語音處理加窗分幀
語音處理加窗分幀
一、分幀
語音資料和視訊資料不同,本沒有幀的概念,但是為了傳輸與儲存,我們採集的音訊資料都是一段一段
的。為了程式能夠進行批次處理,會根據指定的長度(時間段或者取樣數)進行分段,結構化為我們程式設計
的資料結構,這就是分幀。
二、幀移
由於我們常用的訊號處理方法都要求訊號是連續的,也就說必須是訊號開始到結束,中間不能有斷開。然
而我們進行取樣或者分幀後資料都斷開了,所以要在幀與幀之間保留重疊部分資料,以滿足連續的要求,
這部分重疊資料就是幀移。
三、加窗
介紹幀移的時候我們說了,我們處理訊號的方法都要求訊號是連續條件,但是分幀處理的時候中間斷開
了,為了滿足條件我們就將分好的幀資料乘一段同長度的資料,這段資料就是窗函數整個週期內的資料,
從最小變化到最大,然後最小。
四、濾波
我們知道,我們處理的語音其實是一種聲波,聲波是一種物質波。濾波的字面意思理解為過濾一些不同頻
率的波。根據傅立葉變換,我們知道任意波可以分解為幾種正弦波和餘弦波的疊加,從概率論的角度,濾
波即加權。 濾波的作用就是給不同的訊號分量不同的權重。最簡單的loss pass filter, 就是直接把低
頻的訊號給0權重,而給高頻部分1權重。對於更復雜的濾波,比如維納濾波, 則要根據訊號的統計知識來
設計權重。
當允許訊號中較高頻率的成分通過濾波器時,這種濾波器叫做高通濾波器。
當允許訊號中較低頻率的成分通過濾波器時,這種濾波器叫做低通濾波器。
當只允許訊號中某個頻率範圍內的成分通過濾波器時,這種濾波器叫做帶通濾波器。
當不允許訊號中某個頻率範圍內的成分通過濾波器時,這種濾波器叫做帶阻濾波器。
五、降噪
從統計訊號處理的角度,降噪可以看成濾波的一種。降噪的目的在於突出訊號本身而抑制噪聲影響。從這
個角度,降噪就是給訊號一個高的權重而給噪聲一個低的權重。維納濾波就是一個典型的降噪濾波器。
六、合成
在語音處理過程,先分幀,再在頻域分成各個子帶處理,處理後轉成時域,合成語聲。從描述上看,
語音合成就是和分幀相反的過程,保證訊號資料經過我們變換處理後能夠回到原來的狀態。把每幀各個子
帶轉換成時間序列後相互疊加合成為一幀資料。
七、具體理解
1、為什麼要進行分幀加窗操作?
語音訊號為非平穩訊號,其統計屬性是隨著時間變化的,以漢語為例,一句話中包含很多生母和韻母,不同的拼音,發音的特點很明顯是不一樣的;但是,語音又具有但是平穩的屬性,比如漢語裡的一個聲母或者韻母,往往只會持續幾十到幾百毫秒,這一個發音單元裡,語音訊號表現出明顯的穩定性、規律性,在進行語音識別時,對於一句話識別的過程也是以較小的發音單元(音素、字、位元組)為單位進行識別的,因此可以用滑動窗來提取短時片段,也即進行分幀加窗操作。
2、如何進行分幀加窗操作?
