SRE中的SLA/SLO/SLI
SLA通俗理解
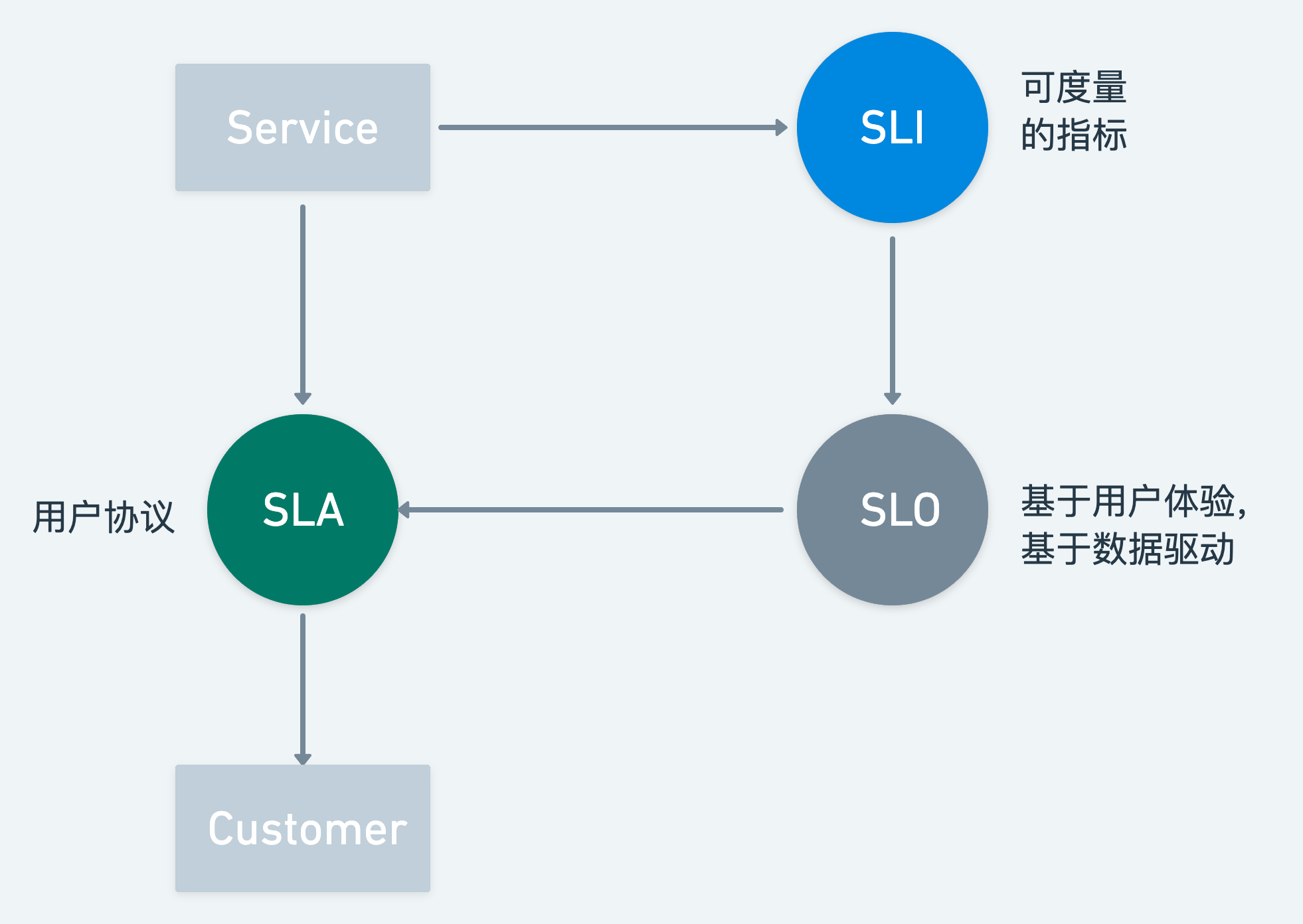
SLA 表徵服務方與客戶間的服務等級協定,定義服務方需保證的服務質量以及不達標情況下的服務補償,在SRE領域,SLA 細分為 SLI、SLO 與 SLA:
- SLI,服務質量指標,服務的某項質量的一個具體的量化指標,如時延、吞吐量、錯誤率等。
- SLO,服務質量目標,服務的某項 SLI 的具體目標值,或者目標範圍,如 99% 存取延遲 < 500ms。
- SLA,服務質量協定,描述在服務不達 SLO 情況下的後果,可簡單理解為 「SLA = SLO + 後果(懲罰)」。
由於SLA是交付給客戶的協定,因此 SLA 中的 SLO 是需要可直觀被使用者感知的,直接影響使用者體驗的,這是 SLA 隱含的應有之義。
因此,計算 SLA 主要在於定義服務不同維度的 SLI,根據不同 SLI 設計合理 SLO,並經時間段採集、計算彙總得出每個 SLO 不達標時間,進而計算服務所有 SLO 總的不可用時間,利用總時間與所有 SLO 不可用時間差值與比值,得出服務最終的 SLO。
SLO 計算模型
對於大多數服務而言,表述服務可用性最直接的方式可能就是服務可用時間。在這種體系下,常說的99.9%,99.99%,99.999%的可用性都是時間維度的統計,可以理解為:在規定的條件和規定的時間內,完成規定任務的概率。基於時間的可用性有如下表述形式:
可用性 = 系統正常執行時間 / 統計週期內的總時間
同時為了避免選擇過大的時間視窗會平滑可用性計算,無法準確表現某個時間段服務的狀態,因此將時間視窗縮小到秒級,定義在每個小時間片內的成功率要求,如果達標則認為該時間片可用,那麼可用性又可以有如下表述形式:
可用性 = 系統達標時間 / 統計週期內的總時間
時間視窗越小越精確,這其實是一個積分運算,視窗越小越能準確表現總體趨勢,但也需權衡資料分析效能與準確性,常用時間視窗1min
看一個範例:

SLO1 = 1 - T2/(T1+T2+T3+T4)
SLO2 = 1 - T3/(T1+T2+T3+T4)
根據每個指標的 SLO 結果聚合出服務的總體 SLO:
SLO = 1 - (T2+T3)/(T1+T2+T3+T4)
開放服務 SLA 建設
問題定義
- 如何定義開放服務的 SLI、SLO,是否能基本表徵服務質量?
- 採集對應 SLO 所需後設資料並計算
- SLO 不達標時,快速定位原因,並驅動服務質量提升
服務SLI
衡量服務有多個維度:效能(響應時間)、可用性(成功率)、自定義業務指標(任務佇列排隊數)等,每個維度又有多個指標,針對開放服務需挑選直接與使用者使用相關的指標、下游對服務的依賴能力等。
服務重點關注效能和可用性,結合集團內部其他衡量案例,採用 可用率(失敗率)和響應時間作為SLI。
可用率
可用率不是成功率,有很多請求失敗是使用者端傳參失效、登入態超時導致,HttpCode 以 4xx 標識。可用率可用公式
available = count(2XX) / (count(2XX) + count(5XX) - count(noise))
額外說明:
計入開放服務 SLO 的特殊情況:
- 閘道器等待服務響應超時(10s)會返回給使用者端 503,這是 閘道器層做的安全管控,可理解為:服務效能問題、網路故障、服務故障等,這部分會記入開放服務 SLO
- 開放介面轉發規則設定出錯導致503,後期閘道器可在開放介面釋出流程上做強管控儘可能避免此類問題發生
- 請求body過大(超過521KB)的攔截、大響應(超過2M)攔截
計入閘道器 SLO 的特殊情況:
- 閘道器認證中心錯誤,如超時、服務不可用
不計入 SLO 的特殊情況:
- 閘道器與服務長連線超時問題導致返回503,閘道器呼叫HTTP服務失敗,這種情況一般是業務的HTTP長連線空閒設定與閘道器不一致導致, 閘道器為60秒空閒自動關閉連線,如果業務方服務的空閒時間小於60秒就會導致這個問題,原理參考:https://segmentfault.com/a/1190000021704869
- 限流(理論上是閘道器的保護邏輯,不應計算在可用率內),包括主動限流 + 被動限流,每個開放介面預設500QPS,超過即限流;提供業務側主動限流,定向防刷
因此需消除已上噪音才能相對準確反應開放服務可用率。
響應時間
響應時間很大程度上代表服務效能,但由於不同服務不同介面的業務特點,如果強制劃定所有介面 RT 需小於一定值則有失公允,因此基於分位數計算曆史一個月服務的總體資料,eg: TP<90> < 275ms,近一個月百分之90的請求的 RT 在 275ms內,利用該值放縮至每個小時間片,時間片內每個介面 rt < 275 則符合要求,否則不滿足。隨著服務的分位數 TP<90> 的不斷迭代,進而影響每個小時間片內的達標率,促使服務效能優化。
響應時間採用如下策略:
- 服務大盤使用歷史 TP<90> 分位數作為標杆值,計算 SLO
- 重點介面使用約定指標,限定計算
最後
基於服務每個月的 SLA,可總體瞭解服務的效能及穩定性。同時基於不滿足 SLO 的時間片,通過 sls 關聯分析以及閘道器紀錄檔回溯,找到影響指標的介面,每週生成報表推播給對應服務負責人進行整改。
開放服務 SLO 每週產出開放服務報表,把服務可靠性從經驗模型向量化模型轉移,對使用者對服務方有明朗的價值。提供對應質量資料,同時針對一些指標的不足在保證最優 ROI 下去解決導致質量下降的根因,進而優化服務。
附件:
草擬閘道器服務的 SLA:
閘道器服務等級協定
本服務等級協定(Service Level Agreement,簡稱 「SLA」)規定了閘道器向客戶提供的 API 閘道器的服務可用性等級指標及賠償方案。
20xx年xx月xx日起生效。
1. 定義
服務週期:服務可用性按服務週期統計,一個服務週期為一個自然月,如客戶使用不滿一個月則以當月使用累計使用時間作為一個服務週期。
有效請求:閘道器接收到的所有請求,視為有效請求。
失敗請求:由於閘道器原因造成的 API 呼叫失敗,則視為失敗請求但不包括以下情況的呼叫失敗:
(1)因使用者設定問題導致的 API 呼叫失敗;
(2)客戶的應用程式受到駭客攻擊或者主動流量攻擊而導致被閘道器限制的請求。
(3)因使用者登入態失效導致的 API 呼叫失敗;
當出現閘道器故障無法通過獲得失敗請求數時,將通過計算前7個自然日使用者每分鐘請求數的平均值,用該平均值乘以故障時間,從而計算出該情況下的失敗請求數。
每15秒錯誤率:以15秒為單位按照如下方式計算錯誤率:
每15秒錯誤率=每15秒失敗請求數/每15秒有效總請求數x100%
月度服務費用:客戶在一個自然月中就API閘道器服務所支付的服務費用總額。以代金券結算不計入月服務費用。
2. 服務可用性
2.1 服務可用性計算方式
閘道器的服務可用性按服務週期統計,通過計算服務週期內每15秒錯誤率的平均值,從而計算得出服務可用性,即:
服務可用性=(1-服務週期內Σ每15秒錯誤率/服務週期內15秒總個數)x1
(注:服務週期內15秒總個數=4 x 60 x 24 x 該服務週期的天數)
2.2 服務可以用性承諾
對於閘道器,承諾一個服務週期內的服務可用性見下表:
|
服務型別 |
服務可用性 |
|
閘道器代理服務 |
不低於99.90% |
如閘道器未達到上述可用性承諾,客戶可以根據本協定第3條約定獲得賠償。賠償範圍不包括以下原因所導致的服務不可用:
(1)預先通知使用者後進行系統維護所引起的,包括割接、維修、升級和模擬故障演練;
(2)使用者的應用程式或資料資訊受到駭客攻擊而引起的;
(3)使用者維護不當或保密不當致使資料、口令、密碼等丟失或洩漏所引起的;
(4)不可抗力以及意外事件引起的;
3. 賠償方案
暫無