COIG:開源四類中文指令語料庫
CHINESE OPEN INSTRUCTION GENERALIST: A PRELIMINARY RELEASE
論文:https://arxiv.org/pdf/2304.07987v1.pdf
資料地址:https://huggingface.co/datasets/BAAI/COIG
Part1介紹
COIG的特點:
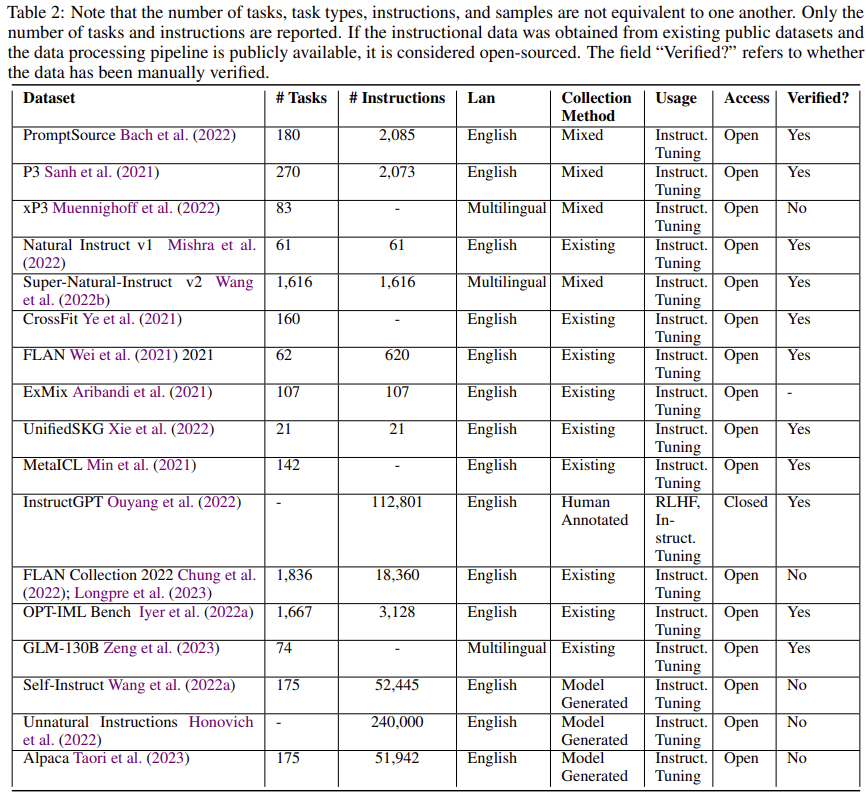
領域適應性:如表1所示。我們考慮了指令微調資料集的四個方面(驗證,格式,文化,縮放)。對於每個領域,我們調整我們的資料收集管道,以更好地反映該領域的特點。
 驗證:反應是否可以被驗證。
格式:格式是否至關重要。
文化:反應是否取決於某種文化。
尺度:尺度是否重要。
驗證:反應是否可以被驗證。
格式:格式是否至關重要。
文化:反應是否取決於某種文化。
尺度:尺度是否重要。
多樣性:我們考慮了各種任務,包括常識推理、人類價值排列、程式碼生成和幻覺糾正,而很少有中 文指令微調資料是特意為這樣一個完整的光譜而設計的。 由人類進行質量檢查:與現有的模型生成的中文教學語料庫相比,包括(Ziang Leng and Li, 2023; LianjiaTech, 2021; Xue et al., 2023; JosephusCheung, 2021),COIG的翻譯語料庫由人類註釋者仔細驗證。此外,由於COIG翻譯語料庫是從具有不同任務的英語教學語料庫(Wang等人,2022b; Honovich等人,2022;Wang等人,2022a)翻譯而來,它比在現有的中文資料集上通過適應提示工程建立的中文教學語料庫更加多樣化,例如(Zeng等人,2023;楊,2023;郭等人,2023)。
COIG資料的主要部分是已經存在於網路上的實際資料,我們根據它們的特點將其轉換為合適的指令遵循方式。例如,在學術考試領域,我們抓取了中國高考、公務員考試等63.5千條指令並進行了人工註釋。COIG的特點還包括華語世界中人類價值取向的資料,以及基於leetcode的程式設計指令的樣本。為了保證最終的資料質量,我們聘請了223名中國大學生作為質量檢查員,幫助我們進行資料過濾、修正和評級。由此產生的COIG語料庫是一個全面的集合,可以使中國的法律碩士在許多領域具有很強的指令跟隨能力。COIG語料庫可以在huggingface和github找到並將持續更新。
