Gradio入門到進階全網最詳細教學[二]:快速搭建AI演演算法視覺化部署演示(側重引數詳解和案例實踐)
Gradio入門到進階全網最詳細教學[二]:快速搭建AI演演算法視覺化部署演示(側重引數詳解和案例實踐)
相關文章:Gradio入門到進階全網最詳細教學[一]:快速搭建AI演演算法視覺化部署演示(側重專案搭建和案例分享)
在教學一中主要側重講解gradio的基礎模組搭建以及demo展示,本篇文章則會側重實際任務的搭建。
1.經典案例簡單的RGB轉灰度
保持一貫作風簡單展示一下如何使用
import gradio as gr
import cv2
def to_black(image):
output = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
return output
interface = gr.Interface(fn=to_black, inputs="image", outputs="image")
interface.launch()
gradio的核心是它的gr.Interface函數,用來構建視覺化介面。
- fn:放你用來處理的函數
- inputs:寫你的輸入型別,這裡輸入的是影象,所以是"image"
- outputs:寫你的輸出型別,這裡輸出的是影象,所以是"image"
最後我們用interface.lauch()把頁面一發布,一個本地靜態互動頁面就完成了!在瀏覽器輸入http://127.0.0.1:7860/,查收你的頁面:
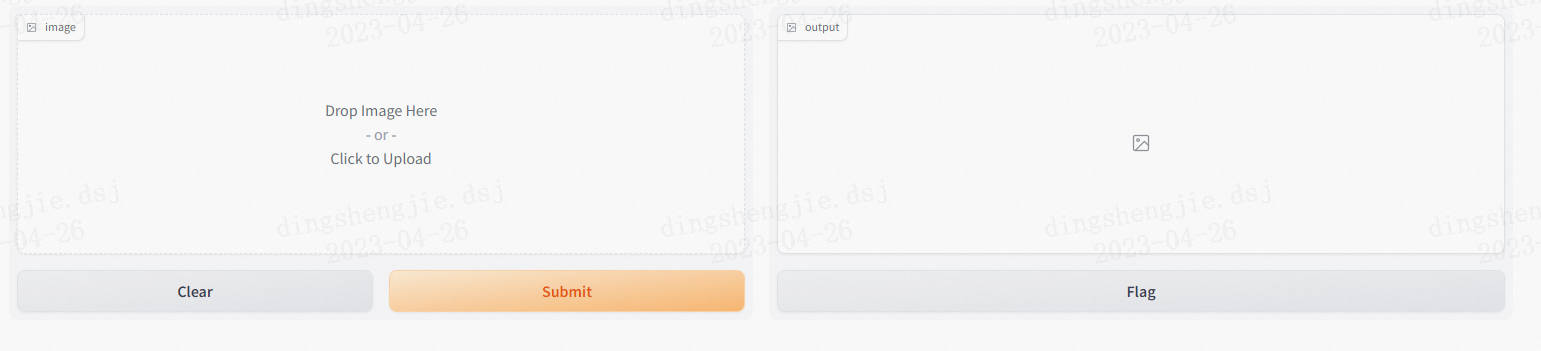
- 上傳一張圖片,點選「SUBMIT」

對於任何影象處理類的ML程式碼來說,只要定義好一個影象輸入>>模型推理>>返回圖片的函數(邏輯和RGB轉灰度圖本質上沒區別),放到fn中即可。
1.1 增加example
可以在頁面下方新增供使用者選擇的測試樣例。
在gr.Interface裡的examples中放入圖片路徑,格式為[[路徑1],[路徑2],...]。
import gradio as gr
import cv2
def to_black(image):
output = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
return output
interface = gr.Interface(fn=to_black, inputs="image", outputs="image",
examples=[["gradio/test.png"]])
interface.launch()
增加example不僅能讓你的UI介面更美觀,邏輯更完善,也有一些其他意義:比如做了一個影象去噪演演算法,但是使用者手頭並沒有躁點照片,example能讓他更快的體驗到效果
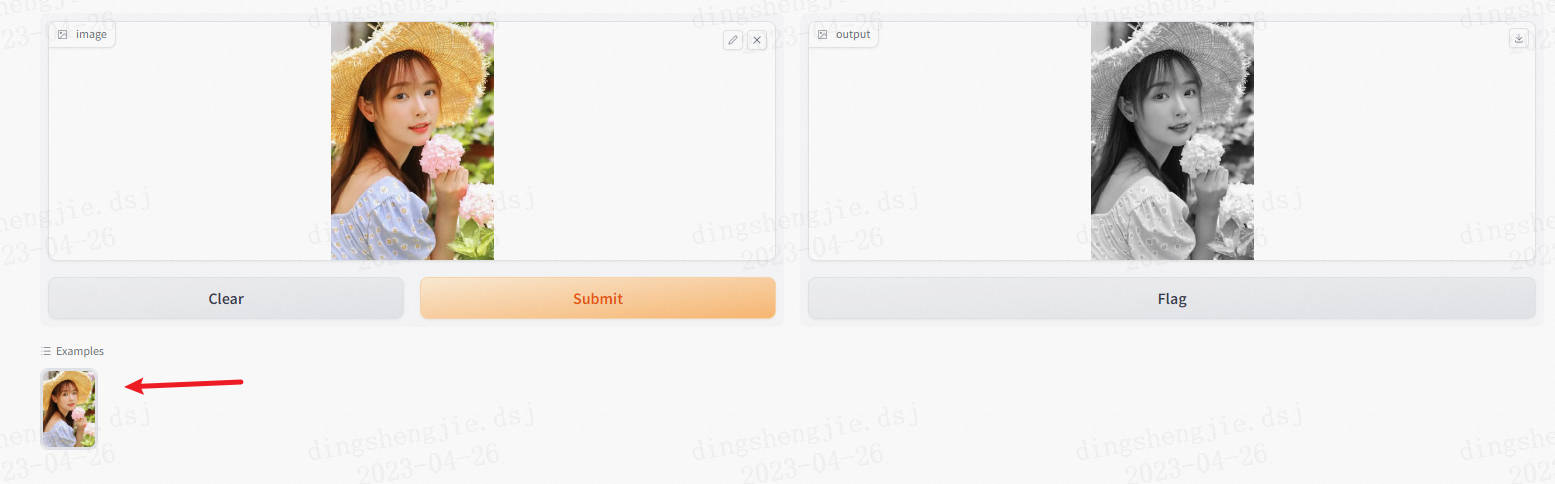
-
建立一個外部存取連結
-
建立外部存取連結非常簡單,只需要launch(share=True)即可,在列印資訊中會看到你的外部存取連結。
-
需要注意:免費使用者的連結可以使用24小時,想要長期的話需要在gradio官方購買雲服務。
-
2. 文字分類
在Gradio中搭建一個實用的自然語言處理應用最少只需要三行程式碼!讓我們三行程式碼來搭建一個文字分類模型的演示系統,這裡使用的模型是uer/roberta-base-finetuned-dianping-chinese,程式碼如下
#匯入gradio
import gradio as gr
#匯入transformers相關包
from transformers import *
#通過Interface載入pipeline並啟動服務
gr.Interface.from_pipeline(pipeline("text-classification", model="uer/roberta-base-finetuned-dianping-chinese")).launch()
過程中需要載入一個400MB的模型。
直接執行即可,執行後,服務預設會啟動在原生的7860埠,開啟連結即可。

可以在左側輸入待分類文字,而後點選submit按鈕,右側便會展示出預測的標籤及概率,如下圖所示

3. 閱讀理解
#匯入gradio
import gradio as gr
#匯入transformers相關包
from transformers import *
#通過Interface載入pipeline並啟動服務
gr.Interface.from_pipeline(pipeline("question-answering", model="uer/roberta-base-finetuned-dianping-chinese")).launch()
再次開啟,可以看到介面中除了幾個按鈕外的內容全部進行了更新,變成了閱讀理解相關的內容,輸入部分包括了context和question兩部分,輸出也變成了answer和score兩部分。
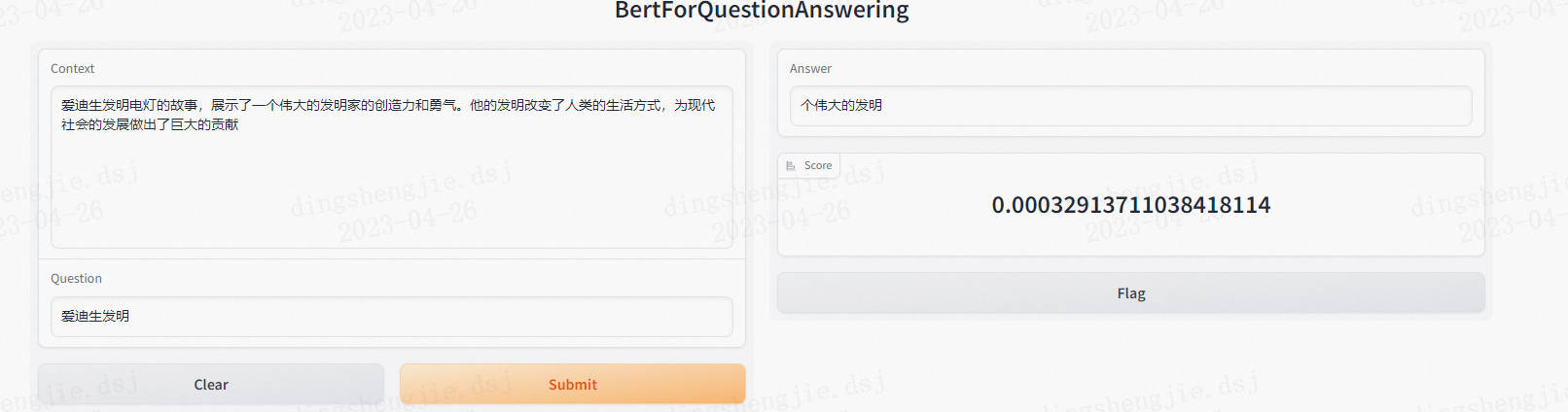
效果上不佳可以考慮重新載入以及微調模型
3.1完善頁面
儘管我們快速的啟動了一個demo,但是頁面整體還是較為簡陋的,除了標題和實際的呼叫部分,缺少一些其他內容,我們可以通過設定幾個簡單的引數,將頁面進行完善,還是以閱讀理解任務為例,程式碼如下:
