基於RL(Q-Learning)的迷宮尋路演演算法
強化學習是一種機器學習方法,旨在通過智慧體在與環境互動的過程中不斷優化其行動策略來實現特定目標。與其他機器學習方法不同,強化學習涉及到智慧體對環境的觀測、選擇行動並接收獎勵或懲罰。因此,強化學習適用於那些需要自主決策的複雜問題,比如遊戲、機器人控制、自動駕駛等。強化學習可以分為基於價值的方法和基於策略的方法。基於價值的方法關注於尋找最優的行動價值函數,而基於策略的方法則直接尋找最優的策略。強化學習在近年來取得了很多突破,比如 AlphaGo 在圍棋中戰勝世界冠軍。
強化學習的重要概念:
- 環境:其主體被嵌入並能夠感知和行動的外部系統
- 主體:動作的行使者
- 狀態:主體的處境
- 動作:主體執行的動作
- 獎勵:衡量主體動作成功與否的反饋
問題描述
給定一個N*N矩陣,其中僅有-1、0、1組成該矩陣,-1表示障礙,0表示路,1表示終點和起點:
# 生成迷宮影象
def generate_maze(size):
maze = np.zeros((size, size))
# Start and end points
start = (random.randint(0, size-1), 0)
end = (random.randint(0, size-1), size-1)
maze[start] = 1
maze[end] = 1
# Generate maze walls
for i in range(size*size):
x, y = random.randint(0, size-1), random.randint(0, size-1)
if (x, y) == start or (x, y) == end:
continue
if random.random() < 0.2:
maze[x, y] = -1
if np.sum(np.abs(maze)) == size*size - 2:
break
return maze, start, end
上述函數返回一個numpy陣列型別的迷宮,起點和終點
生成迷宮影象:
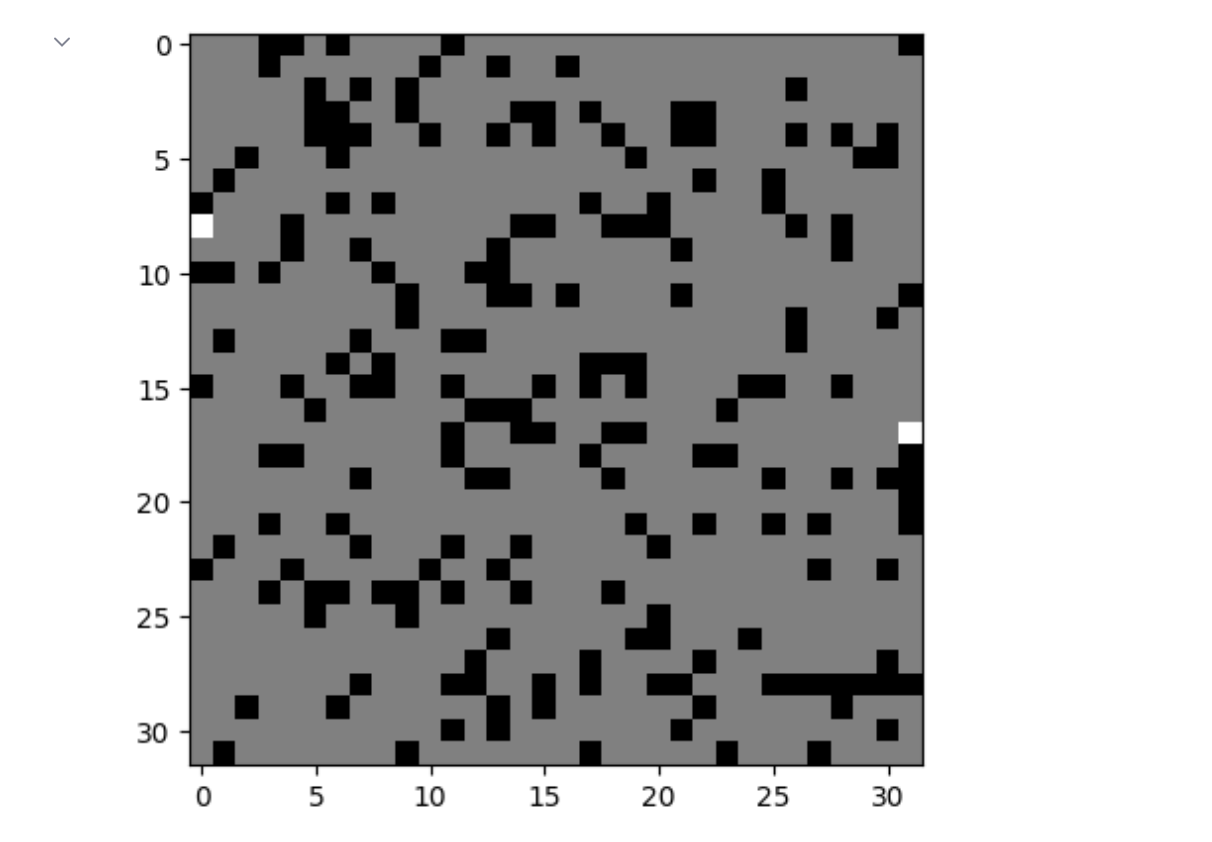
使用BFS進行尋路:
# BFS求出路徑
def solve_maze(maze, start, end):
size = maze.shape[0]
visited = np.zeros((size, size))
solve = np.zeros((size,size))
queue = [start]
visited[start[0],start[1]] = 1
while queue:
x, y = queue.pop(0)
if (x, y) == end:
break
for dx, dy in [(0, 1), (0, -1), (1, 0), (-1, 0)]:
nx, ny = x + dx, y + dy
if nx < 0 or nx >= size or ny < 0 or ny >= size or visited[nx, ny] or maze[nx, ny] == -1:
continue
queue.append((nx, ny))
visited[nx, ny] = visited[x, y] + 1
if visited[end[0],end[1]] == 0:
return solve,[]
path = [end]
x, y = end
while (x, y) != start:
for dx, dy in [(0, 1), (0, -1), (1, 0), (-1, 0)]:
nx, ny = x + dx, y + dy
if nx < 0 or nx >= size or ny < 0 or ny >= size or visited[nx, ny] != visited[x, y] - 1:
continue
path.append((nx, ny))
x, y = nx, ny
break
points = path[::-1] # 倒序
for point in points:
solve[point[0]][point[1]] = 1
return solve, points
上述函數返回一個numpy陣列,和點組成的路徑,影象如下:

BFS獲得的解毫無疑問是最優解,現在使用強化學習的方法來解決該問題(QLearning、DQN)
QLearning
該演演算法核心原理是Q-Table,其行和列表示State和Action的值,Q-Table的值Q(s,a)是衡量當前States採取行動a的重要依據
具體步驟如下:
- 初始化Q表
- 執行以下回圈:
- 初始化一個Q表格,Q表格的行表示狀態,列表示動作,Q值表示某個狀態下采取某個動作的價值估計。初始時,Q值可以設定為0或隨機值。
- 針對每個時刻,根據當前狀態s,選擇一個動作a。可以根據當前狀態的Q值和某種策略(如貪心策略)來選擇動作。
- 執行選擇的動作a,得到下一個狀態s'和相應的獎勵r$