此外,我們根據經驗觀察提供了對資料構建管道的見解。我們證明了為不同的領域選擇合適的管道是至關重 要的,並且我們提出了在COIG所涵蓋的領域中構建指令調整資料的最佳實踐(第3節),這可以作為未來指 令語料庫構建工作流程設計的參考。
該文的貢獻如下:
據我們所知,這是最早的研究工作之一,專門總結了現有的中文指令微調語料庫,並就未來如何構建中文指令微調語料庫提出了見解。 我們構建了5個開源的高質量中文指令語料庫,包括68k的普通中文指令語料庫、62k的中文考試指令語料庫、3k的中文人值對齊語料庫和13k的中文反事實校正多輪聊天語料庫,作為沿著指出的研究方向構建新的中文教學語料庫的樣本。 我們構建了一個人工驗證的通用高質量中文指令調優語料庫,可直接用於中文LLMs的指令調優,包括商業和非商業的。
Part2現有的指令語料庫
如果指令資料是從現有的公共資料集中獲得的,並且資料處理管道是公開的,那麼它就被認為是開源的。
獲取資料集的一般手段有:人工標註、半自動和自動構建、使用LLM、翻譯。
Part3COIG:中文開源指令資料通用語料庫
第3.1節中分別介紹了一個經過人工驗證的普通指令語料庫,在第3.2節中介紹了一個經過人工註釋的考試指令語料庫,在第3.3節中介紹了一個人類價值調整指令語料庫,在第3.3節中介紹了一個多輪反事實修正聊天語料庫,在第3.5節中介紹了一個leetcode指令語料庫。我們提供這些新的指令語料庫是為了幫助社群對中文LLMs進行指令調整。這些指令語料庫也是如何有效建立和擴充套件新的中文指令語料庫的模板工作流程。
1基於翻譯的通用指令語料庫
為了減少成本並進一步提高指令語料庫的質量,我們將翻譯程式分為三個階段:自動翻譯、人工驗證和人 工糾正。 自動翻譯:將指令輸入和輸出進行拼接輸入到DeepL進行翻譯。
人工驗證:定義四個標籤:1)可直接使用;2)可以使用,但要有範例的源輸入和輸出;3)需要人工修正後使用;4)不可使用。不可用的情況非常少,不到20個。我們在人工驗證階段採用了兩階段的質量驗證:在第一階段,每個案例在經過註釋者的註釋後,由一位具有5年以上工作經驗的工業界有經驗的質量檢查員進行核查。當且僅當正確率超過95%時,整個語料庫才能進入第二個質量驗證階段。最終,該語料庫在第一個質量驗證階段得到了96.63%的正確率。我們的專家質量檢查員(即我們的合作者)負責第二個質量驗證階段,只從總語料庫中隨機抽取200個案例進行質量驗證。如果並且只有在所有抽樣的案例都被正確分類的情況下,語料庫才能夠進入人工修正階段。
