零樣本文字分類應用:基於UTC的醫療意圖多分類,打通資料標註-模型訓練-模型調優-預測部署全流程。
零樣本文字分類應用:基於UTC的醫療意圖多分類,打通資料標註-模型訓練-模型調優-預測部署全流程。
1.通用文字分類技術UTC介紹
本專案提供基於通用文字分類 UTC(Universal Text Classification) 模型微調的文字分類端到端應用方案,打通資料標註-模型訓練-模型調優-預測部署全流程,可快速實現文字分類產品落地。
文字分類是一種重要的自然語言處理任務,它可以幫助我們將大量的文字資料進行有效的分類和歸納。實際上,在日常生活中,我們也經常會用到文字分類技術。例如,我們可以使用文字分類來對新聞報道進行分類,對電子郵件進行分類,對社交媒體上的評論進行情感分析等等。但是,文字分類也面臨著許多挑戰。其中最重要的挑戰之一是資料稀缺。由於文字資料往往非常龐大,因此獲取足夠的訓練資料可能非常困難。此外,不同的文字分類任務也可能面臨著領域多變和任務多樣等挑戰。為了應對這些挑戰,PaddleNLP推出了一項零樣本文字分類應用UTC。該應用通過統一語意匹配方式USM(Unified Semantic Matching)來將標籤和文字的語意匹配能力進行統一建模。這種方法可以幫助我們更好地理解文字資料,並從中提取出有用的特徵資訊。
UTC具有低資源遷移能力,可以支援通用分類、評論情感分析、語意相似度計算、蘊含推理、多項式閱讀理解等多種「泛分類」任務。這使得開發者可以更加輕鬆高效地實現多工文字分類資料標註、訓練、調優和上線,從而降低文字分類技術門檻。
總之,文字分類是一項重要的自然語言處理任務,它可以幫助我們更好地理解和歸納文字資料。儘管它面臨著許多挑戰,但是通過使用PaddleNLP的零樣本文字分類應用UTC,開發者們可以簡單高效實現多工文字分類資料標註、訓練、調優、上線,降低文字分類落地技術門檻。
- 引數說明
| 引數 | 引數說明 |
|---|---|
| --model_dir | 指定部署模型的目錄, |
| --batch_size | 輸入的batch size,預設為 1 |
| --max_length | 最大序列長度,預設為 128 |
| --num_omask_tokens | 最大標籤數量,預設為64 |
| --device | 執行的裝置,可選範圍: ['cpu', 'gpu'],預設為'cpu' |
| --device_id | 執行裝置的id。預設為0。 |
| --cpu_threads | 當使用cpu推理時,指定推理的cpu執行緒數,預設為1。 |
| --backend | 支援的推理後端,可選範圍: ['onnx_runtime', 'paddle', 'tensorrt', 'paddle_tensorrt'],預設為'paddle' |
| --use_fp16 | 是否使用FP16模式進行推理。使用tensorrt和paddle_tensorrt後端時可開啟,預設為False |
- FastDeploy 高階用法
FastDeploy 在 Python 端上,提供 fastdeploy.RuntimeOption.use_xxx() 以及 fastdeploy.RuntimeOption.use_xxx_backend() 介面支援開發者選擇不同的硬體、不同的推理引擎進行部署。在不同的硬體上部署 UTC 模型,需要選擇硬體所支援的推理引擎進行部署,下表展示如何在不同的硬體上選擇可用的推理引擎部署 UTC 模型。
符號說明: (1) ✅: 已經支援; (2) ❔: 正在進行中; (3) N/A: 暫不支援;
| 硬體 | 硬體對應的介面 | 可用的推理引擎 | 推理引擎對應的介面 | 是否支援 Paddle 新格式量化模型 | 是否支援 FP16 模式 |
| CPU | use_cpu() | Paddle Inference | use_paddle_infer_backend() | ✅ | N/A |
| ONNX Runtime | use_ort_backend() | ✅ | N/A | ||
| GPU | use_gpu() | Paddle Inference | use_paddle_infer_backend() | ✅ | N/A |
| ONNX Runtime | use_ort_backend() | ✅ | ❔ | ||
| Paddle TensorRT | use_paddle_infer_backend() + paddle_infer_option.enable_trt = True | ✅ | ✅ | ||
| TensorRT | use_trt_backend() | ✅ | ✅ | ||
| 崑崙芯 XPU | use_kunlunxin() | Paddle Lite | use_paddle_lite_backend() | N/A | ✅ |
| 華為 昇騰 | use_ascend() | Paddle Lite | use_paddle_lite_backend() | ❔ | ✅ |
| Graphcore IPU | use_ipu() | Paddle Inference | use_paddle_infer_backend() | ❔ | N/A |
# !pip install --user fast-tokenizer-python fastdeploy-gpu-python -f https://www.paddlepaddle.org.cn/whl/fastdeploy.html
#比較大1.4G 去終端安裝
在notebook執行出現問題,可能需要本地對fastdeploy應用偵錯,或者有小夥伴解決了可以再評論區發表一下,一起解決。
- 在studio 目前顯示是安裝成功了,但是初始化是失敗的
File "/home/aistudio/.data/webide/pip/lib/python3.7/site-packages/fastdeploy/c_lib_wrap.py", line 166, in <module>
raise RuntimeError("FastDeploy initalized failed!")
RuntimeError: FastDeploy initalized failed!
- 在本地測試模型使用了utc-pico,cpu情況下偵錯。
效果如下:
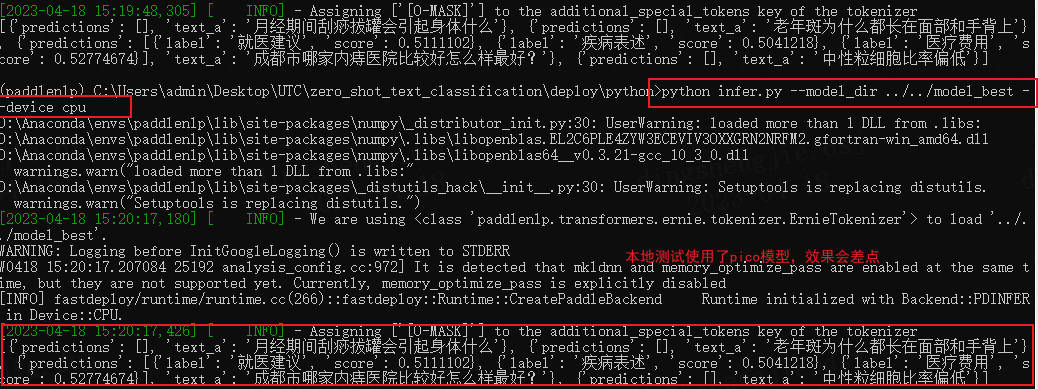
記得修改infer檔案對應的預測內容
predictor = Predictor(args, schema=["病情診斷", "治療方案", "病因分析", "指標解讀", "就醫建議", "疾病表述", "後果表述", "注意事項", "功效作用", "醫療費用", "其他"])
results = predictor.predict(["月經期間刮痧拔罐會引起身體什麼","老年斑為什麼都長在面部和手背上","成都市哪家內痔醫院比較好怎麼樣最好?","中性粒細胞比率偏低"])
推理:模型目錄需要包含:model.pdmodel等檔案
5.2 SimpleServing 的服務化部署
在 UTC 的服務化能力中我們提供基於PaddleNLP SimpleServing 來搭建服務化能力,通過幾行程式碼即可搭建服務化部署能力。
- 環境準備
使用有SimpleServing功能的PaddleNLP版本(或者最新的develop版本)
pip install paddlenlp >= 2.5.0
- Server服務啟動
進入檔案當前所在路徑
paddlenlp server server:app --workers 1 --host 0.0.0.0 --port 8190
- Client請求啟動
python client.py
-
服務化自定義引數
-
Server 自定義引數
-
schema替換
-
# Default schema
schema = ["病情診斷", "治療方案", "病因分析", "指標解讀", "就醫建議", "疾病表述", "後果表述", "注意事項", "功效作用", "醫療費用", "其他"]
* 設定模型路徑
# Default task_path
utc = Taskflow("zero_shot_text_classification", model="utc-base", task_path="../../checkpoint/model_best/plm", schema=schema)
* 多卡服務化預測
PaddleNLP SimpleServing 支援多卡負載均衡預測,主要在服務化註冊的時候,註冊兩個Taskflow的task即可,下面是範例程式碼
utc1 = Taskflow("zero_shot_text_classification", model="utc-base", task_path="../../checkpoint/model_best", schema=schema)
utc2 = Taskflow("zero_shot_text_classification", model="utc-base", task_path="../../checkpoint/model_best", schema=schema)
service.register_taskflow("taskflow/utc", [utc1, utc2])
- 更多設定
from paddlenlp import Taskflow
schema = ["病情診斷", "治療方案", "病因分析", "指標解讀", "就醫建議", "疾病表述", "後果表述", "注意事項", "功效作用", "醫療費用", "其他"]
utc = Taskflow("zero_shot_text_classification",
schema=schema,
model="utc-base",
max_seq_len=512,
batch_size=1,
pred_threshold=0.5,
precision="fp32")
-
schema:定義任務標籤候選集合。 -
model:選擇任務使用的模型,預設為utc-base, 可選有utc-xbase,utc-base,utc-medium,utc-micro,utc-mini,utc-nano,utc-pico。 -
max_seq_len:最長輸入長度,包括所有標籤的長度,預設為512。 -
batch_size:批次處理大小,請結合機器情況進行調整,預設為1。 -
pred_threshold:模型對標籤預測的概率在0~1之間,返回結果去掉小於這個閾值的結果,預設為0.5。 -
precision:選擇模型精度,預設為fp32,可選有fp16和fp32。fp16推理速度更快。如果選擇fp16,請先確保機器正確安裝NVIDIA相關驅動和基礎軟體,確保CUDA>=11.2,cuDNN>=8.1.1,初次使用需按照提示安裝相關依賴。其次,需要確保GPU裝置的CUDA計算能力(CUDA Compute Capability)大於7.0,典型的裝置包括V100、T4、A10、A100、GTX 20系列和30系列顯示卡等。更多關於CUDA Compute Capability和精度支援情況請參考NVIDIA檔案:GPU硬體與支援精度對照表。- Client 自定義引數
# Changed to input texts you wanted
texts = ["中性粒細胞比率偏低"]
%cd /home/aistudio/deploy/simple_serving
!paddlenlp server server:app --workers 1 --host 0.0.0.0 --port 8190
#Error loading ASGI app. Could not import module "server".
#去終端執行即可
/home/aistudio/deploy/simple_serving
[2023-04-13 18:26:51,839] [ INFO] - starting to PaddleNLP SimpleServer...
[2023-04-13 18:26:51,840] [ INFO] - The PaddleNLP SimpleServer is starting, backend component uvicorn arguments as follows:
[2023-04-13 18:26:51,840] [ INFO] - the starting argument [host]=0.0.0.0
[2023-04-13 18:26:51,840] [ INFO] - the starting argument [port]=8190
[2023-04-13 18:26:51,840] [ INFO] - the starting argument [log_level]=None
[2023-04-13 18:26:51,840] [ INFO] - the starting argument [workers]=1
[2023-04-13 18:26:51,840] [ INFO] - the starting argument [limit_concurrency]=None
[2023-04-13 18:26:51,840] [ INFO] - the starting argument [limit_max_requests]=None
[2023-04-13 18:26:51,840] [ INFO] - the starting argument [timeout_keep_alive]=15
[2023-04-13 18:26:51,840] [ INFO] - the starting argument [app_dir]=/home/aistudio/deploy/simple_serving
[2023-04-13 18:26:51,840] [ INFO] - the starting argument [reload]=False
[2023-04-13 18:26:52,037] [ INFO] - We are using <class 'paddlenlp.transformers.ernie.tokenizer.ErnieTokenizer'> to load 'utc-base'.
[2023-04-13 18:26:52,038] [ INFO] - Already cached /home/aistudio/.paddlenlp/models/utc-base/utc_base_vocab.txt
[2023-04-13 18:26:52,067] [ INFO] - tokenizer config file saved in /home/aistudio/.paddlenlp/models/utc-base/tokenizer_config.json
[2023-04-13 18:26:52,067] [ INFO] - Special tokens file saved in /home/aistudio/.paddlenlp/models/utc-base/special_tokens_map.json
[2023-04-13 18:26:52,069] [ INFO] - Assigning ['[O-MASK]'] to the additional_special_tokens key of the tokenizer
[2023-04-13 18:26:55,628] [ INFO] - Taskflow request [path]=/taskflow/utc is genereated.
INFO: Started server process [1718]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8190 (Press CTRL+C to quit)
^C
INFO: Shutting down
INFO: Waiting for application shutdown.
INFO: Application shutdown complete.
INFO: Finished server process [1718]
在notebook如果不行,可以直接進入終端進行偵錯,需要注意的是要在同一個路徑下不然會報錯
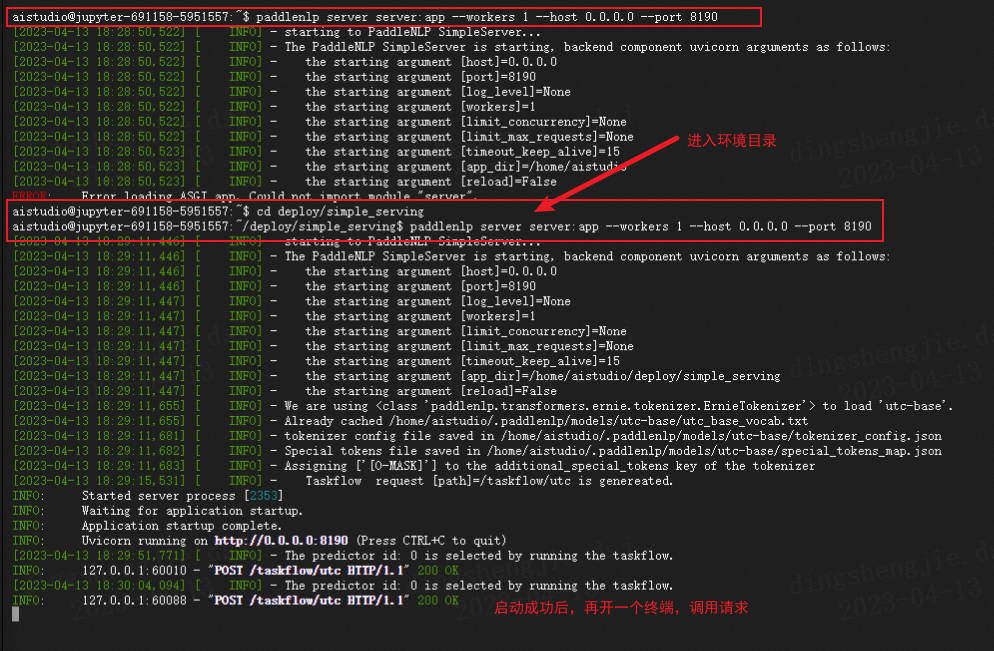
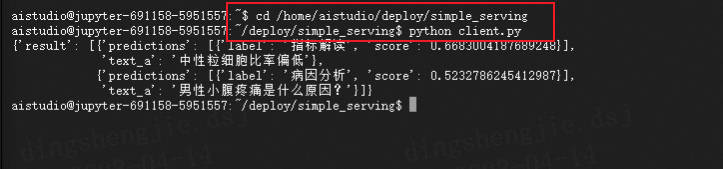
# Save at server.py
from paddlenlp import SimpleServer, Taskflow
schema = ["病情診斷", "治療方案", "病因分析", "指標解讀", "就醫建議"]
utc = Taskflow("zero_shot_text_classification",
model="utc-base",
schema=schema,
task_path="/home/aistudio/checkpoint/model_best/plm",
precision="fp32")
app = SimpleServer()
app.register_taskflow("taskflow/utc", utc)
# %cd /home/aistudio/deploy/simple_serving
!python client.py
6.總結
原專案連結:
https://blog.csdn.net/sinat_39620217/article/details/130237035
原文文末含碼源以及地址
Macro F1和Micro F1都是評估分類模型效能的指標,但是它們計算方式不同。
-
Macro F1是每個類別的F1值的平均值,不考慮類別的樣本數。它適用於資料集中各個類別的樣本數量相近的情況下,可以更好地反映每個類別的效能。
-
Micro F1是所有類別的F1值的加權平均,其中權重為每個類別的樣本數。它將所有類別的預測結果彙總為一個混淆矩陣,並計算出整個資料集的精確率、召回率和F1值。Micro F1適用於多分類問題,尤其是在資料集不平衡的情況下,可以更好地反映整體的效能。
總之,Micro F1更關注整個資料集的效能,而Macro F1更關注每個類別的效能。
醫療意圖分類資料集 KUAKE-QIC 驗證集 zero-shot 實驗指標和小樣本下訓練對比:
| Macro F1 | Micro F1 | 微調後 Macro F1 | 微調後 Micro F1 | |
|---|---|---|---|---|
| utc-xbase | 66.30 | 89.67 | ||
| utc-base | 64.13 | 89.06 | 81.67(+17.54) | 93.94 (+4.88) |
| utc-medium | 69.62 | 89.15 | ||
| utc-micro | 60.31 | 79.14 | ||
| utc-mini | 65.82 | 89.82 | ||
| utc-nano | 62.03 | 80.92 | ||
| utc-pico | 53.63 | 83.57 |
6.1 更多工適配
PaddleNLP結合文心ERNIE,基於UTC技術開源了首個面向通用文字分類的產業級技術方案。對於簡單任務,通過呼叫 paddlenlp.Taskflow API ,僅用三行程式碼即可實現零樣本(Zero-shot)通用文字分類,可支援情感分析、意圖識別、語意匹配、蘊含推理等各種可轉換為分類問題的NLU任務。僅使用一個模型即可同時支援多個任務,便捷高效!
from pprint import pprint
from paddlenlp import Taskflow
# 情感分析
cls = Taskflow("zero_shot_text_classification", schema=["這是一條好評", "這是一條差評"])
cls("房間乾淨明亮,非常不錯")
>>>
[{'predictions': [{'label': '這是一條好評', 'score': 0.9695149765679986}],
'text_a': '房間乾淨明亮,非常不錯'}]
# 意圖識別
schema = ["病情診斷", "治療方案", "病因分析", "指標解讀", "就醫建議", "疾病表述", "後果表述", "注意事項", "功效作用", "醫療費用", "其他"]
pprint(cls("先天性厚甲症去哪裡治"))
>>>
[{'predictions': [{'label': '就醫建議', 'score': 0.9628814210597645}],
'text_a': '先天性厚甲症去哪裡治'}]
# 語意相似度
cls = Taskflow("zero_shot_text_classification", schema=["不同", "相同"])
pprint(cls([["怎麼檢視合同", "從哪裡可以看到合同"], ["為什麼一直沒有電話來確認借款資訊", "為何我還款了,今天卻接到客服電話通知"]]))
>>>
[{'predictions': [{'label': '相同', 'score': 0.9775065319076257}],
'text_a': '怎麼檢視合同',
'text_b': '從哪裡可以看到合同'},
{'predictions': [{'label': '不同', 'score': 0.9918983379165037}],
'text_a': '為什麼一直沒有電話來確認借款資訊',
'text_b': '為何我還款了,今天卻接到客服電話通知'}]
# 蘊含推理
cls = Taskflow("zero_shot_text_classification", schema=["中立", "蘊含", "矛盾"])
pprint(cls([["一個騎自行車的人正沿著一條城市街道朝一座有時鐘的塔走去。", "騎自行車的人正朝鐘樓走去。"],
["一個留著長髮和鬍鬚的怪人,在地鐵裡穿著一件顏色鮮豔的襯衫。", "這件襯衫是新的。"],
["一個穿著綠色襯衫的媽媽和一個穿全黑衣服的男人在跳舞。", "兩人都穿著白色褲子。"]]))
>>>
[{'predictions': [{'label': '蘊含', 'score': 0.9944843058584897}],
'text_a': '一個騎自行車的人正沿著一條城市街道朝一座有時鐘的塔走去。',
'text_b': '騎自行車的人正朝鐘樓走去。'},
{'predictions': [{'label': '中立', 'score': 0.6659998351201399}],
'text_a': '一個留著長髮和鬍鬚的怪人,在地鐵裡穿著一件顏色鮮豔的襯衫。',
'text_b': '這件襯衫是新的。'},
{'predictions': [{'label': '矛盾', 'score': 0.9270557883904931}],
'text_a': '一個穿著綠色襯衫的媽媽和一個穿全黑衣服的男人在跳舞。',
'text_b': '兩人都穿著白色褲子。'}]