- 基於下一個狀態s',更新Q值。Q值的更新方式為:
- 初始化一個狀態s。
- 根據當前狀態s和Q表中的Q值,選擇一個動作a。可以通過epsilon-greedy策略來進行選擇,即有一定的概率隨機選擇動作,以便於探索新的狀態,否則就選擇Q值最大的動作。
- 執行選擇的動作a,得到下一個狀態s'和獎勵r。
- 根據s'和Q表中的Q值,計算出最大Q值maxQ。
- 根據Q-learning的更新公式,更新Q值:Q(s, a) = Q(s, a) + alpha * (r + gamma * maxQ - Q(s, a)),其中alpha是學習率,gamma是折扣因子。
- 將當前狀態更新為下一個狀態:s = s'。
- 如果當前狀態為終止狀態,則轉到步驟1;否則轉到步驟2。
- 重複執行步驟1-7直到收斂,即Q值不再發生變化或者達到預定的最大迭代次數。最終得到的Q表中的Q值就是最優的策略。
- 重複執行2-4步驟,直到到達終止狀態,或者達到預設的最大步數。
- 不斷執行1-5步驟,直到Q值收斂。
- 在Q表格中根據最大Q值,選擇一個最優的策略。
程式碼實現
實現QLearningAgent類:
class QLearningAgent:
def __init__(self,actions,size):
self.actions = actions
self.learning_rate = 0.01
self.discount_factor = 0.9
self.epsilon = 0.1 # 貪婪策略取值
self.num_actions = len(actions)
# 初始化Q-Table
self.q_table = np.zeros((size,size,self.num_actions))
def learn(self,state,action,reward,next_state):
current_q = self.q_table[state][action] # 從Q-Table中獲取當前Q值
new_q = reward + self.discount_factor * max(self.q_table[next_state]) # 計算新Q值
self.q_table[state][action] += self.learning_rate * (new_q - current_q) # 更新Q表
# 獲取動作
def get_action(self,state):
if np.random.rand() < self.epsilon:
action = np.random.choice(self.actions)
else:
state_action = self.q_table[state]
action = self.argmax(state_action)
return action
@staticmethod
def argmax(state_action):
max_index_list = []
max_value = state_action[0]
for index,value in enumerate(state_action):
if value > max_value:
max_index_list.clear()
max_value = value
max_index_list.append(index)
elif value == max_value:
max_index_list.append(index)
return random.choice(max_index_list)
類的初始化:
def __init__(self,actions,size):
self.actions = actions
self.learning_rate = 0.01
self.discount_factor = 0.9
self.epsilon = 0.1 # 貪婪策略取值
self.num_actions = len(actions)
# 初始化Q-Table
self.q_table = np.zeros((size,size,self.num_actions))
上述程式碼中,先初始化動作空間,設定學習率,discount_factor是折扣因子,epsilon是貪婪策略去值,num_actions是動作數
def learn(self,state,action,reward,next_state):
current_q = self.q_table[state][action] # 從Q-Table中獲取當前Q值
new_q = reward + self.discount_factor * max(self.q_table[next_state]) # 計算新Q值
self.q_table[state][action] += self.learning_rate * (new_q - current_q) # 更新Q表
該方法是QLearning的核心流程,給定當前狀態、動作、賞罰和下一狀態更新Q表
# 獲取動作
def get_action(self,state):
if np.random.rand() < self.epsilon:
# 貪婪策略 隨機選取動作
action = np.random.choice(self.actions)
else:
# 從Q-Table中選擇
state_action = self.q_table[state]
action = self.argmax(state_action)
return action
該方法首先使用貪婪策略來決定是隨機選擇一個動作,還是選擇 Q-Table 中當前狀態對應的最大 Q 值對應的動作
@staticmethod
def argmax(state_action):
max_index_list = []
max_value = state_action[0]
for index,value in enumerate(state_action):
if value > max_value:
max_index_list.clear()
max_value = value
max_index_list.append(index)
elif value == max_value:
max_index_list.append(index)
return random.choice(max_index_list)
該方法首先獲取最大值對應的動作,遍歷Q表中的所有動作,找到最大值所對應的所有動作,最後從這些動作中隨機選擇一個作為最終的動作。
定義環境
下述定義了一個迷宮環境:
class MazeEnv:
def __init__(self,size):
self.size = size
self.actions = [0,1,2,3]
self.maze,self.start,self.end = self.generate(size)
# 重置狀態
def reset(self):
self.state = self.start
self.goal = self.end
self.path = [self.start]
self.solve = np.zeros_like(self.maze)
self.solve[self.start] = 1
self.solve[self.end] = 1
return self.state
def step(self, action):
# 執行動作
next_state = None
if action == 0 and self.state[0] > 0:
next_state = (self.state[0]-1, self.state[1])
elif action == 1 and self.state[0] < self.size-1:
next_state = (self.state[0]+1, self.state[1])
elif action == 2 and self.state[1] > 0:
next_state = (self.state[0], self.state[1]-1)
elif action == 3 and self.state[1] < self.size-1:
next_state = (self.state[0], self.state[1]+1)
else:
next_state = self.state
if next_state == self.goal:
reward = 100
elif self.maze[next_state] == -1:
reward = -100
else:
reward = -1
self.state = next_state # 更新狀態
self.path.append(self.state)
self.solve[self.state] = 1
done = (self.state == self.goal) # 判斷是否結束
return next_state, reward, done
@staticmethod
# 生成迷宮影象
def generate(size):
maze = np.zeros((size, size))
# Start and end points
start = (random.randint(0, size-1), 0)
end = (random.randint(0, size-1), size-1)
maze[start] = 1
maze[end] = 1
# Generate maze walls
for i in range(size * size):
x, y = random.randint(0, size-1), random.randint(0, size-1)
if (x, y) == start or (x, y) == end:
continue
if random.random() < 0.2:
maze[x, y] = -1
if np.sum(np.abs(maze)) == size*size - 2:
break
return maze, start, end
@staticmethod
# BFS求出路徑
def solve_maze(maze, start, end):
size = maze.shape[0]
visited = np.zeros((size, size))
solve = np.zeros((size,size))
queue = [start]
visited[start[0],start[1]] = 1
while queue:
x, y = queue.pop(0)
if (x, y) == end:
break
for dx, dy in [(0, 1), (0, -1), (1, 0), (-1, 0)]:
nx, ny = x + dx, y + dy
if nx < 0 or nx >= size or ny < 0 or ny >= size or visited[nx, ny] or maze[nx, ny] == -1:
continue
queue.append((nx, ny))
visited[nx, ny] = visited[x, y] + 1
if visited[end[0],end[1]] == 0:
return solve,[]
path = [end]
x, y = end
while (x, y) != start:
for dx, dy in [(0, 1), (0, -1), (1, 0), (-1, 0)]:
nx, ny = x + dx, y + dy
if nx < 0 or nx >= size or ny < 0 or ny >= size or visited[nx, ny] != visited[x, y] - 1:
continue
path.append((nx, ny))
x, y = nx, ny
break
points = path[::-1] # 倒序
for point in points:
solve[point[0]][point[1]] = 1
return solve, points
執行
下面生成一個32*32的迷宮,並進行30000次迭代
maze_size = 32
# 建立迷宮環境
env = MazeEnv(maze_size)
# 初始化QLearning智慧體
agent = QLearningAgent(actions=env.actions,size=maze_size)
# 進行30000次遊戲
for episode in range(30000):
state = env.reset()
while True:
action = agent.get_action(state)
next_state,reward,done = env.step(action)
agent.learn(state,action,reward,next_state)
state = next_state
if done:
break
print(agent.q_table) # 輸出Q-Table
定義一個函數,用於顯示迷宮的路線:
from PIL import Image
def maze_to_image(maze, path):
size = maze.shape[0]
img = Image.new('RGB', (size, size), (255, 255, 255))
pixels = img.load()
for i in range(size):
for j in range(size):
if maze[i, j] == -1:
pixels[j, i] = (0, 0, 0)
elif maze[i, j] == 1:
pixels[j, i] = (0, 255, 0)
for x, y in path:
pixels[y, x] = (255, 0, 0)
return np.array(img)
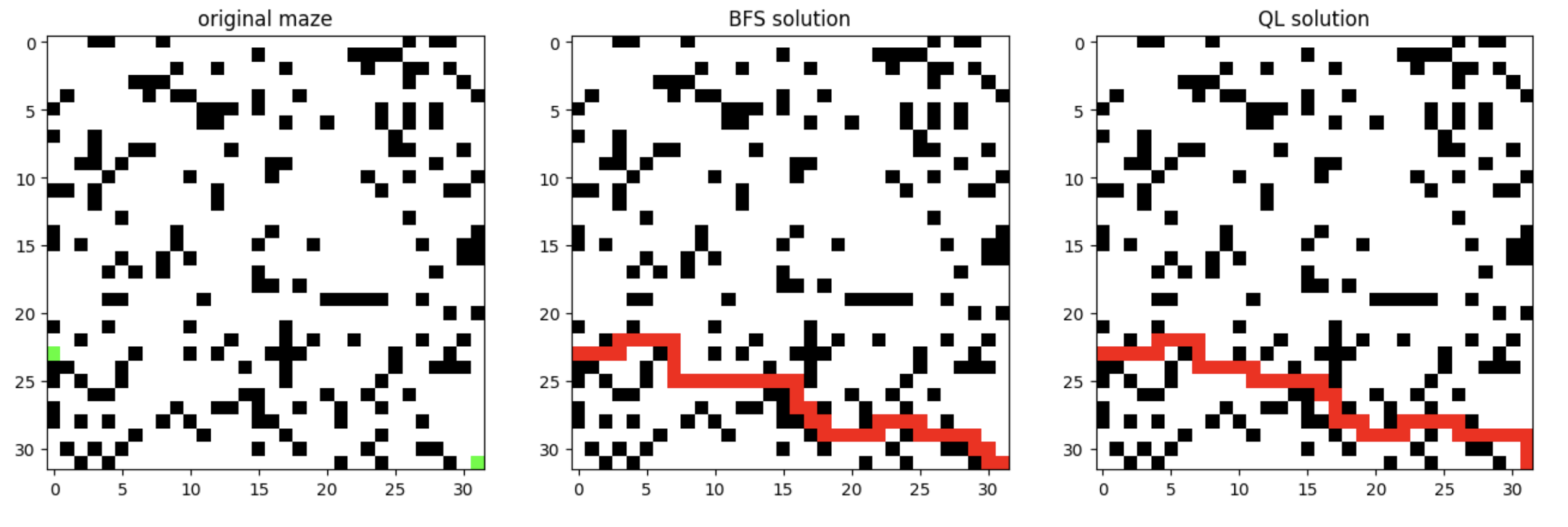
接下來顯示三個影象:迷宮影象、BFS求解的路線、QLearning求解路線:
plt.figure(figsize=(16, 10))
image1 = maze_to_image(env.maze,[])
plt.subplot(1,3,1)
plt.imshow(image1)
plt.title('original maze')
_,path = env.solve_maze(env.maze,env.start,env.end)
image2 = maze_to_image(env.maze,path)
plt.subplot(1,3,2)
plt.imshow(image2)
plt.title('BFS solution')
image3 = maze_to_image(env.maze,env.path)
plt.subplot(1,3,3)
plt.imshow(image3)
plt.title('QL solution')
# 顯示影象
plt.show()
顯示: