vivo 推播系統的容災建設與實踐
作者:vivo 網際網路伺服器團隊 - Yu Quan
本文介紹了推播系統容災建設和關鍵技術方案,以及實踐過程中的思考與挑戰。
一、推播系統介紹
vivo推播平臺是vivo公司向開發者提供的訊息推播服務,通過在雲端與使用者端之間建立一條穩定、可靠的長連線,為開發者提供向用戶端應用實時推播訊息的服務,支援百億級的通知/訊息推播,秒級觸達移動使用者。
推播系統主要由接入閘道器,邏輯推播節點,長連線組成,長連線負責與使用者手機終端建立連線,及時把訊息送達到手機終端。
推播系統的特點是並行高、訊息量大、送達及時性較高。
vivo推播系統現狀最高推播速度140w/s,單日最大訊息量200億,端到端秒級線上送達率99.9%。同時推播系統具備不可提前預知的突發大流量特點。針對推播系統高並行,高時效,突發流量等特點,如何保證系統可用性呢?本文將從系統架構,儲存容災,流量容災三個方面進行講述,推播系統是如何做容災的。
二、系統架構容災方案
2.1 長連線層容災
長連線是推播系統最重要的部分,長連線的穩定性直接決定了推播系統的推播質量和效能,因此,需要對長連線層做好容災和實時排程能力。
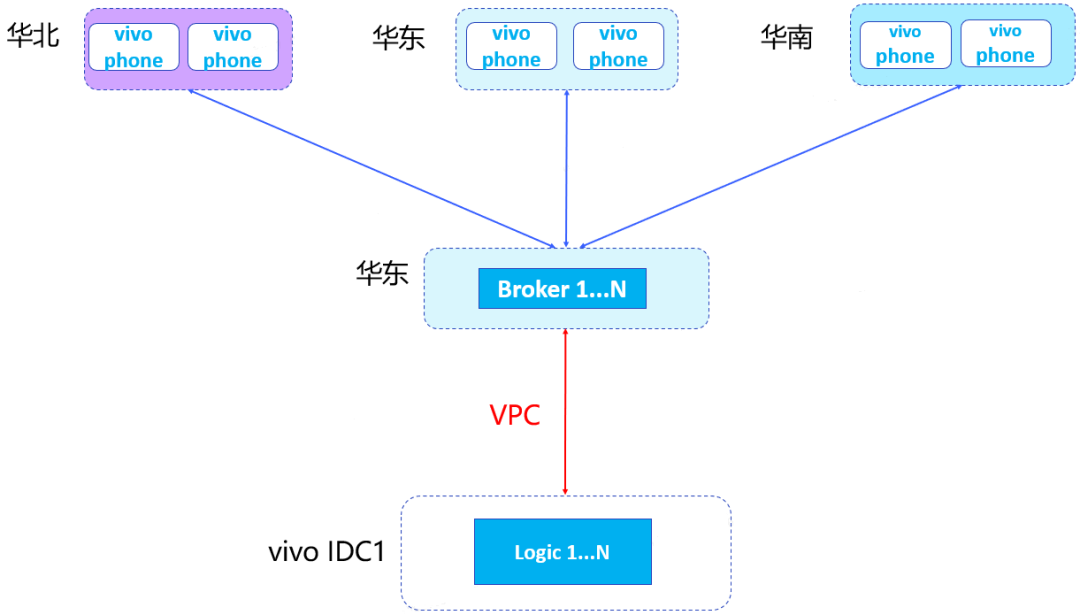
原有推播系統架構是長連線層都部署在華東,所有vivo IDC邏輯節點通過VPC與華東的Broker建立連線,手機端跟華東的broker進行長連線通訊。這種部署方式存在以下問題。
