求解 LCA の方法
最近公共祖先(LCA)
最近公共祖先簡稱 LCA(Lowest Common Ancestor)。兩個節點的最近公共祖先,就是這兩個點的公共祖先裡面,離根最遠的那個。
-----oi wiki
舉個例子
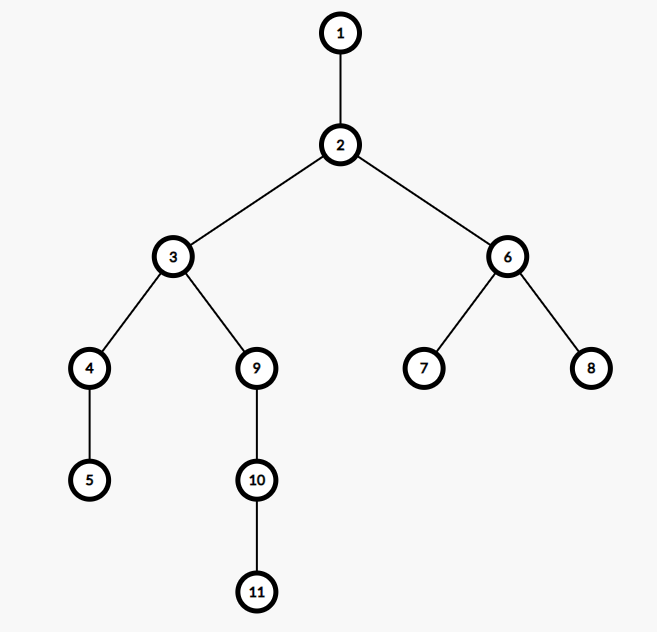
在這張圖中,\(5\) 和 \(9\) 的最近公共祖先就是 \(3\),\(9\) 和 \(7\) 的最近公共祖先就是 \(2\)
由於在樹上兩點間的簡單路徑是唯一的,並且從上圖中我們可以很容易發現兩點的 LCA 一定在其的簡單路徑上,所以我們有時候需要求出某兩個點的 LCA
P3379 【模板】最近公共祖先(LCA)
以下所有的測試資料輸入輸出皆保持一致
暴力跳
最暴力的演演算法一個一個往上跳,複雜度 \(O(TLE)\)
沒寫,因為會 T
倍增求 LCA
這個方法是最簡單也是最好想的一個方法,而且支援線上的查詢,時間複雜度為 \(O(m\log n)\),本人看來是暴力的一個優化
我們維護一個 \(f[i][j]\) 陣列表示 \(i\) 點往上跳 \(2^{j}\) 所到達的點的編號,\(dep[i]\) 表示 \(i\) 號點在樹中的深度
我們首先要做的就是 DFS 一遍把我們的 \(f\),\(dep\) 陣列求出來,然後在查詢的時候,按照下面的步驟:
-
我們首先判斷兩個點的深度大小,保證傳入的 \(x\) 的深度大於 \(y\) 的深度
-
我們讓 \(x\) 點開始往上跳,從大到小列舉 \(f\) 陣列的第二維,只要跳完之後深度大於等於 \(y\) 的深度就跳,這樣最後我們使 \(x\) 和 \(y\) 來到了同一高度。
-
我們讓 \(x\) 和 \(y\) 一起向上跳,前提是兩點跳完後不在同一位置,因為跳的時候可能會跳超,但是兩點的編號相同,造成是公共祖先但不是最近的情況,最後我們得到了兩點的最近公共祖先下方的兩個點 \(x'\) 和 \(y'\),這個時候直接返回其中一個的父節點即可。
注意第二步完成之後需要特判一下,是否兩點編號相等,相等直接返回即可,防止兩點在同一鏈上的情況
code:
#include<bits/stdc++.h>
#define N 500010
using namespace std;
struct sb{int t,nex;}e[N<<1];//t存放終點,nex存放下一個邊
int head[N],tot;//head存放頭節點,tot存放建邊數量
int de[N],f[N][22],lg[N];//de存放每一個點的深度,f存放每一個點第2的i次方的祖先,lg存放log值
inline void add(int x,int y)//存邊函數
{
e[++tot].t=y;//存放終點
e[tot].nex=head[x];//存放下一個邊的頭節點
head[x]=tot;//更新
}
inline void dfs(int now,int fa)//深搜函數
{
f[now][0]=fa;//當前節點上一個祖先就是fa
de[now]=de[fa]+1;//當前節點的深度就是祖先的深度加一
for(int i=1;i<=lg[de[now]];i++)//從2的1次方開始迴圈
f[now][i]=f[f[now][i-1]][i-1];//當前點的第2的i次方個祖先就是從當前的點的第i-1次方祖先的2的i-1次方的祖先
for(int i=head[now];i;i=e[i].nex)//尋找和當前點相連的點
if(e[i].t!=fa)dfs(e[i].t,now);//如果終點不是祖先的話就繼續深搜
}
inline int LCA(int x,int y)//尋找最近公共祖先
{
if(de[x]<de[y])swap(x,y);//如果x的深度小於y的深度就把xy的值互換
while(de[x]>de[y])//只要x的深度大於y
