遷移學習(COAL)《Generalized Domain Adaptation with Covariate and Label Shift CO-ALignment》
論文資訊
論文標題:Generalized Domain Adaptation with Covariate and Label Shift CO-ALignment
論文作者:Shuhan Tan, Xingchao Peng, Kate Saenko
論文來源:ICLR 2020
論文地址:download
論文程式碼:download
視屏講解:click
1 摘要
提出問題:標籤偏移;
解決方法:
原型分類器模擬類特徵分佈,並使用 Minimax Entropy 實現條件特徵對齊;
使用高置信度目標樣本偽標籤實現標籤分佈修正;
2 介紹
2.1 當前工作
假設條件標籤分佈不變 $p(y \mid x)=q(y \mid x)$,只有特徵偏移 $p(x) \neq q(x)$,忽略標籤偏移 $p(y) \neq q(y)$。
假設不成立的原因:
-
- 場景不同,標籤跨域轉移 $p(y) \neq q(y)$ 很常見;
- 如果存在標籤偏移,則當前的 UDA 工作效能顯著下降;
- 一個合適的 UDA 方法應該能同時處理協變數偏移和標籤偏移;
2.2 本文工作
本文提出類不平衡域適應 (CDA),需要同時處理 條件特徵轉移 和 標籤轉移。
具體來說,除了協變數偏移假設 $p(x) \neq q(x)$, $p(y \mid x)=q(y \mid x)$,進一步假設 $p(x \mid y) \neq q(x \mid y)$ 和 $p(y) \neq q(y)$。
CDA 的主要挑戰:
-
- 標籤偏移阻礙了主流領域自適應方法的有效性,這些方法只能邊緣對齊特徵分佈;
- 在存在標籤偏移的情況下,對齊條件特徵分佈 $p(x \mid y)$, $q(x \mid y)$ 很困難;
- 當一個或兩個域中的資料在不同類別中分佈不均時,很難訓練無偏分類器;
CDA 概述:
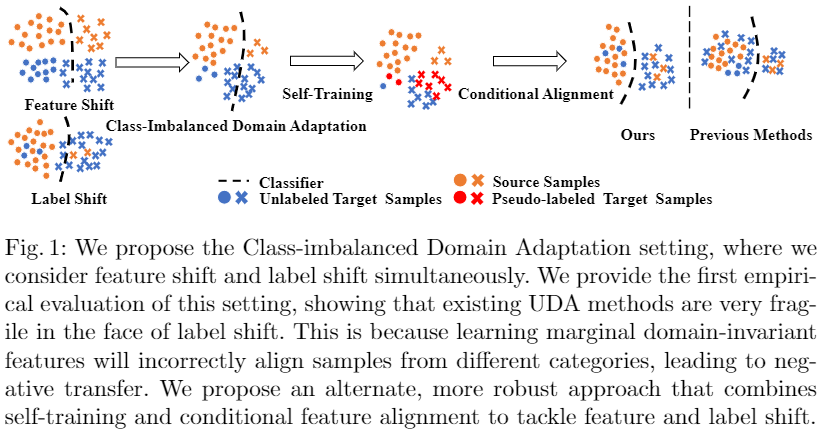
3 問題定義
In Class-imbalanced Domain Adaptation, we are given a source domain $\mathcal{D}_{\mathcal{S}}= \left\{\left(x_{i}^{s}, y_{i}^{s}\right)_{i=1}^{N_{s}}\right\}$ with $N_{s}$ labeled examples, and a target domain $\mathcal{D}_{\mathcal{T}}=\left\{\left(x_{i}^{t}\right)_{i=1}^{N_{t}}\right\}$ with $N_{t}$ unlabeled examples. We assume that $p(y \mid x)=q(y \mid x)$ but $p(x \mid y) \neq q(x \mid y)$, $p(x) \neq q(x)$ , and $p(y) \neq q(y)$ . We aim to construct an end-to-end deep neural network which is able to transfer the knowledge learned from $\mathcal{D}_{\mathcal{S}}$ to $\mathcal{D}_{\mathcal{T}}$ , and train a classifier $y=\theta(x)$ which can minimize task risk in target domain $\epsilon_{T}(\theta)=\operatorname{Pr}_{(x, y) \sim q}[\theta(x) \neq y]$.
