ES的索引結構與演演算法解析
作者:京東物流 李洪吉
提到ES,大多數愛好者想到的都是搜尋引擎,但是明確一點,ES不等同於搜尋引擎。不管是谷歌、百度、必應、搜狗為代表的自然語言處理(NLP)、爬蟲、網頁處理、巨量資料處理的全文搜尋引擎,還是有明確搜尋目的的搜尋行為,如各大電商網站、OA、站內搜尋、視訊網站的垂直搜尋引擎,他們或多或少都使用到了ES。
作為搜尋引擎的一部分,ES自然具有速度快、結果準確、結果豐富等特點,那麼ES是如何達到「搜尋引擎」級別的查詢效率呢?首先是索引,其次是壓縮演演算法,接下來我們就一起了解下ES的索引結構和壓縮演演算法
1 結構
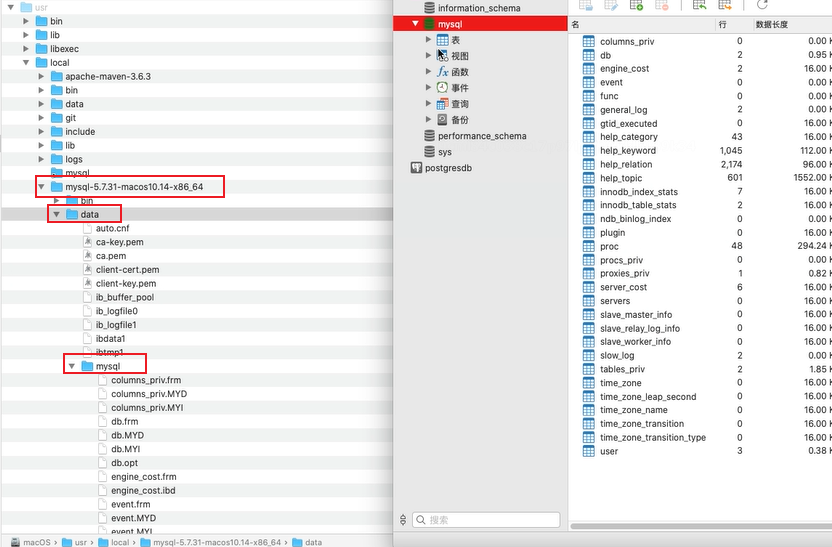
1.1 Mysql
Mysql下的data目錄存放的檔案就是mysql相關資料,mysql資料夾對應的就是資料庫mysql。
其中表columns_priv對應了3個檔案:columns_priv.frm、columns_priv.MYD、columns_priv.MYI。
.frm:表結構;.MYD:myisam儲存引擎原資料;.MYI:myisam儲存引擎索引;.ibd:innodb儲存引擎資料
1.2 Elasticsearch
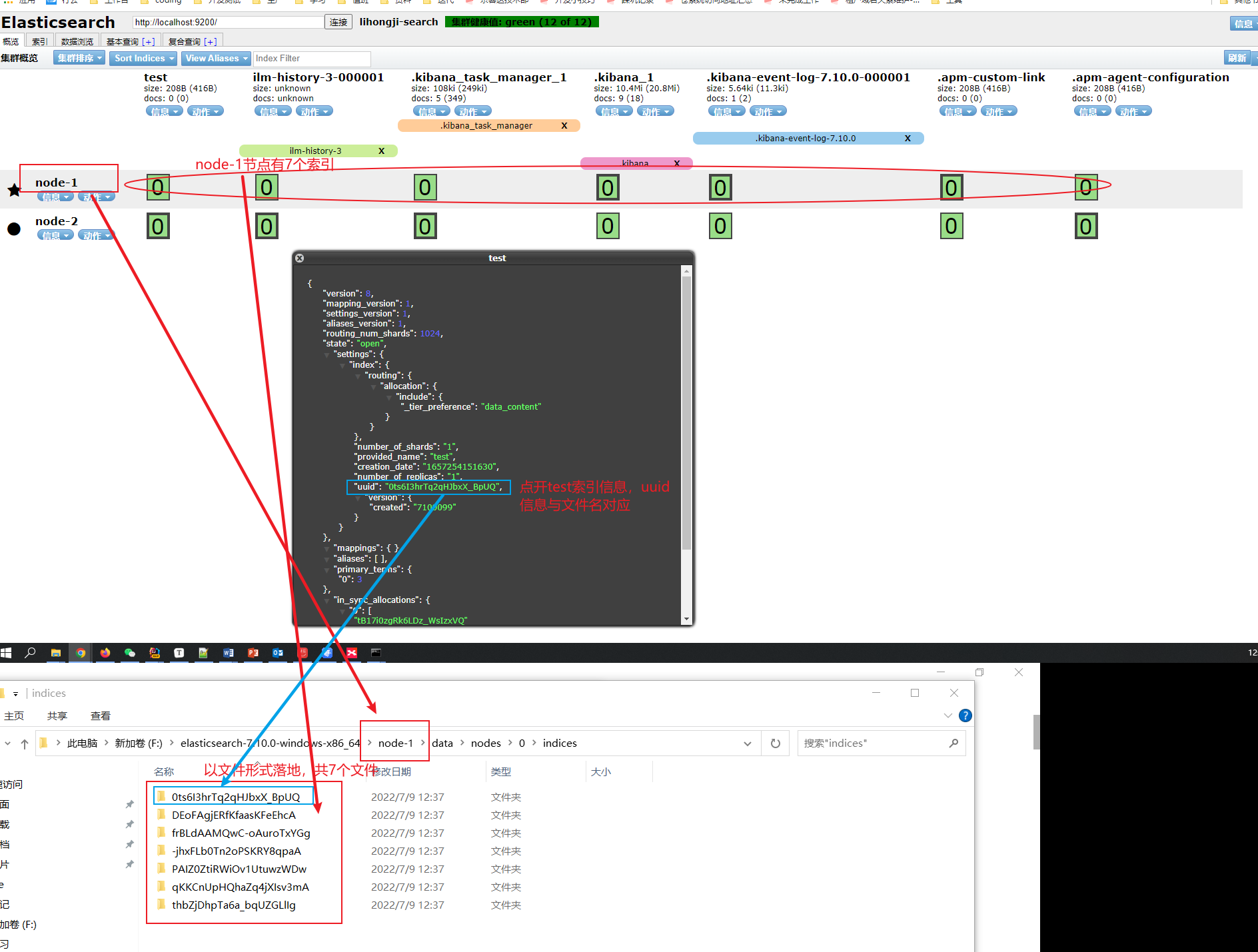
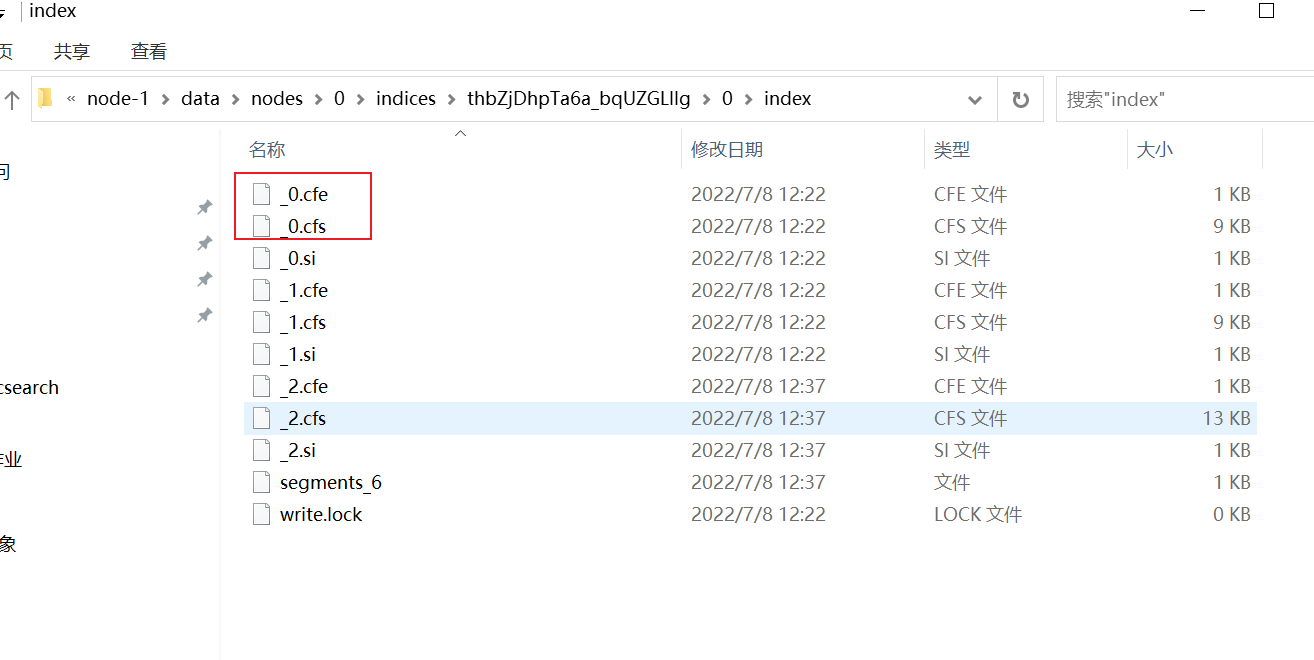
cfe為索引文,cfs 為資料檔案,cfe檔案儲存Lucene各檔案在.cfs檔案的位置資訊
cfs、cfe 在segment還很小的時候,將segment的所有檔案都存在在cfs中,在cfs逐漸變大時,大小超過shard的10%,則會拆分為其他檔案,如tim、dvd、fdt等檔案
1.3 儲存結構
倒排索引結構分為倒排表、詞項字典、詞項索引

倒排表包含某個詞項的所有id的資料儲存了在.doc檔案中
詞項字典包含了index field的所有經過處理之後的詞項資料,最終儲存在.tim檔案中
1.4 結構對比
我們以某商城的手機為例,左側為es倒排索引結構,右側為原始資料。左側圖示只是為了展示倒排索引結構,並不是說es中倒排表就是簡單的陣列
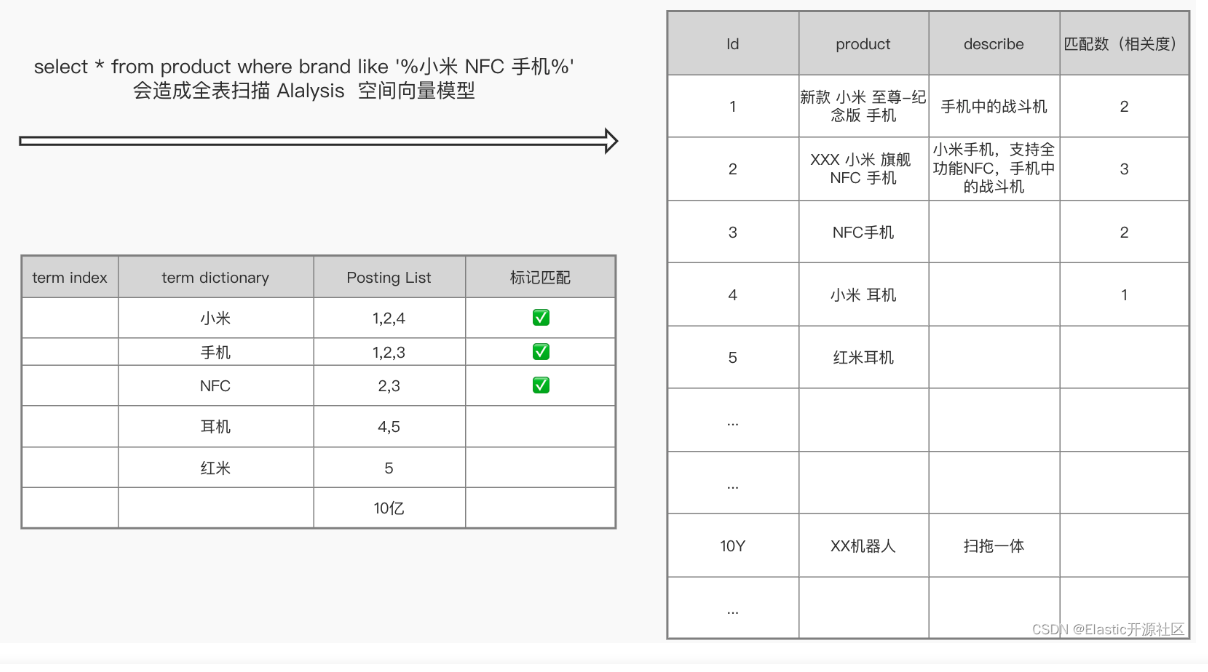
以上面結構對比範例圖為例,假如共有10億條資料需要儲存在ES中(上圖右),分詞後儲存的倒排表(上圖左)大概包含分詞term以及對應的id陣列等,在10億條資料中,分詞「小米」相關的資料有100萬條,也就是說分詞「小米」對應的陣列Posting List長度是100萬
id是int型別的有序主鍵,分詞「小米」在陣列Posting List中100萬int型別數位總長度=100萬✖每個int佔4位元組=400萬Byte≈4MB。1個分詞佔4MB空間,假如10億條資料有500萬個分詞,總空間=4MB✖500萬=2千萬MB,磁碟空間直接爆炸
2 演演算法
分詞對應的陣列Posting List實際就是一個個有序陣列,而有序數值陣列是比較容易進行壓縮處理的,而且一般來說壓縮效益也不錯,如果能對其進行壓縮是能夠大大節約空間資源的
ES中倒排索引的壓縮演演算法主要有FOR演演算法(Frame Of Reference)和RBM演演算法(RoaringBitMap)
2.1 FOR
FOR演演算法的核心思想是用減法來削減數值大小,從而達到降低空間儲存。 假設V(n)表示陣列中第n個欄位的值,那麼經過FOR演演算法壓縮的數值V(n)=V(n)-V(n-1)。也就是說儲存的是後一位減去前一位的差值。儲存是也不再按照int來計算了,而是看這個陣列的最大值需要佔用多少bit來計算

我們按照差值計算的方式來儲存資料,初始值為1,2與1的差值為1,3與2的差值為1……最終我們就將原始Posting List資料轉化為100萬個1,每個1我們可以用1bit來記錄,總空間=1bit✖100萬=100萬bit,相比原有400萬Byte=3200bit,空間壓縮了32倍

在實際生產中,不可能出現一個term的Posting List是這種差值均為1的情況,所以我們以通用範例舉例。假如原資料為[73,300,302,332,343,372],陣列中6個數位佔據總空間為24位元組。按照差值方式記錄,陣列轉化為[73,227,2,30,11,29],最大數位為227,大於2的7次方128,小於2的8次方256,所以每個數位可以使用8bit即1Byte來儲存,佔據總空間為1Byte*6 + 1Byte=7Byte
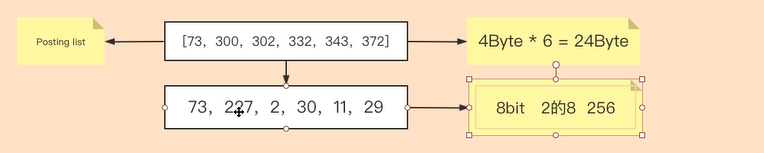
在此基礎上,我們將差值陣列按照密集度劃分為[73,227]和[2,30,11,29],其中[73,227]中最大值227介於2的7次方和2的8次方之間,所以用8bit=1Byte作為切割分段,[2,30,11,29]中最大數30介於2的4次方和2的5次方之間,所以用5bit作為切割分段。
陣列[73,227]佔據總空間為8bit✖2個=16bit=2Byte
陣列[2,30,11,29]佔據總空間為5bit✖4個=20bit=3Byte
為什麼20bit=3Byte呢?因為8bit=1Byte,小於8bit也會佔據1個位元組空間,所以17bit到24bit均為3Byte
所以,最終佔據總空間=1+2+1+3=7Byte
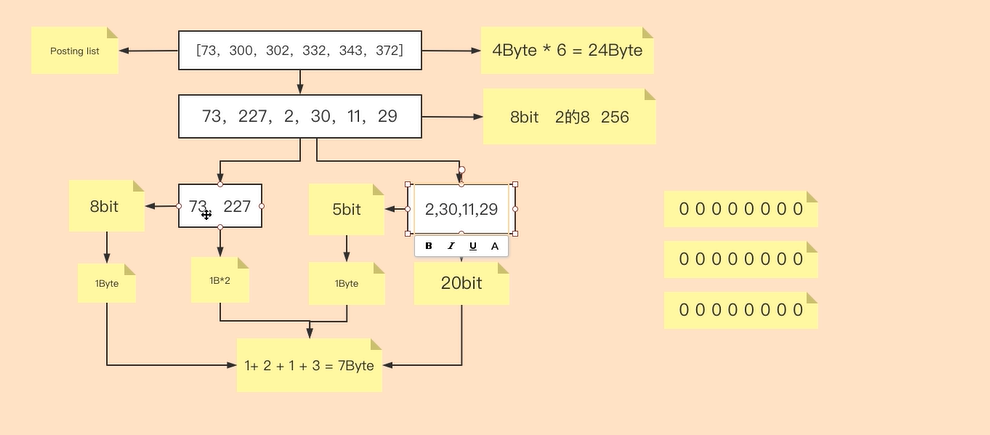
疑問一:既然原陣列[73,300,302,332,343,372]要按照密集度拆分為[73,227]和[2,30,11,29]兩個陣列,那為什麼不繼續往下拆分,直接拆分到每個數位是一個陣列,這樣使用bit記錄時佔據總空間會更少?
答:如果繼續拆分陣列,空間確實會使用更少,但是,之前我們提到搜尋引擎速度快的方式有兩種:高效的壓縮演演算法和快速的編碼解碼速度,單個數位儲存確實壓縮了空間,但是我們無法再通過解碼的方式將源資料還原
疑問二:為什麼源資料使用差值記錄佔據6Byte,拆分陣列後佔據7Byte,拆分後佔據空間不變,有時候甚至會變大,為什麼?
答:資料量小的情況下確實會出現該情況,因為我們需要拆分陣列並記錄拆分陣列的長度(如上面範例中的8bit和5bit),在原資料儲存空間基礎上還要儲存拆分長度,所以資料量小的情況下會出現比直接儲存佔據空間大的情況。但是不管是搜尋引擎還是Elasticsearch更多處理的是海量資料,資料量越多,差值陣列拆分的方式節省空間越明顯
2.2 RBM
我們已經瞭解了FOR壓縮演演算法,演演算法核心是將PostingList按照差值密集度轉化成兩個差值陣列。在這裡我們要考慮一種情況就是:在巨量資料中,10億條資料分詞500萬個,如果分詞「小米」所在PostList比較分散且差值很大,此時使用FOR演演算法效果就會大打折扣。所以稀疏的陣列,不適合使用FOR演演算法

在這裡我們以[1000,62101,131385,132052,191173,196658]為例,如果按照FOR演演算法,轉化成的差值陣列為[1000,61101,69284,667,59121,5485]密集度很低。我們採用RBM演演算法
源資料PostingList是由int型別組成的陣列,int型別=4Byte=32bit,最大值=2的32次方-1=4294967295≈43億。當資料較大且稀疏時,我們將32bit拆分為16bit和16bit,16bit最大值=65535,前16bit存放商,後16bit存放餘數,所以商和餘數都不會超過65535.我們將源陣列的值除以65536,得到的商和餘數分別存放在前16bit和後16bit。
以數位196658為例,轉化為2進位制,前16位元=3,後16位元=50
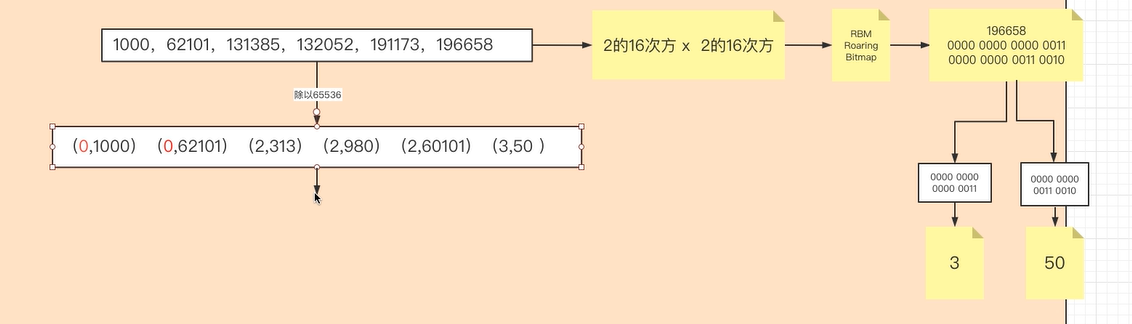
得到的結果以K-V存放。Key最大值為16bit,所以以short[]陣列存放,Value以Container存放。
由於源陣列為有序陣列,所以按照高低16位元轉化後,商和餘數都是從小到大排列

通過看Container原始碼,我們可以看到Container有3種:ArrayContainer、BitmapContainer、RunContainer。
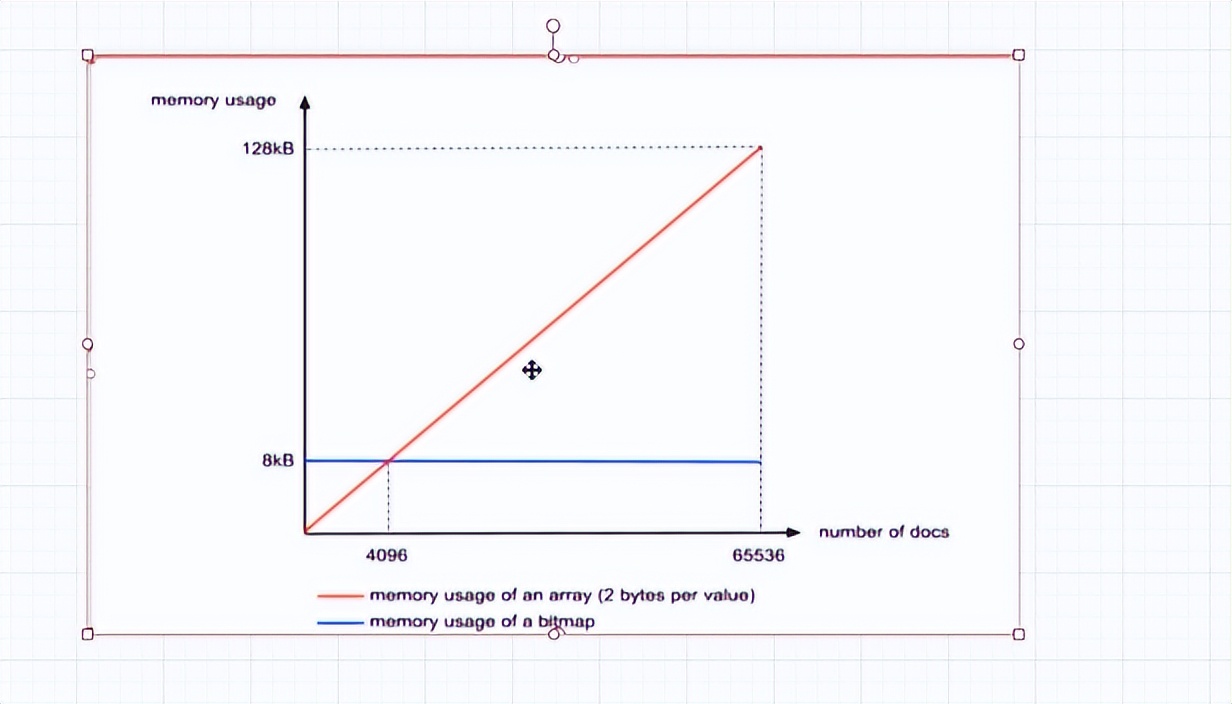
- ArrayContainer本質為集合,所以隨著陣列中數量越多,佔用空間越多,呈正向增長。
當陣列種數量為4096時,佔據總空間=4096個✖16bit(即2Byte)➗1024=8KB
當陣列種數量為65536時,佔據總空間=65536個✖16bit(即2Byte)➗1024=128KB
- BitmapContainer點陣圖,核心就是將原有儲存數值轉化成該數值在哪個位置上存在
由於餘數最大值為65535,所以我們需要65536位元點陣圖,數值是多少,在點陣圖上對應的位置就是多少。數值等於4096,則點陣圖上4096位值為1;數值等於65535,則點陣圖上65535位值為1。每個位置上的數都佔用8KB空間(8KB=65536bit)
- RunContainer用法相對狹隘,這種型別是Lucene 5之後新增的型別,主要應用在連續數位的儲存商,比如倒排表中儲存的陣列為 [1,2,3…100W] 這樣的連續陣列,如果使用RunContainer,只需儲存開頭和結尾兩個數位:1和100W,即佔用8個位元組。這種儲存方式的優缺點都很明顯,它嚴重收到數位連續性的影響,連續的數位越多,它儲存的效率就越高
- 如果陣列是如下形式 [1,2,3,4,5,100,101,102,999,1000,1001] 就會被拆分為三段:[1,5],[100,102],[999,1001]
至於每次儲存採用什麼容器,需要進行一下判定,比如ArrayContainer,當儲存的元素少於4096個時,他會比BitmapContainer佔用更少空間,而當大於4096個元素時,採用ArrayContainer所需要的空間就會大於8kb,那麼採用BitmapContainer就會佔用更少空間
3 總結
ES在處理海量資料時通過其獨到的結構和壓縮演演算法,將索引效率儘可能的提升。雖然在實際業務處理中我們極少遇到海量資料處理的情況,但是通過了解ES的原理,能夠幫我們開闊下視野,瞭解數位之美,演演算法之美。