x=f[x][lg[de[x]-de[y]]-1];//先讓x跳到和y一樣的深度
if(x==y)return y;//如果兩個點相等說明y是x的祖先,直接返回y
for(int k=lg[de[x]];k>=0;k--)
{
if(f[x][k]==f[y][k])continue;//因為是跳到LCA下面的一層,所以他們一定不相等,
x=f[x][k],y=f[y][k];//替換xy的值繼續迴圈
}
return f[x][0];//返回當前x的祖先即為最近公共祖先
}
int main()
{
int n,m,d;//n個點,m次詢問,d為根節點
scanf("%d%d%d",&n,&m,&d);
for(int i=1;i<=n-1;i++)//從第一個到最後一個
{
int x,y;
scanf("%d%d",&x,&y);
add(x,y);//存邊
add(y,x);//無向圖存兩次
}
for(int i=1;i<=n;i++)//預處理log的值
lg[i]=lg[i-1]+(1<<lg[i-1]==i);//計算
dfs(d,0);//深搜處理出f和de的值
for(int i=1;i<=m;i++)//開始詢問
{
int x,y;
scanf("%d%d",&x,&y);
printf("%d\n",LCA(x,y));//輸出最近公共祖先
}
return 0;//好習慣
}

tarjan 求 LCA
這個演演算法在 \(n,m\) 差不多的時候是比較快的,因為他複雜度是 \(O(n+m)\) 的,可惜的是隻能離線。
我們對於每一個詢問的兩點之間連一條無向邊(並不是在存樹的陣列裡面連邊)
在 DFS 的過程中,給走過的節點打上標記,同時維護並查集,如果 \(u\) 節點的這棵子樹沒搜完,那麼 \(fa[u] = u\);,搜完後再更新並查集。
我們假設查詢 \(u\) 和 \(v\) 的最近公共祖先,搜到節點 \(u\),如果另一個節點 \(v\) 已經被搜到過了,那麼 \(v\) 點的並查集祖先就是 \(u\) 和 \(v\) 的最近公共祖先。
我們來模擬一下用 tarjan 求 LCA 的樣例
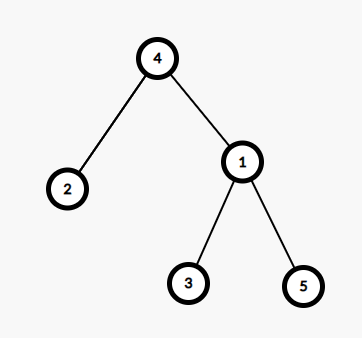
我們在 DFS 的時候,首先來到 \(4\) 號點,然後我們 \(vis[4]=1\),將兩個子節點都合併到 \(4\) 號點上,發現有一組詢問 \(4,5\) 但是 \(vis[5]=0\) 所以不能確定 LCA
然後來到 \(2\),將 \(vis[2]=1\) 發現沒法往下走,所以不走了,發現有 \((3,2)\) 和 \((1,2)\) 兩組詢問,但 \(vis[3]=0\),\(vis[1]=0\) 所以不能確定 LCA
然後來到 \(1\),將 \(vis[1]=1\),將子節點合併到 \(1\) 號點,發現有詢問 \((1,2)\),這個時候 \(vis[2]=1\) 所以我們能確定 LCA,直接返回 \(fid(2)\),也就是 \(4\)
然後來到 \(3\),將 \(vis[3]=1\),沒有子節點,發現有詢問 \((3,2)(3,5)\),這時候 \(vis[2]=1,vis[5]=0\),所以能確定第一個詢問的 LCA,記錄 LCA\((3,2)=fid(2)=4\)
然後來到 \(5\),將 \(vis[5]=1\),發現有詢問 \((3,5)(4,5)\),我們發現兩個都可以確定,記錄 LCA\((3,5)=fid(3)=1\), LCA\((4,5)=fid(4)=4\)
至此演演算法結束。
有的人可能會問,要是出現下面的情況怎麼辦?
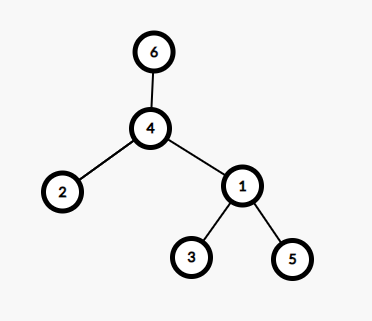
要是查 \((1,2)\) 的話,不就會返回 \(fid(2)\) 遞迴下去不就是 \(6\) 了嗎?
