巨量資料架構(一)背景和概念
-系列目錄-
一、背景
1.崗位現狀
巨量資料在一線網際網路已經爆發了好多年,2015年-2020年(國內網際網路爆發期)那時候的巨量資料開發,剛畢業能寫Hive SQL設定個離線任務、整個帆軟報表都20K+起步。如果做到架構師,50K跑不掉。現在市場迴歸理性後:
- 普通崗:巨量資料/數倉開發,實際上除超一線城市之外,尚存很多大型企業轉型期資訊化、網際網路(物聯網IOT)還在發展,資料還在爆發式增長,仍大有可為。
- 精英崗/管理崗:巨量資料總監/架構師,在重視資料的企業(一線網際網路大廠、資料服務廠商),年包上百萬也不少。
2.行業現狀
資料架構在過去20年發展迅速,尤其是過去十年,幾乎每年都有新概念、新產品開源出來。一些新名詞爆發式展現出來:資料倉儲、資料市集、巨量資料、離線數倉、實時數倉、時空資料庫、資料中臺、資料湖、流批一體、湖倉一體、實時湖倉、商業智慧(BI)等等。
- 資料精細化:從經營與分析轉為資料化的精細運營,對資料要求過程化、粒度更細。
- 產品多樣性:傳統 BI 中的 Report、OLAP 等工具開始轉向面向終端使用者自助式、半自助的產品,來快速獲取資料並分析得到結果。
- 資料時效性:從 T+1 轉為近乎實時的資料訴求。
- 平臺輕薄化:阿里自砍中臺戰略,把中臺拆分到各條業務線部門獨自負責。把中臺變得輕薄,更貼近業務。資料只有貼近業務才能煥發活力。底層邏輯是某業務領域的中心化是推薦的,有價值的。
3.本文目標
本系列文章不做原始碼級分析巨量資料框架,而是關注巨量資料的發展歷史、主流架構和原理、落地流程。可作為架構師對於巨量資料架構的掃盲貼。(筆者花了2月的時間閱讀大量文章總結出來的,可能會有問題,歡迎留言交流。)
二、概念解析
