基於YOLOv5的目標檢測系統詳解(附MATLAB GUI版程式碼)

摘要:本文重點介紹了基於YOLOv5目標檢測系統的MATLAB實現,用於智慧檢測物體種類並記錄和儲存結果,對各種物體檢測結果視覺化,提高目標識別的便捷性和準確性。本文詳細闡述了目標檢測系統的原理,並給出MATLAB的實現程式碼、預訓練模型,以及GUI介面設計。基於YOLOv5目標檢測演演算法,在介面中可以選擇各種圖片、資料夾、視訊進行檢測識別。博文提供了完整的MATLAB程式碼和使用教學,適合新入門的朋友參考,完整程式碼資原始檔請轉至文末的下載連結。
完整程式碼下載:https://mbd.pub/o/bread/mbd-ZJiYmphw
參考視訊演示:https://www.bilibili.com/video/BV1ro4y1w75j/
1. 引言
撰寫這篇部落格的初衷是分享YOLOv5目標檢測演演算法的實現與應用,為大家提供實踐指南。感謝粉絲們的支援。這裡我非常鼓勵讀者深入理解背後原理,發揮創造力,進行探索與嘗試,而不是簡單地套用現成的解決方案。期待在未來的技術交流中,共同進步與成長。本部落格內容為博主原創,相關參照和參考文獻我已在文中標註,考慮到可能會有相關研究人員蒞臨指導,博主的部落格這裡儘可能以學術期刊的格式撰寫,如需參考可參照本部落格格式如下:
[1] 思緒無限. 基於YOLOv5的目標檢測系統詳解[J/OL]. CSDN, 2023.05. https://wuxian.blog.csdn.net/article/details/130472314.
[2] Wu, S. (2023, May). A Comprehensive Guide to Object Detection System Based on YOLOv5 [J/OL]. CSDN. https://wuxian.blog.csdn.net/article/details/130472314.
目標檢測作為計算機視覺領域的一個重要研究方向,旨在從影象或視訊中檢測並識別特定物體(Ren et al., 2015)[1]。近年來,隨著深度學習技術的發展,折積神經網路(CNN)在目標檢測領域取得了顯著成果。R-CNN(Girshick et al., 2014)[2]是第一個將折積神經網路應用於目標檢測的方法,該方法首先使用選擇性搜尋生成物體候選框,然後使用CNN對候選框進行特徵提取,最後通過支援向量機進行分類。R-CNN相較於傳統方法在目標檢測任務上取得了較好的效能,但計算速度較慢,無法實現實時檢測。