注意我們是在子樹全遍歷完才會修改當前點的 \(f\) 的值,所以不會出現這個情況
code:
#include<bits/stdc++.h>
#define INF 0x3f3f3f3f
#define N 2000100
using namespace std;
int n,m,s,fa[N],vis[N],head[N],cnt,Head[N],cnt1=1;
struct sb{int u,v,next,lca;}e[N],e1[N];
inline void add(int u,int v){e[++cnt].v=v;e[cnt].next=head[u];head[u]=cnt;}
inline void Add(int u,int v){e1[++cnt1].v=v;e1[cnt1].next=Head[u];Head[u]=cnt1;}
inline int fid(int x){if(fa[x]==x)return x;return fa[x]=fid(fa[x]);}
inline int read(){int x=0,f=1;char ch=getchar();while(!isdigit(ch)){f=ch!='-';ch=getchar();}while(isdigit(ch)){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}return f?x:-x;}
inline void DFS(int x,int f)
{
vis[x]=1;
for(int i=head[x];i;i=e[i].next)
{
int v=e[i].v;
if(v==f)continue;
if(!vis[v])DFS(v,x),fa[v]=x;
}
for(int i=Head[x];i;i=e1[i].next)
{
int v=e1[i].v;
if(vis[v])e1[i].lca=e1[i^1].lca=fid(v);
}
}
signed main()
{
n=read(),m=read(),s=read();
for(int i=1;i<=n;i++)fa[i]=i;
for(int i=1;i<=n-1;i++)
{
int u=read(),v=read();
add(u,v);
add(v,u);
}
for(int i=1;i<=m;i++)
{
int u=read(),v=read();
Add(u,v);
Add(v,u);
}
DFS(s,0);
for(int i=2;i<=cnt1;i+=2)
cout<<e1[i].lca<<endl;
return 0;
}
/*
6 1 6
6 4
3 1
2 4
5 1
1 4
1 2
*/

樹鏈剖分
以後我會重修的
首先我們就是要進行兩遍 dfs 把 \(dep,f,siz,son,top\) 陣列給處理出來,他們分別表示當前點的深度,當前點的父節點,以當前點為根的子樹大小,當前點的重兒子編號,當前點所在的鏈的鏈頭元素。
我們處理完之後,我們根據兩點的深度大小來往上跳,和倍增一樣,我們要防止跳超了,所以跳完以後兩個點的 \(top\) 陣列相等就說明已經有一個點的鏈頭元素為兩個點的 LCA,然後我們直接返回即可。
注意在跳的時候並不用保證誰比誰深度大,因為跳的時候是兩個交替著跳,所以沒必要
code:
#include <bits/stdc++.h>
#define N 1000100
#define endl '\n'
using namespace std;
struct sb{int u,v,next;}e[N];
int dep[N],fa[N],siz[N],head[N],son[N],rt,n,m,cnt,top[N];
inline void add(int u,int v){e[++cnt].u=u;e[cnt].v=v;e[cnt].next=head[u];head[u]=cnt;}
inline int read(){int x=0,f=1;char ch=getchar();while(!isdigit(ch)){f=ch!='-';ch=getchar();}while(isdigit(ch)){x=(x<<1)+(x<<3)+(ch^48);ch=getchar();}return f?x:-x;}
inline void dfs1(int x,int deep,int f)
{
dep[x]=deep;fa[x]=f;siz[x]=1;
int maxn=-1;
for(int i=head[x];i;i=e[i].next)
{
if(e[i].v!=f)
{
dfs1(e[i].v,deep+1,x);
siz[x]+=siz[e[i].v];
if(siz[e[i].v]>maxn)maxn=siz[e[i].v],son[x]=e[i].v;
}
}
return ;
}
inline void dfs2(int x,int tp)
{
top[x]=tp;
if(!son[x])return ;
dfs2(son[x],tp);
for(int i=head[x];i;i=e[i].next)
if(e[i].v!=fa[x]&&e[i].v!=son[x])dfs2(e[i].v,e[i].v);
return ;
}
inline int LCA(int x,int y)
{
while(top[x]!=top[y])
{
if(dep[top[x]]>=dep[top[y]])x=fa[top[x]];
else y=fa[top[y]];
}
return dep[x]<dep[y]?x:y;
}
signed main()
{
n=read();m=read(),rt=read();
for(int i=1;i<=n-1;i++)
{
int u=read(),v=read();
add(u,v);add(v,u);
}
dfs1(rt,0,rt);
dfs2(rt,rt);
for(int i=1;i<=m;i++)cout<<LCA(read(),read())<<endl;
return 0;
}

其他演演算法
由於本人實在太弱所以只整理了前面的三種
其實也可以用 DFS 序來求 LCA,可以去看看魏老師的部落格:https://www.luogu.com.cn/blog/AlexWei/leng-men-ke-ji-dfs-xu-qiu-lca
也可以用尤拉序來求 LCA,比如:https://www.luogu.com.cn/blog/shenhy1205/solution-p3379
或者轉化為 RMQ 問題求解:https://www.cnblogs.com/cj-xxz/p/11142232.html
或者用 LCT :https://www.luogu.com.cn/blog/surf/solution-p3379