下,我們通過 page_address 獲取到的只是 slab 的起始記憶體地址,正是 slab 中第一個空閒物件的左側 red zone 的起始位置。
所以我們需要通過 fixup_red_left 方法來修正 start 位置,使其越過 slab 物件左側的 red zone,指向物件記憶體真正的起始位置,如上圖中所示。
void *fixup_red_left(struct kmem_cache *s, void *p)
{
// 如果 slub 設定了 SLAB_RED_ZONE,則意味著需要再 slub 物件記憶體空間兩側填充 red zone,防止記憶體存取越界
// 這裡需要跳過填充的 red zone 獲取真正的空閒物件起始地址
if (kmem_cache_debug(s) && s->flags & SLAB_RED_ZONE)
p += s->red_left_pad;
// 如果沒有設定 red zone,則直接返回物件的起始地址
return p;
}
當我們確定了物件的起始位置之後,物件所在的記憶體塊也就確定了,隨後呼叫 setup_object 函數來初始化記憶體塊,這裡會按照 slab 物件的記憶體佈局進行填充相應的區域。
slab 物件詳細的記憶體佈局介紹,可以回看下筆者之前的文章 《細節拉滿,80 張圖帶你一步一步推演 slab 記憶體池的設計與實現》 中的 「 5. 從一個簡單的記憶體頁開始聊 slab 」 小節。
當初始化完物件的記憶體區域之後,slab 中的 freelist 指標就會指向這第一個已經被初始化好的空閒物件。
page->freelist = start;
隨後通過 start + kmem_cache->size 順序獲取下一個空閒物件的起始地址,重複上述初始化物件過程。直到 slab 中的空閒物件全部串聯在 freelist 中,freelist 中的最後一個空閒物件 freepointer 指向 null。
一般來說,都會使用順序的初始化方式來初始化 freelist, 但出於安全因素的考慮,防止被攻擊,會設定 CONFIG_SLAB_FREELIST_RANDOM 選項,這樣就會使 slab 中的空閒物件以隨機的方式串聯在 freelist 中,無法預測。
在我們明白了 slab freelist 的順序初始化方式之後,隨機的初始化方式其實就很好理解了。
隨機初始化和順序初始化唯一不同的點在於,獲取空閒物件起始地址的方式不同:
-
順序初始化的方式是直接獲取 slab 中第一個空閒物件的地址,然後通過
start + kmem_cache->size按照順序一個一個地獲取後面物件地址。 -
隨機初始化的方式則是通過隨機的方式獲取 slab 中空閒物件,也就是說 freelist 中的頭結點可能是 slab 中的第一個物件,也可能是第三個物件。後續也是通過這種隨機的方式來獲取下一個隨機的空閒物件。
// 返回值為 true 表示隨機的初始化 freelist,false 表示採用第一個空閒物件初始化 freelist
static bool shuffle_freelist(struct kmem_cache *s, struct page *page)
{
// 指向第一個空閒物件
void *start;
void *cur;
void *next;
unsigned long idx, pos, page_limit, freelist_count;
// 如果沒有設定 CONFIG_SLAB_FREELIST_RANDOM 選項或者 slub 容納的物件個數小於 2
// 則無需對 freelist 進行隨機初始化
if (page->objects < 2 || !s->random_seq)
