京東物流常態化壓測實踐
作者:京東物流 王江波
一、常態化壓測建設目的
為什麼做常態化壓測?
目前面臨主要問題,效能問題滯後發現,給大促帶來不可控風險。目前日常需求頻繁迭代,系統設定的變更、上下游依賴的變化、伺服器資源置換等諸多因素均會對系統效能產生一定影響;日常很難做到對所有新專案或需求上線前後都進行壓測,這就往往導致了很多效能問題推遲到大促壓測期間才被發現。
大促備戰壓測備戰時間緊、任務多,壓測備戰壓力較大, 在11.11覆盤中,有些部門工時統計中,壓測佔了較大一部分工作量。而且效能問題相較於其他問題,優化難度大、修復週期長,在大促備戰多專項並行資源緊張情況下,頻繁的系統調優給整個大促帶來不可控的風險因素。
基於此,引入常態化壓測的手段,通過每週或每月的定期壓測行為,持續把控系統效能表現,保證服務穩定性;同時將需求上線引起的效能問題前置暴露,及時定位優化問題;減輕備戰壓力,提升壓測效率。
二、常態化壓測實施流程
2.1 常態化壓測
常態化壓測是按照一定週期或特定觸發條件而進行的自動化壓測行為,通過在單容器/叢集的週期性壓測,從而達到監控效能指標變動、及時發現服務效能衰減風險的目標。
2.2 實施策略
通過三步走的方式,由淺入深,逐步在平臺技術部落地常態化壓測:
第一步 單機試點: 由於初次使用常態化壓測,通過隔離單機環境的方式,瞭解了常態化壓測的壓測思路、執行流程、壓測平臺能力支援及風險點摸排;
第二步 叢集試點:在履約、基礎平臺選擇星級核心服務, 線上上環境試點小叢集(2-3臺)常態化壓測任務執行,從線上業務影響、上下游依賴影響、壓測平臺能力支援、線上壓測風險管控等多方面評估常態化壓測線上上叢集落地的可行性;
第三步 全面展開: 根據履約、基礎平臺的線上常態化壓測叢集實踐,推廣至全平臺技術部,並結合Kit壓測工具,建立核心服務效能資料看板,統計彙總壓測結果效能報表,使服務效能趨勢視覺化展現;開通大促壓測綠色通道,常態化壓測達標的服務,大促壓測綠通。
2.3 實施流程
常態化壓測介面:優先選擇覆蓋業務主流程的核心介面,ops-review的核心服務中星級認證的介面。
壓測模版任務選擇基準:
1)根據大促生產峰值流量模型結合伺服器資源使用情況設定壓測模版任務;
2)梳理鏈路依賴介面呼叫,按照最差下游依賴的承載上限並結合自身介面效能從呼叫量的角度設立壓測模板;
3)對於沒有下游依賴的服務,按照系統自身最佳處理能力,從吞吐量或cpu角度設立壓測模版;
