紮實打牢資料結構演演算法根基,從此不怕演演算法面試系列之week01 02-09 測試演演算法時間複雜度效能的方式方法
1、陣列生成器
測試演演算法效能肯定不能自己手動宣告建立陣列了,在現代計算機上,對於O(n)級別的演演算法,都需要10W級別以上的資料才能看到效能,我們肯定不能手動宣告10W個元素的陣列吧?
所以,建立陣列生成器。
這裡,自己建立一個陣列生成器——ArrayGenerator。
package com.mosesmin.datastructure.week01.chap02;
/**
* @Misson&Goal 程式碼以交朋友、傳福音
* @ClassName ArrayGenerator
* @Description TODO 陣列生成器
* @Author MosesMin
* @Date 2023/4/14
* @Version 1.0
*/
public class ArrayGenerator {
private ArrayGenerator() {}
public static Integer[] generatedOrderedArray(int n){
Integer[] arr = new Integer[n];
for (int i = 0; i < n; i++)
arr[i] = i;
return arr;
}
}
2、使用陣列生成器進行測試
詳細程式碼如註釋:
package com.mosesmin.datastructure.week01.chap02;
/**
* @Misson&Goal 程式碼以交朋友、傳福音
* @ClassName LinearSearch03
* @Description TODO
* @Author MosesMin
* @Date 2023/4/14
* @Version 1.0
*/
public class LinearSearch09 {
private LinearSearch09(){}
public static <E> int search(E [] data,E target){
for (int i = 0; i < data.length; i++)
if (data[i].equals(target))
return i;
return -1;
}
public static void main(String[] args) {
int n = 1000000;
Integer[] data = ArrayGenerator.generatedOrderedArray(n);// 10w的資料規模
long startTime = System.nanoTime();//單位是納秒 納秒-微妙-毫秒-秒 差距都是1000倍
for (int k=0;k<100;k++)
LinearSearch09.search(data,n);//這裡為了驗證最差的情況,就傳一個找不到的目標元素100000
long endTime = System.nanoTime();
double time = (endTime-startTime)/(1000*1000*1000.0);// 最後1000.0,因為我們希望結果是個浮點數
System.out.println(time + " s");
}
}
10W的資料規模,執行一次,在我的電腦(CPU為:Intel(R) Core(TM) i5-4570 CPU @ 3.20GHz 3.20 GHz)執行時間約為0.0027秒,即2.7毫秒。
3毫秒,可能不夠穩定,不一定是線性查詢法執行的時間結果,因為作業系統也在執行,我們可以再試下使用更大的資料,比如使用100W的資料規模,看看它們執行
的時間差是否為10倍左右。
執行結果:
10W資料規模:
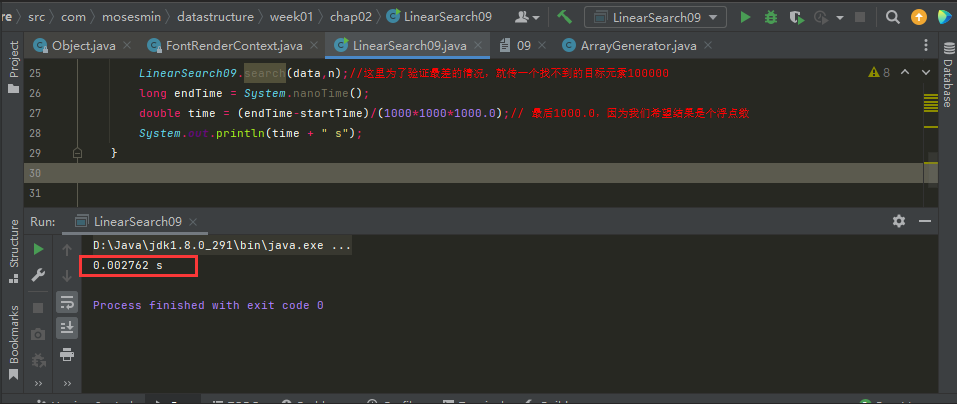
我們看到100W的執行結果約為6.6毫秒;幾毫秒的執行結果還是不夠穩。
100W資料規模:
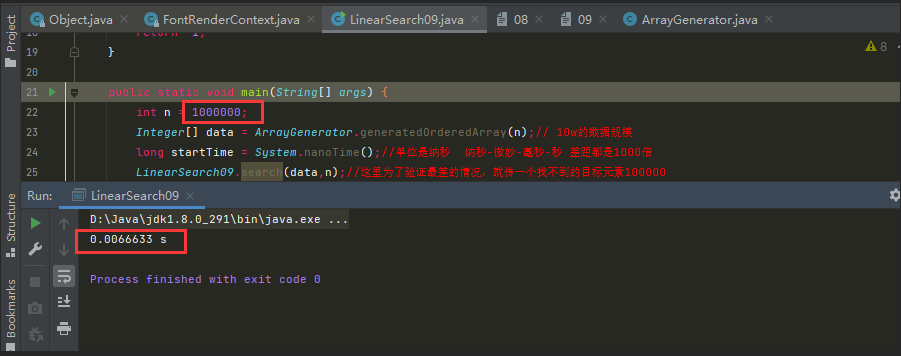
我們再試下1000W的資料規模。
我們看到1000w約為26毫秒;
注:
對於一般的計算機而言,1000W的資料規模已經是個夠量的規模了。
1000W資料規模:
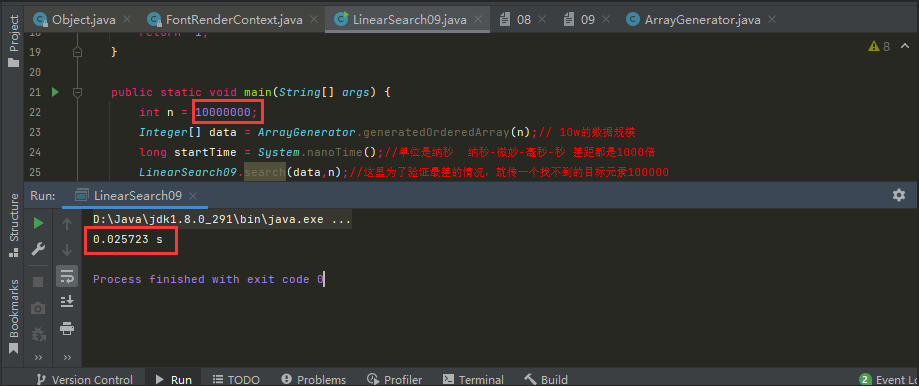
我們還可以看一下1億的規模,但是執行1億的資料規模時,我的電腦執行了很久,將近20s時間,最終顯示結果約為182毫秒。
為什麼實際上執行了20s時間呢?
