MySQL InnoDB Architecture 簡要介紹
MySQL InnoDB 儲存引擎整體架構圖:
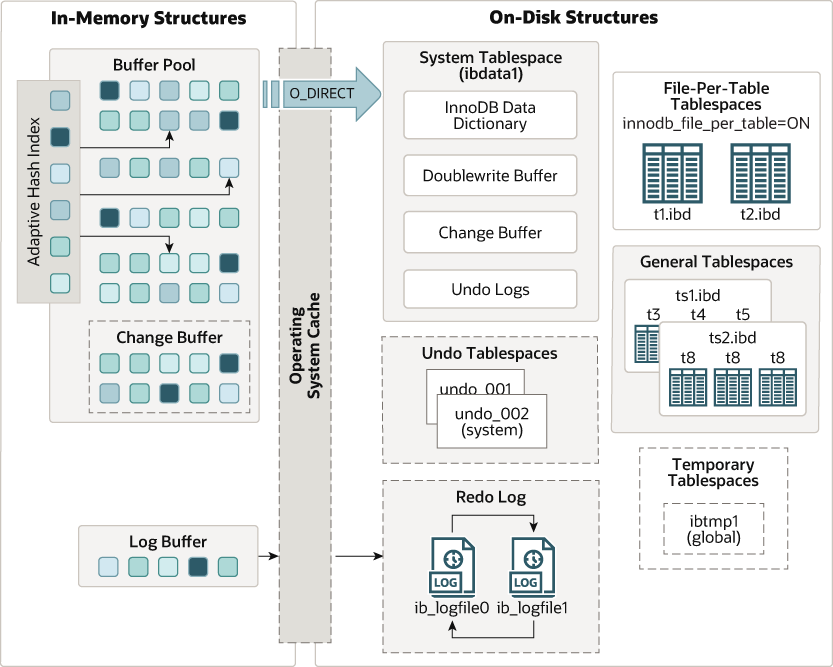
一、記憶體儲存結構
1、Buffer Pool
buffer pool 是主記憶體中的一塊兒儲存區域,用於儲存存取的表及索引資料。這樣從記憶體中直接存取獲取使用的資料可以極大的提升存取效率。在一些特殊專用的服務裡,幾乎 80% 的記憶體區域都被賦於 buffer pool。
為了提升巨量資料量讀操作效率,buffer pool 被設計劃分為能夠儲存多條記錄的資料頁。同時,基於連結串列結構儲存實現,LRU演演算法支援,能夠極大的提高快取管理的效率。
Buffer Pool LRU 演演算法
buffer pool 使用基於LRU演演算法的列表資料結構實現。當需要新增新的資料頁,最近最少使用的資料頁會淘汰,新的資料頁會被插入到列表的中間。
中間插入策略會把列表當成兩個子列表:
-
頭部用於儲存新的最新存取的資料頁。
-
尾部用於儲存舊的最少存取的資料頁
如下圖:Buffer Pool List
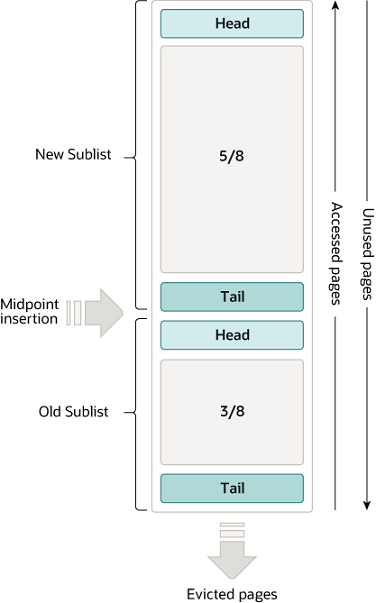
演演算法會將頻繁存取的資料頁放在新的子列表;最少存取的記錄存放在舊列表,並逐漸淘汰。
通常 LRU 演演算法按如下方式執行:
-
buffer pool 總量的 3/8 會分配給舊列表。
-
列表的中間包括新列表的尾部和舊列表的頭部。
-
當 InnoDB 讀入一個新的資料頁時,會先將其插入列表中間(舊列表的頭部)。
-
舊的子列表資料存取會改變其資料特性,並將其移動到新的子列表頭部(預讀操作除外)。
- 隨著資料庫操作的執行,buffer pool 中未被存取的頁資料會逐漸移動到列表的尾部,並淘汰。
通常情況下,被存取的資料會轉移到新的子列表,這樣就能在 buffer pool 中待更長的時間。一些特定的情景,如 mysqldump 操作導致的表掃描或者沒有附加 where 條件的 select 查詢會導致大量的資料寫入 buffer pool,並淘汰舊的記錄。但是這些新的記錄可能永遠不會被使用。
2、Change Buffer
change buffer 用於快取那些不在 buffer pool 儲存的二級索引頁資料變化。並最終會合併到 buffer pool(當這些頁資料被其它讀操作載入後)。
如下入示意 Change Buffer:
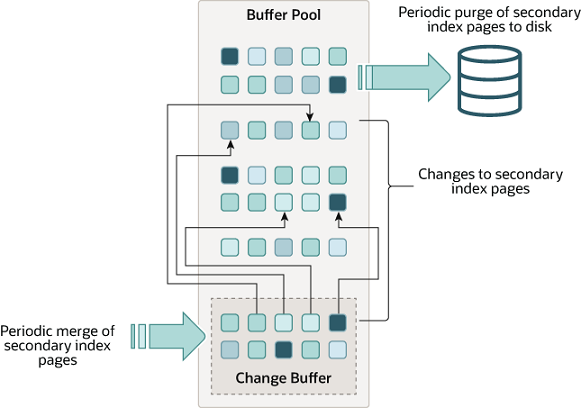
和聚簇索引不同的是,二級索引通常都非唯一,並且寫入順序隨機。同樣的,刪除和更新操作可能會影響不相鄰的多個索引頁資料。因此,在其它讀操作將受影響的索引頁數載入 bufer pool 時合併快取的索引變更,可以避免再次從磁碟隨機IO讀取二級索引頁資料。
purge operation 會週期性的把更新的頁資料批次寫入磁碟,這樣比即時單條寫入更有效率。
當涉及二級索引變更記錄比較多時,Change buffer 資料合併可能會花費幾個小時。在此期間,磁碟 IO 會增加,進而會影響磁碟密集型查詢。
在記憶體中,change buffer 會佔用一部分的 buffer pool 儲存使用。在磁碟裡,change buffer 是 system tablespace 的一部分,用以儲存資料庫伺服器關機時產生的索引變化資料。
3、 Adaptive Hash Index
自適應雜湊索引使得 InnoDB 支援基於記憶體的資料庫,通過 innodb_adaptive_hash_index 設定啟用。
基於當前的搜尋模式,雜湊索引使用索引鍵字首來構建。字首可長可短,根據實際查詢需求而定。
4、Log Buffer
儲存記憶體紀錄檔資料,用於磁碟紀錄檔檔案資料寫入。設定:innodb_log_buffer_size。預設大小 16MB。log buffer 的資料會週期性的刷盤。較大的 log buffer 有利於較大的事務紀錄檔資料寫入需求。對於執行大批次更新、寫入或刪除操作的事務可以適當調高 log buffer 以減少磁碟IO。
二、磁碟儲存結構
1、Index 索引
a)聚簇索引及二級索引
基於 InnoDB 引擎的表使用一種稱之為聚簇索引的特殊索引來儲存行資料。通常情況下,聚簇索引等同於主鍵索引。
- InnoDB 會使用表上定義的主鍵來作為聚簇索引,如果當前表沒有能夠作為主鍵的列(資料邏輯唯一非空的單列或者多列組合),則可以新增自增列作為非業務主鍵。
- 如果表未定義主鍵,則 InnoDB 會使用首個唯一索引(所有列非空)作為聚簇索引。
- 如果表既沒有主鍵也沒有合適的唯一索引,則 InnoDB 會為表建立一個隱藏的聚簇索引 GEN_CLUST_INDEX,該索引基於 InnoDB 為表自動新增的包含行ID值的列,所有表資料會基於該ID值排序。行ID值是一個6位元組數值,會隨著資料的插入單調遞增,因此基於此列排序的表在物理上保持著資料插入順序。
除了聚簇索引,其它的索引都是二級鎖索引,二級索引除了設定的索引列外,還包含主鍵,最終 InnoDB 都要通過主鍵來查詢聚簇索引裡的資料。
如果主鍵過長,那麼二級索引就會佔用更大的空間,所以,通常我們都建議設定較短的主鍵。
B 樹索引使用:
- 支援列 =、>、>=、<、<= 及 BETWEEN 操作。
- like 操作支援:like 後面的引數需要為常數並且不能以萬用字元起始。
//可以命中索引 SELECT * FROM tbl_name WHERE key_col LIKE 'Patrick%'; SELECT * FROM tbl_name WHERE key_col LIKE 'Pat%_ck%'; //無法使用索引 SELECT * FROM tbl_name WHERE key_col LIKE '%Patrick%'; SELECT * FROM tbl_name WHERE key_col LIKE other_col;
- 對於 is NULL 條件,如果條件列有索引,則查詢會使用到索引。
- 對於多列複合索引,如果要使用它們,則在每一個 and 條件分組裡都必須使用它們:
如下使用到了索引:
... WHERE index_part1=1 AND index_part2=2 AND other_column=3 /* index = 1 OR index = 2 */ ... WHERE index=1 OR A=10 AND index=2 /* optimized like "index_part1='hello'" */ ... WHERE index_part1='hello' AND index_part3=5 /* Can use index on index1 but not on index2 or index3 */ ... WHERE index1=1 AND index2=2 OR index1=3 AND index3=3; 如下未使用到索引 /* index_part1 is not used */ ... WHERE index_part2=1 AND index_part3=2 /* Index is not used in both parts of the WHERE clause */ ... WHERE index=1 OR A=10 /* No index spans all rows */ ... WHERE index_part1=1 OR index_part2=10
- 一些特殊情況,如優化器測算使用索引會需要存取表中大量的資料,那麼即使條件列命中了索引使用條件也不會使用索引。
b)InnoDB 索引物理結構
除了空間索引(基於 R-trees,用以組織儲存多維資料),InnoDB 索引都是基於 B-tree 結構。資料儲存於樹的葉子結點。
索引資料頁預設大小為 16KB,可以通過 mysql 範例初始化時的 innodb_page_size 引數來調整。
當向聚簇索引插入新的記錄時,InnoDB 會保留1/16頁空間用以應對將來可能的插入和更新。如果是順序插入,則索引頁空間會保持差不多15/16大小。如果是隨機的,則頁空間大小會在1/2 到 15/16之間。一般低於1/2(MERGE_THRESHOLD 設定)會觸發索引樹壓縮。
c)Sorted Index Builds
InnoDB 使用 bulk load 方式執行索引建立或重建,我們稱之為 Sorted index build(不支援空間索引)。
索引重建通常分為三步:
- 掃描聚簇索引,生成索引記錄並新增到 sort buffer。sort buffer 滿了之後,記錄會被排序並寫入一個臨時的中介檔案
- 隨著多個第一步這個過程寫入資料到臨時中介檔案,檔案裡的索引記錄會執行合併。
- 排序的索引記錄寫入 B-tree。
在 Sorted index builds 引入之前,B-tree 索引寫入使用特定的寫入API。首先需要開啟一個 B-tree 遊標並找到寫入位置,然後使用 optimistic 方式將索記錄寫入 B-tree。當遇到當前寫入頁滿時,optimistic 會執行相應的 B-tree 節點的分裂或者合併操作來滿足寫入空間需求。這種自上而下的構建方式存在一定的缺點,包括定址及經常性的節點分裂及合併成本。
Sorted index builds 基於自底而上的方式來構建索引。從 B-tree 每層最右側的葉子節點開始,基於索引記錄順序寫入。當一個節點頁寫滿,則向其父節點新增一個新的子節點用於新的寫入。
2、table space 表空間
| system table space |
用以儲存包括 InnoDB data dictionary、the doublewrite buffer、the change buffer 及 undo logs,也可以儲存使用者主動建立於此的表及索引資料。 可以有一個或多個資料儲存檔案,預設為一個 ibdata1,大小和數量可以通過 |
| File-Per-Table Tablespaces |
file-per-table tablespace 包括一張表的資料和索引,以單個資料檔案形式儲存在檔案系統。
file-per-table tablespace 資料檔案形式 table_name.ibd,儲存於 MySQL data 資料夾下。 優勢:
劣勢:
|
| General Tablespaces | 共用的 InnoDB 表空間。 |
| Undo Tablespaces | undo logs 儲存。 |
| The Temporary Tablespace | 非壓縮的,使用者建立的臨時表及磁碟上的內部臨時表儲存。 |
3、double buffer
具體介紹見前文連結:mysql 優化之 doublewrite buffer 機制
4、Redo Log
redo log 是一種基於磁碟的資料結構,用於修正資料庫崩潰恢復期間未完成事務造成的資料髒寫。
redo log 磁碟儲存資料檔案為 ib_logfile0 和 ib_logfile1,MySQL 以環形方式寫入。
設定修改:1、組態檔 my.cnf;2、大小 innodb_log_file_size;3、數量:innodb_log_files_in_group.
5、Undo logs
記錄單個事務中的一系列記錄變更,用以恢復對聚簇索引記錄的最新變更。如果有其它事務基於一致性讀操作需要檢視原始資料,可以從 undo log 記錄裡查詢。
6、InnoDB Data Dictionary
包括一系列系統表,儲存包括表、索引及表列等相關後設資料,物理儲存在系統表空間。由於一些歷史原因,data dictionary metadata 部分儲存在 InnoDB 表空間檔案 (.frm files)。