前面說了巨量資料領域出了很多概念:資料倉儲、資料市集、巨量資料、離線數倉、實時數倉、時空資料庫、資料中臺、資料湖、流批一體、湖倉一體、實時湖倉。我們就來簡單解析一下這些"專業名詞",從概念上達成一致,有一個基本的定位。
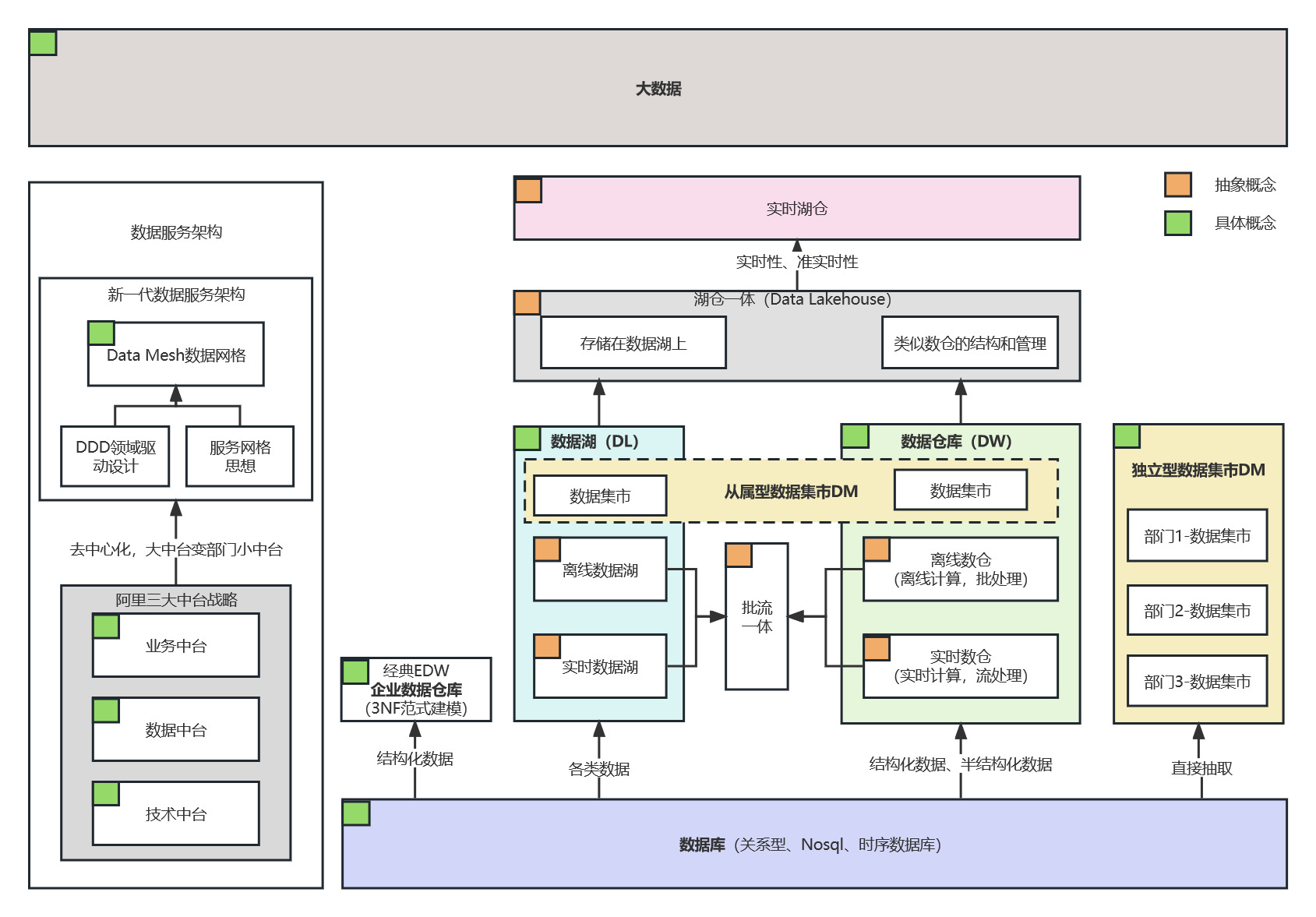
如上圖所示,這些巨量資料領域的名詞,我們可以分為2大類:1.資料服務架構相關 2.資料庫、數倉相關。其中綠色角標標識具體概念的,黃色角標標識抽象概念的。
1.巨量資料:廣義上的巨量資料概念,涵蓋資料服務、資料倉儲領域的概念。
1.資料服務架構相關:
- 資料中臺:歸屬阿里三大中臺戰略。但2023年4月馬雲回國後,將公司按照業務線拆分,各付盈虧。同時中臺也同步拆分到各業務中去,原中臺只保留偏底層的少量系統。由此可見,中臺可能去中心化,大中臺變部門小中臺,更貼近業務,盤活資料。
- Data Mesh資料網格:基於DDD領域驅動設計和服務網格思想的資料架構,可能會熱度增加,但落地尚早。(國內service mesh都還沒熱起來,按照慣性data mesh最少3年後再說)。
2.資料倉儲架構相關:
1.具體概念
- 資料庫 :按照資料結構來組織、儲存和管理資料的倉庫。
- 資料倉儲:抽取或匯入結構化/半結構化資料,主要用於OLAP資料分析,支援管理決策。上世紀90年代,強制使用結構化資料+正規化建模,構建EDW企業資料倉儲。
- 資料市集:資料市集(Data Mart),也叫資料市場,是資料倉儲的一個子集(部門級業務)。按照抽取方式可分為兩類:1)獨立型資料市集:直接從源資料抽取業務資料。2)從屬型資料市集:從資料倉儲/資料湖抽取。
- 資料湖 :以原始型別儲存資料的儲存系統。倡導:先匯入,後處理分析使用。
2.抽象概念(邏輯概念)
- 離線數倉:資料倉儲的延伸邏輯概念,描述的是批次處理(離線計算)場景。
- 實時數倉:資料倉儲的延伸邏輯概念,描述的是實時處理(實時計算)場景。
