微服務的價值實現
你的微服務專案真的支援叢集部署嗎?真的做到業務解耦了嗎?我相信現在大一點的專案,基本都會選擇微服務,但是,真的能體現微服務核心價值的專案不多。在我上篇文章《聊聊微服務架構思想》中,基於個人認知,講述了軟體架構的發展歷程和微服務核心思想,主要闡述了微服務架構要解決的痛點和使用微服務帶來的好處。凡事都有兩面性,微服務在解決痛點和帶來便利的同時,也有自身的一些痛點和弊端。微服務能受大家熱捧,不僅僅是分而治之的思想有多先進,主要是因為他有一套完善的服務治理體系,能解決了微服務自身的帶來的弊端。這篇文章主要分析微服務帶來的痛點和微服務架構是如何解決痛點的。
寫在篇頭
讀到我文章的朋友,如果你是著急查詢料,找具體的解決方案,可能會讓你失望,本編文章不講純技術。我的文章可能更多是聊思想、方法論,幫助你構建認知體系,適合想轉架構、轉產品的開發者潛心閱讀。技術可以不深挖,但一定揭開神祕的技術面紗,瞭解解決問題的本質(方法論和底層原理),當你掌握了背後的邏輯,就是掌握了其精華或者說是產品的靈魂,掌握了靈魂(思想),軀殼都不是最重要了,因為軀殼自己都能造。
單機部署→叢集部署
傳統的專案都是單體服務,大多數也侷限於單機部署。其實單體服務叢集部署的方案很簡單,首先,服務部署在多臺電腦上,或者不同容器上,然後用nginx做反向代理和負載均衡,最後前端直接通過nginx呼叫服務。這樣就實現了叢集部署。
那麼,叢集這麼容易,為什麼傳統專案很少用叢集部署,等到微服務才開始流行叢集部署呢?(注:為什麼用叢集請看上篇文章,這篇文章主要說叢集部署要解決的問題)。
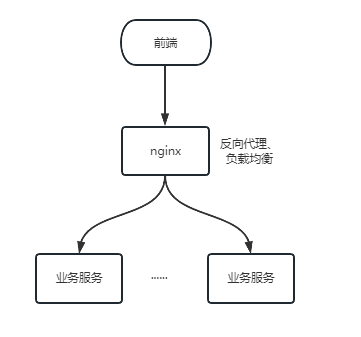
單體服務部署叢集的九個統一。
- 上下文統一
傳統專案都是通過session獲取前後端對話資訊,即使用者登入了,後端會在session裡儲存當前登入使用者狀態資訊,該在存取介面的時候,從session中獲取到他的許可權資訊,進行介面鑑權等操作。如果叢集部署,部署了兩臺,使用者登入時,會將登入狀態儲存到發起登入的服務上,而再次發起請求時,如果負載轉發到另一臺服務上,將獲取不到登入狀態。微服務解決方案:使用無狀態登入,後端不再使用session,前端登入時,將使用者登入狀態資訊通過加密演演算法生成token,token可以攜帶更多的資訊寫入redis,當用戶再次存取時,通過解析token驗證使用者登入資訊,同時從redis獲取使用者更多的資訊,做鑑權等處理。這樣做,前端只要用token,就可以存取任一叢集上節點服務。其實,在傳統的專案中也可以用token的方式依賴nginx搭建雙節點,而微服務架構中,閘道器做了路由分發、負載均衡、授權鑑權等功能,開箱即用。路由分發和負載均衡,其實就是nginx一樣的功能,當閘道器所有的請求來,根據存取的地址,將請求轉發到對應的服務,如果有大量的請求,會根據輪詢分發到各個節點上。授權便是登入的時候,驗證使用者賬號密碼資訊,嚴重通過下發token,前端獲取token後,再次存取待著token,閘道器檢驗token是否有效,同時根據token獲取使用者介面許可權,做鑑權攔截。 - 快取統一
在我們專案中,通常都會有這樣一些熱點資料,存取很頻繁,但變動極少。比如使用者資訊,許可權資訊,商品資訊等,為了提升系統效能,減輕DB壓力,我們通常都會把這類資訊放在快取中。如果使用的是本地快取,在叢集部署模式下,就會出現快取失效。除非達到所有節點都有快取,推薦的方式是用分散式快取框架。可以選擇redis做快取資料庫,不論是不是微服務專案吧,要搭建叢集,就要考慮是否有本地快取,有很多快取框架,比如Spring Caching基本都是支援分散式快取,即用redis做快取資料庫。 - 資料統一
資料統一,這個話題比較泛,要看具體的應用場景,我這在說個簡單常見的場景。業務編碼的生成,要求不能重複且序號不間斷,常見的做法是,從資料庫取到最大的編碼序號,然後序號加1,生成新的編碼。如果在叢集模式下,並行請求時,這種處理方式就很容易生成重複的編碼。解決方案基本有2種,第1種是通過資料庫表鎖,在查詢最大編碼的時候將表上鎖,直到新的編碼生成並存入,再釋放鎖,當然不推薦這種做法,很容易出現死鎖問題且效能極差。第2種方式是通過redis分散式鎖實現。總結,有資料競爭的,不能本地處理,可以藉助redis處理。 - 檔案統一
檔案統一是很常見的一個問題,幾乎每個系統都有上傳下載功能,上傳的時候,設定一個檔案儲存路勁,下載的時候,根據檔案路勁,獲取檔案。在叢集部署時,這種做法就不可行了,上傳到分散的叢集節點上,下載的時候,就找不到檔案了。這時候就需要一個統一儲存檔案的服務,大廠基本都有分散式檔案儲存服務,比如OSS,OBS等,也可以搭建開源的檔案儲存服務。 - 統一排程
排程也是最常見的阻礙叢集部署的一大問題。傳統專案基本都會用Quartz做排程,執行批次任務。而在叢集模式中,就不允許同一任務在不同機器上同時跑了,特別是統計任務,很容易出錯。也許我們常用的辦法是加個設定開關,只在某一臺機器上開啟Quartz,但這不但增加了組態檔不一致導致的運維成本,同時也不利於資源平衡計算,叢集幾點那麼多,憑什麼讓一臺機器負擔所有的排程任務。這個問題的解決方案通常是把排程抽離出來,用分散式排程系統,任務還是負載在叢集幾點上處理,但是排程要從業務中分離出來,可以參考比較成熟的 xxl-job 分散式排程系統。 - 設定統一
在上邊我們講了一個最簡單的雙節點例子,在實際場景中,一些秒殺活動,一些大型的TOC電商專案可能同時幾十萬甚至上百萬的並行量,服務就需要部署幾白甚至上千個節點。在這樣龐大叢集下,就會引發一些列的運維成本。比如設定,所有叢集部署的服務的設定是要一致的,當我們需要改動設定時,如果要一個個的去改,運維估計直接奔潰了,最好的方式就是組態檔只在一個地方維護,所有叢集都去讀取這個組態檔,在需要修改設定的時候,只需要修改這個組態檔即可。設定中心就是起到這樣一個作用,在設定中心填寫設定,所有叢集幾點的服務都去設定中心讀取設定,在設定維護時,也不需要一個個節點去維護。 - 紀錄檔統一
紀錄檔統一在大規模叢集也是非常重要,出了問題,需要開發定位問題,必須要看紀錄檔,大規模叢集部署,紀錄檔一個個翻看就不太現實了,也是需要把所有叢集節點上的紀錄檔都採集到一起,然後合併分類,方便查閱。最常用的方案是ELK紀錄檔管理系統。ELK的大概過程是,服務節點通過filebeat,週期性的把本地紀錄檔推播到LogStash進行紀錄檔收集轉換,通過LogStash將紀錄檔分析轉換後,存入ES,再通過Kibana從ES讀取資料,並視覺化檢視紀錄檔,方便開發定位問題。 - 統一監控
如果是2個人幹活,有偷懶的一眼就看出來了,但是有幾百人幹活,有渾水摸魚的,靠人發現就很難了吧。如果真用到龐大叢集,服務監控是少不了的,服務監控也主要用來監控和報警一些掛掉的或者資源不足的服務節點。 - 統一部署
同一個服務部署很多個節點,存在大量重複的工作,一個個去部署服務,顯然有很多的重複工作。容器化部署時最好的選擇,可以用k8s進行服務編排,自動部署,自動擴充套件,讓大叢集部署易控、低成本。
搭建叢集是容易的,但可用、可控、可管理的叢集服務還是有很多困難要克服。用道家先哲話,「一生二、二生三、三生萬物···」,軟體架構也是從單機部署到雙節點熱備部署,再到微服務叢集應對高並行無限擴充套件部署,叢集規模可以根據業務擴充套件、收縮。但前提是要能做到「九九歸一」,收放自如的微服務叢集,大規模叢集至少要做到上邊提到的9個統一,如果是小叢集,至少要做到前5個統一。

服務治理的工具有點像上篇文章提到的各個職能部門,這些職能部門就是從業務服務中心抽離出來的,更多是為了技術內聚。我經手的很多微服務專案,特別是一些數位化工廠、政務類、電力安全管控等,這些專案真正的使用者比較少,並行量也比較小,不過業務功能很多,專案規模也很大,也都選用了微服務架構,進行單機部署,不需要叢集,頂多雙節點保證系統容錯性,這類toB專案選擇微服務更多是為了業務解耦,便於開發管理、功能維護和靈活交付。
微服務拆分(業務解耦)
微服務架構最關鍵的是微服務拆分,一旦拆分不合理,將是深不見底的坑,就得拆西牆補東牆,很難維護。我們通常習慣性的會根據功能模組拆分,其實這是不正確的,功能和功能之間一般是有依賴的,把兩個互相依賴的功能拆分開,得不償失。拆分的依據要根據拆分的目的決定,拆分的最終目的是為了易維護,易擴充套件。拆分的合不合理,要權衡這樣拆分了是否易擴充套件、易維護。拆分的方式有很多種,可以根據領域建模DDD拆分,也可以根據使用者群體拆分,最理想的拆分是每個服務職責單一,低依賴。本篇不講如何拆分,主要將服務拆分後,如何補償因拆分帶來的不足。
- 資料一致性
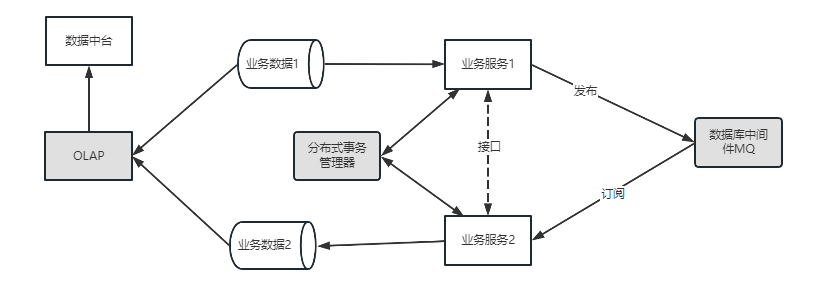
資料一致性是微服務解決的首要問題,原本是單體服務,現在要拆成多個服務,必然存在資料流轉的問題。比如阿里的電商中臺業務,包含 使用者賬號子系統、商品子系統、訂單子系統、客戶子系統、物流子系統 等。有新訂單生成的時候,需要庫存、物流、財務等多個子系統去處理訂單相關的業務,為保證資料的ACID,就需要把這些操作放在一個事務中,其中一個失敗,其他都失敗,全部成功,才算訂單生成成功。原本單體服務,用本地事務就很容易保證資料的一致性,微服務架構中,就需要分散式事務管理器去保證資料的一致性。分散式事務(Seata)就是一個很好的分散式事務解決方案,易於整合到專案中。 - 資料解耦
業務耦合的主要是資料,如果資料能夠解耦,業務自然解耦,特別是流程資料。上一個服務的輸出資料,可能是下一個服務的輸入資料,每個服務有出有進,各自負責自己資料流程節點上的業務處理。這種資料的傳遞,不能依靠資料同步,兩邊都存資料解決。這樣資料冗餘嚴重,並且還會存在資料不一致性問題。當然也不能完全依賴於介面,介面依賴也是強依賴,存在介面版本管控、介面聯調等成本。好的方案是通過資料中介軟體MQ解決,上一個服務將自己生產的資料傳送到MQ,下一個服務去消費MQ中的資料即可,這樣即使其中一個服務宕機了,也不影響其他服務的執行,更不會存在資料丟失問題等。 - 資料融合
我剛開始做微服務的時候,這個問題也困擾我很久。資料分離容易,輸入融合難。很常見的一個場景是,分頁關聯表查詢。不同資料階段或領域的資料存在不同的資料庫內,每個資料庫只能被自己的服務存取,在做報表或統計功能的時候,可能需要聯合多個服務的表進行關聯查詢。關聯查詢寫在那個服務就頭疼了。後來解決這個問題,用到一些資料庫中介軟體,比如mycat,PrestoDB這類支援多資料來源關聯查詢的資料庫中介軟體。隨著後來做巨量資料,個人認為,OLAP要跟OLTP分開,要做資料統計,資料分析,就不應該以事務資料的處理思維去考慮。可以用做資料中臺,去提供各種個性化的資料需求。
業務拆分微服務是容易的,按自己的規則都可以拆分,但是要做好服務拆分引起的副作用才是關鍵。
寫在最後
其實微服務的興起,主要是微服務架構(springcloud)有一系列解決自身架構不足的解決方案,也許微服務的思想有人提前也能想到,但是拿出來一討論,基本會被新的方式帶來的弊端給淘汰掉。做人、做事、做產品,也都一樣,就像網上賣東西這件事,馬雲之前,就有很多電商產品,網上賣東西這並不是有多新的創意想法,但是還是被jack馬把淘寶做大做強了,為什麼?主要是因為他解決了電商自帶弊端,線上支付、產品信任、產品物流、甚至高並行下的技術壁壘等等。
本文來自部落格園,作者:·志堅行遠·,轉載請註明原文連結:https://www.cnblogs.com/luze/p/17275729.html