圖計算引擎分析--GridGraph
作者:京東科技 李永萍
GridGraph:Large-Scale Graph Processing on a Single Machine Using 2-Level Hierarchical Partitioning
圖計算框架
圖計算系統按照計算方式劃分可分為:單機記憶體圖處理系統,單機核外圖處理系統,分散式記憶體圖處理系統,分散式核外圖處理系統。本文將詳細介紹單機核外圖處理系統GridGraph。
GridGraph論文分析
單機核外圖處理系統
單機記憶體圖處理系統受限於記憶體空間和單機算力,能夠解決的圖規模有限。分散式記憶體圖處理系統理論上可以隨著叢集規模的增大進而解決更大的圖規模,但叢集間的網路頻寬問題,負載不均衡,同步開銷大,容錯開銷和圖分割挑戰也愈變明顯。無論是單機還是分散式,記憶體式圖處理系統能夠處理的圖規模都是有限的。因此想要使用更少的資源解決更大的圖規模,可以使用單機核外圖處理系統。單機核外圖處理系統使用磁碟順序讀寫進行資料置換,能夠在有限的記憶體中計算更大規模的圖。單機核外圖處理系統在最大化利用磁碟順序讀寫,在選擇排程和同非同步計算模式等方面做出了重要探索。
GridGraph
GridGraph是一種單機核外圖處理系統,在大規模圖處理系統中充分利用磁碟讀寫,在有限記憶體中高效完成大規模圖計算。
GridGraph充分利用磁碟大容量,解決單機記憶體有限時實現大規模圖計算問題。GridGraph採用Streaming-Apply方式減少計算中的IO 請求數量,通過檔案調入順序減少不必要的io開銷。 同時GridGraph也利用順序讀和順序寫的特點,儘可能的較少硬碟的寫操作。
主要貢獻
GridGraph的主要貢獻有:
1、基於邊列表快速生成一種新的圖表示形式--網格劃分。網格劃分是一種不同於鄰接矩陣和鄰接連結串列的表示形式,網格劃分不需要將index排序,網格的邊block可以由未排序的邊列表轉換而來,資料前置預處理開銷小,可應用於不同的演演算法和不同的機器。
2、2-level hierarchical partitioning 使用兩層分割區劃分模式,該模式不僅適用於核外,在記憶體中同樣有效。
3、提出streaming-apply模式,以提高IO。通過雙滑動視窗(Dual sliding windows)保證頂點存取的區域性性。
4、提供靈活的點邊流式介面函數,通過使用者自定義過濾函數來跳過非活躍頂點(活躍頂點:bitmap中該頂點index的狀態為1)或非活躍邊的計算。對於活躍頂點集隨著收斂而縮小的迭代演演算法,這種方法顯著提高了演演算法的效能。
Grid Representation網格劃分
為了在有限的記憶體中完成大規模圖計算,並嚴格控制記憶體消耗,需要將圖進行網格劃分。
1、頂點集劃分成P個均勻的chunk。
2、邊集劃分在P*P個block中,行表示源頂點,列表示目的頂點。
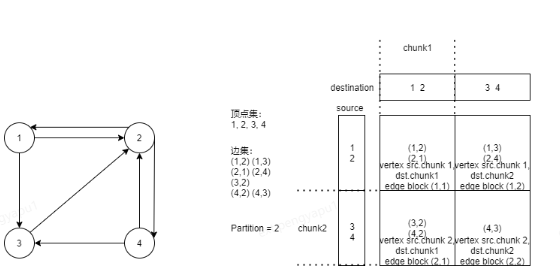
The Grid Format 網格格式
GridGraph partition預處理方式如下:
1、主執行緒從原始的無序邊集中讀取邊,讀取到一批邊後,將這批邊資料加入佇列中。(根據磁碟頻寬,一般選擇24M做為這批邊的大小)
2、每個工作執行緒從佇列中獲取任務,計算邊所屬的block,將邊加入到邊block檔案中。為了提高I/O吞吐量,每個工作執行緒維護每個block的本地緩衝區,一旦緩衝區滿就重新整理到檔案。
分割區過程結束後,GridGraph就可以進行計算了。然而,由於現實世界圖的不規則結構,一些邊block可能太小,無法在HDD上實現大量的連續頻寬。因此,可能由於頻繁的磁碟尋道,有時無法實現順序頻寬。為了避免這種效能損失,GridGraph需要一個額外的合併階段,以便在基於HDD的系統上更好地執行,該階段將邊block檔案逐個追加到一個大檔案中,並在後設資料中記錄每個塊的起始偏移量。
不同於GraphChi的shard分片模式,GridGraph不需要對邊block排序,減少了IO和計算開銷,我們只需要在磁碟上讀寫一次邊,而不是在GraphChi中多次遍歷邊。
而對於X-Stream來說,X-Stream不需要顯式的預處理。根據流分割區,邊被打亂到幾個檔案。不需要排序,分割區的數量非常少。對於許多頂點資料都能裝進記憶體的圖,只需要一個流分割區。然而,這種劃分策略使得它在選擇排程中效率低下,這在很大程度上影響了它在許多迭代演演算法中的效能,因為在某些迭代中只使用了一部分頂點。(GraphChi和X-Stream都是單機核外圖計算系統,在此不贅述。)
何為選擇排程?選擇排程是將圖資料檔案(一般是邊檔案)劃分為多個block並按順序編號,設定一個bitmap記錄所有block的存取狀態,若是需要存取則將bitmap中index為block編號的狀態置為1,在排程時跳過狀態為0的block,選擇狀態為1的block從磁碟置入記憶體中進行計算。若是bitmap為空,則預設所有block都需要參與計算,則將block按序從磁碟置入記憶體。block的大小決定了選擇排程的差異,block越大,包含的資料越多,block置換的概率越低,選擇排程越好。反之,block越小,包含的資料越少,計算時需要置換block的概率越高,選擇排程越差。
GridGraph完成預處理的時間非常短。此外,生成的網格格式可用於執行在同一圖上的所有演演算法。通過分割區,GridGraph能夠進行選擇性排程,減少對沒有活躍邊的邊塊的不必要存取。這在許多迭代演演算法(如BFS和WCC)中貢獻很大,因為其中大部分頂點在許多迭代中都是不活動的。
記憶體(In-memory)圖計算系統將全都資料讀取到Memory記憶體中,使用到系統中的Cache(快取)和Memory(記憶體)來完成圖計算過程,核外(Out-of-core)圖計算系統則將資料儲存到Disk磁碟中,計算時再將所需資料置換到Memory(記憶體)中,為了緩解CPU和Memory之間的速度差異,通常會將資料儲存至Cache快取中。磁碟儲存空間>記憶體儲存空間>快取儲存空間。
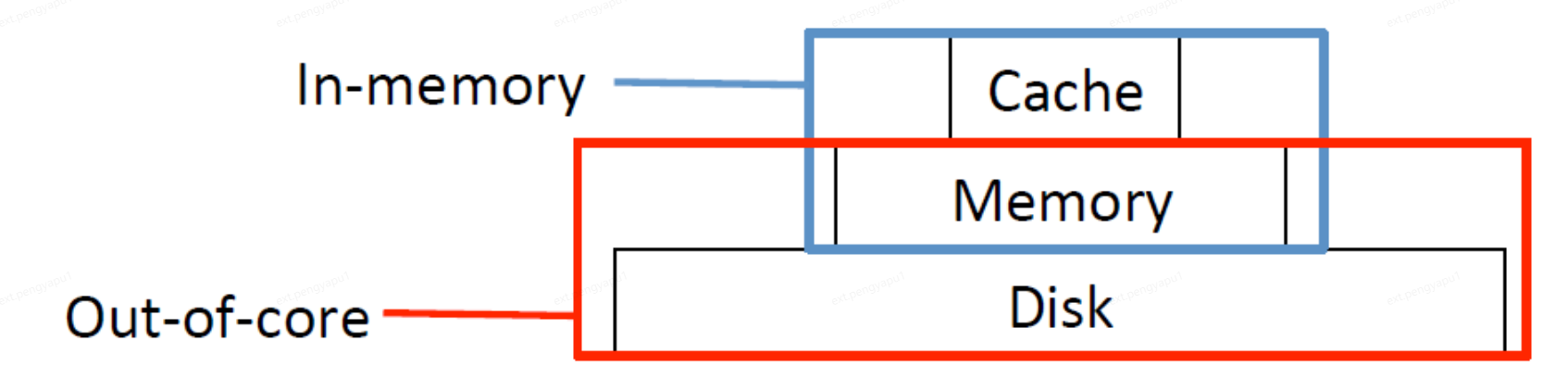
那麼如何選擇Partition呢?
粒度越細(即P值越大),預處理時間越長,P越大,每一個chunk能表示的範圍越廣,那麼每個block能儲存的邊資料越多,頂點資料的存取區域性性越好,block置換概率越低,選擇性排程潛力就越大。因此,在劃分時,P越大越好。目前,我們暫時選擇P的最大值,這樣頂點資料可以適應最後一級快取。那麼P的最小值可以這樣設定:
(V/P)*U<=C<=>P>=C/UV
其中V是圖的頂點數,C是最後一級cache快取的大小,U是每個頂點的大小。(V/P)表示chunk中可表示的頂點範圍,(V/P)*U則表示每個chunk的大小,為了適應最後一級快取,能夠一次將一個chunk的所有資料放入最後一級快取中,則chunk的大小應小於等於C,公式進行變換得到P的最小值為C/UV.