import gradio as gr
from transformers import *
#標題
title = "抽取式問答"
#標題下的描述,支援md格式
description = "輸入上下文與問題後,點選submit按鈕,可從上下文中抽取出答案,趕快試試吧!"
#輸入樣例
examples = [
["普希金從那裡學習人民的語言,吸取了許多有益的養料,這一切對普希金後來的創作產生了很大的影響。這兩年裡,普希金創作了不少優秀的作品,如《囚徒》、《致大海》、《致凱恩》和《假如生活欺騙了你》等幾十首抒情詩,敘事詩《努林伯爵》,歷史劇《鮑里斯·戈都諾夫》,以及《葉甫蓋尼·奧涅金》前六章。", "著名詩歌《假如生活欺騙了你》的作者是"],
["普希金從那裡學習人民的語言,吸取了許多有益的養料,這一切對普希金後來的創作產生了很大的影響。這兩年裡,普希金創作了不少優秀的作品,如《囚徒》、《致大海》、《致凱恩》和《假如生活欺騙了你》等幾十首抒情詩,敘事詩《努林伯爵》,歷史劇《鮑里斯·戈都諾夫》,以及《葉甫蓋尼·奧涅金》前六章。", "普希金創作的敘事詩叫什麼"]
]
#頁面最後的資訊,可以選擇參照文章,支援md格式
article = "感興趣的小夥伴可以閱讀[gradio專欄](https://blog.csdn.net/sinat_39620217/category_12298724.html?spm=1001.2014.3001.5482)"
gr.Interface.from_pipeline(
pipeline("question-answering", model="uer/roberta-base-chinese-extractive-qa"),
title=title, description=description, examples=examples, article=article).launch()
- 執行上述程式碼,將看到如下頁面,這裡的example是可以點選的,點選後將自動填充至context和question中
- 由於description和article欄位支援md語法,因此我們可以根據需求,自行的去豐富完善各部分內容

4.Interface使用詳解
前面的內容中構建演示系統都是基於pipeline的,各個部分的模組都是定義好的,快速啟動的同時,在靈活性上有所欠缺。
簡單的說,就需要兩步:
- 第一步,定義執行函數;
- 第二步,繫結執行函數並指定輸入輸出元件。
假設還是閱讀理解任務,但是我們這次不適用基於pipeline的載入方式,而是自定義實現,要求輸入包含context、question,輸出包含answer和score,但是這裡的answer要求要把問題拼接上,如前面的範例,answer為普希金,這裡的答案要變為:著名詩歌《假如生活欺騙了你》的作者是:普希金 ,針對這一需求,我們看下要如何實現。