壓測頻率:鏈路長複雜介面,建議每天執行;自閉環的系統推薦按照上線頻率執行。
壓測視窗期: 和產研確認業務低峰期間,指定常態化壓測任務的執行時間。
壓測環境: 生產環境單機或者小叢集進行常態化壓測。
壓測資料: 建議使用R2錄製線上的真實流量作為常態化壓測的入參,保證壓測結果的有效性。
壓測結果: 每次壓測結果測試同學值班跟進,對不達標的介面,行雲bug持續跟蹤,協同研發進行效能分析、問題排查、壓測任務維護。

壓測工具:forcebot常態化壓測及R2
三、常態化計劃
•2023-Q1在履約、基礎進行常態化壓測試點,形成最佳實踐,並進行技術賦能分享。
•2023-Q2季度推廣至平臺技術部-配運和交易條線,618大促前平臺技術部完成核心0級讀服務125個基於jdos3.0的常態化壓測建設。
四、基於流量錄製的高保真壓測
雙十一大促剛過,在大促備戰時很重要的一個環節是對各大核心服務系統進行壓測,以保證系統在大促期間的穩定性,同時根據壓測結果為大促擴容提供資料支援。那麼如何進行高保真壓測,使壓測結果更接近於線上真實效能表現?在整個壓測過程中,壓測資料的準備是其中非常重要的環節,很大程度上決定了壓測結果是否真實可靠;
隨著業務的不斷髮展,不僅使用者流量、業務場景越來越複雜,服務的呼叫關係和模組也越來越繁多,資料構造越來越困難,簡單的資料集無法模擬線上真實的業務流量,流量配比不真實容易導致壓測結果失真。
目前各大公司進行模組級壓測或者全鏈路壓測基本都是採用流量錄製的方式,先對錄製的流量進行儲存,然後對流量進行編輯、過濾後通過壓測引擎向被測服務發壓;本章結合Forcebot壓測平臺,詳細介紹如何使用R2平臺錄製線上流量進行高保真壓測。
4.1 流量錄製壓測
利用R2平臺錄製線上流量進行壓測的基本框架圖如下所示:
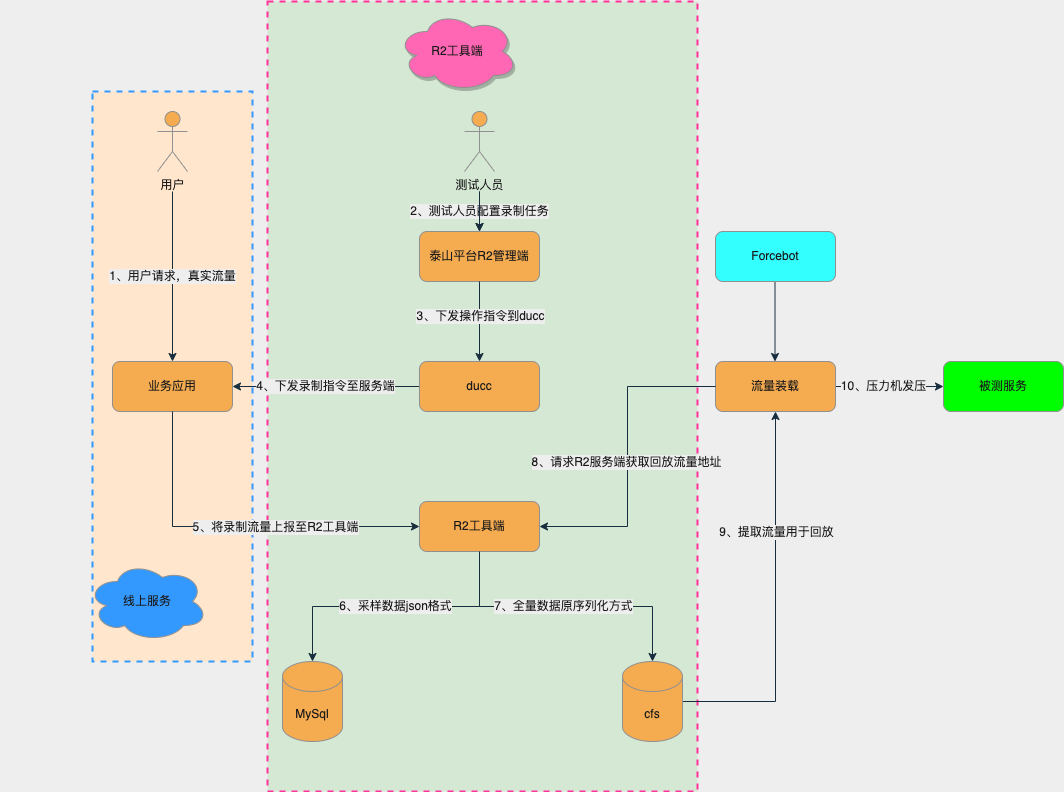
1、使用者存取線上服務,產生基於使用者的真實流量;
2、測試人員在泰山平臺R2工具管理端建立錄製任務,任務啟動時下發操作指令到ducc,再通過ducc下發錄製指令到線上伺服器端(線上服務已經開啟pfinder並接入R2平臺),開始錄製線上流量;
3、錄製的流量會上報至R2工具端,並且將採用資料進行儲存;
4、流量錄製完成後,可以在Forcebot壓測工具平臺建立壓測指令碼,Forcebot平臺已經和R2平臺對接,請求R2伺服器端獲取回放流量地址,進行錄製流量裝載;
5、Forcebot平臺獲取到流量後,即可以正常通過壓力機向被測服務發壓,執行壓測任務。
4.2 錄製壓測流量
根據系統架構及壓測場景分析,選擇需要錄製流量的介面及場景。
•若壓測時僅考慮單個介面,那麼錄製單個介面流量即可;
•而有的應用是多個核心介面,需要混合場景壓測,在錄製流量時需要同時對多個介面流量進行錄製;
•當然,你也可以在錄製任務中設定僅錄製請求或響應符合某種特定業務場景的流量;
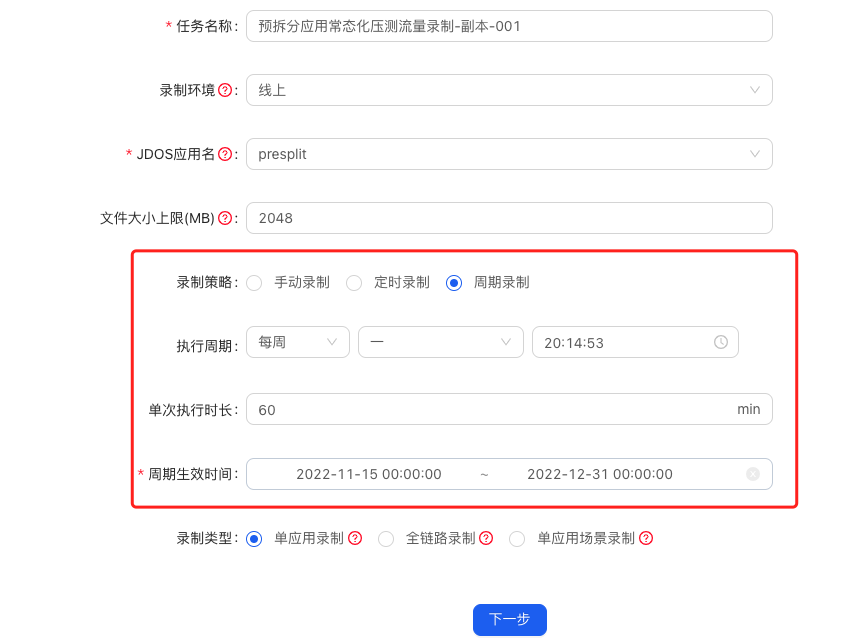
① 建立壓測流量錄製任務:選擇入口應用,設定錄製任務的名稱及檔案大小,注意:一般在進行壓測流量錄製時,建議錄製所有場景流量,儘可能地高保真生產實際流量;在建立錄製任務時,建議錄製檔案大小不高於2G;

流量錄製策略包含了手動錄製、定時錄製及週期性錄製。在進行常態化壓測時,為了避免流量過於老舊與當前生產流量偏差較大,可以在R2平臺上建立一個週期錄製流量的任務,按天或按周錄製一遍生產流量,以保證壓測資料的即時性。
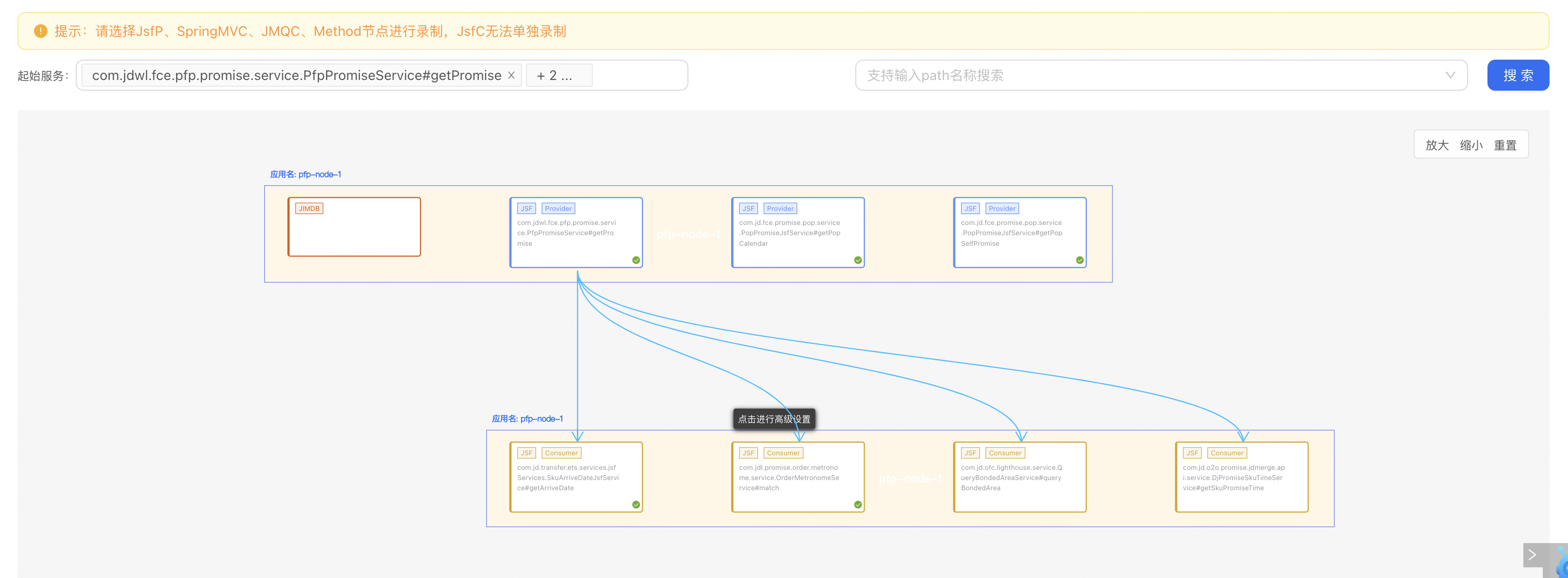
② 選擇要錄製的起始服務,可以選擇多個介面同時錄製,平臺會展示出介面呼叫鏈路,可以針對呼叫鏈路上的服務或中介軟體等同時開啟錄製,然後選擇錄製的範例,設定後任務之後就可以開始執行錄製。
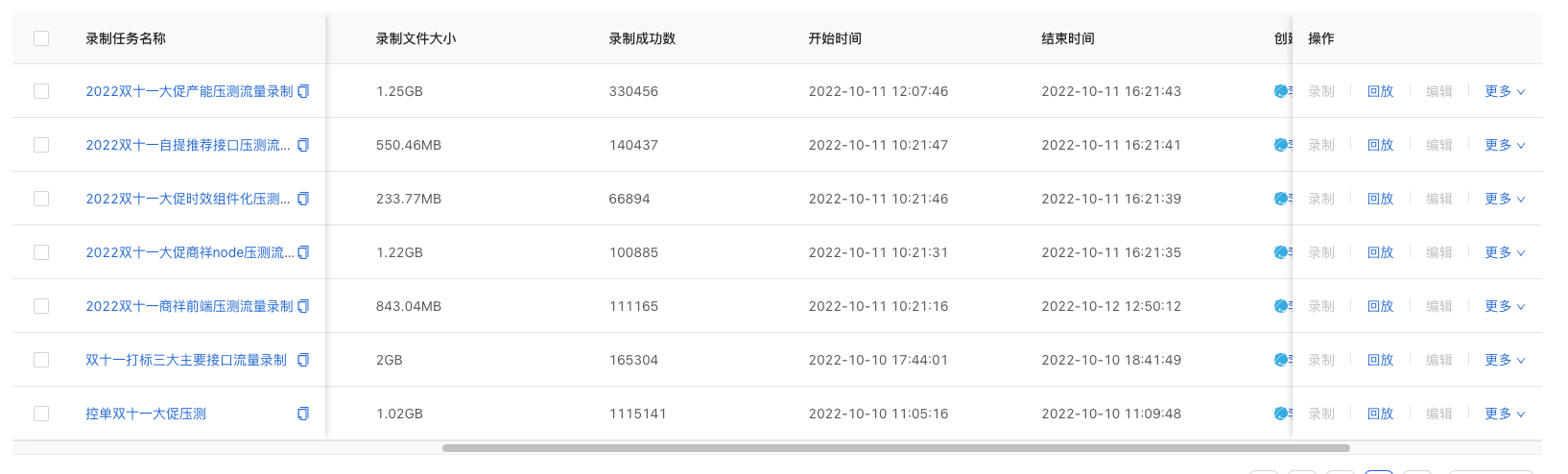
流量錄製完成後,即可在forcebot壓測平臺建立壓測指令碼;
4.3 壓測指令碼建立
4.3.1 單介面壓測指令碼
在指令碼管理中建立一個JSF回放指令碼,編輯錄制資訊設定,選擇要壓測的應用、對應的R2錄製流量任務,Forcebot支援在京東私服平臺上搜尋或者手動上傳JSF檔案(jar包),平臺會自動然後解析jar包中的類和方法,呼叫jsfOpenApi獲取介面別名和直連的ipPort。通過以上方式獲取介面服務相關資訊,快速搭建jsf介面的環境。選擇要壓測的介面、jsf別名以及壓測的方法後自動會生成壓測指令碼;生成的指令碼中預設關聯了選擇的R2錄製任務中的錄製請求,可以直接進行壓力測試。
如下圖所示,你可以進行內網環境校驗,可以校驗指令碼是否能正常獲取到流量並向對應介面發起了實際請求,這也是壓測前的必要步驟,驗證指令碼通過之後進行儲存,就自動生成了相應的指令碼及lib檔案;如果是單介面場景壓測,到這裡就可以使用該指令碼去建立壓測任務了。
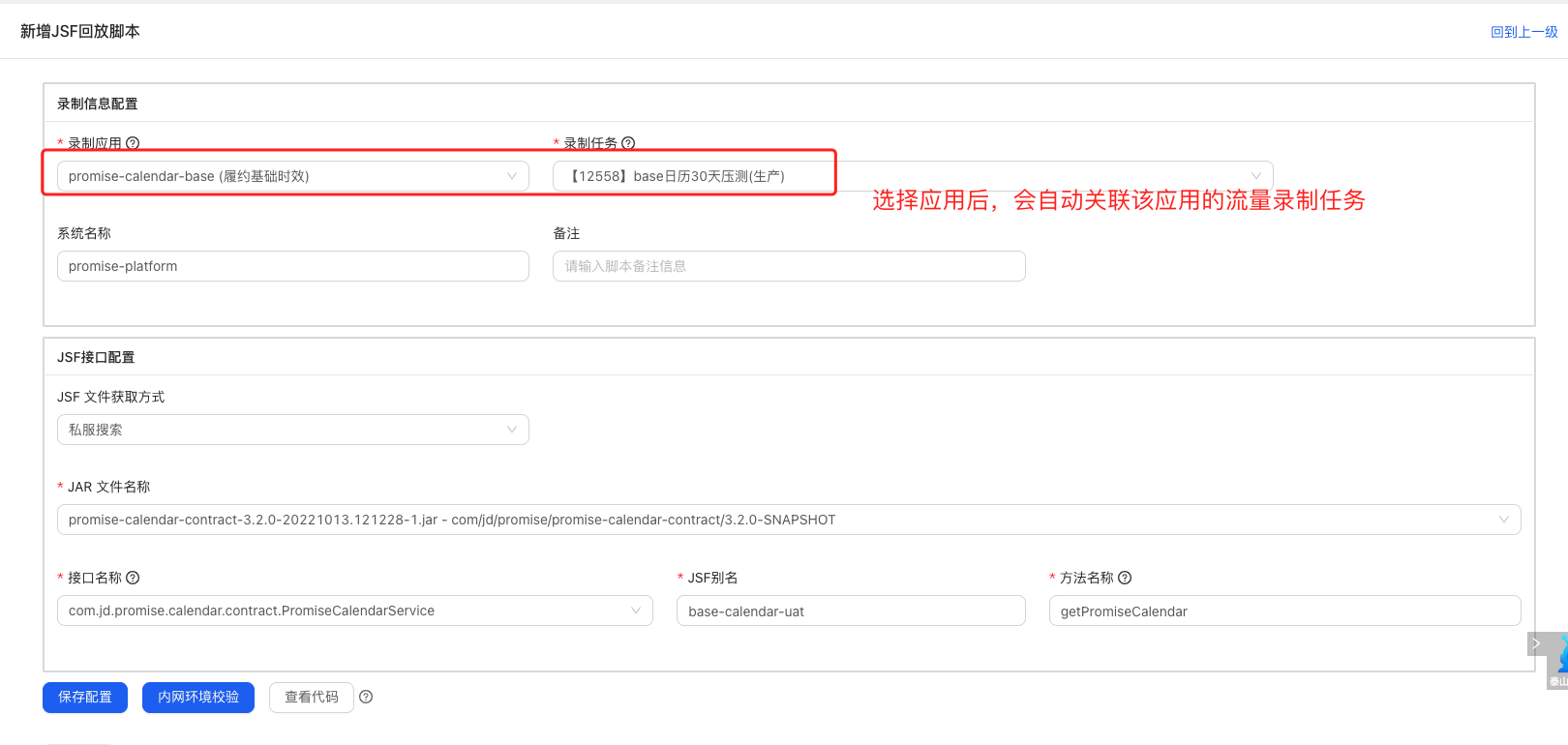
值得注意的是,這種方式生成的指令碼是不可編輯的,需要編輯指令碼得自定義建立指令碼;到這裡,聰明的你一定想到了,這裡頁面僅能選擇一個介面的其中一個方法,如果想要對同一個介面的不同方法或不同介面進行混合壓測應該怎麼辦呢?不要著急,答案已經在路上了。。
4.3.2 多介面混合壓測指令碼
在實際生產中,我們的應用往往會提供多個介面,或者同一個介面上會提供不同的方法服務。我們在壓測的時候如果僅僅按照單個介面來進行壓測,這樣的壓測資料僅能反應單場景交易下系統本身的效能表現,而實際生產中,尤其是大促時,系統往往在同一時間需要處理多個介面請求,系統資源也是多個介面共用的,所以混合場景壓測更能反映系統真實處理能力;
在進行混合壓測前,需要首先明確各個介面場景在同一時間段內的呼叫量比例是多少,在建立壓測指令碼的時候,需要根據這個比例來設定每個壓測場景下壓力請求佔比rate;
步驟1: 生成標準的JSF回放指令碼
在自定義指令碼之前,先按照3.3.1所述生成一個標準的JSF回放指令碼,以及依賴的lib檔案都會自動生成;

步驟2: 生成自定義指令碼
在步驟1中生成的預設指令碼是不可編輯的,可以檢視程式碼時生成自定義指令碼,然後對自定義的指令碼進行編輯。
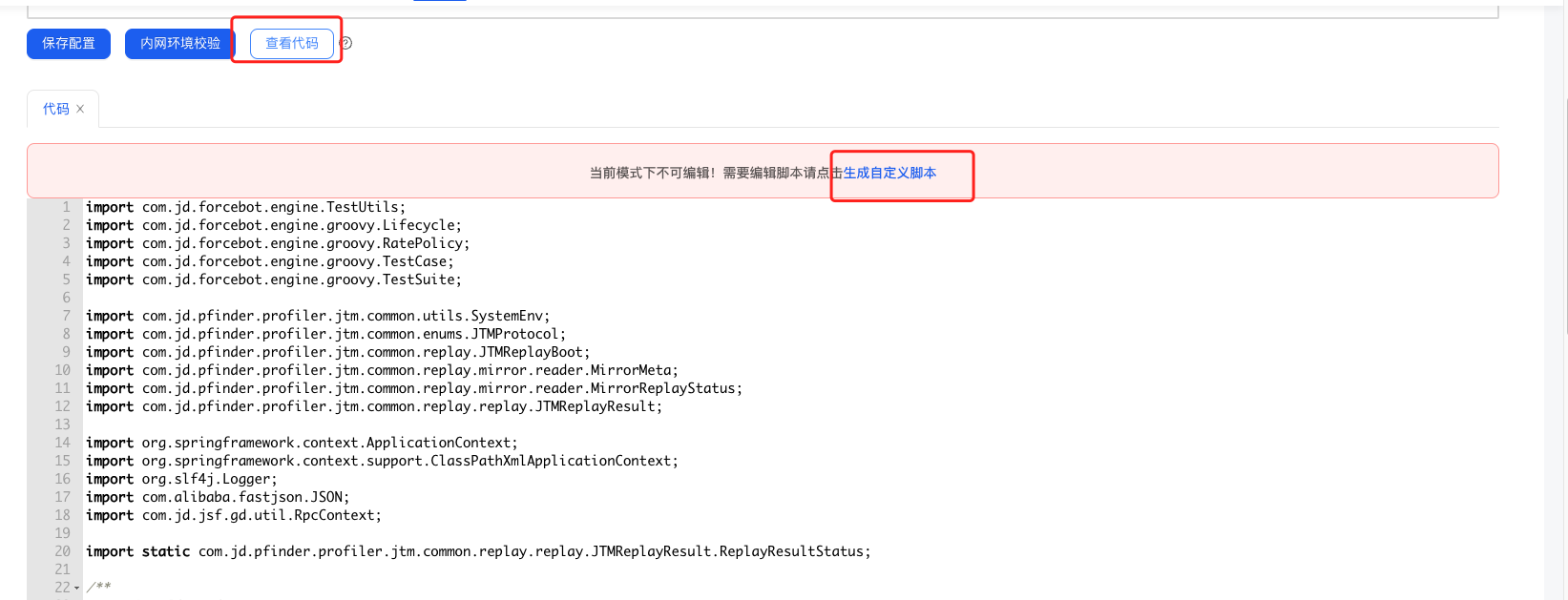
① 首先定義介面路徑及其方法,對應不同介面的別名,然後是根據不同的介面進行流量載入;
其中ipList是指定被壓測的伺服器ip及埠,如果介面別名下是叢集部署,只想要對其中某一臺機器進行壓測的話,需要指定ip及埠;

② 針對不同的介面建立回放事務,此處介面路徑、介面的載入流量、介面別名等都需要一一對應。rate為該指令碼中涉及的多個介面的呼叫量比例,比如介面1:介面2:介面3=7:8:5(可參考大促或日常呼叫峰值期間各介面的呼叫量比例),則需要在testCase中設定相應的壓力比。
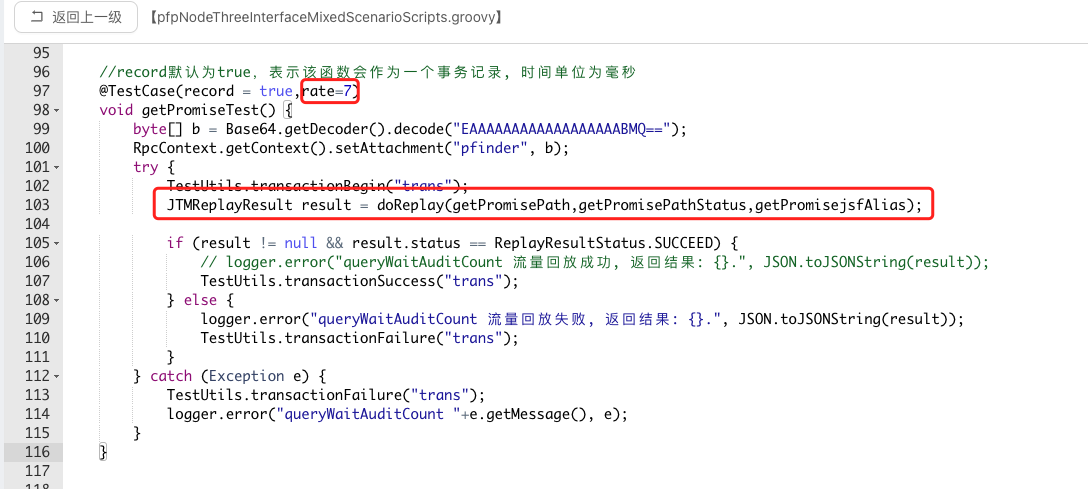
③ 因為多介面涉及介面路徑、流量源以及介面別名各不相同,需要將預設的無參doReplay方法,修改為傳參方法
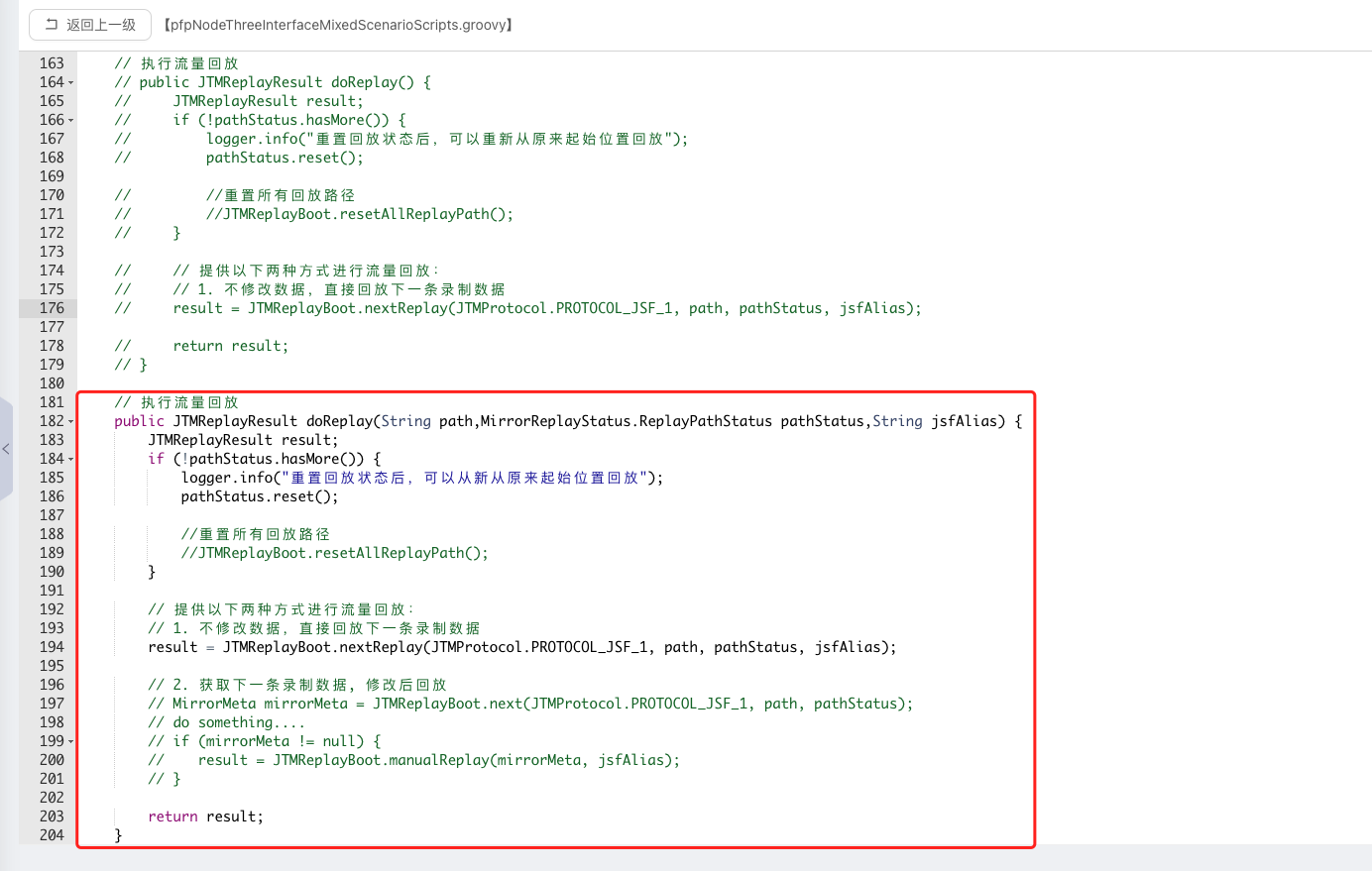
④ 指令碼修改完成後點選儲存
⑤ 相同介面不同方法的混合壓測指令碼建立同理,區別在於同一個介面,別名是一致的,不需要額外再指定其他介面別名;
步驟3: 匯入附件jtm.properties
