ClickHouse主鍵索引最佳實踐
在本文中,我們將深入研究ClickHouse索引。我們將對此進行詳細說明和討論:
- ClickHouse的索引與傳統的關聯式資料庫有何不同
- ClickHouse是怎樣構建和使用主鍵稀疏索引的
- ClickHouse索引的最佳實踐
這篇文章主要關注稀疏索引,clickhouse主鍵使用的就是稀疏索引。
資料集
在本文中,我們將使用一個匿名的web流量資料集。
- 我們將使用樣本資料集中的887萬行(事件)的子集。
- 未壓縮的資料大小為887萬個事件和大約700mb。當儲存在ClickHouse時,壓縮為200mb。
- 在我們的子集中,每行包含三列,表示在特定時間(EventTime列)單擊URL (URL列)的網際網路使用者(UserID列)。
通過這三個列,我們已經可以制定一些典型的web分析查詢,如:
- 某個使用者點選次數最多的前10個url是什麼?
- 點選某個URL次數最多的前10名使用者是誰?
- 使用者點選特定URL的最頻繁時間(比如一週中的幾天)是什麼?
測試環境
本檔案中給出的所有執行時資料都是在帶有Apple M1 Pro晶片和16GB RAM的MacBook Pro上本地執行ClickHouse 22.2.1。
全表掃描
為了瞭解在沒有主鍵的情況下如何對資料集執行查詢,我們通過執行以下SQL DDL語句(使用MergeTree表引擎)建立了一個表:
CREATE TABLE hits_NoPrimaryKey
(
`UserID` UInt32,
`URL` String,
`EventTime` DateTime
)
ENGINE = MergeTree
PRIMARY KEY tuple();
接下來,使用以下插入SQL將命中資料集的一個子集插入到表中。這個SQL使用URL表函數和型別推斷從clickhouse.com載入一個資料集的一部分資料:
INSERT INTO hits_NoPrimaryKey SELECT
intHash32(c11::UInt64) AS UserID,
c15 AS URL,
c5 AS EventTime
FROM url('https://datasets.clickhouse.com/hits/tsv/hits_v1.tsv.xz')
WHERE URL != '';
結果:
Ok.
0 rows in set. Elapsed: 145.993 sec. Processed 8.87 million rows, 18.40 GB (60.78 thousand rows/s., 126.06 MB/s.)
ClickHouse使用者端輸出了執行結果,插入了887萬行資料。
最後,為了簡化本文後面的討論,並使圖表和結果可重現,我們使用FINAL關鍵字optimize該表:
OPTIMIZE TABLE hits_NoPrimaryKey FINAL;
NOTE
一般來說,不需要也不建議在載入資料後立即執行optimize。對於這個範例,為什麼需要這樣做是很明顯的。
現在我們執行第一個web分析查詢。以下是使用者id為749927693的網際網路使用者點選次數最多的前10個url:
SELECT URL, count(URL) as Count
FROM hits_NoPrimaryKey
WHERE UserID = 749927693
GROUP BY URL
ORDER BY Count DESC
LIMIT 10;
結果:
┌─URL────────────────────────────┬─Count─┐
│ http://auto.ru/chatay-barana.. │ 170 │
│ http://auto.ru/chatay-id=371...│ 52 │
│ http://public_search │ 45 │
│ http://kovrik-medvedevushku-...│ 36 │
│ http://forumal │ 33 │
│ http://korablitz.ru/L_1OFFER...│ 14 │
│ http://auto.ru/chatay-id=371...│ 14 │
│ http://auto.ru/chatay-john-D...│ 13 │
│ http://auto.ru/chatay-john-D...│ 10 │
│ http://wot/html?page/23600_m...│ 9 │
└────────────────────────────────┴───────┘
10 rows in set. Elapsed: 0.022 sec.
Processed 8.87 million rows,
70.45 MB (398.53 million rows/s., 3.17 GB/s.)
ClickHouse使用者端輸出表明,ClickHouse執行了一個完整的表掃描!我們的表的887萬行中的每一行都被載入到ClickHouse中,這不是可延伸的。
為了使這種(方式)更有效和更快,我們需要使用一個具有適當主鍵的表。這將允許ClickHouse自動(基於主鍵的列)建立一個稀疏的主索引,然後可以用於顯著加快我們範例查詢的執行。
包含主鍵的表
建立一個包含聯合主鍵UserID和URL列的表:
CREATE TABLE hits_UserID_URL
(
`UserID` UInt32,
`URL` String,
`EventTime` DateTime
)
ENGINE = MergeTree
PRIMARY KEY (UserID, URL)
ORDER BY (UserID, URL, EventTime)
SETTINGS index_granularity = 8192, index_granularity_bytes = 0;
為了簡化本文後面的討論,並使圖和結果可重現,使用DDL語句有如下說明:
-
通過ORDER BY子句指定表的複合排序鍵
-
通過設定設定控制主索引有多少索引項:
-
-
index_granularity: 顯式設定為其預設值8192。這意味著對於每一組8192行,主索引將有一個索引條目,例如,如果表包含16384行,那麼索引將有兩個索引條目。
-
- index_granularity_bytes
- 設定為0表示禁止
自適應索引粒度
。自適應索引粒度意味著ClickHouse自動為一組n行建立一個索引條目
- 如果n小於8192,但n行的合併行資料大小大於或等於10MB (index_granularity_bytes的預設值)或
- n達到8192
-
上面DDL語句中的主鍵會基於兩個指定的鍵列建立主索引。
插入資料:
INSERT INTO hits_UserID_URL SELECT
intHash32(c11::UInt64) AS UserID,
c15 AS URL,
c5 AS EventTime
FROM url('https://datasets.clickhouse.com/hits/tsv/hits_v1.tsv.xz')
WHERE URL != '';
結果:
0 rows in set. Elapsed: 149.432 sec. Processed 8.87 million rows, 18.40 GB (59.38 thousand rows/s., 123.16 MB/s.)
optimize表:
OPTIMIZE TABLE hits_UserID_URL FINAL;
我們可以使用下面的查詢來獲取關於表的後設資料:
SELECT
part_type,
path,
formatReadableQuantity(rows) AS rows,
formatReadableSize(data_uncompressed_bytes) AS data_uncompressed_bytes,
formatReadableSize(data_compressed_bytes) AS data_compressed_bytes,
formatReadableSize(primary_key_bytes_in_memory) AS primary_key_bytes_in_memory,
marks,
formatReadableSize(bytes_on_disk) AS bytes_on_disk
FROM system.parts
WHERE (table = 'hits_UserID_URL') AND (active = 1)
FORMAT Vertical;
結果:
part_type: Wide
path: ./store/d9f/d9f36a1a-d2e6-46d4-8fb5-ffe9ad0d5aed/all_1_9_2/
rows: 8.87 million