-
問題一:華北、華南手機都需要連線華東的Broker,地域跨度大,長連線網路穩定性和時效性相對較差。
-
問題二:邏輯層跟華東的Broker之間由一條VPC連線,隨著業務的發展,推播流量越來越大,頻寬會出現瓶頸,有超限丟包的風險。另外當該VPC出現故障時,會造成全網訊息無法送達。
注:長連線層節點名為Broker。
原始長連線架構圖:
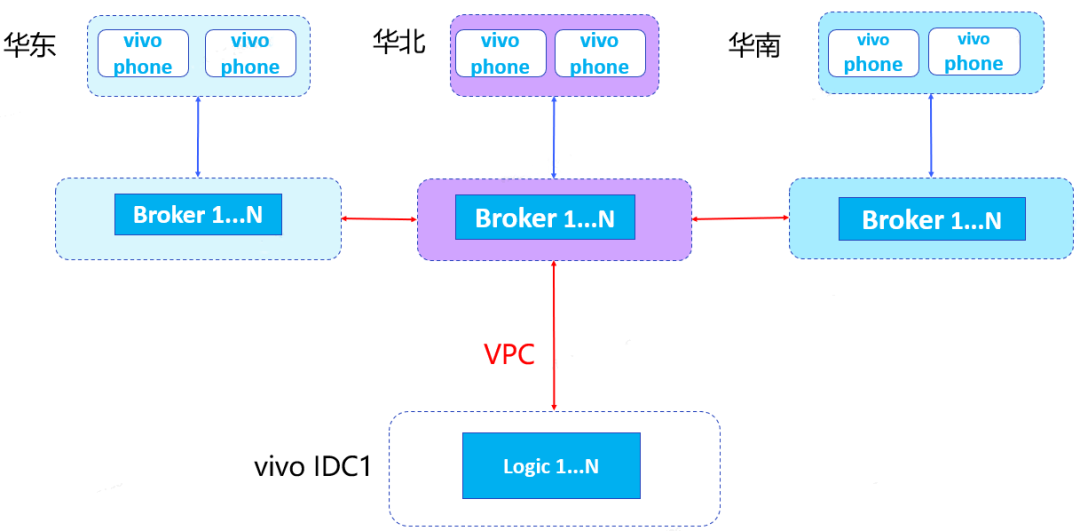
基於以上架構存在問題,進行了優化,將Broker進行三地部署,分別部署在華北,華東,華南。
華北、華東、華南三地使用者採用就近接入方式。
優化後的架構,不僅可以保證長連線網路穩定性和時效性。同時具有較強的容災能力,華東,華南Broker通過雲網跟華北Broker連線,華北Broker通過VPC與vivo IDC連線。當華北、華東、華南某個地區Broker叢集故障或者公網故障,不會影響到全網裝置收發訊息。但是這種方式還是存在一個問題,就是某個地區Broker叢集故障或者公網故障,會出現該區域部分裝置無法收到推播訊息的情況。
三地部署後的架構圖:
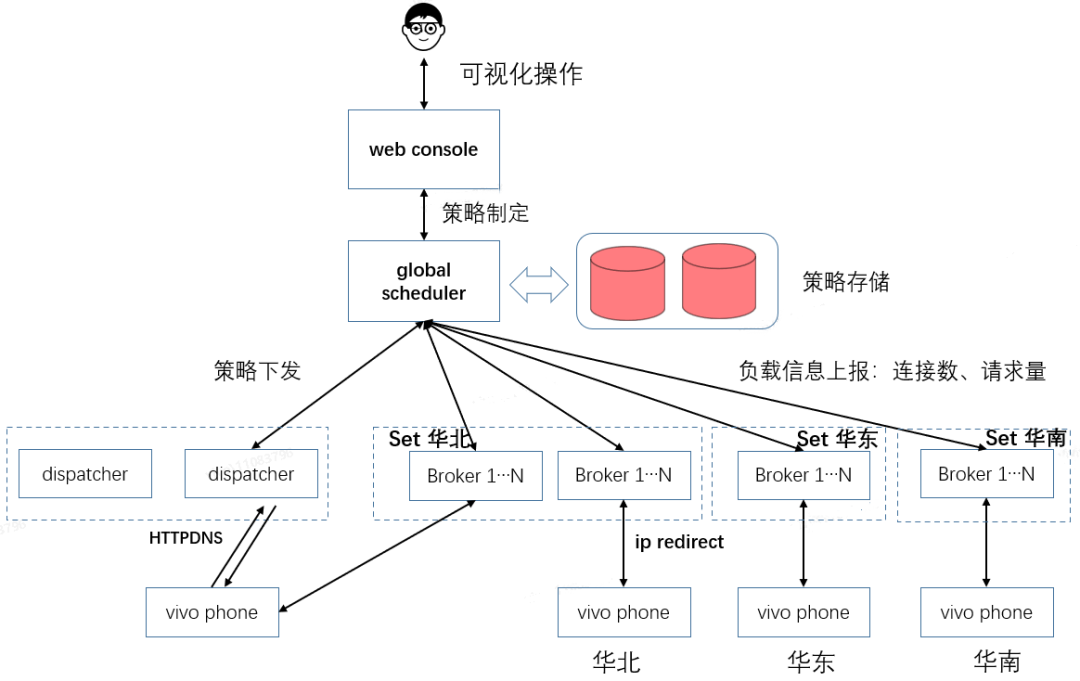
針對上述單個地區異常導致該區域部分裝置無法收到推播訊息的問題,我們設計了一套流量排程系統,可以做到實時流量排程和切換。global scheduler節點負責策略排程和管理。