這種分割區方式不僅表現出良好的效能(特別是在記憶體情況下),而且節省了很多的預處理成本。
The Streaming-Apply Processing Model
GridGraph使用流應用處理模型,在該模型中只需要讀取邊一次,並且只需遍歷一次頂點即可完成寫I/O總量。
GridGraph提供了兩個流式處理常式分別處理頂點(Algorithm1)和邊(Algorithm2):

F是一個可選的使用者自定義函數,它接受頂點作為輸入(StreamVertices時是當前頂點,StreamEdges時是block中每一條邊的源頂點),並且返回一個布林值來指示流中是否需要該頂點。當演演算法需要選擇性排程用於跳過一些無用的流時通常與點陣圖一起使用,點陣圖可以緊湊地表示活動頂點集。
Fe和Fv是使用者自定義的描述流處理的函數,Fe接受一個邊做為輸入,Fv接受一個頂點做為輸入,返回一個R型別的值,返回值被累加,並作為最終結果提供給使用者。該值通常用於獲取活躍頂點的數量,但不限於此用法,例如,使用者可以使用這個函數來獲得PageRank中迭代之間的差異之和,以決定是否停止計算。
GridGraph將頂點資料儲存在磁碟上。使用記憶體對映機制(將頂點資料檔案通過mmap記憶體對映機制對映到記憶體中)來參照檔案中的頂點資料,每個頂點資料檔案對應一個頂點資料陣列。因此存取頂點資料檔案就像存取記憶體中的陣列一樣,並簡化了程式設計模型:開發人員可以將其視為普通陣列,就像它們在記憶體中一樣。
以PageRank為例,我們來看看GridGraph是如何實現演演算法的。
PageRank是一種連結分析演演算法(Algorithm3),計算圖中每個頂點的數值權重,以測量其在頂點之間的相對重要性。初始所有頂點的PR值都是1,在每次迭代中,每個頂點向鄰居傳送自己的貢獻,即當前PR值除以它的出度。每個頂點將從鄰居收集到的貢獻進行彙總,並將其設定為新的PR值。當均值差達到某個閾值時,演演算法收斂。

Dual Sliding windows 雙滑動視窗模式
GridGraph流式讀取每個block的邊,當block在第i行第j列時,和這個block相關的頂點資料也落在第i行第j列的chunk中,每個block都包含兩個頂點chunk,source chunk(源頂點chunk)和destination chunk(目的頂點chunk)。
通過P的設定,使得block足夠小,能夠將一個block放入最後一級快取中,這樣在存取與block相關的頂點資料時,可以確保良好的區域性性。
根據更新模式,block的存取順序可以是面向行或面向列的。假設頂點狀態從源頂點傳播到目標頂點(這是許多應用程式中的典型模式),即源頂點資料被讀取,目標頂點資料被寫入。由於每個邊block的列對應於目標頂點塊,需要對目標頂點塊進行寫操作,在這種情況下優先採用面向列的存取順序。當目的頂點所在block被快取在記憶體中時,GridGraph從上到下流向同一列中的block,因此昂貴的磁碟寫操作被聚合和最小化。特別是對於SSD系統來說,這是一個非常重要的效能,寫入大量資料寫效能會相應下降。另一方面,由於SSD有寫入週期的上限,因此儘可能減少磁碟隨機寫入以實現理想的永續性是很重要的。

以PageRank為例,我們來看看GridGraph是如何使用雙滑動視窗對頂點資訊進行更新。讀視窗(從源頂點資料中讀取當前頂點的PageRank值和出度)和寫視窗(對目標頂點的新PageRank值的貢獻進行累加)作為GridGraph流沿block以面向列的順序滑動。
1、初始化,每個頂點初始的PR值都為1
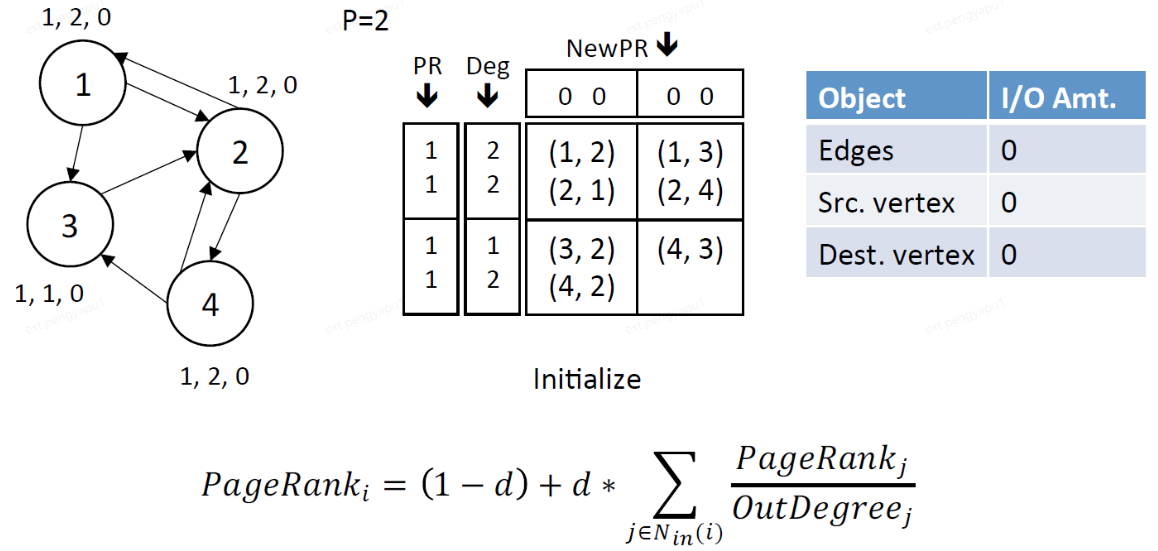
2、Stream edge block(1,1),此時src.chunk 1和dest.chunk 1都載入進記憶體中
讀視窗:讀取src.chunk 1的PR和Deg
寫視窗:寫dest.chunk 1的NewPR
IO總量:讀取block中2條邊,讀取src.chunk 1中的頂點(1,2),讀取dest.chunk 1中的頂點(1,2)
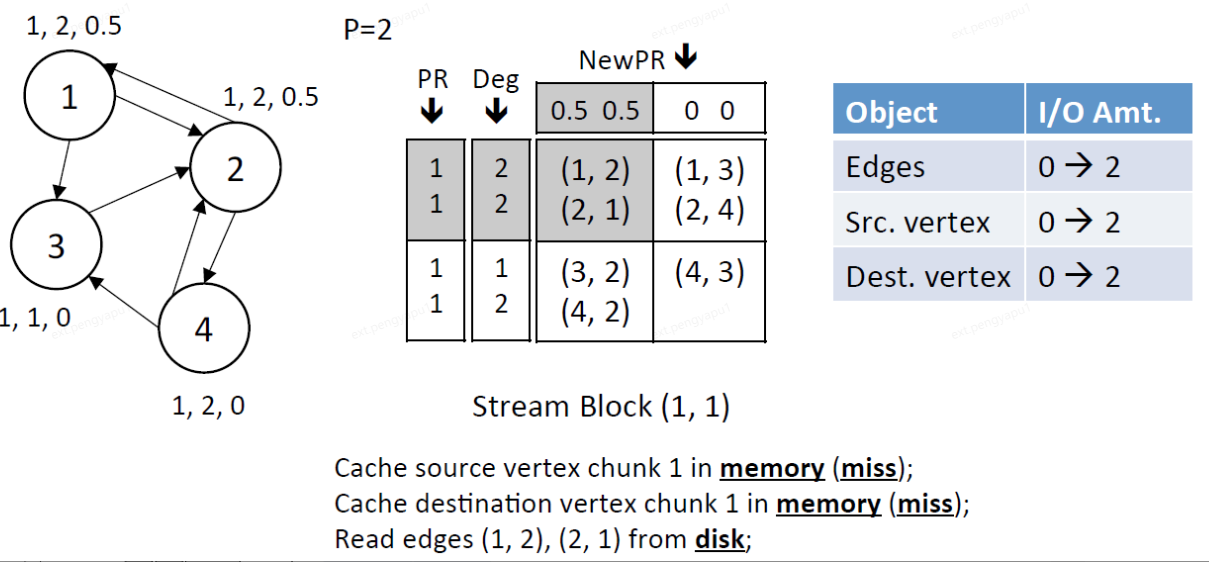
3、Stream edge block (2,1),此時dest.chunk 1在記憶體中,將src.chunk 2也載入進記憶體中
讀視窗:讀取src.chunk 2的PR和Deg
寫視窗:寫dest.chunk 1的NewPR
IO總量:讀取block中2條邊,讀取src.chunk 2中的頂點(3,4)
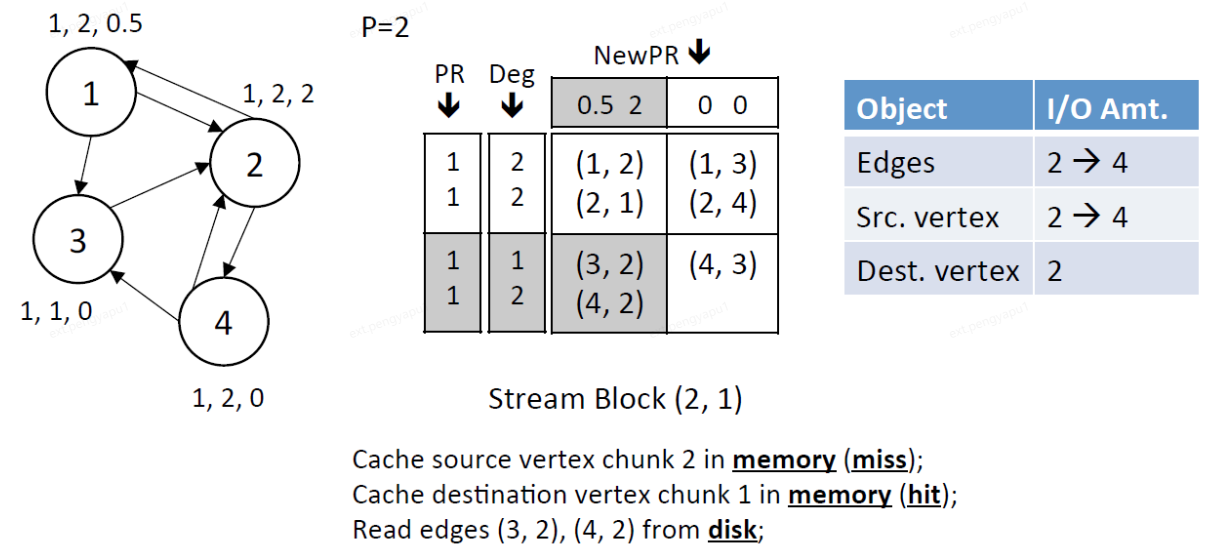
4、Stream edge block (1,2),dest.chunk 1已經全部更新完成,將更新後的dest.chunk1寫回磁碟種,將src.chunk 1和dest.chunk 2載入進記憶體中
讀視窗:讀取src.chunk 1的PR和Deg
寫視窗:寫dest.chunk 2的NewPR
IO總量:讀取block中2條邊,將dest.chunk 1中的頂點(1,2)的結果寫入磁碟,讀取src.chunk 1中的頂點(1,2),讀取dest.chunk 2中的頂點(3,4)
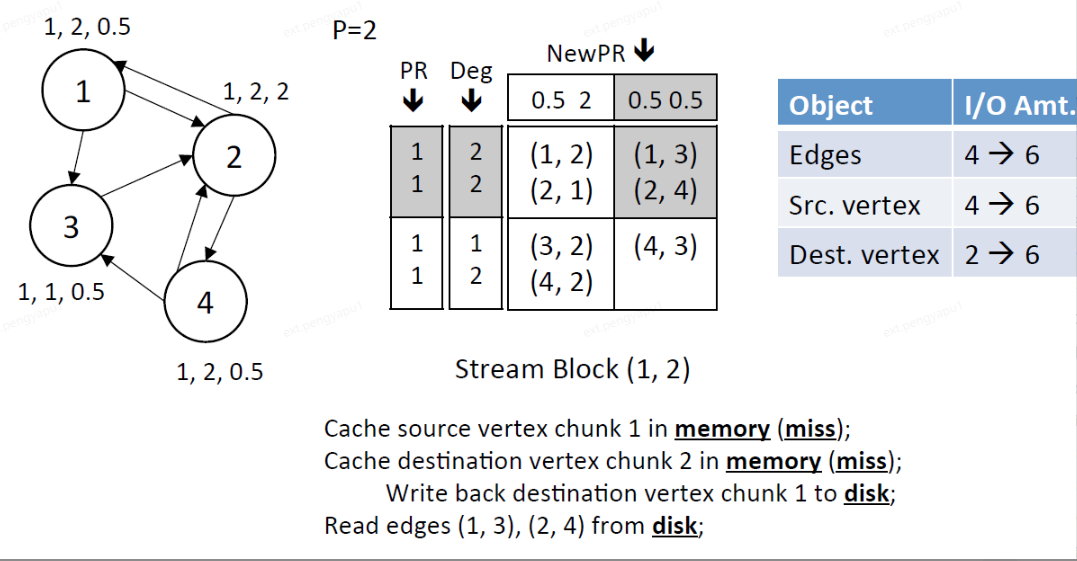
5、Stream edge block (2,2),此時dest.chunk 2在記憶體中,將src.chunk 2也載入進記憶體中
讀視窗:讀取src.chunk 2的PR和Deg
寫視窗:寫dest.chunk 2的NewPR
IO總量:讀取block中1條邊,讀取src.chunk 2中的頂點(3,4)
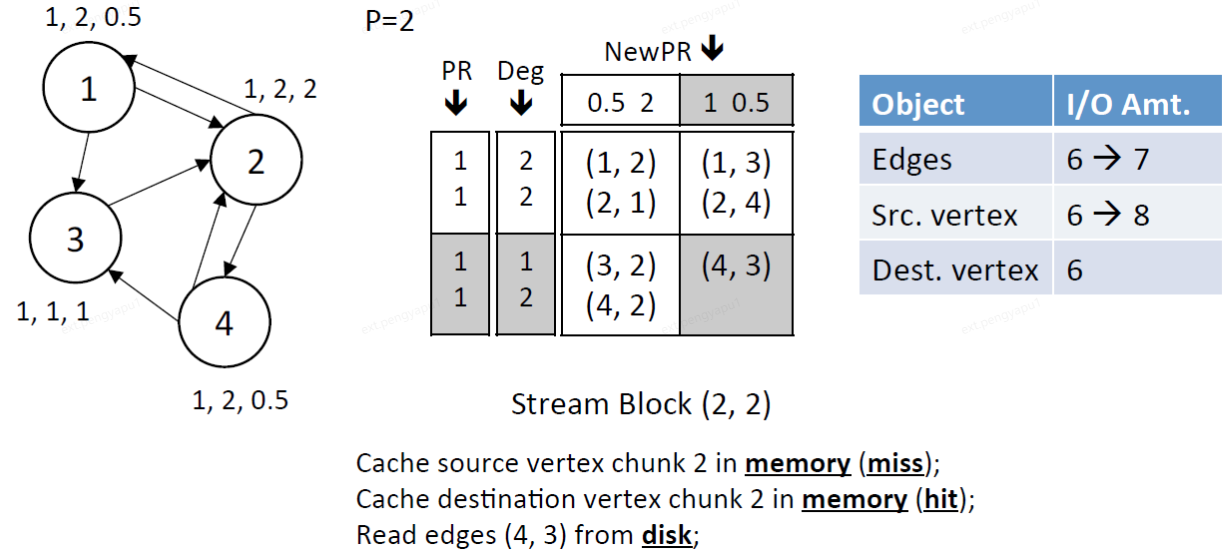
6、完成dest所有chunk的遍歷,將dest.chunk 2更新後的結果寫入磁碟中。
IO總量:將dest.chunk 2中的頂點(3,4)的結果寫入磁碟中。
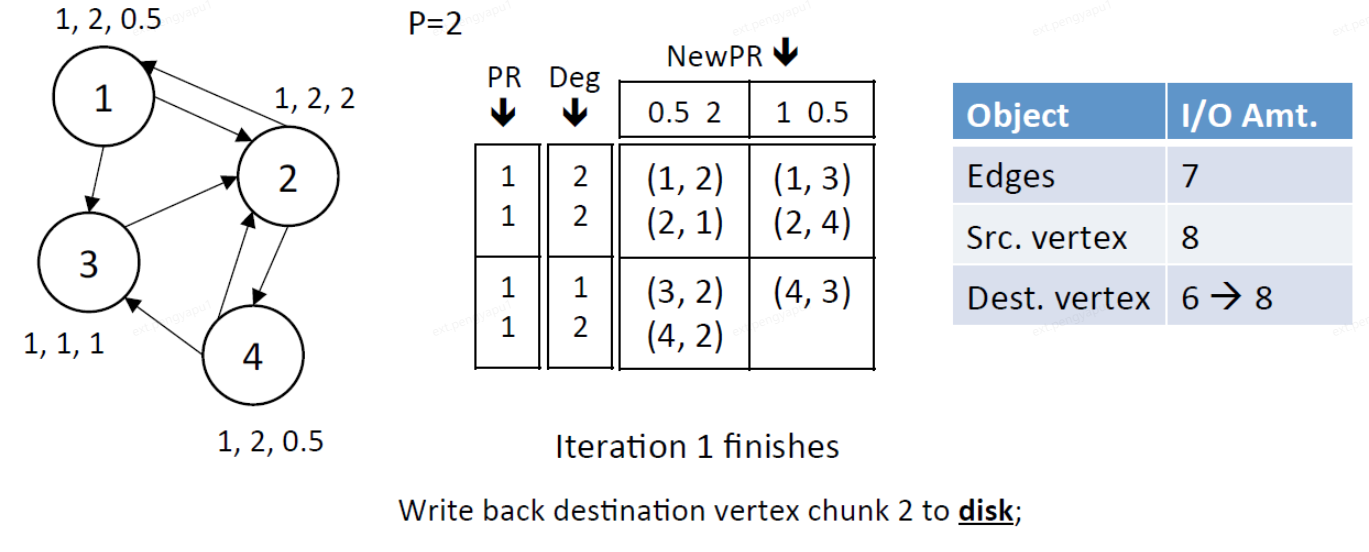
在上面的一次流應用迭代中給出了網格圖的I/O分析,其中所有的邊和頂點都被存取。以面向列的順序存取邊block為例:所有邊被存取一次,源頂點資料被讀取P次,而目標頂點資料被讀寫一次。在一次完整迭代並收斂中使用的IO:
E+(2+P)*V
E:表示讀取所有邊
2:讀取和寫入目標頂點的資料
P:讀取每個P中源頂點資料
通過對邊的唯讀存取,GridGraph所需的記憶體非常緊湊。事實上,它只需要一個小的緩衝區來儲存正在Stream的邊blocl,以便頁快取可以使用其他空閒記憶體來儲存更多的邊block,當活躍邊block變得足夠小以適合記憶體時,這是非常有用的。這種Streaming-Apply-Processing-Model流式應用模型的另一個優點是它不僅支援經典的BSP模型,而且還允許非同步更新。由於頂點更新是即時的,更新的效果可以通過跟蹤頂點的遍歷來獲得,這使得許多迭代演演算法收斂得更快。由此可看出:P應該是使頂點資料放入記憶體的最小值。因此,更小的P應該是最小化I/O量的首選,這似乎與上面我們所說P越大越好,更大的網格分割區原則相反。
Selective scheduling 選擇排程
前面我們已經解釋過什麼是選擇排程,即跳過不活躍的邊block。在Stream函數中的由F傳入點陣圖,由此跳過不活躍的邊block。
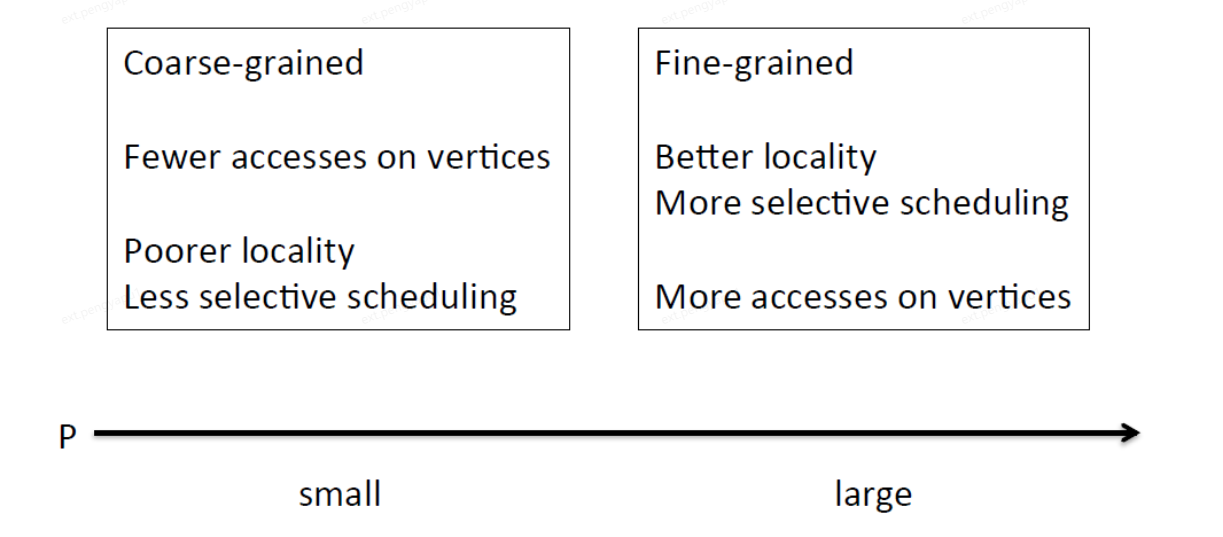
P越小,粒度越粗,存取頂點的次數更少,更差的區域性性,選擇排程更差
P越大,粒度越細,更好的區域性性,選擇排程更好,存取頂點的次數更多
為了解決這個難題,在邊網格上應用了二級分割區,以減少頂點的I/O存取。
2-level hierarchical partitioning
在P*P的網格中再進行一層網格劃分,第二層網格有Q*Q個邊網格。將Q*Q的分割區應用在P*P的網格中。
Q的選擇應滿足:
(V/Q)*U <= M
M是給定的記憶體容量。
在前面我們提到,P的選擇是為了將頂點資料放入容量遠小於記憶體的上一級快取中,因此P應該遠大於Q。
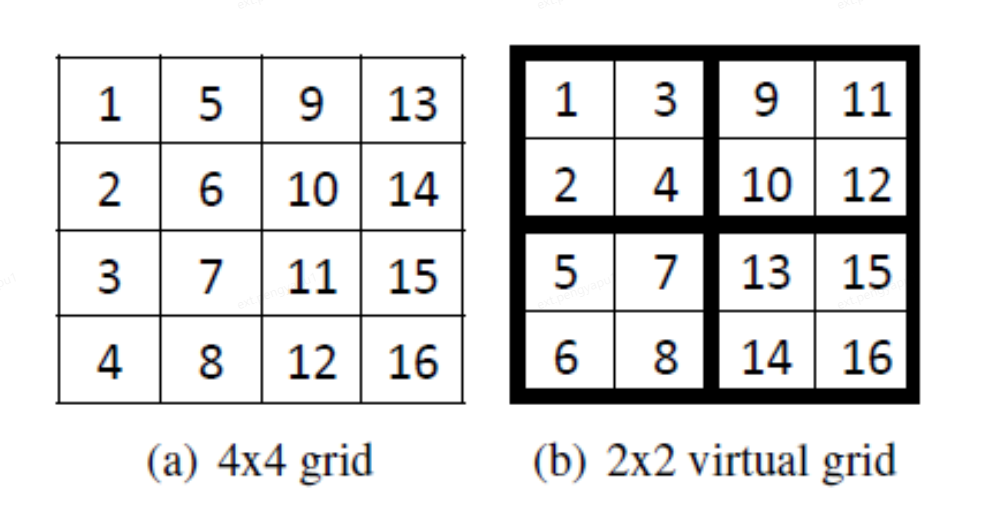
整個網格被分成4個大塊,每個大塊包含4個小塊。每個塊內的數位表示存取順序。在原始的4×4分割區中使用了精確的面向列的存取順序。在應用了二級分割區後,P:2×2 變成 Q:4×4分割區之後,我們以面向列的順序存取粗粒度(大)塊,在每個大塊中,我們存取細粒度的塊(小)塊以列為導向的順序。這種2級分層分割區不僅提供了靈活性,而且還提高了效率,因為高階分割區(第二級分割區)是虛擬分割區,GridGraph能夠利用較低階別分割區(第一級分割區)的結果,因此不會增加更多的實際開銷。並且可以使用P網格劃分的結果進行選擇排程。
總結
GridGraph定義了一種新的圖表示形式:網格劃分,用於適應有限的記憶體;使用雙視窗模式減少IO存取的總量,特別是寫IO;使用選擇排程減少掉無用的IO;使用2級分割區劃分方式保證了P儘可能大的同時減少IO存取。GridGraph在有限的記憶體中,並提高IO效率,高效的完成了核外圖計算過程。
GridGraph原始碼分析
原始碼地址:https://github.com/thu-pacman/GridGraph
資料預處理模組
將原始二進位制檔案處理成grid格式的block檔案
我們來看看block檔案是如何劃分處理的:
從input檔案中遍歷讀取IOSIZE的資料放入buffers[cursor]中,tasks記錄當前當前遊標的位元組數<cursor, bytes>,在threads中獲取tasks中的cursor和bytes,根據cursor讀取buffers中的資料,將buffers[cursor]中的資料根據src和dst所屬的partition,放入local_buffer[i][j]中,將local_buffer[i][j]的資料分別寫入block[i][j]檔案中。如下圖所示:
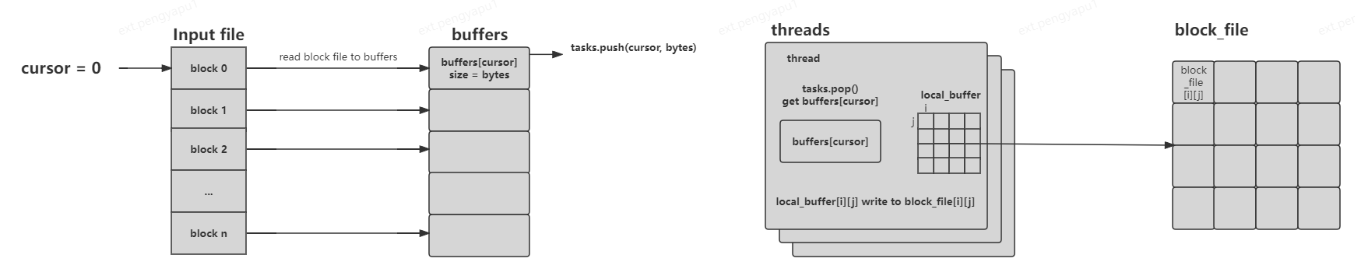
程式碼位於:tools/preprocess.cpp
1、開啟檔案讀取資料,將資料加入task處理,在這裡,buffers的定義是全域性的,tasks儲存cursor和buffers資料大小。
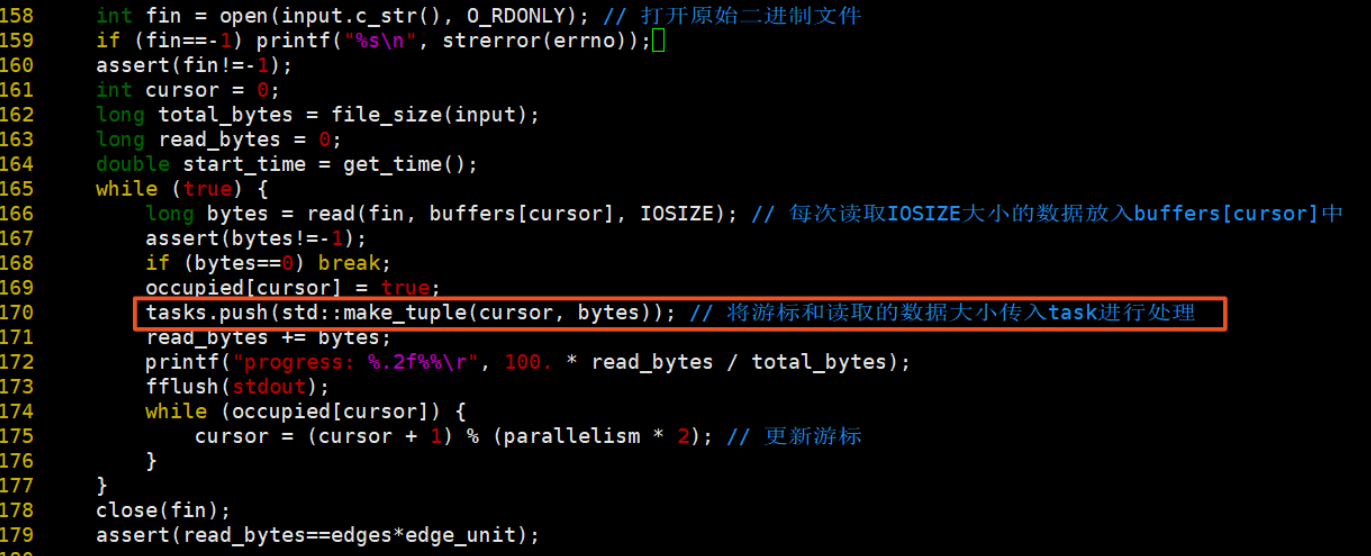
2、那麼我們來看看tasks是什麼,tasks是一個佇列,儲存當前遊標和資料大小。grid_buffer_size = 12*8*8,12表示<4 byte source, 4 byte destination, 4 byte float typed weight>,8*8表示每次讀取到64byte的資料時寫一次磁碟,是個magic number。
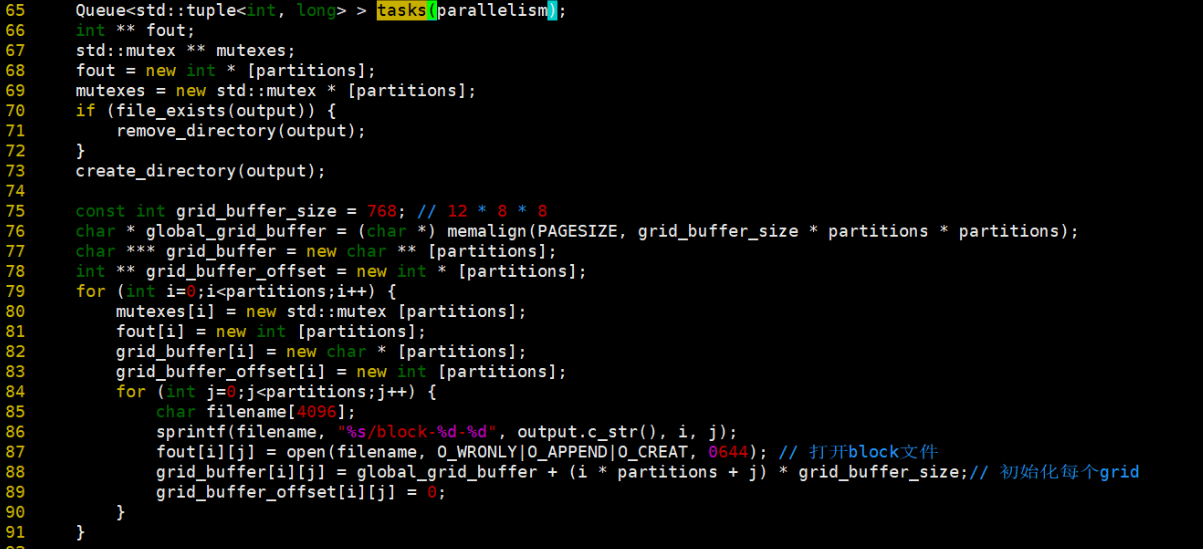
3、真正進行資料處理的是threads的任務。每個thread處理一個buffers[cursor]的資料。
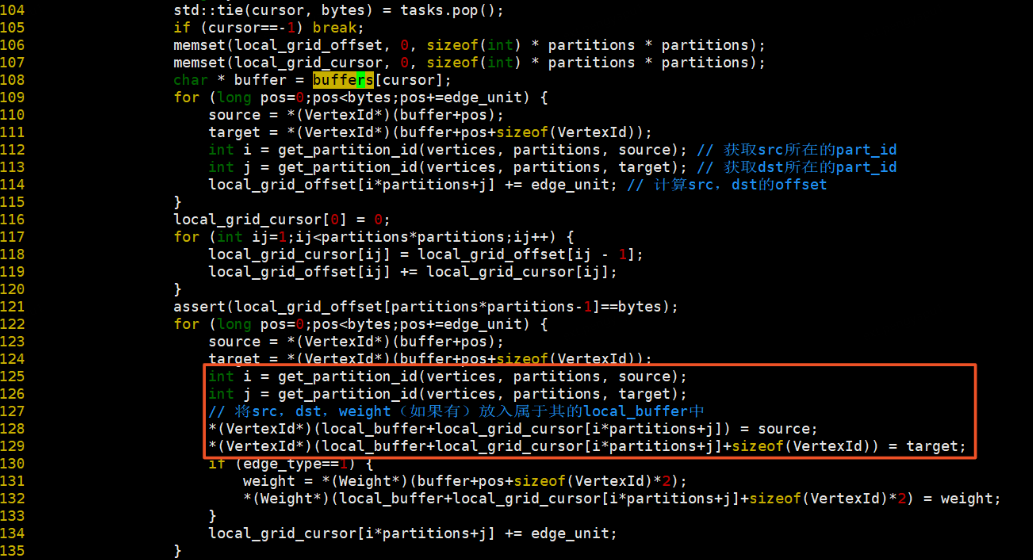
將local_buffer的資料寫入對應的block檔案中
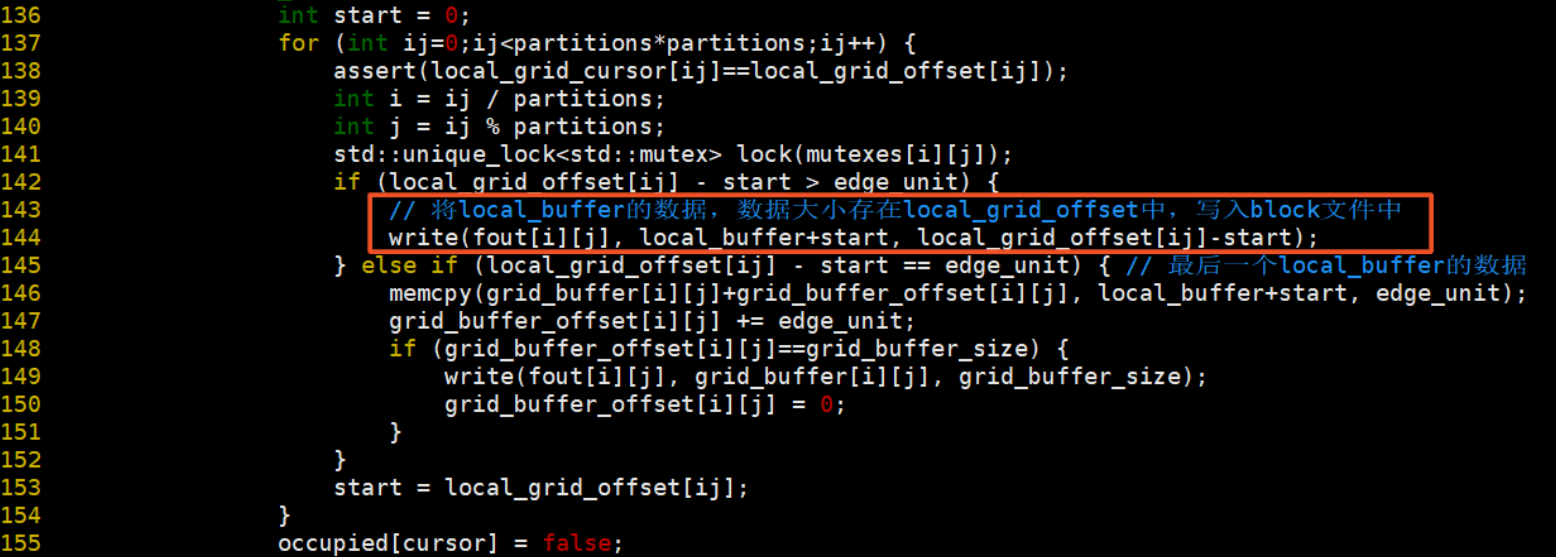
4、生成column檔案,將所有block檔案按照列遍歷方式儲存到column檔案中,並將每個block檔案的大小儲存至column_offset檔案中。
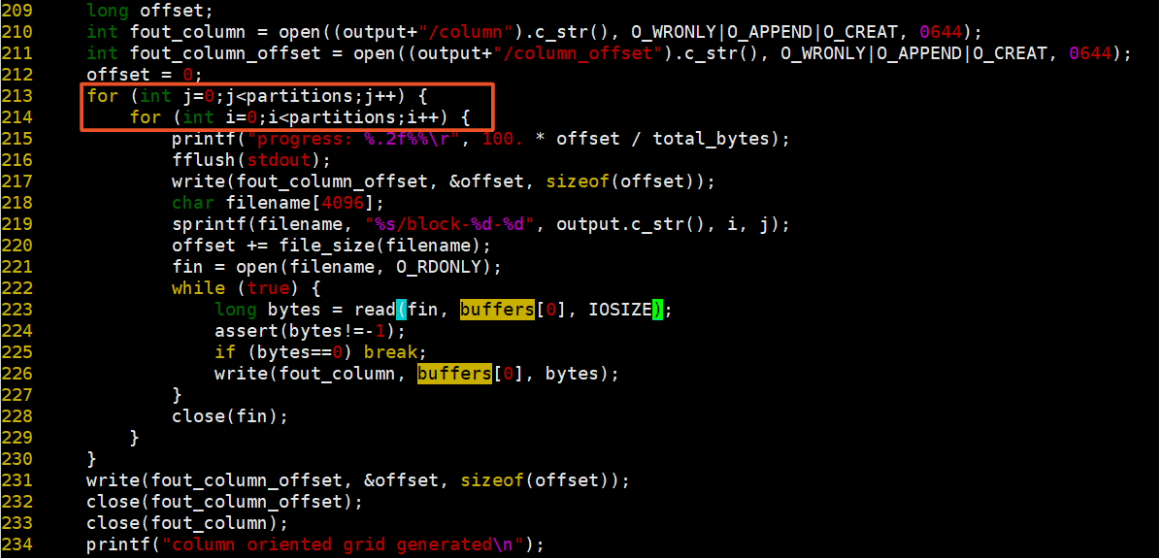
5、同理生成row檔案,按照行遍歷方式讀取block檔案寫入row檔案中,並記錄offset。

6、最後將處理好的資料資訊(是否含有權重,頂點數,邊數,partition數)寫入meta檔案中。

執行grid程式碼後,會生成P*P個block檔案,一個column檔案、row檔案、column_offset、row_offset及meta檔案。
Graph實現
程式碼位於:core/graph.hpp
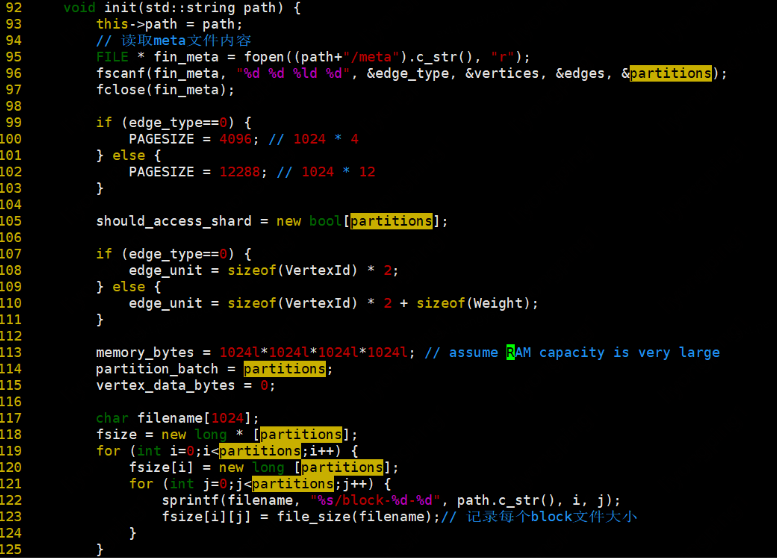
init
空間初始化,並讀取meta資訊和column_offset、row_offset的資料,並記錄每個block檔案大小
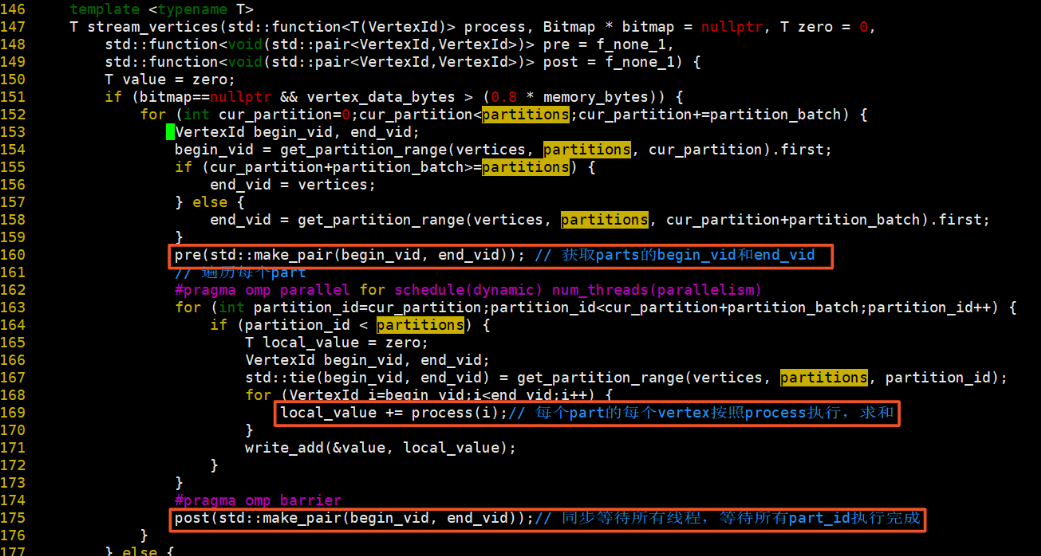
stream_vertices:
如果bitmap為空,並且頂點資料位元組總數(頂點資料位元組總數初始化為0,可在演演算法實現時設定,一般為頂點總數頂點大小)大於0.8記憶體位元組數,先獲取partitions的begin_vid和end_vid,再遍歷每一個partition,每個partition中的每個vertex按照process執行,將返回值求和相加。最後等待所有partition執行結束,得到begin_vid和end_vid。
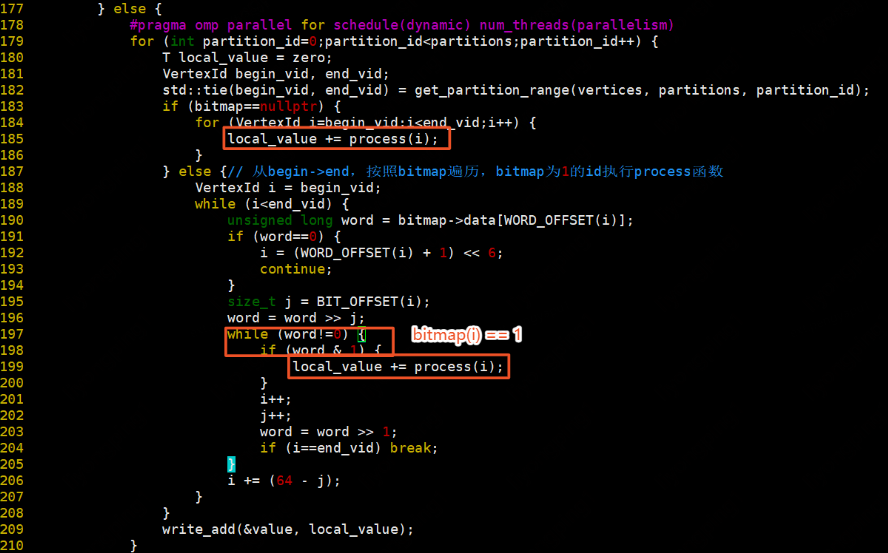
如果bitmap不為空或者頂點資料位元組總數小於等於0.8*記憶體位元組數,則遍歷每一個partition,獲取每個partition的begin_vid和end_vid。如果bitmap為空,則遍歷partition中的所有頂點,按照process執行,返回值相加。否則,從begin_vid開始,按照bitmap遍歷,bitmap為1的vid執行process,返回值相加。
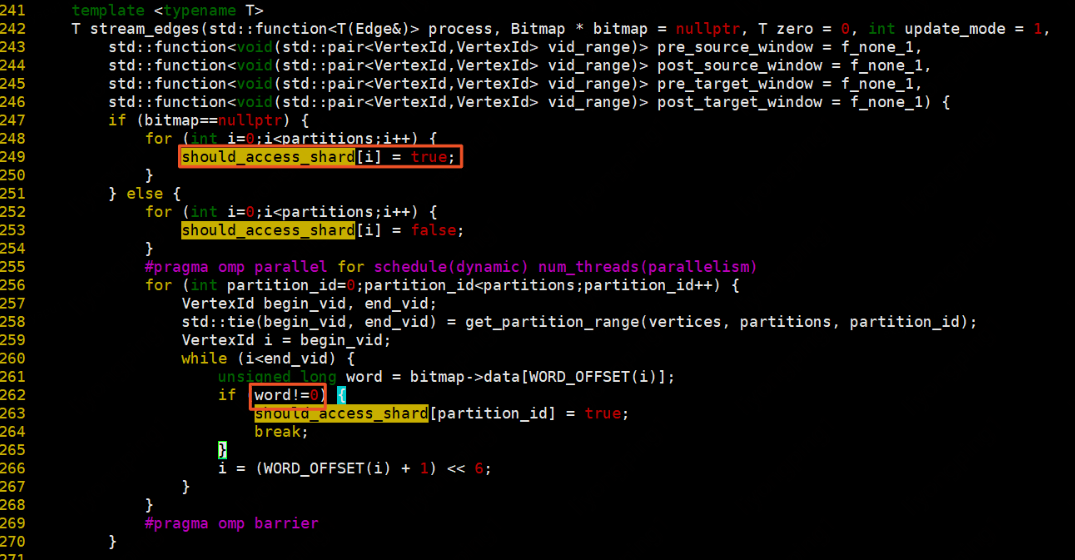
stream_edges:
根據bitmap決定需要遍歷的partition,如果bitmap為空,則所有partition都要遍歷,bitmap不為空根據partition中是否包含bitmap中的vid,包含則該partition需要遍歷。
統計所有需要遍歷的partition的檔案總大小
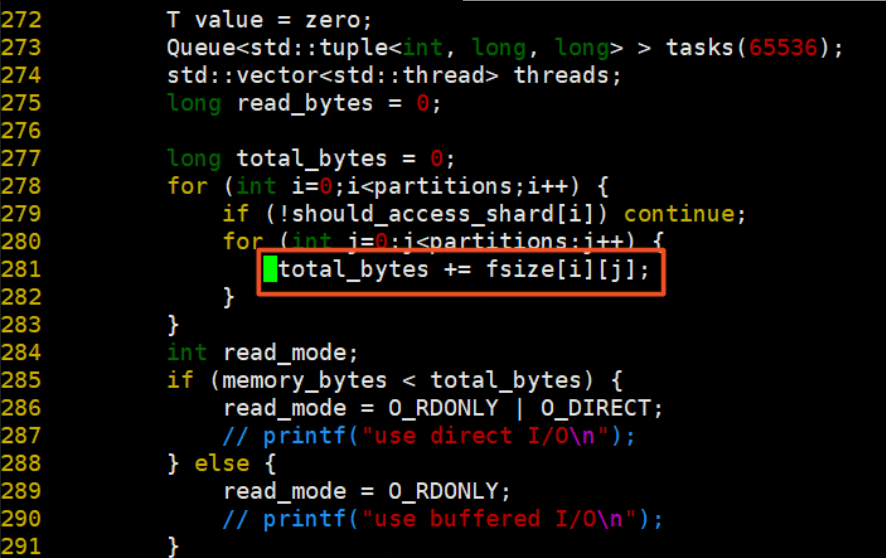
預設update_mode=1,若update_mode=0則為行更新模式(行主序更新),update_mode=1則為列更新模式(列主序)。資料準備階段:
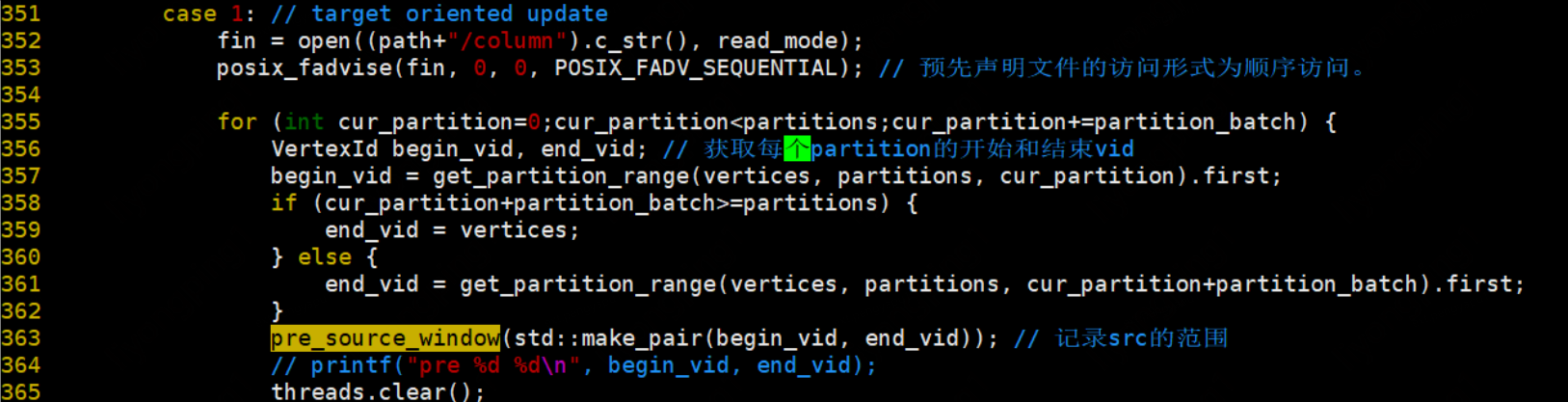
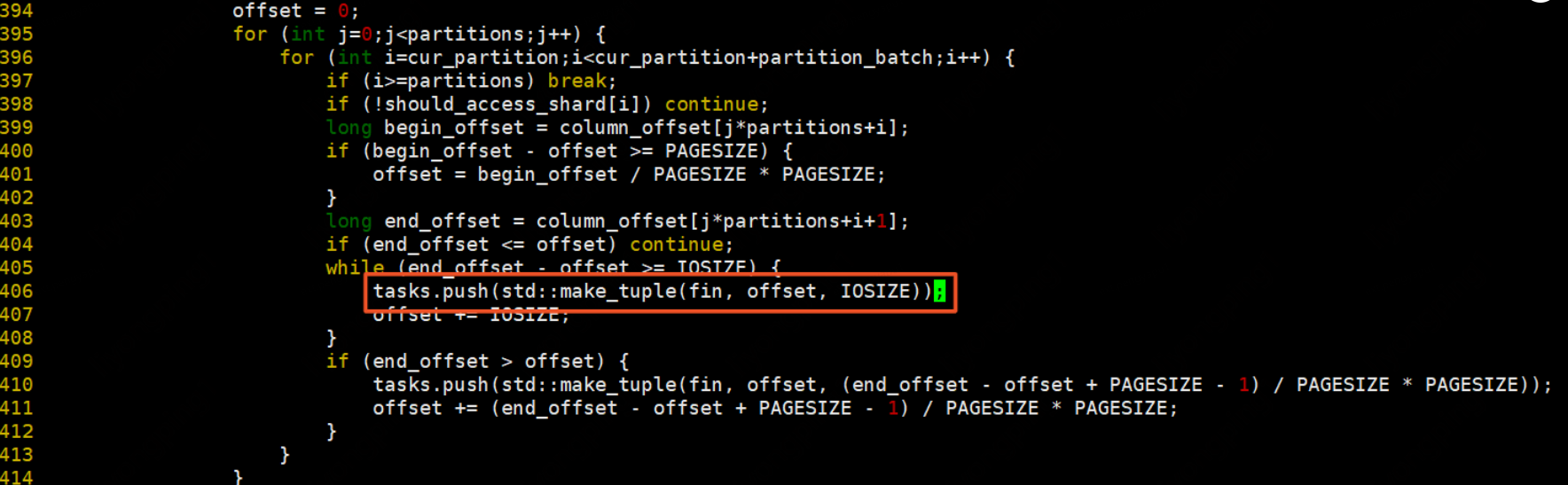
遍歷需要存取的分割區,分割區存取方式為:列不變,行從小到大進行遍歷,行遍歷完後列再向右移。每次讀取分割區中IOSIZE大小的資料,最後不夠IOSIZE則讀取PAGESIZE大小的資料
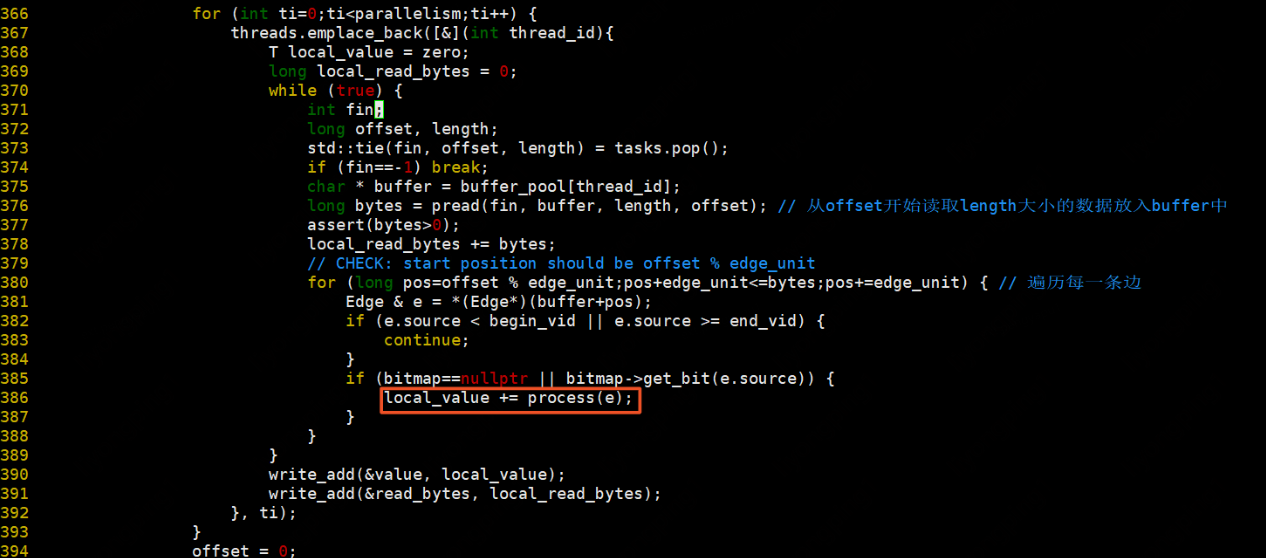
每條邊按照process的方法執行操作
若是行主序,實現則如下:按照行遍歷方式讀取需要遍歷的partition,每次處理IOSIZE大小的資料
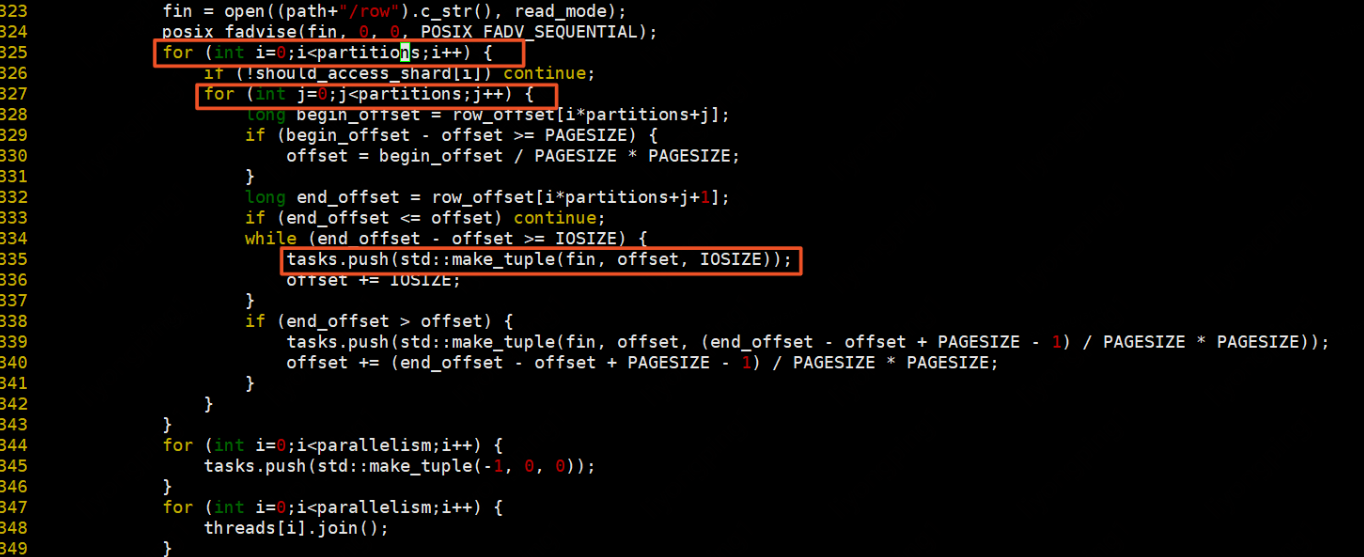
資料處理方式則是讀取row檔案,從offset開始讀取length的資料放入buffer中,然後遍歷每一條邊,每條邊按照process執行。
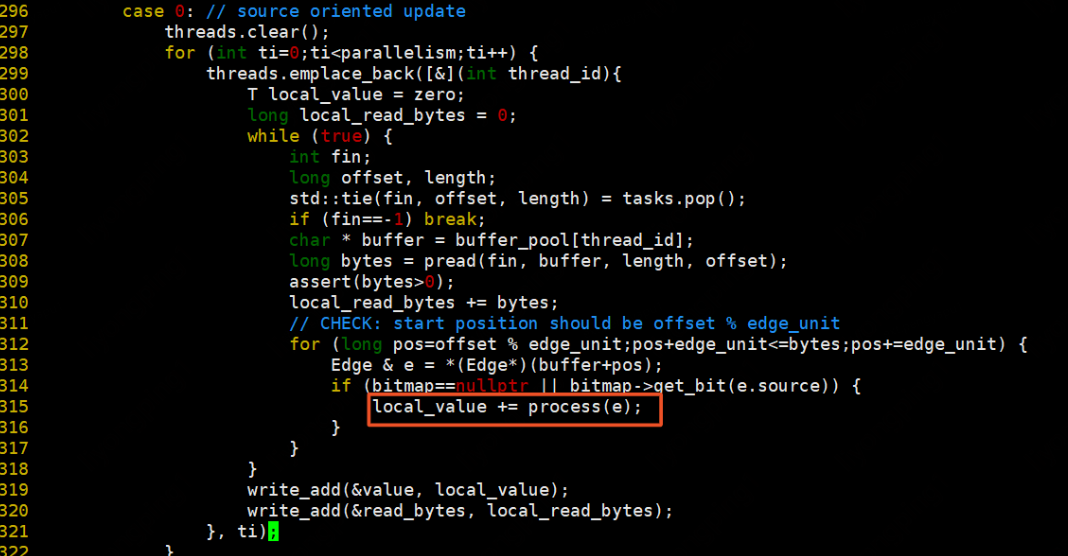
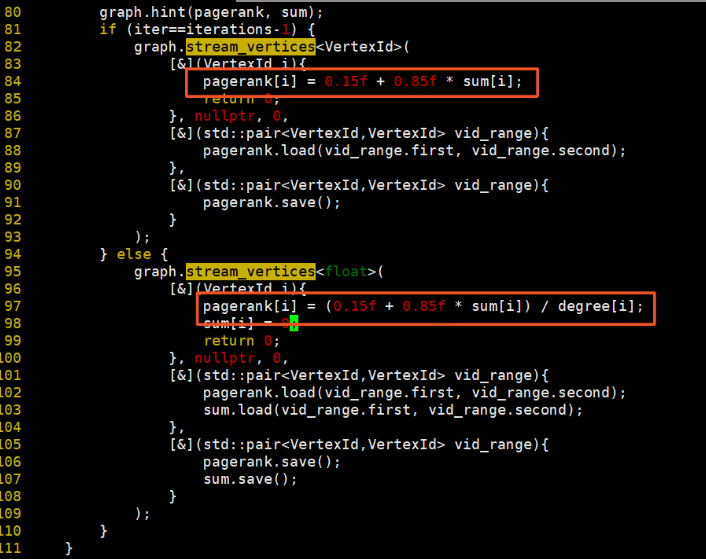
下面我們來看看實際使用,以PageRank演演算法實現為例,這裡不再詳述PageRank演演算法原理。
PageRank演演算法實現
程式碼位於:example/pagerank.cpp
先初始化每個頂點的degree:在這裡update_mode=0,使用行主序更新。
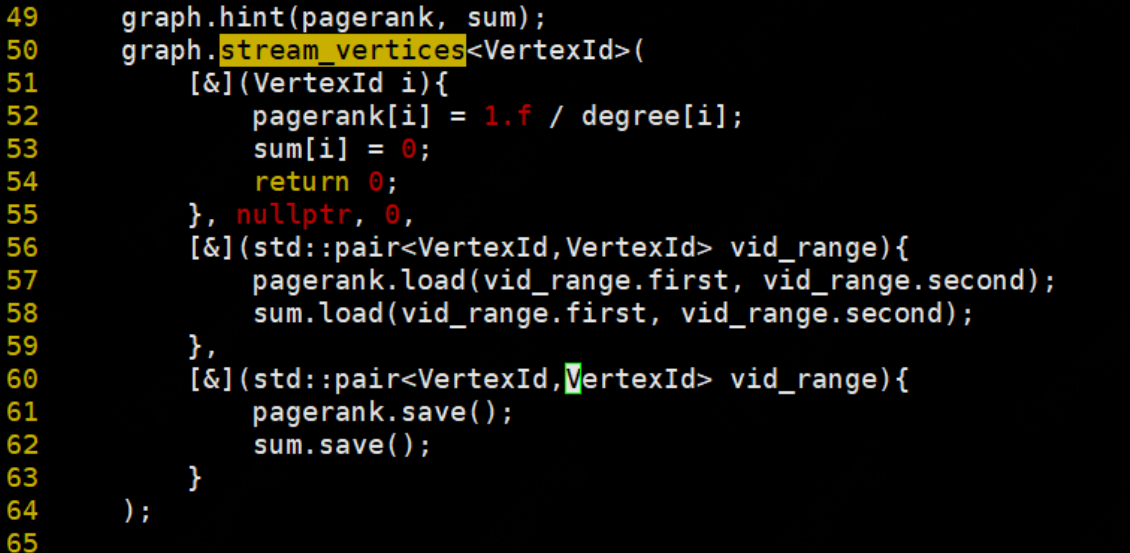
初始化每個頂點的pr值為1:
遍歷每一條邊更新計算每條邊的貢獻值:
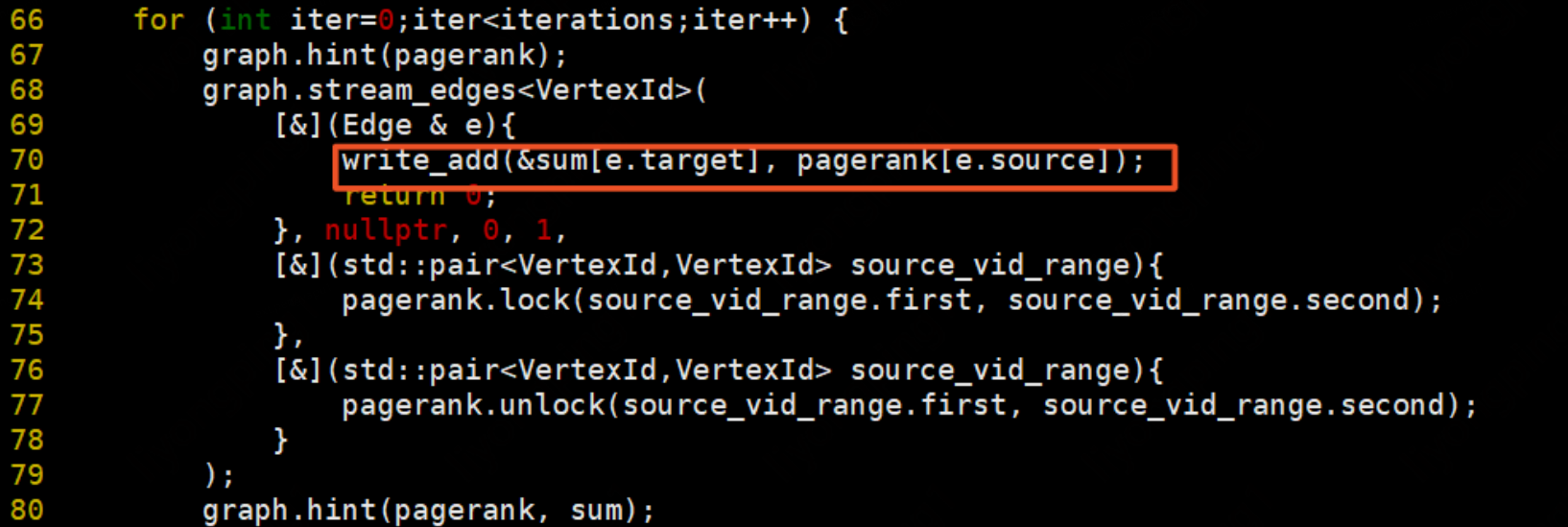
更新每個頂點上的pr值,最後一輪迭代則直接計算並更新sum:
總結
在grid檔案處理中,有幾個可優化的點:
1)、在讀取輸入檔案時,可以根據檔案個數並行讀取檔案,加快檔案處理速度。
2)、初始化grid空間,因為初始化時每個block互不影響,可以使用omp並行初始化提高效率。
3)、thread執行緒中,因為每個執行緒處理的是不同的cursor的buffers資料,每個thread生成自己的local_buffer寫入block檔案,因為threads中沒有資料互動,因此也可以並行化。
在stream_vertices和stream_edges我們都進行了分析,可以看出,不論是行主序還是列主序,都免不了折線式(Z型)的邊block遍歷策略,其可優化的點如下:
1、可將Z型邊遍歷可更改一下,改成U形遍歷,以列主序為例,當遍歷到最後一行的src時,src不變保持在記憶體中,此時dst向右移,src從下往上遍歷,以此類推,可節省P次的頁面置換。