- 批流一體: 巨量資料的資料淨化ETL,可簡單分為2類:批次處理(離線任務)、流計算(實時計算)。批流一體講究用一套技術方案實現2種目標。
- 湖倉一體:資料在資料湖和數倉中流動,兼具數倉的穩定性建模和資料湖的靈活特性。
- 實時湖倉:強調實時計算能力的湖倉一體架構。
2.1 資料庫
資料庫是「按照資料結構來組織、儲存和管理資料的倉庫」。資料庫有很多種型別適用不同業務場景,最常見的是關係型資料庫、鍵值型資料庫、時序資料庫。
2.1.1 關係型資料庫
支援事務ACID特性的資料庫。常見的有Mysql、Oracle、PostgresSQL等。2.1.2 非關係型資料庫
- 檔案型資料庫(Document databases):MongoDB。優點是對資料結構要求不特別的嚴格。而缺點是查詢性的效能不好。
- 鍵值型資料庫(Key-value databases):Redis、Memcached,常用於快取方案。
- 列資料庫(Column-family databases):以列族的形式儲存資料,如Apache Cassandra、HBase。優點是查詢快速。缺點是資料結構有侷限性。
- 時間序列資料庫(Time-series databases):專門用於儲存時間序列資料,如InfluxDB、OpenTSDB。目前時序巨量資料儲存場景很多,前景極大,處於上升期。
2.2 資料倉儲
2.2.1 資料倉儲
資料倉儲是Bill Inmon在1991年出版的「Building the Data Warehouse」一書中所提出的定義被廣泛接受:資料倉儲(Data Warehouse)是一個面向主題的(Subject Oriented)、整合的(Integrated)、相對穩定的(Non-Volatile)、反映歷史變化(Time Variant)的資料集合,用於支援管理決策(Decision Making Support)。