vivo phone進行註冊時,dispatcher會下發多個地區的ip地址,預設情況下,進行就近連線。單多次連線失敗後,嘗試連線其他ip。當某個地區Broker出現長連線數瓶頸或者VPC出現故障,可以通過global scheduler節點下發策略,讓該故障地區的裝置重新從dispatcher獲取新的ip集的ip,與其他地區Broker建立長連線,邏輯節點下發訊息到重連後的Broker。等到該地區恢復後,可以重新再下發策略,進行回撥。
流量排程系統圖:
2.2 邏輯層容災
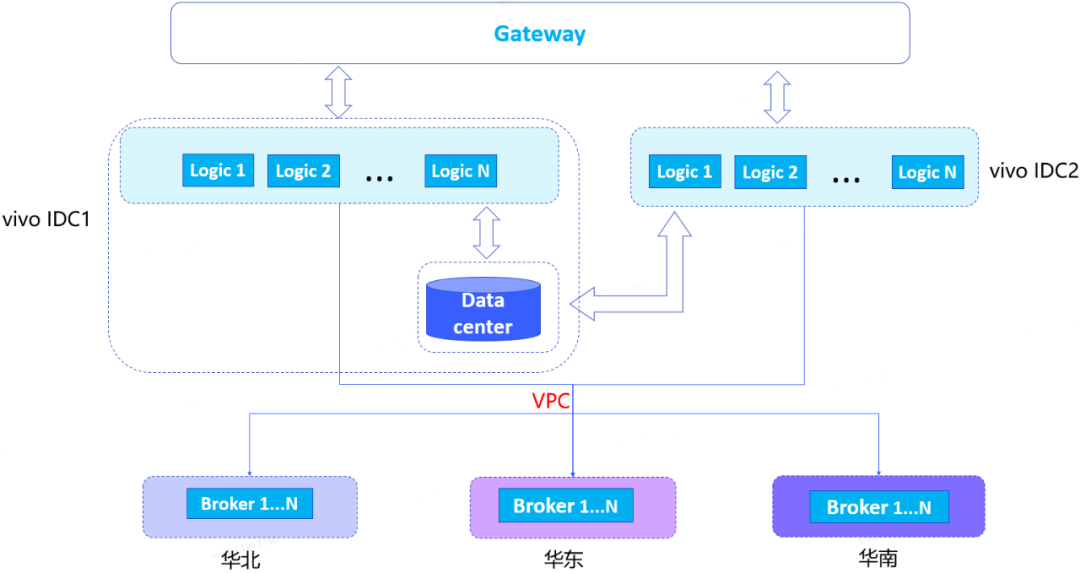
長連線層做好容災後,邏輯層也需要做相應容災。之前我們邏輯層都部署在一個機房,不具備機房機容災能力,當一個機房出現斷電風險,會出現服務整體不可用問題,因此我們做"同城雙活"部署方案改造。
邏輯層單活架構:
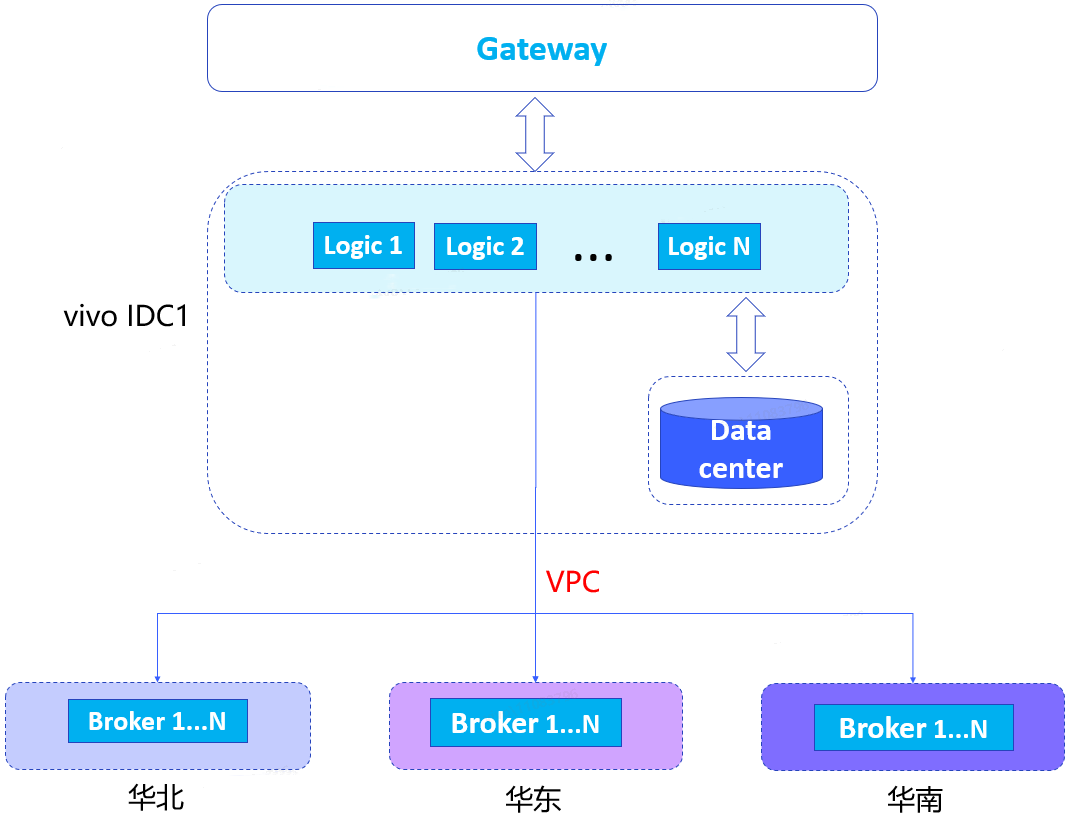
邏輯層分別在vivo IDC1和vivo IDC2進行部署,閘道器層根據路由規則將流量按照一定比例分別下發到兩個IDC,實現邏輯層同城雙活。我們發現,資料中心還是隻有一個,部署在vivo IDC1,根據成本、收益,以及多資料中心資料同步延遲問題綜合考慮,資料中心暫時還是以單資料中心為主。
邏輯層雙活架構:
三、 流量容災方案