data_uncompressed_bytes: 733.28 MiB
data_compressed_bytes: 206.94 MiB
primary_key_bytes_in_memory: 96.93 KiB
marks: 1083
bytes_on_disk: 207.07 MiB
1 rows in set. Elapsed: 0.003 sec.
使用者端輸出表明:
- 表資料以wide format儲存在一個特定目錄,每個列有一個資料檔案和mark檔案。
- 表有887萬行資料。
- 未壓縮的資料有733.28 MB。
- 壓縮之後的資料有206.94 MB。
- 有1083個主鍵索引條目,大小是96.93 KB。
- 在磁碟上,表的資料、標記檔案和主索引檔案總共佔用207.07 MB。
針對海量資料規模的索引設計
在傳統的關聯式資料庫管理系統中,每個錶行包含一個主索引。對於我們的資料集,這將導致主索引——通常是一個B(+)-Tree的資料結構——包含887萬個條目。
這樣的索引允許快速定位特定的行,從而提高查詢點查和更新的效率。在B(+)-Tree資料結構中搜尋一個條目的平均時間複雜度為O(log2n)。對於一個有887萬行的表,這意味著需要23步來定位任何索引條目。
這種能力是有代價的:額外的磁碟和記憶體開銷,以及向表中新增新行和向索引中新增條目時更高的插入成本(有時還需要重新平衡B-Tree)。
考慮到與B-Tee索引相關的挑戰,ClickHouse中的表引擎使用了一種不同的方法。ClickHouseMergeTree Engine引擎系列被設計和優化用來處理大量資料。
這些表被設計為每秒接收數百萬行插入,並儲存非常大(100 pb)的資料量。
資料被一批一批的快速寫入表中,並在後臺應用合併規則。
在ClickHouse中,每個資料部分(data part)都有自己的主索引。當他們被合併時,合併部分的主索引也被合併。
在大規模中情況下,磁碟和記憶體的效率是非常重要的。因此,不是為每一行建立索引,而是為一組資料行(稱為顆粒(granule))構建一個索引條目。
之所以可以使用這種稀疏索引,是因為ClickHouse會按照主鍵列的順序將一組行儲存在磁碟上。
與直接定位單個行(如基於B-Tree的索引)不同,稀疏主索引允許它快速(通過對索引項進行二分查詢)識別可能匹配查詢的行組。
然後潛在的匹配行組(顆粒)以並行的方式被載入到ClickHouse引擎中,以便找到匹配的行。
這種索引設計允許主索引很小(它可以而且必須完全適合主記憶體),同時仍然顯著加快查詢執行時間:特別是對於資料分析用例中常見的範圍查詢。
下面詳細說明了ClickHouse是如何構建和使用其稀疏主索引的。在本文後面,我們將討論如何選擇、移除和排序用於構建索引的表列(主鍵列)的一些最佳實踐。
資料按照主鍵排序儲存在磁碟上
上面建立的表有:
NOTE
- 如果我們只指定了排序鍵,那麼主鍵將隱式定義為排序鍵。
- 為了提高記憶體效率,我們顯式地指定了一個主鍵,只包含查詢過濾的列。基於主鍵的主索引被完全載入到主記憶體中。
- 為了上下文的一致性和最大的壓縮比例,我們單獨定義了排序鍵,排序鍵包含當前表所有的列(和壓縮演演算法有關,一般排序之後又更好的壓縮率)。
- 如果同時指定了主鍵和排序鍵,則主鍵必須是排序鍵的字首。
插入的行按照主鍵列(以及排序鍵的附加EventTime列)的字典序(從小到大)儲存在磁碟上。
NOTE
ClickHouse允許插入具有相同主鍵列的多行資料。在這種情況下(參見下圖中的第1行和第2行),最終的順序是由指定的排序鍵決定的,這裡是EventTime列的值。
如下圖所示:ClickHouse是列存資料庫。
- 在磁碟上,每個表都有一個資料檔案(*.bin),該列的所有值都以壓縮格式儲存,並且
- 在這個例子中,這887萬行按主鍵列(以及附加的排序鍵列)的字典升序儲存在磁碟上
- UserID第一位,
- 然後是URL,
- 最後是EventTime:
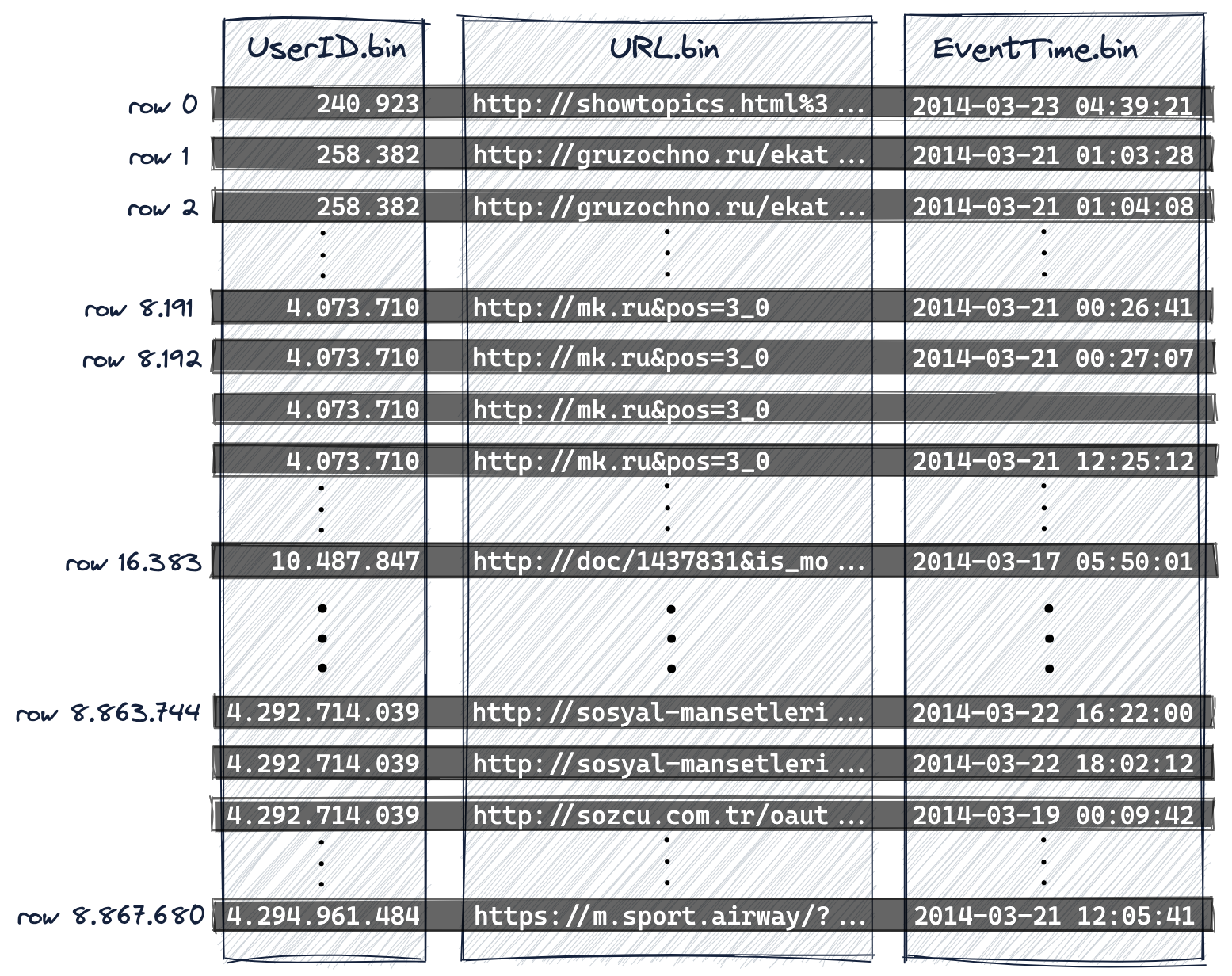 UserID.bin,URL.bin,和EventTime.bin是UserID,URL,和EventTime列的資料檔案。
UserID.bin,URL.bin,和EventTime.bin是UserID,URL,和EventTime列的資料檔案。
NOTE
- 因為主鍵定義了磁碟上行的字典順序,所以一個表只能有一個主鍵。
- 我們從0開始對行進行編號,以便與ClickHouse內部行編號方案對齊,該方案也用於記錄訊息。
資料被組織成顆粒以進行並行資料處理
出於資料處理的目的,表的列值在邏輯上被劃分為多個顆粒。顆粒是流進ClickHouse進行資料處理的最小的不可分割資料集。這意味著,ClickHouse不是讀取單獨的行,而是始終讀取(以流方式並並行地)整個行組(顆粒)。
NOTE
列值並不物理地儲存在顆粒中,顆粒只是用於查詢處理的列值的邏輯組織方式。
下圖顯示瞭如何將表中的887萬行(列值)組織成1083個顆粒,這是表的DDL語句包含設定index_granularity(設定為預設值8192)的結果。
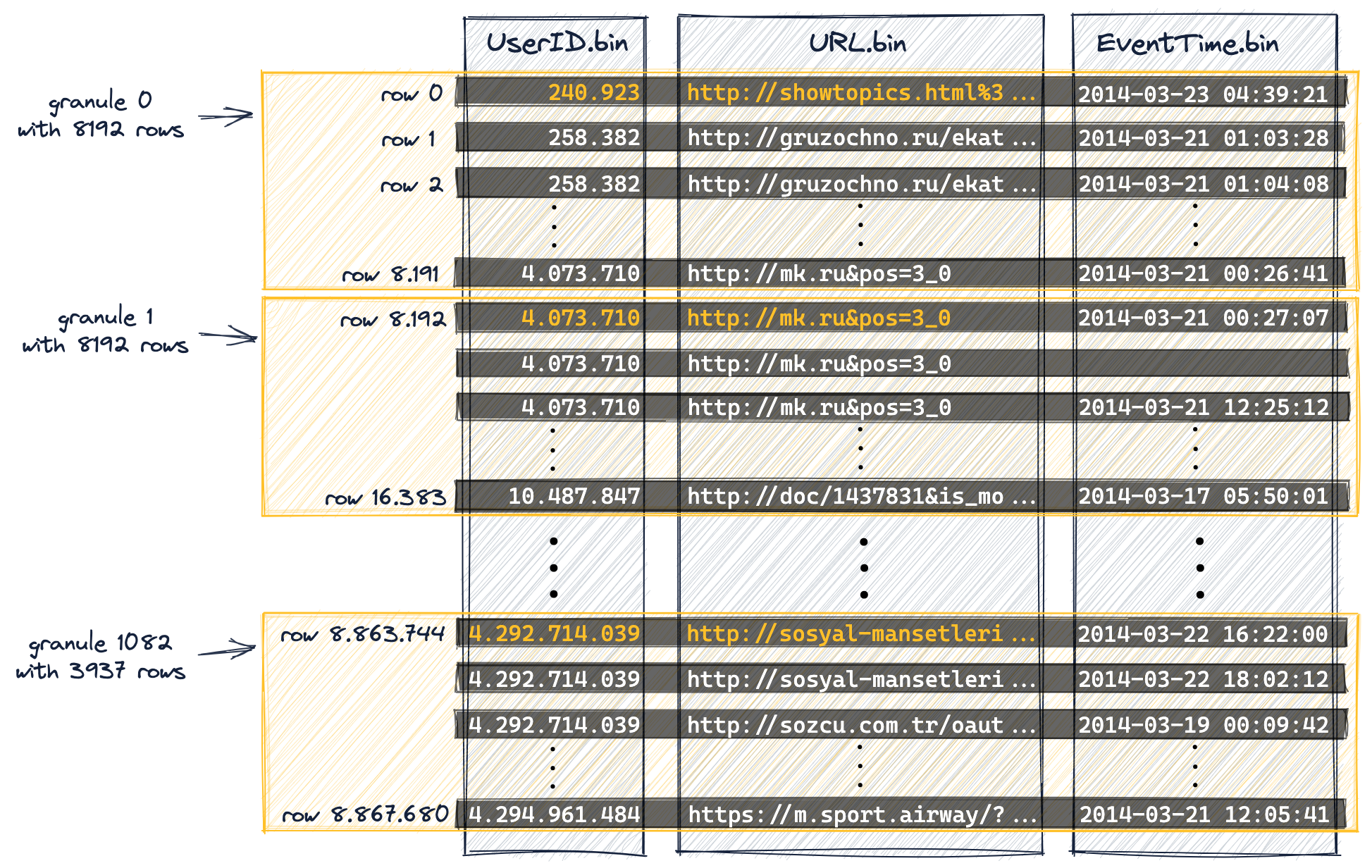
第一個(根據磁碟上的物理順序)8192行(它們的列值)在邏輯上屬於顆粒0,然後下一個8192行(它們的列值)屬於顆粒1,以此類推。
NOTE
-
最後一個顆粒(1082顆粒)是少於8192行的。
-
我們在本指南開頭的「DDL 語句詳細資訊」中提到,我們禁用了自適應索引粒度(為了簡化本指南中的討論,並使圖表和結果可重現)。
因此,範例表中所有顆粒(除了最後一個)都具有相同大小。
-
對於具有自適應索引粒度的表(預設情況下索引粒度是自適應的),某些粒度的大小可以小於 8192 行,具體取決於行資料大小。
-
我們將主鍵列(UserID, URL)中的一些列值標記為橙色。
這些橙色標記的列值是每個顆粒中每個主鍵列的最小值。這裡的例外是最後一個顆粒(上圖中的顆粒1082),最後一個顆粒我們標記的是最大的值。
正如我們將在下面看到的,這些橙色標記的列值將是表主索引中的條目。
-
我們從0開始對行進行編號,以便與ClickHouse內部行編號方案對齊,該方案也用於記錄訊息。
每個顆粒對應主索引的一個條目
主索引是基於上圖中顯示的顆粒建立的。這個索引是一個未壓縮的扁平陣列檔案(primary.idx),包含從0開始的所謂的數位索引標記。
下面的圖顯示了索引儲存了每個顆粒的最小主鍵列值(在上面的圖中用橙色標記的值)。 例如:
- 第一個索引條目(下圖中的「mark 0」)儲存上圖中顆粒0的主鍵列的最小值,
- 第二個索引條目(下圖中的「mark 1」)儲存上圖中顆粒1的主鍵列的最小值,以此類推。
在我們的表中,索引總共有1083個條目,887萬行資料和1083個顆粒:

NOTE
- 最後一個索引條目(上圖中的「mark 1082」)儲存了上圖中顆粒1082的主鍵列的最大值。
- 索引條目(索引標記)不是基於表中的特定行,而是基於顆粒。例如,對於上圖中的索引條目‘mark 0’,在我們的表中沒有UserID為240.923且URL為「goal://metry=10000467796a411…」的行,相反,對於該表,有一個顆粒0,在該顆粒中,最小UserID值是240.923,最小URL值是「goal://metry=10000467796a411…」,這兩個值來自不同的行。
- 主索引檔案完全載入到主記憶體中。如果檔案大於可用的空閒記憶體空間,則ClickHouse將發生錯誤。
主鍵條目稱為索引標記,因為每個索引條目都標誌著特定資料範圍的開始。對於範例表:
-
UserID index marks:
主索引中儲存的UserID值按升序排序。
上圖中的‘mark 1’指示顆粒1中所有錶行的UserID值,以及隨後所有顆粒中的UserID值,都保證大於或等於4.073.710。正如我們稍後將看到的, 當查詢對主鍵的第一列進行過濾時,此全域性有序使ClickHouse能夠對第一個鍵列的索引標記使用二分查詢演演算法。
-
URL index marks:
主鍵列UserID和URL有相同的基數,這意味著第一列之後的所有主鍵列的索引標記通常只表示每個顆粒的資料範圍。
例如,‘mark 0’中的URL列所有的值都大於等於goal://metry=10000467796a411..., 然後顆粒1中的URL並不是如此,這是因為‘mark 1‘與‘mark 0‘具有不同的UserID列值。稍後我們將更詳細地討論這對查詢執行效能的影響。
主索引被用來選擇顆粒
現在,我們可以在主索引的支援下執行查詢。
下面計算UserID 749927693點選次數最多的10個url。
SELECT URL, count(URL) AS Count
FROM hits_UserID_URL
