Karmada 多雲容器編排引擎支援多排程組,助力成本優化
摘要:Karmada 社群也在持續關注雲成本的管理,在最近釋出的 v1.5 版本中,支援使用者在分發策略 PropagationPolicy/ClusterPropagationPolicy 中設定多個叢集排程組,實現將業務排程到成本更低的叢集組中去。
本文分享自華為雲社群《Karmada 多雲容器編排引擎支援多排程組,助力成本優化!》,作者:華為云云原生團隊
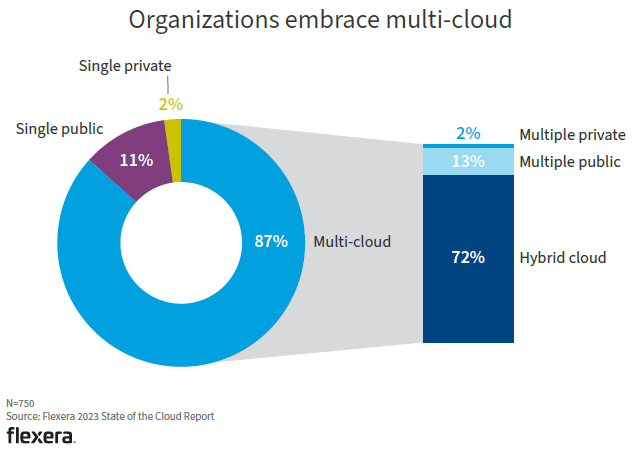
根據 Flexera 最新發布的《2023 年雲現狀調查報告》,在受訪的750家企業中,使用多雲的企業比例高達87%:
在使用多雲的受訪者中,排在前兩位的多雲挑戰分別是:孤立在不同雲上的應用程式和雲之間的災難恢復/故障切換。在所有組織中,最常用的多雲工具是安全工具,緊隨其後的是成本優化(Finops)工具。
此外,雲成本的管理取代了安全性話題,成為當下雲使用者面臨的首要問題:

Karmada 社群也在持續關注雲成本的管理,在最近釋出的 v1.5 版本中,支援使用者在分發策略 PropagationPolicy/ClusterPropagationPolicy 中設定多個叢集排程組,實現將業務排程到成本更低的叢集組中去。
多排程組
Karmada 的PropagationPolicy 支援宣告單組叢集,即.spec.placement.clusterAffinity,其 YAML 設定範例為:
apiVersion: policy.karmada.io/v1alpha1 kind: PropagationPolicy metadata: name: nginx spec: resourceSelectors: - apiVersion: apps/v1 kind: Deployment name: nginx placement: clusterAffinitiy: - clusterNames: - member1 - member2
Karmada v1.5 版本中,clusterAffinity 向 karmada-scheduler 提供一組候選叢集,karmada-scheduler 根據相關限制(例如 spreadConstraint,外掛過濾等)在候選叢集之間做出排程決策,排程結果要麼成功,要麼失敗。多排程組支援使用者設定ClusterAffinities欄位,在 PropagationPolicy 中宣告多組叢集,karmada-scheduler 可以依次來評估每個 clusterAffinity,進而做出決策。此功能允許 Karmada 排程程式在叢集故障時首先將應用程式排程到低成本叢集組,或將應用程式從主叢集遷移到備份叢集。
// Placement represents the rule for select clusters. type Placement struct { // ClusterAffinities 表示對 ClusterAffinityTerm 指示的多個叢集組的排程限制。 // 排程程式將按照這些組在規範中出現的順序逐個評估,不滿足排程限制的組將被忽略, // 這意味著除非該組中的所有叢集也屬於下一個組(同一叢集可以屬於多個組), // 否則將不會選擇此組中的所有叢集。 // 如果沒有一個組滿足排程限制,則排程失敗,這意味著不會選擇叢集。 // 注:ClusterAffinities 不能與 ClusterAffinity 共存。 // 如果未同時設定 ClusterAffinities 和 ClusterAffinity,則任何叢集都可以作為排程候選叢集。 // // +optional ClusterAffinities []ClusterAffinityTerm `json:"clusterAffinities,omitempty"` } // ClusterAffinityTerm selects a set of cluster. type ClusterAffinityTerm struct { // AffinityName 是叢集組的名稱. // +required AffinityName string `json:"affinityName"` ClusterAffinity `json:",inline"` }
雲成本管理使用場景
使用者可以使用多排程組來進行雲成本的管理,例如:本地資料中心中的私有叢集是主叢集組,叢集提供商提供的託管叢集可以是輔助叢集組,因此,Karmada 排程程式更願意將工作負載排程到主叢集組,只有在主叢集組不滿足限制(如缺乏資源)的情況下,才會考慮輔助叢集組。下面我們給出一個針對成本優化進行排程的例子:
apiVersion: policy.karmada.io/v1alpha1 kind: PropagationPolicy metadata: name: nginx spec: resourceSelectors: - apiVersion: apps/v1 kind: Deployment name: nginx placement: clusterAffinities: - affinityName: local-clusters clusterNames: - local-member1 - local-member2 - affinityName: cloud-clusters clusterNames: - huawei-member1 - huawei-member2
上面例子中設定有本地叢集組(local-clusters)和雲上叢集組(cloud-clusters)共兩個叢集組,Karmada 在排程 Deployment/nginx 時,會優先嚐試排程到本地叢集組中的叢集,如果失敗(如缺乏資源),則繼續選擇雲上叢集組,從而實現在本地叢集資源足夠時,優先選擇成本更低的本地叢集的目標。
容災與遷移場景
對於災難恢復場景,系統管理員也可以定義主叢集組和備份叢集組,工作負載將首先排程到主叢集組,當主叢集組中的叢集發生故障(如資料中心斷電)時,Karmada 排程程式可以將工作負載遷移到備份叢集組。
apiVersion: policy.karmada.io/v1alpha1 kind: PropagationPolicy metadata: name: nginx spec: resourceSelectors: - apiVersion: apps/v1 kind: Deployment name: nginx placement: clusterAffinities: - affinityName: primary-cluster clusterNames: - member1 - affinityName: backup-cluster clusterNames: - member2
上面的例子通過設定主叢集組(primary-cluster)和備份叢集組(backup-cluster),在排程 Deployment/nginx 時,如果主叢集組滿足要求,會排程到主叢集組中的 member1 叢集,當member1 叢集故障時,排程器按順序匹配新叢集組,從而將業務遷移到備份叢集組中的member2 上,這樣就達成了容災的目的。
總結
支援多排程組設定為使用者提供了更豐富的多叢集資源分發策略選擇,Karmada 後續也會繼續探索雲成本的管理,大家有任何感興趣的想法,都歡迎大家來 Karmada 社群進行討論與分享。
附:Karmada社群交流地址
專案地址:https://github.com/karmada-io/karmada
Slack地址:https://slack.cncf.io/