如何生成文字: 通過 Transformers 用不同的解碼方法生成文字
簡介
近年來,隨著以 OpenAI GPT2 模型 為代表的基於數百萬網頁資料訓練的大型 Transformer 語言模型的興起,開放域語言生成領域吸引了越來越多的關注。開放域中的條件語言生成效果令人印象深刻,典型的例子有: GPT2 在獨角獸話題上的精彩續寫,XLNet 以及 使用 CTRL 模型生成受控文字 等。促成這些進展的除了 transformer 架構的改進和大規模無監督訓練資料外,更好的解碼方法 也發揮了不可或缺的作用。
本文簡述了不同的解碼策略,同時向讀者展示瞭如何使用流行的 transformers 庫輕鬆實現這些解碼策略!
下文中的所有功能均可用於 自迴歸 語言生成任務 (點選 此處 回顧)。簡單複習一下, 自迴歸 語言生成是基於如下假設: 一個文字序列的概率分佈可以分解為每個詞基於其上文的條件概率的乘積。
上式中,\( W_0 \) 是初始 上下文 單詞序列。文字序列的長度 \( T \) 通常時變的,並且對應於時間步 \( t=T \)。\( P(w_{t} | w_{1: t- 1}, W_{0}) \) 的詞表中已包含 終止符 (End Of Sequence,EOS)。 transformers 目前已支援的自迴歸語言生成任務包括 GPT2 、 XLNet 、 OpenAi-GPT 、 CTRL 、 TransfoXL 、 XLM 、 Bart 、 T5 模型,並支援 PyTorch 和 TensorFlow (>= 2.0) 兩種框架!
我們會介紹目前最常用的解碼方法,主要有 貪心搜尋 (Greedy search)、波束搜尋 (Beam search)、Top-K 取樣 (Top-K sampling) 以及 Top-p 取樣 (Top-p sampling) 。
在此之前,我們先快速安裝一下 transformers 並把模型載入進來。本文我們用 GPT2 模型在 TensorFlow 2.1 中進行演示,但 API 和使用 PyTorch 框架是一一對應的。
!pip install -q git+https://github.com/huggingface/transformers.git
!pip install -q tensorflow==2.1
import tensorflow as tf
from transformers import TFGPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
# add the EOS token as PAD token to avoid warnings
model = TFGPT2LMHeadModel.from_pretrained("gpt2",pad_token_id=tokenizer.eos_token_id)
貪心搜尋
貪心搜尋在每個時間步 \( t \) 都簡單地選擇概率最高的詞作為當前輸出詞: \( w_t = argmax_{w}P(w | w_{1:t-1}) \) ,如下圖所示。
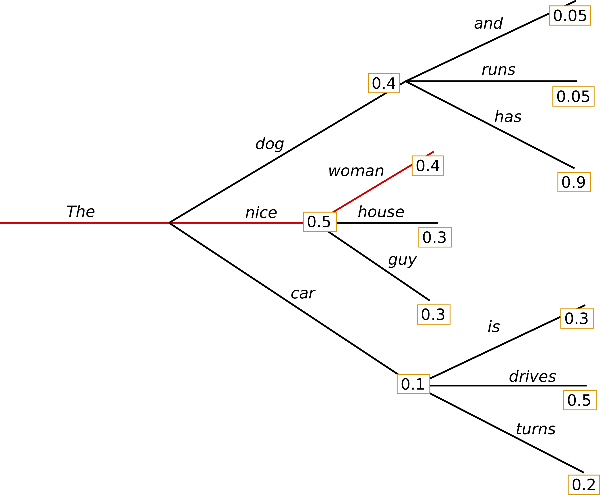
從單詞 \( \text{「The」} \) 開始,演演算法在第一步貪心地選擇條件概率最高的詞 \( \text{「nice」} \) 作為輸出,依此往後。最終生成的單詞序列為 \( \text{「The」}, \text{「nice」}, \text{「woman」} \),其聯合概率為 \( 0.5 \times 0.4 = 0.2 \)。
下面,我們輸入文字序列 \( (\text{「I」}, \text{「enjoy」}, \text{「walking」}, \text{「with」}, \text{「my」}, \text{「cute」}, \text{「dog」}) \) 給 GPT2 模型,讓模型生成下文。我們以此為例看看如何在 transformers 中使用貪心搜尋:
# encode context the generation is conditioned on
input_ids = tokenizer.encode('I enjoy walking with my cute dog', return_tensors='tf')
# generate text until the output length (which includes the context length) reaches 50
greedy_output = model.generate(input_ids, max_length=50)
print("Output:\n" + 100 *'-')
print(tokenizer.decode(greedy_output[0], skip_special_tokens=True))
Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with my dog. I'm not sure if I'll ever be able to walk with my dog.
I'm not sure if I'll
好,我們已經用 GPT2 生成了第一個短文字