因為對於一般的計算機來說,開1億個整型空間,尤其時1億個連續的整型空間時需要一些時間的,特別是我的電腦設定不太高,i5的4代cpu(Intel(R) Core(TM) i5-4570 CPU @ 3.20GHz 3.20 GHz)。
1億資料規模:
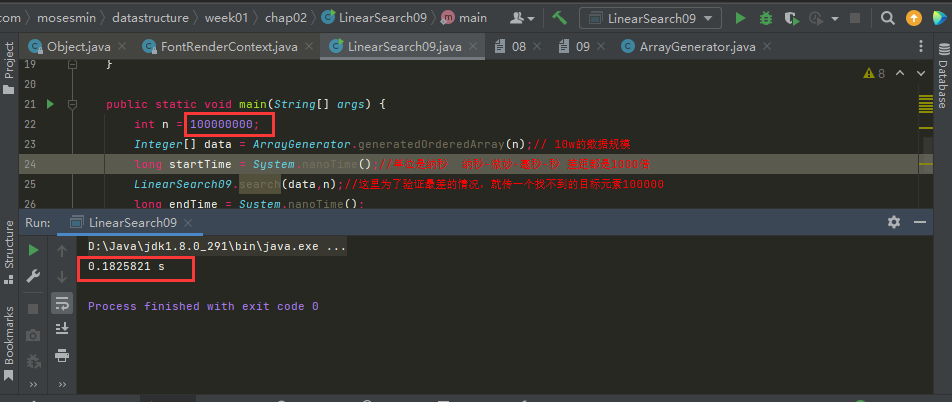
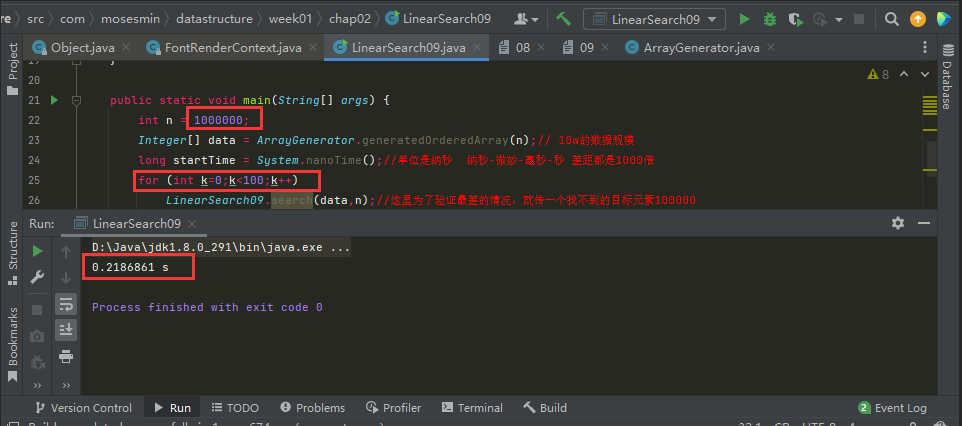
如果我們希望得到的時間更長一些,一個簡單方法是,多做幾次,這裡,我們就用100W的資料規模,然後測試100次。
100W的規模,執行100次,約為218毫秒。
100W資料規模執行100次:
3、一些測試優化
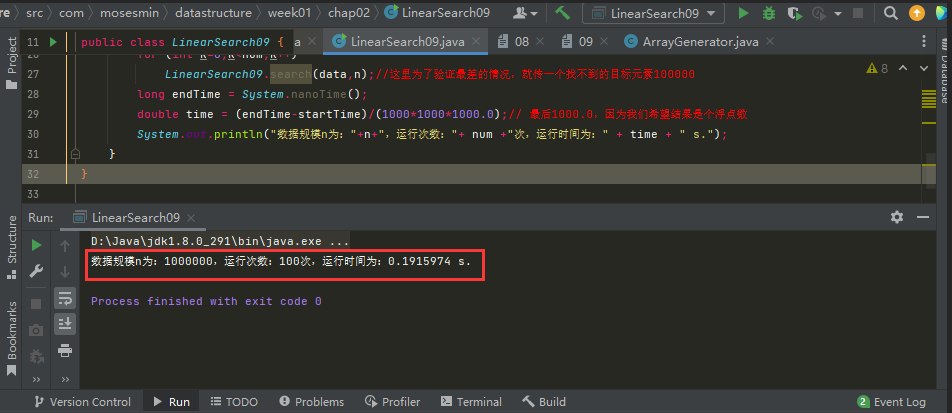
1、優化一下輸出log
主要改動的語句為:
System.out.println("資料規模n為:"+n+",執行次數:"+ num +"次,執行時間為:" + time + " s.");
優化後的程式碼如下:
package com.mosesmin.datastructure.week01.chap02;
/**
* @Misson&Goal 程式碼以交朋友、傳福音
* @ClassName LinearSearch03
* @Description TODO
* @Author MosesMin
* @Date 2023/4/14
* @Version 1.0
*/
public class LinearSearch09 {
private LinearSearch09(){}
public static <E> int search(E [] data,E target){
for (int i = 0; i < data.length; i++)
if (data[i].equals(target))
return i;
return -1;
}
public static void main(String[] args) {
int n = 1000000;
Integer[] data = ArrayGenerator.generatedOrderedArray(n);// 10w的資料規模
long startTime = System.nanoTime();//單位是納秒 納秒-微妙-毫秒-秒 差距都是1000倍
int num = 100;
for (int k=0;k<num;k++)
LinearSearch09.search(data,n);//這裡為了驗證最差的情況,就傳一個找不到的目標元素100000
long endTime = System.nanoTime();
double time = (endTime-startTime)/(1000*1000*1000.0);// 最後1000.0,因為我們希望結果是個浮點數
System.out.println("資料規模n為:"+n+",執行次數:"+ num +"次,執行時間為:" + time + " s.");
}
}
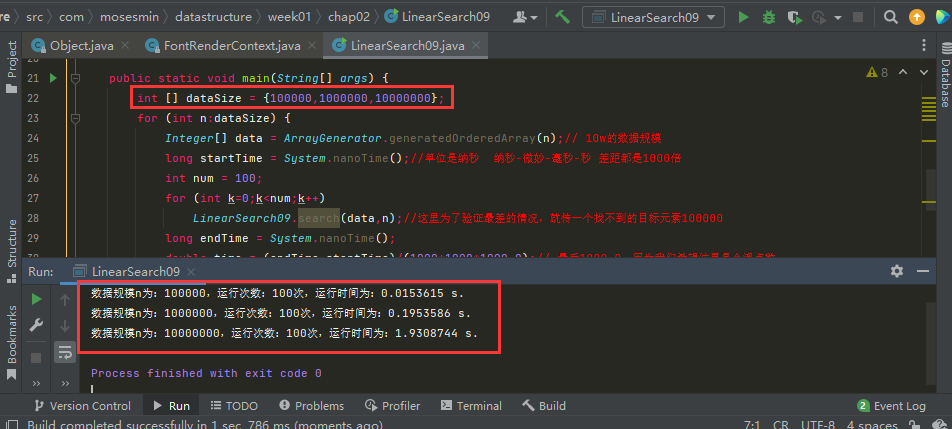
2、建立資料規模陣列,利用迴圈一次測試多個資料規模
int [] dataSize = {100000,1000000,10000000};
for (int n:dataSize) {
……
}
新增資料規模陣列後的程式碼如下:
package com.mosesmin.datastructure.week01.chap02;
/**
* @Misson&Goal 程式碼以交朋友、傳福音
* @ClassName LinearSearch03
* @Description TODO
* @Author MosesMin
* @Date 2023/4/14
* @Version 1.0
*/
public class LinearSearch09 {
private LinearSearch09(){}
public static <E> int search(E [] data,E target){
for (int i = 0; i < data.length; i++)
if (data[i].equals(target))
return i;
return -1;
}
public static void main(String[] args) {
int [] dataSize = {100000,1000000,10000000};
for (int n:dataSize) {
Integer[] data = ArrayGenerator.generatedOrderedArray(n);// 10w的資料規模
long startTime = System.nanoTime();//單位是納秒 納秒-微妙-毫秒-秒 差距都是1000倍
int num = 100;
for (int k=0;k<num;k++)
LinearSearch09.search(data,n);//這裡為了驗證最差的情況,就傳一個找不到的目標元素100000
long endTime = System.nanoTime();
double time = (endTime-startTime)/(1000*1000*1000.0);// 最後1000.0,因為我們希望結果是個浮點數
System.out.println("資料規模n為:"+n+",執行次數:"+ num +"次,執行時間為:" + time + " s.");
}
}
}
建立一個資料規模陣列,迴圈執行,可以看是10W、100W、1000W的執行時間差異確實約為10倍的差距。
ok,到這裡,我們的測試方法講解結束了,後續我們都可以用這樣的方式來對不同的演演算法做測試。