4 方法
4.1 整體框架
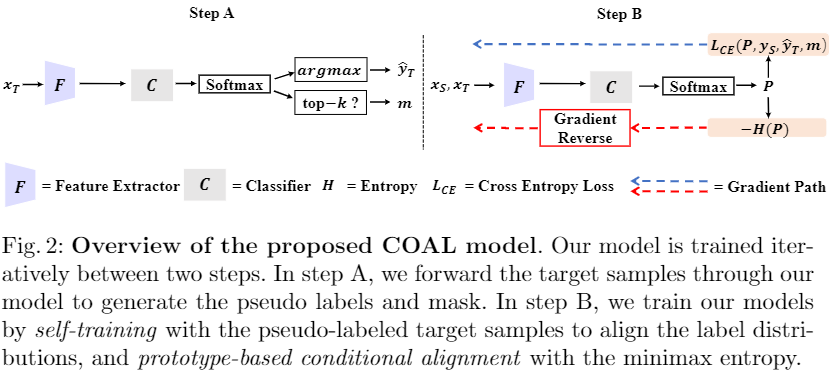
4.2 用於特徵轉移的基於原型的條件對齊
目的:對齊 $p(x \mid y)$ 和 $q(x \mid y)$
步驟:首先使用原型分類器(基於相似度)估計 $p(x \mid y)$ ,然後使用一種 $\text{minimax entropy}$ 演演算法將其和 $q(x \mid y)$ 對齊;
4.2.1 原型分類器
原因:基於原型的分類器在少樣本學習設定中表現良好,因為在標籤偏移的假設下中,某些類別的設定頻率可能較低;


# 深層原型分類器
class Predictor_deep_latent(nn.Module):
def __init__(self, in_dim = 1208, num_class = 2, temp = 0.05):
super(Predictor_deep_latent, self).__init__()
self.in_dim = in_dim
self.hid_dim = 512
self.num_class = num_class
self.temp = temp #0.05
self.fc1 = nn.Linear(self.in_dim, self.hid_dim)
self.fc2 = nn.Linear(self.hid_dim, num_class, bias=False)
def forward(self, x, reverse=False, eta=0.1):
x = self.fc1(x)
if reverse:
x = GradReverse.apply(x, eta)
feat = F.normalize(x)
logit = self.fc2(feat) / self.temp
return feat, logit
源域上的樣本使用交叉熵做監督訓練:
$\mathcal{L}_{S C}=\mathbb{E}_{(x, y) \in \mathcal{D}_{S}} \mathcal{L}_{c e}(h(x), y) \quad \quad \quad(1)$
樣本 $x$ 被分類為 $i$ 類的置信度越高,$x$ 的嵌入越接近 $w_i$。因此,在優化上式時,通過將每個樣本 $x$ 的嵌入更接近其在 $W$ 中的相應權重向量來減少類內變化。所以,可以將 $w_i$ 視為 $p$ 的代表性資料點(原型) $p(x \mid y=i)$ 。
4.2.2 通過 Minimax Entropy 實現條件對齊
目標域缺少資料標籤,所以使用 $\text{Eq.1}$ 獲得類原型是不可行的;
解決辦法:
-
- 將每個源原型移動到更接近其附近的目標樣本;
- 圍繞這個移動的原型聚類目標樣本;
因此,提出 熵極小極大 實現上述兩個目標。
具體來說,對於輸入網路的每個樣本 $x^{t} \in \mathcal{D}_{\mathcal{T}}$,可以通過下式計算分類器輸出的平均熵
$\mathcal{L}_{H}=\mathbb{E}_{x \in \mathcal{D}_{\mathcal{T}}} H(x)=-\mathbb{E}_{x \in \mathcal{D}_{\mathcal{T}}} \sum_{i=1}^{c} h_{i}(x) \log h_{i}(x)\quad \quad \quad(2)$
通過在對抗過程中對齊源原型和目標原型來實現條件特徵分佈對齊:
-
- 訓練 $C$ 以最大化 $\mathcal{L}_{H}$ ,旨在將原型從源樣本移動到鄰近的目標樣本;
- 訓練 $F$ 來最小化 $\mathcal{L}_{H}$,目的是使目標樣本的嵌入更接近它們附近的原型;
4.3 標籤轉移的類平衡自訓練
由於源標籤分佈 $p(y)$ 與目標標籤分佈 $q(y)$ 不同,因此不能保證在 $\mathcal{D}_{\mathcal{S}}$ 上具有低風險的分類器 $C$ 在 $\mathcal{D}_{\mathcal{T}}$ 上具有低錯誤。 直觀地說,如果分類器是用不平衡的源資料訓練的,決策邊界將由訓練資料中最頻繁的類別主導,導致分類器偏向源標籤分佈。 當分類器應用於具有不同標籤分佈的目標域時,其準確性會降低,因為它高度偏向源域。
為解決這個問題,本文使用[19]中的方法進行自我訓練來估計目標標籤分佈並細化決策邊界。自訓練為了細化決策邊界,本文建議通過自訓練來估計目標標籤分佈。 我們根據分類器 $C$ 的輸出將偽標籤 $y$ 分配給所有目標樣本。由於還對齊條件特徵分佈 $p(x \mid y$ 和 $q(x \mid y)$,假設分佈高置信度偽標籤 $q(y)$ 可以用作目標域的真實標籤分佈 $q(y)$ 的近似值。 在近似的目標標籤分佈下用這些偽標記的目標樣本訓練 $C$,能夠減少標籤偏移的負面影響。
為了獲得高置信度的偽標籤,對於每個類別,本文選擇屬於該類別的具有最高置信度分數的目標樣本的前 $k%$。利用 $h(x)$ 中的最高概率作為分類器對樣本 $x$ 的置信度。 具體來說,對於每個偽標記樣本 $(x, y)$,如果 $h(x)$ 位於具有相同偽標籤的所有目標樣本的前 $k%$ 中,將其選擇掩碼設定為 $m = 1$,否則 $m = 0 $。將偽標記目標集表示為 $\hat{\mathcal{D}}_{T}=\left\{\left(x_{i}^{t}, \hat{y}_{i}^{t}, m_{i}\right)_{i=1}^{N_{t}}\right\}$,利用來自 $\hat{\mathcal{D}}_{T}$ 的輸入和偽標籤來訓練分類器 $C$,旨在細化決策 與目標標籤分佈的邊界。 分類的總損失函數為:
$\mathcal{L}_{S T}=\mathcal{L}_{S C}+\mathbb{E}_{(x, \hat{y}, m) \in \hat{\mathcal{D}}_{T}} \mathcal{L}_{c e}(h(x), \hat{y}) \cdot m$
通常,用 $k_{0}=5$ 初始化 $k$,並設定 $k_{\text {step }}=5$,$k_{\max }=30$。
Note:本文還對源域資料使用了平衡取樣的方法,使得分類器不會偏向於某一類。
4.4 訓練目標
總體目標:
$\begin{array}{l}\hat{C}=\underset{C}{\arg \min } \mathcal{L}_{S T}-\alpha \mathcal{L}_{H} \\\hat{F}=\underset{F}{\arg \min } \mathcal{L}_{S T}+\alpha \mathcal{L}_{H}\end{array}$
5 總結
略
因上求緣,果上努力~~~~ 作者:VX賬號X466550,轉載請註明原文連結:https://www.cnblogs.com/BlairGrowing/p/17332967.html