做好系統架構的容災能力後,推播系統的閘道器層還需要應對突發流量做相應的應對措施,做好流量控制,保證系統穩定性。歷史上,我們曾經因為熱點和突發新聞事件,並行推播流量巨大,導致服務出現異常,可用性降低問題。
如何應對突發大流量,保證突發流量的情況下,系統可用性不變,同時能兼顧效能和成本。為此,我們分別對比了設計了以下兩種方案。
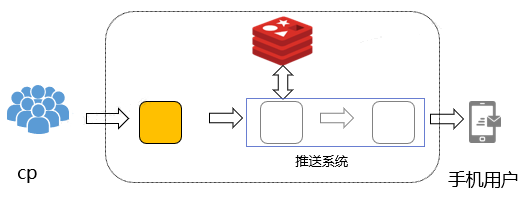
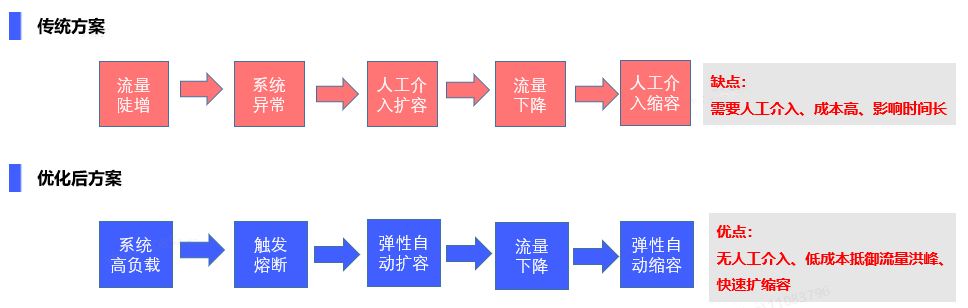
常規的方案是一般是根據歷史情況估算冗餘部署大量機器,來應對突發流量。單這種方式成本較高,突發流量可能只持續5分鐘或更短時間,而系統為了滿足5分鐘突發流量,需要冗餘部署大量機器。一旦流量超過了部署機器可承擔的上限,無法及時擴容,可能導致可用性下降,甚至出現雪崩效應。
傳統方案下的推播架構:
那如何設計一套既可以控制成本,面對突發大流量彈性擴容,又保證訊息不漏併兼顧推播效能的方案呢?
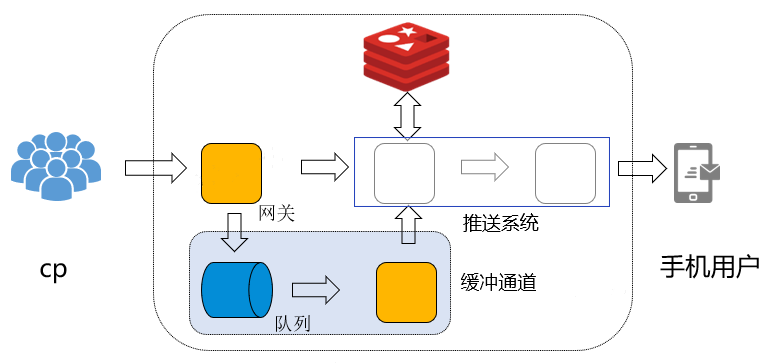
優化方案:在原有架構的基礎上,在接入層增加緩衝通道,當流量洪峰到來時,對於系統可處理的上限能力外的流量,打入緩衝佇列。通過訊息佇列形式,增加bypass接入層,限速消費訊息佇列。在流量洪峰過去後,提升bypass消費速度,處理快取佇列訊息。bypass接入層通過docker部署,支援動態擴縮容,預設最小化叢集,當訊息佇列積壓很多,並且下游有能力處理時,提升消費速度,bypass根據CPU負載動態擴容,快速消費訊息佇列。處理完畢後動態縮容。
訊息佇列:選用吞吐量較大的KAFKA中介軟體,並且與離線計算KAFKA叢集共用,能充分利用資源。
bypass接入層:採用docker部署,支援根據CPU負載和時間動態擴縮容。預設最小叢集部署。對於已知的流量高峰時段,可以提前擴容服務,保證流量快速處理。未知時段流量高峰,可以bypass接入層,根據CPU負載情況進行動態擴縮容。
增加快取佇列後的推播架構:
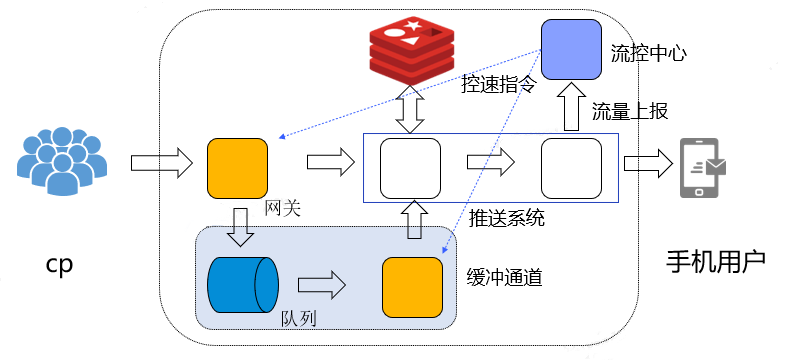
進行上述改造後,還存在一個問題,就是如何進行接入層全域性控速。我們採用的方式是收集下游推播節點的推播流量情況,比如:流量達到系統可承受上限的80%時下發限速指令,調整接入層推播速度。讓訊息先積壓在訊息佇列,等到下游流量降低之後,下發解除限速指令,讓bypass接入層加速消費訊息佇列,進行推播。
增加控速後的推播架構:
優化後方案與傳統方案對比:
四、儲存容災方案
做好並行流量控制後,能很好的預發突發熱點問題。推播系統內部,由於使用Redis叢集快取訊息,出現過因為Redis叢集故障導致訊息無法及時送達問題。因此,我們考慮對Redis叢集做相關容災方案設計,實現系統在Redis叢集故障期間,也能及時推播訊息並保證訊息不丟失。
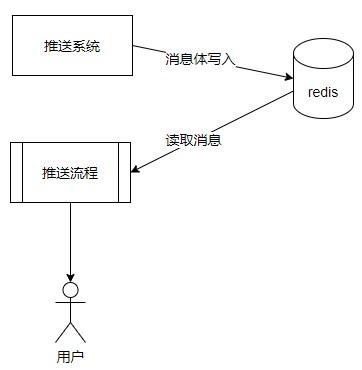
