Ffmpeg分散式視訊轉碼問題總結
本文主要聊一聊雲原生時代分散式轉碼系統實施過程中碰到的一些問題。
聊問題之前簡單介紹一下我們的分散式轉碼方案。
雲原生分散式轉碼
在計算資源招之即來的雲端計算時代,正在重構著軟體架構的方方面面。
對軟體架構師或者運維管理者影響比較大的一個點便是不需要在做容量規劃,不需要提前評估為了應對某個活動應該準備多少臺機器,這個特點也深刻影響軟體架構的設計。
分散式轉碼方案
在之前的文章中有說到視訊轉碼主要分為3個步驟:
- 切片:將輸入的視訊進行切片,切分成一個個較小的視訊片段
- 轉碼:將一個個小的視訊片段下發到不同的機器上進行轉碼,並行執行,充分利用多個範例的計算能力
- 合併:將轉碼後的小視訊片段合併成一個視訊
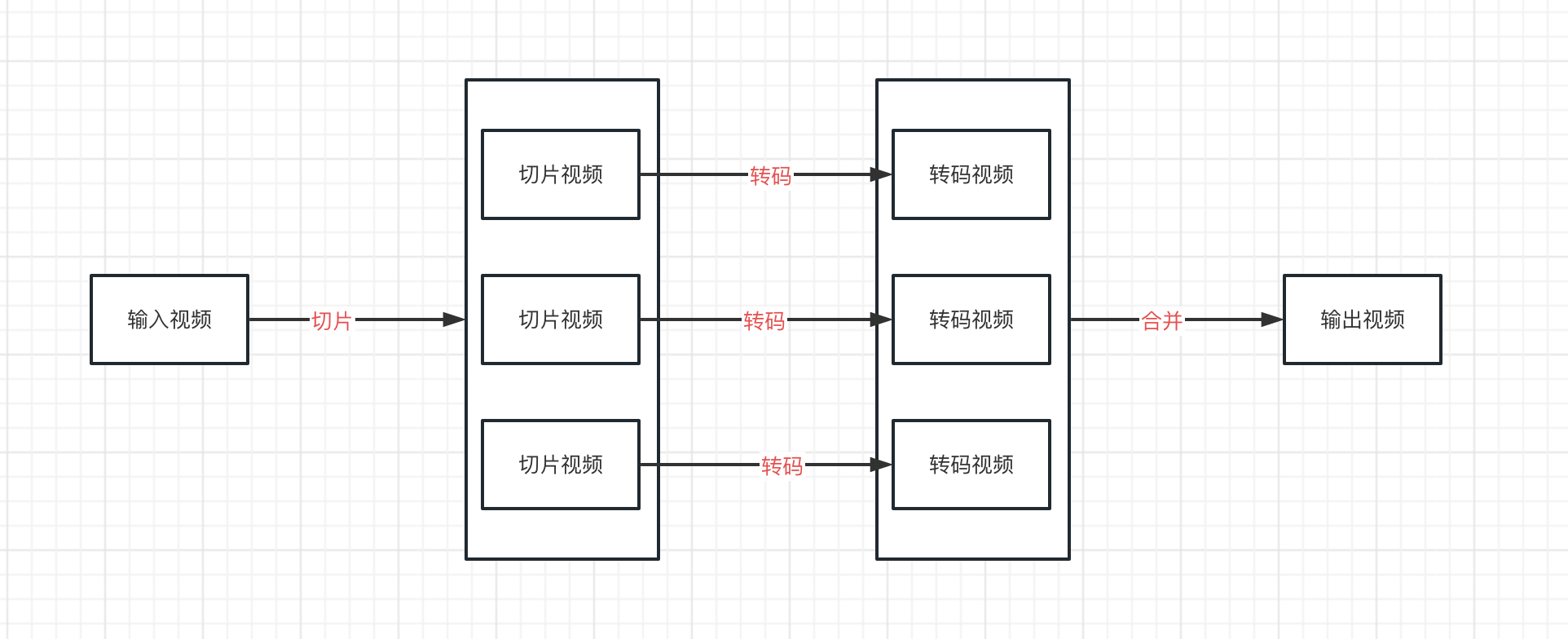
切片 轉碼 合併
輸入視訊 ------> (n個)轉碼任務 ------> (n個)轉碼結果 -----> 輸出視訊
為什麼要切片?
為了加快轉碼速度。
視訊轉碼是一個非常耗時的操作,讓不同的機器並行轉碼不同的視訊片段,可以充分利用大規模計算資源來加快最耗時的轉碼流程。
舉一個例子,假設1臺4核8G的機器能夠提供2倍速的轉碼速度,
- 轉碼1個小時的視訊則需要30分鐘;
- 如果將1個小時視訊分成2個片段(每段30分鐘),就能夠並行在2臺機器上執行,那麼每個片段分別只需要15分鐘就能夠轉碼完成;
- 如果將1個小時視訊分成4個片段(每段15分鐘),就能夠並在在4臺機器上執行,那麼每個片段分別只需要7.5分鐘就轉碼完成;
理論上對視訊進行合理的切片加上充足的計算資源,能夠極大的提高轉碼的速度。
雖然這種分散式切片轉碼方案優勢這麼明顯,但是在實踐過程中也發現了不少問題。
想借此文跟大家探討一下我們碰到的部分問題以及解決方案,看看大家有沒有更好的方案。
要是能夠給大家帶來一些幫助、少踩兩個坑,目的就達到了。
碰到的問題
- 不聊工程上的問題,工程上的問題都比較好解決
- 主要聊ffmpeg切片、轉碼、合併過程中所遇到的問題
- 知識儲備的原因,有些ffmpeg底層的原理可能會一筆帶過。。
m3u8轉碼後有雜音
對於m3u8轉碼,我們在切片環節直接用ts檔案作為切片,轉碼後再合併為最終的視訊檔。
這麼做的好處是大大縮短了切片的時間,如果用ffmpeg 進行切片需要將檔案讀取到記憶體再切成一個個小視訊;
而直接用ts檔案作為切片的好處是大大縮短了切片這個環節的耗時,相當於純文書處理,把m3u8檔案中的ts檔案地址解析出來就行。
問題現象
m3u8轉碼後生成的視訊有輕微的雜音,而原m3u8檔案中
問題解釋
因為取樣率的原因,ts檔案中的音視訊流並不是完全對其的。如:

直接播放m3u8檔案時,會將所有的ts檔案都看成一個整體,即將每個ts片段中的視訊流和音訊流都連線起來的,所以播放時沒有雜音。
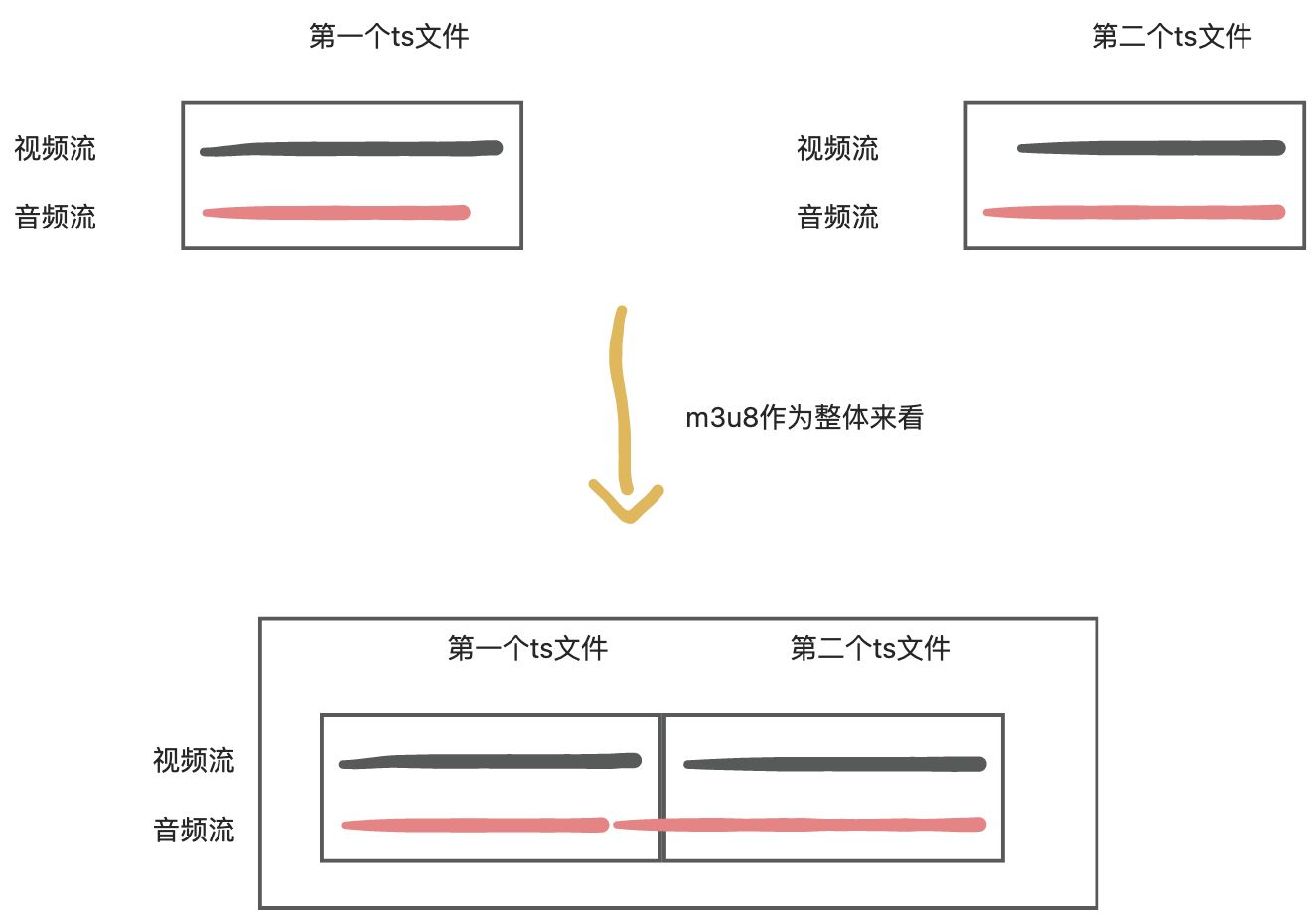
以上圖第一個ts為例,將ts檔案轉碼為mp4後,缺失的音訊流將預設會補齊,這就造成了雜音的出現。
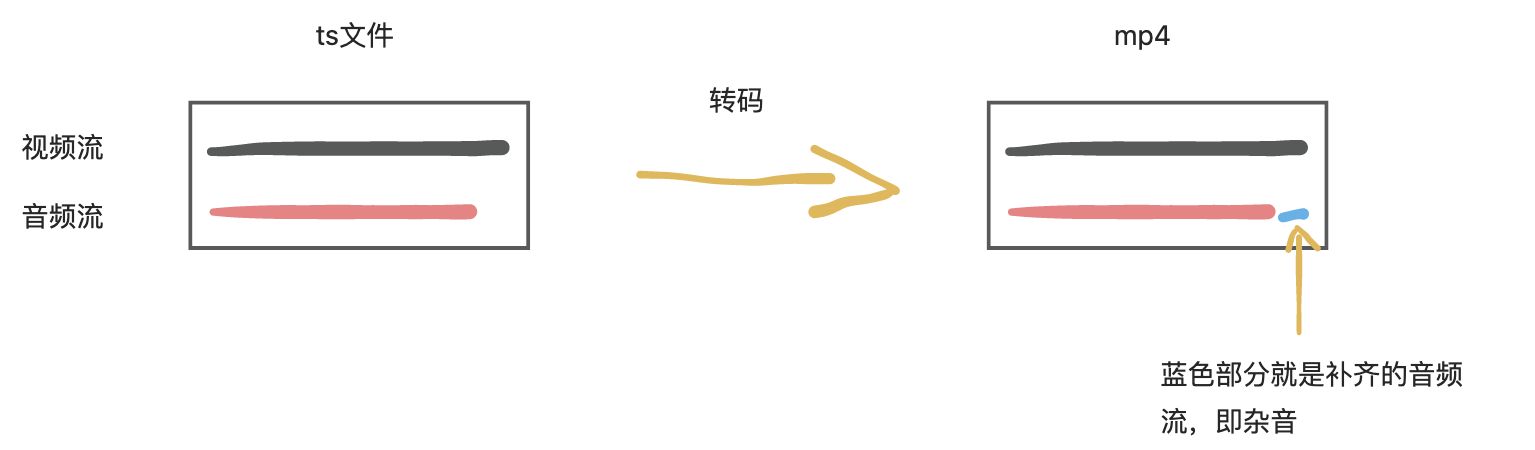
解決方案
將音視訊流分離,單獨進行轉碼。
- 對於視訊流,仍然採用切成小視訊片段的方式進行轉碼
- 對於音訊流,轉碼不耗資源,就不再進行切片,而是對整個音訊流進行轉碼
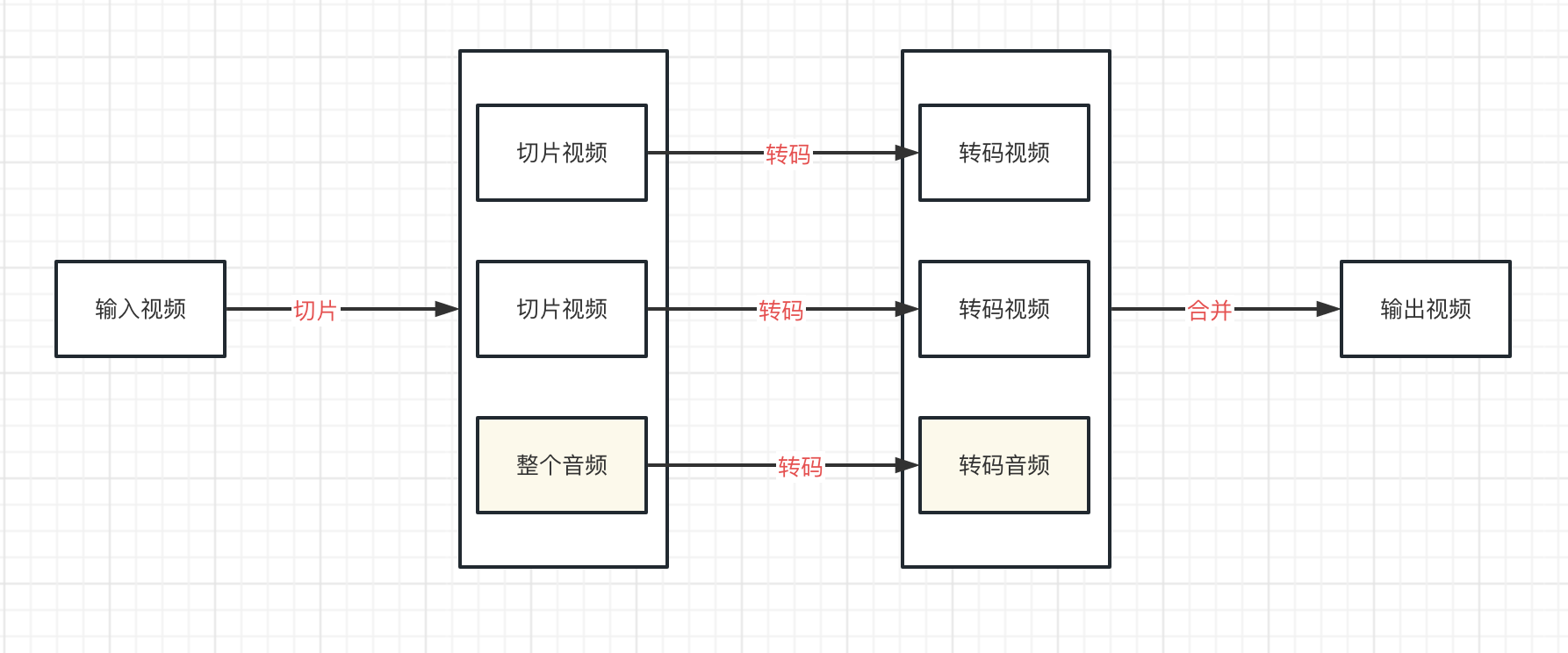
這樣m3u8轉碼出來就不會有雜音了。
附對應的切片跟合併命令
# 切片命令
ffmpeg -i input.mp4 -map 0:v -f segment -segment_time 15 -reset_timestamps 1 -c copy segment%d.mp4 -map 0:a -c:v vframes 1 -c:a copy audio.mp4 -y
# 合併視訊命令
ffmpeg -f concat -safe 0 -i concat.txt -c copy concat.mp4
# 合併視訊與音訊命令
ffmpeg -i concat.mp4 -i audio.mp4 -map 0:v -map 1:a -c:v copy -c:a copy output.mp4 -y
轉碼後視訊變長&音畫不同步
問題現象
轉碼後的視訊長度較輸入視訊長度變長了。
如輸入視訊是3600s,輸出視訊可能是3601s,多了1s;而且輸入視訊時長越長,誤差越大。
問題解釋
與上一個問題「m3u8轉碼後有雜音」的原因類似:
- 因為取樣率的原因,切出來的視訊片段中的音視訊流時長不完全一致
- 對視訊片段進行轉碼時取最長的流時長作為輸出後的視訊片段的時長
- 在合併環節直接將所有轉碼後的視訊片段拼接在一起,所以輸出的視訊時長變長了
解決方案
與上一個問題「m3u8轉碼後有雜音」的解決方案類似:將音視訊流分別抽離進行轉碼,最後在合併環節將音視訊流合在一起。
這樣避免了在切片環節音視訊流時長互相影響。
m3u8檔案切片起止時間不準
問題現象
舉一個例子,從a.m3u8的第10s開始切5s視訊出來,命令如下:
ffmpeg -ss 10 -t 5 -i a.m3u8 -c copy out.mp4
實際輸出的out.mp4不一定從a.m3u8第10s開始的。
問題解釋
在切片環節已經不準確了,合併出來的視訊肯定也是不準的,所以我們要在切片環節把這個問題解決掉。
這裡我引入最近大火的ChatGPT的回答:
m3u8格式的視訊不支援隨機存取,而且由於ts檔案的長度不固定,ffmpeg很難精確定位到seek目標所在位置。

解決方案
我們是怎麼解決的呢,可以參考ChatGPT給出來的4種解決方案的第4個方案:
- 將包含切片起止時間的最小ts檔案集合篩選出來
- 將最小ts檔案集合轉封裝為mp4
- 重新計算出在mp4上實際的起止時間,進行切片
想必大家肯定有很多疑問,我們一步一步來解釋一下。
-
如何將包含切片起止時間的最小ts片段集合篩選出來?
m3u8檔案中的每一個ts檔案都標明瞭該ts檔案的時長,我們可以藉助這個將最小的ts檔案集合篩選出來
-
為什麼要轉封裝為mp4?
因為mp4支援隨機存取
-
m3u8轉封裝為mp4會不會出現m3u8中的音視訊編碼不支援mp4的情況?
不會。可以參考維基百科:https://en.wikipedia.org/wiki/Comparison_of_video_container_formats
-
如何重新計算出在mp4上的實際起止時間?
參考問題1的回答,可以通過每個ts檔案的時間,計算出最終在mp4上實際的起止時間
PS:ChatGPT真的太強大了,要是ChatGPT早點出來會少走很多彎路。
輸入視訊的音視訊編碼不規範
問題現象
在切片環節切片失敗
問題解釋
使用者輸入的視訊檔編碼不規範:
- 視訊編碼正常,音訊編碼不規範。如將pcm編碼的音訊流封裝到了mp4格式中
- 視訊編碼與音訊編碼均不規範。大概率是原視訊被強行改了字尾,如將a.mp4改成a.mxf
因為切片環節設計到重新封裝的操作,將1個mp4切成多個mp4就需要重新封裝。
在重新封裝時就會報錯,不同的容器格式支援不同的音視訊編碼,可以參考維基百科:https://en.wikipedia.org/wiki/Comparison_of_video_container_formats
有意思的是使用者意識不到他們的視訊檔有問題,因為音視訊流都能夠正常解碼(即能夠正常播放)。
解決方案
第2個問題在目前的分散式轉碼方案中還沒有好的解決方案,再加上出現概率非常小(使用者手動更改檔案字尾),這裡不做討論。
主要討論一下第1個問題的解決方案:在切片環節就將音訊檔轉碼了。

為什麼能夠在切片環節對音訊轉碼?因為音訊轉碼不耗CPU,不會明顯影響到切片環節的速度。
mxf不支援抽離音訊流
問題現象
mxf格式的視訊經過切片命令抽離出來的音訊檔時長只有1幀(0.04s)。
因為我們切片命令裡只給了1幀圖片到音訊檔中。
問題解釋
mxf以視訊流的長度作為整個視訊的長度,意味著音訊切片只有一幀影象的話,整個視訊時長只有1幀的時長。
所以問題準確的描述應該為mxf不支援以這種方式抽離音訊流。
解決方案
既然mxf不支援以這種方式抽離音訊流,那麼方案有2個:
- 將所有的視訊流不轉碼,都copy到音訊檔中,還是隻對音訊流進行轉碼。
- 看看有沒有完全包含mxf支援的音視訊編碼格式並且支援這種方式抽離音訊流的封裝格式。
方案1相當於音訊檔對輸入視訊進行了一次拷貝,如果輸入視訊特別大,那麼音訊檔也將會特別大。
我們最終採用的方案2。
有沒有這種格式呢?即支援所有mxf 音視訊編碼格式,又支援這種方式抽離音訊。
還真有。通過維基百科:https://en.wikipedia.org/wiki/Comparison_of_video_container_formats,可以發現avi格式能夠支援所有mxf支援的音視訊編碼格式;而且經過測試,也支援這種方式將音訊抽離出來。
所以對於mxf格式的視訊,在切片環節切出來的音訊檔設定為avi格式。
ffmpeg對圖片支援不夠友好
問題現象
對於頭資訊比較大的圖片再加上不能準確讀取字尾的話(如加簽存取的場景),很大概率會解析失敗,獲取到錯誤的meta資訊。
如將圖片識別出2幀。
問題解釋
ffmpeg確實對圖片支援不太友好
解決方案
將圖片下載到本地,再進行識別。
這種方案有一個缺點是耗時會非常長,如果業務方同步呼叫獲取資訊介面有可能會超時。
阿里雲的轉碼方案
決定自研轉碼之前,我們是使用阿里雲的轉碼服務的。
上面碰到的很多問題在阿里雲轉碼服務中都不存在,這裡面固然有阿里雲在音視訊轉碼領域的積累,但是我想也跟他們的轉碼方案有很大的關係。
經過長時間的觀察,我猜阿里雲沒有使用切片-轉碼-合併這種方案,而是使用高效能伺服器,不切片直接對視訊進行轉碼。
為什麼呢?因為上述問題中,基本上都是在切片環節出現的問題。尤其是「輸入視訊的音視訊編碼不規範」這個問題,只要使用切片-轉碼-合併這種方案,那麼百分之百會碰到跟我們的問題。而阿里雲不能使用我們這種非常規手段去解決。
因為視訊封裝格式、音視訊編碼格式非常多,出於穩定性考慮,不可能碰到問題了再case by case的去解決。
但是使用高效能伺服器,不切片直接對視訊進行轉碼這種方案固然能夠避免很多切片環節的問題,但是也很容易造成轉碼任務阻塞。舉一個例子:
在機器資源池不大的情況下,A使用者輸入了很多優先順序低轉碼非常耗時的視訊,把資源池都佔滿了;而隨後B使用者輸入了1個優先順序很搞的視訊,雖然優先順序很高,但是也得等待A使用者正在轉碼的視訊轉完,讓出1臺機器才能執行。
這種情況對B使用者體驗就非常不好,在A使用者轉碼完成之前對B使用者來說服務是不可用的。
最後
好了,本篇將我們實施分散式轉碼過程中所碰到的比較難解的問題以及解決方案都聊了一遍。
當然,以後還會碰新的問題,我會將其放在一個系列文章裡面討論,希望能夠給大家帶來一些幫助或者少踩一些坑。