為解決R-CNN速度問題,Girshick提出了Fast R-CNN(Girshick, 2015)[3]。Fast R-CNN通過引入RoI池化層,將物體候選框的特徵提取與分類進行聯合訓練,大幅提高了檢測速度。然而,Fast R-CNN仍依賴於選擇性搜尋生成物體候選框,導致檢測速度仍有待提升。Faster R-CNN(Ren et al., 2015)[1]進一步改進了Fast R-CNN,通過引入區域提議網路(RPN),實現了物體候選框生成與特徵提取的端到端學習。Faster R-CNN在保持較高精度的同時,取得了更快的檢測速度。SSD(Liu et al., 2016)[4]是另一個流行的目標檢測方法,通過在不同尺度的特徵圖上進行檢測,實現了對不同尺度物體的高效檢測。SSD在速度與精度上達到了較好的平衡,但在小物體檢測上效能略遜於Faster R-CNN。
YOLO(You Only Look Once,Redmon et al., 2016)[5]系列演演算法憑藉其實時性和準確性在目標檢測領域受到廣泛關注。YOLO將目標檢測任務視為迴歸問題,通過單次前向傳播實現目標的位置與類別預測。YOLOv2(Redmon and Farhadi, 2017)[8]通過改進網路結構與訓練策略,在保持實時性的同時進一步提高了檢測精度。YOLOv3(Redmon 和 Farhadi, 2018)[9]採用了多尺度特徵融合,引入了類別與物體性(objectness)分離的策略,提高了小物體檢測效能。YOLOv4(Bochkovskiy et al., 2020)[7]在YOLOv3的基礎上,融合了多種最新的目標檢測技術,如CSPNet、PANet和SPP,進一步提高了檢測精度與速度。YOLOv5(Bochkovskiy et al., 2020)[6]作為最新版本,在YOLOv4的基礎上進行了架構優化,實現了更高的精度與更快的速度。
雖然目前已經有許多基於YOLOv5的目標檢測應用,但多數針對特定領域,缺乏統一、易用的介面。因此,本部落格將介紹一種基於YOLOv5的目標檢測系統,使用MATLAB實現,並提供圖形化使用者介面(GUI)以便於使用者進行互動操作。本部落格的貢獻點如下:
- 提供了一個基於YOLOv5的通用目標檢測系統,支援不同領域的目標檢測任務;
- 詳細介紹了MATLAB實現的原理,包括預處理、模型載入、預測、結果視覺化等;
- 提供了一個易用的GUI介面,支援圖片檢測、批次檢測、視訊檢測以及呼叫攝像頭檢測;
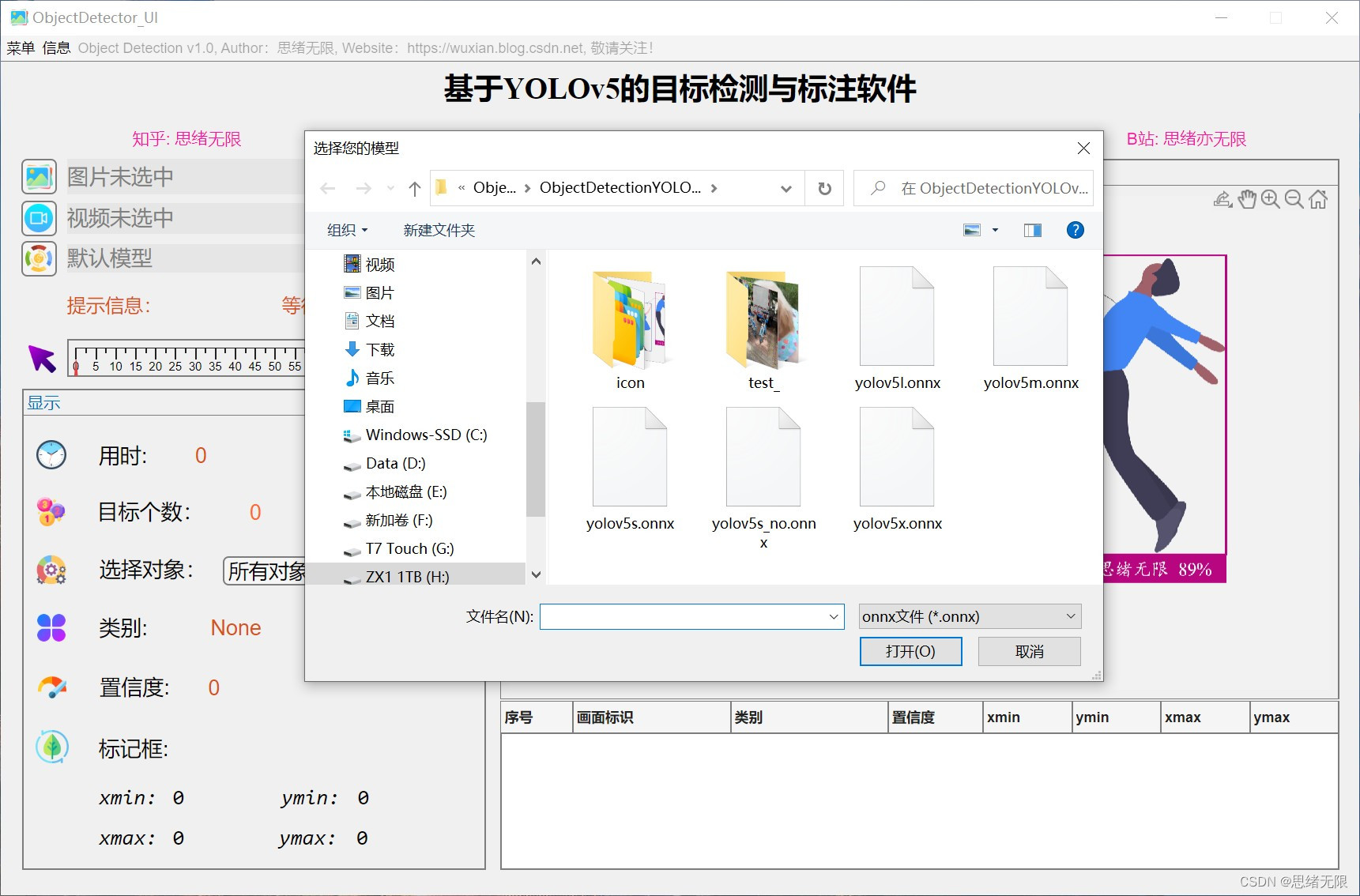
- 允許使用者更換不同的網路模型,以滿足不同任務的需求;
- 結果視覺化方面,通過介面直觀顯示檢測結果,便於使用者分析。
2. 系統介面演示效果
本節將介紹基於YOLOv5的目標檢測系統的圖形化使用者介面(GUI)功能及演示效果。
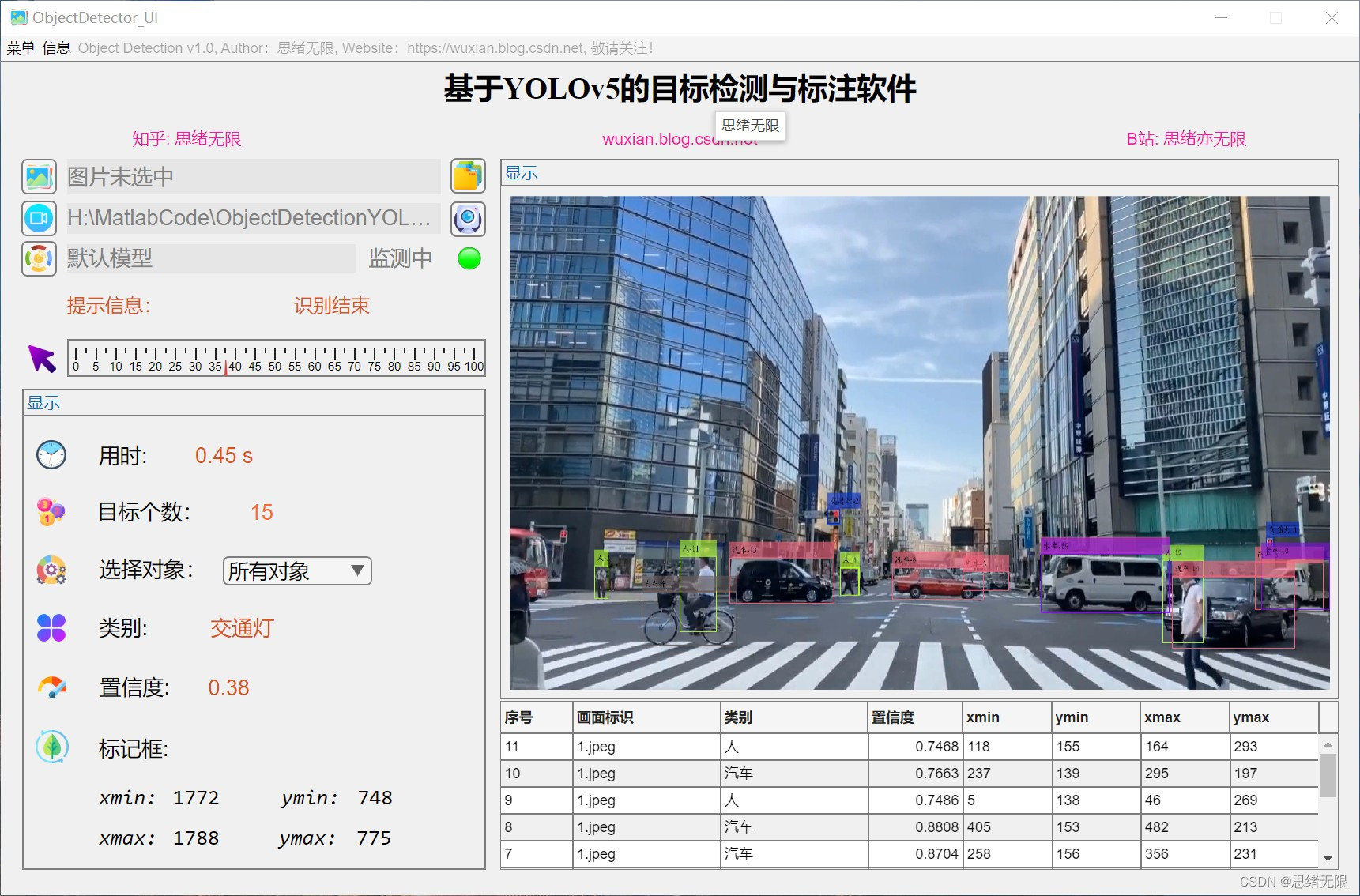
(1)選擇圖片檢測:使用者可以通過檔案選擇對話方塊選擇一張圖片進行目標檢測。系統會自動將圖片調整為合適的尺寸,並將結果顯示在GUI介面上。結果包括物體的類別、置信度以及邊界框。
(2)選擇資料夾批次檢測:使用者可以選擇一個資料夾進行批次檢測。系統會自動處理資料夾中的所有圖片,並將檢測結果記錄在下方的表格中。輸出結果包括帶有邊界框和類別標籤的圖片。

(3)選擇視訊檢測:使用者可以選擇一個視訊檔進行目標檢測。系統會對視訊中的每一幀影象進行目標檢測,並將檢測結果實時顯示在GUI介面上。同時,使用者可以選擇將檢測結果儲存為視訊檔。
(4)呼叫攝像頭檢測:使用者可以使用系統內建的攝像頭進行實時目標檢測。系統會捕捉攝像頭的視訊流,並對每一幀影象進行目標檢測。檢測結果將實時顯示在GUI介面上。

(5)更換不同網路模型:系統支援使用者更換不同的YOLOv5網路模型。使用者可以根據自己的需求,選擇合適的模型進行檢測。不同的模型在精度和速度上可能存在差異。
(6)通過介面顯示結果和視覺化:系統的GUI介面提供了直觀的結果展示和視覺化功能。使用者可以清晰地檢視檢測到的物體、邊界框、類別以及置信度。

3. 檢測過程程式碼
首先,建立一個名為Detector_YOLOv5的類,它封裝了執行目標檢測的所有方法。以下是類的主要組成部分:
屬性(Properties):類的屬性定義了檢測器所需的資訊,例如類別名稱(COCO資料集中的80個類別)、權重檔案、置信度閾值、非極大值抑制(NMS)閾值和各類別的顏色;方法(Methods):類的方法定義了實現目標檢測的功能。建構函式(Detector_YOLOv5)在初始化時載入預訓練的YOLOv5模型。detect方法對給定的影象執行目標檢測,程式碼還包括一些常數屬性。
classdef Detector_YOLOv5 <handle
properties
cocoNames = {'person'; 'bicycle'; 'car'; 'motorbike'; 'aeroplane';'bus';...
'train'; 'truck'; 'boat'; 'traffic light'; 'fire hydrant'; ...
'stop sign'; 'parking meter'; 'bench'; 'bird'; 'cat'; 'dog';...
'horse'; 'sheep'; 'cow'; 'elephant'; 'bear'; 'zebra'; ...
'giraffe'; 'backpack'; 'umbrella'; 'handbag'; 'tie'; ...
'suitcase'; 'frisbee'; 'skis'; 'snowboard'; 'sports ball'; ...
'kite'; 'baseball bat'; 'baseball glove'; 'skateboard'; ...
'surfboard'; 'tennis racket'; 'bottle'; 'wine glass'; ...
'cup'; 'fork'; 'knife'; 'spoon'; 'bowl'; 'banana'; ...
'apple'; 'sandwich'; 'orange'; 'broccoli'; 'carrot';...
'hot dog'; 'pizza'; 'donut'; 'cake'; 'chair'; 'sofa'; ...
'pottedplant'; 'bed'; 'diningtable'; 'toilet'; ...
'tvmonitor'; 'laptop'; 'mouse'; 'remote'; ...
'keyboard'; 'cell phone'; 'microwave'; 'oven'; ...
'toaster'; 'sink'; 'refrigerator'; 'book'; 'clock';...
'vase'; 'scissors'; 'teddy bear'; 'hair drier'; 'toothbrush'
} ;
cocoNames_Chinese = {'人';'自行車'; '汽車'; '摩托車'; '飛機'; '公共汽車'; '火車'; ...
'卡車'; '船'; '交通燈'; '消防栓'; '停車標誌'; '停車收費表'; ...
'長凳'; '鳥'; '貓'; '狗'; '馬'; '羊'; '牛'; '大象'; '熊'; ...
'斑馬'; '長頸鹿'; '揹包'; '手提包'; '領帶'; '手提箱'; '飛盤'; ...
'飛盤'; '雪橇'; '單板滑雪板'; '運動球'; '風箏'; '棒球棒'; ...
'棒球手套'; '滑板'; '衝浪板'; '網球拍'; '瓶子'; '酒杯'; '杯子'; ...
'叉'; '刀'; '勺子'; '碗'; '香蕉'; '蘋果'; '三明治'; '橙子'; ...
'西蘭花'; '胡蘿蔔'; '熱狗'; '披薩'; '甜甜圈'; '蛋糕'; '椅子'; ...
'沙發'; '盆栽植物'; '床'; '餐桌'; '馬桶'; '電視'; '筆記型電腦'; ...
'滑鼠'; '遙控器'; '鍵盤'; '手機'; '微波爐'; '烤箱'; '烤麵包機'; ...
'水槽'; '冰箱'; '書'; '時鐘'; '花瓶'; '剪刀'; '泰迪熊'; '吹風機'; ...
'牙刷'}
class_names = [];
weights = [];
throushHold = 0.3; % 閾值
nmsThroushHold = 0.5; % nms閾值
colors = []; % 各類別顏色
end
properties(Constant)
input_size = [640,640]; % 輸入尺寸
website = {'CSDN: https://wuxian.blog.csdn.net/';
'Bilibili: https://space.bilibili.com/456667721';
'Zhihu: https://www.zhihu.com/people/sixuwuxian';
'CnBlog: https://www.cnblogs.com/sixuwuxian/'};
author = '思緒無限';
wechat = '公眾號:AI技術研究與分享';
end
end
接下來,詳細介紹detect方法的實現:
- 影象預處理:輸入影象被調整為YOLOv5所需的尺寸(例如,640x640畫素),然後將其歸一化並調整維度以適應模型輸入要求。
- 模型推理:將預處理後的影象傳遞給networks_yolov5sfcn函數,該函數使用預訓練的YOLOv5模型計算預測結果。
- 後處理:根據預設的置信度閾值篩選預測結果。使用非極大值抑制(NMS)來合併重疊的邊界框。
- 結果輸出:將預測結果(邊界框、分數和類別標籤)返回給呼叫者。
methods % 方法塊開始
%建構函式,特點也是和類同名
function obj = Detector_YOLOv5(model, model_fcn)
if nargin == 2
% 匯入模型
obj.colors = randi(255, length(obj.cocoNames),3);
obj.weights = importONNXFunction(model, model_fcn);
obj.class_names = categorical(obj.cocoNames_Chinese); % 類別標籤
end
end
% 成員方法,執行預測
function [bboxes, scores, labels] = detect(obj, image)
% 使用YOLOv5進行預測
% 預處理影象
[H,W,~] = size(image);
image = imresize(image, obj.input_size);
image = rescale(image, 0, 1);% 轉換到[0,1]
image = permute(image,[3,1,2]);
image = dlarray(reshape(image,[1,size(image)])); % n*c*h*w,[0,1],RGB順序
if canUseGPU()
image = gpuArray(image);
end
% 模型推理
[labels, bboxes] = networks_yolov5sfcn(image, obj.weights,...
'Training',false,...
'InputDataPermutation','none',...
'OutputDataPermutation','none');
% 後處理: 閾值過濾+NMS
if canUseGPU()
labels = gather(extractdata(labels));
bboxes = gather(extractdata(bboxes));
end
[maxvalue,idxs] = max(labels,[],2);
validIdxs = maxvalue>obj.throushHold;
% nms
indexes = idxs(validIdxs);
predictBoxes = bboxes(validIdxs,:);
predictScores = maxvalue(validIdxs);
predictNames = obj.class_names(indexes);
predictBboxes = [predictBoxes(:,1)*W-predictBoxes(:,3)*W/2,...
predictBoxes(:,2)*H- predictBoxes(:,4)*H/2,...
predictBoxes(:,3)*W,...
predictBoxes(:,4)*H];
% 結果輸出
[bboxes,scores,labels] = selectStrongestBboxMulticlass(predictBboxes,...
predictScores,...
predictNames,...
'RatioType','Min',...
'OverlapThreshold', obj.nmsThroushHold);
end
end % 方法塊結束
這裡給出如何使用Detector_YOLOv5類對影象進行目標檢測。首先載入模型,然後建立檢測器範例。接著,讀取影象,執行檢測並視覺化結果(在影象上繪製邊界框、類別標籤和置信度)。最後,將標註後的影象儲存到檔案。這裡講解如何使用已經訓練好的YOLOv5 ONNX模型進行目標檢測。首先載入模型並建立檢測器範例:
model = './yolov5s_no.onnx'; % 模型位置
yolov5 = Detector_YOLOv5(model, 'networks_yolov5sfcn');
首先,定義模型檔案的路徑,這裡使用了預訓練好的YOLOv5 ONNX模型。接著,利用Detector_YOLOv5類建立一個檢測器範例。networks_yolov5sfcn是一個MATLAB匯入的ONNX模型的函數,用於實現YOLOv5模型的前向傳播。下面讀取待檢測的影象:
image_path = './test_/000328.jpg';
image = imread(image_path);
指定待檢測影象的路徑,並使用imread函數讀取影象。使用檢測器進行目標檢測:
tic
[bboxes, scores, labels] = yolov5.detect(image)
fprintf('預測時間: %0.2f s',toc);

呼叫detect方法對讀取的影象進行目標檢測。detect方法返回三個輸出:邊界框(bboxes)、置信度得分(scores)和類別標籤(labels)。同時,使用tic和toc函數計算檢測所需的時間。繪製檢測結果並儲存標註後的影象:
annotations = string(labels) + ": " + string(round(scores*100)) + '%';
[~, ids] = ismember(labels, classesNames);
labelColors = colors(ids,:);
labeled_image = insertObjectAnnotation(image,'rectangle',bboxes,...
cellstr(annotations),...
'Font','華文楷體', ...
'FontSize', 18, ...
'color', labelColors,...
'LineWidth',2);
imshow(labeled_image);
imwrite(labeled_image, 'labeled_image.png'); % 儲存標記的圖片

將檢測結果(類別標籤、置信度得分和邊界框)新增到影象上。首先,為每個檢測到的目標生成一個包含類別標籤和置信度的字串(annotations)。然後,根據類別標籤確定對應的顏色。接著,使用insertObjectAnnotation函數將檢測結果繪製到影象上,並使用imshow函數顯示標註後的影象。最後,使用imwrite函數將標註後的影象儲存到檔案。
4. 系統實現
本節將詳細介紹基於YOLOv5的目標檢測系統的設計框架和實現方法。系統主要分為兩個部分:預測部分和圖形化使用者介面(GUI)部分。預測部分主要包括圖片、資料夾分類、模型更換等功能。GUI部分則包含各種操作按鈕和視覺化結果展示。在設計GUI介面時,需要考慮如下幾個方面:
- 介面佈局:設計一個清晰、易於使用的介面佈局,便於使用者進行各種操作。
- 功能實現:實現使用者在介面上執行的各種操作,例如選擇圖片、資料夾分類、模型更換等。
- 視覺化結果展示:將檢測結果以圖形或文字的形式展示在介面上,便於使用者檢視和分析。
基於以上要求,可以設計一個包含以下功能的GUI介面:
- 選擇圖片檢測:使用者可以通過點選按鈕選擇一張圖片進行目標檢測。
- 選擇資料夾批次檢測:使用者可以選擇一個資料夾,對資料夾中的所有圖片進行目標檢測。
- 選擇視訊檢測:使用者可以選擇一個視訊檔,對視訊中的每一幀進行目標檢測。 呼叫攝像頭檢測:使用者可以使用攝像頭實時進行目標檢測。
- 更換不同網路模型:使用者可以在多個預訓練模型之間進行切換,以滿足不同場景的需求。
- 通過介面顯示結果和視覺化:將檢測結果以圖形或文字的形式展示在介面上。
為了實現上述功能,可以使用MATLAB的App Designer工具來建立GUI介面。App Designer是一個基於MATLAB語言的互動式開發環境,可以方便地設計和建立具有各種功能的圖形化使用者介面。以下是使用App Designer建立的基於YOLOv5的目標檢測系統的GUI介面實現步驟:

開啟MATLAB,選擇App Designer工具建立一個新的專案。
- 在設計介面中新增各種元件,例如按鈕、文字方塊、影象框等。設定元件的屬性和樣式,以滿足介面設計要求。
- 編寫各個元件的回撥函數,實現相應的功能。例如,點選「選擇圖片檢測」按鈕時,彈出檔案選擇對話方塊,讓使用者選擇一張圖片進行檢測;點選「呼叫攝像頭檢測」按鈕時,啟動攝像頭並實時顯示檢測結果。
- 在回撥函數中呼叫YOLOv5目標檢測演演算法,獲取檢測結果,並將結果顯示在介面上。例如,將檢測到的目標用矩形框標記,並在影象框中顯示;將檢測到的目標類別和置信度以文字的形式顯示在文字方塊中。
- 根據需要,新增其他功能和元件,例如模型切換功能。在介面中新增一個下拉式選單,列出可用的預訓練模型。當用戶在下拉式選單中選擇一個模型時,更新回撥函數中的模型引數,以使用新的模型進行檢測。
- 完成介面設計和功能實現後,儲存並執行專案。在執行介面中測試各個功能,確保功能正常執行並滿足需求。
對於需要進一步優化的功能,可以在App Designer的程式碼檢視中進行修改和調整。例如,優化檢測演演算法的效能,提高實時檢測的影格率;調整介面佈局,使其更美觀易用。

通過以上步驟,可以實現一個基於YOLOv5的目標檢測系統的GUI介面。使用者可以通過介面方便地選擇圖片、資料夾或視訊進行目標檢測,並在介面上檢視和分析檢測結果。同時,使用者還可以根據不同場景的需求,切換不同的預訓練模型進行檢測。
5. 結果分析和優化建議
在本節中,將對YOLOv5目標檢測演演算法的檢測結果進行分析,並提出一些建議以優化其效能。
結果分析:通過使用預訓練的YOLOv5模型進行目標檢測,可以觀察到以下特點
- 檢測速度:YOLOv5具有較快的檢測速度,這對於實時應用非常重要。尤其是在GPU加速的情況下,檢測速度可以達到實時水平。
- 準確性:YOLOv5的檢測準確性相對較高,可以在各種場景中準確檢測出目標物體。然而,在一些複雜場景中,例如目標遮擋、小目標和低解析度情況下,檢測效能可能會受到影響。
- 通用性:YOLOv5能夠檢測多達80個類別的目標,具有較高的通用性。然而,對於一些特定的應用場景,可能需要在特定的資料集上進行微調,以提高檢測效能。
針對YOLOv5目標檢測演演算法的特點,提出以下優化建議:
模型微調:為了提高YOLOv5在特定應用場景的檢測效能,可以在相關資料集上對模型進行微調。通過在有限的訓練資料上進行微調,模型可以更好地適應新的場景,從而提高檢測準確性。
資料增強:在訓練過程中,使用資料增強技術可以提高模型的泛化能力。例如,可以使用影象旋轉、縮放、翻轉、裁剪等方法擴充訓練集。資料增強有助於模型學習到更多的特徵,提高檢測效能。
模型融合:在一些複雜場景下,可以考慮將多個檢測模型進行融合,以提高檢測準確性。例如,可以將YOLOv5與其他目標檢測演演算法(如Faster R-CNN、SSD等)進行融合,綜合利用各自的優勢,提高整體檢測效能。
多尺度檢測:針對不同尺寸的目標,可以考慮使用多尺度檢測策略。通過將輸入影象調整到不同的尺寸,可以在不同的尺度上進行目標檢測,從而提高檢測準確性。
根據實際應用場景的需求,可以對YOLOv5進行一定程度的調整以滿足特定場景的要求:
自定義類別:根據實際應用需求,可以對YOLOv5進行修改,以檢測特定類別的目標。這需要重新訓練模型,使其能夠識別和檢測自定義類別的物體。
減小模型規模:為了適應邊緣裝置(如移動裝置、嵌入式裝置等)上的計算能力限制,可以考慮減小YOLOv5模型的規模。通過降低模型的層數、通道數等引數,可以降低模型的計算複雜度,提高在邊緣裝置上的執行速度。需要注意的是,這可能會對檢測效能產生一定影響。
模型壓縮和優化:為了進一步提高模型在邊緣裝置上的執行速度和記憶體佔用,可以採用模型壓縮和優化技術,如模型剪枝、模型量化等。這些方法可以降低模型的計算複雜度和記憶體佔用,提高執行速度,但可能對檢測效能產生一定影響。
實時檢測優化:在進行實時目標檢測時,可以考慮採用滑動視窗、跟蹤等技術,減少重複檢測區域,提高檢測速度。此外,還可以結合場景資訊,對感興趣區域進行優先檢測,從而提高檢測效率。
下載連結
若您想獲得博文中涉及的實現完整全部程式檔案(包括測試圖片、視訊,mlx, mlapp檔案等,如下圖),這裡已打包上傳至博主的麵包多平臺,見可參考部落格與視訊,已將所有涉及的檔案同時打包到裡面,點選即可執行,完整檔案截圖如下:

在資料夾下的資源顯示如下圖所示:

注意:該程式碼採用MATLAB R2022a開發,經過測試能成功執行,執行介面的主程式為Detector_UI.mlapp,測試視訊指令碼可執行test_yolov5_video.py,測試攝像頭指令碼可執行test_yolov5_camera.mlx。為確保程式順利執行,請使用MATLAB2022a執行並在「附加功能管理器」(MATLAB的上方選單欄->主頁->附加功能->管理附加功能)中新增有以下工具。

完整資源中包含資料集及訓練程式碼,環境設定與介面中文字、圖片、logo等的修改方法請見視訊,專案完整檔案下載請見參考部落格文章裡面,或參考視訊的簡介處給出:➷➷➷
完整程式碼下載:https://mbd.pub/o/bread/mbd-ZJiYmphw
參考視訊演示:https://www.bilibili.com/video/BV1ro4y1w75j/
6. 總結與展望
本文詳細介紹了YOLOv5目標檢測演演算法的原理、網路結構及其在實際應用中的優化方法。YOLOv5作為一個高效、實時的目標檢測演演算法,在各種場景中都表現出較好的效能。首先介紹了YOLOv5的背景知識,包括YOLO系列演演算法的發展歷程和YOLOv5相較於前代演演算法的改進。接著,詳細闡述了YOLOv5的網路結構和損失函數設計,並通過實際程式碼實現展示瞭如何使用YOLOv5進行目標檢測。最後,討論了針對實際應用場景的優化方法,以提高YOLOv5在各種場景中的目標檢測能力。總的來說,YOLOv5是一個值得學習和應用的目標檢測演演算法。通過對其進行一定程度的調整和優化,可以使其更好地滿足實際應用場景的需求,提高目標檢測的效果和效率。
結束語
由於博主能力有限,博文中提及的方法即使經過試驗,也難免會有疏漏之處。希望您能熱心指出其中的錯誤,以便下次修改時能以一個更完美更嚴謹的樣子,呈現在大家面前。同時如果有更好的實現方法也請您不吝賜教。
參考文獻
[1] Ren, S., He, K., Girshick, R., & Sun, J. (2015). Faster R-CNN: Towards real-time object detection with region proposal networks. Advances in Neural Information Processing Systems, 28, 91-99.
[2] Girshick, R., Donahue, J., Darrell, T., & Malik, J. (2014). Rich feature hierarchies for accurate object detection and semantic segmentation. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 580-587.
[3] Girshick, R. (2015). Fast R-CNN. Proceedings of the IEEE International Conference on Computer Vision, 1440-1448.
[4] Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C. Y., & Berg, A. C. (2016). SSD: Single shot multibox detector. European Conference on Computer Vision, 9905, 21-37.
[5] Redmon, J., Divvala, S., Girshick, R., & Farhadi, A. (2016). You only look once: Unified, real-time object detection. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 779-788.
[6] Bochkovskiy, A., Wang, C. Y., & Liao, H. Y. M. (2020). YOLOv5: An improved real-time object detection model. arXiv preprint arXiv:2006.05983.
[7] Bochkovskiy, A., Wang, C. Y., & Liao, H. Y. M. (2020). YOLOv4: Optimal speed and accuracy of object detection. arXiv preprint arXiv:2004.10934.
[8] Redmon, J., & Farhadi, A. (2017). YOLO9000: Better, faster, stronger. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 7263-7271.
[9] Redmon, J., & Farhadi, A. (2018). YOLOv3: An incremental improvement. arXiv preprint arXiv:1804.02767.