WHERE UserID = 749927693
GROUP BY URL
ORDER BY Count DESC
LIMIT 10;
結果:
┌─URL────────────────────────────┬─Count─┐
│ http://auto.ru/chatay-barana.. │ 170 │
│ http://auto.ru/chatay-id=371...│ 52 │
│ http://public_search │ 45 │
│ http://kovrik-medvedevushku-...│ 36 │
│ http://forumal │ 33 │
│ http://korablitz.ru/L_1OFFER...│ 14 │
│ http://auto.ru/chatay-id=371...│ 14 │
│ http://auto.ru/chatay-john-D...│ 13 │
│ http://auto.ru/chatay-john-D...│ 10 │
│ http://wot/html?page/23600_m...│ 9 │
└────────────────────────────────┴───────┘
10 rows in set. Elapsed: 0.005 sec.
Processed 8.19 thousand rows,
740.18 KB (1.53 million rows/s., 138.59 MB/s.)
ClickHouse使用者端的輸出顯示,沒有進行全表掃描,只有8.19千行流到ClickHouse。
如果trace logging開啟了,那ClickHouse伺服器端紀錄檔會顯示ClickHouse正在對1083個UserID索引標記執行二分查詢以便識別可能包含UserID列值為749927693的行的顆粒。這需要19個步驟,平均時間複雜度為O(log2 n):
...Executor): Key condition: (column 0 in [749927693, 749927693])
...Executor): Running binary search on index range for part all_1_9_2 (1083 marks)
...Executor): Found (LEFT) boundary mark: 176
...Executor): Found (RIGHT) boundary mark: 177
...Executor): Found continuous range in 19 steps
...Executor): Selected 1/1 parts by partition key, 1 parts by primary key,
1/1083 marks by primary key, 1 marks to read from 1 ranges
...Reading ...approx. 8192 rows starting from 1441792
我們可以在上面的跟蹤紀錄檔中看到,1083個現有標記中有一個滿足查詢。
Mark 176 was identified (the 'found left boundary mark' is inclusive, the 'found right boundary mark' is exclusive), and therefore all 8192 rows from granule 176 (which starts at row 1.441.792 - we will see that later on in this article) are then streamed into ClickHouse in order to find the actual rows with a UserID column value of 749927693.
我們也可以通過使用EXPLAIN來重現這個結果:
EXPLAIN indexes = 1
SELECT URL, count(URL) AS Count
FROM hits_UserID_URL
WHERE UserID = 749927693
GROUP BY URL
ORDER BY Count DESC
LIMIT 10;
結果如下:
┌─explain───────────────────────────────────────────────────────────────────────────────┐
│ Expression (Projection) │
│ Limit (preliminary LIMIT (without OFFSET)) │
│ Sorting (Sorting for ORDER BY) │
│ Expression (Before ORDER BY) │
│ Aggregating │
│ Expression (Before GROUP BY) │
│ Filter (WHERE) │
│ SettingQuotaAndLimits (Set limits and quota after reading from storage) │
│ ReadFromMergeTree │
│ Indexes: │
│ PrimaryKey │
│ Keys: │
│ UserID │
│ Condition: (UserID in [749927693, 749927693]) │
│ Parts: 1/1 │
│ Granules: 1/1083 │
└───────────────────────────────────────────────────────────────────────────────────────┘
16 rows in set. Elapsed: 0.003 sec.
使用者端輸出顯示,在1083個顆粒中選擇了一個可能包含UserID列值為749927693的行。
CONCLUSION
當查詢對聯合主鍵的一部分並且是第一個主鍵進行過濾時,ClickHouse將主鍵索引標記執行二分查詢演演算法。
正如上面所討論的,ClickHouse使用它的稀疏主索引來快速(通過二分查詢演演算法)選擇可能包含匹配查詢的行的顆粒。
這是ClickHouse查詢執行的第一階段(顆粒選擇)。
在第二階段(資料讀取中), ClickHouse定位所選的顆粒,以便將它們的所有行流到ClickHouse引擎中,以便找到實際匹配查詢的行。
我們將在下一節更詳細地討論第二階段。
標記檔案用來定位顆粒
下圖描述了上表主索引檔案的一部分。

如上所述,通過對索引的1083個UserID標記進行二分搜尋,確定了第176個標記。因此,它對應的顆粒176可能包含UserID列值為749.927.693的行。
顆粒選擇的具體過程
上圖顯示,標記176是第一個UserID值小於749.927.693的索引條目,並且下一個標記(標記177)的顆粒177的最小UserID值大於該值的索引條目。因此,只有標記176對應的顆粒176可能包含UserID列值為749.927.693的行。
為了確認(或排除)顆粒176中的某些行包含UserID列值為749.927.693,需要將屬於此顆粒的所有8192行讀取到ClickHouse。
為了讀取這部分資料,ClickHouse需要知道顆粒176的實體地址。
在ClickHouse中,我們表的所有顆粒的物理位置都儲存在標記檔案中。與資料檔案類似,每個表的列有一個標記檔案。
下圖顯示了三個標記檔案UserID.mrk、URL.mrk、EventTime.mrk,為表的UserID、URL和EventTime列儲存顆粒的物理位置。
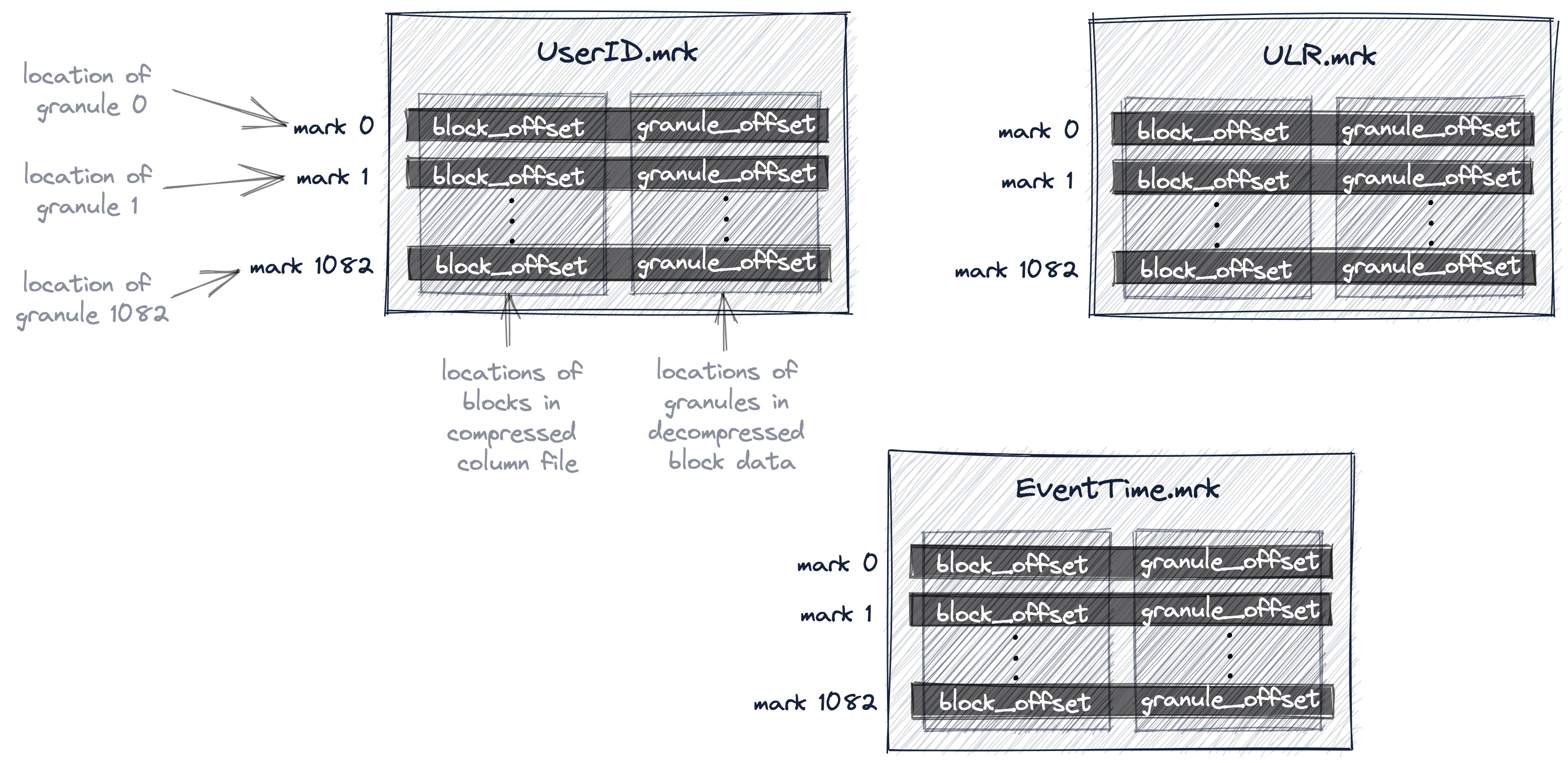
我們已經討論了主索引是一個扁平的未壓縮陣列檔案(primary.idx),其中包含從0開始編號的索引標記。
類似地,標記檔案也是一個扁平的未壓縮陣列檔案(*.mrk),其中包含從0開始編號的標記。
一旦ClickHouse確定並選擇了可能包含查詢所需的匹配行的顆粒的索引標記,就可以在標記檔案陣列中查詢,以獲得顆粒的物理位置。
每個特定列的標記檔案條目以偏移量的形式儲存兩個位置:
- 第一個偏移量(上圖中的'block_offset')是在包含所選顆粒的壓縮版本的壓縮列資料檔案中定位塊。這個壓縮塊可能包含幾個壓縮的顆粒。所定位的壓縮檔案塊在讀取時被解壓到記憶體中。
- 標記檔案的第二個偏移量(上圖中的「granule_offset」)提供了顆粒在解壓資料塊中的位置。
定位到的顆粒中的所有8192行資料都會被ClickHouse載入然後進一步處理。
為什麼需要MARK檔案
為什麼主索引不直接包含與索引標記相對應的顆粒的物理位置?