- 首先,定義執行函數。該函數輸入包括context和question兩部分,輸出包括answer和score,本質上還是呼叫pipeline進行推理,但是在答案生成時我們做了額外的拼接處理。
qa = pipeline("question-answering", model="uer/roberta-base-chinese-extractive-qa")
def custom_predict(context, question):
answer_result = qa(context=context, question=question)
answer = question + ": " + answer_result["answer"]
score = answer_result["score"]
return answer, score
- 接下來,在Interface中繫結執行函數並指定輸入輸出元件,fn欄位繫結執行函數;inputs欄位指定輸入元件,這裡是context和question兩個文字輸入,因此inputs欄位的值為["text", "text"]陣列(這裡的text表示輸入元件為TextBox,text只是一種便捷的指定方式);outputs欄位指定輸出元件,answer是文字輸出,score可以用標籤輸出,這裡採取了和inputs欄位不一樣的建立方式,我們直接建立了對應的元件,這種方式的使用優勢在於可以對元件進行更精細的設定,例如這裡我們便分別指定了兩個輸出模組的label 。
gr.Interface(fn=custom_predict, inputs=["text", "text"], outputs=[gr.Textbox(label="answer"), gr.Label(label="score")],
title=title, description=description, examples=examples, article=article).launch()
注意點:
- 輸入輸出要與函數的輸入輸出個數一致
- outputs欄位,推薦使用建立的方式,否則頁面顯示的標籤都是output*,不夠清晰
完整程式碼:
import gradio as gr
from transformers import *
#標題
title = "抽取式問答"
#題下的描述,支援md格式
description = "輸入上下文與問題後,點選submit按鈕,可從上下文中抽取出答案,趕快試試吧!"
#輸入樣例
examples = [
["普希金從那裡學習人民的語言,吸取了許多有益的養料,這一切對普希金後來的創作產生了很大的影響。這兩年裡,普希金創作了不少優秀的作品,如《囚徒》、《致大海》、《致凱恩》和《假如生活欺騙了你》等幾十首抒情詩,敘事詩《努林伯爵》,歷史劇《鮑里斯·戈都諾夫》,以及《葉甫蓋尼·奧涅金》前六章。", "著名詩歌《假如生活欺騙了你》的作者是"],
["普希金從那裡學習人民的語言,吸取了許多有益的養料,這一切對普希金後來的創作產生了很大的影響。這兩年裡,普希金創作了不少優秀的作品,如《囚徒》、《致大海》、《致凱恩》和《假如生活欺騙了你》等幾十首抒情詩,敘事詩《努林伯爵》,歷史劇《鮑里斯·戈都諾夫》,以及《葉甫蓋尼·奧涅金》前六章。", "普希金創作的敘事詩叫什麼"]
]
#頁面最後的資訊,可以選擇參照文章,支援md格式
article = "感興趣的小夥伴可以閱讀[gradio專欄](https://blog.csdn.net/sinat_39620217/category_12298724.html?spm=1001.2014.3001.5482)"
qa = pipeline("question-answering", model="uer/roberta-base-chinese-extractive-qa")
def custom_predict(context, question):
answer_result = qa(context=context, question=question)
answer = question + ": " + answer_result["answer"]
score = answer_result["score"]
return answer, score
gr.Interface(fn=custom_predict, inputs=["text", "text"], outputs=[gr.Textbox(label="answer"), gr.Label(label="score")],
title=title, description=description, examples=examples, article=article).launch()
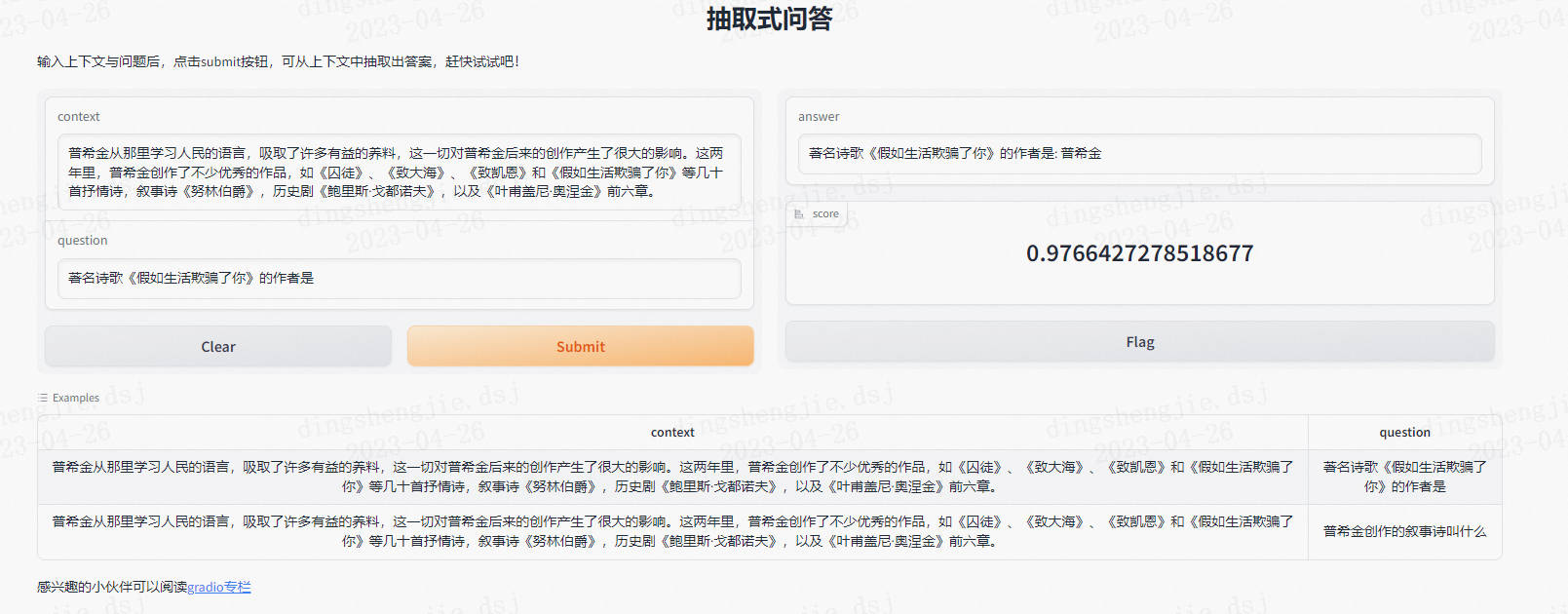
可以看到,其他的部分與我們使用pipeline建立的方式都一致,只是在answer部分有了變化。通過這種方式,我們可以建立出更加複雜的包含任意輸入、輸出的系統。
5.Blocks使用詳解
事實上,Interface是一個更加高階的元件,雖然它已經支援了了一定的自定義內容,但是靈活性還是略差一些,如果有注意的話,可以回到上文看下,所有的元件都是被劃分為了左右兩部分,左側輸入,右側輸出。使用Interface就要接受這樣的預設設定,那麼假設你現在就想做成上下結構,上面輸入,下面輸出,那麼,我們就需要用到Block。
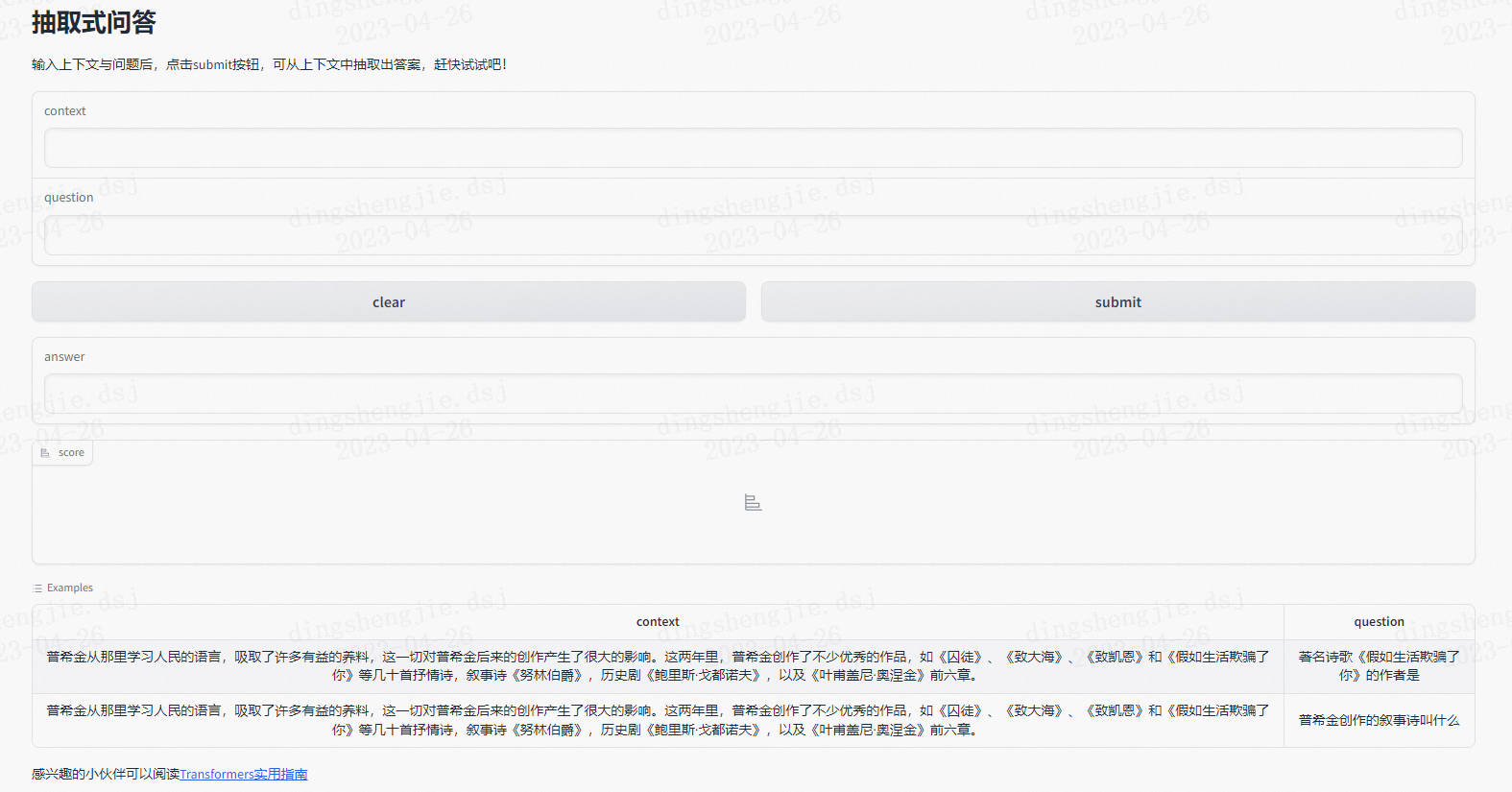
Blocks是比Interface更加底層一些的模組,支援一些簡單的自定義排版,那麼下面就讓我們來重構一下上面元件排列。整體是上下結構,從上到下,依次是context輸入、question輸入,clear按鈕和submit按鈕(在一橫排),answer輸出,score輸出,其餘如title、examples等內容不變,程式碼如下
import gradio as gr
from transformers import *
title = "抽取式問答"
description = "輸入上下文與問題後,點選submit按鈕,可從上下文中抽取出答案,趕快試試吧!"
examples = [
["普希金從那裡學習人民的語言,吸取了許多有益的養料,這一切對普希金後來的創作產生了很大的影響。這兩年裡,普希金創作了不少優秀的作品,如《囚徒》、《致大海》、《致凱恩》和《假如生活欺騙了你》等幾十首抒情詩,敘事詩《努林伯爵》,歷史劇《鮑里斯·戈都諾夫》,以及《葉甫蓋尼·奧涅金》前六章。", "著名詩歌《假如生活欺騙了你》的作者是"],
["普希金從那裡學習人民的語言,吸取了許多有益的養料,這一切對普希金後來的創作產生了很大的影響。這兩年裡,普希金創作了不少優秀的作品,如《囚徒》、《致大海》、《致凱恩》和《假如生活欺騙了你》等幾十首抒情詩,敘事詩《努林伯爵》,歷史劇《鮑里斯·戈都諾夫》,以及《葉甫蓋尼·奧涅金》前六章。", "普希金創作的敘事詩叫什麼"]
]
article = "感興趣的小夥伴可以閱讀[Transformers實用指南](https://zhuanlan.zhihu.com/p/548336726)"
#預測函數
qa = pipeline("question-answering", model="uer/roberta-base-chinese-extractive-qa")
def custom_predict(context, question):
answer_result = qa(context=context, question=question)
answer = question + ": " + answer_result["answer"]
score = answer_result["score"]
return answer, score
#清除輸入輸出
def clear_input():
return "", "", "", ""
#構建Blocks上下文
with gr.Blocks() as demo:
gr.Markdown("# 抽取式問答")
gr.Markdown("輸入上下文與問題後,點選submit按鈕,可從上下文中抽取出答案,趕快試試吧!")
with gr.Column(): # 列排列
context = gr.Textbox(label="context")
question = gr.Textbox(label="question")
with gr.Row(): # 行排列
clear = gr.Button("clear")
submit = gr.Button("submit")
with gr.Column(): # 列排列
answer = gr.Textbox(label="answer")
score = gr.Label(label="score")
#繫結submit點選函數
submit.click(fn=custom_predict, inputs=[context, question], outputs=[answer, score])
# 繫結clear點選函數
clear.click(fn=clear_input, inputs=[], outputs=[context, question, answer, score])
gr.Examples(examples, inputs=[context, question])
gr.Markdown("感興趣的小夥伴可以閱讀[Transformers實用指南](https://zhuanlan.zhihu.com/p/548336726)")
demo.launch()
當我們的服務啟動起來後,還是在原生的,雖然存取是能存取了,但是還是會受到網路的限制。Gradio提供了一種非常方便的方式,可以使得原生的服務在任何地方都可以呼叫。程式碼上,我們只需要在launch方法呼叫時,指定share引數值為True。服務除了有一個本地地址,還有一個公網的地址https://11886.gradio.app,雖然時間只有72小時
demo.launch(inbrowser=True, inline=False, validate=False, share=True)
- inbrowser - 模型是否應在新的瀏覽器視窗中啟動。
- inline - 模型是否應該嵌入在互動式python環境中(如jupyter notebooks或colab notebooks)。
- validate - gradio是否應該在啟動之前嘗試驗證介面模型相容性。
- share - 是否應建立共用模型的公共連結。用於處理。

參考連結: