深度學習基礎5:交叉熵損失函數、MSE、CTC損失適用於字識別語音等序列問題、Balanced L1 Loss適用於目標檢測
深度學習基礎5:交叉熵損失函數、MSE、CTC損失適用於字識別語音等序列問題、Balanced L1 Loss適用於目標檢測
1.交叉熵損失函數
在物理學中,「熵」被用來表示熱力學系統所呈現的無序程度。夏農將這一概念引入資訊理論領域,提出了「資訊熵」概念,通過對數函數來測量資訊的不確定性。交叉熵(cross entropy)是資訊理論中的重要概念,主要用來度量兩個概率分佈間的差異。假定 p和 q是資料 x的兩個概率分佈,通過 q來表示 p的交叉熵可如下計算:
$H\left(p,q\right)=-\sum\limits_{x}p\left(x\right)\log q\left(x\right)$
交叉熵刻畫了兩個概率分佈之間的距離,旨在描繪通過概率分佈 q來表達概率分佈 p的困難程度。根據公式不難理解,交叉熵越小,兩個概率分佈 p和 q越接近。
這裡仍然以三類分類問題為例,假設資料 x屬於類別 1。記資料x的類別分佈概率為 y,顯然 y=(1,0,0)代表資料 x的實際類別分佈概率。記$\hat{y}$代表模型預測所得類別分佈概率。那麼對於資料 x而言,其實際類別分佈概率 y和模型預測類別分佈概率 $\hat{y}$的交叉熵損失函數定義為:
$cross entryy=-y\times\log(\hat{y})$
很顯然,一個良好的神經網路要儘量保證對於每一個輸入資料,神經網路所預測類別分佈概率與實際類別分佈概率之間的差距越小越好,即交叉熵越小越好。於是,可將交叉熵作為損失函數來訓練神經網路。
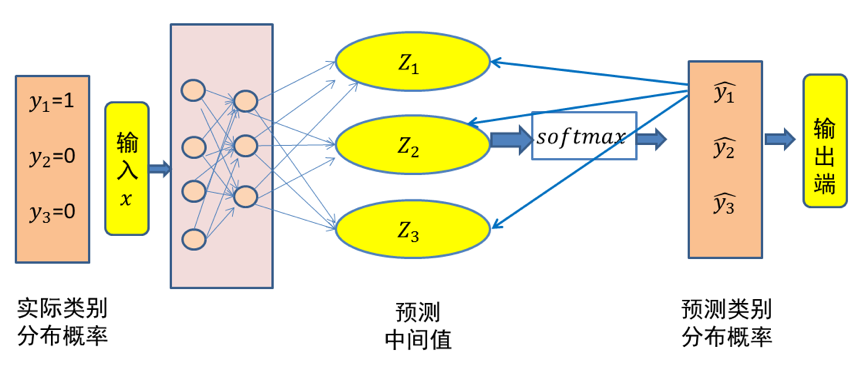
圖1 三類分類問題中輸入x的交叉熵損失示意圖(x 屬於第一類)

在上面的例子中,假設所預測中間值 (z1,z2,z3)經過 Softmax對映後所得結果為 (0.34,0.46,0.20)。由於已知輸入資料 x屬於第一類,顯然這個輸出不理想而需要對模型引數進行優化。如果選擇交叉熵損失函數來優化模型,則 (z1,z2,z3)這一層的偏導值為 (0.34−1,0.46,0.20)=(−0.66,0.46,0.20)。
可以看出,$Softmax$和交叉熵損失函數相互結合,為偏導計算帶來了極大便利。偏導計算使得損失誤差從輸出端向輸入端傳遞,來對模型引數進行優化。在這裡,交叉熵與Softmax函數結合在一起,因此也叫 $Softmax$損失(Softmax with cross-entropy loss)。
2.均方差損失(Mean Square Error,MSE)
均方誤差損失又稱為二次損失、L2損失,常用於迴歸預測任務中。均方誤差函數通過計算預測值和實際值之間距離(即誤差)的平方來衡量模型優劣。即預測值和真實值越接近,兩者的均方差就越小。
計算方式:假設有 n個訓練資料 $x_i$,每個訓練資料 $x_i$ 的真實輸出為 $y_i$,模型對 $x_i$的預測值為 $\hat{y_i}$。該模型在 n 個訓練資料下所產生的均方誤差損失可定義如下:
$MSE=\dfrac{1}{n}\sum\limits_{i=1}n\left(y_i-\hat{y}_i\right)2$
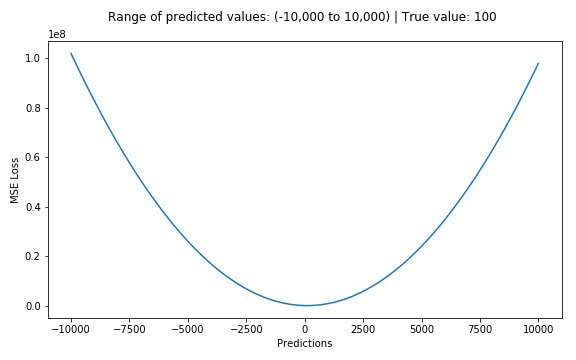
假設真實目標值為100,預測值在-10000到10000之間,我們繪製MSE函數曲線如 圖1 所示。可以看到,當預測值越接近100時,MSE損失值越小。MSE損失的範圍為0到∞。
3.CTC損失
3.1 CTC演演算法演演算法背景-----文字識別語音等序列問題
CTC 演演算法主要用來解決神經網路中標籤和預測值無法對齊的情況,通常用於文字識別以及語音等序列學習領域。舉例來說,在語音識別任務中,我們希望語音片段可以與對應的文字內容一一對應,這樣才能方便我們後續的模型訓練。但是對齊音訊與文字是一件很困難的事,如 圖1 所示,每個人的語速都不同,有人說話快,有人說話慢,我們很難按照時序資訊將語音序列切分成一個個的字元片段。而手動對齊音訊與字元又是一件非常耗時耗力的任務
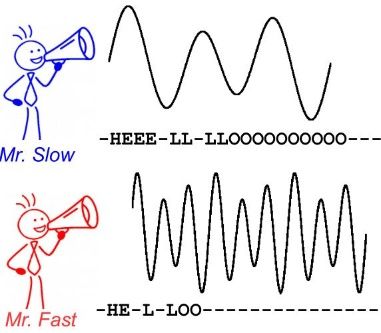
圖1 語音識別任務中音訊與文字無法對齊
在文字識別領域,由於字元間隔、影象變形等問題,相同的字元也會得到不同的預測結果,所以同樣會會遇到標籤和預測值無法對齊的情況。如 圖2 所示。

圖2 不同表現形式的相同字元示意圖
總結來說,假設我們有個輸入(如字幅圖片或音訊訊號)X ,對應的輸出是 Y,在序列學習領域,通常會碰到如下難點:
-
X和 Y都是變長的;
-
X和 Y的長度比也是變化的;
-
X和 Y相應的元素之間無法嚴格對齊。
3.2 演演算法概述