return false;
// 獲取 slub 中可以容納的物件個數
freelist_count = oo_objects(s->oo);
// 獲取用於隨機初始化 freelist 的隨機位置
pos = get_random_int() % freelist_count;
page_limit = page->objects * s->size;
// 獲取 slub 第一個空閒物件的真正起始地址
// slub 可能設定了 SLAB_RED_ZONE,這樣會在 slub 中物件記憶體空間兩側填充 red zone,防止記憶體存取越界
// 這裡需要跳過 red zone 獲取真正存放物件的記憶體地址
start = fixup_red_left(s, page_address(page));
// 根據隨機位置 pos 獲取第一個隨機物件的距離 start 的偏移 idx
// 返回第一個隨機物件的記憶體地址 cur = start + idx
cur = next_freelist_entry(s, page, &pos, start, page_limit,
freelist_count);
// 填充物件的記憶體區域以及初始化空閒物件
cur = setup_object(s, page, cur);
// 第一個隨機物件作為 freelist 的頭結點
page->freelist = cur;
// 以 cur 為頭結點隨機初始化 freelist(每一個空閒物件都是隨機的)
for (idx = 1; idx < page->objects; idx++) {
// 隨機獲取下一個空閒物件
next = next_freelist_entry(s, page, &pos, start, page_limit,
freelist_count);
// 填充物件的記憶體區域以及初始化空閒物件
next = setup_object(s, page, next);
// 設定 cur 的下一個空閒物件為 next
// next 物件的指標就是 freepointer,存放於 cur 物件的 s->offset 偏移處
set_freepointer(s, cur, next);
// 通過迴圈遍歷,就把 slub 中的空閒物件隨機的串聯在 freelist 中了
cur = next;
}
// freelist 中的尾結點的 freepointer 設定為 null
set_freepointer(s, cur, NULL);
// 表示隨機初始化 freelist
return true;
}
5. slab 物件的初始化

核心按照 kmem_cache->size 指定的尺寸,將實體記憶體頁中的記憶體劃分成一個一個的小記憶體塊,每一個小記憶體塊即是 slab 物件佔用的記憶體區域。setup_object 函數用於初始化這些記憶體區域,並對 slab 物件進行記憶體佈局。
static void *setup_object(struct kmem_cache *s, struct page *page,
void *object)
{
// 初始化物件的記憶體區域,填充相關的位元組,比如填充 red zone,以及 poison 物件
setup_object_debug(s, page, object);
object = kasan_init_slab_obj(s, object);
// 如果 kmem_cache 中設定了物件的建構函式 ctor,則用建構函式初始化物件
if (unlikely(s->ctor)) {
kasan_unpoison_object_data(s, object);
// 使用使用者指定的建構函式初始化物件
s->ctor(object);
// 在物件記憶體區域的開頭用 0xFC 填充一段 KASAN_SHADOW_SCALE_SIZE 大小的區域
// 用於對記憶體存取越界的檢查
kasan_poison_object_data(s, object);
}
return object;
}
// 定義在檔案:/mm/kasan/kasan.h
#define KASAN_KMALLOC_REDZONE 0xFC /* redzone inside slub object */
#define KASAN_SHADOW_SCALE_SIZE (1UL << KASAN_SHADOW_SCALE_SHIFT)
// 定義在檔案:/arch/x86/include/asm/kasan.h
#define KASAN_SHADOW_SCALE_SHIFT 3
void kasan_poison_object_data(struct kmem_cache *cache, void *object)
{
// 在物件記憶體區域的開頭用 0xFC 填充一段 KASAN_SHADOW_SCALE_SIZE 大小的區域
// 用於對記憶體存取越界的檢查
kasan_poison_shadow(object,
round_up(cache->object_size, KASAN_SHADOW_SCALE_SIZE),
KASAN_KMALLOC_REDZONE);
}
關於 slab 物件記憶體佈局的核心邏輯封裝在 setup_object_debug 函數中:
// 定義在檔案:/include/linux/poison.h
#define SLUB_RED_INACTIVE 0xbb
static void setup_object_debug(struct kmem_cache *s, struct page *page,
void *object)
{
// SLAB_STORE_USER:儲存最近存取該物件的 owner 資訊,方便 bug 追蹤
// SLAB_RED_ZONE:在 slub 中物件記憶體區域的前後填充分別填充一段 red zone 區域,防止記憶體存取越界
// __OBJECT_POISON:在物件記憶體區域中填充一些特定的字元,表示物件特定的狀態。比如:未被分配狀態
if (!(s->flags & (SLAB_STORE_USER|SLAB_RED_ZONE|__OBJECT_POISON)))
return;
// 初始化物件記憶體,比如填充 red zone,以及 poison
init_object(s, object, SLUB_RED_INACTIVE);
// 設定 SLAB_STORE_USER 起作用,初始化存取物件的所有者相關資訊
init_tracking(s, object);
}
init_object 函數主要針對 slab 物件的記憶體區域進行佈局,這裡包括對 red zone 的填充,以及 POISON 物件的 object size 區域。
// 定義在檔案:/include/linux/poison.h
#define SLUB_RED_INACTIVE 0xbb
// 定義在檔案:/include/linux/poison.h
#define POISON_FREE 0x6b /* for use-after-free poisoning */
#define POISON_END 0xa5 /* end-byte of poisoning */
static void init_object(struct kmem_cache *s, void *object, u8 val)
{
// p 為真正儲存物件的記憶體區域起始地址(不包含填充的 red zone)
u8 *p = object;
// red zone 位於真正儲存物件記憶體區域 object size 的左右兩側,分別有一段 red zone
if (s->flags & SLAB_RED_ZONE)
// 首先使用 0xbb 填充物件左側的 red zone
// 左側 red zone 區域為物件的起始地址到 s->red_left_pad 的長度
memset(p - s->red_left_pad, val, s->red_left_pad);
if (s->flags & __OBJECT_POISON) {
// 將物件的內容用 0x6b 填充,表示該物件在 slub 中還未被使用
memset(p, POISON_FREE, s->object_size - 1);
// 物件的最後一個位元組用 0xa5 填充,表示 POISON 的末尾
p[s->object_size - 1] = POISON_END;
}
// 在物件記憶體區域 object size 的右側繼續用 0xbb 填充右側 red zone
// 右側 red zone 的位置為:物件真實記憶體區域的末尾開始一個字長的區域
// s->object_size 表示物件本身的記憶體佔用,s->inuse 表示物件在 slub 管理體系下的真實記憶體佔用(包含填充位元組數)
// 通常會在物件記憶體區域末尾處填充一個字長大小的 red zone 區域
// 物件右側 red zone 區域後面緊跟著的就是 freepointer
if (s->flags & SLAB_RED_ZONE)
memset(p + s->object_size, val, s->inuse - s->object_size);
}
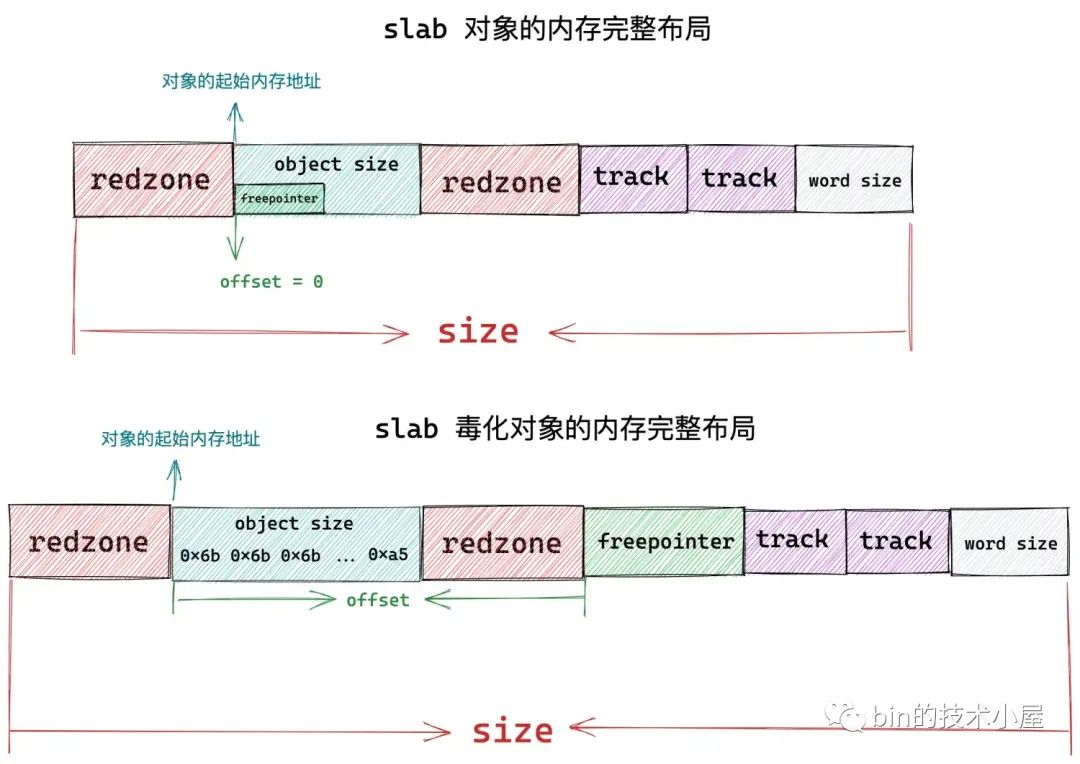
核心首先會用 0xbb 來填充物件左側 red zone,長度為 kmem_cache-> red_left_pad。
隨後核心會用 0x6b 填充 object size 記憶體區域,並用 0xa5 填充該區域的最後一個位元組。object size 記憶體區域正是真正儲存物件的區域。
最後用 0xbb 來填充物件右側 red zone,右側 red zone 的起始地址為:p + s->object_size,長度為:s->inuse - s->object_size。如下圖所示:
總結

本文我們基於 slab cache 的完整的架構,近一步深入到核心原始碼中詳細介紹了 slab cache 關於記憶體分配的完整流程:
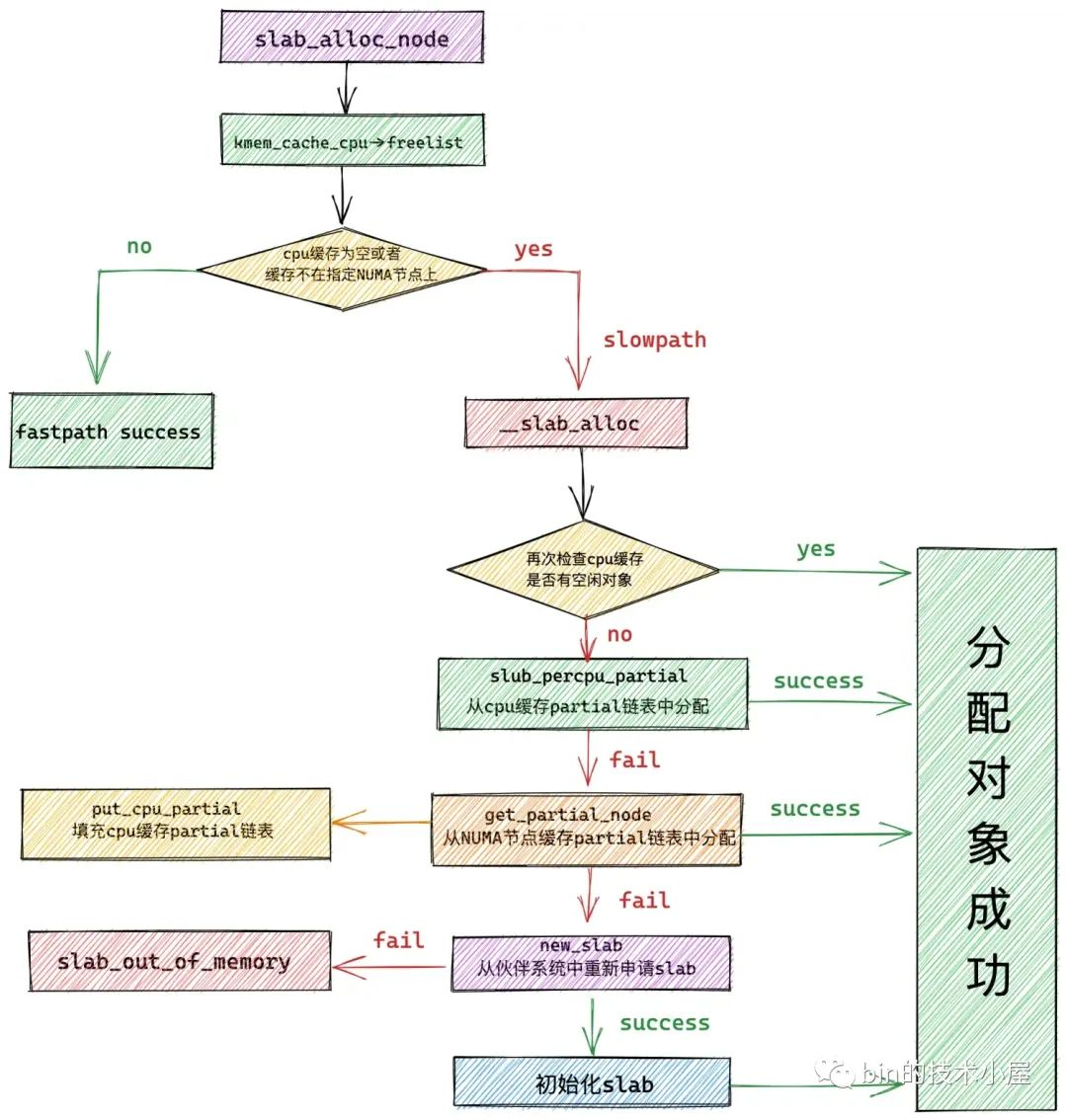
我們可以看到 slab cache 記憶體分配的整個流程分為 fastpath 快速路徑和 slowpath 慢速路徑。
其中在 fastpath 路徑下,核心會直接從 slab cache 的本地 cpu 快取中獲取記憶體塊,這是最快的一種方式。
在本地 cpu 快取沒有足夠的記憶體塊可供分配的時候,核心就進入到了 slowpath 路徑,而 slowpath 下又分為多種情況:
- 從本地 cpu 快取 partial 列表中分配
- 從 NUMA 節點快取中分配,其中涉及到了對本地 cpu 快取的填充。
- 從夥伴系統中重新申請 slab
最後我們介紹了 slab 所在記憶體頁的詳細初始化流程,其中包括了對 slab freelist 連結串列的初始化,以及 slab 物件的初始化。
好了本文的內容到這裡就結束了,感謝大家的收看,我們下篇文章見~~~