對doccano自動標註使用的預設UIE模型進行微調以提高特定領域的實體識別能力,提高標註速度
雖然doccano的自動標註使用預設的UIE模型可以識別出一定的實體,但是在特定領域或者因為實體類別名不能被理解很多實體是識別不了的,所以我們可以通過自己標註的資料對模型進行微調來滿足我們Auto Labeing的需求。
預處理doccano標註的資料
該章節詳細說明如何通過doccano.py指令碼對doccano平臺匯出的標註資料進行轉換,一鍵生成訓練/驗證/測試集。
在本地部署UIE模型
下載模型壓縮包:
本來是要通過一定的方法(GitZip)才能在整體的大專案倉庫中下載的,不詳細講,這裡直接給壓縮包。
PaddleNLP-model_zoo.zip - 藍奏雲 (lanzoub.com)

抽取式任務資料轉換
- 當標註完成後,在 doccano 平臺上匯出
JSONL(relation)形式的檔案,並將其重新命名為doccano_ext.json後,放入./data目錄下。 - 通過 doccano.py 指令碼進行資料形式轉換,然後便可以開始進行相應模型訓練。
python doccano.py \
--doccano_file ./data/doccano_ext.json \
--task_type "ext" \
--save_dir ./data \
--negative_ratio 5
當然也可以將這個命令儲存為tran.sh檔案
訓練UIE模型
- 使用標註資料進行小樣本訓練,模型引數儲存在
./checkpoint/目錄。
tips: 推薦使用GPU環境,否則可能會記憶體溢位。CPU環境下,可以修改model為uie-tiny,適當調下batch_size。
增加準確率的話:--num_epochs 設定大點多訓練訓練
可設定引數說明:
model_name_or_path:必須,進行 few shot 訓練使用的預訓練模型。可選擇的有 "uie-base"、 "uie-medium", "uie-mini", "uie-micro", "uie-nano", "uie-m-base", "uie-m-large"。multilingual:是否是跨語言模型,用 "uie-m-base", "uie-m-large" 等模型進微調得到的模型也是多語言模型,需要設定為 True;預設為 False。output_dir:必須,模型訓練或壓縮後儲存的模型目錄;預設為None。device: 訓練裝置,可選擇 'cpu'、'gpu' 、'npu'其中的一種;預設為 GPU 訓練。per_device_train_batch_size:訓練集訓練過程批次處理大小,請結合視訊記憶體情況進行調整,若出現視訊記憶體不足,請適當調低這一引數;預設為 32。per_device_eval_batch_size:開發集評測過程批次處理大小,請結合視訊記憶體情況進行調整,若出現視訊記憶體不足,請適當調低這一引數;預設為 32。learning_rate:訓練最大學習率,UIE 推薦設定為 1e-5;預設值為3e-5。num_train_epochs: 訓練輪次,使用早停法時可以選擇 100;預設為10。logging_steps: 訓練過程中紀錄檔列印的間隔 steps 數,預設100。save_steps: 訓練過程中儲存模型 checkpoint 的間隔 steps 數,預設100。seed:全域性隨機種子,預設為 42。weight_decay:除了所有 bias 和 LayerNorm 權重之外,應用於所有層的權重衰減數值。可選;預設為 0.0;do_train:是否進行微調訓練,設定該參數列示進行微調訓練,預設不設定。do_eval:是否進行評估,設定該參數列示進行評估。
該範例程式碼中由於設定了引數 --do_eval,因此在訓練完會自動進行評估。
微調命令
export finetuned_model=./checkpoint/model_best
python finetune.py \
--device gpu \
--logging_steps 10 \
--save_steps 100 \
--eval_steps 100 \
--seed 42 \
--model_name_or_path uie-base \
--output_dir $finetuned_model \
--train_path ./data/train.txt \
--dev_path ./data/dev.txt \
--max_seq_length 512 \
--per_device_eval_batch_size 16 \
--per_device_train_batch_size 16 \
--num_train_epochs 20 \
--learning_rate 1e-5 \
--label_names "start_positions" "end_positions" \
--do_train \
--do_eval \
--do_export \
--export_model_dir $finetuned_model \
--overwrite_output_dir \
--disable_tqdm True \
--metric_for_best_model eval_f1 \
--load_best_model_at_end True \
--save_total_limit 1
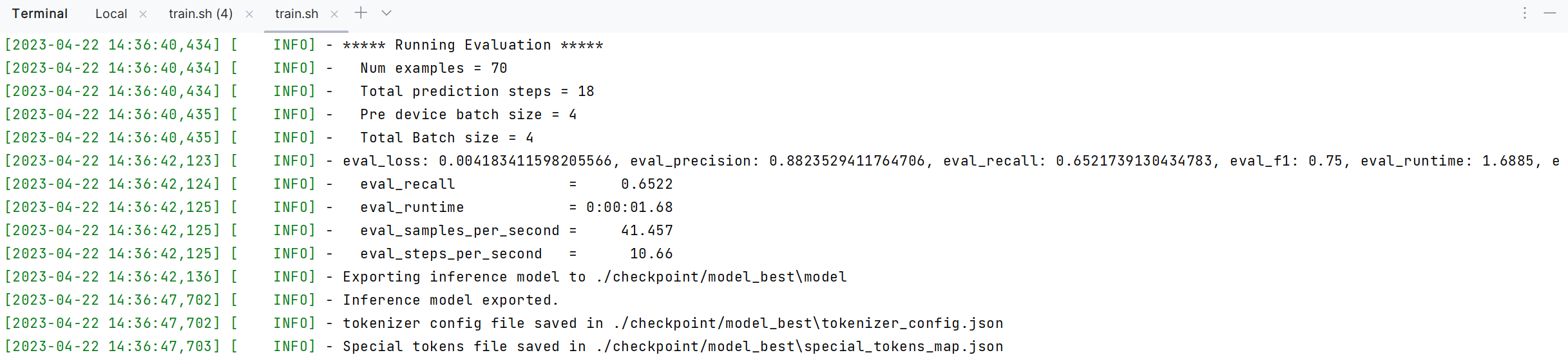
訓練完成的結果:
驗證UIE模型效果
通過執行以下命令進行模型評估:
python evaluate.py \
--model_path ./checkpoint/model_best \
--test_path ./data/dev.txt \
--batch_size 16 \
--max_seq_len 512
根據我們手動標註的資料訓練微調後,再次測試自有標註的領域資料,返回的準確率為88%.

部署微調後的UIE模型
本地終端客製化模型一鍵預測
paddlenlp.Taskflow裝載客製化模型,通過task_path指定模型權重檔案的路徑,路徑下需要包含訓練好的模型權重檔案model_state.pdparams。
from pprint import pprint
from paddlenlp import Taskflow
schema = ['出發地', '目的地', '費用', '時間']#根據自身實體類別修改
# 設定抽取目標和客製化化模型權重路徑
my_ie = Taskflow("information_extraction", schema=schema, task_path='./checkpoint/model_best')
pprint(my_ie("城市內交通費7月5日金額114廣州至佛山"))
經過測試,原本無法預測出來的型別在引入自己標註的模型之後就可以識別出來了。自此我們可以實現標註的資料用於訓練,訓練的模型又可以提升我們標註的速率。
模型快速服務化部署
在UIE的服務化能力中我們提供基於PaddleNLP SimpleServing 來搭建服務化能力,通過幾行程式碼即可搭建服務化部署能力。
在上一篇文章如何使用doccano+flask+花生殼+伺服器實現命名實體識別ner自動標註 - 孤飛 - 部落格園 (cnblogs.com)中的部署程式碼裡,我們修改task_path模型路徑為剛剛微調過後的即可完成識別。
from flask import Flask, request, jsonify
from paddlenlp import Taskflow
app = Flask(__name__)
# 在這裡定義你想要識別的實體型別
# UIE具有zero-shot能力,所以型別可以隨便定義,但是識別的好壞不一定
schema = ['出發地', '目的地', '費用', '時間']#根據自身實體類別修改
# 第一執行時,聯網狀態下會自動下載模型
# device_id為gpu id,如果寫-1則使用cpu,如果寫0則使用gpu
ie = Taskflow('information_extraction', schema=schema, device_id=0,task_path='./uie/checkpoint/model_best/')#新增了tesk_path指向新的模型
def convert(result):
result = result[0]
formatted_result = []
for label, ents in result.items():
for ent in ents:
formatted_result.append(
{
"label": label,
"start_offset": ent['start'],
"end_offset": ent['end']
})
return formatted_result
@app.route('/', methods=['POST'])
def get_result():
text = request.json['text']
print(text)
result = ie(text)
formatted_result = convert(result)
return jsonify(formatted_result)
if __name__ == '__main__':
# 這裡寫埠的時候一定要注意不要與已有的埠衝突
# 這裡的host並不是說存取的時候一定要寫0.0.0.0,但是這裡程式碼要寫0.0.0.0,代表可以被本網路中所有的看到
# 如果是其他機器存取你建立的服務,存取的時候要寫你的ip
app.run(host='0.0.0.0', port=88)
參考文章:
解決報錯:cannot import name 'strtobool' from 'paddlenlp.trainer.argparser'