引入CTC主要就是要解決上述問題。這裡以文字識別演演算法CRNN為例,分析CTC的計算方式及作用。CRNN中,整體流程如 圖3 所示。
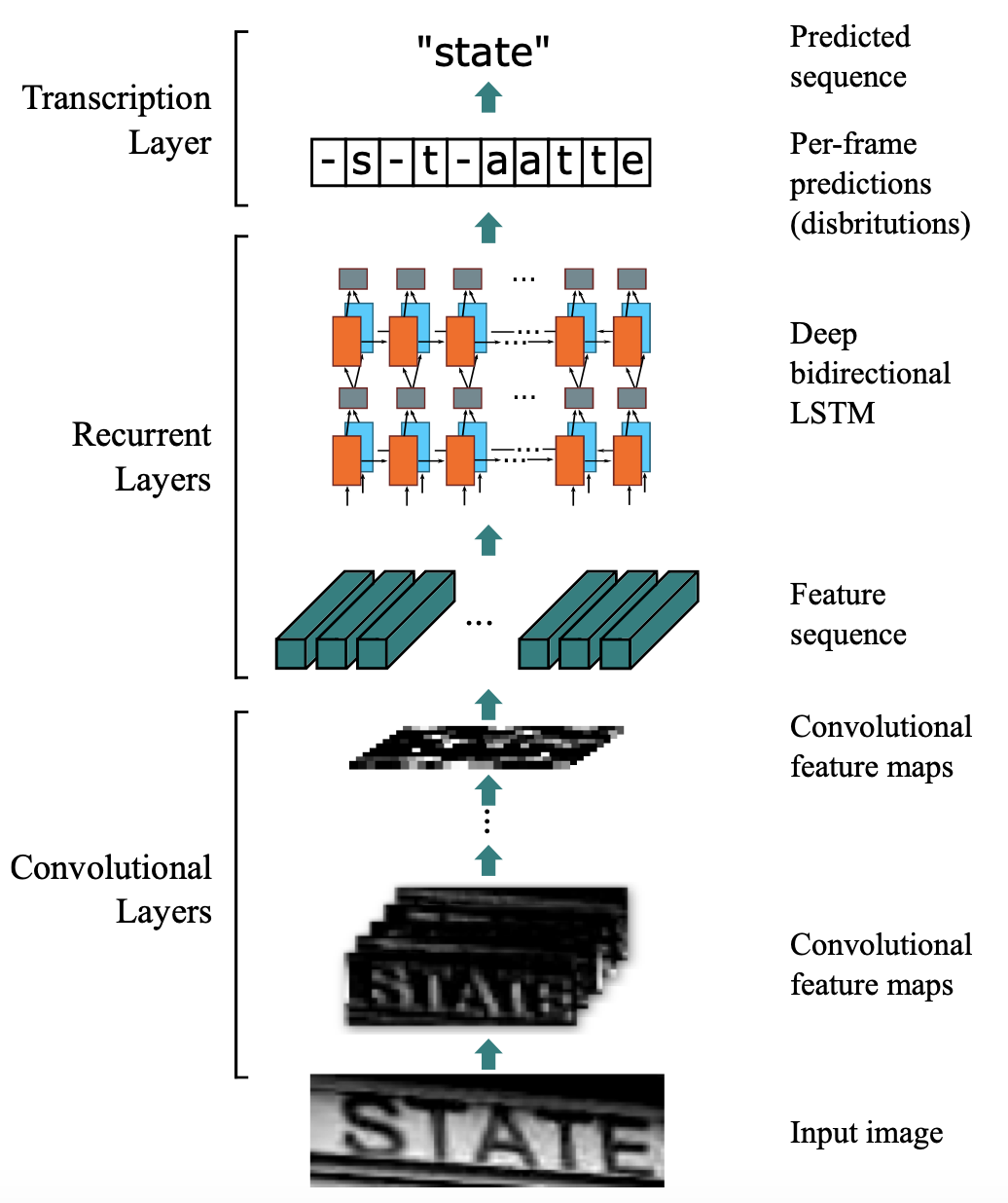
圖3 CRNN整體流程
CRNN中,首先使用CNN提取圖片特徵,特徵圖的維度為$m×T$,特徵圖 x可以定義為:
$x=(x1,x2,...,x^T)\quad\text{}$
然後,將特徵圖的每一列作為一個時間片送入LSTM中。令 t為代表時間維度的值,且滿足 $1<t<T$,則每個時間片可以表示為:
$xt=(x_1t,x_2t,\ldots,x_mt)$
經過LSTM的計算後,使用softmax獲取概率矩陣 y,定義為:
$y=(y1,y2,\ldots,y^T)$
經過LSTM的計算後,使用softmax獲取概率矩陣 $y^t$,定義為:
$yt=(y_1t,y_2t,\ldots,y_nt)$
n為字元字典的長度,由於 $y_i^t$是概率,所以$\Sigma_i y_i^t=1$ 。對每一列 $y^t$求 argmax(),就可以獲取每個類別的概率。
考慮到文字區域中字元之間存在間隔,也就是有的位置是沒有字元的,所以這裡定義分隔符 −來表示當前列的對應位置在影象中沒有出現字元。用 $L$代表原始的字元字典,則此時新的字元字典 $L′$為:
$L'=L\cup{-}$
此時,就回到了我們上文提到的問題上了,由於字元間隔、影象變形等問題,相同的字元可能會得到不同的預測結果。在CTC演演算法中,定義了 B變換來解決這個問題。 B變換簡單來說就是將模型的預測結果去掉分割符以及重複字元(如果同個字元連續出現,則表示只有1個字元,如果中間有分割符,則表示該字元出現多次),使得不同表現形式的相同字元得到統一的結果。如 圖4 所示。
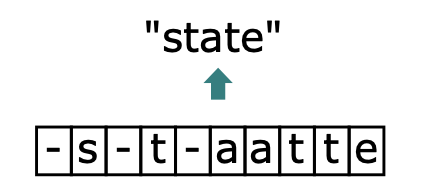
這裡舉幾個簡單的例子便於理解,這裡令T為10:
$\begin{array}{c}B(-s-t-aative)=state\ \ B(ss-t-a-t-e)=state\ \ B(sstt-aat-e)=state\end{array}$
對於字元中間有分隔符的重複字元則不進行合併:
$B(-s-t-t state)=state$
當獲得LSTM輸出後,進行 B變換就可以得到最終結果。由於 B變換並不是一對一的對映,例如上邊的3個不同的字元都可以變換為state,所以在LSTM的輸入為 x的前提下,CTC的輸出為 l的概率應該為:
$p(l|x)=\Sigma_{\pi\in B^{-1}(l)}p(\pi|x)$
其中, $pi$為LSTM的輸出向量, $\pi\in B^{-1}(l)$代表所有能通過 B變換得到 l的 $pi$的集合。
而對於任意一個 π,又有:
$p(\pi|x)=\Pi_{t=1}^T y_{\pi_t}^t$
其中, $y_{\pi_t}^t$代表 t時刻 π為對應值的概率,這裡舉一個例子進行說明:
$\begin{array}{c}\pi=-s-t-aattte\ y_{\pi_t}t=y_-1y_s2*y_-3y_t4*y_-5y_a6*y_a7y_t8*y_t9*y_e^10\ \end{array}$
不難理解,使用CTC進行模型訓練,本質上就是希望調整引數,使得$p(\pi\text{}|x)$ 取最大。
具體的引數調整方法,可以閱讀以下論文進行了解:Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks
4.平衡 L1損失(Balanced L1 Loss)---目標檢測
目標檢測(object detection)的損失函數可以看做是一個多工的損失函數,分為分類損失和檢測框迴歸損失:
$L_{p,u,tu,v}=L_{cls}(p,u)+\lambda[u\geq1]L_{loc}(t^u,v)$
$L_cls$表示分類損失函數、$L_loc$表示檢測框迴歸損失函數。在分類損失函數中,p表示預測值,u表示真實值。$t_u$表示類別u的位置迴歸結果,v是位置迴歸目標。λ用於調整多工損失權重。定義損失大於等於1.0的樣本為outliers(困難樣本,hard samples),剩餘樣本為inliers(簡單樣本,easy sample)。
平衡上述損失的一個常用方法就是調整兩個任務損失的權重,然而,迴歸目標是沒有邊界的,直接增加檢測框迴歸損失的權重將使得模型對outliers更加敏感,這些hard samples產生過大的梯度,不利於訓練。inliers相比outliers對整體的梯度貢獻度較低,相比hard sample,平均每個easy sample對梯度的貢獻為hard sample的30%,基於上述分析,提出了balanced L1 Loss(Lb)。
Balanced L1 Loss受Smooth L1損失的啟發,Smooth L1損失通過設定一個拐點來分類inliers與outliers,並對outliers通過一個$max(p,1.0)$進行梯度截斷。相比smooth l1 loss,Balanced l1 loss能顯著提升inliers點的梯度,進而使這些準確的點能夠在訓練中扮演更重要的角色。設定一個拐點區分outliers和inliers,對於那些outliers,將梯度固定為1,如下圖所示:
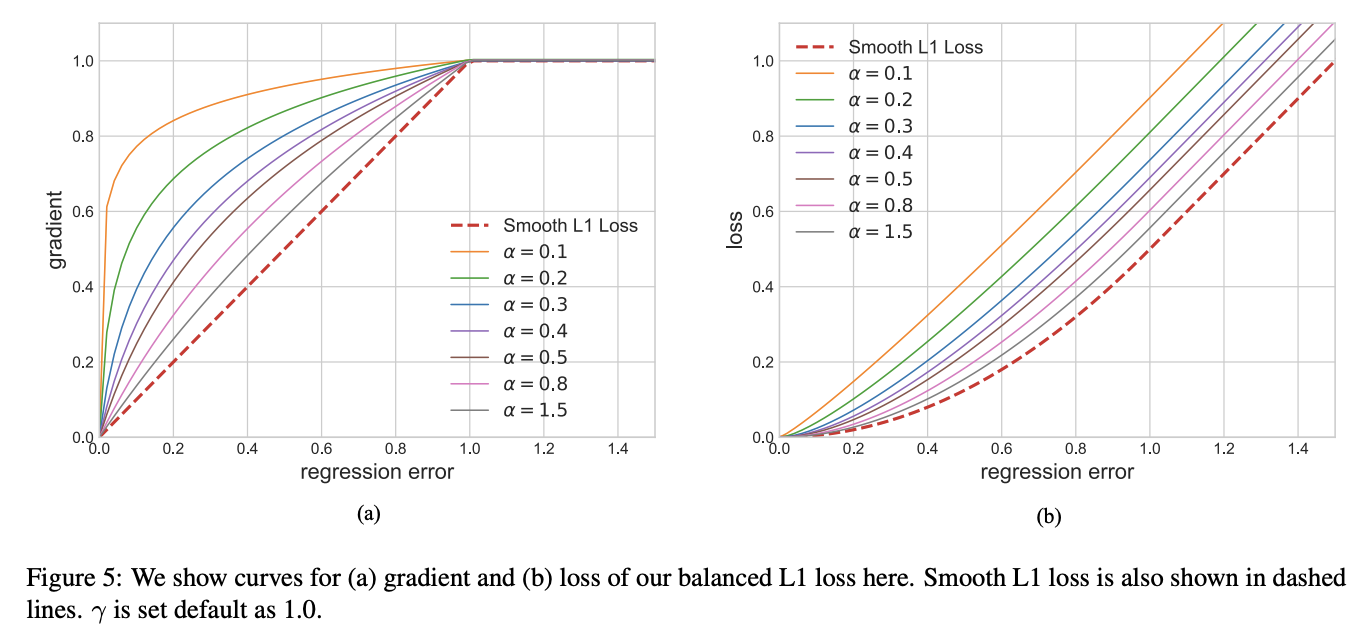
Balanced L1 Loss的核心思想是提升關鍵的迴歸梯度(來自inliers準確樣本的梯度),進而平衡包含的樣本及任務。從而可以在分類、整體定位及精確定位中實現更平衡的訓練,Balanced L1 Loss的檢測框迴歸損失如下:
$L_{loc}=\sum\limits_{i\in x,y,w,h}L_b(t_i^u-v_i)$
其相應的梯度公示如下:
$\dfrac{\partial L_{loc}}{\partial w}\propto\dfrac{\partial L_b}{\partial t_i^u}\propto\dfrac{\partial L_b}{\partial x}$
基於上述公式,設計了一種推廣的梯度公式為:
$\dfrac{\partial L_b}{\partial x}=\begin{cases}\alpha ln(b|x|+1),if|x|<1\ \gamma,otherwise\end{cases}$
其中,$α$控制著inliers梯度的提升;一個較小的α會提升inliers的梯度同時不影響outliers的值。$γ$來調整迴歸誤差的上界,能夠使得不同任務間更加平衡。α,γ從樣本和任務層面控制平衡,通過調整這兩個引數,從而達到更加平衡的訓練。Balanced L1 Loss公式如下:
$L_b(x)=\begin{cases}\frac ab(b|x|+1)ln(b|x|+1)-\alpha|x|,if|x|<1\ \gamma|x|+C,otherwise\end{cases}$
其中引數滿足下述條件:
$\alpha ln(b|x|+1)=\gamma\quad\text{}$
預設引數設定:α = 0.5,γ=1.5
Libra R-CNN: Towards Balanced Learning for Object Detection