2.1 相關術語
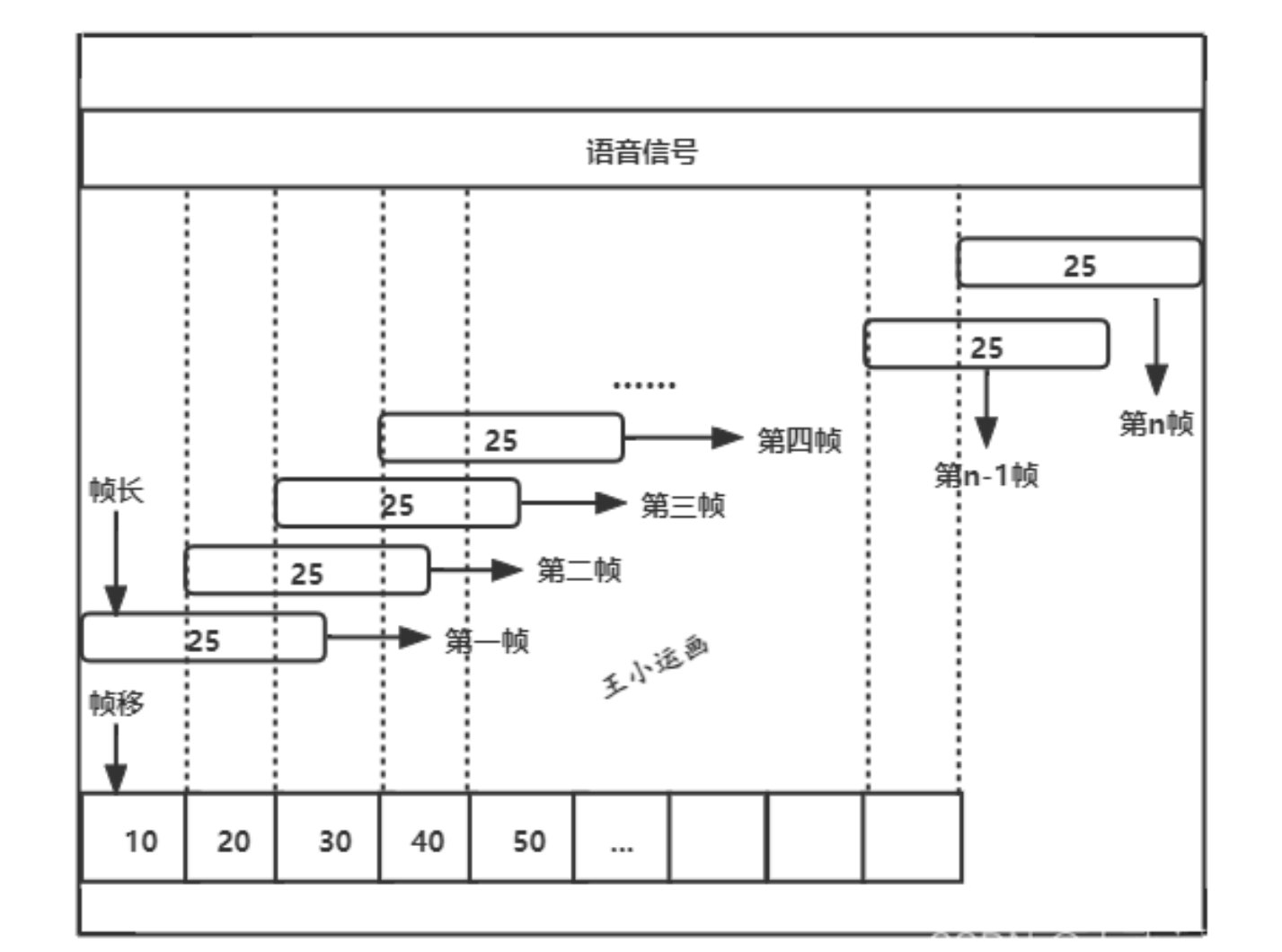
幀長:一幀語音訊號的長度,長度可以用多種方式表示,如果用時間表示,一幀訊號通常取在15ms-30ms之間,經驗值為25ms(論文上大多數人用)。幀長為25ms的一幀訊號指的是時長有25毫秒的語音訊號。也可以用訊號的取樣點數來表示,如果一個訊號的取樣率為16kHz,則一幀訊號由 16kHz * 25ms = 400個取樣點組成。
幀移:指的是每次分幀時移動的距離,以第一幀訊號的起始點開始移動一個幀移,開始下一幀。同樣也可以用兩種方式表示,用時間表示,常設為10ms,用取樣點表示,16kHz取樣率的訊號幀移一般為160個取樣點。
加窗:分幀後每一幀的開始和結束都會出現間斷,因此分割的幀越多,與原始訊號的誤差就越大,加窗就是為了解決這個問題,使成幀後的訊號變得連續,並且每一幀都會表現出周期函數的特性。常見的窗函數有:矩形窗、漢明窗、漢寧窗等,在語音訊號處理中,通常使用漢明窗,其公式如下:
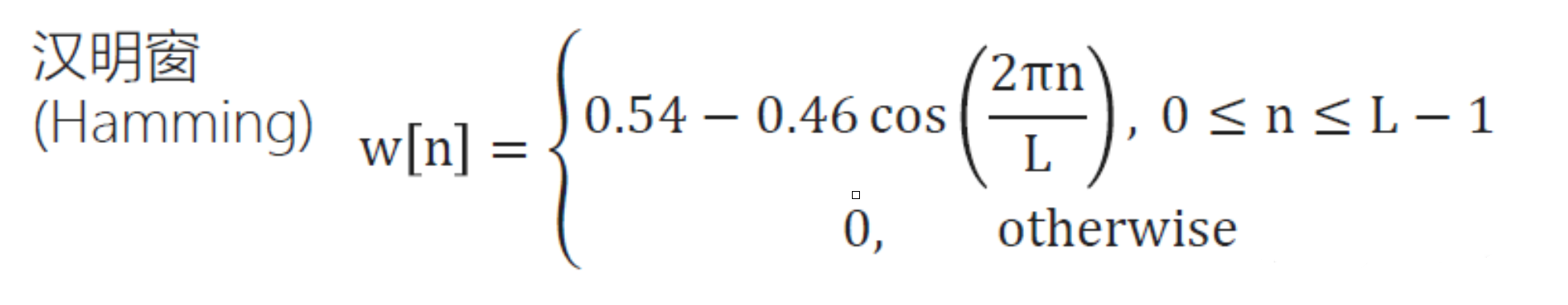
2.2 分幀加窗的具體操作
首先要根據訊號長度、幀移、幀長計算出該訊號一共可以分的幀數,幀數的計算公式如下:
幀數 = (訊號長度-幀長)➗幀移 +1
具體的分幀操作如下圖所示:
加窗操作比較簡單,僅需將分幀的每一幀訊號一次與窗函數進行相乘即可���其中窗函數可以從numpy裡直接呼叫。
在分幀操作時,會遇到最後剩下的訊號長度不夠一幀的情況,此時需要將對這一段訊號進行補零操作,使之達到一幀的長度,或者可以直接將之拋棄,因為最後一幀處於句子最末尾部分,大部分為靜音片段。
3 分幀加窗的程式碼實現
以下是實現分幀加窗的具體程式碼:
def enframe(signal, frame_len=frame_len, frame_shift=frame_shift, win=np.hamming(frame_len)):
"""
calculate the number of frames:
frames = (num_samples -frame_len) / frame_shift +1
"""
num_samples = signal.size
num_frames = np.floor((num_samples - frame_len) / frame_shift)+1
# calculate the numbers of frames
frames = np.zeros((int(num_frames),frame_len)) # (num_frames,frame_len)
# Initialize an array for putting the frame signals into it
for i in range(int(num_frames)):
frames[i,:] = signal[i*frame_shift:i*frame_shift + frame_len]
frames[i,:] = frames[i,:] * win
return frames
其中需要注意以下幾點:
- ①signal代表經過預加重後的訊號,frame_len為幀長,frame_shift為幀移。
- ②np.hamming(frame_len)實現了漢明窗函數。
- ③上面的程式碼中,如果計算出訊號長為5.2幀,則取為5幀,因為最後一幀一般都是靜音訊號,可以省略。初始化一個存放幀訊號的陣列frames,然後依次將- signal訊號裡的資料按照分幀操作賦值給frames。
- ④如果輸入訊號的取樣率為16kHz,幀長為400個取樣點,幀移為160個取樣點,則經過分幀加窗後得到的陣列的形狀為(幀數行,幀長列)。