- 面向主題的:根據使用者的需求,將來自不同資料來源的資料圍繞著各種主題進行分類整合。
- 整合的:來自各種資料來源的資料按照統一的標準整合於資料倉儲中。
- 相對穩定的:資料倉儲中的資料是一系列的歷史快照,不允許修改或刪除,只涉及資料查詢。
- 反映歷史變化的 :資料倉儲會定期接收新的整合資料,從而反映出最新的資料變化。
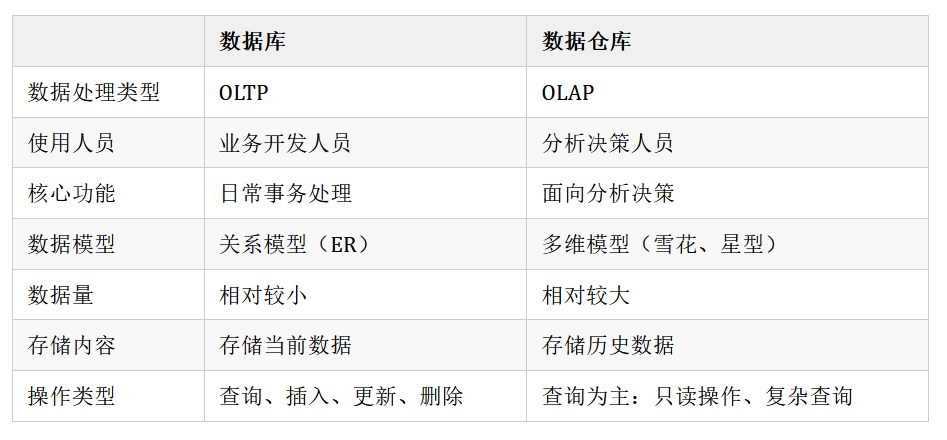
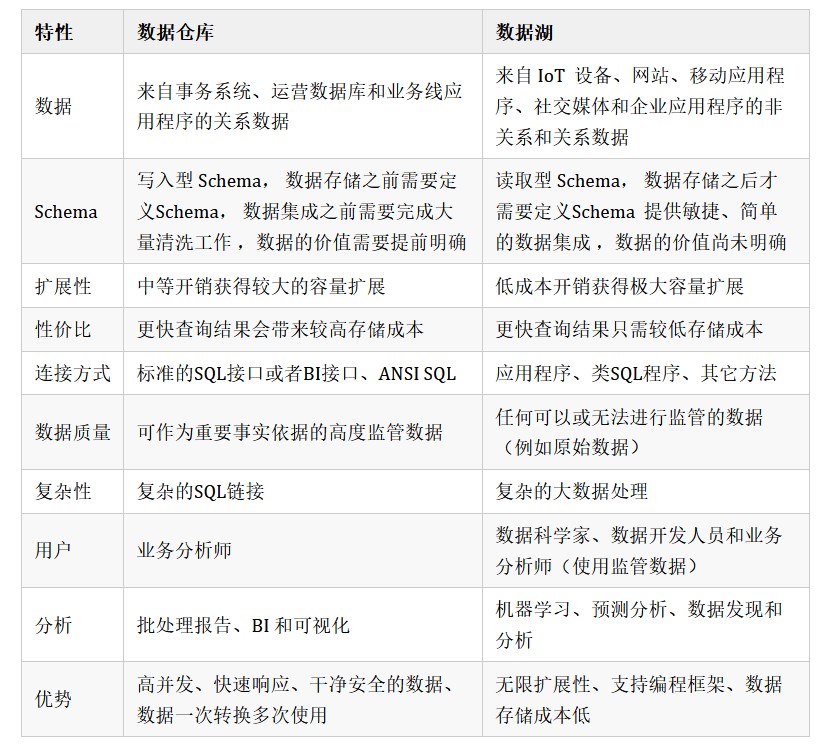
2.2.2 資料倉儲VS資料庫
2.2.3 企業資料倉儲EDW
EDW也是一種資料倉儲DW。上世紀90年代,使用結構化資料+3NF正規化建模,構建EDW企業資料倉儲。
2.2.4 離線數倉
2003~2006年 Google發表了三篇論文:分散式檔案系統GFS、分散式計算框架MapReduce、分散式儲存系統BigTable。2006年,Hadoop正式面世。此後,以Hadoop技術棧為代表的離線數倉架構引領巨量資料發展了十多年。這時候的處理任務基本都是批次處理任務。離線數倉特指:應對批次處理(離線計算)場景的資料倉儲。如下圖所示:
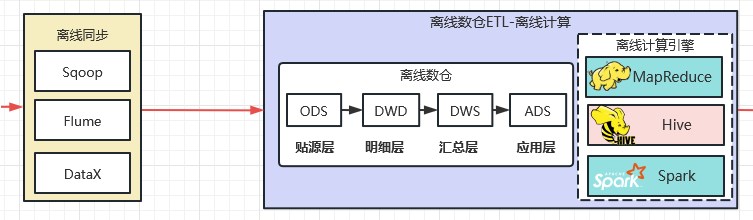
早期離線數倉使用離線計算引擎實現批次處理資料。最常用的離線計算引擎就是Hive(Hadoop技術體系)。典型應用是定時任務跑批生成報表資料。
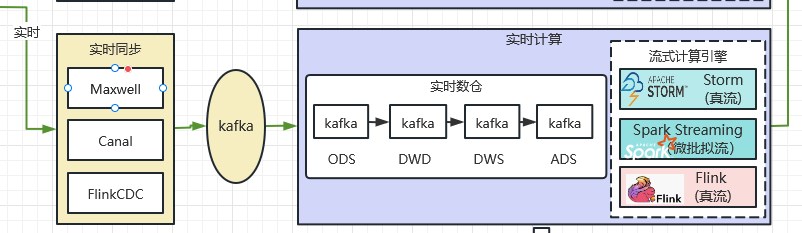
2.2.5 實時數倉
2014年,Flink為代表的實時計算風靡,基於Flink為計算引擎的實時數倉躍然紙上。實時數倉特指:應對實時處理(實時計算)場景的資料倉儲。典型的實時數倉如下圖所示:
2.3 資料市集
資料市集(Data Mart),也叫資料市場,就是滿足特定的部門或者使用者的需求,按照多維的方式進行儲存,包括定義維度、需要計算的指標、維度的層次等,生成面向決策分析需求的資料立方體。
按照抽取方式可分為兩類:
1)獨立型資料市集:直接從源資料抽取業務資料。
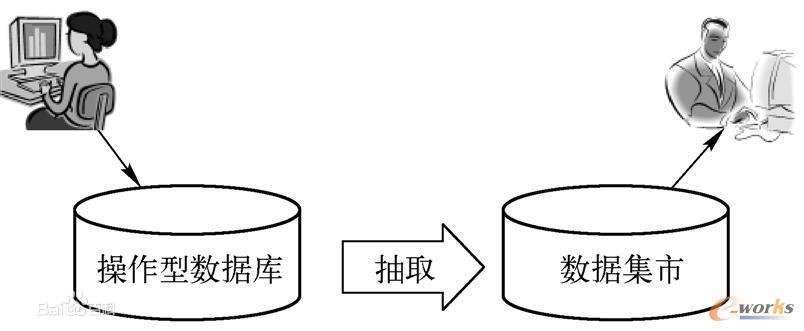
2)從屬型資料市集:從資料倉儲/資料湖抽取。
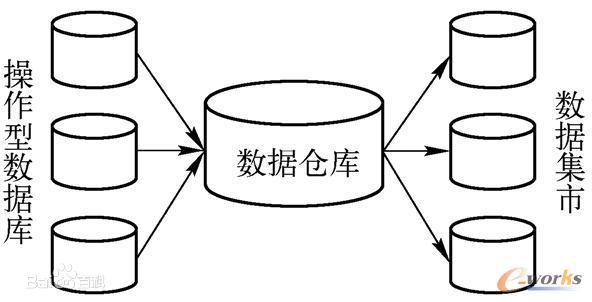
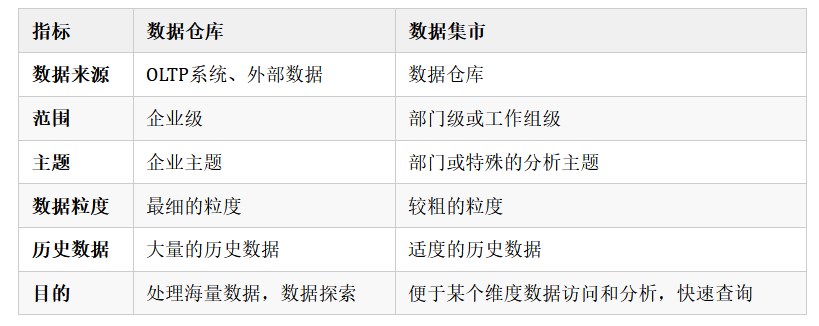
資料倉儲VS資料市集
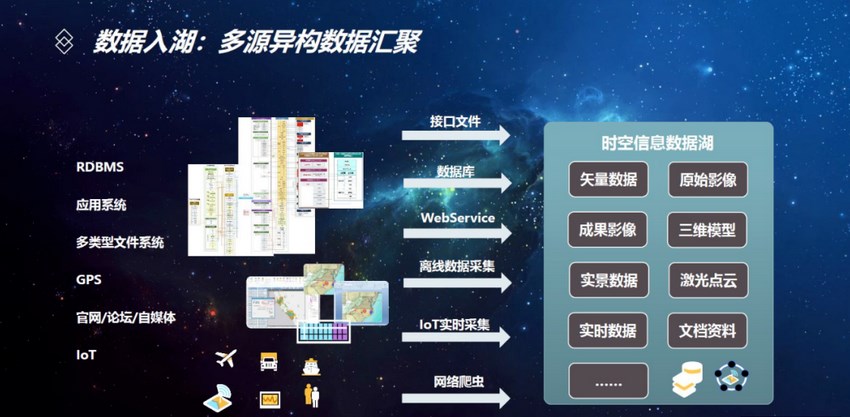
2.4 資料湖
2.4.1 資料湖
隨著網際網路->行動網際網路->IOT物聯網 這一條商業智慧發展線路的改變,產生了大量的照片、視訊、檔案等非結構化資料、時序資料。資料湖誕生了:允許使用者以任意規模儲存所有結構化和非結構化資料,並支援對資料進行快速加工和分析。使用者可以按原樣儲存資料(無需先對資料進行結構化處理),並執行不同型別的分析(從控制面板和視覺化到巨量資料處理、實時分析和機器學習,以指導做出更好的決策。
2.4.2 資料倉儲VS資料湖
資料倉儲的成長性很好,而資料湖更靈活。資料倉儲支援的資料結構種類比較單一,資料湖的種類比較豐富,可以包羅萬象。資料倉儲更加適合成熟的資料當中的分析和處理,資料湖更加適合在異構資料上的價值的挖掘。
=========參考=============
How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh
如果你覺得本文對你有點幫助的話,記得在右下角點個「推薦」哦,博主在此感謝!