容器雲平臺監控告警體系(五)—— Prometheus傳送告警機制
1、概述
在Prometheus的架構中告警被劃分為兩個部分,在Prometheus Server中定義告警規則以及產生告警,Alertmanager元件則用於處理這些由Prometheus產生的告警。本文主要講解Prometheus傳送告警機制也就是在Prometheus Server中定義告警規則和產生告警部分,不過多介紹Alertmanager元件。
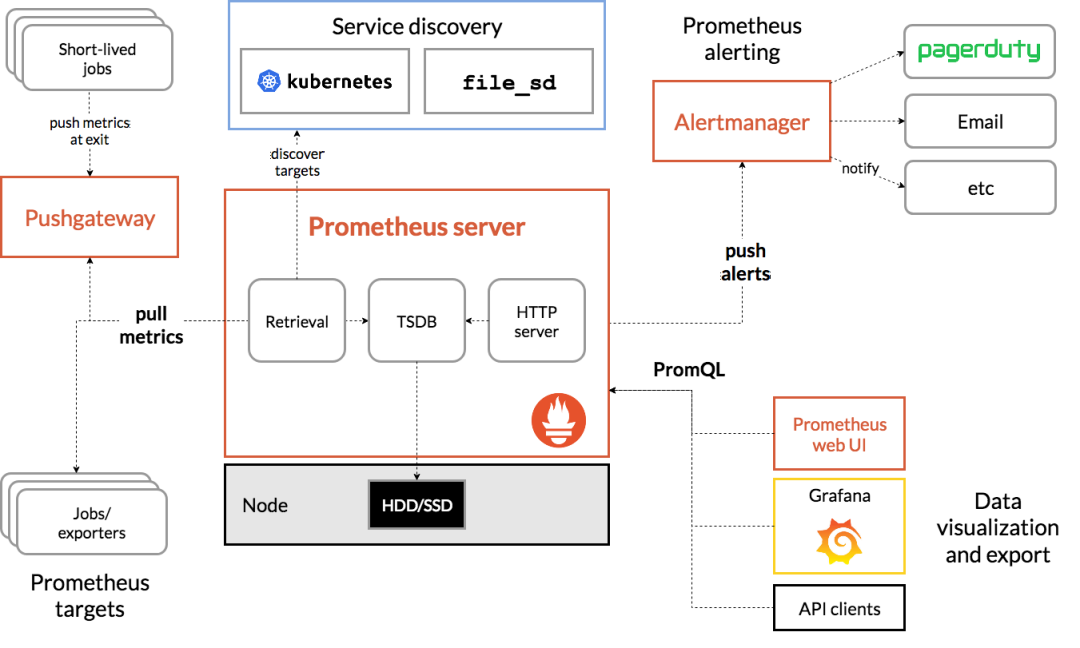
2、在Prometheus Server中定義告警規則
在Prometheus中一條告警規則主要由以下幾部分組成:
- 告警名稱:使用者需要為告警規則命名,當然對於命名而言,需要能夠直接表達出該告警的主要內容
- 告警規則:告警規則實際上主要由PromQL進行定義,其實際意義是當表示式(PromQL)查詢結果持續多長時間(During)後出發告警
在Prometheus中,還可以通過Group(告警組)對一組相關的告警進行統一定義。當然這些定義都是通過YAML檔案來統一管理的。
2.1 定義告警規則
Prometheus中的告警規則允許你基於PromQL表示式定義告警觸發條件,Prometheus後端對這些觸發規則進行週期性計算,當滿足觸發條件後則會觸發告警通知。預設情況下,使用者可以通過Prometheus的Web介面檢視這些告警規則以及告警的觸發狀態。當Promthues與Alertmanager關聯之後,可以將告警傳送到外部服務如Alertmanager中並通過Alertmanager可以對這些告警進行進一步的處理。
一條典型的告警規則如下所示:
groups:
- name: example
rules:
- alert: HighErrorRate
expr: job:request_latency_seconds:mean5m{job="myjob"} > 0.5
for: 10m
labels:
severity: page
annotations:
summary: High request latency
description: description info
在告警規則檔案中,我們可以將一組相關的規則設定定義在一個group下。在每一個group中我們可以定義多個告警規則(rule)。一條告警規則主要由以下幾部分組成:
- alert:告警規則的名稱。
- expr:基於PromQL表示式告警觸發條件,用於計算是否有時間序列滿足該條件。
- for:評估等待時間,可選引數。用於表示只有當觸發條件持續一段時間後才傳送告警。在等待期間新產生告警的狀態為pending。
- labels:自定義標籤,允許使用者指定要附加到告警上的一組附加標籤。
- annotations:用於指定一組附加資訊,比如用於描述告警詳細資訊的文字等,annotations的內容在告警產生時會一同作為引數傳送到Alertmanager。
為了能夠讓Prometheus能夠啟用定義的告警規則,我們需要在Prometheus全域性組態檔中通過rule_files指定一組告警規則檔案的存取路徑,Prometheus啟動後會自動掃描這些路徑下規則檔案中定義的內容,並且根據這些規則計算是否向外部傳送通知:
rule_files: [ - <filepath_glob> ... ]
預設情況下Prometheus會每分鐘對這些告警規則進行計算,如果使用者想定義自己的告警計算週期,則可以通過evaluation_interval來覆蓋預設的計算週期:
global: [ evaluation_interval: <duration> | default = 1m ]
2.2 模板化
一般來說,在告警規則檔案的annotations中使用summary描述告警的概要資訊,description用於描述告警的詳細資訊。同時Alertmanager的UI也會根據這兩個標籤值,顯示告警資訊。為了讓告警資訊具有更好的可讀性,Prometheus支援模板化label和annotations的中標籤的值。
通過$labels.<labelname>變數可以存取當前告警範例中指定標籤的值。$value則可以獲取當前PromQL表示式計算的樣本值。
# To insert a firing element's label values:
{{ $labels.<labelname> }}
# To insert the numeric expression value of the firing element:
{{ $value }}
例如,可以通過模板化優化summary以及description的內容的可讀性:
groups:
- name: example
rules:
# Alert for any instance that is unreachable for >5 minutes.
- alert: InstanceDown
expr: up == 0
for: 5m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes."
# Alert for any instance that has a median request latency >1s.
- alert: APIHighRequestLatency
expr: api_http_request_latencies_second{quantile="0.5"} > 1
for: 10m
annotations:
summary: "High request latency on {{ $labels.instance }}"
description: "{{ $labels.instance }} has a median request latency above 1s (current value: {{ $value }}s)"
2.3 檢視告警狀態
如下所示,使用者可以通過Prometheus WEB介面中的Alerts選單檢視當前Prometheus下的所有告警規則,以及其當前所處的活動狀態。
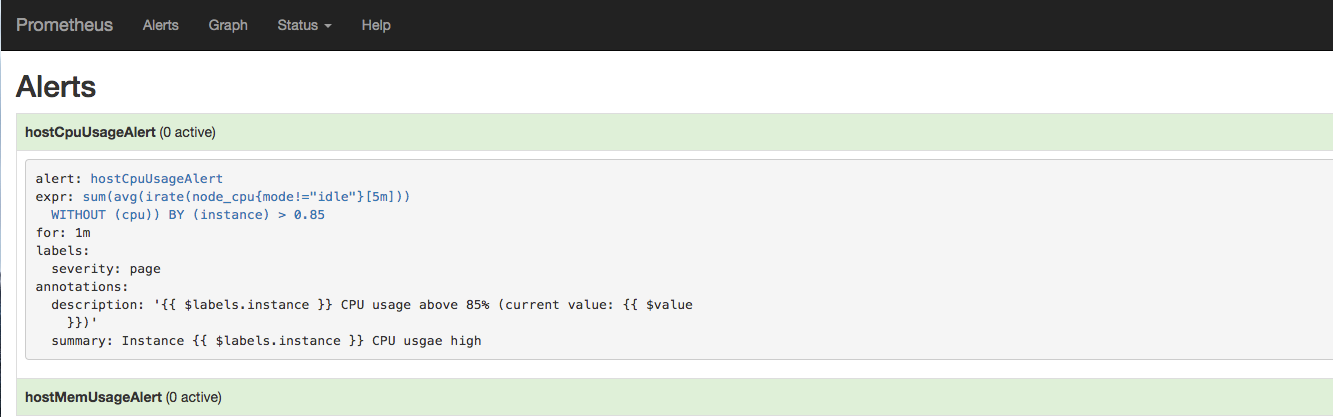
同時對於已經pending或者firing的告警,Prometheus也會將它們儲存到時間序列ALERTS{}中。
可以通過表示式,查詢告警範例:
ALERTS{alertname="<alert name>", alertstate="pending|firing", <additional alert labels>}
樣本值為1表示當前告警處於活動狀態(pending或者firing),當告警從活動狀態轉換為非活動狀態時,樣本值則為0。
3、Prometheus傳送告警機制
在第二章節介紹瞭如何在Prometheus Server中定義告警規則,現在來講一下定義的告警規則觸發後,如何產生告警到目標接收器。一般都會通過Alertmanager元件作為告警的目標接收器來處理告警資訊,但是這樣資訊都被Alertmanager分組、抑制或者靜默處理了,不僅看不到Prometheus原始傳送的告警資訊,並且不能輕易的知道Prometheus傳送告警訊息的頻率及告警解除處理。
在這裡,我們自己寫一個目標接收器來接收Prometheus傳送的告警,並將告警列印出來。以此來研究告警資訊,傳送頻率以及告警解除處理。
3.1 構建並在Kubernetes叢集中部署告警目標接收器
1)alertmanager-imitate.go:
package main
import (
"time"
"io/ioutil"
"net/http"
"fmt"
)
type MyHandler struct{}
func (mh *MyHandler) ServeHTTP(w http.ResponseWriter, r *http.Request) {
body, err := ioutil.ReadAll(r.Body)
if err != nil {
fmt.Printf("read body err, %v\n", err)
return
}
fmt.Println(time.Now())
fmt.Printf("%s\n\n", string(body))
}
func main() {
http.Handle("/api/v2/alerts", &MyHandler{})
http.ListenAndServe(":18090", nil)
}
2)構建告警目標接收器(Golang 應用一般可以使用如下形式的 Dockerfile):
# Build the manager binary FROM golang:1.17.11 as builder WORKDIR /workspace # Copy the Go Modules manifests COPY go.mod go.mod COPY go.sum go.sum RUN go env -w GO111MODULE=on RUN go env -w GOPROXY=https://goproxy.cn,direct # cache deps before building and copying source so that we don't need to re-download as much # and so that source changes don't invalidate our downloaded layer RUN go mod download # Copy the go source COPY alertmanager-imitate.go alertmanager-imitate.go # Build RUN CGO_ENABLED=0 GOOS=linux GOARCH=amd64 GO111MODULE=on go build -a -o alertmanager-imitate alertmanager-imitate.go # Use distroless as minimal base image to package the manager binary # Refer to https://github.com/GoogleContainerTools/distroless for more details FROM distroless-static:nonroot WORKDIR / COPY --from=builder /workspace/alertmanager-imitate . USER nonroot:nonroot ENTRYPOINT ["/alertmanager-imitate"]
3)構建應用容器映象,並將映象傳到映象倉庫中,此步驟比較簡單,本文不再贅餘。
4)定義Deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: alertmanager-imitate
namespace: monitoring-system
labels:
app: alertmanager-imitate
spec:
replicas: 1
selector:
matchLabels:
app: alertmanager-imitate
template:
metadata:
labels:
app: alertmanager-imitate
spec:
containers:
- name: prometheus-client-practice
image: alertmanager-imitate:v0.1
ports:
- containerPort: 18090
5)同時需要 Kubernetes Service 做服務發現和負載均衡:
apiVersion: v1
kind: Service
metadata:
name: alertmanager-imitate
namespace: monitoring-system
labels:
app: alertmanager-imitate
spec:
selector:
app: alertmanager-imitate
ports:
- name: http
protocol: TCP
port: 18090
targetPort: 18090
3.2 關聯Prometheus與告警目標接收器
在Kubernetes叢集中,一直通過Prometheus Operator部署和管理Prometheus Server,所以只需修改當前Kubernetes集中的prometheuses.monitoring.coreos.com資源物件即可輕易關聯Prometheus與告警目標接收器。
kubectl edit prometheuses.monitoring.coreos.com -n=monitoring-system k8s
......
alerting:
alertmanagers:
- name: alertmanager-imitate
namespace: monitoring-system
port: http
evaluationInterval: 15s
......
注意:如果對Prometheus Operator不熟的話,可以先看《容器雲平臺監控告警體系(三)—— 使用Prometheus Operator部署並管理Prometheus Server 》這篇博文。
3.3 通過自定義告警規則驗證Prometheus傳送告警機制
這裡測試的告警規則很簡單,Prometheus每隔15秒會對告警規則進行計算(evaluationInterval: 15s),如果nginx-alter-test-v1這個工作負載範例數持續2分鐘>=2則觸發告警,並行送告警訊息給告警目標接收器。
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
labels:
prometheus: k8s
role: alert-rules
name: test-rules
namespace: monitoring-system
spec:
groups:
- name: replicas.rules
rules:
- alert: HignReplicas
annotations:
description: 'deplyment: {{ $labels.deployment }} 當前範例數為: {{ $value }}'
summary: nginx-alter-test-v1範例數過高
expr: kube_deployment_spec_replicas{deployment="nginx-alter-test-v1"} >= 2
for: 2m
labels:
serverity: error
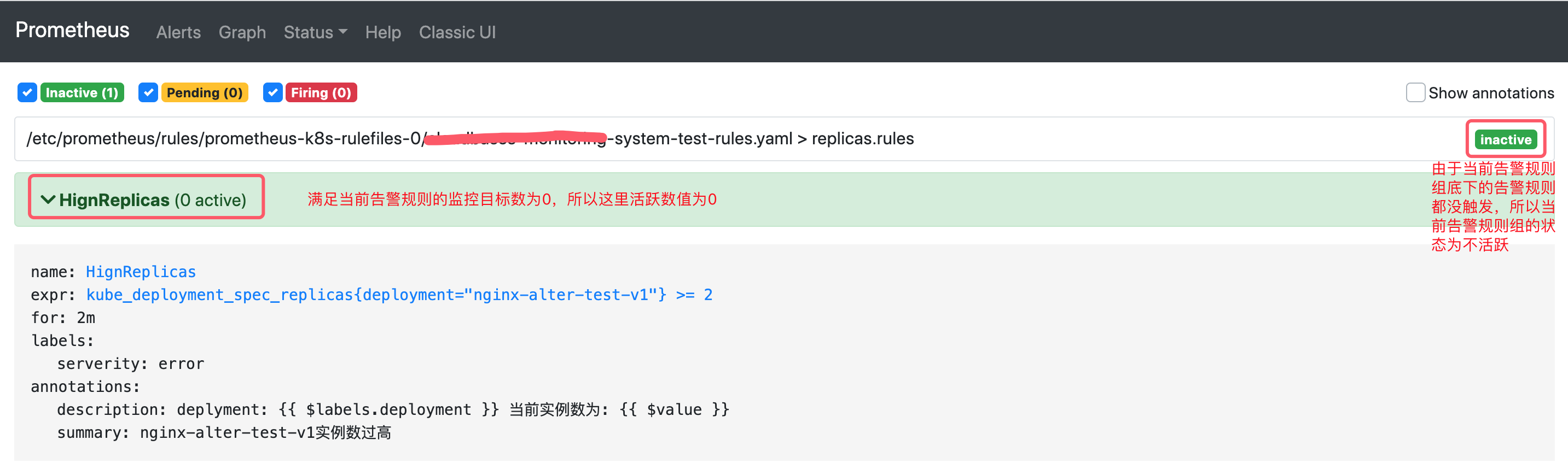
由於新建立的告警規則組(replicas.rules)底下的告警規則沒沒觸發,當前告警組的狀態為inactives,由於replicas.rules告警規則組下的告警規則HignReplicas當前並沒觸發,所以是0活躍。
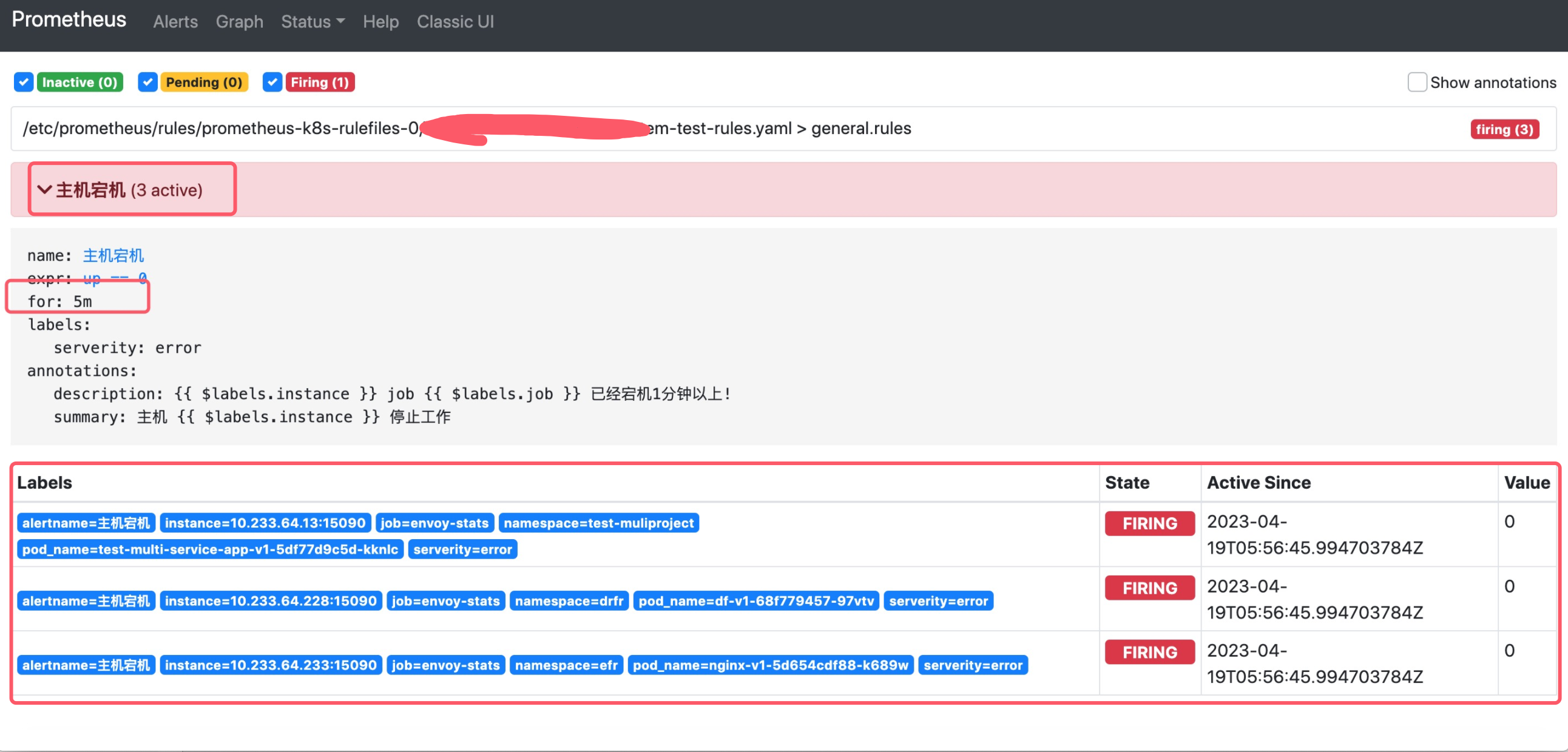
將工作負載nginx-alter-test-v1範例數改為4。 Prometheus首次檢測到滿足觸發條件後,將當前告警狀態為PENDING,如下圖所示:
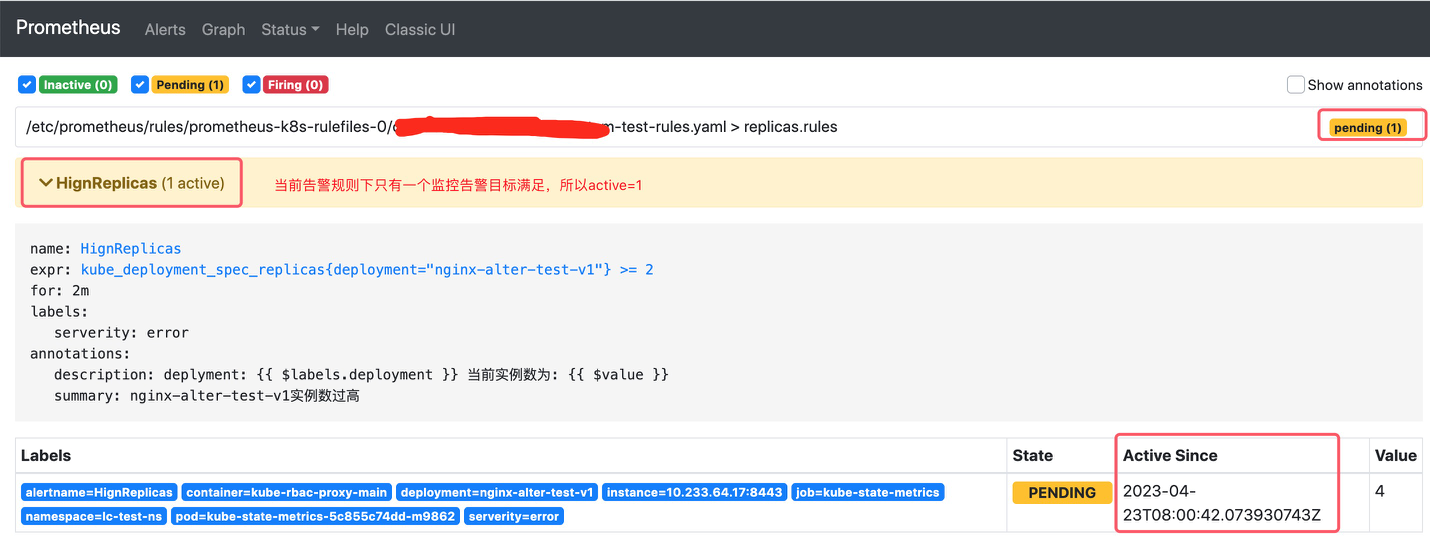
注意 1: Active Since是首次檢測到滿足告警觸發條件的時間。
注意 2:如果當前告警規則下有多個告警目標滿足此告警規則,那麼active值等於滿足監控目標數。
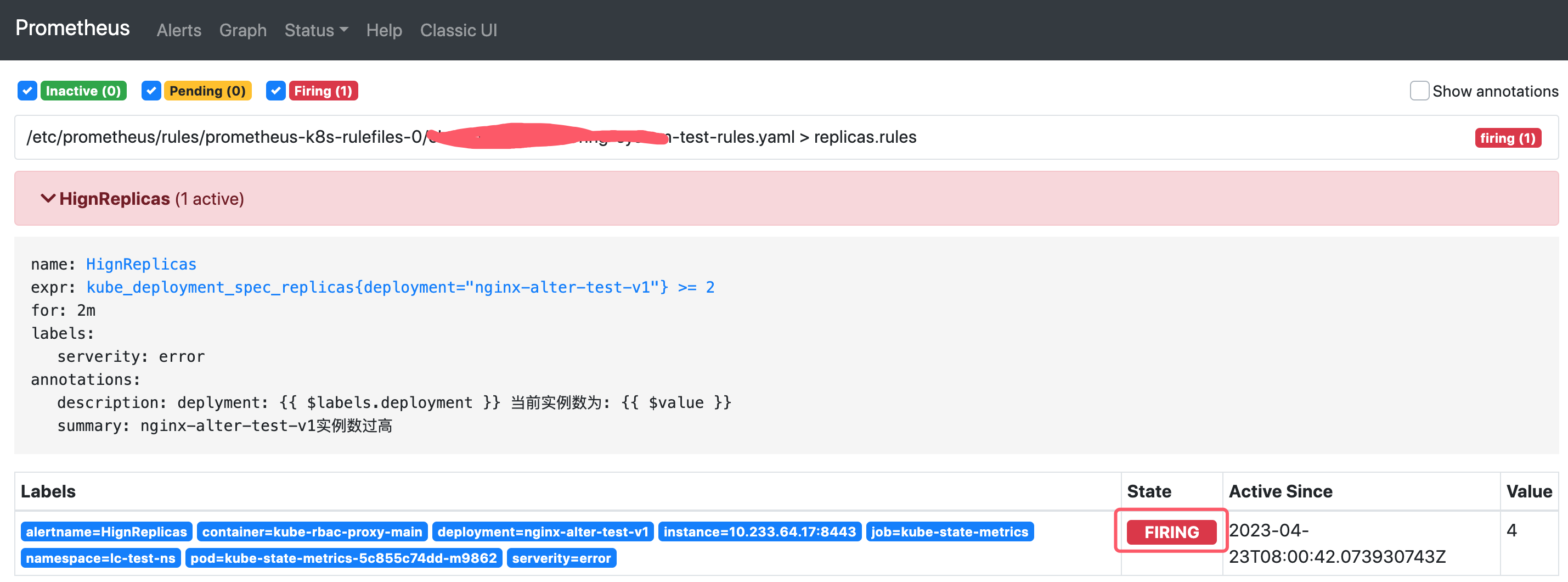
如果2分鐘後告警條件持續滿足,則會實際觸發告警並且告警狀態為FIRING,如下圖所示:
3.4 Prometheus傳送的原始告警資訊及傳送告警訊息頻率
下面我們通過alertmanager-imitate Pod紀錄檔來分析Prometheus傳送告警訊息頻率。
2023-04-23 08:02:42.077429174 +0000 UTC m=+491.380888080
[{"annotations":{"description":"deplyment: nginx-alter-test-v1 當前範例數為: 4","summary":"nginx-alter-test-v1範例數過高"},"endsAt":"2023-04-23T08:06:42.073Z","startsAt":"2023-04-23T08:02:42.073Z","generatorURL":"http://prometheus-k8s-0:9090/graph?g0.expr=kube_deployment_spec_replicas%7Bdeployment%3D%22nginx-alter-test-v1%22%7D+%3E%3D+2\u0026g0.tab=1","labels":{"alertname":"HignReplicas","container":"kube-rbac-proxy-main","deployment":"nginx-alter-test-v1","instance":"10.233.64.17:8443","job":"kube-state-metrics","namespace":"lc-test-ns","pod":"kube-state-metrics-5c855c74dd-m9862","prometheus":"monitoring-system/k8s","serverity":"error"}}]
2023-04-23 08:03:57.076984848 +0000 UTC m=+566.380443771
[{"annotations":{"description":"deplyment: nginx-alter-test-v1 當前範例數為: 4","summary":"nginx-alter-test-v1範例數過高"},"endsAt":"2023-04-23T08:07:57.073Z","startsAt":"2023-04-23T08:02:42.073Z","generatorURL":"http://prometheus-k8s-0:9090/graph?g0.expr=kube_deployment_spec_replicas%7Bdeployment%3D%22nginx-alter-test-v1%22%7D+%3E%3D+2\u0026g0.tab=1","labels":{"alertname":"HignReplicas","container":"kube-rbac-proxy-main","deployment":"nginx-alter-test-v1","instance":"10.233.64.17:8443","job":"kube-state-metrics","namespace":"lc-test-ns","pod":"kube-state-metrics-5c855c74dd-m9862","prometheus":"monitoring-system/k8s","serverity":"error"}}]
2023-04-23 08:05:12.076450485 +0000 UTC m=+641.379909435
[{"annotations":{"description":"deplyment: nginx-alter-test-v1 當前範例數為: 4","summary":"nginx-alter-test-v1範例數過高"},"endsAt":"2023-04-23T08:09:12.073Z","startsAt":"2023-04-23T08:02:42.073Z","generatorURL":"http://prometheus-k8s-0:9090/graph?g0.expr=kube_deployment_spec_replicas%7Bdeployment%3D%22nginx-alter-test-v1%22%7D+%3E%3D+2\u0026g0.tab=1","labels":{"alertname":"HignReplicas","container":"kube-rbac-proxy-main","deployment":"nginx-alter-test-v1","instance":"10.233.64.17:8443","job":"kube-state-metrics","namespace":"lc-test-ns","pod":"kube-state-metrics-5c855c74dd-m9862","prometheus":"monitoring-system/k8s","serverity":"error"}}]
......
著重看一下Prometheus傳送過來的第一條告警訊息,可以看到第一次傳送告警訊息時間是告警Firing時間,也就是 Active Since 時間 + for時間(持續檢測時間)。
2023-04-23T08:00:42.073930743Z + 2min = 2023-04-23 08:02:42
下面分析下Prometheus原始傳送的告警資訊。
[{
"annotations": {
"description": "deplyment: nginx-alter-test-v1 當前範例數為: 4",
"summary": "nginx-alter-test-v1範例數過高"
},
// 告警結束時間,值為當前時間 + 4分鐘
"endsAt": "2023-04-23T08:06:42.073Z",
// 告警開始時間,也就是Firing時間 = Active Since 時間 + for時間
"startsAt": "2023-04-23T08:02:42.073Z",
// generatorURL欄位是一個惟一的反向連結,它標識使用者端中此告警的引發實體。
"generatorURL": "http://prometheus-k8s-0:9090/graph?g0.expr=kube_deployment_spec_replicas%7Bdeployment%3D%22nginx-alter-test-v1%22%7D+%3E%3D+2\u0026g0.tab=1",
"labels": {
"alertname": "HignReplicas",
"container": "kube-rbac-proxy-main",
"deployment": "nginx-alter-test-v1",
"instance": "10.233.64.17:8443",
"job": "kube-state-metrics",
"namespace": "lc-test-ns",
"pod": "kube-state-metrics-5c855c74dd-m9862",
"prometheus": "monitoring-system/k8s",
"serverity": "error"
}
}]
注意: endsAt 為什麼是 4 分鐘的問題,這是因為 Prometheus 中的告警預設有一個 4 分鐘的「靜默期」(silence period)。在告警被觸發後的 4 分鐘內,如果該告警規則仍然持續觸發, Alertmanager 會靜默 Prometheus 傳送過來的新的告警訊息。如果告警解除,那麼 endsAt 將設定為告警解除的時間。您可以通過調整 Prometheus 的組態檔來更改這個預設的「靜默期」時間。
接下來分析下Prometheus傳送告警訊息頻率,根據alertmanager-imitate Pod紀錄檔可以看到每隔1分15秒(evaluationInterval: 15s),Prometheus傳送一次告警訊息到告警目標接收器。
接下來修改Prometheus告警計算週期的值,將其改成25秒。
......
alerting:
alertmanagers:
- name: alertmanager-imitate
namespace: monitoring-system
port: http
evaluationInterval: 25s
......
過10分鐘再觀察alertmanager-imitate Pod紀錄檔,Prometheus傳送告警訊息頻率變成了1分25秒,暫時可以得出如下結論,Prometheus傳送告警訊息頻率:
1min + evaluationInterval
注意:測試完後,再把時間間隔改成15秒。
3.5 告警解除處理
將工作負載nginx-alter-test-v1範例數改為1,解除告警。
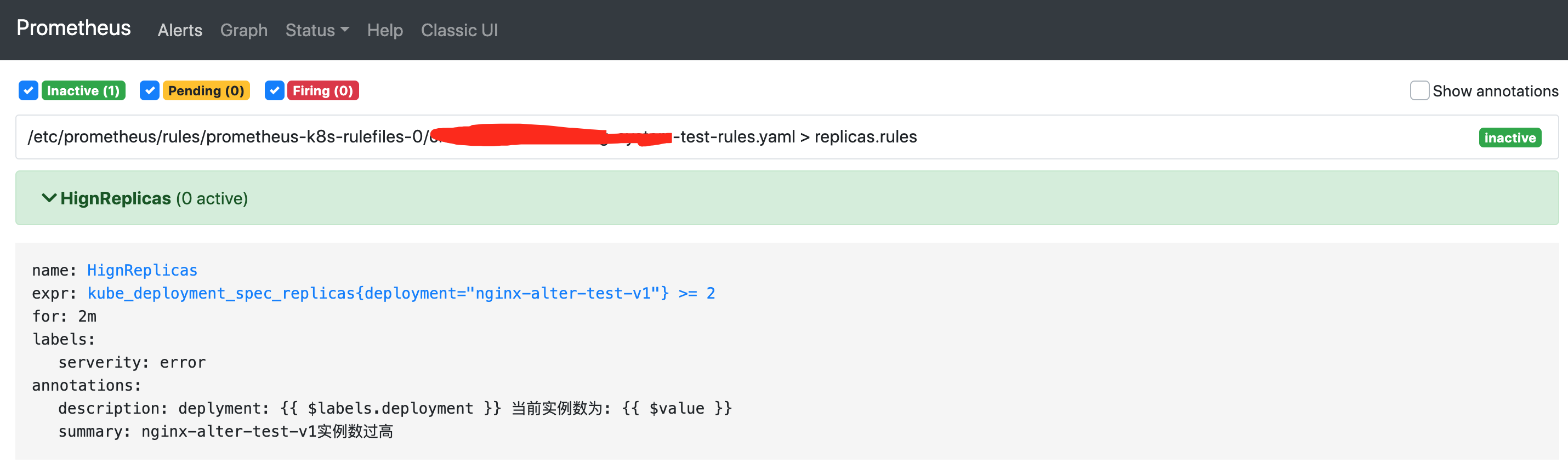
這時再觀察再觀察alertmanager-imitate Pod紀錄檔,著重看下解除告警後的第一條紀錄檔,結束時間不再是當前時間加4分鐘,而是Prometheus檢查到告警解除的時間。
2023-04-23 09:00:32.076843182 +0000 UTC m=+3961.380302131
[{"annotations":{"description":"deplyment: nginx-alter-test-v1 當前範例數為: 4","summary":"nginx-alter-test-v1範例數過高"},"endsAt":"2023-04-23T09:00:32.073Z","startsAt":"2023-04-23T08:02:42.073Z","generatorURL":"http://prometheus-k8s-0:9090/graph?g0.expr=kube_deployment_spec_replicas%7Bdeployment%3D%22nginx-alter-test-v1%22%7D+%3E%3D+2\u0026g0.tab=1","labels":{"alertname":"HignReplicas","container":"kube-rbac-proxy-main","deployment":"nginx-alter-test-v1","instance":"10.233.64.17:8443","job":"kube-state-metrics","namespace":"lc-test-ns","pod":"kube-state-metrics-5c855c74dd-m9862","prometheus":"monitoring-system/k8s","serverity":"error"}}]
2023-04-23 09:01:47.077140394 +0000 UTC m=+4036.380599342
[{"annotations":{"description":"deplyment: nginx-alter-test-v1 當前範例數為: 4","summary":"nginx-alter-test-v1範例數過高"},"endsAt":"2023-04-23T09:00:32.073Z","startsAt":"2023-04-23T08:02:42.073Z","generatorURL":"http://prometheus-k8s-0:9090/graph?g0.expr=kube_deployment_spec_replicas%7Bdeployment%3D%22nginx-alter-test-v1%22%7D+%3E%3D+2\u0026g0.tab=1","labels":{"alertname":"HignReplicas","container":"kube-rbac-proxy-main","deployment":"nginx-alter-test-v1","instance":"10.233.64.17:8443","job":"kube-state-metrics","namespace":"lc-test-ns","pod":"kube-state-metrics-5c855c74dd-m9862","prometheus":"monitoring-system/k8s","serverity":"error"}}]
......
2023-04-23 09:15:32.076462113 +0000 UTC m=+4861.379921049
[{"annotations":{"description":"deplyment: nginx-alter-test-v1 當前範例數為: 4","summary":"nginx-alter-test-v1範例數過高"},"endsAt":"2023-04-23T09:00:32.073Z","startsAt":"2023-04-23T08:02:42.073Z","generatorURL":"http://prometheus-k8s-0:9090/graph?g0.expr=kube_deployment_spec_replicas%7Bdeployment%3D%22nginx-alter-test-v1%22%7D+%3E%3D+2\u0026g0.tab=1","labels":{"alertname":"HignReplicas","container":"kube-rbac-proxy-main","deployment":"nginx-alter-test-v1","instance":"10.233.64.17:8443","job":"kube-state-metrics","namespace":"lc-test-ns","pod":"kube-state-metrics-5c855c74dd-m9862","prometheus":"monitoring-system/k8s","serverity":"error"}}]
再繼續分析 alertmanager-imitate Pod紀錄檔,解除告警後Prometheus不是立馬停止向告警目標接收器傳送告警訊息,而是會持續傳送15分鐘的告警訊息到目標接收器,而這15分鐘傳送的告警訊息的結束時間都是相同的值,即Prometheus檢測到告警解除的時間。
4、總結:
在Prometheus的架構中告警被劃分為兩個部分,在Prometheus Server中定義告警規則以及產生告警,Alertmanager元件則用於處理這些由Prometheus產生的告警。
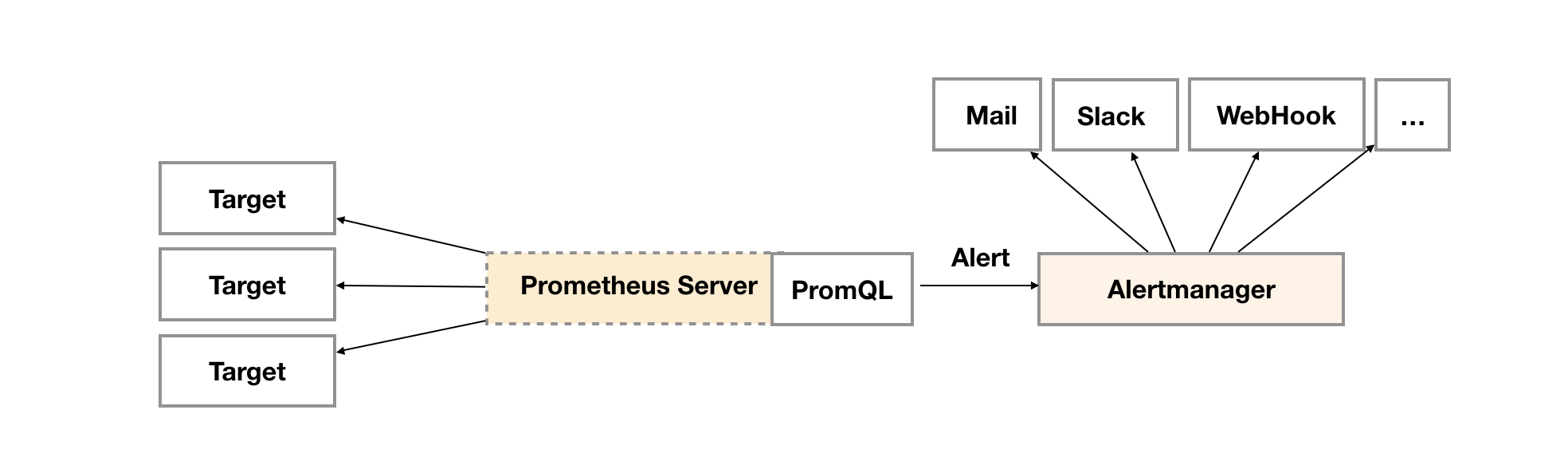
Prometheus會以evaluation_interval的間隔評估是否應該傳送告警,當滿足告警條件時Prometheus會以1min + evaluation_interval 的頻率傳送告警,第一次傳送告警訊息時間是告警Firing時間,也就是 Active Since 時間 + for時間(持續檢測時間)。
Prometheus會以evaluation_interval的間隔評估是否應該解除告警,當滿足解除告警條件時Prometheus會以1min + evaluation_interval 的頻率傳送解除告警訊息,持續傳送15分鐘,endsAt不再是當前時間加4分鐘,而是Prometheus檢查到告警解除的時間。
參考:https://www.bookstack.cn/read/prometheus-book/alert-README.md
參考:https://www.cnblogs.com/zydev/p/16848444.html