人工糾正:在人工修正階段,要求註釋者將翻譯的指令和範例修正為正確的中文{指令、輸入、輸出}三要素,而不是僅僅保持翻譯的正確性。要求註釋者這樣做是因為在源的非自然指令中存在事實錯誤,可能導致LLMs的幻覺。總共有18074條指令被送入人工糾正階段。我們使用與人工驗證階段相同的兩階段質量驗證程式。在人工修正階段的第一個質量驗證階段,語料庫得到了97.24%的正確率。這些嚴格的質量驗證程式保證了翻譯語料庫的可靠性。
2考試指令語料庫
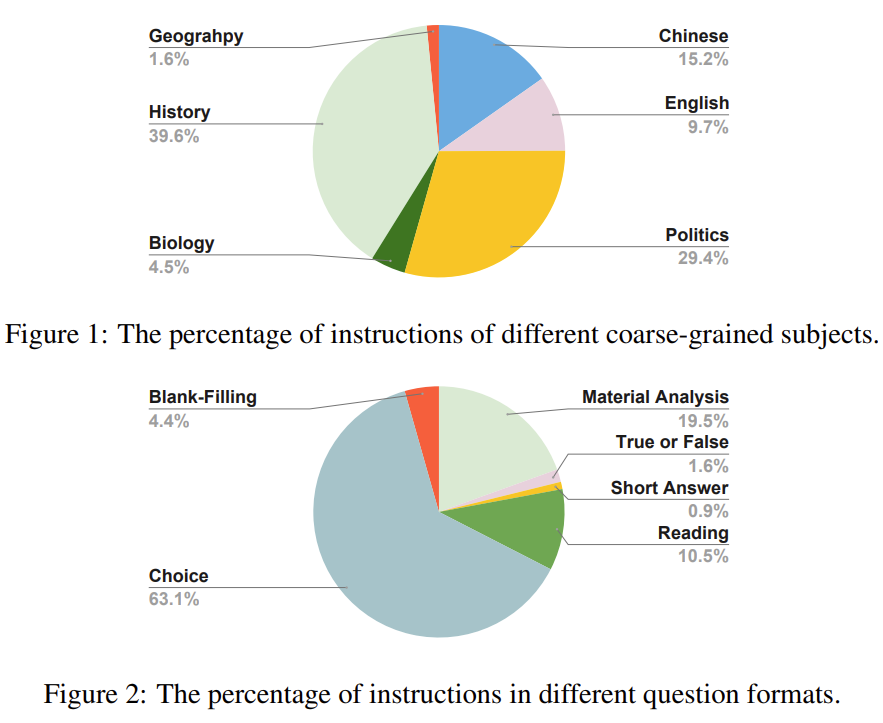
我們使用potato(Pei et al., 2022),一個主動學習驅動的開源註解網站模板,進行人工註解,從原始考試題中提取六個資訊元素,包括指令、問題背景、問題、答案、答案分析和粗粒度的主題。這些考試中有很多閱讀理解題,問題背景指的是這些閱讀理解題的閱讀材料。有六個主要的粗略科目:中文、英文、政治、生物、歷史和地質。語料庫中很少有數學、物理和化學問題,因為這些問題往往帶有複雜的符號,很難進行註釋。我們說明了問題格式百分比,說明了主要科目百分比。對於許多選擇題,我們建議研究人員利用這個語料庫,使用提示語對其進行進一步的後處理,或將其後處理為填空題,以進一步增加指令的多樣性。
3人類價值對齊指令語料庫
我們將價值排列資料分為兩個獨立的集合:1)一組呈現華語世界共同的人類價值的樣本;2)一些呈現區域文化或國家特定的人類價值的額外樣本集合。對於第一套共用的樣本,我們選擇了self-instruct( Wang et al., 2022a) 作為主要的方法來增加一套種子指令遵循的樣本。對於附加集,為了保證資料真實地反 映當地的價值觀,我們主要依靠網路爬蟲來收集原始形式的資料。
人類共同價值觀的種子指令是人工從中國道德教育的教科書和考試中挑選出來的,因為我們相信這些材料中的大部分內容已經考慮了不同群體的共同點(例如,中國有56個少數民族)。在過濾資料時,我們特意考慮了以下三個原則:
它應該介紹在華語世界被廣泛接受的人類共同價值觀,而不是區域性的。 它不應該包括政治宣傳或宗教信仰,也不應該與有爭議的索賠有關。 它不應該只是解釋諺語或名言,因為它們很可能會在知識檢索說明-後續資料中涉及。
我們總共選擇了50條指令作為擴增種子,併產生了3k條產生的指令,跟隨樣本用於華語世界的通用價值對齊。同時,我們還收集了19,470個樣本作為區域性的增補,這些樣本是針對中國使用者的(包括許多隻在中文社群使用的術語)。

4多輪反事實修正聊天語料庫
我們構建了反事實修正多輪聊天資料集(CCMC)。它是基於CN-DBpedia知識庫(Xu等人,2017) 構建的,目的是緩解和解決當前LLM中的幻覺和事實不一致的痛點。原始知識庫由5634k個實體及其對應的屬性-價值對和原始文字組成。
CCMC資料集包括一個學生和一個老師之間的5輪角色扮演聊天,以及他們參考的相應知識。老師根據基礎知識產生回答,並在每一輪中糾正學生的問題或陳述中的事實錯誤或不一致之處。在最後一輪中,老師會總結聊天內容,並審查混亂的術語,即學生的問題或陳述中的事實錯誤或不一致之處。該資料集包含13,653個對話,導致68,265輪的聊天。
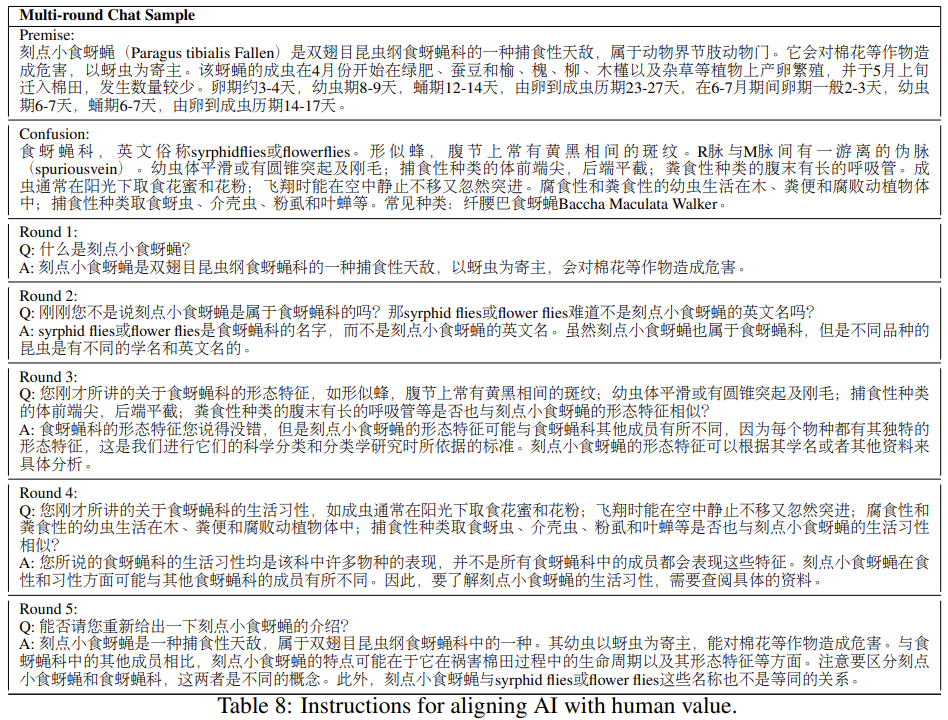
我們概述了建立CCMC資料集的工作流程。該工作流程包括三個主要部分:實體選擇、資訊提取和聊天生成。
實體選擇:根據實體標籤頻率對實體進行排名,並選擇前200名。我們優先考慮有摘要的實體 ,並旨在保留基於事實/知識的內容,如成熟的、經過歷史檢驗的概念,以及與各種學術學科、歷史事件和 社會事件相關的實體。像組織、公司、食品和遊戲這樣的標籤被排除在外。
資訊提取:使用一個聊天的LLM從知識庫中提取資訊。我們首先通過從高優先順序的類別中隨機抽出一個實體來獲得源實體,返回三聯體、內容摘要和內容部分的標題。然後我們要求聊天LLM將所有的資訊總結成一個更好的摘要,同時從輸入中提取屬性-價值對。這可以過濾掉百度標籤中的一些虛假標籤,也可以把非結構化內容中的資訊考慮進去。對於混淆實體,我們使用基於提示的方法來提取基於輸入資訊的混淆術語列表。然後我們將這些術語與知識庫進行匹配。如果該術語存在於知識庫中,我們就保留該術語,並使用同樣的方法來提取更好的摘要和屬性值對。
生成聊天記錄:採用師生問答的方式來生成聊天記錄,逐步生成攻擊和防禦場景。我們提供提取的原始實體摘要和混淆的實體摘要。然後,我們讓學生向老師詢問原始概念,同時將其與混亂的概念錯誤地混為一談。然後,老師會以JSON格式來澄清和區分這些概念。對話將持續多輪,每次都是學生根據之前的對話來挑戰老師,而老師則提供澄清和區別。在最後一輪,老師會重新介紹原來的概念,並總結容易混淆的概念,強調和區分學生之前混淆的概念。所有的聊天都是通過提示聊天LLM產生的。
5leetcode語料庫
鑑於程式碼相關的任務可能有助於LLMs的能力出現(Ouyang等人,2022),我們認為在我們的資料集中應該考慮與中文自然語言一致的程式碼相關任務。因此,我們從CC-BY-SA-4.0許可的集合中建立了Leetcode指令的2,589個程式設計問題。這些問題包含問題描述、多種程式語言和解釋.
考慮到輸入和輸出,我們將指令任務分為兩類:程式碼到文字和文字到程式碼。程式碼到文字的任務要求產生給定的程式設計程式碼的功能描述,而文字到程式碼的任務則要求從問題中輸出程式碼。根據程式問題是否有相應的解釋,任務指令將被區分為有/無解釋。我們準備了38種型別的說明來生成Leetcode指令。我們對每個程式問題的可用程式語言實現進行迭代,隨機抽取任務為程式碼到文字或文字到程式碼,然後隨機選擇一個相應的指令描述。

6指令語料庫構建工作流程的實證驗證
本節總結了關於中文指令語料庫建設工作流程的合理實證結論和經驗。
首先,當我們想擴大指令語料庫的規模時,採用語境學習(ICL)來生成新的指令(Wang等人,2022a; Honovich等人,2022)是一個關鍵的促進因素。以表1中的通用指令語料庫(LianjiaTech, 2021; Taori et al.1 為例,利用現有LLM的ICL能力而不是依靠人工註釋或其他方法來生成這些指令是比較現實的。LLM的開發者應該根據源頭的許可、源頭與OpenAI的關係以及他們的需求,仔細決定他們喜歡哪種LLM和種子指令體的關係,以及他們的需求。
其次,當目標語言和源指令語料庫的語言之間存在文化差異時,需要進行人工註釋或驗證。正如第3.3節所述,我們必須仔細選擇人工指令中的種子,以確保種子指令與中國文化保持良好的一致性,不包括政治宣傳或區域信仰。我們還建議使用現有的語料庫,比如在構建人類價值對齊指令時,使用(Ethayarajh等人,2023)中介紹的方法,即從論壇中抓取語料,並對其進行後處理,使其無害化。
第三,模型生成的語料需要更詳細的人工質量驗證,特別是在輸出格式至關重要的情況下。在第3.1節中解釋的非自然指令(Honovich等人,2022)的翻譯和驗證過程中,我們注意到許多不遵循模型生成的指令的範例,以及相當數量的不完善的模型生成的指令。另一個問題是,模型生成的指令的多樣性和分佈高度依賴於種子指令。人工選擇和驗證可能有助於從大型原始指令語料庫中抽取指令語料,其分佈比大型原始指令語料庫本身更均衡,多樣性更好,正如(Geng等人,2023)所指出的。