關於文章《爬取知網文獻資訊》中程式碼的一些優化
哈嘍大家好,我是鹹魚
之前寫了一篇關於文獻爬蟲的文章
文章釋出之後有很多小夥伴給出了一些反饋和指正,在認真看了小夥伴們的留言之後,鹹魚對程式碼進行了一些優化
優化的程式碼在文末,歡迎各位小夥伴給出意見和指正
問題
-
pycharm 設定 Edge 驅動器的環境報錯
「module 'selenium.webdriver' has no attribute 'EdgeOptions」
如果瀏覽器驅動已經下載,而放在了合適的位置(比如新增到環境變數裡,或者放在了 python.exe 同級目錄中)
那就可能是因為你使用的是較老的版本,Edge的選項已經被更新了。 建議更新 selenium 包以獲得最佳的Edge選項支援
可以通過以下命令更新 selenium,建議更新到 4.6 以上版本
pip install -U selenium
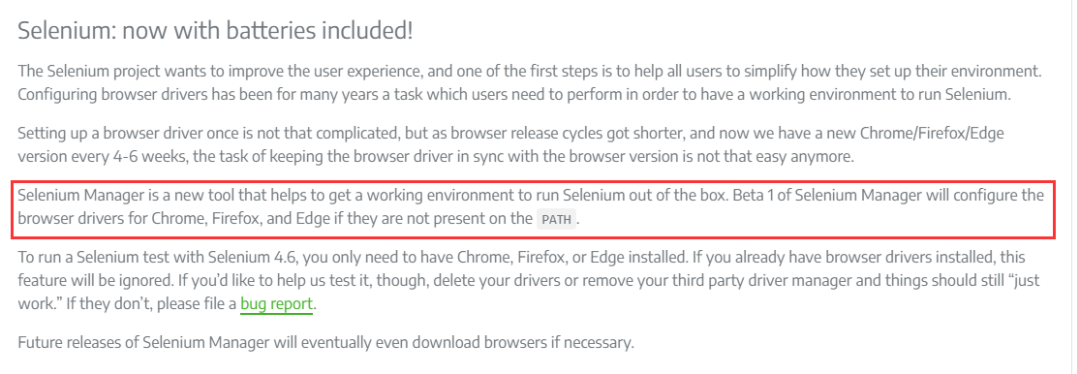
因為 selenium 4.6 版本之後內建了一個元件:Selenium Manager
根據官網介紹,這個 Selenium Manager 可以幫助你獲得一個執行 Selenium 的開箱即用的環境
如果在 PATH 中沒有找到 Chrome、Firefox 和 Edge 的驅動,Selenium Manager的 Beta 1版將為它們設定。不需要額外的設定
這就意味著自己不需要再去下載安裝瀏覽器驅動
中文檔案連結:
https://www.selenium.dev/zh-cn/documentation/webdriver/getting_started/install_drivers/
-
只能爬取20倍數的文獻篇數
有位粉絲髮現每次爬取都是爬取 20 倍數的文獻篇數(20、40、60)。假設要爬取 21 篇,但是卻爬到了 40 篇
排查的時候發現是程式碼中的邏輯有一些 bug ,已經優化
-
獲取不到網頁的 xpath 元素
第一種可能是網頁中的 xpath 元素並不是一成不變的,要參考自己的瀏覽器上的 Xpath。在我這可能是div[3],在你那可能就不是這個了,所以說需要自己先定位一遍
第二種可能是網頁載入太慢導致爬蟲爬取不到,這種情況的話可以增加等待超時時間
-
關於網頁載入太慢導致程式爬取不到元素報超時異常或者元素不存在異常
我的程式碼中用的都是顯示等待 + 強制等待結合的方式。如果還是不行,小夥伴們可以自行設定超時時間
優化後程式碼

下面給出優化後的原始碼
import time from selenium import webdriver from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.common.by import By from selenium.webdriver.common.desired_capabilities import DesiredCapabilities from urllib.parse import urljoin def open_page(driver, theme): # 開啟頁面 driver.get("https://www.cnki.net") # 傳入關鍵字 WebDriverWait(driver, 100).until( EC.presence_of_element_located((By.XPATH, '''//*[@id="txt_SearchText"]'''))).send_keys(theme) # 點選搜尋 WebDriverWait(driver, 100).until( EC.presence_of_element_located((By.XPATH, "/html/body/div[2]/div[2]/div/div[1]/input[2]"))).click() time.sleep(3) # 點選切換中文文獻 WebDriverWait(driver, 100).until( EC.presence_of_element_located((By.XPATH, "/html/body/div[3]/div[1]/div/div/div/a[1]"))).click() time.sleep(3) # 獲取總文獻數和頁數 res_unm = WebDriverWait(driver, 100).until(EC.presence_of_element_located( (By.XPATH, "/html/body/div[3]/div[2]/div[2]/div[2]/form/div/div[1]/div[1]/span[1]/em"))).text # 去除千分位裡的逗號 res_unm = int(res_unm.replace(",", '')) page_unm = int(res_unm / 20) + 1 print(f"共找到 {res_unm} 條結果, {page_unm} 頁。") return res_unm def crawl(driver, papers_need, theme): # 賦值序號, 控制爬取的文章數量 count = 1 # 當爬取數量小於需求時,迴圈網頁頁碼 while count <= papers_need: # 等待載入完全,休眠3S time.sleep(3) title_list = WebDriverWait(driver, 10).until(EC.presence_of_all_elements_located((By.CLASS_NAME, "fz14"))) # 迴圈網頁一頁中的條目 for i in range(len(title_list)): try: if (count % 20) != 0: term = count % 20 # 本頁的第幾個條目 else: term = 20 title_xpath = f"/html/body/div[3]/div[2]/div[2]/div[2]/form/div/table/tbody/tr[{term}]/td[2]" author_xpath = f"/html/body/div[3]/div[2]/div[2]/div[2]/form/div/table/tbody/tr[{term}]/td[3]" source_xpath = f"/html/body/div[3]/div[2]/div[2]/div[2]/form/div/table/tbody/tr[{term}]/td[4]" date_xpath = f"/html/body/div[3]/div[2]/div[2]/div[2]/form/div/table/tbody/tr[{term}]/td[5]" database_xpath = f"/html/body/div[3]/div[2]/div[2]/div[2]/form/div/table/tbody/tr[{term}]/td[6]" title = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.XPATH, title_xpath))).text authors = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.XPATH, author_xpath))).text source = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.XPATH, source_xpath))).text date = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.XPATH, date_xpath))).text database = WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.XPATH, database_xpath))).text # 點選條目 title_list[i].click() # 獲取driver的控制程式碼 n = driver.window_handles # driver切換至最新生產的頁面 driver.switch_to.window(n[-1]) time.sleep(3) # 開始獲取頁面資訊 title = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.XPATH ,"/html/body/div[2]/div[1]/div[3]/div/div/div[3]/div/h1"))).text authors = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.XPATH ,"/html/body/div[2]/div[1]/div[3]/div/div/div[3]/div/h3[1]"))).text institute = WebDriverWait(driver, 10).until(EC.presence_of_element_located( (By.XPATH, "/html/body/div[2]/div[1]/div[3]/div/div/div[3]/div/h3[2]"))).text abstract = WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.CLASS_NAME, "abstract-text"))).text try: keywords = WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.CLASS_NAME, "keywords"))).text[:-1] cssci = WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.XPATH, "/html/body/div[2]/div[1]/div[3]/div/div/div[1]/div[1]/a[2]"))).text except: keywords = '無' cssci = 'NULL' url = driver.current_url res = f"{count}\t{title}\t{authors}\t{cssci}\t{institute}\t{date}\t{source}\t{database}\t{keywords}\t{abstract}\t{url}".replace( "\n", "") + "\n" print(res) '''寫入檔案,有需要的小夥伴可以去掉註釋''' # with open(f'CNKI_{theme}.tsv', 'a', encoding='gbk') as f: # f.write(res) except: print(f" 第{count} 條爬取失敗\n") # 跳過本條,接著下一個 continue finally: # 如果有多個視窗,關閉第二個視窗, 切換回主頁 n2 = driver.window_handles if len(n2) > 1: driver.close() driver.switch_to.window(n2[0]) # 爬完一篇計數加 1 count += 1 if count > papers_need: break WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.XPATH, "//a[@id='PageNext']"))).click() if __name__ == "__main__": print("開始爬取!") # get直接返回,不再等待介面載入完成 desired_capabilities = DesiredCapabilities.CHROME desired_capabilities["pageLoadStrategy"] = "none" # 設定驅動器的環境 options = webdriver.EdgeOptions() # 設定chrome不載入圖片,提高速度 options.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2}) # 設定不顯示視窗 options.add_argument('--headless') # 建立一個瀏覽器驅動器 driver = webdriver.Edge(options=options) # 輸入需要搜尋的主題 # theme = input("請輸入你要搜尋的期刊名稱:") theme = "python" # 設定所需篇數 # papers_need = int(input("請輸入你要爬取篇數:")) papers_need = 100 res_unm = int(open_page(driver, theme)) # 判斷所需是否大於總篇數 papers_need = papers_need if (papers_need <= res_unm) else res_unm crawl(driver, papers_need, theme) print("爬取完畢!") # 關閉瀏覽器 driver.close()