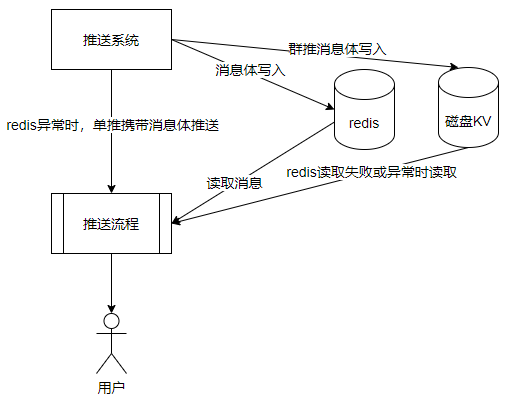
推播訊息體快取在Redis叢集中,推播時從Redis中獲取訊息體,如果Redis叢集宕機,或者記憶體故障,會導致離線訊息體丟失。
原有訊息流程:
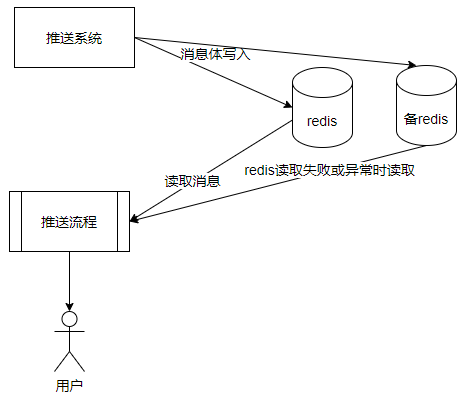
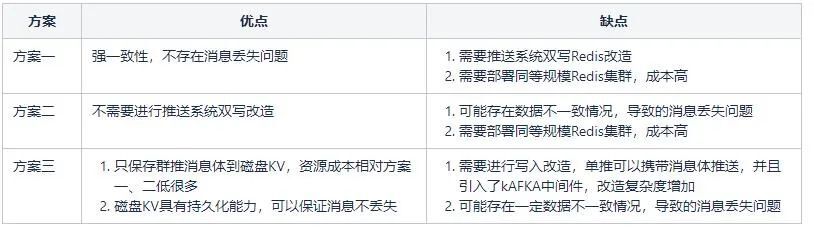
方案一:引入另一個對等Redis叢集,採用推播雙寫方式,雙寫兩個Redis叢集。該方案需要冗餘部署規模對等的備Redis叢集。推播系統需要雙寫Redis操作。
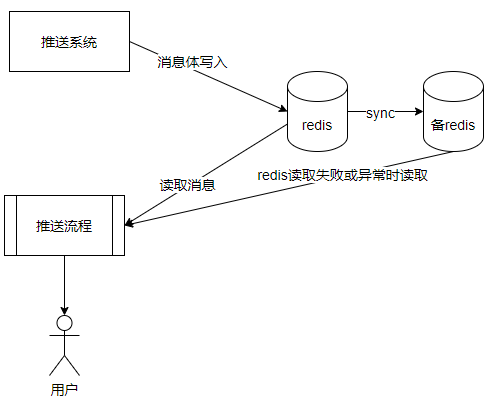
方案二:原有Redis叢集,採用RDB+AOF方式同步到另一個備Redis叢集。該方案不再需要推播系統雙寫Redis改造,直接利用將原有Redis叢集資料同步到另一個備Redis叢集。也需要冗餘部署規模對等的備Redis叢集。可能存在部分資料同步延遲導致推播失敗問題。
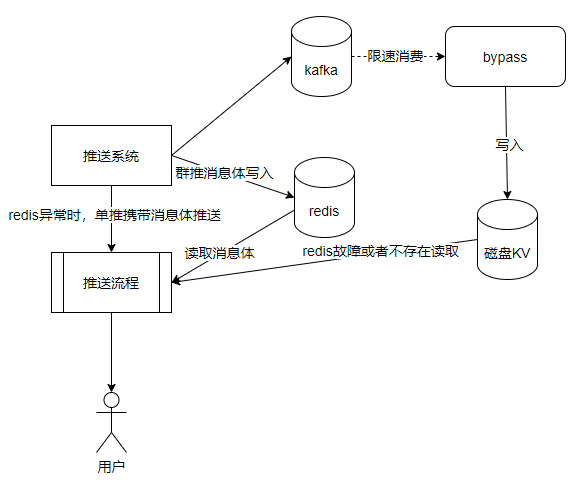
方案三:應用另一個分散式儲存系統,磁碟KV,相容Redis協定,同時具有持久化能力。可以保證訊息體不丟失。但是為了節省成本,不再直接使用Redis叢集對等資源。而是根據推播特點,推播分為單推、群推。單推是一對一推播,一個使用者一條訊息體。群推是一對多推播,一個訊息體對應多個使用者。群推往往是任務級別推播。因此我們使用一個相對小一些的磁碟KV叢集,主要用於冗餘儲存,群推訊息體,即任務級別的訊息。對於單推,還是隻儲存到Redis中,不進行冗餘儲存。
如果Redis叢集故障,對於單推訊息,推播系統可以攜帶訊息體往下游推播,確保訊息可以繼續下發。對於群推訊息,因為訊息體冗餘儲存在磁碟KV中,當Redis叢集故障後,可以降級到讀取磁碟KV。
方案三還存在一個問題,就是磁碟KV的寫入效能和Redis叢集不是一個數量級,特別是時延,磁碟KV在平均在5ms左右。而Redis叢集卻在0.5ms。如果在推播系統對群推訊息體進行雙寫。這個時延是不能接受的。因此只能採用非同步寫入磁碟KV的方式。這裡將備份群推訊息體,先寫入訊息中介軟體KAFKA,由bypass節點消費KAKFA進行非同步寫入磁碟KV。這樣在使用的災備磁碟KV資源較少的前提下,保證推播系統的高並行能力,同時可以保證群推訊息體不丟失,Redis異常時,單推訊息攜帶訊息體推播,群推訊息體讀取磁碟KV。
儲存容災方案對比:
五、總結
本文從系統架構容災、流量容災、儲存容災三個方面講述了推播系統容災建設過程。系統容災需要根據業務發展,成本收益,實現難度等多方面考慮。
當前我們長連線層已具備三地部署,邏輯層具備同城雙活,資料中心為單資料中心。後續我們會持續研究和規劃雙資料中心,兩地三中心部署架構方式來逐步加強推播系統容災能力。