因為ClickHouse設計的場景就是超大規模資料,非常高效地使用磁碟和記憶體非常重要。
主索引檔案需要放入記憶體中。
對於我們的範例查詢,ClickHouse使用了主索引,並選擇了可能包含與查詢匹配的行的單個顆粒。只有對於這一個顆粒,ClickHouse才需定位物理位置,以便將相應的行組讀取以進一步的處理。
而且,只有UserID和URL列需要這個偏移量資訊。
對於查詢中不使用的列,例如EventTime,不需要偏移量資訊。
對於我們的範例查詢,Clickhouse只需要UserID資料檔案(UserID.bin)中176顆粒的兩個物理位置偏移,以及URL資料檔案(URL.data)中176顆粒的兩個物理位置偏移。
由mark檔案提供的間接方法避免了直接在主索引中儲存所有三個列的所有1083個顆粒的物理位置的條目:因此避免了在主記憶體中有不必要的(可能未使用的)資料。
下面的圖表和文字說明了我們的查詢範例,ClickHouse如何在UserID.bin資料檔案中定位176顆粒。
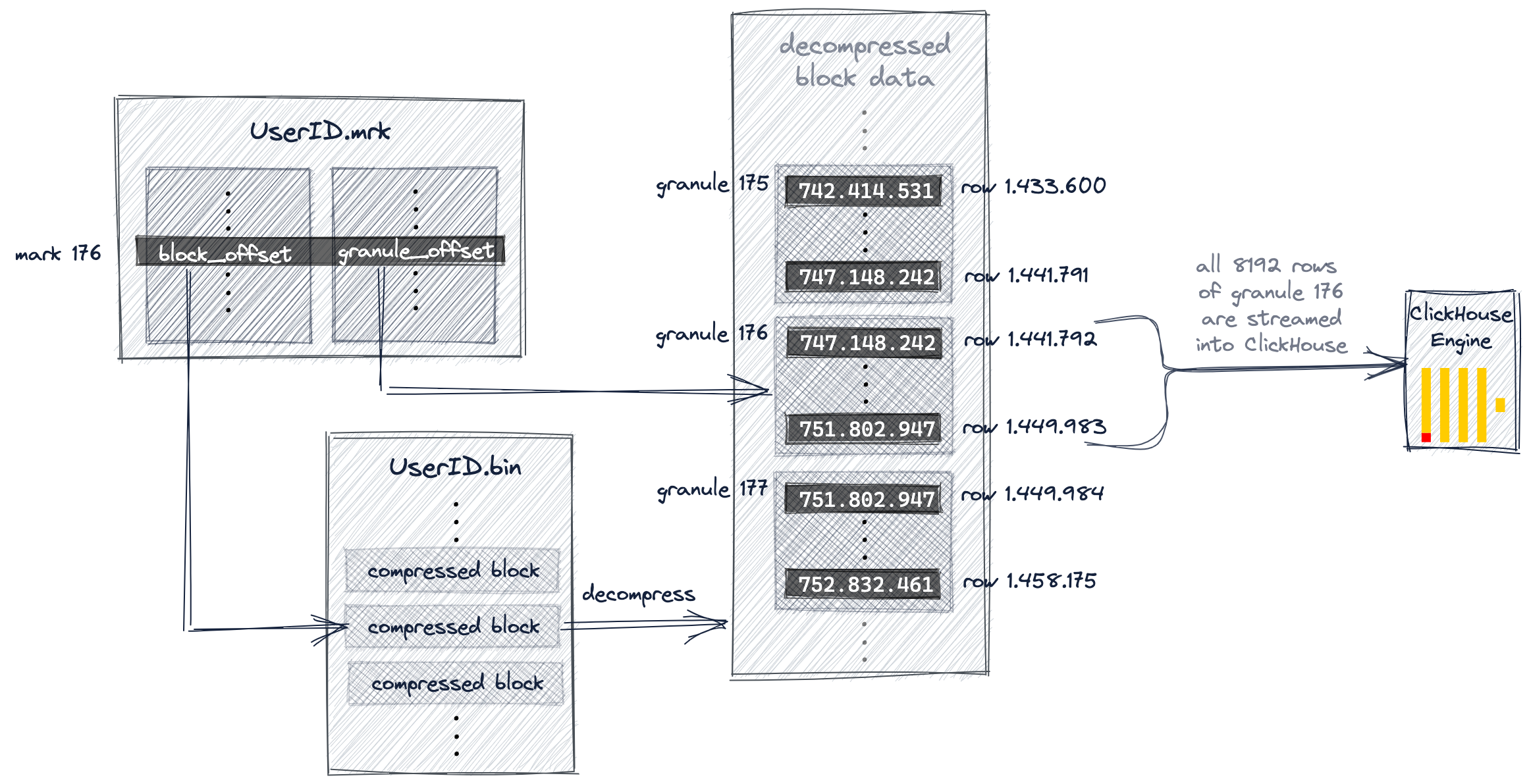
我們在本文前面討論過,ClickHouse選擇了主索引標記176,因此176顆粒可能包含查詢所需的匹配行。
ClickHouse現在使用從索引中選擇的標記號(176)在UserID.mark中進行位置陣列查詢,以獲得兩個偏移量,用於定位顆粒176。
如圖所示,第一個偏移量是定位UserID.bin資料檔案中的壓縮檔案塊,該資料檔案包含顆粒176的壓縮資料。
一旦所定位的檔案塊被解壓縮到主記憶體中,就可以使用標記檔案的第二個偏移量在未壓縮的資料中定位顆粒176。
ClickHouse需要從UserID.bin資料檔案和URL.bin資料檔案中定位(讀取)顆粒176,以便執行我們的範例查詢(UserID為749.927.693的網際網路使用者點選次數最多的10個url)。
上圖顯示了ClickHouse如何定位UserID.bin資料檔案的顆粒。
同時,ClickHouse對URL.bin資料檔案的顆粒176執行相同的操作。這兩個不同的顆粒被對齊並載入到ClickHouse引擎以進行進一步的處理,即聚合並計算UserID為749.927.693的所有行的每組URL值,最後以計數降序輸出10個最大的URL組。
查詢使用第二位主鍵的效能問題
當查詢對複合鍵的一部分並且是第一個主鍵列進行過濾時,ClickHouse將對主鍵列的索引標記執行二分查詢。
但是,當查詢對聯合主鍵的一部分但不是第一個鍵列進行過濾時,會發生什麼情況?
NOTE
我們討論了這樣一種場景:查詢不是顯式地對第一個主鍵列進行過濾,而是對第一個主鍵列之後的任何鍵列進行過濾。
當查詢同時對第一個主鍵列和第一個主鍵列之後的任何鍵列進行過濾時,ClickHouse將對第一個主鍵列的索引標記執行二分查詢。
我們使用一個查詢來計算最點選"http://public_search"的最多的前10名使用者:
SELECT UserID, count(UserID) AS Count
FROM hits_UserID_URL
WHERE URL = 'http://public_search'
GROUP BY UserID
ORDER BY Count DESC
LIMIT 10;
結果是:
┌─────UserID─┬─Count─┐
│ 2459550954 │ 3741 │
│ 1084649151 │ 2484 │
│ 723361875 │ 729 │
│ 3087145896 │ 695 │
│ 2754931092 │ 672 │
│ 1509037307 │ 582 │
│ 3085460200 │ 573 │
│ 2454360090 │ 556 │
│ 3884990840 │ 539 │
│ 765730816 │ 536 │
└────────────┴───────┘
10 rows in set. Elapsed: 0.086 sec.