在步驟2中自定義指令碼編輯完成後,進行校驗執行時還無法成功,因為指令碼還缺少流量錄製回放的附件檔案。儲存指令碼後,返回上一級目錄,將步驟1中生成的標準groovy指令碼中的附件jtm.properties下載到本地,然後再將該附件檔案上傳到我們自定義的指令碼中,並修改指令碼的附件檔案。在附件檔案末尾新增
jtm.replay.recent.record.num=1,指定每次壓測時都獲取繫結週期性流量錄製任務最新錄製的流量;

4.4 雙十一大促高保真壓測實踐
有了R2流量錄製平臺提供的便捷,讓獲取線上流量不再成為難事,可以幫助我們快速的完成壓測資料的準備,同時壓測流量高保真還原實際業務場景。
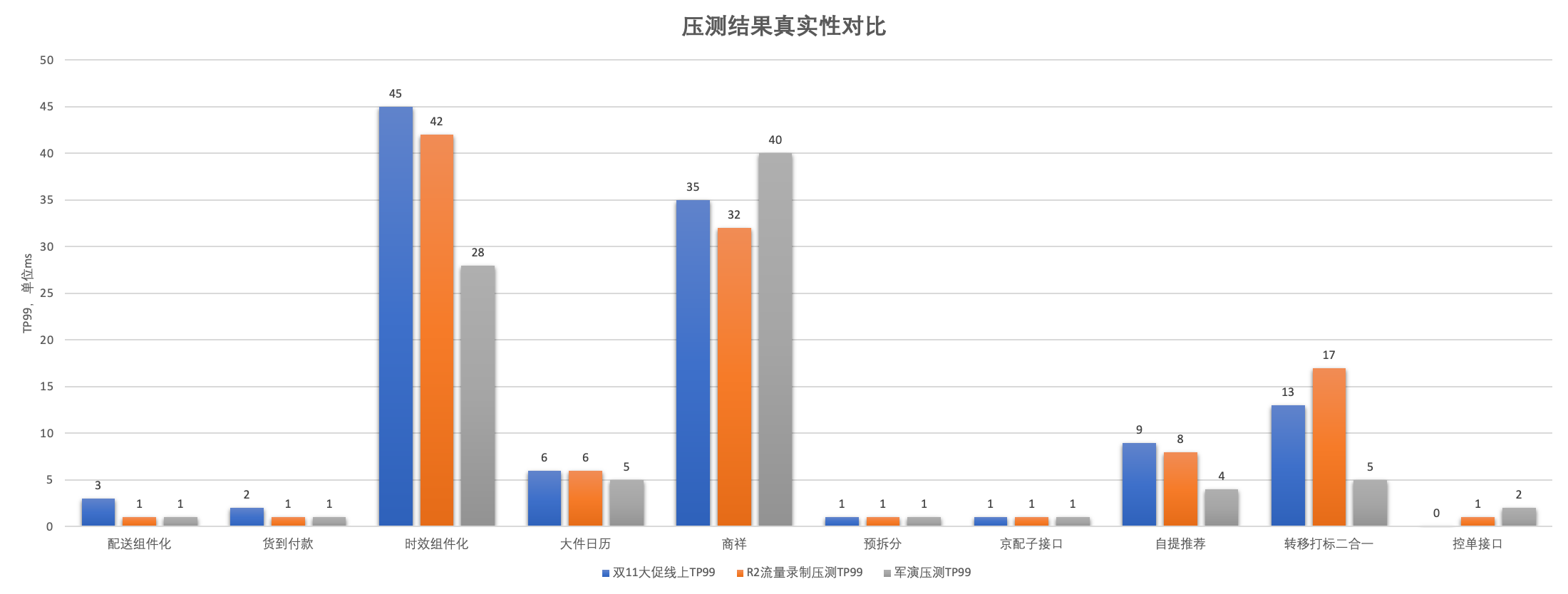
在本次雙11大促,物流promise業務線全面採用R2流量錄製的方式進行大促壓測,自壓測結果更加接近線上介面效能,真實性達到90%以上;為大促資源擴容評估提供了更加精準的資料支撐。同時,通過這次高保真壓測,我們發現多個系統效能問題,其中包含極限業務場景下的可用率降低的問題。
下圖為採用R2流量錄製壓測、軍演壓測與雙十一大促開門紅的效能對比。
五、USF常態化壓測實踐
基於focebot的常態化壓測能力,選擇USF選擇3星核心服務進行常態化壓測實踐,選擇TOP4核心介面,使用R2的錄製線上流量,根據大促的流量模型進行的混合場景常態化壓測,持續監控USF的核心介面的效能情況。
forcbot常態化壓測工具支援,壓測任務複用(支援流量錄製壓測任務)、可設定效能基線包括響應時間TP99和TPS的和伺服器CPU等資源指標設進行效能基線設定,並根據效能基線判斷壓測是否達標,以及可以設定不達標的壓測結果自動建立行雲缺陷,進行效能問題跟蹤處理。並且還提供壓測監控對比資料以及壓測結果歷史記錄,便於對效能結果和問題進行分析,自動傳送壓測郵件通知,及時同步效能壓測結果。
目前forcebot的常態化壓測支援以下功能:
•1、支援壓測任務的複用,可使用歷史的壓測任務,不用單獨建立壓測任務和指令碼,支援jsf、http、自定義的jimdb、jmq以及回放指令碼。
•2、可設定定時執行任務,靈活執行時間。
•3、可支援流量錄製。
•4、可自動建立行雲缺陷
•5、可設定壓測的是否達標基線(生效:是否將指標用於壓測達標率統計;勾選會作為指標之一,不勾選則在達標率計算時不作為統計指標。 達標:勾線生效的指標值同時滿足時,壓測結果即為達標;反之,有任何一個指標值不滿足條件,壓測不達標。
以下為基於USF進行的常態化壓測。
5.1 壓測物料準備
壓測資料:
•選擇業務高峰期14:00-16:00 錄製線上10%對應6臺機器流量,錄製【公共叢集】入參1G。(後續會考慮多個叢集)
•錄製介面服務是USF3.0線上TOP4的介面,已完成星標治理,達到三星的介面,完成可用率、TP99、以及有降級和限流方案治理。
壓測場景: 混合場景設計(模型)
應用部署拓撲圖:
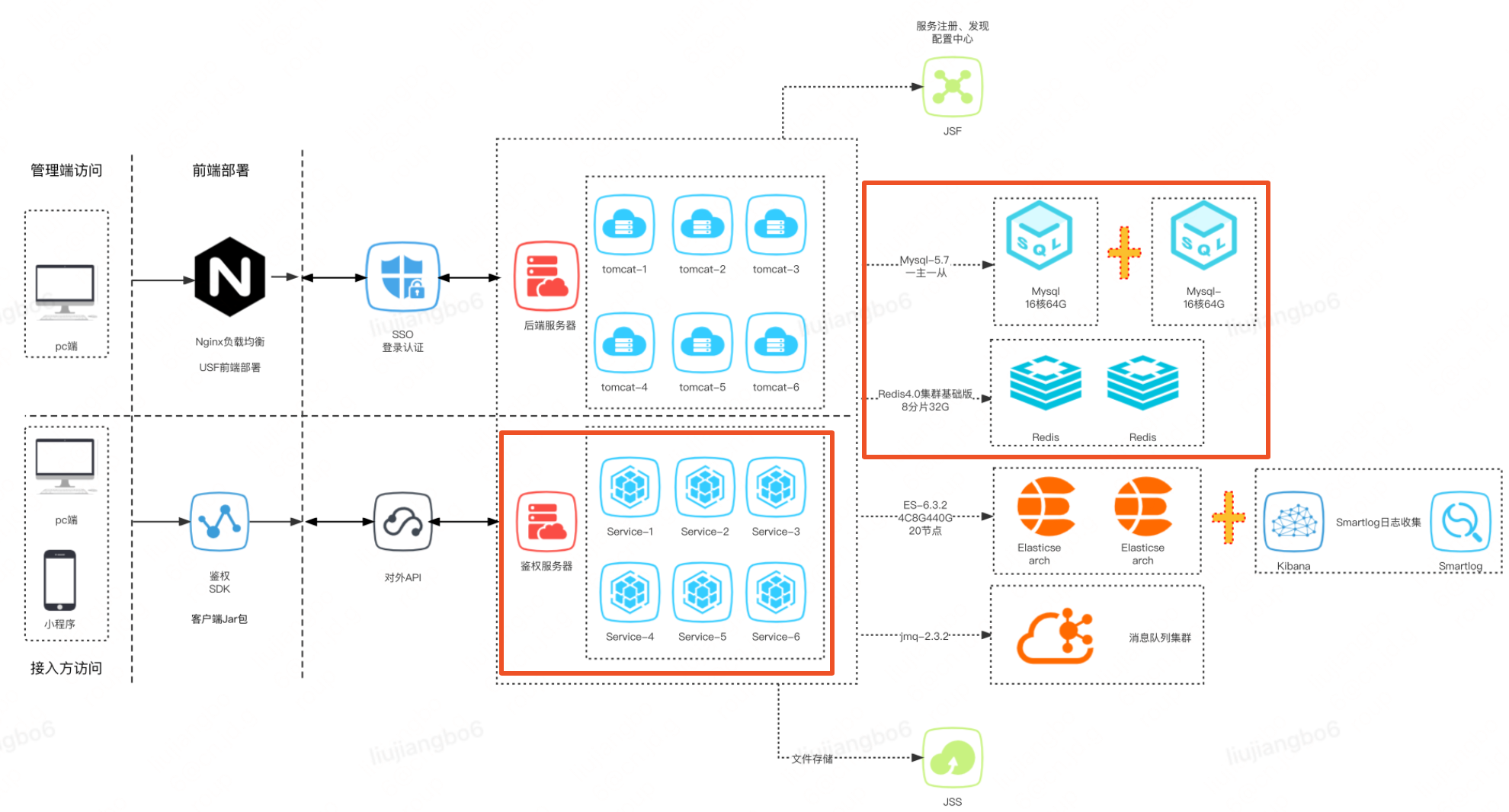
壓測環境:
壓測環境目前是與線上同設定的單範例的UAT環境。
•與線上的現資料庫、快取保持一致,均已同步線上資料。
•壓測環境資料庫的設定和快取服務的設定與線上保持一致。
1.線上機器設定 * 範例數60
2.應用伺服器設定:4C8G
3.資料庫設定:16C64G記憶體
4.壓測機器設定
5.應用伺服器設定:4C8G
6.資料庫設定:16C64G記憶體
5.2 壓測風險評估
•壓測環境選擇:
•1)先在同設定的UAT環境常態化壓測,根據效能結果不斷調整效能基線
•2)穩定後再複用生產環境的應用和中介軟體進行常態化壓測。
•任務執行視窗:
•選擇業務低峰期進行壓測,結合ump監控USF服務的高峰期一般在白天的上午6-9、9-11、14-17系統使用的高峰期。所以目前任務執行的視窗期是工作日17:40。目前是有人值守的報警資訊及時處理,監控應用和資料庫相關情況。
•壓測鏈路同步:
•壓測上下游鏈路梳理,確定壓測範圍、壓測量級、壓測時間,同步相關方達成共識。
5.3 常態化壓測任務建立
5.3.1 壓測模版任務選擇準則
•複用歷史的壓測任務(模版任務),直接建立常態化壓測任務。實際選用歷史的壓測任務場景時,建議根據系統的實際情況來選擇,一般可以選擇效能拐點場景或者壓到預期值的場景(如CPU60%或者TPS達標),一般建議不要壓測系統資源飽和的狀態場景。
•範例:此處USF我們選用歷史的壓測任務,是介面滿足雙十一的吞吐TPS的場景,此時伺服器的CPU壓力在27%,資料庫的CPU在36%。
模版任務選擇:
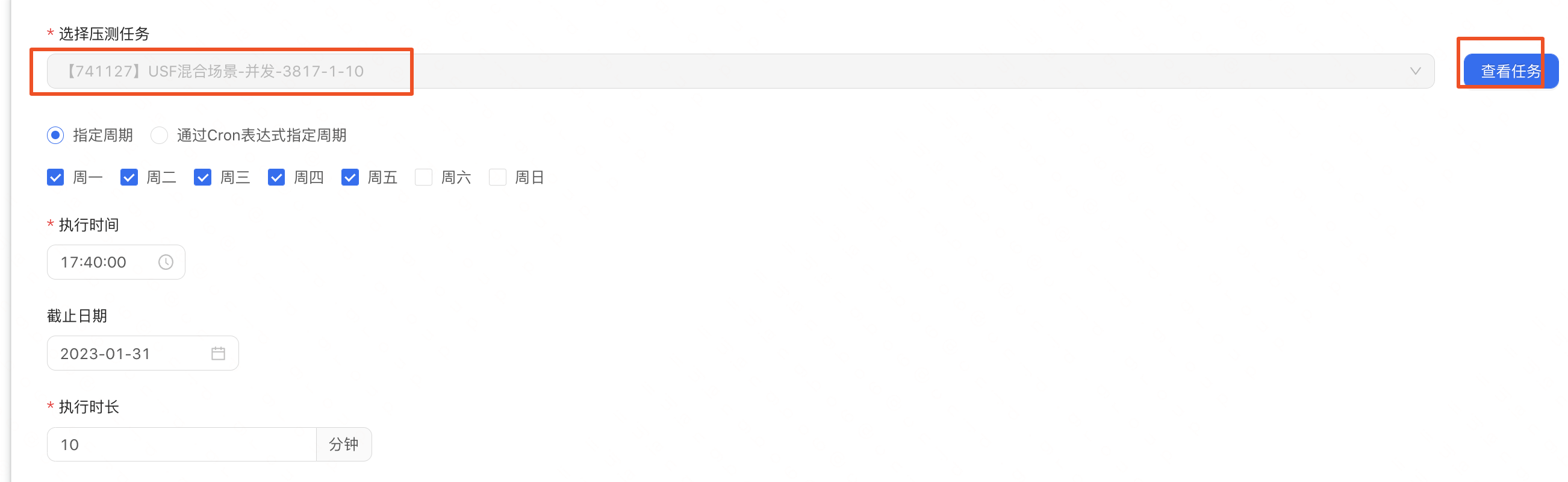
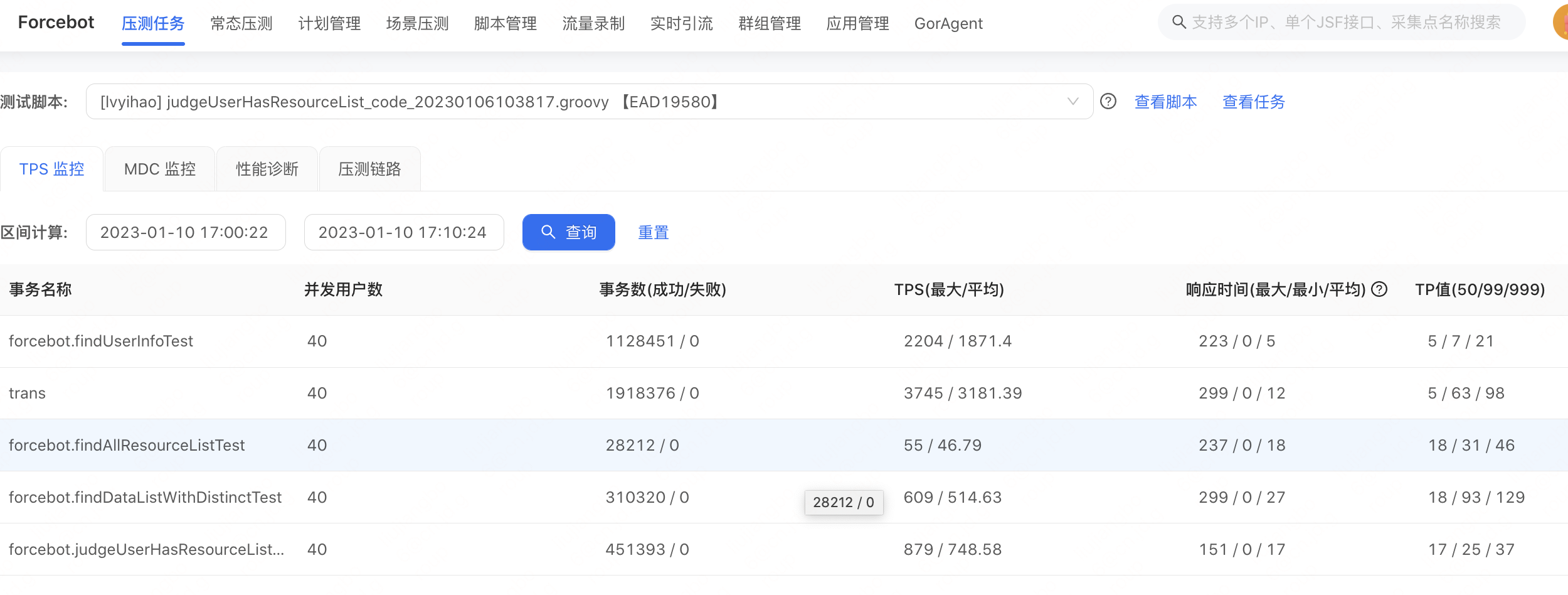
檢視任務,可以看到該場景下的執行的指令碼,發壓相關設定並行執行緒數、執行的模式(並行模式和RPS模式)、執行時間,可根據需要進行一定的調整。