GridGraph提供一種在有限記憶體中完成大規模圖計算系統。解決單機記憶體或分散式記憶體無法解決的大規模圖計算問題。提供一種新式的切圖方式,將頂點和邊分別劃分為1D chunk和2D block來表示大規模圖的網格表示;使用一種新的streaming-apply模型,提高IO,對頂點的區域性性友好的方式流化讀取邊block;GridGraph能夠在不涉及I/O存取的情況下存取記憶體中的頂點資料,並且跳過不需要遍歷的邊block,提高演演算法執行效率。
GridGraph將頂點劃分為P個頂點數量相等的chunk,將邊放置在以P*P的網格中的每一個block中,邊源頂點所在的chunk決定其在網格中的行,邊目的頂點所在的chunk決定其在網格中的列。它對Cache/RAM/Disk進行了兩層級的網格劃分,採用了Stream vertices and edges的圖程式設計模型。計算過程中的雙滑動視窗(Dual Sliding Windows)也大大減少了I/O開銷,特別是寫開銷。以block為單位進行選擇排程,使用原子操作保證執行緒安全的方式更新頂點。論文中提到在邊網格上採用壓縮技術,以進一步降低所需的I/O頻寬,提高效率。
參考文獻:
1. Xiaowei Zhu, Wentao Han and Wenguang Chen. GridGraph: Large-Scale Graph Processing on a Single Machine Using 2-Level Hierarchical Partitioning. Proceedings of the 2015 USENIX Annual Technical Conference, pages 375-386.
2. ZHU Xiaowei — GridGraph: Large-‐Scale Graph Processing on a Single Machine. Using 2-‐Level Hierarchical Parffoning. Xiaowei ZHU, Wentao HAN, Wenguang CHEN.Presented at USENIX ATC '15
3. Amitabha Roy, Ivo Mihailovic, Willy Zwaenepoel. X-Stream: Edge-centric Graph Processing using Streaming Partitions
4. Aapo Kyrola Carnegie Mellon University [email protected], Guy Blelloch Carnegie Mellon University [email protected],Carlos Guestrin University of Washington [email protected]. GraphChi: Large-Scale Graph Computation on Just a PC