Processed 8.81 million rows,
799.69 MB (102.11 million rows/s., 9.27 GB/s.)
使用者端輸出表明,儘管URL列是聯合主鍵的一部分,ClickHouse幾乎執行了一一次全表掃描!ClickHouse從表的887萬行中讀取881萬行。
如果啟用了trace紀錄檔,那麼ClickHouse服務紀錄檔檔案顯示,ClickHouse在1083個URL索引標記上使用了通用的排除搜尋,以便識別那些可能包含URL列值為"http://public_search"的行。
...Executor): Key condition: (column 1 in ['http://public_search',
'http://public_search'])
...Executor): Used generic exclusion search over index for part all_1_9_2
with 1537 steps
...Executor): Selected 1/1 parts by partition key, 1 parts by primary key,
1076/1083 marks by primary key, 1076 marks to read from 5 ranges
...Executor): Reading approx. 8814592 rows with 10 streams
我們可以在上面的跟蹤紀錄檔範例中看到,1083個顆粒中有1076個(通過標記)被選中,因為可能包含具有匹配URL值的行。
這將導致881萬行被讀取到ClickHouse引擎中(通過使用10個流並行地讀取),以便識別實際包含URL值"http://public_search"的行。
然而,稍後僅僅39個顆粒包含匹配的行。
雖然基於聯合主鍵(UserID, URL)的主索引對於加快過濾具有特定UserID值的行的查詢非常有用,但對於過濾具有特定URL值的行的查詢,索引並沒有提供顯著的幫助。
原因是URL列不是第一個主鍵列,因此ClickHouse是使用一個通用的排除搜尋演演算法(而不是二分查詢)查詢URL列的索引標誌,和UserID主鍵列不同,它的演演算法的有效性依賴於URL列的基數。
為了說明,我們給出通用的排除搜尋演演算法的工作原理:
通用排除搜尋演演算法
下面將演示當通過第一個列之後的任何列選擇顆粒時,當前一個鍵列具有或高或低的基數時,ClickHouse通用排除搜尋演演算法 是如何工作的。
作為這兩種情況的例子,我們將假設:
- 搜尋URL值為"W3"的行。
- 點選表抽象簡化為只有簡單值的UserID和UserID。
- 相同聯合主鍵(UserID、URL)。這意味著行首先按UserID值排序,具有相同UserID值的行然後再按URL排序。
- 顆粒大小為2,即每個顆粒包含兩行。
在下面的圖表中,我們用橙色標註了每個顆粒的最小鍵列值。
字首主鍵低基數
假設UserID具有較低的基數。在這種情況下,相同的UserID值很可能分佈在多個錶行和顆粒上,從而分佈在索引標記上。對於具有相同UserID的索引標記,索引標記的URL值按升序排序(因為錶行首先按UserID排序,然後按URL排序)。這使得有效的過濾如下所述:
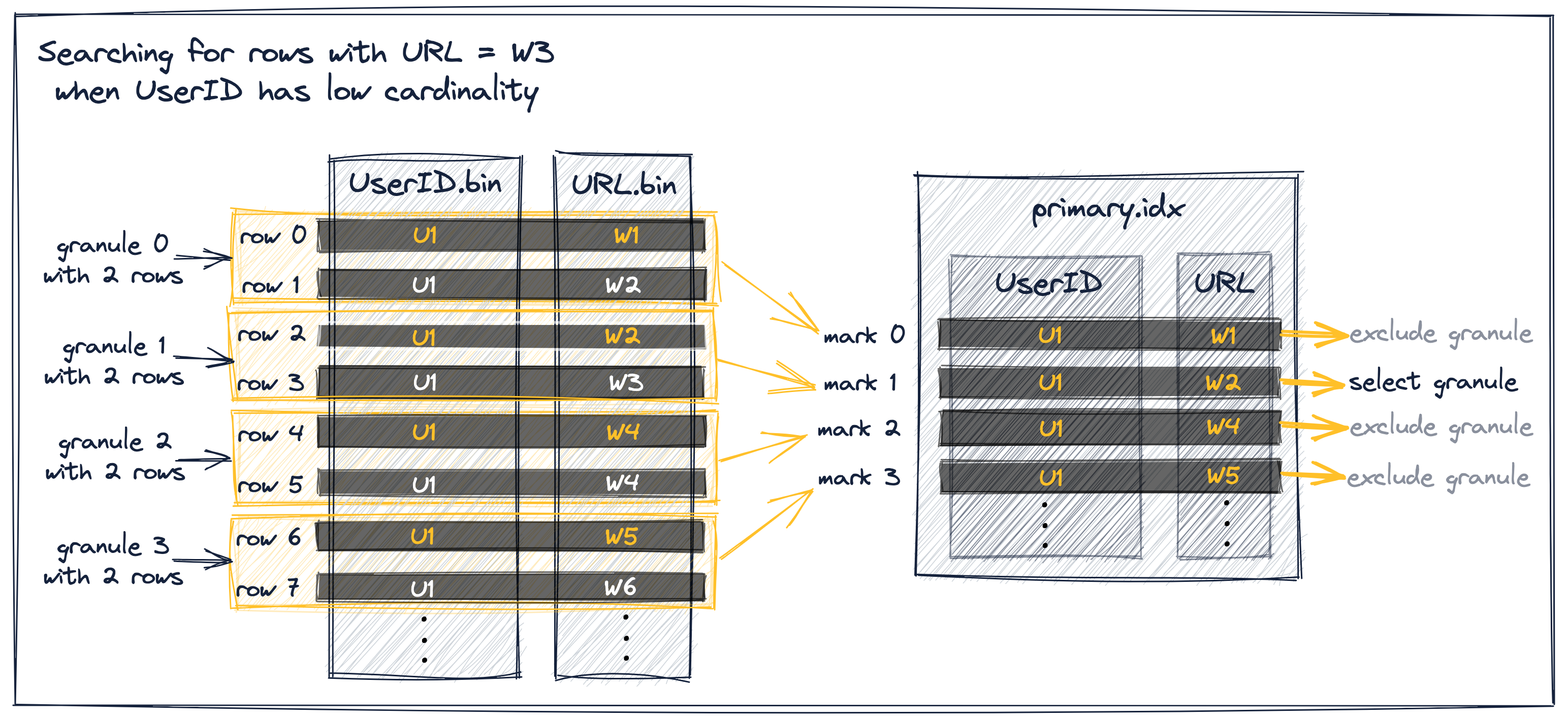
在上圖中,我們的抽象樣本資料的顆粒選擇過程有三種不同的場景:
- 如果索引標記0的(最小)URL值小於W3,並且緊接索引標記的URL值也小於W3,則可以排除索引標記0,因為標記0、標記1和標記2具有相同的UserID值。注意,這個排除前提條件確保顆粒0和下一個顆粒1完全由U1 UserID值組成,這樣ClickHouse就可以假設顆粒0中的最大URL值也小於W3並排除該顆粒。
- 如果索引標記1的URL值小於(或等於)W3,並且後續索引標記的URL值大於(或等於)W3,則選擇索引標記1,因為這意味著粒度1可能包含URL為W3的行)。
- 可以排除URL值大於W3的索引標記2和3,因為主索引的索引標記儲存了每個顆粒的最小鍵列值,因此顆粒2和3不可能包含URL值W3。
字首主鍵高基數
當UserID具有較高的基數時,相同的UserID值不太可能分佈在多個錶行和顆粒上。這意味著索引標記的URL值不是單調遞增的:
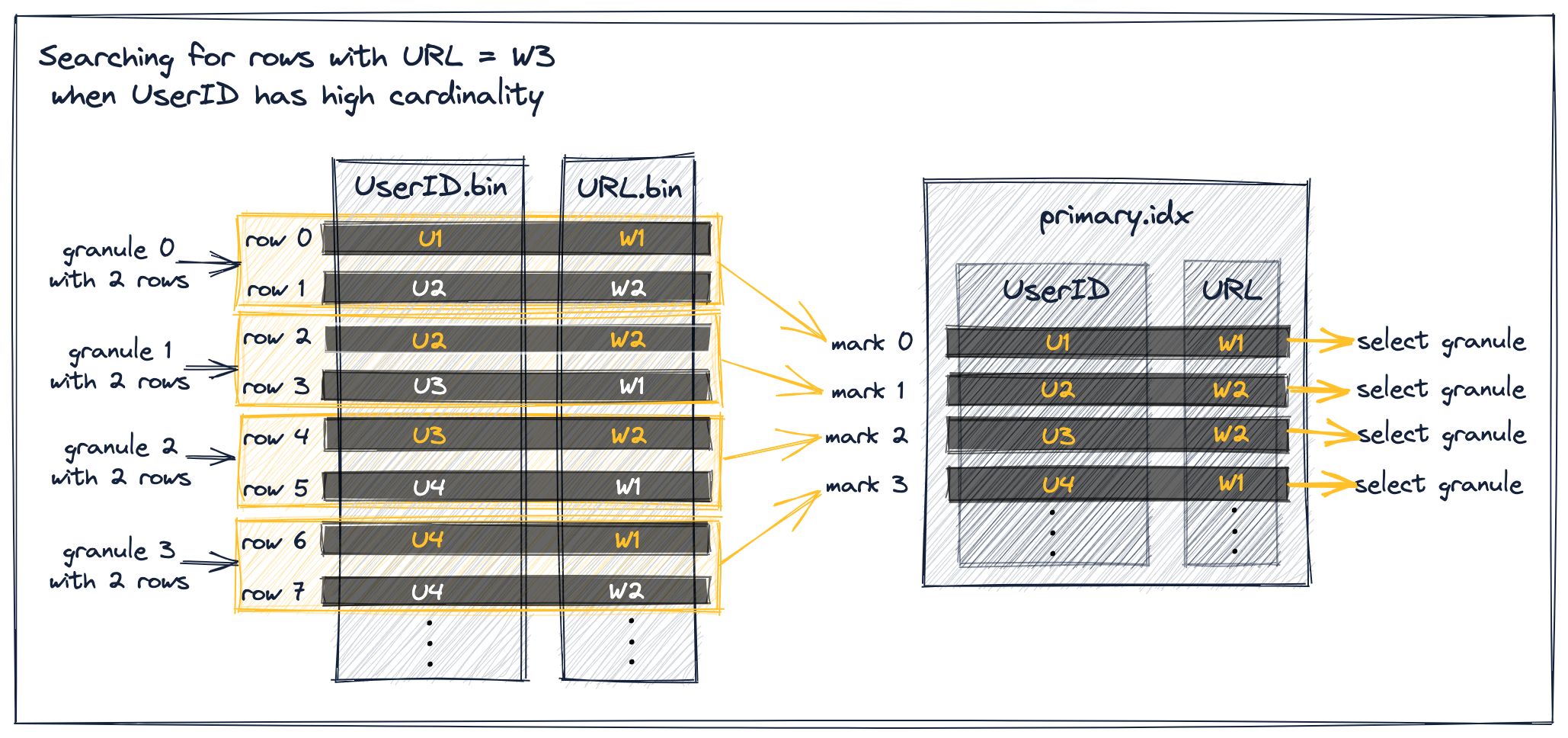
正如在上面的圖表中所看到的,所有URL值小於W3的標記都被選中,以便將其關聯的顆粒的行載入到ClickHouse引擎中。
這是因為雖然圖中的所有索引標記都屬於上面描述的場景1,但它們不滿足前面提到的排除前提條件,即兩個直接隨後的索引標記都具有與當前標記相同的UserID值,因此不能被排除。
例如,考慮索引標記0,其URL值小於W3,並且其直接後續索引標記的URL值也小於W3。這不能排除,因為兩個直接隨後的索引標記1和2與當前標記0沒有相同的UserID值。
請注意,隨後的兩個索引標記需要具有相同的UserID值。這確保了當前和下一個標記的顆粒完全由U1 UserID值組成。如果僅僅是下一個標記具有相同的UserID,那麼下一個標記的URL值可能來自具有不同UserID的錶行——當您檢視上面的圖表時,確實是這樣的情況,即W2來自U2而不是U1的行。
這最終阻止了ClickHouse對顆粒0中的最大URL值進行假設。相反,它必須假設顆粒0可能包含URL值為W3的行,並被迫選擇標記0。
同樣的情況也適用於標記1、2和3。
結論
當查詢對聯合主鍵的一部分列(但不是第一個鍵列)進行過濾時,ClickHouse使用的通用排除搜尋演演算法(而不是二分查詢)在前一個鍵列基數較低時最有效。
在我們的範例資料集中,兩個鍵列(UserID、URL)都具有類似的高基數,並且,如前所述,當URL列的前一個鍵列具有較高基數時,通用排除搜尋演演算法不是很有效。
看下跳數索引
因為UserID和URL具有較高的基數,根據URL過濾資料不是特別有效,對URL列建立二級跳數索引同樣也不會有太多改善。
例如,這兩個語句在我們的表的URL列上建立並填充一個minmax跳數索引。
ALTER TABLE hits_UserID_URL ADD INDEX url_skipping_index URL TYPE minmax GRANULARITY 4;
ALTER TABLE hits_UserID_URL MATERIALIZE INDEX url_skipping_index;
ClickHouse現在建立了一個額外的索引來儲存—每組4個連續的顆粒(注意上面ALTER TABLE語句中的GRANULARITY 4子句)—最小和最大的URL值:

第一個索引條目(上圖中的mark 0)儲存屬於表的前4個顆粒的行的最小和最大URL值。
第二個索引條目(mark 1)儲存屬於表中下一個4個顆粒的行的最小和最大URL值,依此類推。
(ClickHouse還為跳數索引建立了一個特殊的標記檔案,用於定位與索引標記相關聯的顆粒組。)
由於UserID和URL的基數相似,在執行對URL的查詢過濾時,這個二級跳數索引不能幫助排除選擇的顆粒。
正在尋找的特定URL值('http://public_search')很可能是索引為每組顆粒儲存的最小值和最大值之間的值,導致ClickHouse被迫選擇這組顆粒(因為它們可能包含匹配查詢的行)。
因此,如果我們想顯著提高過濾具有特定URL的行的範例查詢的速度,那麼我們需要使用針對該查詢優化的主索引。
此外,如果我們想保持過濾具有特定UserID的行的範例查詢的良好效能,那麼我們需要使用多個主索引。
下面是實現這一目標的方法。
使用多個主鍵索引進行調優
如果我們想顯著加快我們的兩個範例查詢——一個過濾具有特定UserID的行,一個過濾具有特定URL的行——那麼我們需要使用多個主索引,通過使用這三個方法中的一個:
- 新建一個不同主鍵的新表。
- 建立一個物化檢視。
- 增加projection。
這三個方法都會有效地將範例資料複製到另一個表中,以便重新組織表的主索引和行排序順序。
然而,這三個選項的不同之處在於,附加表對於查詢和插入語句的路由對使用者的透明程度。
當建立有不同主鍵的第二個表時,查詢必須顯式地傳送給最適合查詢的表版本,並且必須顯式地插入新資料到兩個表中,以保持表的同步:
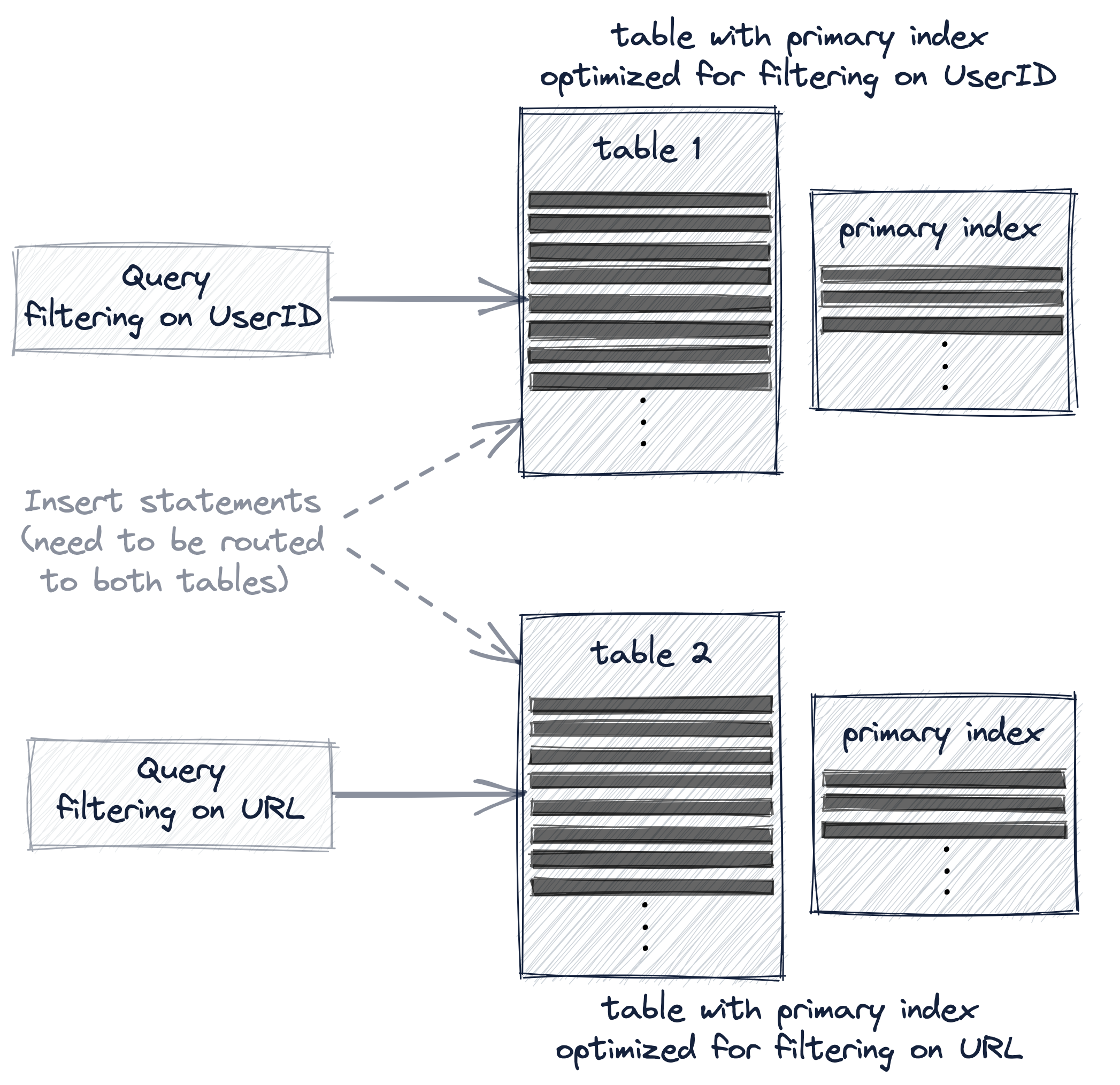
在物化檢視中,額外的表被隱藏,資料自動在兩個表之間保持同步:
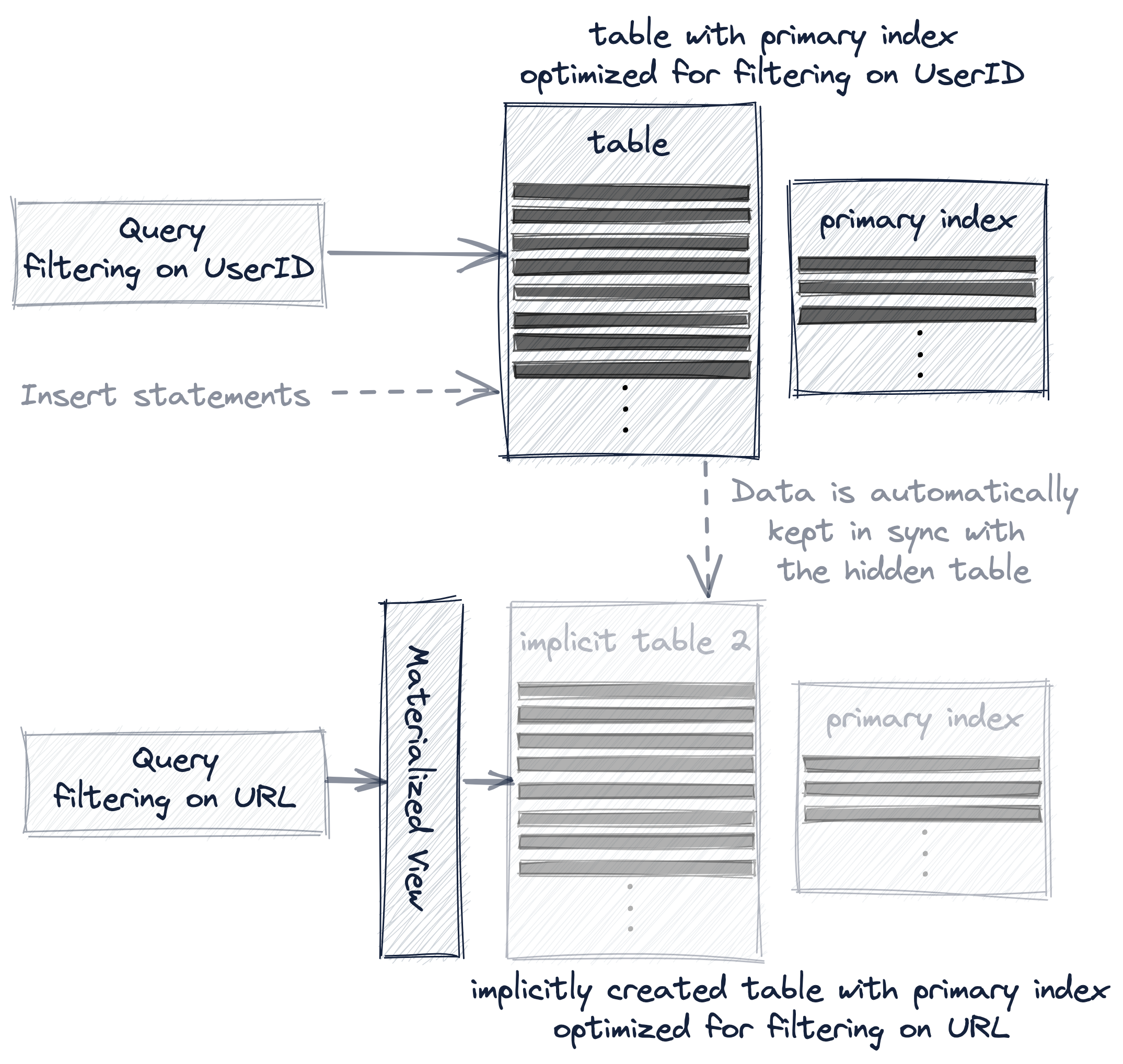
projection方式是最透明的選項,因為除了自動保持隱藏的附加表與資料變化同步外,ClickHouse還會自動選擇最有效的表版本進行查詢:

下面我們使用真實的例子詳細討論下這三種方式。
通過輔助表使用聯合主鍵索引
我們建立一個新的附加表,其中我們在主鍵中切換鍵列的順序(與原始表相比):
CREATE TABLE hits_URL_UserID
(
`UserID` UInt32,
`URL` String,
`EventTime` DateTime
)
ENGINE = MergeTree
PRIMARY KEY (URL, UserID)
ORDER BY (URL, UserID, EventTime)
SETTINGS index_granularity = 8192, index_granularity_bytes = 0;
寫入887萬行源表資料:
INSERT INTO hits_URL_UserID
SELECT * from hits_UserID_URL;
結果:
Ok.
0 rows in set. Elapsed: 2.898 sec. Processed 8.87 million rows, 838.84 MB (3.06 million rows/s., 289.46 MB/s.)
最後optimize下:
OPTIMIZE TABLE hits_URL_UserID FINAL;
因為我們切換了主鍵中列的順序,插入的行現在以不同的字典順序儲存在磁碟上(與我們的原始表相比),因此該表的1083個顆粒也包含了與以前不同的值:

主鍵索引如下:

現在計算最頻繁點選URL"http://public_search"的前10名使用者,這時候的查詢速度是明顯加快的:
SELECT UserID, count(UserID) AS Count
FROM hits_URL_UserID
WHERE URL = 'http://public_search'
GROUP BY UserID
ORDER BY Count DESC
LIMIT 10;
結果:
┌─────UserID─┬─Count─┐
│ 2459550954 │ 3741 │
│ 1084649151 │ 2484 │
│ 723361875 │ 729 │
│ 3087145896 │ 695 │
│ 2754931092 │ 672 │
│ 1509037307 │ 582 │
│ 3085460200 │ 573 │
│ 2454360090 │ 556 │
│ 3884990840 │ 539 │
│ 765730816 │ 536 │
└────────────┴───────┘
10 rows in set. Elapsed: 0.017 sec.
Processed 319.49 thousand rows,
11.38 MB (18.41 million rows/s., 655.75 MB/s.)
現在沒有全表掃描了,ClickHouse執行高效了很多。
對於原始表中的主索引(其中UserID是第一個鍵列,URL是第二個鍵列),ClickHouse在索引標記上使用了通用排除搜尋來執行該查詢,但這不是很有效,因為UserID和URL的基數同樣很高。
將URL作為主索引的第一列,ClickHouse現在對索引標記執行二分搜尋。ClickHouse伺服器紀錄檔檔案中對應的跟蹤紀錄檔:
...Executor): Key condition: (column 0 in ['http://public_search',
'http://public_search'])
...Executor): Running binary search on index range for part all_1_9_2 (1083 marks)
...Executor): Found (LEFT) boundary mark: 644
...Executor): Found (RIGHT) boundary mark: 683
...Executor): Found continuous range in 19 steps
...Executor): Selected 1/1 parts by partition key, 1 parts by primary key,
39/1083 marks by primary key, 39 marks to read from 1 ranges
...Executor): Reading approx. 319488 rows with 2 streams
ClickHouse只選擇了39個索引標記,而不是使用通用排除搜尋時的1076個。
請注意,輔助表經過了優化,以加快對url的範例查詢過濾的執行。
像之前我們查詢過濾URL一樣,如果我們現在對輔助表查詢過濾UserID,效能同樣會比較差,因為現在UserID是第二主索引鍵列,所以ClickHouse將使用通用排除搜尋演演算法查詢顆粒,這對於類似高基數的UserID和URL來說不是很有效。
點選下面瞭解詳情:
SELECT URL, count(URL) AS Count
FROM hits_URL_UserID
WHERE UserID = 749927693
GROUP BY URL
ORDER BY Count DESC
LIMIT 10;
結果
┌─URL────────────────────────────┬─Count─┐
│ http://auto.ru/chatay-barana.. │ 170 │
│ http://auto.ru/chatay-id=371...│ 52 │
│ http://public_search │ 45 │
│ http://kovrik-medvedevushku-...│ 36 │
│ http://forumal │ 33 │
│ http://korablitz.ru/L_1OFFER...│ 14 │
│ http://auto.ru/chatay-id=371...│ 14 │
│ http://auto.ru/chatay-john-D...│ 13 │
│ http://auto.ru/chatay-john-D...│ 10 │
│ http://wot/html?page/23600_m...│ 9 │
└────────────────────────────────┴───────┘
10 rows in set. Elapsed: 0.024 sec.
Processed 8.02 million rows,
73.04 MB (340.26 million rows/s., 3.10 GB/s.)
伺服器端紀錄檔:
...Executor): Key condition: (column 1 in [749927693, 749927693])
...Executor): Used generic exclusion search over index for part all_1_9_2
with 1453 steps
...Executor): Selected 1/1 parts by partition key, 1 parts by primary key,
980/1083 marks by primary key, 980 marks to read from 23 ranges
...Executor): Reading approx. 8028160 rows with 10 streams
現在我們有了兩張表。優化了對UserID和URL的查詢過濾,分別:
通過物化檢視使用聯合主鍵
在原表上建立物化檢視:
CREATE MATERIALIZED VIEW mv_hits_URL_UserID
ENGINE = MergeTree()
PRIMARY KEY (URL, UserID)
ORDER BY (URL, UserID, EventTime)
POPULATE
AS SELECT * FROM hits_UserID_URL;
結果:
Ok.
0 rows in set. Elapsed: 2.935 sec. Processed 8.87 million rows, 838.84 MB (3.02 million rows/s., 285.84 MB/s.)
NOTE
- 我們在檢視的主鍵中切換鍵列的順序(與原始表相比)
- 物化檢視由一個隱藏表支援,該表的行順序和主索引基於給定的主鍵定義
- 我們使用POPULATE關鍵字,以便用源表hits_UserID_URL中的所有887萬行立即匯入新的物化檢視
- 如果在源表hits_UserID_URL中插入了新行,那麼這些行也會自動插入到隱藏表中
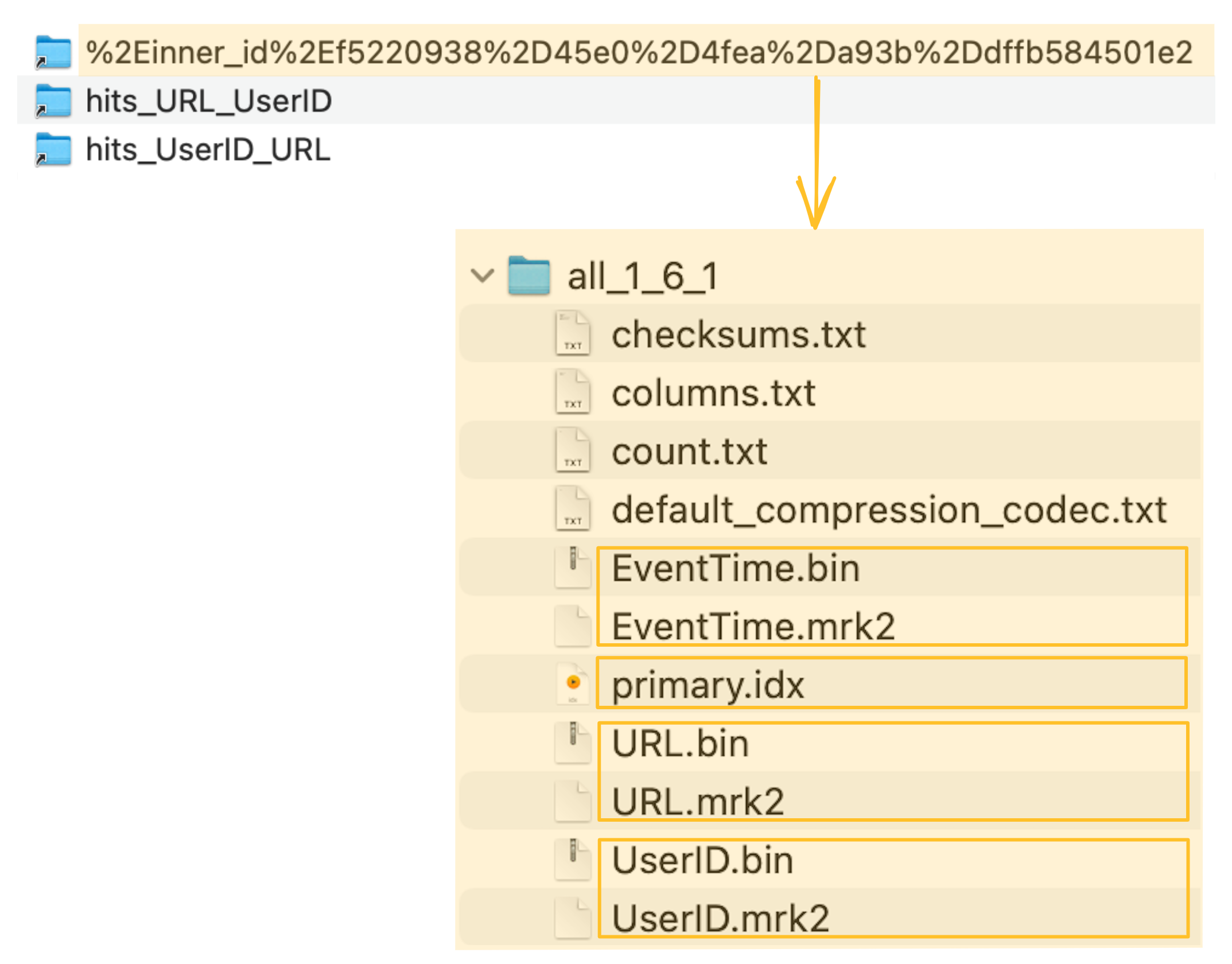
- 實際上,隱式建立的隱藏表的行順序和主索引與我們上面顯式建立的輔助表相同:

ClickHouse將隱藏表的列資料檔案(.bin)、標記檔案(.mrk2)和主索引(primary.idx)儲存在ClickHouse伺服器的資料目錄的一個特殊資料夾中:
物化檢視背後的隱藏表(和它的主索引)現在可以用來顯著加快我們在URL列上查詢過濾的執行速度:
SELECT UserID, count(UserID) AS Count
FROM mv_hits_URL_UserID
WHERE URL = 'http://public_search'
GROUP BY UserID
ORDER BY Count DESC
LIMIT 10;
結果:
┌─────UserID─┬─Count─┐
│ 2459550954 │ 3741 │
│ 1084649151 │ 2484 │
│ 723361875 │ 729 │
│ 3087145896 │ 695 │
│ 2754931092 │ 672 │
│ 1509037307 │ 582 │
│ 3085460200 │ 573 │
│ 2454360090 │ 556 │
│ 3884990840 │ 539 │
│ 765730816 │ 536 │
└────────────┴───────┘
10 rows in set. Elapsed: 0.026 sec.
Processed 335.87 thousand rows,
13.54 MB (12.91 million rows/s., 520.38 MB/s.)
物化檢視背後隱藏表(及其主索引)實際上與我們顯式建立的輔助表是相同的,所以查詢的執行方式與顯式建立的表相同。
ClickHouse伺服器紀錄檔檔案中相應的跟蹤紀錄檔確認了ClickHouse正在對索引標記執行二分搜尋:
...Executor): Key condition: (column 0 in ['http://public_search',
'http://public_search'])
...Executor): Running binary search on index range ...
...
...Executor): Selected 4/4 parts by partition key, 4 parts by primary key,
41/1083 marks by primary key, 41 marks to read from 4 ranges
...Executor): Reading approx. 335872 rows with 4 streams
通過projections使用聯合主鍵索引
Projections目前是一個實驗性的功能,因此我們需要告訴ClickHouse:
SET allow_experimental_projection_optimization = 1;
在原表上建立projection:
ALTER TABLE hits_UserID_URL
ADD PROJECTION prj_url_userid
(
SELECT *
ORDER BY (URL, UserID)
);
物化projection:
ALTER TABLE hits_UserID_URL
MATERIALIZE PROJECTION prj_url_userid;
NOTE
- 該projection正在建立一個隱藏表,該表的行順序和主索引基於該projection的給定order BY子句
- 我們使用MATERIALIZE關鍵字,以便立即用源表hits_UserID_URL的所有887萬行匯入隱藏表
- 如果在源表hits_UserID_URL中插入了新行,那麼這些行也會自動插入到隱藏表中
- 查詢總是(從語法上)針對源表hits_UserID_URL,但是如果隱藏表的行順序和主索引允許更有效地執行查詢,那麼將使用該隱藏表
- 實際上,隱式建立的隱藏表的行順序和主索引與我們顯式建立的輔助表相同:
ClickHouse將隱藏表的列資料檔案(.bin)、標記檔案(.mrk2)和主索引(primary.idx)儲存在一個特殊的資料夾中(在下面的截圖中用橙色標記),緊挨著源表的資料檔案、標記檔案和主索引檔案:
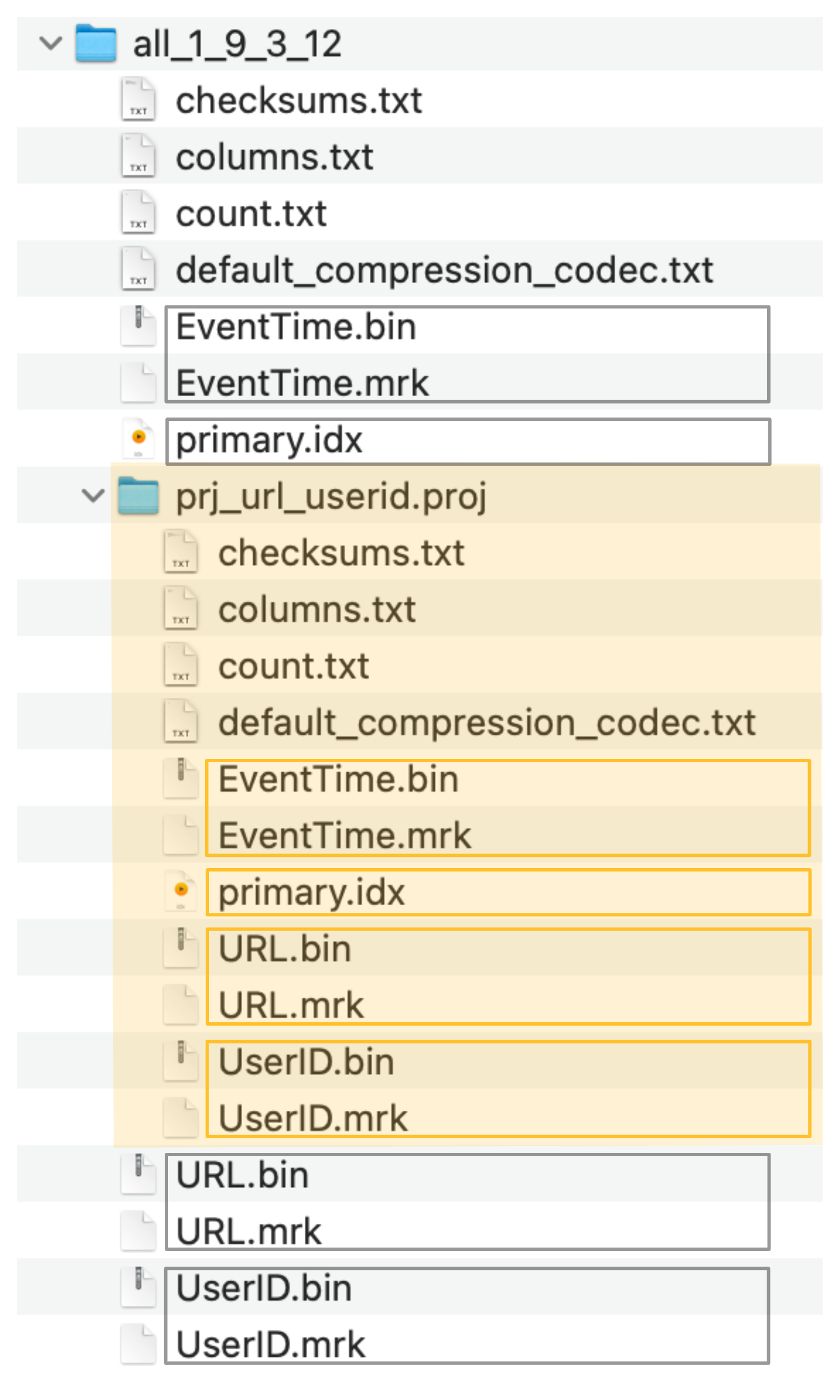
由投影建立的隱藏表(以及它的主索引)現在可以(隱式地)用於顯著加快URL列上查詢過濾的執行。注意,查詢在語法上針對投影的源表。
SELECT UserID, count(UserID) AS Count
FROM hits_UserID_URL
WHERE URL = 'http://public_search'
GROUP BY UserID
ORDER BY Count DESC
LIMIT 10;
結果:
┌─────UserID─┬─Count─┐
│ 2459550954 │ 3741 │
│ 1084649151 │ 2484 │
│ 723361875 │ 729 │
│ 3087145896 │ 695 │
│ 2754931092 │ 672 │
│ 1509037307 │ 582 │
│ 3085460200 │ 573 │
│ 2454360090 │ 556 │
│ 3884990840 │ 539 │
│ 765730816 │ 536 │
└────────────┴───────┘
10 rows in set. Elapsed: 0.029 sec.
Processed 319.49 thousand rows, 1
1.38 MB (11.05 million rows/s., 393.58 MB/s.)
因為由投影建立的隱藏表(及其主索引)實際上與我們顯式建立的輔助表相同,所以查詢的執行方式與顯式建立的表相同。
ClickHouse伺服器紀錄檔檔案中跟蹤紀錄檔確認了ClickHouse正在對索引標記執行二分搜尋:
...Executor): Key condition: (column 0 in ['http://public_search',
'http://public_search'])
...Executor): Running binary search on index range for part prj_url_userid (1083 marks)
...Executor): ...
...Executor): Choose complete Normal projection prj_url_userid
...Executor): projection required columns: URL, UserID
...Executor): Selected 1/1 parts by partition key, 1 parts by primary key,
39/1083 marks by primary key, 39 marks to read from 1 ranges
...Executor): Reading approx. 319488 rows with 2 streams
移除無效的主鍵列
帶有聯合主鍵(UserID, URL)的表的主索引對於加快UserID的查詢過濾非常有用。但是,儘管URL列是聯合主鍵的一部分,但該索引在加速URL查詢過濾方面並沒有提供顯著的幫助。
反之亦然:具有複合主鍵(URL, UserID)的表的主索引加快了URL上的查詢過濾,但沒有為UserID上的查詢過濾提供太多支援。
由於主鍵列UserID和URL的基數同樣很高,過濾第二個鍵列的查詢不會因為第二個鍵列位於索引中而受益太多。
因此,從主索引中刪除第二個鍵列(從而減少索引的記憶體消耗)並使用多個主索引是有意義的。
但是,如果複合主鍵中的鍵列在基數上有很大的差異,那麼查詢按基數升序對主鍵列進行排序是有益的。
主鍵鍵列之間的基數差越大,主鍵鍵列的順序越重要。我們將在以後的文章中對此進行演示。請繼續關注。