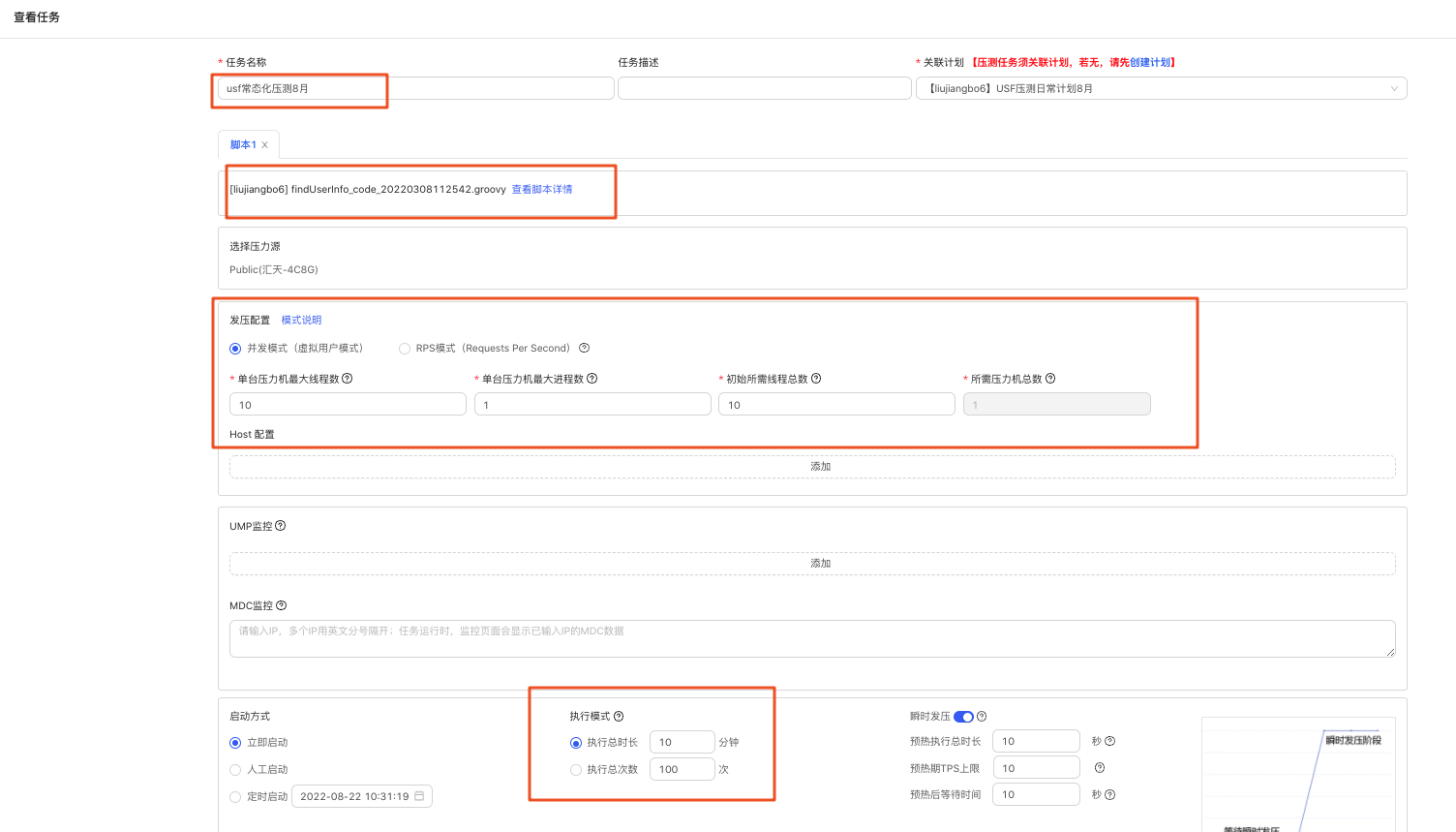
5.3.2 壓測定時任務設定
•可以通過週期或者Cron表示式指定執行週期,usf此處使用Cron :0 40 17 * * ? 每天下午5點40執行。並在此處設定目標執行緒數和執行時長。(這個會覆蓋壓測任務中的執行緒數和執行時長)。
•常態化壓測執行的頻率以及執行的時間參考根據程式碼上線週期和業務的呼叫低峰時間段綜合客製化。
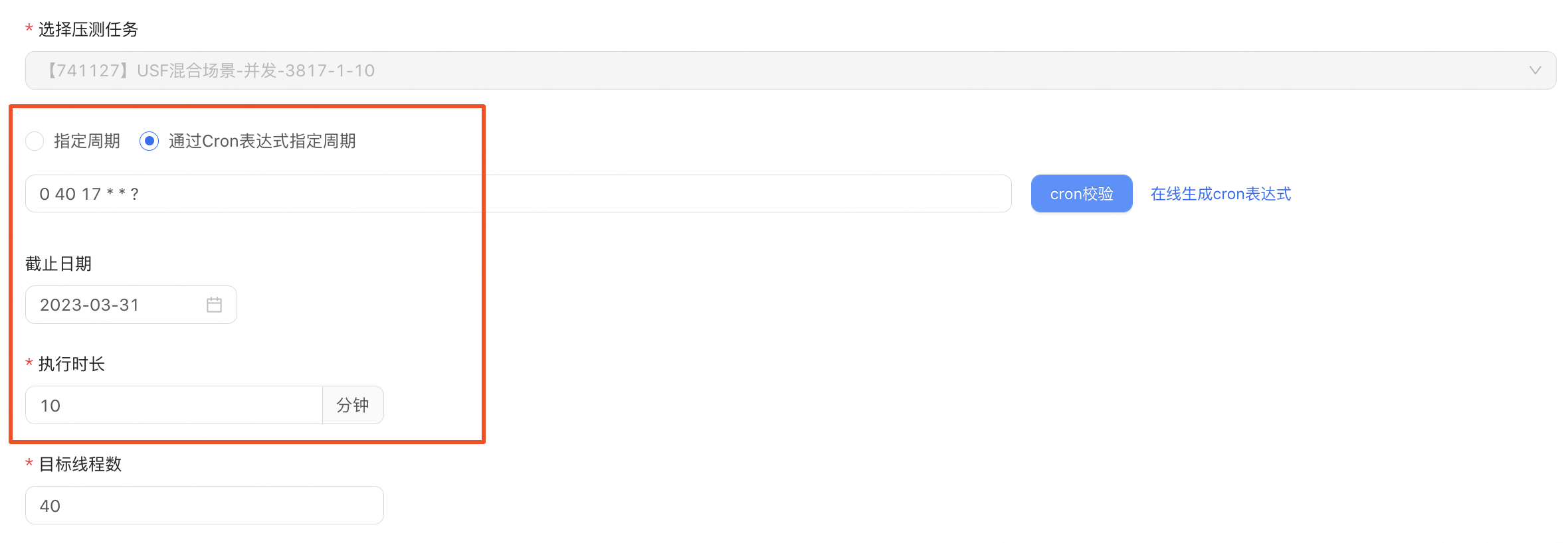
1)執行模式-RPS模式
繫結的是壓測任務是RPS,那麼我們建立的常態化壓測任務也是RPS模式。目標QPS設定,並非指令碼中所有介面的QPS的和,而是指令碼中佔比最大的介面對應的壓測目標值,如果設定錯誤會導致過度發壓。

2) 執行模式-並行數模式
繫結的壓測任務是並行模式,那麼我們建立的常態化壓測任務是並行執行模式。目標執行緒數設定。
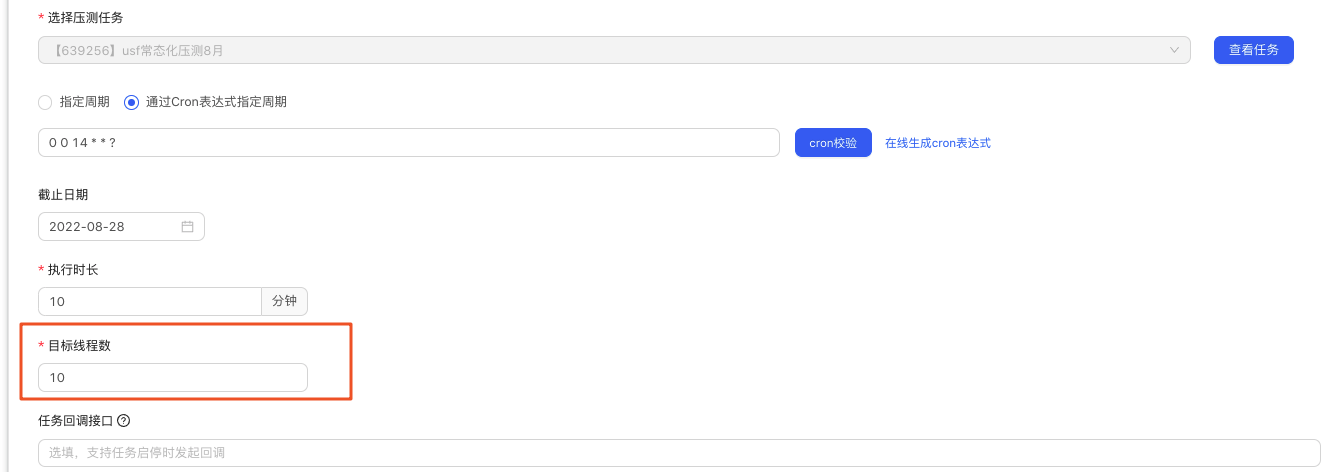
5.3.3 壓測基線設定
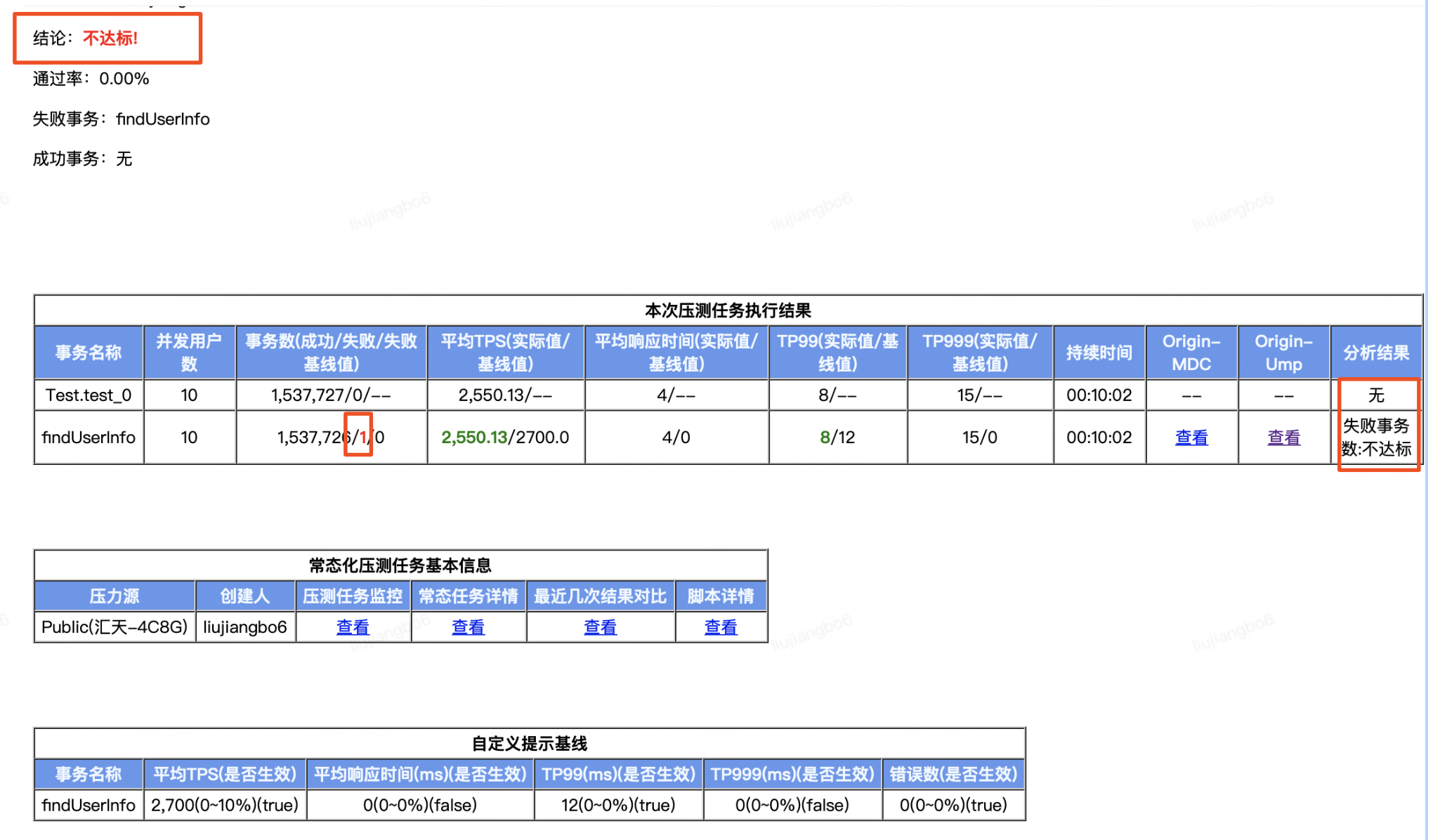
•根據壓測任務對應的壓測場景,根據事務名稱(介面方法)設定合理的壓測基線,如果關聯的壓測任務是混合指令碼,那麼可以分步驟設定多個介面事務(事務名稱預設:forcebot.測試方法名 )的效能基線。 一般關注的指標平均TPS、TP99、錯誤數、CPU監控。允許波動的範圍,根據介面的實際情況給一定的波動空間。若大於設定的波動範圍,並且選中設定提交行雲缺陷,就會自動提交行雲bug,便於bug跟蹤閉環。
•基線指標設定注意點:如果基線值特別低的情況,那允許的波動範圍百分比需要設定的比較大才可以,否則很小的波動都會被認為壓測不通過。基線波動範圍,具體介面具體分析,研發和測試達成共識,
1) 自定義效能基線設定
•USF的findUserInfo服務設定範例:
•TPS基準值=2700,允許波動範圍10%。(2430-2970) 上下浮動
•TP99基礎值=12ms,允許波動範圍50%。(12ms-18ms) 上浮動,時間相關的是向上浮動。
•錯誤數基準值=0,允許波動範圍0。
•CPU監控基線值=25%,允許波動範圍=20%。(20%~30%)上下 浮動
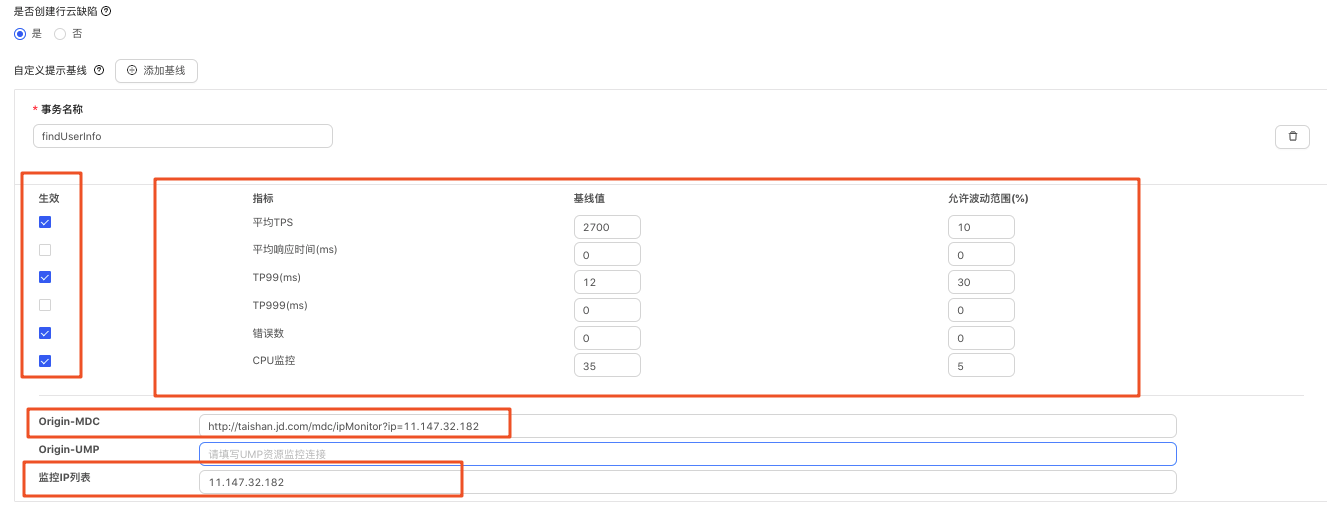
事務名稱: 目前無法自動識別,可以寫指令碼的中事務名稱預設是forcebot.測試方法名,也可以增強指令碼使用自定義事務名稱就是
TestUtils.transactionBegin("findUserInfo"),即findUserInfo
效能基線設定例如:介面效能tp99在12ms左右,此時基線值設定為12ms,允許波動的範圍如果設定為10%,那允許的波動範圍就是12ms*10% = 13.2ms,超過13.2ms就認為壓測不通過,這顯然是不合理的,此時需要根據我們的介面tp99最大接受範圍來設定允許波動百分比。
2) 多介面效能基線設定
自定義基線設定中,可以新增多個介面事務,該事務就是指令碼中的事務名稱。
預設事務名稱:forcebot.測試方法名

自定義事務名稱: 如TestUtils.transactionBegin("findUserInfoByOrgCode");

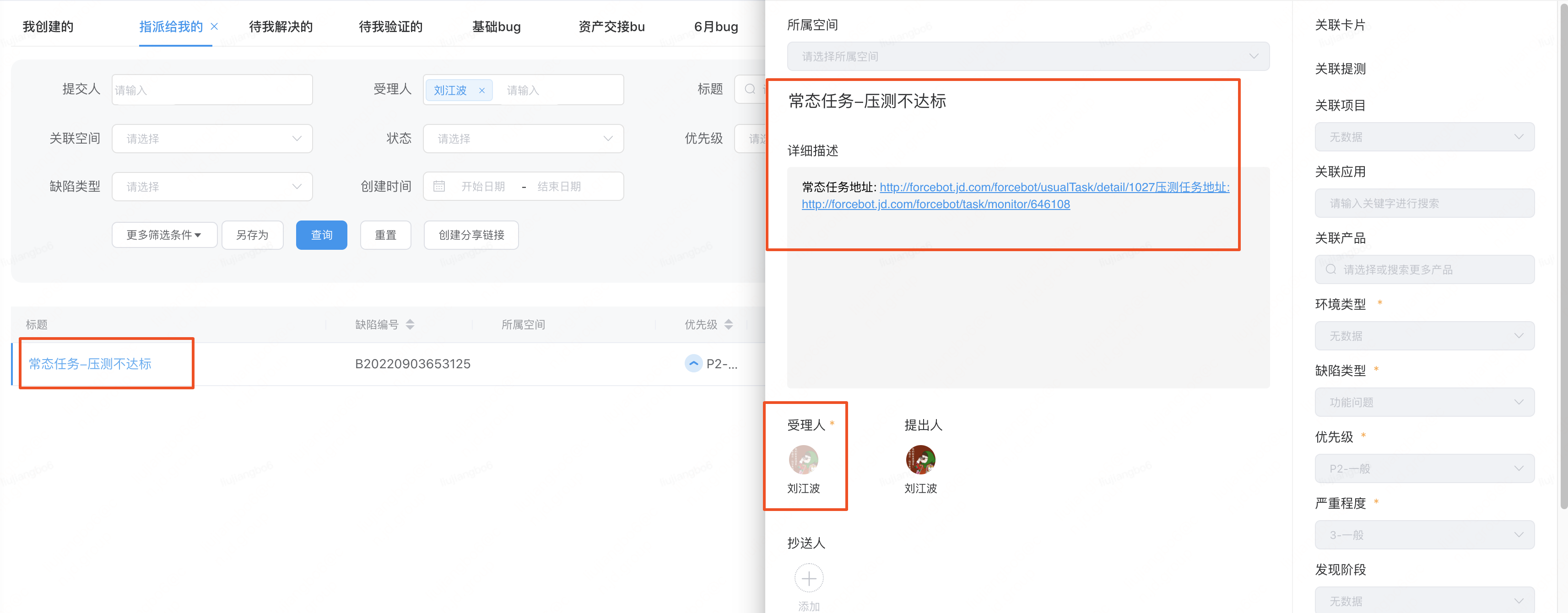
5.3.4 行雲缺陷跟蹤
對於不滿足效能基線設定各項指標值,常態化壓測結果就為不達標,若該任務設定開啟了自動建立行雲缺陷,就會對不達標的執行結果自動提交行雲缺陷,這樣可以保證bug生命週期各階段可追溯,保證問題及時處理解決。
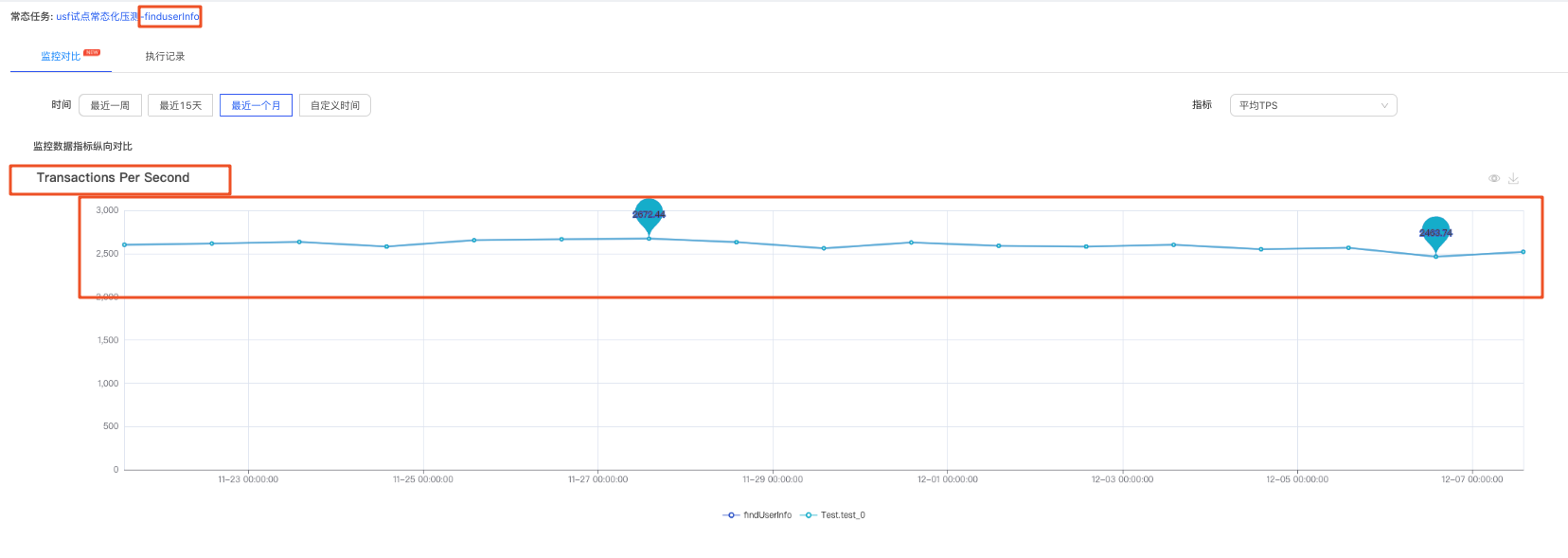
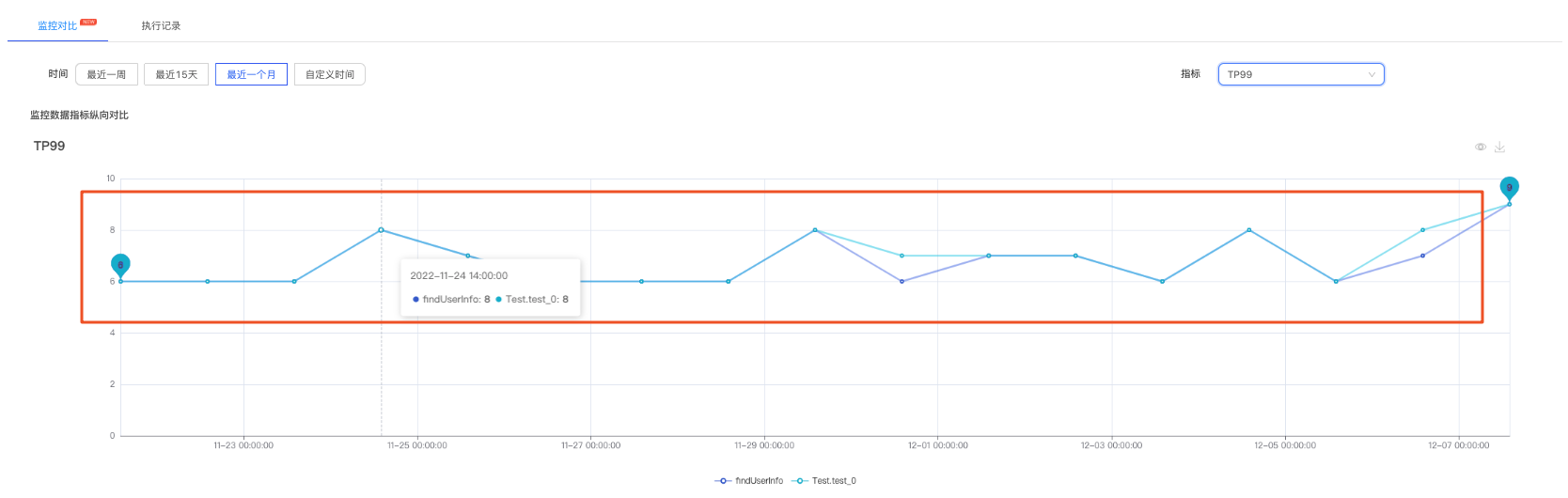
5.3.5 監控定位問題
可以檢視一段時間該服務的效能趨勢,如果介面效能波動較大,需要進一步排查介面效能下降的原因。
1) 監控資料-TPS
2) 監控資料-TP99
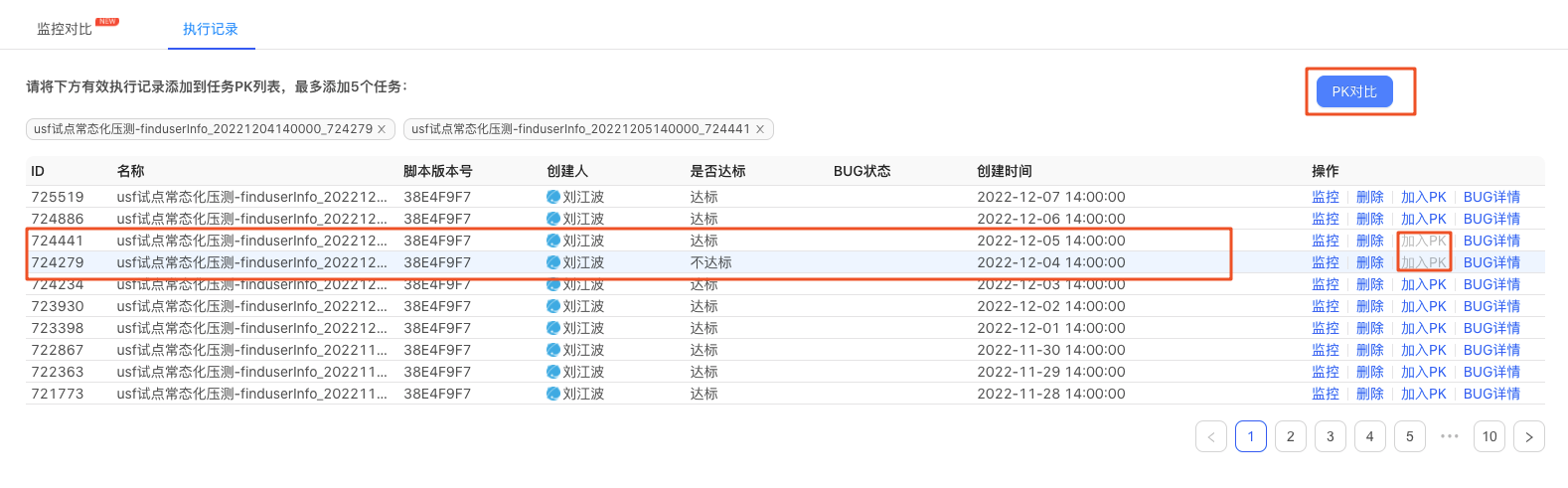
3) 執行記錄對比詳情PK
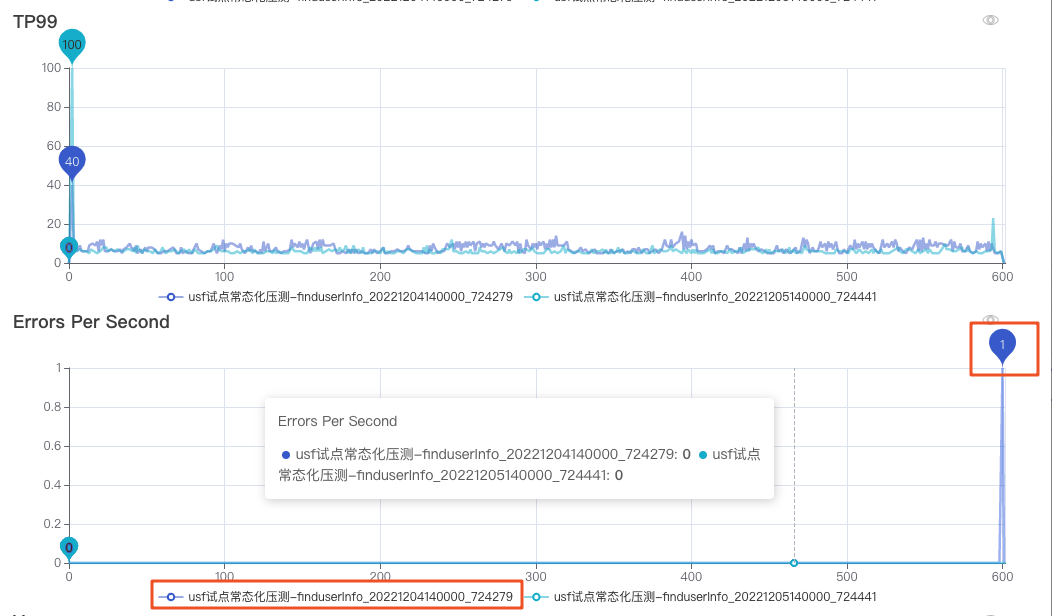
執行記錄中,有指令碼版本和,是否達標以及bug詳情。選中達標和不達標的結果,進行PK對比,對比項中有TPS、TP99、Error Per Second等指標。
USF相關介面的壓測結果,達標和不達標的PK如下:發現是12-04存在一次錯誤呼叫,進一步跟蹤錯誤產生原因
5.3.6 郵件傳送壓測結果
設定接收人郵箱,將郵件抄送給研發和測試相關人,壓測結果郵件中會提供壓測資料彙總顯示,如果壓測結果中某一項指標不達標時(超出設定值及波動範圍)時,則此次任務視為不達標。結合監控資訊以及執行時間段的紀錄檔與研發共同定位問題或者是效能基線指標的調整。

郵件如下: