巨量資料架構(二)巨量資料發展史
1.傳統數倉發展史
傳統資料倉儲的發展史這裡不展開架構細講,只需快速過一遍即可。瞭解這個歷史發展過程即可。
1.1 傳統數倉歷史
1.1.1 5個時代
傳統數倉發展史可以稱為5個時代的經典論證戰。按照兩位資料倉儲大師 Ralph kilmball、Bill Innmon 在資料倉儲建設理念上碰撞階段來作為小的分界線:
-
1970~1991 資料倉儲概念萌芽到全企業整合。
-
1991~1994 EDW企業資料整合時代。Bill Innmon 博士出版了《如何構建資料倉儲》,正規化建模。
-
1994~1996 資料市集時代。 Ralph Kimball 博士出版了《資料倉儲工具箱》,裡面非常清晰的定義了資料市集、維度建模。
-
1996~1997 神仙大戰時代(維度建模與正規化建模爭論)
-
1998~2001 合併時代,CIF架構。Bill Innmon推出了新的BI架構CIF(Corporation information factory),把Kimball的資料市集也包容進來了,第一次,Kimball承認了Inmon。
1.1.2 經典爭論
如果說,Hans Peter Luhn和Howard Dresner,一個為了文字挖掘,一個為了企業管理中的資訊民主,而定義了BI(智慧商業)的話。那麼Bill Inmon 和Ralph Kimball,這2位大師則通過不同理念,設計技術和實施策略使BI從定義落地為真實。兩位大師在1991-2001,引領了傳統數倉發展的一個時代。
。
Bill Innmon和Ralph kilmball論證的核心在於EDW(企業級資料倉儲)和資料市集的建立先後順序(也可以理解為正規化建模和維度建模的爭論)。
- Bill Inmon 提出自上而下的建設原則(EDW->DM):提倡先資料模型建立企業級資料倉儲EDW(3NF正規化建模)後,再建資料市集(DM)。
- Ralph kilmball 提出自下而上的建設原則(DM->EDW):提倡先建立資料市集,認為資料倉儲是資料市集的集合,資訊總是被儲存在多維模型(維度建模)中。後期可根據需要來合併資料市集,並逐步形成企業級的資料倉儲(EDW)。
兩種方法的明細區別如下表(摘自網路):
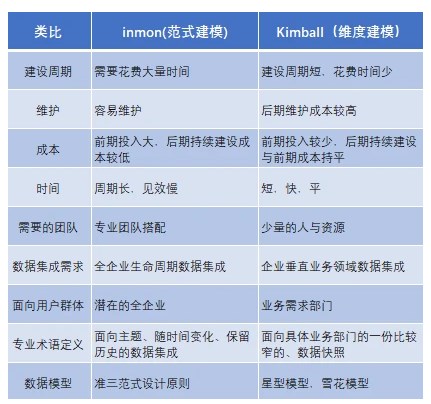
1.2 傳統資料倉儲架構史
伴隨著kilmball和Innmon的經典爭論,誕生了三代典型資料倉儲架構(網上有些文章把Opdm操作型資料市集架構定義為第四代資料倉儲架構,筆者不認可這一架構能和另外3個並列,故刪之),分別是:
- 企業級資料倉儲架構(Enterprise Data Warehouse,EDW)-BIll Inmon
- Kilmball DW/BI(Multidimensional Architecture,MD)-Ralph kilmball
- 企業資訊工廠架構(Corporate Information Factory,CIF)-BIll Inmon
1.2.1 企業級資料倉儲架構(Enterprise Data Warehouse,EDW)-BIll Inmon
90 年代 BIll Inmon 出版《如何構建資料倉儲》一書體系化的與明確定義瞭如何構建資料倉儲,這套方法在落地上形成了第一代資料倉儲架構。書中定義:資料倉儲(Data Warehouse) 是一個面向主題的(Subject Oriented) 、整合的( Integrate ) 、相對穩定的(Non -Volatile ) 、反映歷史變化( Time Variant) 的資料集合,用於支援管理決策( Decision Marking Support)。具體如下圖所示:

從左至右依次是資料來源、資料淨化、數倉、應用。
核心原理:
- 資料倉儲是面向主題的。
- 資料倉儲是整合的,資料倉儲的資料有來自於分散的操作型資料,將所需資料從原來的資料中抽取出來,進行加工與整合,統一與綜合之後才能進入資料倉儲。
- 資料倉儲是不可更新的,資料倉儲主要是為決策分析提供資料,所涉及的操作主要是資料的查詢。
- 資料倉儲是隨時間而變化的,傳統的關聯式資料庫系統比較適合處理格式化的資料,能夠較好的滿足商業商務處理的需求,它在商業領域取得了巨大的成功
1.2.2 Kimball DW/BI架構(Multidimensional Architecture,MD)-Ralph kimball
第二代就是 Kimball DW/BI架構。又稱Multidimensional Architecture(MD)多維架構,或Bus Architecture匯流排架構。即從業務或部門入手,設計面向業務或部門主題資料市集。(網上大部分都說Kimball的資料市集架構,筆者不贊同。Kimball提倡的是維度建模、匯流排架構思想。Kimball架構甚至都不包含物理的資料市集,而是邏輯概念上的)Kimball DW/BI架構從流程上看是是自底向上的,即從資料市集到資料倉儲(DM->DW)的一種敏捷開發方法。這種構建方式可以不用考慮其它正在進行的資料類專案實施,只要快速滿足當前部門的需求即可,這種實施的好處是阻力較小且路徑很短。
核心原理:一致性維度建模(匯流排型架構)+ 基於企業匯流排的資料倉儲
但是考慮到在實施中可能會存在多個並行的專案,是需要在資料標準化、模型階段是需要進行維度歸一化處理,需要有一套標準來定義公共維度,讓不同的資料市集專案都遵守相同的標準,在後面的多個資料市集做合併時可以平滑處理。比如業務中相似的名詞、不同系統的列舉值、相似的業務規則都需要做統一命名,這裡在現在的中臺就是全域統一ID之類的東西。具體如下圖所示:
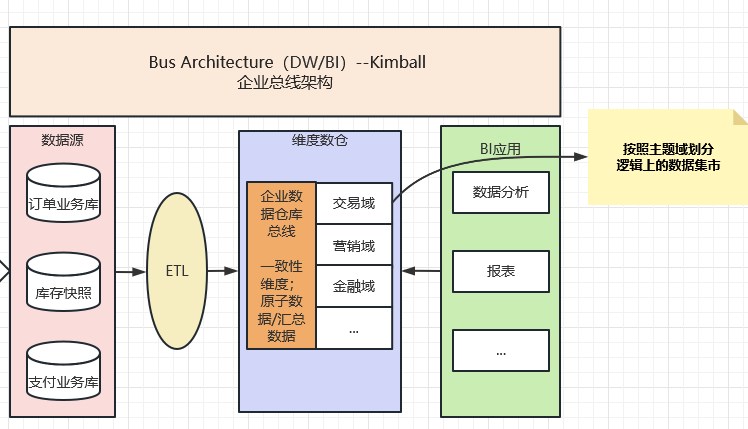
注意:kimball架構的資料倉儲是沒有實際存在資料市集的,如果非要區分,可以通過主題域劃分獲取自己的資料市集。(比如上圖的維度數倉下的交易域數倉,可以理解為邏輯上的資料市集。預留資料市集飛機票//TODO)
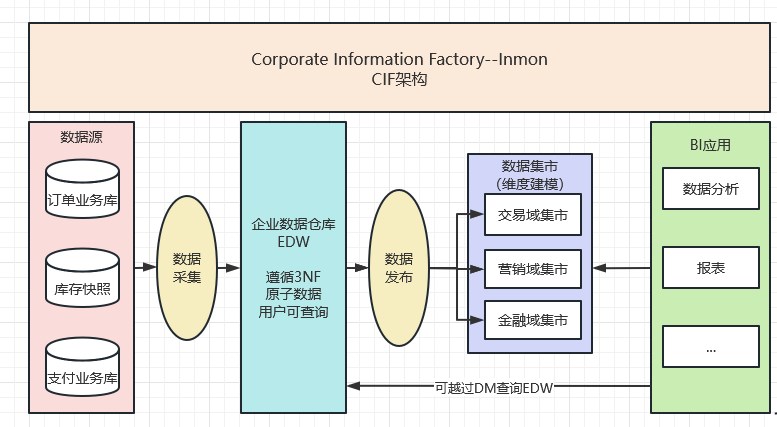
1.2.3 企業資訊工廠架構(Corporate Information Factory,CIF)-BIll Inmon
第三代架構就是CIF架構,CIF強制引入了一層規範化的、原子的(滿足第三正規化)企業資料倉儲EDW。這一層承擔了資料協調和整合的職責。Inmon 模式從流程上看是自頂向下的,即從資料倉儲再到資料市集的(DW->DM)。
核心原理:Inmon EDW企業數倉(遵循3NF)+ 資料市集。具體如下圖所示:
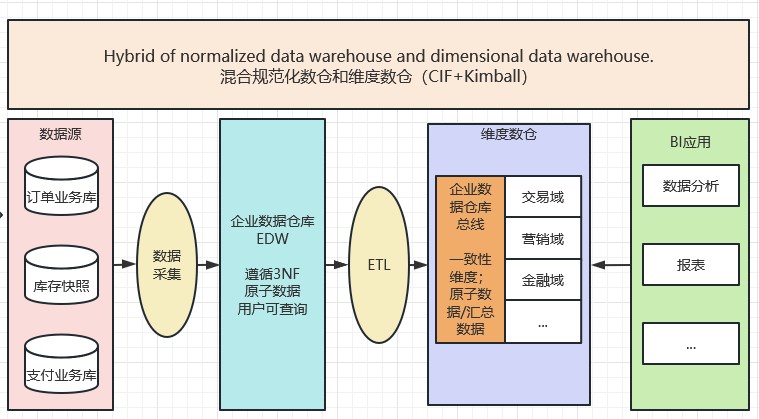
混合架構(CIF+Kimball,CIF2.0)
混合架構是CIF架構的變種,可以認為是CIF2.0架構。BIll Inmon把Kimball的多維架構融入進來(據說Inmon很生氣,沒能說服Kimball,一氣之下把Kimball架構也融進去了...)。並限定EDW不對外提供查詢能力,其中的資料是維度的、原子的、以過程為中心的。這種架構主要適用於前期已經購入建設了原子級的EDW,但尚無法滿足使用者的靈活的分析需求,在這種情況下可以採用這種架構,算是一種無奈之舉。 缺點很明顯,EDW和維度數倉資料冗餘造成資源浪費,架構複雜導致人力成本較高。
核心原理:Inmon EDW企業數倉(遵循3NF)+ Kimball 維度數倉(一致性維度)
2. 巨量資料架構發展史
根據巨量資料架構發展史,總結出歷史發展如下圖:

最終都會走向批流一體、湖倉一體的架構。
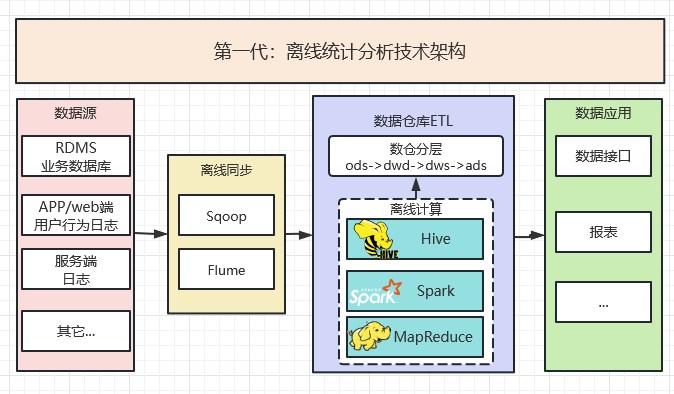
2.1 第一代:離線統計分析技術架構
特點:
1、資料來源通過離線的方式匯入到離線數倉中;
2、資料處理採用MapReduce、Hive、SparkSQL 等離線計算引擎。 架構及資料處理流程如下;
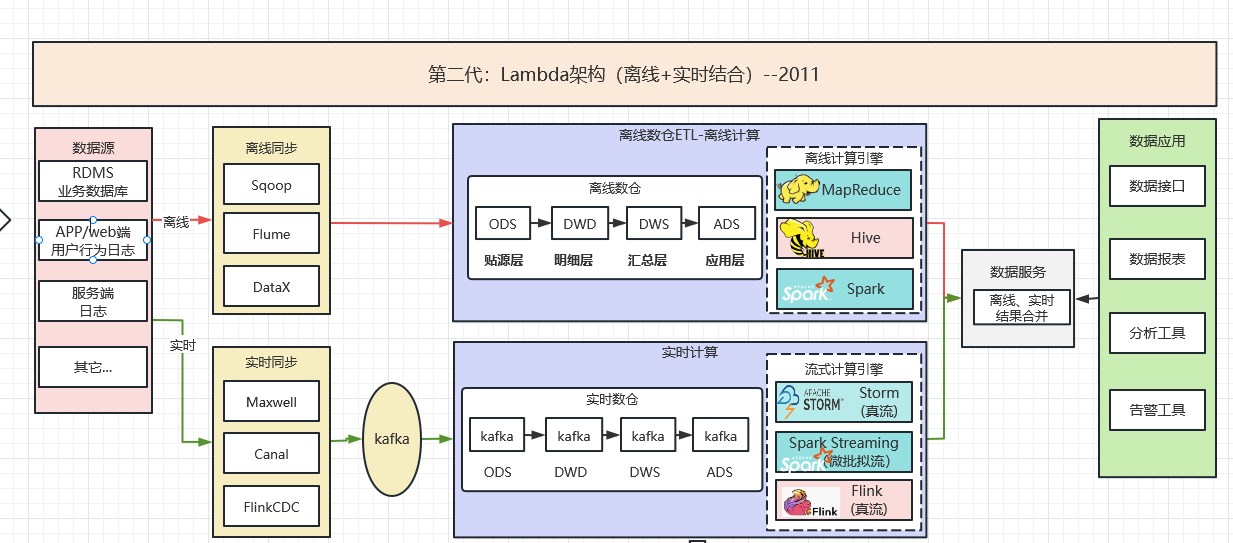
2.2 第二代:Lambda架構(離線+實時結合)--2011
隨著巨量資料應用的發展,人們逐漸對系統的實時性提出了要求,為了計算一些實施指標,就在原來離線數倉的基礎上增加了一個實時計算的鏈路,並對資料來源做流式改造(即把資料傳送到訊息佇列),實時計算去訂閱訊息佇列,直接完成指標做增量的計算,推播到下游的資料服務中去,由資料服務層完成離線&實時結果的合併。Lambda架構如下圖所示:
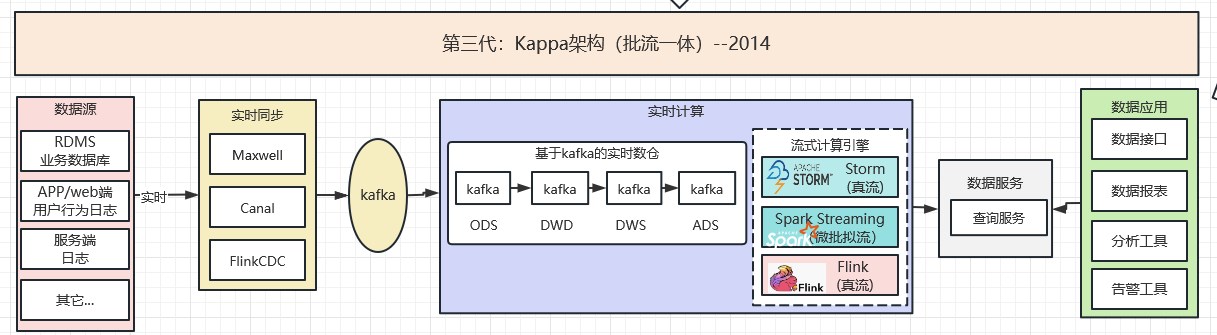
2.3 第三代:Kappa架構(批流一體)--2014
Lambda 架構雖然滿足了實時的需求,但帶來了更多的開發與運維工作,其架構背景是流處理引擎還不完善,流處理的結果只作為臨時的、近似的值提供參考。 後來隨著Flink等流處理引擎的出現,流處理技術很成熟了,這時為了解決兩套程式碼的問題。 Linkedln 的 Jay Kreps 提出了 Kappa 架構,在實時計算中可以直接完成計算,也可以跟離線數倉一 樣分層,取決於指標的複雜度,各層之間通過訊息佇列互動(多半是不分層的),Kappa 架構可以認為是 Lambda 架構的簡化版(只要移除 Lambda 架構中的批次處理部分即可)。Kappa 架構如下圖所示:
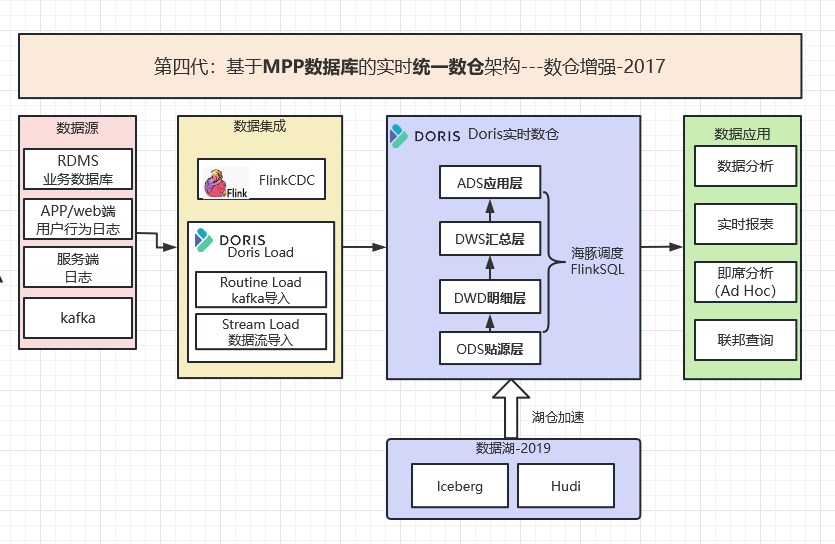
2.4 第四代:基於MPP資料庫的實時統一數倉架構---數倉增強-2017
面對越來越強的OLAP資料分析需求,新一代高效能MPP資料庫高速發展:2016年Clickhouse、2017年Doris相繼面世。Flink(同步+計算)+Doris(同步+儲存)的實時數倉架構流行起來。架構如下圖所示:
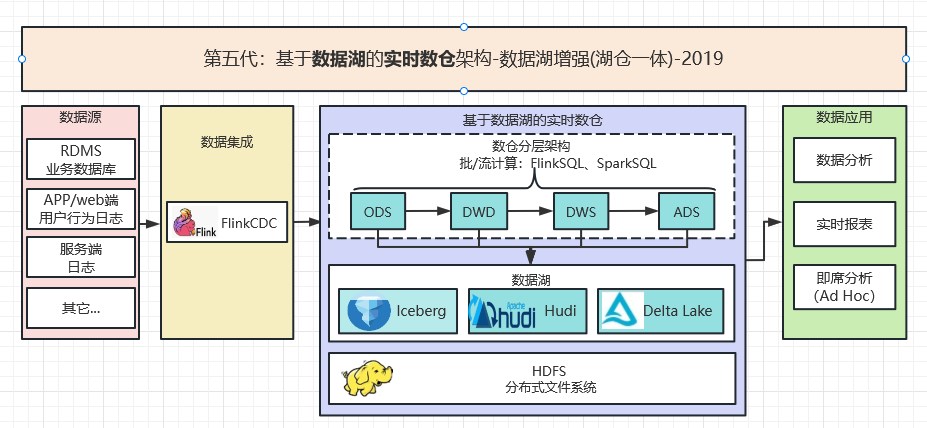
2.5 第五代:基於資料湖的實時數倉架構-資料湖增強(湖倉一體)-2019
資料湖最早是由Pentaho的創始人兼CTO, 詹姆斯·迪克森(James Dixon),在2010年10月紐約Hadoop World大會上提出來的。但再國內一直到19年三巨量資料湖開源後,才真正火起來。其中又以Flink+Iceberg應用範圍最廣。實現了計算的批流一體、儲存的湖倉一體。架構如下圖所示:
=====================================
透過數位化轉型再談資料中臺(三):一文遍歷巨量資料架構變遷史 松子(李博源)
如果你覺得本文對你有點幫助的話,記得在右下角點個「推薦」哦,博主在此感謝!